
Android 8.0 包括針對吞吐量和延遲的 binder 和 hwbinder 性能測試。雖然存在許多用於檢測可察覺的性能問題的場景,但運行此類場景可能非常耗時,並且在集成系統之前通常無法獲得結果。使用提供的性能測試可以更輕鬆地在開發過程中進行測試,更早地發現嚴重問題並改善用戶體驗。
性能測試包括以下四類:
- binder 吞吐量(在
system/libhwbinder/vts/performance/Benchmark_binder.cpp中可用) - binder 延遲(在
frameworks/native/libs/binder/tests/schd-dbg.cpp) - hwbinder 吞吐量(在
system/libhwbinder/vts/performance/Benchmark.cpp中可用) - hwbinder 延遲(在
system/libhwbinder/vts/performance/Latency.cpp中可用)
關於 binder 和 hwbinder
Binder 和 hwbinder 是 Android 進程間通信 (IPC) 基礎設施,它們共享相同的 Linux 驅動程序,但有以下質的區別:
| 方面 | 粘合劑 | hwbinder |
|---|---|---|
| 目的 | 為框架提供通用IPC方案 | 與硬件通信 |
| 財產 | 針對 Android 框架使用進行了優化 | 最小開銷低延遲 |
| 更改前台/後台調度策略 | 是的 | 不 |
| 參數傳遞 | 使用 Parcel 對象支持的序列化 | 使用分散緩衝區並避免複製 Parcel 序列化所需的數據的開銷 |
| 優先繼承 | 不 | 是的 |
Binder 和 hwbinder 進程
systrace 可視化器按如下方式顯示事務:
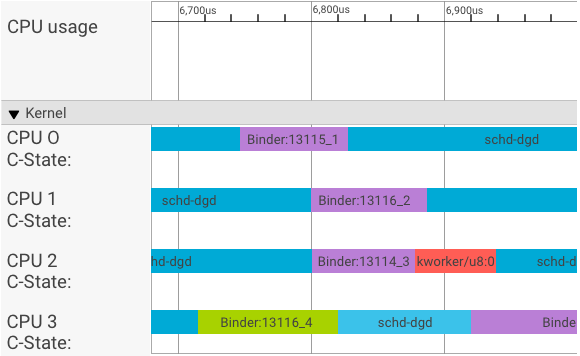
在上面的例子中:
- 四 (4) 個 schd-dbg 進程是客戶端進程。
- 四 (4) 個 binder 進程是服務器進程(名稱以Binder開頭,以序列號結尾)。
- 客戶端進程始終與專用於其客戶端的服務器進程配對。
- 所有客戶端-服務器進程對由內核同時獨立調度。
在 CPU 1 中,操作系統內核執行客戶端發出請求。然後,它盡可能使用相同的 CPU 來喚醒服務器進程、處理請求並在請求完成後切換回上下文。
吞吐量與延遲
在客戶端和服務器進程無縫切換的完美事務中,吞吐量和延遲測試不會產生明顯不同的消息。但是,當操作系統內核正在處理來自硬件的中斷請求 (IRQ)、等待鎖定或只是選擇不立即處理消息時,可能會形成延遲泡沫。
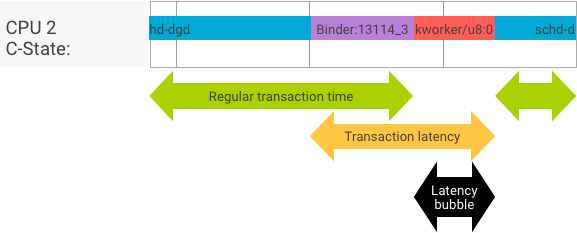
吞吐量測試生成大量具有不同有效負載大小的事務,為常規事務時間(在最佳情況下)和 binder 可以實現的最大吞吐量提供了良好的估計。
相比之下,延遲測試不會對有效負載執行任何操作以最小化常規事務時間。我們可以使用事務時間來估計 binder 開銷,對最壞情況進行統計,併計算延遲滿足指定期限的事務的比率。
處理優先級反轉
當具有較高優先級的線程在邏輯上等待具有較低優先級的線程時,就會發生優先級反轉。實時 (RT) 應用程序存在優先級反轉問題:
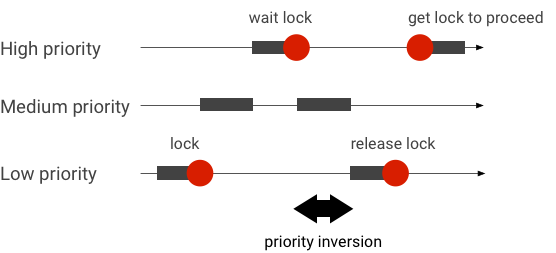
當使用 Linux Completely Fair Scheduler (CFS) 調度時,即使其他線程具有更高的優先級,一個線程也始終有機會運行。因此,具有 CFS 調度的應用程序將優先級反轉作為預期行為而不是問題來處理。但是,如果Android框架需要RT調度來保證高優先級線程的權限,則必須解決優先級反轉問題。
綁定器事務期間的示例優先級反轉(在等待綁定器線程服務時,RT 線程在邏輯上被其他 CFS 線程阻塞):
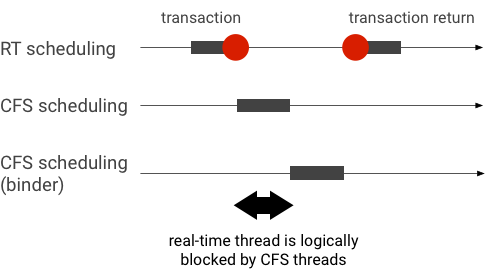
為避免阻塞,您可以在 Binder 線程為來自 RT 客戶端的請求提供服務時,使用優先級繼承將其臨時升級為 RT 線程。請記住,RT 調度資源有限,應謹慎使用。在有n 個CPU 的系統中,當前 RT 線程的最大數量也是n ;如果所有 CPU 都被其他 RT 線程佔用,則額外的 RT 線程可能需要等待(從而錯過它們的截止日期)。
