
Halaman ini memberikan ikhtisar tentang cara mengimplementasikan driver Neural Networks API (NNAPI). Untuk detail lebih lanjut, lihat dokumentasi yang ditemukan di file definisi HAL di hardware/interfaces/neuralnetworks . Contoh implementasi driver ada di frameworks/ml/nn/driver/sample .
Untuk informasi selengkapnya tentang Neural Networks API, lihat Neural Networks API .
Jaringan Neural HAL
Neural Networks (NN) HAL mendefinisikan abstraksi dari berbagai perangkat , seperti unit pemrosesan grafis (GPU) dan prosesor sinyal digital (DSP), yang ada dalam suatu produk (misalnya, ponsel atau tablet). Driver untuk perangkat ini harus sesuai dengan NN HAL. Antarmuka ditentukan dalam file definisi HAL di hardware/interfaces/neuralnetworks .
Aliran umum antarmuka antara kerangka kerja dan driver digambarkan pada gambar 1.
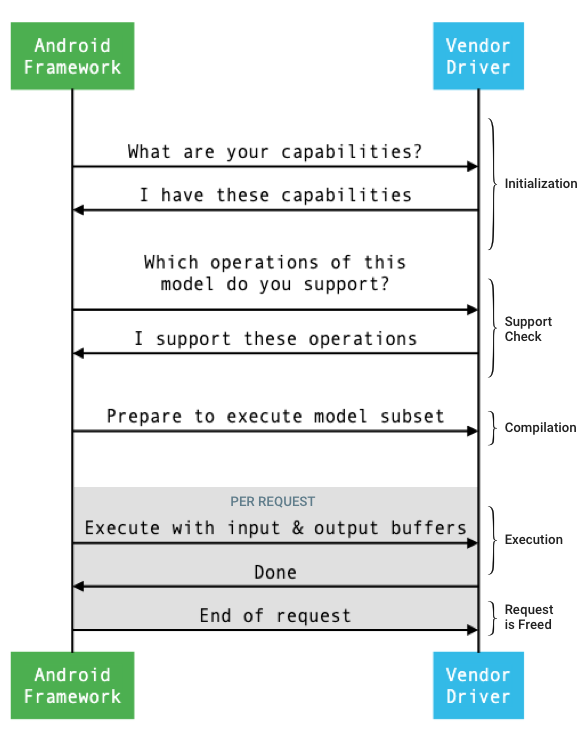
Gambar 1. Aliran Neural Network
inisialisasi
Pada inisialisasi, kerangka kerja menanyakan driver untuk kemampuannya menggunakan IDevice::getCapabilities_1_3 . Struktur @1.3::Capabilities mencakup semua tipe data dan mewakili kinerja yang tidak santai menggunakan vektor.
Untuk menentukan bagaimana mengalokasikan komputasi ke perangkat yang tersedia, framework menggunakan kemampuan untuk memahami seberapa cepat dan seberapa efisien energi setiap driver dapat melakukan eksekusi. Untuk memberikan informasi ini, pengemudi harus memberikan angka kinerja standar berdasarkan pelaksanaan beban kerja referensi.
Untuk menentukan nilai yang dikembalikan driver sebagai respons terhadap IDevice::getCapabilities_1_3 , gunakan aplikasi tolok ukur NNAPI untuk mengukur kinerja tipe data terkait. Model MobileNet v1 dan v2, asr_float , dan tts_float direkomendasikan untuk mengukur kinerja untuk nilai titik mengambang 32-bit dan model terkuantisasi MobileNet v1 dan v2 direkomendasikan untuk nilai terkuantisasi 8-bit. Untuk informasi selengkapnya, lihat Android Machine Learning Test Suite .
Di Android 9 dan yang lebih rendah, struktur Capabilities menyertakan informasi kinerja driver hanya untuk floating point dan tensor terkuantisasi dan tidak menyertakan tipe data skalar.
Sebagai bagian dari proses inisialisasi, kerangka kerja dapat meminta informasi lebih lanjut, menggunakan IDevice::getType , IDevice::getVersionString , IDevice:getSupportedExtensions , dan IDevice::getNumberOfCacheFilesNeeded .
Di antara reboot produk, framework mengharapkan semua kueri yang dijelaskan di bagian ini untuk selalu melaporkan nilai yang sama untuk driver tertentu. Jika tidak, aplikasi yang menggunakan driver tersebut mungkin menunjukkan penurunan kinerja atau perilaku yang salah.
Kompilasi
Framework menentukan perangkat mana yang akan digunakan saat menerima permintaan dari aplikasi. Di Android 10, aplikasi dapat menemukan dan menentukan perangkat yang dipilih kerangka kerja. Untuk informasi lebih lanjut, lihat Penemuan dan Penetapan Perangkat .
Pada waktu kompilasi model, framework mengirimkan model ke setiap kandidat driver dengan memanggil IDevice::getSupportedOperations_1_3 . Setiap driver mengembalikan array boolean yang menunjukkan operasi model mana yang didukung. Pengemudi dapat menentukan bahwa itu tidak dapat mendukung operasi tertentu karena sejumlah alasan. Sebagai contoh:
- Pengemudi tidak mendukung tipe data.
