
Android 8.0 включает тесты производительности связующего и hwbinder для определения пропускной способности и задержки. Хотя существует множество сценариев для обнаружения заметных проблем с производительностью, выполнение таких сценариев может занять много времени, а результаты часто недоступны до тех пор, пока система не будет интегрирована. Использование предоставленных тестов производительности упрощает тестирование во время разработки, позволяет раньше обнаруживать серьезные проблемы и улучшать взаимодействие с пользователем.
Тесты производительности включают следующие четыре категории:
- пропускная способность связующего (доступно в
system/libhwbinder/vts/performance/Benchmark_binder.cpp) - задержка связывателя (доступна в
frameworks/native/libs/binder/tests/schd-dbg.cpp) - пропускная способность hwbinder (доступна в
system/libhwbinder/vts/performance/Benchmark.cpp) - задержка hwbinder (доступна в
system/libhwbinder/vts/performance/Latency.cpp)
О связующем и hwbinder
Binder и hwbinder — это инфраструктуры межпроцессного взаимодействия (IPC) Android, которые используют один и тот же драйвер Linux, но имеют следующие качественные отличия:
| Аспект | связующее | хвбиндер |
|---|---|---|
| Цель | Обеспечить общую схему IPC для фреймворка | Связь с оборудованием |
| Имущество | Оптимизирован для использования в рамках Android. | Минимальные накладные расходы с низкой задержкой |
| Изменить политику планирования для переднего плана/фона | Да | Нет |
| Передача аргументов | Использует сериализацию, поддерживаемую объектом Parcel. | Использует буферы разброса и позволяет избежать накладных расходов на копирование данных, необходимых для сериализации Parcel. |
| Приоритетное наследование | Нет | Да |
Процессы связывания и hwbinder
Визуализатор systrace отображает транзакции следующим образом:
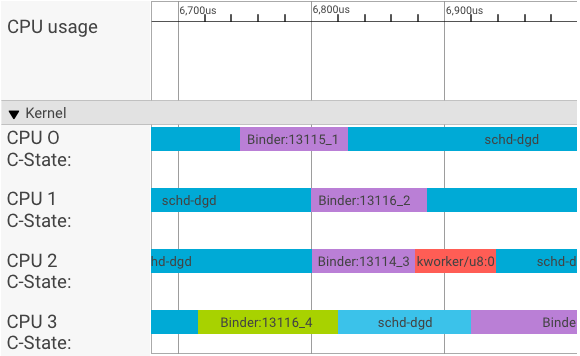
В приведенном выше примере:
- Четыре (4) процесса schd-dbg являются клиентскими процессами.
- Четыре (4) процесса связывателя являются серверными процессами (имя начинается с Binder и заканчивается порядковым номером).
- Клиентский процесс всегда связан с серверным процессом, который предназначен для его клиента.
- Все пары процессов клиент-сервер планируются ядром независимо одновременно.
В ЦП 1 ядро ОС выполняет клиента для выдачи запроса. Затем он использует тот же ЦП, когда это возможно, для пробуждения серверного процесса, обработки запроса и обратного переключения контекста после завершения запроса.
Пропускная способность и задержка
В идеальной транзакции, когда клиентский и серверный процессы переключаются беспрепятственно, тесты пропускной способности и задержки не создают существенно различающихся сообщений. Однако, когда ядро ОС обрабатывает запрос на прерывание (IRQ) от оборудования, ожидает блокировки или просто решает не обрабатывать сообщение немедленно, может образоваться пузырь задержки.
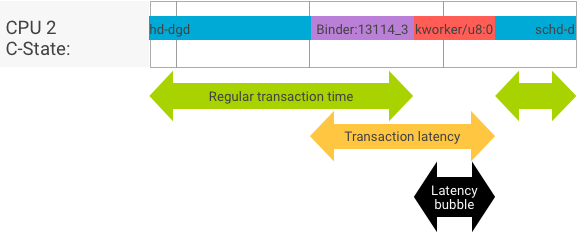
Тест пропускной способности генерирует большое количество транзакций с различными размерами полезной нагрузки, обеспечивая хорошую оценку обычного времени транзакции (в лучшем случае) и максимальную пропускную способность, которую может достичь связующее.
