
Para admitir un tablero de integración continua que sea escalable, eficaz y flexible, el backend del tablero VTS debe diseñarse cuidadosamente con una sólida comprensión de la funcionalidad de la base de datos. Google Cloud Datastore es una base de datos NoSQL que ofrece garantías ACID transaccionales y coherencia final, así como una coherencia sólida dentro de los grupos de entidades. Sin embargo, la estructura es muy diferente a las bases de datos SQL (e incluso a Cloud Bigtable); en lugar de tablas, filas y celdas, hay clases, entidades y propiedades.
Las siguientes secciones describen la estructura de datos y los patrones de consulta para crear un backend eficaz para el servicio web VTS Dashboard.
Entidades
Las siguientes entidades almacenan resúmenes y recursos de ejecuciones de prueba de VTS:
- Entidad de prueba . Almacena metadatos sobre ejecuciones de prueba de una prueba en particular. Su clave es el nombre de la prueba y sus propiedades incluyen el recuento de fallas, el recuento de aprobación y la lista de rupturas de casos de prueba desde el momento en que los trabajos de alerta lo actualizan.
- Entidad de ejecución de prueba . Contiene metadatos de ejecuciones de una prueba en particular. Debe almacenar las marcas de tiempo de inicio y finalización de la prueba, el ID de compilación de la prueba, el número de casos de prueba aprobados y fallidos, el tipo de ejecución (p. ej., antes del envío, después del envío o local), una lista de enlaces de registro, el host nombre de la máquina y recuentos de resumen de cobertura.
- Entidad de información del dispositivo . Contiene detalles sobre los dispositivos utilizados durante la ejecución de la prueba. Incluye el ID de compilación del dispositivo, el nombre del producto, el objetivo de compilación, la sucursal y la información de ABI. Esto se almacena por separado de la entidad de ejecución de prueba para admitir ejecuciones de prueba de varios dispositivos de uno a muchos.
- Entidad de ejecución de punto de generación de perfiles . Resume los datos recopilados para un punto de creación de perfiles en particular dentro de una ejecución de prueba. Describe las etiquetas de los ejes, el nombre del punto de generación de perfiles, los valores, el tipo y el modo de regresión de los datos de generación de perfiles.
- Entidad de Cobertura . Describe los datos de cobertura recopilados para un archivo. Contiene la información del proyecto Git, la ruta del archivo y la lista de recuentos de cobertura por línea en el archivo de origen.
- Entidad de ejecución de caso de prueba . Describe el resultado de un caso de prueba particular de una ejecución de prueba, incluido el nombre del caso de prueba y su resultado.
- Entidad de favoritos del usuario . Cada suscripción de usuario se puede representar en una entidad que contiene una referencia a la prueba y el ID de usuario generado a partir del servicio de usuario de App Engine. Esto permite consultas bidireccionales eficientes (es decir, para todos los usuarios suscritos a una prueba y para todas las pruebas marcadas como favoritas por un usuario).
agrupación de entidades
Cada módulo de prueba representa la raíz de un grupo de entidades. Las entidades de ejecución de prueba son elementos secundarios de este grupo y elementos primarios de las entidades de dispositivo, las entidades de puntos de generación de perfiles y las entidades de cobertura relevantes para la prueba respectiva y el ancestro de ejecución de prueba.
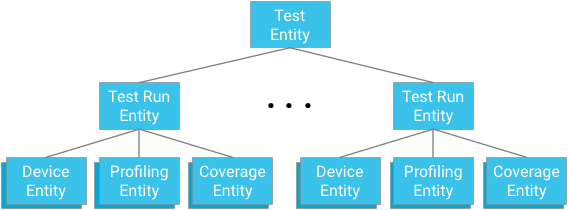
Punto clave: al diseñar relaciones de ascendencia, debe equilibrar la necesidad de proporcionar mecanismos de consulta efectivos y coherentes con las limitaciones impuestas por la base de datos.
Beneficios
El requisito de coherencia garantiza que las operaciones futuras no verán los efectos de una transacción hasta que se confirme, y que las transacciones del pasado sean visibles para las operaciones presentes. En Cloud Datastore, la agrupación de entidades crea islas de sólida coherencia de lectura y escritura dentro del grupo, que en este caso son todas las ejecuciones de prueba y los datos relacionados con un módulo de prueba. Esto ofrece los siguientes beneficios:
- Las lecturas y actualizaciones del estado del módulo de prueba mediante tareas de alerta se pueden tratar como atómicas.
- Vista coherente garantizada de los resultados de los casos de prueba dentro de los módulos de prueba
- Consultas más rápidas dentro de los árboles de ascendencia
Limitaciones
No se recomienda escribir en un grupo de entidades a una velocidad superior a una entidad por segundo, ya que es posible que se rechacen algunas escrituras. Siempre que los trabajos de alerta y la carga no se realicen a una velocidad superior a una escritura por segundo, la estructura es sólida y garantiza una gran consistencia.
En última instancia, el límite de una escritura por módulo de prueba por segundo es razonable porque las ejecuciones de prueba suelen tardar al menos un minuto, incluida la sobrecarga del marco VTS; a menos que una prueba se ejecute simultáneamente en más de 60 hosts diferentes, no puede haber un cuello de botella de escritura. Esto se vuelve aún más improbable dado que cada módulo es parte de un plan de prueba que a menudo toma más de una hora. Las anomalías se pueden manejar fácilmente si los hosts ejecutan las pruebas al mismo tiempo, provocando breves ráfagas de escrituras en los mismos hosts (por ejemplo, al detectar errores de escritura y volver a intentarlo).