- Pengemudi hanya mendukung operasi dengan parameter input tertentu. Misalnya, driver mungkin mendukung operasi konvolusi 3x3 dan 5x5, tetapi tidak mendukung operasi konvolusi 7x7.
- Pengemudi memiliki batasan memori yang mencegahnya menangani grafik atau input besar.
Selama kompilasi, input, output, dan operan internal model, seperti yang dijelaskan dalam OperandLifeTime , dapat memiliki dimensi atau peringkat yang tidak diketahui. Untuk informasi selengkapnya, lihat Bentuk keluaran .
Framework menginstruksikan setiap driver yang dipilih untuk bersiap mengeksekusi subset model dengan memanggil IDevice::prepareModel_1_3 . Setiap driver kemudian mengkompilasi subsetnya. Misalnya, pengemudi mungkin membuat kode atau membuat salinan bobot yang disusun ulang. Karena mungkin ada banyak waktu antara kompilasi model dan eksekusi permintaan, sumber daya seperti potongan besar memori perangkat tidak boleh ditetapkan selama kompilasi.
Jika berhasil, driver mengembalikan pegangan @1.3::IPreparedModel . Jika driver mengembalikan kode kegagalan saat menyiapkan subset modelnya, kerangka kerja menjalankan seluruh model pada CPU.
Untuk mengurangi waktu yang digunakan untuk kompilasi saat aplikasi dimulai, driver dapat meng-cache artefak kompilasi. Untuk informasi selengkapnya, lihat Caching Kompilasi .
Eksekusi
Saat aplikasi meminta framework untuk mengeksekusi permintaan, framework memanggil metode HAL IPreparedModel::executeSynchronously_1_3 secara default untuk melakukan eksekusi sinkron pada model yang disiapkan. Permintaan juga dapat dieksekusi secara asinkron menggunakan metode execute_1_3 , metode executeFenced (lihat Feced execution ), atau dieksekusi menggunakan burst execution .
Panggilan eksekusi sinkron meningkatkan kinerja dan mengurangi overhead threading dibandingkan dengan panggilan asinkron karena kontrol dikembalikan ke proses aplikasi hanya setelah eksekusi selesai. Ini berarti bahwa driver tidak memerlukan mekanisme terpisah untuk memberi tahu proses aplikasi bahwa eksekusi telah selesai.
Dengan metode execute_1_3 asinkron, kontrol kembali ke proses aplikasi setelah eksekusi dimulai, dan driver harus memberi tahu framework saat eksekusi selesai, menggunakan @1.3::IExecutionCallback .
Parameter Request yang diteruskan ke metode eksekusi mencantumkan operand input dan output yang digunakan untuk eksekusi. Memori yang menyimpan data operan harus menggunakan urutan baris-utama dengan iterasi dimensi pertama paling lambat dan tidak memiliki padding di akhir baris mana pun. Untuk informasi lebih lanjut tentang jenis operan, lihat Operan .
Untuk driver NN HAL 1.2 atau lebih tinggi, saat permintaan diselesaikan, status kesalahan, bentuk keluaran , dan informasi waktu dikembalikan ke kerangka kerja. Selama eksekusi, output atau operan internal model dapat memiliki satu atau lebih dimensi yang tidak diketahui atau peringkat yang tidak diketahui. Ketika setidaknya satu operan keluaran memiliki dimensi atau peringkat yang tidak diketahui, driver harus mengembalikan informasi keluaran berukuran dinamis.
Untuk driver dengan NN HAL 1.1 atau lebih rendah, hanya status kesalahan yang dikembalikan saat permintaan diselesaikan. Dimensi untuk operan input dan output harus ditentukan sepenuhnya agar eksekusi berhasil diselesaikan. Operand internal dapat memiliki satu atau lebih dimensi yang tidak diketahui, tetapi mereka harus memiliki peringkat yang ditentukan.
Untuk permintaan pengguna yang menjangkau beberapa driver, kerangka kerja bertanggung jawab untuk menyimpan memori perantara dan untuk mengurutkan panggilan ke setiap driver.
Beberapa permintaan dapat dimulai secara paralel pada @1.3::IPreparedModel yang sama. Pengemudi dapat mengeksekusi permintaan secara paralel atau membuat serial eksekusi.
Kerangka kerja dapat meminta pengemudi untuk menyimpan lebih dari satu model yang disiapkan. Misalnya, siapkan model m1 , siapkan m2 , jalankan permintaan r1 pada m1 , jalankan r2 pada m2 , jalankan r3 pada m1 , jalankan r4 pada m2 , lepaskan (dijelaskan dalam Pembersihan ) m1 , dan lepaskan m2 .
Untuk menghindari eksekusi pertama yang lambat yang dapat mengakibatkan pengalaman pengguna yang buruk (misalnya, frame pertama stutter), driver harus melakukan sebagian besar inisialisasi dalam fase kompilasi. Inisialisasi pada eksekusi pertama harus dibatasi pada tindakan yang berdampak negatif pada kesehatan sistem saat dilakukan lebih awal, seperti memesan buffer sementara yang besar atau meningkatkan kecepatan jam perangkat. Driver yang hanya dapat menyiapkan sejumlah model bersamaan mungkin harus melakukan inisialisasi pada eksekusi pertama.