Напротив, тест задержки не выполняет никаких действий с полезной нагрузкой, чтобы свести к минимуму обычное время транзакции. Мы можем использовать время транзакции, чтобы оценить накладные расходы связывателя, сделать статистику для наихудшего случая и рассчитать долю транзакций, задержка которых соответствует заданному сроку.
Обработка инверсии приоритетов
Инверсия приоритета происходит, когда поток с более высоким приоритетом логически ожидает поток с более низким приоритетом. Приложения реального времени (RT) имеют проблему инверсии приоритетов:
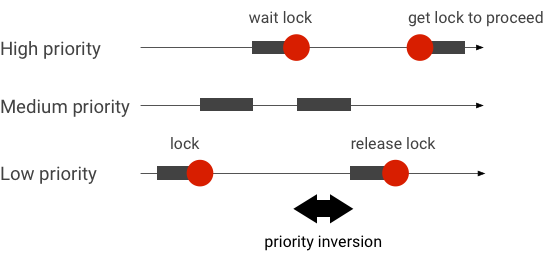
При использовании планирования Linux Completely Fair Scheduler (CFS) поток всегда имеет шанс запуститься, даже если другие потоки имеют более высокий приоритет. В результате приложения с планированием CFS обрабатывают инверсию приоритета как ожидаемое поведение, а не как проблему. Однако в тех случаях, когда платформе Android требуется планирование RT, чтобы гарантировать привилегию потоков с высоким приоритетом, необходимо разрешить инверсию приоритета.
Пример инверсии приоритета во время транзакции связывателя (поток RT логически блокируется другими потоками CFS при ожидании обслуживания потока связывателя):
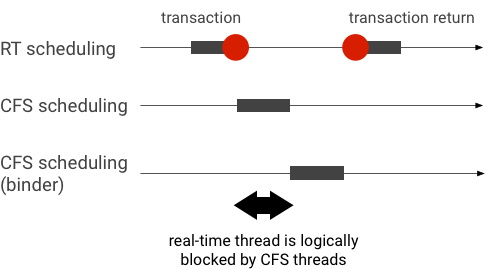
Чтобы избежать блокировок, вы можете использовать наследование приоритетов для временной эскалации потока Binder до потока RT, когда он обслуживает запрос от клиента RT. Имейте в виду, что планирование RT имеет ограниченные ресурсы и должно использоваться осторожно. В системе с n ЦП максимальное количество текущих потоков RT также равно n ; дополнительным потокам RT может потребоваться подождать (и, таким образом, пропустить свои крайние сроки), если все ЦП заняты другими потоками RT.
Чтобы разрешить все возможные инверсии приоритетов, вы можете использовать наследование приоритетов как для связывателя, так и для hwbinder. Однако, поскольку связыватель широко используется в системе, включение наследования приоритетов для транзакций связывателя может привести к спаму системы большим количеством потоков RT, чем она может обслужить.
Запуск тестов пропускной способности
Тест пропускной способности выполняется для пропускной способности транзакций связующего/hwbinder. В системе, которая не перегружена, пузыри задержки встречаются редко, и их влияние можно устранить, если количество итераций достаточно велико.
- Тест пропускной способности связующего находится в
system/libhwbinder/vts/performance/Benchmark_binder.cpp. - Тест пропускной способности hwbinder находится в
system/libhwbinder/vts/performance/Benchmark.cpp.
Результаты теста
Пример результатов теста пропускной способности для транзакций, использующих разные размеры полезной нагрузки:
Benchmark Time CPU Iterations --------------------------------------------------------------------- BM_sendVec_binderize/4 70302 ns 32820 ns 21054 BM_sendVec_binderize/8 69974 ns 32700 ns 21296 BM_sendVec_binderize/16 70079 ns 32750 ns 21365 BM_sendVec_binderize/32 69907 ns 32686 ns 21310 BM_sendVec_binderize/64 70338 ns 32810 ns 21398 BM_sendVec_binderize/128 70012 ns 32768 ns 21377 BM_sendVec_binderize/256 69836 ns 32740 ns 21329 BM_sendVec_binderize/512 69986 ns 32830 ns 21296 BM_sendVec_binderize/1024 69714 ns 32757 ns 21319 BM_sendVec_binderize/2k 75002 ns 34520 ns 20305 BM_sendVec_binderize/4k 81955 ns 39116 ns 17895 BM_sendVec_binderize/8k 95316 ns 45710 ns 15350 BM_sendVec_binderize/16k 112751 ns 54417 ns 12679 BM_sendVec_binderize/32k 146642 ns 71339 ns 9901 BM_sendVec_binderize/64k 214796 ns 104665 ns 6495
- Время указывает задержку прохождения туда и обратно, измеренную в реальном времени.
