
本頁概述瞭如何實現神經網絡 API (NNAPI) 驅動程序。有關更多詳細信息,請參閱hardware/interfaces/neuralnetworks中的 HAL 定義文件中的文檔。示例驅動程序實現位於frameworks/ml/nn/driver/sample 。
有關神經網絡 API 的更多信息,請參閱神經網絡 API 。
神經網絡 HAL
神經網絡 (NN) HAL 定義了產品(例如手機或平板電腦)中的各種設備的抽象,例如圖形處理單元 (GPU) 和數字信號處理器 (DSP)。這些設備的驅動程序必須符合 NN HAL。該接口在hardware/interfaces/neuralnetworks的 HAL 定義文件中指定。
框架和驅動程序之間接口的一般流程如圖 1 所示。
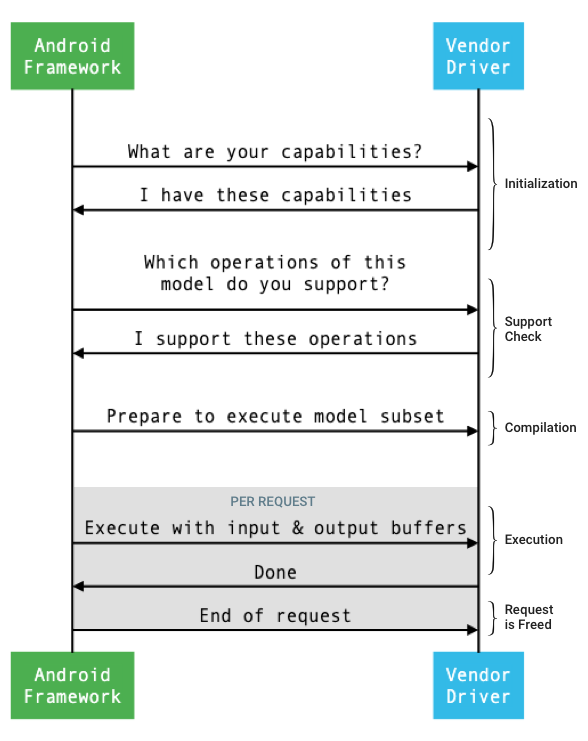
圖 1.神經網絡流程
初始化
在初始化時,框架使用IDevice::getCapabilities_1_3查詢驅動程序的功能。 @1.3::Capabilities結構包括所有數據類型,並使用向量表示非鬆弛性能。
為了確定如何將計算分配給可用設備,框架使用這些功能來了解每個驅動程序執行執行的速度和能量效率。要提供此信息,驅動程序必鬚根據參考工作負載的執行情況提供標準化的性能數字。
要確定驅動程序在響應IDevice::getCapabilities_1_3時返回的值,請使用 NNAPI 基準應用程序來測量相應數據類型的性能。建議使用 MobileNet v1 和 v2、 asr_float和tts_float模型來測量 32 位浮點值的性能,建議使用 MobileNet v1 和 v2 量化模型來測量 8 位量化值。有關詳細信息,請參閱Android 機器學習測試套件。
在 Android 9 及更低版本中, Capabilities結構僅包含浮點和量化張量的驅動程序性能信息,不包含標量數據類型。
作為初始化過程的一部分,框架可以使用IDevice::getType 、 IDevice::getVersionString 、 IDevice:getSupportedExtensions和IDevice::getNumberOfCacheFilesNeeded查詢更多信息。
在產品重新啟動之間,框架希望本節中描述的所有查詢始終報告給定驅動程序的相同值。否則,使用該驅動程序的應用程序可能會表現出性能下降或錯誤行為。
彙編
框架在收到來自應用程序的請求時確定使用哪些設備。在 Android 10 中,應用可以發現並指定框架從中挑選的設備。有關詳細信息,請參閱設備發現和分配。
在模型編譯時,框架通過調用IDevice::getSupportedOperations_1_3將模型發送給每個候選驅動程序。每個驅動程序返回一個布爾數組,指示模型的哪些操作受支持。由於多種原因,驅動程序可以確定它不能支持給定的操作。例如:
- 驅動程序不支持數據類型。
- 驅動程序僅支持具有特定輸入參數的操作。例如,驅動程序可能支持 3x3 和 5x5,但不支持 7x7 卷積操作。
- 驅動程序存在內存限制,無法處理大型圖形或輸入。
在編譯期間,模型的輸入、輸出和內部操作數(如OperandLifeTime中所述)可能具有未知的維度或等級。有關詳細信息,請參閱輸出形狀。
框架通過調用IDevice::prepareModel_1_3指示每個選定的驅動程序準備執行模型的子集。然後每個驅動程序編譯它的子集。例如,驅動程序可能會生成代碼或創建權重的重新排序副本。因為在模型的編譯和請求的執行之間可能有很長的時間,所以不應在編譯期間分配諸如大塊設備內存之類的資源。
成功時,驅動程序返回一個@1.3::IPreparedModel句柄。如果驅動程序在準備模型的子集時返回失敗代碼,則框架在 CPU 上運行整個模型。
為了減少應用程序啟動時用於編譯的時間,驅動程序可以緩存編譯工件。有關詳細信息,請參閱編譯緩存。
執行