Di Android 10 atau lebih tinggi, dalam kasus di mana beberapa eksekusi dengan model yang disiapkan sama dieksekusi secara berurutan, klien dapat memilih untuk menggunakan objek burst eksekusi untuk berkomunikasi antara proses aplikasi dan driver. Untuk informasi selengkapnya, lihat Eksekusi Burst dan Antrean Pesan Cepat .
Untuk meningkatkan kinerja untuk beberapa eksekusi secara berurutan, driver dapat mempertahankan buffer sementara atau meningkatkan kecepatan clock. Membuat utas pengawas disarankan untuk melepaskan sumber daya jika tidak ada permintaan baru yang dibuat setelah jangka waktu tertentu.
Bentuk keluaran
Untuk permintaan di mana satu atau lebih operan keluaran tidak memiliki semua dimensi yang ditentukan, driver harus memberikan daftar bentuk keluaran yang berisi informasi dimensi untuk setiap operan keluaran setelah eksekusi. Untuk informasi lebih lanjut tentang dimensi, lihat OutputShape .
Jika eksekusi gagal karena buffer output berukuran terlalu kecil, driver harus menunjukkan operand output mana yang memiliki ukuran buffer yang tidak mencukupi dalam daftar bentuk output, dan harus melaporkan informasi dimensi sebanyak mungkin, menggunakan nol untuk dimensi yang tidak diketahui.
Waktu
Di Android 10, aplikasi dapat menanyakan waktu eksekusi jika aplikasi telah menetapkan satu perangkat untuk digunakan selama proses kompilasi. Untuk detailnya, lihat MeasureTiming dan Device Discovery and Assignment . Dalam hal ini, driver NN HAL 1.2 harus mengukur durasi eksekusi atau melaporkan UINT64_MAX (untuk menunjukkan bahwa durasi tidak tersedia) saat menjalankan permintaan. Pengemudi harus meminimalkan penalti kinerja yang dihasilkan dari pengukuran durasi eksekusi.
Pengemudi melaporkan durasi berikut dalam mikrodetik dalam struktur Pengaturan Timing :
- Waktu eksekusi di perangkat: Tidak termasuk waktu eksekusi di driver, yang berjalan pada prosesor host.
- Waktu eksekusi di driver: Termasuk waktu eksekusi pada perangkat.
Durasi ini harus mencakup waktu saat eksekusi ditangguhkan, misalnya, saat eksekusi telah didahului oleh tugas lain atau saat menunggu sumber daya tersedia.
Saat driver belum diminta untuk mengukur durasi eksekusi, atau saat ada kesalahan eksekusi, driver harus melaporkan durasi sebagai UINT64_MAX . Bahkan ketika driver telah diminta untuk mengukur durasi eksekusi, malahan dapat melaporkan UINT64_MAX untuk waktu di perangkat, waktu di driver, atau keduanya. Saat driver melaporkan kedua durasi sebagai nilai selain UINT64_MAX , waktu eksekusi di driver harus sama atau melebihi waktu di perangkat.
Eksekusi berpagar
Di Android 11, NNAPI memungkinkan eksekusi menunggu daftar pegangan sync_fence dan secara opsional mengembalikan objek sync_fence , yang ditandai saat eksekusi selesai. Ini mengurangi overhead untuk model urutan kecil dan kasus penggunaan streaming. Eksekusi berpagar juga memungkinkan interoperabilitas yang lebih efisien dengan komponen lain yang dapat memberi sinyal atau menunggu sync_fence . Untuk informasi lebih lanjut tentang sync_fence , lihat Kerangka Sinkronisasi .
Dalam eksekusi berpagar, kerangka kerja memanggil metode IPreparedModel::executeFenced untuk meluncurkan eksekusi berpagar, asinkron pada model yang disiapkan dengan vektor pagar sinkronisasi untuk menunggu. Jika tugas asinkron selesai sebelum panggilan kembali, pegangan kosong dapat dikembalikan untuk sync_fence . Objek IFencedExecutionCallback juga harus dikembalikan untuk memungkinkan kerangka kerja menanyakan status kesalahan dan informasi durasi.
Setelah eksekusi selesai, dua nilai waktu berikut yang mengukur durasi eksekusi dapat ditanyakan melalui IFencedExecutionCallback::getExecutionInfo .
-
timingLaunched: Durasi dari saatexecuteFenceddipanggil hingga saatexecuteFencedmemberi sinyal padasyncFenceyang dikembalikan . -
timingFenced: Durasi dari saat semua pagar sinkronisasi yang menunggu eksekusi ditandai hingga saat executionFenced memberi sinyalexecuteFencedyangsyncFence.