要解決所有可能的優先級倒置,您可以對 binder 和 hwbinder 使用優先級繼承。然而,由於 binder 在整個系統中廣泛使用,為 binder 事務啟用優先級繼承可能會給系統帶來比它所能服務的 RT 線程更多的垃圾郵件。
運行吞吐量測試
吞吐量測試針對 binder/hwbinder 事務吞吐量運行。在沒有過載的系統中,延遲氣泡很少見,只要迭代次數足夠高,就可以消除它們的影響。
- binder吞吐量測試位於
system/libhwbinder/vts/performance/Benchmark_binder.cpp中。 - hwbinder吞吐量測試位於
system/libhwbinder/vts/performance/Benchmark.cpp中。
試驗結果
使用不同有效負載大小的事務的示例吞吐量測試結果:
Benchmark Time CPU Iterations --------------------------------------------------------------------- BM_sendVec_binderize/4 70302 ns 32820 ns 21054 BM_sendVec_binderize/8 69974 ns 32700 ns 21296 BM_sendVec_binderize/16 70079 ns 32750 ns 21365 BM_sendVec_binderize/32 69907 ns 32686 ns 21310 BM_sendVec_binderize/64 70338 ns 32810 ns 21398 BM_sendVec_binderize/128 70012 ns 32768 ns 21377 BM_sendVec_binderize/256 69836 ns 32740 ns 21329 BM_sendVec_binderize/512 69986 ns 32830 ns 21296 BM_sendVec_binderize/1024 69714 ns 32757 ns 21319 BM_sendVec_binderize/2k 75002 ns 34520 ns 20305 BM_sendVec_binderize/4k 81955 ns 39116 ns 17895 BM_sendVec_binderize/8k 95316 ns 45710 ns 15350 BM_sendVec_binderize/16k 112751 ns 54417 ns 12679 BM_sendVec_binderize/32k 146642 ns 71339 ns 9901 BM_sendVec_binderize/64k 214796 ns 104665 ns 6495
- 時間表示實時測量的往返延遲。
- CPU表示調度 CPU 進行測試的累計時間。
- Iterations表示測試函數執行的次數。
例如,對於 8 字節的有效負載:
BM_sendVec_binderize/8 69974 ns 32700 ns 21296
... binder 可以實現的最大吞吐量計算如下:
8 字節有效負載的最大吞吐量 = (8 * 21296)/69974 ~= 2.423 b/ns ~= 2.268 Gb/s
測試選項
要以 .json 格式獲取結果,請使用--benchmark_format=json參數運行測試:
libhwbinder_benchmark --benchmark_format=json
{
"context": {
"date": "2017-05-17 08:32:47",
"num_cpus": 4,
"mhz_per_cpu": 19,
"cpu_scaling_enabled": true,
"library_build_type": "release"
},
"benchmarks": [
{
"name": "BM_sendVec_binderize/4",
"iterations": 32342,
"real_time": 47809,
"cpu_time": 21906,