當應用程序要求框架執行請求時,框架默認調用IPreparedModel::executeSynchronously_1_3 HAL 方法對準備好的模型執行同步執行。請求也可以使用execute_1_3方法、 executeFenced方法(請參閱 Fenced execution )異步執行,或使用突發執行執行。
與異步調用相比,同步執行調用提高了性能並減少了線程開銷,因為只有在執行完成後才將控制權返回給應用進程。這意味著驅動程序不需要單獨的機制來通知應用進程執行已完成。
使用異步execute_1_3方法,在執行開始後控制權返回到應用程序進程,並且驅動程序必須在執行完成時通知框架,使用@1.3::IExecutionCallback 。
傳遞給 execute 方法的Request參數列出了用於執行的輸入和輸出操作數。存儲操作數數據的內存必須使用行優先順序,第一個維度的迭代速度最慢,並且在任何行的末尾都沒有填充。有關操作數類型的更多信息,請參閱操作數。
對於 NN HAL 1.2 或更高版本的驅動程序,當請求完成時,會將錯誤狀態、輸出形狀和時序信息返回給框架。在執行期間,模型的輸出或內部操作數可能具有一個或多個未知維度或未知等級。當至少一個輸出操作數具有未知維度或等級時,驅動程序必須返回動態大小的輸出信息。
對於 NN HAL 1.1 或更低版本的驅動程序,請求完成時僅返回錯誤狀態。必須完全指定輸入和輸出操作數的維度才能成功完成執行。內部操作數可以有一個或多個未知維度,但它們必須具有指定的等級。
對於跨越多個驅動程序的用戶請求,框架負責保留中間內存和對每個驅動程序的調用進行排序。
多個請求可以在同一個@1.3::IPreparedModel上並行發起。驅動程序可以並行執行請求或序列化執行。
該框架可以要求驅動程序保留多個準備好的模型。例如,準備模型m1 ,準備m2 ,在m1上執行請求r1 ,在m2上執行r2 ,在m1上執行r3 ,在m2上執行r4 ,釋放(在Cleanup中描述) m1 ,然後釋放m2 。
為避免可能導致糟糕的用戶體驗(例如,第一幀卡頓)的緩慢首次執行,驅動程序應在編譯階段執行大多數初始化。首次執行時的初始化應僅限於在早期執行時會對系統健康產生負面影響的操作,例如保留大型臨時緩衝區或增加設備的時鐘頻率。只能準備有限數量的並發模型的驅動程序可能必須在第一次執行時進行初始化。
在 Android 10 或更高版本中,在快速連續執行相同準備模型的多個執行的情況下,客戶端可以選擇使用執行突發對像在應用程序和驅動程序進程之間進行通信。有關詳細信息,請參閱突發執行和快速消息隊列。
為了提高快速連續多次執行的性能,驅動程序可以保留臨時緩衝區或提高時鐘頻率。如果在固定時間後沒有創建新請求,建議創建看門狗線程以釋放資源。
輸出形狀
對於一個或多個輸出操作數未指定所有維度的請求,驅動程序必須提供輸出形狀列表,其中包含執行後每個輸出操作數的維度信息。有關尺寸的更多信息,請參閱OutputShape 。
如果由於輸出緩衝區大小不足而導致執行失敗,驅動程序必須在輸出形狀列表中指出哪些輸出操作數的緩衝區大小不足,並且應該報告盡可能多的維度信息,對於未知的維度使用零。
定時
在 Android 10 中,如果應用在編譯過程中指定了要使用的單個設備,則應用可以詢問執行時間。有關詳細信息,請參閱MeasureTiming和Device Discovery and Assignment 。在這種情況下,NN HAL 1.2 驅動程序必須在執行請求時測量執行持續時間或報告UINT64_MAX (以指示持續時間不可用)。驅動程序應盡量減少因測量執行持續時間而導致的任何性能損失。
驅動程序在Timing結構中報告以下持續時間(以微秒為單位):
- 設備上的執行時間:不包括在主機處理器上運行的驅動程序中的執行時間。
- 驅動程序中的執行時間:包括設備上的執行時間。
這些持續時間必須包括執行暫停的時間,例如,當執行被其他任務搶占或等待資源變得可用時。
如果未要求驅動程序測量執行持續時間,或者存在執行錯誤,則驅動程序必須將持續時間報告為UINT64_MAX 。即使已要求驅動程序測量執行持續時間,它也可以報告UINT64_MAX以表示設備上的時間、驅動程序中的時間或兩者。當驅動程序將兩個持續時間報告為UINT64_MAX以外的值時,驅動程序中的執行時間必須等於或超過設備上的時間。