Kontrol aliran
Untuk perangkat yang menjalankan Android 11 atau lebih tinggi, NNAPI menyertakan dua operasi aliran kontrol, IF dan WHILE , yang menggunakan model lain sebagai argumen dan menjalankannya secara kondisional ( IF ) atau berulang kali ( WHILE ). Untuk informasi selengkapnya tentang cara menerapkan ini, lihat Aliran kontrol .
Kualitas pelayanan
Di Android 11, NNAPI menyertakan peningkatan kualitas layanan (QoS) dengan memungkinkan aplikasi menunjukkan prioritas relatif modelnya, jumlah waktu maksimum yang diharapkan untuk model yang akan disiapkan, dan jumlah waktu maksimum yang diharapkan untuk eksekusi. untuk diselesaikan. Untuk informasi lebih lanjut, lihat Kualitas Layanan .
Membersihkan
Saat aplikasi selesai menggunakan model yang disiapkan, kerangka kerja melepaskan referensinya ke objek @1.3::IPreparedModel . Saat objek IPreparedModel tidak lagi direferensikan, objek tersebut secara otomatis dimusnahkan di layanan driver yang membuatnya. Sumber daya model-spesifik dapat direklamasi saat ini dalam implementasi driver destructor. Jika layanan driver ingin objek IPreparedModel dihancurkan secara otomatis saat tidak lagi dibutuhkan oleh klien, layanan tersebut tidak boleh menyimpan referensi apa pun ke objek IPreparedModel setelah objek IPreparedeModel dikembalikan melalui IPreparedModelCallback::notify_1_3 .
penggunaan CPU
Pengemudi diharapkan menggunakan CPU untuk mengatur perhitungan. Pengemudi tidak boleh menggunakan CPU untuk melakukan perhitungan grafik karena hal itu mengganggu kemampuan kerangka kerja untuk mengalokasikan pekerjaan dengan benar. Pengemudi harus melaporkan bagian-bagian yang tidak dapat ditanganinya ke kerangka kerja dan membiarkan kerangka kerja menangani sisanya.
Kerangka kerja ini menyediakan implementasi CPU untuk semua operasi NNAPI kecuali untuk operasi yang ditentukan vendor. Untuk informasi selengkapnya, lihat Ekstensi Vendor .
Operasi yang diperkenalkan di Android 10 (API level 29) hanya memiliki implementasi CPU referensi untuk memverifikasi bahwa pengujian CTS dan VTS sudah benar. Implementasi yang dioptimalkan yang disertakan dalam kerangka kerja pembelajaran mesin seluler lebih disukai daripada implementasi CPU NNAPI.
Fungsi utilitas
Basis kode NNAPI mencakup fungsi utilitas yang dapat digunakan oleh layanan driver.
File frameworks/ml/nn/common/include/Utils.h berisi berbagai macam fungsi utilitas, seperti yang digunakan untuk logging dan untuk mengonversi antara versi NN HAL yang berbeda.
VLogging:
VLOGadalah makro pembungkus di sekitarLOGAndroid yang hanya mencatat pesan jika tag yang sesuai diatur di propertidebug.nn.vlog.initVLogMask()harus dipanggil sebelum panggilan apa pun keVLOG. MakroVLOG_IS_ONdapat digunakan untuk memeriksa apakahVLOGsaat ini diaktifkan, memungkinkan kode logging yang rumit untuk dilewati jika tidak diperlukan. Nilai properti harus salah satu dari berikut ini:- String kosong, yang menunjukkan bahwa tidak ada pencatatan yang harus dilakukan.
- Token
1atauall, menunjukkan bahwa semua pencatatan harus dilakukan. - Daftar tag, dibatasi oleh spasi, koma, atau titik dua, yang menunjukkan logging mana yang harus dilakukan. Tag tersebut adalah
compilation,cpuexe,driver,execution,manager, danmodel.
compliantWithV1_*: Mengembalikan nilaitruejika objek NN HAL dapat dikonversi ke tipe yang sama dari versi HAL yang berbeda tanpa kehilangan informasi. Misalnya, memanggilcompliantWithV1_0padaV1_2::Modelmengembalikanfalsejika model menyertakan jenis operasi yang diperkenalkan di NN HAL 1.1 atau NN HAL 1.2.convertToV1_*: Mengonversi objek NN HAL dari satu versi ke versi lainnya. Peringatan dicatat jika konversi mengakibatkan hilangnya informasi (yaitu, jika versi baru dari jenis tidak dapat sepenuhnya mewakili nilai).Kemampuan: Fungsi
nonExtensionOperandPerformancedanupdatedapat digunakan untuk membantu membangun bidangCapabilities::operandPerformance.Menanyakan properti jenis:
isExtensionOperandType,isExtensionOperationType,nonExtensionSizeOfData,nonExtensionOperandSizeOfData,nonExtensionOperandTypeIsScalar,tensorHasUnspecifiedDimensions.
File frameworks/ml/nn/common/include/ValidateHal.h berisi fungsi utilitas untuk memvalidasi bahwa objek NN HAL valid sesuai dengan spesifikasi versi HAL-nya.