"time_unit": "ns"
},
….
}
運行延遲測試
延遲測試測量客戶端開始初始化事務、切換到服務器進程進行處理以及接收結果所需的時間。該測試還查找可能對事務延遲產生負面影響的已知不良調度程序行為,例如不支持優先級繼承或不遵守同步標誌的調度程序。
- binder 延遲測試位於
frameworks/native/libs/binder/tests/schd-dbg.cpp中。 - hwbinder 延遲測試位於
system/libhwbinder/vts/performance/Latency.cpp中。
試驗結果
結果(在 .json 中)顯示平均/最佳/最差延遲的統計信息以及錯過的最後期限數量。
測試選項
延遲測試採用以下選項:
| 命令 | 描述 |
|---|---|
-i value | 指定迭代次數。 |
-pair value | 指定進程對的數量。 |
-deadline_us 2500 | 在我們指定截止日期。 |
-v | 獲取詳細(調試)輸出。 |
-trace | 在最後期限命中時停止跟踪。 |
以下部分詳細介紹了每個選項、描述用法並提供示例結果。
指定迭代
具有大量迭代和詳細輸出禁用的示例:
libhwbinder_latency -i 5000 -pair 3
{
"cfg":{"pair":3,"iterations":5000,"deadline_us":2500},
"P0":{"SYNC":"GOOD","S":9352,"I":10000,"R":0.9352,
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}
},
"P1":{"SYNC":"GOOD","S":9334,"I":10000,"R":0.9334,
"other_ms":{ "avg":0.19, "wst":2.9 , "bst":0.055, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":3.1 , "bst":0.066, "miss":1, "meetR":0.9998}
},
"P2":{"SYNC":"GOOD","S":9369,"I":10000,"R":0.9369,
"other_ms":{ "avg":0.19, "wst":4.8 , "bst":0.055, "miss":6, "meetR":0.9988},
"fifo_ms": { "avg":0.15, "wst":1.8 , "bst":0.067, "miss":0, "meetR":1}
},
"inheritance": "PASS"
}
這些測試結果表明:
-
"pair":3 - 創建一個客戶端和服務器對。
-
"iterations": 5000 - 包括 5000 次迭代。
-
"deadline_us":2500 - 截止時間為 2500us(2.5ms);大多數交易都有望達到這個價值。
-
"I": 10000 - 單個測試迭代包括兩 (2) 個事務:
- 按正常優先級進行的一項事務(
CFS other) - 一筆交易按實時優先級(
RT-fifo)
- 按正常優先級進行的一項事務(
-
"S": 9352 - 9352 個事務在同一個 CPU 中同步。
-
"R": 0.9352 - 指示客戶端和服務器在同一 CPU 中一起同步的比率。
-
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996} - 普通優先級調用者發出的所有事務的平均 (
avg)、最差 (wst) 和最佳 (bst) 情況。兩筆交易miss了最後期限,使得滿足率 (meetR) 0.9996。 -
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1} - 與
other_ms類似,但用於客戶端發出的具有rt_fifo優先級的事務。other_msfifo_ms的結果,具有更低的avg和wst值以及更高的meetR(隨著後台負載的差異可能更加顯著)。
注意:後台負載可能會影響吞吐量結果和延遲測試中的other_ms元組。只要後台加載的優先級低於RT-fifo ,只有fifo_ms可能會顯示類似的結果。