圍欄執行
在 Android 11 中,NNAPI 允許執行等待sync_fence句柄列表,並可選擇返回一個sync_fence對象,該對像在執行完成時發出信號。這減少了小序列模型和流用例的開銷。 Fenced 執行還允許與可以發出信號或等待sync_fence的其他組件進行更有效的互操作性。有關sync_fence的更多信息,請參閱同步框架。
在受保護的執行中,框架調用IPreparedModel::executeFenced方法在準備好的模型上啟動受保護的異步執行,並等待同步柵欄向量。如果異步任務在調用返回之前完成,則可以為sync_fence返回一個空句柄。還必須返回一個IFencedExecutionCallback對象,以允許框架查詢錯誤狀態和持續時間信息。
執行完成後,可以通過IFencedExecutionCallback::getExecutionInfo查詢以下兩個測量執行時長的計時值。
-
timingLaunched:從調用executeFenced到executeFencedsyncFence的持續時間。 -
timingFenced:從執行等待的所有同步柵欄發出信號到 executeFenced 發出返回的executeFenced信號的syncFence。
控制流
對於運行 Android 11 或更高版本的設備,NNAPI 包括兩個控制流操作,即IF和WHILE ,它們將其他模型作為參數並有條件地 ( IF ) 或重複地執行它們 ( WHILE )。有關如何實現此功能的更多信息,請參閱控制流。
服務質量
在 Android 11 中,NNAPI 包括改進的服務質量 (QoS),它允許應用指示其模型的相對優先級、準備模型的最大預期時間量以及預期執行的最大時間量要完成的。有關詳細信息,請參閱服務質量。
清理
當應用程序完成使用準備好的模型時,框架會釋放其對@1.3::IPreparedModel對象的引用。當不再引用IPreparedModel對象時,它會在創建它的驅動程序服務中自動銷毀。此時可以在驅動程序的析構函數實現中回收特定於模型的資源。如果驅動服務希望IPreparedModel對像在客戶端不再需要時自動銷毀,則在通過IPreparedModelCallback::notify_1_3返回IPreparedeModel對像後,它不得持有對IPreparedModel對象的任何引用。
CPU使用率
驅動程序應使用 CPU 來設置計算。驅動程序不應使用 CPU 執行圖形計算,因為這會干擾框架正確分配工作的能力。驅動程序應該向框架報告它無法處理的部分,並讓框架處理其餘部分。
該框架為除供應商定義的操作之外的所有 NNAPI 操作提供 CPU 實現。有關詳細信息,請參閱供應商擴展。
Android 10(API 級別 29)中引入的操作只有一個參考 CPU 實現來驗證 CTS 和 VTS 測試是否正確。移動機器學習框架中包含的優化實現優於 NNAPI CPU 實現。
實用功能
NNAPI 代碼庫包括可供驅動程序服務使用的實用功能。
frameworks/ml/nn/common/include/Utils.h文件包含各種實用功能,例如用於記錄和在不同 NN HAL 版本之間轉換的實用功能。
VLogging:
VLOG是圍繞 AndroidLOG的包裝宏,僅當在debug.nn.vlog屬性中設置了適當的標記時才會記錄消息。initVLogMask()必須在對VLOG的任何調用之前調用。VLOG_IS_ON宏可用於檢查當前是否啟用了VLOG,如果不需要,可以跳過複雜的日誌記錄代碼。財產的價值必須是以下之一:- 一個空字符串,表示不進行日誌記錄。
- 令牌
1或all,表示要完成所有日誌記錄。 - 標籤列表,由空格、逗號或冒號分隔,指示要執行的日誌記錄。標籤是
cpuexecompilationdriver、execution、manager和model。