-
validate*: Mengembalikan nilaitruejika objek NN HAL valid menurut spesifikasi versi HAL-nya. Jenis OEM dan jenis ekstensi tidak divalidasi. Misalnya,validateModelmengembalikanfalsejika model berisi operasi yang mereferensikan indeks operan yang tidak ada, atau operasi yang tidak didukung pada versi HAL tersebut.
File frameworks/ml/nn/common/include/Tracing.h berisi makro untuk menyederhanakan penambahan informasi systracing ke kode Neural Networks. Sebagai contoh, lihat pemanggilan makro NNTRACE_* di driver sampel .
File frameworks/ml/nn/common/include/GraphDump.h berisi fungsi utilitas untuk membuang konten Model dalam bentuk grafis untuk keperluan debugging.
-
graphDump: Menulis representasi model dalam format Graphviz (.dot) ke aliran yang ditentukan (jika disediakan) atau ke logcat (jika tidak ada aliran yang disediakan).
Validasi
Untuk menguji implementasi NNAPI Anda, gunakan pengujian VTS dan CTS yang disertakan dalam kerangka kerja Android. VTS melatih driver Anda secara langsung (tanpa menggunakan kerangka kerja), sedangkan CTS melatihnya secara tidak langsung melalui kerangka kerja. Ini menguji setiap metode API dan memverifikasi bahwa semua operasi yang didukung oleh driver bekerja dengan benar dan memberikan hasil yang memenuhi persyaratan presisi.
Persyaratan presisi dalam CTS dan VTS untuk NNAPI adalah sebagai berikut:
Titik-mengambang: abs(diharapkan - aktual) <= atol + rtol * abs(diharapkan); di mana:
- Untuk fp32, atol = 1e-5f, rtol = 5.0f * 1.1920928955078125e-7
- Untuk fp16, atol = rtol = 5.0f * 0,0009765625f
Terkuantisasi: off-by-one (kecuali untuk
mobilenet_quantized, yang off-by-three)Boolean: sama persis
Salah satu cara CTS menguji NNAPI adalah dengan membuat grafik pseudorandom tetap yang digunakan untuk menguji dan membandingkan hasil eksekusi dari setiap driver dengan implementasi referensi NNAPI. Untuk driver dengan NN HAL 1.2 atau lebih tinggi, jika hasilnya tidak memenuhi kriteria presisi, CTS melaporkan kesalahan dan membuang file spesifikasi untuk model yang gagal di bawah /data/local/tmp untuk debugging. Untuk detail selengkapnya tentang kriteria presisi, lihat TestRandomGraph.cpp dan TestHarness.h .
Pengujian fuzzy
Tujuan pengujian fuzz adalah untuk menemukan kerusakan, pernyataan, pelanggaran memori, atau perilaku umum yang tidak ditentukan dalam kode yang sedang diuji karena faktor-faktor seperti input yang tidak terduga. Untuk pengujian fuzz NNAPI, Android menggunakan pengujian berdasarkan libFuzzer , yang efisien dalam fuzzing karena menggunakan cakupan baris dari kasus pengujian sebelumnya untuk menghasilkan input acak baru. Misalnya, libFuzzer menyukai kasus uji yang berjalan pada baris kode baru. Ini sangat mengurangi jumlah waktu yang dibutuhkan tes untuk menemukan kode yang bermasalah.
Untuk melakukan pengujian fuzz guna memvalidasi implementasi driver Anda, ubah frameworks/ml/nn/runtime/test/android_fuzzing/DriverFuzzTest.cpp di utilitas pengujian libneuralnetworks_driver_fuzzer yang terdapat di AOSP untuk menyertakan kode driver Anda. Untuk informasi selengkapnya tentang pengujian fuzz NNAPI, lihat frameworks/ml/nn/runtime/test/android_fuzzing/README.md .
Keamanan
Karena proses aplikasi berkomunikasi langsung dengan proses driver, driver harus memvalidasi argumen panggilan yang mereka terima. Validasi ini diverifikasi oleh VTS. Kode validasi ada di frameworks/ml/nn/common/include/ValidateHal.h .
Pengemudi juga harus memastikan bahwa aplikasi tidak dapat mengganggu aplikasi lain saat menggunakan perangkat yang sama.
Rangkaian Tes Pembelajaran Mesin Android
Android Machine Learning Test Suite (MLTS) adalah tolok ukur NNAPI yang disertakan dalam CTS dan VTS untuk memvalidasi keakuratan model nyata pada perangkat vendor. Benchmark mengevaluasi latensi dan akurasi, dan membandingkan hasil driver dengan hasil menggunakan TF Lite yang berjalan di CPU, untuk model dan set data yang sama. Ini memastikan bahwa akurasi driver tidak lebih buruk daripada implementasi referensi CPU.
Pengembang platform Android juga menggunakan MLTS untuk mengevaluasi latensi dan akurasi driver.
Benchmark NNAPI dapat ditemukan di dua proyek di AOSP:
-
platform/test/mlts/benchmark(aplikasi benchmark) -
platform/test/mlts/models(model dan kumpulan data)
Model dan kumpulan data
Tolok ukur NNAPI menggunakan model dan set data berikut.