Consideraciones de escala
Una ejecución de prueba no necesariamente necesita tener la prueba como su padre (por ejemplo, podría tomar alguna otra clave y tener el nombre de la prueba, la hora de inicio de la prueba como propiedades); sin embargo, esto cambiará una fuerte consistencia por una eventual consistencia. Por ejemplo, es posible que el trabajo de alerta no vea una instantánea mutuamente consistente de las ejecuciones de prueba más recientes dentro de un módulo de prueba, lo que significa que el estado global puede no mostrar una representación completamente precisa de la secuencia de ejecuciones de prueba. Esto también puede afectar la visualización de las ejecuciones de prueba dentro de un único módulo de prueba, que puede no ser necesariamente una instantánea coherente de la secuencia de ejecución. Eventualmente, la instantánea será consistente, pero no hay garantías de que los datos más actualizados lo sean.
Casos de prueba
Otro cuello de botella potencial son las pruebas grandes con muchos casos de prueba. Las dos restricciones operativas son el rendimiento máximo de escritura dentro de un grupo de entidades de una por segundo, junto con un tamaño máximo de transacción de 500 entidades.
Un enfoque sería especificar un caso de prueba que tenga una ejecución de prueba como ancestro (similar a cómo se almacenan los datos de cobertura, los datos de perfiles y la información del dispositivo):
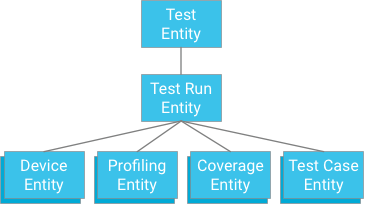
Si bien este enfoque ofrece atomicidad y consistencia, impone fuertes limitaciones a las pruebas: si una transacción está limitada a 500 entidades, entonces una prueba no puede tener más de 498 casos de prueba (suponiendo que no haya cobertura ni datos de perfil). Si una prueba superara esto, entonces una sola transacción no podría escribir todos los resultados de los casos de prueba a la vez, y dividir los casos de prueba en transacciones separadas podría exceder el rendimiento máximo de escritura del grupo de entidades de una iteración por segundo. Como esta solución no escalará bien sin sacrificar el rendimiento, no se recomienda.
Sin embargo, en lugar de almacenar los resultados de los casos de prueba como elementos secundarios de la ejecución de prueba, los casos de prueba se pueden almacenar de forma independiente y sus claves se pueden proporcionar a la ejecución de prueba (una ejecución de prueba contiene una lista de identificadores para sus entidades de casos de prueba):
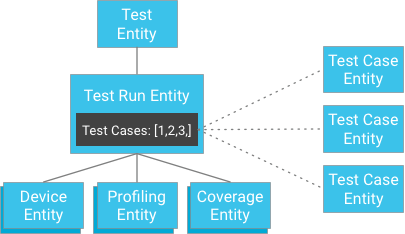
A primera vista, puede parecer que esto rompe la sólida garantía de consistencia. Sin embargo, si el cliente tiene una entidad de ejecución de prueba y una lista de identificadores de casos de prueba, no necesita construir una consulta; en cambio, puede obtener directamente los casos de prueba por sus identificadores, lo que siempre garantiza que sea consistente. Este enfoque alivia en gran medida la restricción sobre el número de casos de prueba que puede tener una ejecución de prueba al mismo tiempo que obtiene una gran consistencia sin amenazar con una escritura excesiva dentro de un grupo de entidades.
Patrones de acceso a datos
El panel VTS utiliza los siguientes patrones de acceso a datos:
- Favoritos del usuario . Se puede consultar mediante un filtro de igualdad en las entidades favoritas de los usuarios que tienen el objeto Usuario de App Engine en particular como propiedad.
- Listado de prueba . Consulta simple de entidades de prueba. Para reducir el ancho de banda para representar la página de inicio, se puede usar una proyección en los conteos aprobados y fallidos para omitir la lista potencialmente larga de ID de casos de prueba fallidos y otros metadatos utilizados por los trabajos de alerta.
- Ejecuciones de prueba . La consulta de entidades de ejecución de prueba requiere una ordenación de la clave (marca de tiempo) y un posible filtrado de las propiedades de la ejecución de prueba, como el ID de compilación, el recuento de pases, etc. Al realizar una consulta de ancestro con una clave de entidad de prueba, la lectura es muy coherente. En este punto, todos los resultados del caso de prueba se pueden recuperar utilizando la lista de ID almacenada en una propiedad de ejecución de prueba; también se garantiza que este será un resultado muy coherente por la naturaleza de las operaciones de obtención del almacén de datos.
- Perfilado y datos de cobertura . La consulta de datos de perfil o cobertura asociados con una prueba se puede realizar sin recuperar otros datos de ejecución de prueba (como otros datos de perfil/cobertura, datos de casos de prueba, etc.). Una consulta de antecesores que utilice las claves de entidad test test y test run recuperará todos los puntos de creación de perfiles registrados durante la ejecución de la prueba; al filtrar también por el nombre del punto de generación de perfiles o el nombre de archivo, se puede recuperar una sola entidad de generación de perfiles o cobertura. Por la naturaleza de las consultas de ancestros, esta operación es muy consistente.
Para obtener detalles sobre la interfaz de usuario y las capturas de pantalla de estos patrones de datos en acción, consulte Interfaz de usuario del panel VTS .