compliantWithV1_*:如果可以將 NN HAL 對象轉換為不同 HAL 版本的相同類型而不會丟失信息,則返回true。例如,如果模型包含 NN HAL 1.1 或 NN HAL 1.2 中引入的操作類型,則對V1_2::Model調用compliantWithV1_0將返回false。convertToV1_*:將 NN HAL 對像從一個版本轉換為另一個版本。如果轉換導致信息丟失(即,如果類型的新版本不能完全表示該值),則會記錄警告。Capabilities:
nonExtensionOperandPerformance和update函數可用於幫助構建Capabilities::operandPerformance字段。查詢類型的屬性:
isExtensionOperandType,isExtensionOperationType,nonExtensionSizeOfData,nonExtensionOperandSizeOfData,nonExtensionOperandTypeIsScalar,tensorHasUnspecifiedDimensions。
frameworks/ml/nn/common/include/ValidateHal.h文件包含用於根據其 HAL 版本規範驗證 NN HAL 對像是否有效的實用程序函數。
-
validate*:如果 NN HAL 對像根據其 HAL 版本的規範有效,則返回true。 OEM 類型和擴展類型未經過驗證。例如,如果模型包含引用不存在的操作數索引的操作,或者該 HAL 版本不支持的操作,則validateModel將返回false。
frameworks/ml/nn/common/include/Tracing.h文件包含用於簡化將系統跟踪信息添加到神經網絡代碼的宏。例如,請參閱示例驅動程序中的NNTRACE_*宏調用。
frameworks/ml/nn/common/include/GraphDump.h文件包含一個實用函數,用於以圖形形式轉儲Model的內容以進行調試。
-
graphDump:將 Graphviz (.dot) 格式的模型表示寫入指定的流(如果提供)或 logcat (如果沒有提供流)。
驗證
要測試 NNAPI 的實現,請使用 Android 框架中包含的 VTS 和 CTS 測試。 VTS 直接練習您的驅動程序(不使用框架),而 CTS 通過框架間接練習它們。這些測試每個 API 方法並驗證驅動程序支持的所有操作是否正常工作並提供滿足精度要求的結果。
NNAPI 在 CTS 和 VTS 中的精度要求如下:
浮點數: abs(預期 - 實際) <= atol + rtol * abs(預期);在哪裡:
- 對於 fp32,atol = 1e-5f,rtol = 5.0f * 1.1920928955078125e-7
- 對於 fp16,atol = rtol = 5.0f * 0.0009765625f
量化: off-by-one(
mobilenet_quantized除外,它是 off-by-3)布爾值:完全匹配
CTS 測試 NNAPI 的一種方法是生成固定的偽隨機圖,用於測試和比較來自每個驅動程序的執行結果與 NNAPI 參考實現。對於 NN HAL 1.2 或更高版本的驅動程序,如果結果不符合精度標準,CTS 會報告錯誤並將失敗模型的規範文件轉儲到/data/local/tmp下以進行調試。有關精度標準的更多詳細信息,請參閱TestRandomGraph.cpp和TestHarness.h 。
模糊測試
模糊測試的目的是在被測代碼中發現由於意外輸入等因素導致的崩潰、斷言、內存違規或一般未定義行為。對於 NNAPI 模糊測試,Android 使用基於libFuzzer的測試,這些測試在模糊測試方面非常有效,因為它們使用先前測試用例的行覆蓋來生成新的隨機輸入。例如,libFuzzer 偏愛在新代碼行上運行的測試用例。這大大減少了測試查找有問題的代碼所花費的時間。