- MobileNetV1 float dan u8 dikuantisasi dalam ukuran yang berbeda, dijalankan terhadap subset kecil (1500 gambar) dari Open Images Dataset v4.
- MobileNetV2 float dan u8 dikuantisasi dalam berbagai ukuran, dijalankan melawan subset kecil (1500 gambar) Open Images Dataset v4.
- Model akustik berbasis long short-term memory (LSTM) untuk text-to-speech, dijalankan melawan subset kecil dari set CMU Arctic.
- Model akustik berbasis LSTM untuk pengenalan suara otomatis, dijalankan terhadap sebagian kecil dari kumpulan data LibriSpeech.
Untuk informasi lebih lanjut, lihat platform/test/mlts/models .
Tes stres
Android Machine Learning Test Suite mencakup serangkaian tes crash untuk memvalidasi ketahanan driver dalam kondisi penggunaan yang berat atau dalam kasus perilaku klien yang sulit.
Semua tes kecelakaan menyediakan fitur berikut:
- Deteksi hang: Jika klien NNAPI hang selama pengujian, pengujian gagal dengan alasan kegagalan
HANGdan rangkaian pengujian pindah ke pengujian berikutnya. - Deteksi kerusakan klien NNAPI: Pengujian bertahan dari kerusakan klien dan pengujian gagal dengan alasan kegagalan
CRASH. - Deteksi kerusakan driver: Pengujian dapat mendeteksi kerusakan driver yang menyebabkan kegagalan pada panggilan NNAPI. Perhatikan bahwa mungkin ada crash dalam proses driver yang tidak menyebabkan kegagalan NNAPI dan tidak menyebabkan pengujian gagal. Untuk menutupi jenis kegagalan ini, disarankan untuk menjalankan perintah
tailpada log sistem untuk kesalahan atau crash terkait driver. - Penargetan semua akselerator yang tersedia: Pengujian dijalankan terhadap semua driver yang tersedia.
Semua tes tabrakan memiliki empat kemungkinan hasil berikut:
-
SUCCESS: Eksekusi selesai tanpa kesalahan. -
FAILURE: Eksekusi gagal. Biasanya disebabkan oleh kegagalan saat menguji model, yang menunjukkan bahwa driver gagal mengkompilasi atau mengeksekusi model. -
HANG: Proses pengujian menjadi tidak responsif. -
CRASH: Proses pengujian macet.
Untuk informasi lebih lanjut tentang stress testing dan daftar lengkap crash test, lihat platform/test/mlts/benchmark/README.txt .
Menggunakan MLTS
Untuk menggunakan MLTS:
- Hubungkan perangkat target ke workstation Anda dan pastikan perangkat tersebut dapat dijangkau melalui adb . Ekspor variabel lingkungan
ANDROID_SERIALperangkat target jika lebih dari satu perangkat terhubung. cdke direktori sumber tingkat atas Android.source build/envsetup.sh lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available. ./test/mlts/benchmark/build_and_run_benchmark.shDi akhir menjalankan benchmark, hasilnya disajikan sebagai halaman HTML dan diteruskan ke
xdg-open.
Untuk informasi lebih lanjut, lihat platform/test/mlts/benchmark/README.txt .
Neural Networks versi HAL
Bagian ini menjelaskan perubahan yang diperkenalkan pada versi HAL Android dan Neural Networks.
Android 11
Android 11 memperkenalkan NN HAL 1.3, yang mencakup perubahan penting berikut.
- Dukungan untuk kuantisasi 8-bit yang ditandatangani di NNAPI. Menambahkan jenis operan
TENSOR_QUANT8_ASYMM_SIGNED. Driver dengan NN HAL 1.3 yang mendukung operasi dengan kuantisasi tidak bertanda juga harus mendukung varian bertanda dari operasi tersebut. Saat menjalankan versi yang ditandatangani dan tidak ditandatangani dari sebagian besar operasi terkuantisasi, driver harus menghasilkan hasil yang sama hingga offset 128. Ada lima pengecualian untuk persyaratan ini:CAST,HASHTABLE_LOOKUP,LSH_PROJECTION,PAD_V2, danQUANTIZED_16BIT_LSTM. OperasiQUANTIZED_16BIT_LSTMtidak mendukung operan yang ditandatangani dan empat operasi lainnya mendukung kuantisasi yang ditandatangani tetapi tidak memerlukan hasil yang sama. - Dukungan untuk eksekusi berpagar di mana kerangka kerja memanggil metode
IPreparedModel::executeFenceduntuk meluncurkan eksekusi berpagar, asinkron pada model yang disiapkan dengan vektor pagar sinkronisasi untuk menunggu. Untuk informasi selengkapnya, lihat Eksekusi berpagar . - Dukungan untuk aliran kontrol. Menambahkan operasi
IFdanWHILE, yang mengambil model lain sebagai argumen dan mengeksekusinya secara kondisional (IF) atau berulang kali (WHILE). Untuk informasi selengkapnya, lihat Aliran kontrol . - Peningkatan kualitas layanan (QoS) karena aplikasi dapat menunjukkan prioritas relatif dari modelnya, jumlah waktu maksimum yang diharapkan untuk menyiapkan model, dan jumlah waktu maksimum yang diharapkan untuk penyelesaian eksekusi. Untuk informasi lebih lanjut, lihat Kualitas Layanan .