- ЦП указывает накопленное время, когда ЦП запланированы для теста.
- Итерации указывает, сколько раз выполнялась тестовая функция.
Например, для 8-байтовой полезной нагрузки:
BM_sendVec_binderize/8 69974 ns 32700 ns 21296
… максимальная пропускная способность, которую может достичь связующее, рассчитывается как:
МАКС. пропускная способность с 8-байтовой полезной нагрузкой = (8 * 21296)/69974 ~= 2,423 бит/нс ~= 2,268 Гбит/с
Варианты тестирования
Чтобы получить результаты в формате .json, запустите тест с аргументом --benchmark_format=json :
libhwbinder_benchmark --benchmark_format=json
{
"context": {
"date": "2017-05-17 08:32:47",
"num_cpus": 4,
"mhz_per_cpu": 19,
"cpu_scaling_enabled": true,
"library_build_type": "release"
},
"benchmarks": [
{
"name": "BM_sendVec_binderize/4",
"iterations": 32342,
"real_time": 47809,
"cpu_time": 21906,
"time_unit": "ns"
},
….
}
Запуск тестов задержки
Тест задержки измеряет время, которое требуется клиенту, чтобы начать инициализацию транзакции, переключиться на серверный процесс для обработки и получить результат. Тест также ищет известное плохое поведение планировщика, которое может негативно повлиять на задержку транзакций, например планировщик, который не поддерживает наследование приоритетов или не учитывает флаг синхронизации.
- Тест задержки связующего находится в
frameworks/native/libs/binder/tests/schd-dbg.cpp. - Тест задержки hwbinder находится в
system/libhwbinder/vts/performance/Latency.cpp.
Результаты теста
Результаты (в формате .json) показывают статистику по средней/лучшей/наихудшей задержке и количеству пропущенных сроков.
Варианты тестирования
Тесты задержки принимают следующие параметры:
| Команда | Описание |
|---|---|
-i value | Укажите количество итераций. |
-pair value | Укажите количество пар процессов. |
-deadline_us 2500 | Срок уточняйте у нас. |
-v | Получите подробный (отладочный) вывод. |
-trace | Остановите трассировку при наступлении крайнего срока. |
В следующих разделах подробно описывается каждый параметр, описывается его использование и приводятся примеры результатов.
Указание итераций
Пример с большим количеством итераций и отключенным подробным выводом:
libhwbinder_latency -i 5000 -pair 3
{
"cfg":{"pair":3,"iterations":5000,"deadline_us":2500},
"P0":{"SYNC":"GOOD","S":9352,"I":10000,"R":0.9352,
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}
},
"P1":{"SYNC":"GOOD","S":9334,"I":10000,"R":0.9334,
"other_ms":{ "avg":0.19, "wst":2.9 , "bst":0.055, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":3.1 , "bst":0.066, "miss":1, "meetR":0.9998}
},
"P2":{"SYNC":"GOOD","S":9369,"I":10000,"R":0.9369,
"other_ms":{ "avg":0.19, "wst":4.8 , "bst":0.055, "miss":6, "meetR":0.9988},
"fifo_ms": { "avg":0.15, "wst":1.8 , "bst":0.067, "miss":0, "meetR":1}
},
"inheritance": "PASS"
}
Эти результаты испытаний показывают следующее:
-
"pair":3 - Создает одну пару клиент-сервер.
-
"iterations": 5000 - Включает 5000 итераций.
-
"deadline_us":2500 - Дедлайн 2500 us (2,5 мс); ожидается, что большинство транзакций будет соответствовать этому значению.
-
"I": 10000 - Одна тестовая итерация включает две (2) транзакции:
- Одна транзакция по обычному приоритету (
CFS other) - Одна транзакция с приоритетом в реальном времени (
RT-fifo)
- Одна транзакция по обычному приоритету (
-
"S": 9352 - 9352 транзакции синхронизируются в одном процессоре.
-
"R": 0.9352 - Указывает соотношение, при котором клиент и сервер синхронизируются вместе в одном ЦП.