要執行模糊測試以驗證您的驅動程序實現,請修改 AOSP 中的libneuralnetworks_driver_fuzzer測試實用程序中的frameworks/ml/nn/runtime/test/android_fuzzing/DriverFuzzTest.cpp以包含您的驅動程序代碼。有關 NNAPI 模糊測試的更多信息,請參閱frameworks/ml/nn/runtime/test/android_fuzzing/README.md 。
安全
因為應用程序進程直接與驅動程序的進程通信,所以驅動程序必須驗證他們收到的調用的參數。此驗證由 VTS 驗證。驗證代碼在frameworks/ml/nn/common/include/ValidateHal.h中。
驅動程序還應確保應用程序在使用同一設備時不會干擾其他應用程序。
Android 機器學習測試套件
Android 機器學習測試套件 (MLTS) 是 CTS 和 VTS 中包含的 NNAPI 基準測試,用於驗證供應商設備上真實模型的準確性。該基準評估延遲和準確性,並將驅動程序的結果與使用在 CPU 上運行的TF Lite的結果進行比較,用於相同的模型和數據集。這可確保驅動程序的準確性不低於 CPU 參考實現。
Android 平台開發人員還使用 MLTS 來評估驅動程序的延遲和準確性。
NNAPI 基準可以在 AOSP 的兩個項目中找到:
-
platform/test/mlts/benchmark(基準應用程序) -
platform/test/mlts/models(模型和數據集)
模型和數據集
NNAPI 基準測試使用以下模型和數據集。
- MobileNetV1 float 和 u8 量化為不同大小,針對 Open Images Dataset v4 的一小部分(1500 張圖像)運行。
- MobileNetV2 float 和 u8 量化為不同大小,針對 Open Images Dataset v4 的一小部分(1500 張圖像)運行。
- 基於長短期記憶 (LSTM) 的文本轉語音聲學模型,針對 CMU 北極集的一小部分運行。
- 基於 LSTM 的自動語音識別聲學模型,針對 LibriSpeech 數據集的一小部分運行。
有關更多信息,請參閱platform/test/mlts/models 。
壓力測試
Android 機器學習測試套件包括一系列碰撞測試,以驗證驅動程序在大量使用條件下或客戶端行為的極端情況下的彈性。
所有碰撞測試都提供以下功能:
- 掛起檢測:如果 NNAPI 客戶端在測試期間掛起,則測試失敗,失敗原因為
HANG,並且測試套件移動到下一個測試。 - NNAPI 客戶端崩潰檢測:測試在客戶端崩潰後仍然存在,並且測試因失敗原因而失敗
CRASH。 - 驅動程序崩潰檢測:測試可以檢測導致 NNAPI 調用失敗的驅動程序崩潰。請注意,驅動程序進程中可能存在不會導致 NNAPI 失敗且不會導致測試失敗的崩潰。為解決此類故障,建議在系統日誌中運行
tail命令以查找與驅動程序相關的錯誤或崩潰。 - 針對所有可用加速器:針對所有可用驅動程序運行測試。
所有碰撞測試都有以下四種可能的結果:
-
SUCCESS:執行完成且沒有錯誤。 -
FAILURE:執行失敗。通常由測試模型時失敗引起,表明驅動程序未能編譯或執行模型。 -
HANG:測試過程變得無響應。 -
CRASH:測試過程崩潰。
有關壓力測試的更多信息和崩潰測試的完整列表,請參閱platform/test/mlts/benchmark/README.txt 。
使用 MLTS
要使用 MLTS:
- 將目標設備連接到您的工作站並確保可以通過adb訪問它。如果連接了多個設備,則導出目標設備
ANDROID_SERIAL環境變量。 cd進入 Android 頂級源目錄。source build/envsetup.sh lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available. ./test/mlts/benchmark/build_and_run_benchmark.sh在基準運行結束時,結果以 HTML 頁面的形式呈現並傳遞給