- Dukungan untuk domain memori yang menyediakan antarmuka pengalokasi untuk buffer yang dikelola driver. Hal ini memungkinkan untuk melewatkan memori asli perangkat di seluruh eksekusi, menekan penyalinan data yang tidak perlu dan transformasi antara eksekusi berurutan pada driver yang sama. Untuk informasi selengkapnya, lihat Domain memori .
Android 10
Android 10 memperkenalkan NN HAL 1.2, yang mencakup perubahan penting berikut.
- Struktur
Capabilitiesmencakup semua tipe data termasuk tipe data skalar, dan merepresentasikan kinerja yang tidak direlaksasi menggunakan vektor daripada bidang bernama. - Metode
getVersionStringdangetTypememungkinkan kerangka kerja untuk mengambil jenis perangkat (DeviceType) dan informasi versi. Lihat Penemuan dan Penetapan Perangkat . - Metode
executeSynchronouslydipanggil secara default untuk melakukan eksekusi secara sinkron. Metodeexecute_1_2memberi tahu kerangka kerja untuk melakukan eksekusi secara asinkron. Lihat Eksekusi . - Parameter
MeasureTimingtoexecuteSynchronously,execute_1_2, dan burst execution menentukan apakah driver akan mengukur durasi eksekusi. Hasilnya dilaporkan dalam strukturTiming. Lihat Waktu . - Dukungan untuk eksekusi di mana satu atau lebih operan keluaran memiliki dimensi atau peringkat yang tidak diketahui. Lihat Bentuk keluaran .
- Dukungan untuk ekstensi vendor, yang merupakan kumpulan operasi dan tipe data yang ditentukan vendor. Driver melaporkan ekstensi yang didukung melalui metode
IDevice::getSupportedExtensions. Lihat Ekstensi Vendor . - Kemampuan objek burst untuk mengontrol serangkaian eksekusi burst menggunakan antrean pesan cepat (FMQ) untuk berkomunikasi antara proses aplikasi dan driver, sehingga mengurangi latensi. Lihat Eksekusi Burst dan Antrian Pesan Cepat .
- Dukungan untuk AHardwareBuffer untuk memungkinkan driver melakukan eksekusi tanpa menyalin data. Lihat AHardwareBuffer .
- Peningkatan dukungan untuk caching artefak kompilasi untuk mengurangi waktu yang digunakan untuk kompilasi saat aplikasi dimulai. Lihat Caching Kompilasi .
Android 10 memperkenalkan jenis dan operasi operan berikut.
-
ANEURALNETWORKS_BOOL -
ANEURALNETWORKS_FLOAT16 -
ANEURALNETWORKS_TENSOR_BOOL8 -
ANEURALNETWORKS_TENSOR_FLOAT16 -
ANEURALNETWORKS_TENSOR_QUANT16_ASYMM -
ANEURALNETWORKS_TENSOR_QUANT16_SYMM -
ANEURALNETWORKS_TENSOR_QUANT8_SYMM -
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL
-
-
ANEURALNETWORKS_ABS -
ANEURALNETWORKS_ARGMAX -
ANEURALNETWORKS_ARGMIN -
ANEURALNETWORKS_AXIS_ALIGNED_BBOX_TRANSFORM -
ANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_LSTM -
ANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_RNN -
ANEURALNETWORKS_BOX_WITH_NMS_LIMIT -
ANEURALNETWORKS_CAST -
ANEURALNETWORKS_CHANNEL_SHUFFLE -
ANEURALNETWORKS_DETECTION_POSTPROCESSING -
ANEURALNETWORKS_EQUAL -
ANEURALNETWORKS_EXP -
ANEURALNETWORKS_EXPAND_DIMS -
ANEURALNETWORKS_GATHER -
ANEURALNETWORKS_GENERATE_PROPOSALS -
ANEURALNETWORKS_GREATER -
ANEURALNETWORKS_GREATER_EQUAL -
ANEURALNETWORKS_GROUPED_CONV_2D -
ANEURALNETWORKS_HEATMAP_MAX_KEYPOINT -
ANEURALNETWORKS_INSTANCE_NORMALIZATION -
ANEURALNETWORKS_LESS -
ANEURALNETWORKS_LESS_EQUAL -
ANEURALNETWORKS_LOG -
ANEURALNETWORKS_LOGICAL_AND -
ANEURALNETWORKS_LOGICAL_NOT -
ANEURALNETWORKS_LOGICAL_OR -
ANEURALNETWORKS_LOG_SOFTMAX -
ANEURALNETWORKS_MAXIMUM -
ANEURALNETWORKS_MINIMUM -
ANEURALNETWORKS_NEG -