-
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996} - Средний (
avg), худший (wst) и лучший (bst) случай для всех транзакций, выданных вызывающей стороной с обычным приоритетом. Две транзакцииmissукладываются в срок, в результате чего коэффициент выполнения (meetR) равен 0,9996. -
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1} - Аналогично
other_ms, но для транзакций, выданных клиентом с приоритетомrt_fifo. Вполне вероятно (но не обязательно), чтоfifo_msимеет лучший результат, чемother_ms, с более низкими значениямиavgиwstи более высокимmeetR(разница может быть еще более значительной при нагрузке в фоновом режиме).
Примечание. Фоновая загрузка может повлиять на результат пропускной способности и кортеж other_ms в тесте задержки. Только fifo_ms может показать аналогичные результаты, если фоновая загрузка имеет более низкий приоритет, чем RT-fifo .
Указание парных значений
Каждый клиентский процесс связан с серверным процессом, выделенным для клиента, и каждая пара может быть запланирована независимо для любого процессора. Однако миграция ЦП не должна происходить во время транзакции, если установлен флаг honor .
Убедитесь, что система не перегружена! Несмотря на то, что в перегруженной системе ожидается высокая задержка, результаты тестирования для перегруженной системы не дают полезной информации. Чтобы протестировать систему с более высоким давлением, используйте -pair #cpu-1 (или -pair #cpu с осторожностью). Тестирование с использованием -pair n с n > #cpu перегружает систему и генерирует бесполезную информацию.
Указание значений крайних сроков
После обширного тестирования пользовательского сценария (выполнение теста задержки на соответствующем продукте) мы определили, что 2,5 мс — это крайний срок, который необходимо соблюдать. Для новых приложений с более высокими требованиями (например, 1000 фотографий в секунду) это значение срока будет изменено.
Указание подробного вывода
Использование параметра -v отображает подробный вывод. Пример:
libhwbinder_latency -i 1 -v-------------------------------------------------- service pid: 8674 tid: 8674 cpu: 1 SCHED_OTHER 0-------------------------------------------------- main pid: 8673 tid: 8673 cpu: 1 -------------------------------------------------- client pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0-------------------------------------------------- fifo-caller pid: 8677 tid: 8678 cpu: 0 SCHED_FIFO 99 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 ??? 99-------------------------------------------------- other-caller pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 SCHED_OTHER 0
- Поток службы создается с приоритетом
SCHED_OTHERи запускается вCPU:1сpid 8674. - Затем первая транзакция запускается
fifo-caller. Для обслуживания этой транзакции hwbinder повышает приоритет сервера (pid: 8674 tid: 8676) до 99, а также помечает его переходным классом планирования (печатается как???). Затем планировщик помещает серверный процесс вCPU:0для запуска и синхронизирует его с тем же ЦП со своим клиентом. - Второй вызывающий объект транзакции имеет приоритет
SCHED_OTHER. Сервер понижает свою версию и обслуживает вызывающую сторону с приоритетомSCHED_OTHER.
Использование трассировки для отладки
Вы можете указать параметр -trace для устранения проблем с задержкой. При использовании теста задержки запись журнала трассировки останавливается в тот момент, когда обнаруживается плохая задержка. Пример:
atrace --async_start -b 8000 -c sched idle workq binder_driver sync freqlibhwbinder_latency -deadline_us 50000 -trace -i 50000 -pair 3deadline triggered: halt ∓ stop trace log:/sys/kernel/debug/tracing/trace
Следующие компоненты могут повлиять на задержку:
- Режим сборки Android . Режим Eng обычно медленнее, чем режим userdebug.
- Рамки . Как служба фреймворка использует
ioctlдля настройки связывателя? - Биндер водитель . Поддерживает ли драйвер тонкую блокировку? Содержит ли он все патчи для повышения производительности?
- Версия ядра . Чем лучше возможности реального времени у ядра, тем лучше результаты.
- Конфигурация ядра . Содержит ли конфигурация ядра конфигурации
DEBUG, такие какDEBUG_PREEMPTиDEBUG_SPIN_LOCK? - Планировщик ядра . Есть ли в ядре планировщик Energy-Aware (EAS) или планировщик Heterogeneous Multi-Processing (HMP)? Влияют ли какие-либо драйверы ядра (драйвер
cpu-freq, драйверcpu-idle,cpu-hotplugи т. д.) на планировщик?