xdg-open。
有關更多信息,請參閱platform/test/mlts/benchmark/README.txt 。
神經網絡 HAL 版本
本節介紹 Android 和神經網絡 HAL 版本中引入的更改。
安卓 11
Android 11 引入了 NN HAL 1.3,其中包括以下顯著變化。
- 支持 NNAPI 中的有符號 8 位量化。添加
TENSOR_QUANT8_ASYMM_SIGNED操作數類型。支持無符號量化操作的 NN HAL 1.3 驅動程序還必須支持這些操作的有符號變體。在運行大多數量化操作的有符號和無符號版本時,驅動程序必須產生相同的結果,最大偏移量為 128。此要求有五個例外:CAST、HASHTABLE_LOOKUP、LSH_PROJECTION、PAD_V2和QUANTIZED_16BIT_LSTM。QUANTIZED_16BIT_LSTM操作不支持有符號操作數,其他四個操作支持有符號量化,但不要求結果相同。 - 支持防護執行,其中框架調用
IPreparedModel::executeFenced方法在準備好的模型上啟動防護的異步執行,並等待同步防護向量。有關詳細信息,請參閱圍欄執行。 - 支持控制流。添加
IF和WHILE操作,它們將其他模型作為參數並有條件地(IF)或重複(WHILE)執行它們。有關詳細信息,請參閱控制流。 - 改進的服務質量 (QoS) 應用程序可以指示其模型的相對優先級、準備模型的最大預期時間量以及完成執行的預期最大時間量。有關詳細信息,請參閱服務質量。
- 支持為驅動程序管理的緩衝區提供分配器接口的內存域。這允許跨執行傳遞設備本機內存,抑制在同一驅動程序上連續執行之間不必要的數據複製和轉換。有關詳細信息,請參閱內存域。
安卓 10
Android 10 引入了 NN HAL 1.2,其中包括以下顯著變化。
-
Capabilities結構包括所有數據類型,包括標量數據類型,並使用向量而不是命名字段來表示非鬆弛性能。 -
getVersionString和getType方法允許框架檢索設備類型 (DeviceType) 和版本信息。請參閱設備發現和分配。 - 默認調用
executeSynchronously方法以同步執行。execute_1_2方法告訴框架異步執行。請參閱執行。 -
executeSynchronously、execute_1_2和突發執行的MeasureTiming參數指定驅動程序是否要測量執行持續時間。結果在Timing結構中報告。請參閱時序。 - 支持一個或多個輸出操作數具有未知維度或等級的執行。請參閱輸出形狀。
- 支持供應商擴展,這是供應商定義的操作和數據類型的集合。驅動程序通過
IDevice::getSupportedExtensions方法報告支持的擴展。請參閱供應商擴展。 - 突發對象能夠使用快速消息隊列 (FMQ) 在應用程序和驅動程序進程之間進行通信來控制一組突發執行,從而減少延遲。請參閱突發執行和快速消息隊列。
- 支持 AHardwareBuffer 以允許驅動程序在不復制數據的情況下執行執行。請參閱AHardwareBuffer 。
- 改進了對編譯工件緩存的支持,以減少應用程序啟動時用於編譯的時間。請參閱編譯緩存。
Android 10 引入了以下操作數類型和操作。
ANEURALNETWORKS_BOOL-
ANEURALNETWORKS_FLOAT16 -
ANEURALNETWORKS_TENSOR_BOOL8 -
ANEURALNETWORKS_TENSOR_FLOAT16 -
ANEURALNETWORKS_TENSOR_QUANT16_ASYMM -
ANEURALNETWORKS_TENSOR_QUANT16_SYMM -
ANEURALNETWORKS_TENSOR_QUANT8_SYMM -
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL
ANEURALNETWORKS_ABS-