ANEURALNETWORKS_NOT_EQUAL -
ANEURALNETWORKS_PAD_V2 -
ANEURALNETWORKS_POW -
ANEURALNETWORKS_PRELU -
ANEURALNETWORKS_QUANTIZE -
ANEURALNETWORKS_QUANTIZED_16BIT_LSTM -
ANEURALNETWORKS_RANDOM_MULTINOMIAL -
ANEURALNETWORKS_REDUCE_ALL -
ANEURALNETWORKS_REDUCE_ANY -
ANEURALNETWORKS_REDUCE_MAX -
ANEURALNETWORKS_REDUCE_MIN -
ANEURALNETWORKS_REDUCE_PROD -
ANEURALNETWORKS_REDUCE_SUM -
ANEURALNETWORKS_RESIZE_NEAREST_NEIGHBOR -
ANEURALNETWORKS_ROI_ALIGN -
ANEURALNETWORKS_ROI_POOLING -
ANEURALNETWORKS_RSQRT -
ANEURALNETWORKS_SELECT -
ANEURALNETWORKS_SIN -
ANEURALNETWORKS_SLICE -
ANEURALNETWORKS_SPLIT -
ANEURALNETWORKS_SQRT -
ANEURALNETWORKS_TILE -
ANEURALNETWORKS_TOPK_V2 -
ANEURALNETWORKS_TRANSPOSE_CONV_2D -
ANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_LSTM -
ANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_RNN
-
Android 10 memperkenalkan pembaruan ke banyak operasi yang ada. Pembaruan terutama terkait dengan hal-hal berikut:
- Dukungan untuk tata letak memori NCHW
- Dukungan untuk tensor dengan peringkat berbeda dari 4 dalam operasi softmax dan normalisasi
- Dukungan untuk konvolusi yang melebar
- Dukungan untuk input dengan kuantisasi campuran di
ANEURALNETWORKS_CONCATENATION
Daftar di bawah ini menunjukkan operasi yang dimodifikasi di Android 10. Untuk detail lengkap tentang perubahan tersebut, lihat OperationCode dalam dokumentasi referensi NNAPI.
-
ANEURALNETWORKS_ADD -
ANEURALNETWORKS_AVERAGE_POOL_2D -
ANEURALNETWORKS_BATCH_TO_SPACE_ND -
ANEURALNETWORKS_CONCATENATION -
ANEURALNETWORKS_CONV_2D -
ANEURALNETWORKS_DEPTHWISE_CONV_2D -
ANEURALNETWORKS_DEPTH_TO_SPACE -
ANEURALNETWORKS_DEQUANTIZE -
ANEURALNETWORKS_DIV -
ANEURALNETWORKS_FLOOR -
ANEURALNETWORKS_FULLY_CONNECTED -
ANEURALNETWORKS_L2_NORMALIZATION -
ANEURALNETWORKS_L2_POOL_2D -
ANEURALNETWORKS_LOCAL_RESPONSE_NORMALIZATION -
ANEURALNETWORKS_LOGISTIC -
ANEURALNETWORKS_LSH_PROJECTION -
ANEURALNETWORKS_LSTM -
ANEURALNETWORKS_MAX_POOL_2D -
ANEURALNETWORKS_MEAN -
ANEURALNETWORKS_MUL -
ANEURALNETWORKS_PAD -
ANEURALNETWORKS_RELU -
ANEURALNETWORKS_RELU1 -
ANEURALNETWORKS_RELU6 -
ANEURALNETWORKS_RESHAPE -
ANEURALNETWORKS_RESIZE_BILINEAR -
ANEURALNETWORKS_RNN -
ANEURALNETWORKS_ROI_ALIGN -
ANEURALNETWORKS_SOFTMAX -
ANEURALNETWORKS_SPACE_TO_BATCH_ND -
ANEURALNETWORKS_SPACE_TO_DEPTH -
ANEURALNETWORKS_SQUEEZE -
ANEURALNETWORKS_STRIDED_SLICE -
ANEURALNETWORKS_SUB -
ANEURALNETWORKS_SVDF -
ANEURALNETWORKS_TANH -
ANEURALNETWORKS_TRANSPOSE
Android 9
NN HAL 1.1 diperkenalkan di Android 9 dan menyertakan perubahan penting berikut.
-
IDevice::prepareModel_1_1menyertakan parameterExecutionPreference. Pengemudi dapat menggunakan ini untuk menyesuaikan persiapannya, mengetahui bahwa aplikasi lebih suka menghemat baterai atau akan menjalankan model dalam panggilan cepat yang berurutan. - Sembilan operasi baru telah ditambahkan:
BATCH_TO_SPACE_ND,DIV,MEAN,PAD,SPACE_TO_BATCH_ND,SQUEEZE,STRIDED_SLICE,SUB,TRANSPOSE. - Aplikasi dapat menentukan bahwa komputasi float 32-bit dapat dijalankan menggunakan rentang dan/atau presisi float 16-bit dengan menyetel
Model.relaxComputationFloat32toFloat16ketrue. StructCapabilitiesmemiliki field tambahanrelaxedFloat32toFloat16Performancesehingga pengemudi dapat melaporkan kinerja santainya ke framework.
Android 8.1
Neural Networks HAL (1.0) awal dirilis di Android 8.1. Untuk informasi lebih lanjut, lihat /neuralnetworks/1.0/ .