指定對值
每個客戶端進程都與一個專用於客戶端的服務器進程配對,並且每一對都可以獨立調度到任何 CPU。但是,只要 SYNC 標誌是honor ,CPU 遷移就不應該在事務期間發生。
確保系統沒有過載!雖然預計過載系統會出現高延遲,但過載系統的測試結果並不能提供有用的信息。要測試具有更高壓力的系統,請使用-pair #cpu-1 (或-pair #cpu謹慎使用)。使用-pair n和n > #cpu進行測試會使系統過載並生成無用信息。
指定期限值
經過廣泛的用戶場景測試(在合格產品上運行延遲測試),我們確定 2.5 毫秒是要滿足的最後期限。對於要求更高的新應用(如 1000 張照片/秒),此截止日期值會有所變化。
指定詳細輸出
使用-v選項顯示詳細輸出。例子:
libhwbinder_latency -i 1 -v-------------------------------------------------- service pid: 8674 tid: 8674 cpu: 1 SCHED_OTHER 0-------------------------------------------------- main pid: 8673 tid: 8673 cpu: 1 -------------------------------------------------- client pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0-------------------------------------------------- fifo-caller pid: 8677 tid: 8678 cpu: 0 SCHED_FIFO 99 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 ??? 99-------------------------------------------------- other-caller pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 SCHED_OTHER 0
- 服務線程是使用
SCHED_OTHER優先級創建的,並在CPU:1中以pid 8674運行。 - 然後第一個事務由
fifo-caller啟動。為了服務這個事務,hwbinder 將服務器的優先級(pid: 8674 tid: 8676)升級為 99 並用一個臨時調度類標記它(打印為???)。然後調度程序將服務器進程置於CPU:0中運行,並將其與客戶端的同一 CPU 同步。 - 第二個事務調用者俱有
SCHED_OTHER優先級。服務器自行降級並以SCHED_OTHER優先級為調用者提供服務。
使用跟踪進行調試
您可以指定-trace選項來調試延遲問題。使用時,延遲測試會在檢測到不良延遲時停止跟踪日誌記錄。例子:
atrace --async_start -b 8000 -c sched idle workq binder_driver sync freqlibhwbinder_latency -deadline_us 50000 -trace -i 50000 -pair 3deadline triggered: halt ∓ stop trace log:/sys/kernel/debug/tracing/trace
以下組件可能會影響延遲:
- 安卓構建模式。 Eng 模式通常比 userdebug 模式慢。
- 框架。框架服務如何使用
ioctl來配置 binder? - 粘合劑驅動程序。驅動程序是否支持細粒度鎖定?它是否包含所有性能轉換補丁?
- 內核版本。內核的實時能力越好,結果就越好。
- 內核配置。內核配置是否包含
DEBUG配置,例如DEBUG_PREEMPT和DEBUG_SPIN_LOCK? - 內核調度程序。內核是否具有能量感知調度程序 (EAS) 或異構多處理 (HMP) 調度程序?任何內核驅動程序(
cpu-freq驅動程序、cpu-idle驅動程序、cpu-hotplug等)是否會影響調度程序?