ANEURALNETWORKS_ARGMAX -
ANEURALNETWORKS_ARGMIN -
ANEURALNETWORKS_AXIS_ALIGNED_BBOX_TRANSFORM -
ANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_LSTM -
ANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_RNN -
ANEURALNETWORKS_BOX_WITH_NMS_LIMIT -
ANEURALNETWORKS_CAST -
ANEURALNETWORKS_CHANNEL_SHUFFLE -
ANEURALNETWORKS_DETECTION_POSTPROCESSING -
ANEURALNETWORKS_EQUAL -
ANEURALNETWORKS_EXP -
ANEURALNETWORKS_EXPAND_DIMS -
ANEURALNETWORKS_GATHER -
ANEURALNETWORKS_GENERATE_PROPOSALS -
ANEURALNETWORKS_GREATER -
ANEURALNETWORKS_GREATER_EQUAL -
ANEURALNETWORKS_GROUPED_CONV_2D -
ANEURALNETWORKS_HEATMAP_MAX_KEYPOINT -
ANEURALNETWORKS_INSTANCE_NORMALIZATION -
ANEURALNETWORKS_LESS -
ANEURALNETWORKS_LESS_EQUAL -
ANEURALNETWORKS_LOG -
ANEURALNETWORKS_LOGICAL_AND -
ANEURALNETWORKS_LOGICAL_NOT -
ANEURALNETWORKS_LOGICAL_OR -
ANEURALNETWORKS_LOG_SOFTMAX -
ANEURALNETWORKS_MAXIMUM -
ANEURALNETWORKS_MINIMUM -
ANEURALNETWORKS_NEG -
ANEURALNETWORKS_NOT_EQUAL -
ANEURALNETWORKS_PAD_V2 -
ANEURALNETWORKS_POW -
ANEURALNETWORKS_PRELU -
ANEURALNETWORKS_QUANTIZE -
ANEURALNETWORKS_QUANTIZED_16BIT_LSTM -
ANEURALNETWORKS_RANDOM_MULTINOMIAL -
ANEURALNETWORKS_REDUCE_ALL -
ANEURALNETWORKS_REDUCE_ANY -
ANEURALNETWORKS_REDUCE_MAX -
ANEURALNETWORKS_REDUCE_MIN -
ANEURALNETWORKS_REDUCE_PROD -
ANEURALNETWORKS_REDUCE_SUM -
ANEURALNETWORKS_RESIZE_NEAREST_NEIGHBOR -
ANEURALNETWORKS_ROI_ALIGN -
ANEURALNETWORKS_ROI_POOLING -
ANEURALNETWORKS_RSQRT -
ANEURALNETWORKS_SELECT -
ANEURALNETWORKS_SIN -
ANEURALNETWORKS_SLICE -
ANEURALNETWORKS_SPLIT -
ANEURALNETWORKS_SQRT -
ANEURALNETWORKS_TILE -
ANEURALNETWORKS_TOPK_V2 -
ANEURALNETWORKS_TRANSPOSE_CONV_2D -
ANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_LSTM -
ANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_RNN
