
Для поддержки масштабируемой, производительной и гибкой панели мониторинга непрерывной интеграции серверная часть панели мониторинга VTS должна быть тщательно разработана с учетом функциональности базы данных. Google Cloud Datastore — это база данных NoSQL, которая предлагает гарантии транзакций ACID и конечную согласованность, а также строгую согласованность внутри групп сущностей. Однако структура сильно отличается от баз данных SQL (и даже от Cloud Bigtable); вместо таблиц, строк и ячеек — виды, сущности и свойства.
В следующих разделах описывается структура данных и шаблоны запросов для создания эффективной серверной части веб-службы VTS Dashboard.
Сущности
Следующие сущности хранят сводки и ресурсы тестовых прогонов VTS:
- Тестовая сущность . Хранит метаданные о тестовых запусках определенного теста. Его ключом является имя теста, а его свойства включают количество сбоев, количество пройденных тестов и список поломок тестового набора, когда задания предупреждений обновляют его.
- Объект тестового запуска . Содержит метаданные из прогонов определенного теста. Он должен хранить временные метки начала и окончания теста, идентификатор сборки теста, количество пройденных и не пройденных тестовых случаев, тип запуска (например, до отправки, после отправки или локально), список ссылок на журнал, хост имя машины и количество сводок покрытия.
- Объект информации об устройстве . Содержит сведения об устройствах, используемых во время выполнения теста. Он включает в себя идентификатор сборки устройства, название продукта, цель сборки, ветку и информацию об ABI. Он хранится отдельно от объекта тестового запуска для поддержки тестовых прогонов на нескольких устройствах по принципу «один ко многим».
- Профилирование объекта Point Run . Обобщает данные, собранные для конкретной точки профилирования в ходе выполнения теста. Он описывает метки осей, имя точки профилирования, значения, тип и режим регрессии данных профилирования.
- Объект покрытия . Описывает данные покрытия, собранные для одного файла. Он содержит информацию о проекте Git, путь к файлу и список счетчиков покрытия на строку в исходном файле.
- Сущность запуска тестового примера . Описывает результат выполнения конкретного тестового набора, включая имя тестового набора и его результат.
- Сущность Избранного пользователя . Каждая пользовательская подписка может быть представлена в виде объекта, содержащего ссылку на тест и идентификатор пользователя, сгенерированный пользовательской службой App Engine. Это позволяет эффективно выполнять двунаправленные запросы (т. е. для всех пользователей, подписавшихся на тест, и для всех тестов, избранных пользователем).
Группировка объектов
Каждый тестовый модуль представляет собой корень группы сущностей. Объекты тестового запуска являются как дочерними элементами этой группы, так и родительскими для объектов устройств, объектов точек профилирования и объектов покрытия, относящихся к соответствующему предку теста и тестового запуска.
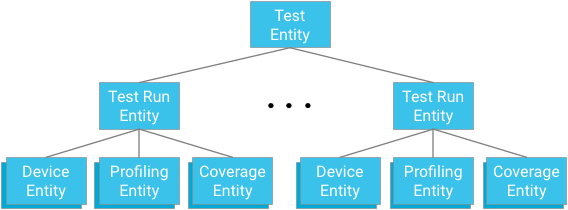
Ключевой момент: при разработке отношений предков вы должны сбалансировать необходимость предоставления эффективных и согласованных механизмов запросов с ограничениями, налагаемыми базой данных.
Преимущества
Требование непротиворечивости гарантирует, что будущие операции не будут видеть последствия транзакции до тех пор, пока она не будет зафиксирована, и что транзакции в прошлом будут видимы для текущих операций. В Cloud Datastore группировка сущностей создает островки строгой согласованности чтения и записи внутри группы, которая в данном случае представляет собой все тестовые прогоны и данные, относящиеся к тестовому модулю. Это дает следующие преимущества:
- Чтение и обновление состояния тестового модуля заданиями предупреждений можно рассматривать как атомарные.
- Гарантированное согласованное представление результатов тестовых случаев в тестовых модулях
- Более быстрые запросы в деревьях предков
Ограничения
Запись в группу объектов со скоростью, превышающей один объект в секунду, не рекомендуется, поскольку некоторые операции записи могут быть отклонены. Пока задания предупреждений и загрузка не происходят со скоростью, превышающей одну запись в секунду, структура является надежной и гарантирует надежную согласованность.
В конечном счете, ограничение в одну запись на тестовый модуль в секунду является разумным, поскольку выполнение тестов обычно занимает не менее одной минуты, включая накладные расходы на структуру VTS; если тест последовательно не выполняется одновременно на более чем 60 различных хостах, не может быть узкого места записи. Это становится еще более маловероятным, учитывая, что каждый модуль является частью плана тестирования, который часто занимает больше часа. С аномалиями можно легко справиться, если хосты запускают тесты в одно и то же время, вызывая короткие всплески операций записи на одни и те же хосты (например, перехватывая ошибки записи и повторяя попытку).