Android 10 對許多現有操作進行了更新。更新主要與以下內容有關:
- 支持 NCHW 內存佈局
- 在 softmax 和歸一化操作中支持秩不同於 4 的張量
- 支持擴張卷積
- 支持
ANEURALNETWORKS_CONCATENATION中的混合量化輸入
下面的列表顯示了在 Android 10 中修改的操作。有關更改的完整詳細信息,請參閱 NNAPI 參考文檔中的OperationCode 。
-
ANEURALNETWORKS_ADD -
ANEURALNETWORKS_AVERAGE_POOL_2D -
ANEURALNETWORKS_BATCH_TO_SPACE_ND -
ANEURALNETWORKS_CONCATENATION -
ANEURALNETWORKS_CONV_2D -
ANEURALNETWORKS_DEPTHWISE_CONV_2D -
ANEURALNETWORKS_DEPTH_TO_SPACE -
ANEURALNETWORKS_DEQUANTIZE -
ANEURALNETWORKS_DIV -
ANEURALNETWORKS_FLOOR -
ANEURALNETWORKS_FULLY_CONNECTED -
ANEURALNETWORKS_L2_NORMALIZATION -
ANEURALNETWORKS_L2_POOL_2D -
ANEURALNETWORKS_LOCAL_RESPONSE_NORMALIZATION -
ANEURALNETWORKS_LOGISTIC -
ANEURALNETWORKS_LSH_PROJECTION -
ANEURALNETWORKS_LSTM -
ANEURALNETWORKS_MAX_POOL_2D -
ANEURALNETWORKS_MEAN -
ANEURALNETWORKS_MUL -
ANEURALNETWORKS_PAD -
ANEURALNETWORKS_RELU -
ANEURALNETWORKS_RELU1 -
ANEURALNETWORKS_RELU6 -
ANEURALNETWORKS_RESHAPE -
ANEURALNETWORKS_RESIZE_BILINEAR -
ANEURALNETWORKS_RNN -
ANEURALNETWORKS_ROI_ALIGN -
ANEURALNETWORKS_SOFTMAX -
ANEURALNETWORKS_SPACE_TO_BATCH_ND -
ANEURALNETWORKS_SPACE_TO_DEPTH -
ANEURALNETWORKS_SQUEEZE -
ANEURALNETWORKS_STRIDED_SLICE -
ANEURALNETWORKS_SUB -
ANEURALNETWORKS_SVDF -
ANEURALNETWORKS_TANH -
ANEURALNETWORKS_TRANSPOSE
安卓 9
NN HAL 1.1 在 Android 9 中引入,包括以下顯著變化。
-
IDevice::prepareModel_1_1包含一個ExecutionPreference參數。驅動程序可以使用它來調整其準備,知道應用程序更喜歡節省電池或將在快速連續調用中執行模型。 - 添加了九個新操作:
BATCH_TO_SPACE_ND、DIV、MEAN、PAD、SPACE_TO_BATCH_ND、SQUEEZE、STRIDED_SLICE、SUB、TRANSPOSE。 - 應用程序可以通過將
Model.relaxComputationFloat32toFloat16設置為true來指定可以使用 16 位浮點範圍和/或精度運行 32 位浮點計算。Capabilities結構具有額外的字段relaxedFloat32toFloat16Performance,以便驅動程序可以向框架報告其寬鬆的性能。
安卓8.1
最初的神經網絡 HAL (1.0) 在 Android 8.1 中發布。有關更多信息,請參閱/neuralnetworks/1.0/ 。