Соображения по масштабированию
Тестовый запуск не обязательно должен иметь тест в качестве родителя (например, он может взять какой-то другой ключ и иметь имя теста, время начала теста в качестве свойств); однако это заменит сильную согласованность на конечную согласованность. Например, задание оповещения может не видеть взаимно непротиворечивого снимка самых последних тестовых запусков в тестовом модуле, что означает, что глобальное состояние может не отражать полностью точное представление последовательности тестовых запусков. Это также может повлиять на отображение тестовых прогонов в одном тестовом модуле, который не обязательно может быть согласованным моментальным снимком последовательности прогонов. В конце концов снимок будет согласованным, но нет никаких гарантий, что самые свежие данные будут такими же.
Тестовые случаи
Еще одним потенциальным узким местом являются большие тесты с множеством тестовых случаев. Двумя рабочими ограничениями являются максимальная пропускная способность записи в пределах группы сущностей, равная одному в секунду, а также максимальный размер транзакции, равный 500 сущностям.
Один из подходов заключается в том, чтобы указать тестовый пример, который имеет тестовый запуск в качестве предка (аналогично тому, как хранятся данные о покрытии, данные профилирования и информация об устройстве):
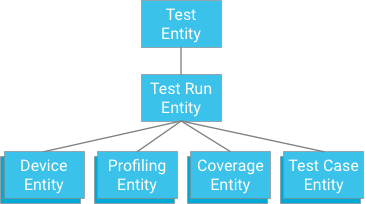
Хотя этот подход предлагает атомарность и согласованность, он накладывает серьезные ограничения на тесты: если транзакция ограничена 500 сущностями, то тест может иметь не более 498 тестовых случаев (при условии отсутствия данных о покрытии или профилировании). Если бы тест превышал это значение, то одна транзакция не могла бы записать все результаты тестового примера одновременно, а разделение тестовых случаев на отдельные транзакции могло бы превысить максимальную пропускную способность записи группы сущностей, составляющую одну итерацию в секунду. Поскольку это решение не будет хорошо масштабироваться без ущерба для производительности, оно не рекомендуется.
Однако вместо того, чтобы сохранять результаты тестовых наборов как дочерние элементы тестового прогона, тестовые наборы можно хранить независимо, а их ключи предоставлять тестовому прогону (тестовый прогон содержит список идентификаторов своих объектов тестовых наборов):
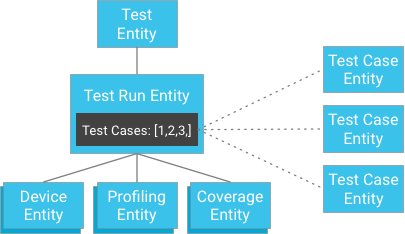
На первый взгляд может показаться, что это нарушает строгую гарантию согласованности. Однако если у клиента есть объект тестового запуска и список идентификаторов тестовых случаев, ему не нужно создавать запрос; вместо этого он может напрямую получать тестовые примеры по их идентификаторам, что всегда гарантирует согласованность. Этот подход значительно снижает ограничение на количество тестовых случаев, которые может иметь тестовый прогон, при этом обеспечивая строгую согласованность, не угрожая чрезмерным написанием внутри группы сущностей.
Шаблоны доступа к данным
VTS Dashboard использует следующие шаблоны доступа к данным:
- Избранное пользователя . Можно запросить с помощью фильтра равенства для сущностей избранного пользователя, имеющих конкретный объект пользователя App Engine в качестве свойства.
- Список тестов . Простой запрос тестовых сущностей. Чтобы уменьшить пропускную способность для отображения домашней страницы, можно использовать прогнозирование количества пройденных и неудачных тестов, чтобы исключить потенциально длинный список идентификаторов неудачных тестовых наборов и других метаданных, используемых заданиями оповещения.
- Тестовые прогоны . Для запроса объектов тестового запуска требуется сортировка по ключу (отметка времени) и возможная фильтрация свойств тестового запуска, таких как идентификатор сборки, количество прохождений и т. д. При выполнении запроса предка с ключом тестового объекта чтение строго согласовано. На этом этапе все результаты тестового примера можно получить, используя список идентификаторов, хранящихся в свойстве тестового запуска; это также гарантирует строго согласованный результат благодаря характеру операций получения хранилища данных.
- Данные профилирования и покрытия . Запрос данных профилирования или покрытия, связанных с тестом, можно выполнять без извлечения каких-либо других данных о выполнении теста (таких как другие данные профилирования/покрытия, данные тестового примера и т. д.). Запрос предка, использующий ключи сущности тестового теста и тестового прогона, извлечет все точки профилирования, записанные во время тестового прогона; путем также фильтрации по имени точки профилирования или имени файла можно получить один объект профилирования или покрытия. По характеру запросов предков эта операция строго непротиворечива.
Дополнительные сведения о пользовательском интерфейсе и скриншоты этих шаблонов данных в действии см. в разделе Пользовательский интерфейс VTS Dashboard .