
systrace es la herramienta principal para analizar el rendimiento del dispositivo Android. Sin embargo, es realmente un envoltorio alrededor de otras herramientas. Es el contenedor del lado del host alrededor de atrace , el ejecutable del lado del dispositivo que controla el seguimiento del espacio de usuario y configura ftrace , y el mecanismo de seguimiento principal en el kernel de Linux. systrace usa atrace para habilitar el rastreo, luego lee el búfer de ftrace y lo envuelve todo en un visor HTML autónomo. (Si bien los núcleos más nuevos son compatibles con el filtro de paquetes Berkeley mejorado (eBPF) de Linux, la siguiente documentación se refiere al núcleo 3.18 (sin eFPF), ya que eso es lo que se usó en Pixel/Pixel XL).
systrace es propiedad de los equipos de Google Android y Google Chrome y es de código abierto como parte del proyecto Catapult . Además de systrace, Catapult incluye otras utilidades útiles. Por ejemplo, ftrace tiene más funciones de las que systrace o atrace pueden habilitar directamente y contiene algunas funciones avanzadas que son fundamentales para depurar problemas de rendimiento. (Estas funciones requieren acceso de raíz y, a menudo, un nuevo kernel).
Correr sistema
Al depurar fluctuaciones en Pixel/Pixel XL, comience con el siguiente comando:
./systrace.py sched freq idle am wm gfx view sync binder_driver irq workq input -b 96000
Cuando se combina con los puntos de seguimiento adicionales necesarios para la GPU y la actividad de canalización de visualización, esto le brinda la capacidad de rastrear desde la entrada del usuario hasta el cuadro que se muestra en la pantalla. Establezca el tamaño del búfer en algo grande para evitar la pérdida de eventos (porque sin un búfer grande, algunas CPU no contienen eventos después de algún punto en el seguimiento).
Al pasar por systrace, tenga en cuenta que cada evento se desencadena por algo en la CPU .
Debido a que systrace se basa en ftrace y ftrace se ejecuta en la CPU, algo en la CPU debe escribir el búfer de ftrace que registra los cambios de hardware. Esto significa que si tiene curiosidad acerca de por qué una valla de visualización cambió de estado, puede ver qué se estaba ejecutando en la CPU en el punto exacto de su transición (algo que se ejecutaba en la CPU desencadenó ese cambio en el registro). Este concepto es la base para analizar el rendimiento mediante systrace.
Ejemplo: marco de trabajo
Este ejemplo describe un systrace para una canalización de interfaz de usuario normal. Para seguir con el ejemplo, descargue el archivo zip de seguimientos (que también incluye otros seguimientos a los que se hace referencia en esta sección), descomprima el archivo y abra el archivo systrace_tutorial.html en su navegador. Tenga en cuenta que este systrace es un archivo grande; a menos que use systrace en su trabajo diario, es probable que este sea un seguimiento mucho más grande con mucha más información de la que haya visto antes en un solo seguimiento.
Para una carga de trabajo periódica y constante, como TouchLatency, la canalización de la interfaz de usuario contiene lo siguiente:
- EventThread en SurfaceFlinger activa el subproceso de la interfaz de usuario de la aplicación, lo que indica que es hora de representar un nuevo marco.
- La aplicación representa un marco en el subproceso de interfaz de usuario, RenderThread y hwuiTasks, utilizando recursos de CPU y GPU. Esta es la mayor parte de la capacidad gastada para la interfaz de usuario.
- La aplicación envía el marco renderizado a SurfaceFlinger usando un archivador, luego SurfaceFlinger entra en modo de suspensión.
- Un segundo EventThread en SurfaceFlinger activa SurfaceFlinger para activar la composición y mostrar la salida. Si SurfaceFlinger determina que no hay trabajo por hacer, vuelve a dormir.
- SurfaceFlinger maneja la composición usando Hardware Composer (HWC)/Hardware Composer 2 (HWC2) o GL. La composición HWC/HWC2 es más rápida y de menor consumo, pero tiene limitaciones según el sistema en un chip (SoC). Esto suele tardar entre 4 y 6 ms, pero puede superponerse con el paso 2 porque las aplicaciones de Android siempre tienen un búfer triple. (Si bien las aplicaciones siempre tienen triple búfer, es posible que solo haya un marco pendiente esperando en SurfaceFlinger, lo que hace que parezca idéntico al doble búfer).
- SurfaceFlinger envía el resultado final para que se muestre con un controlador de proveedor y vuelve a dormir, esperando que se active EventThread.
Recorramos el marco que comienza en 15409 ms:
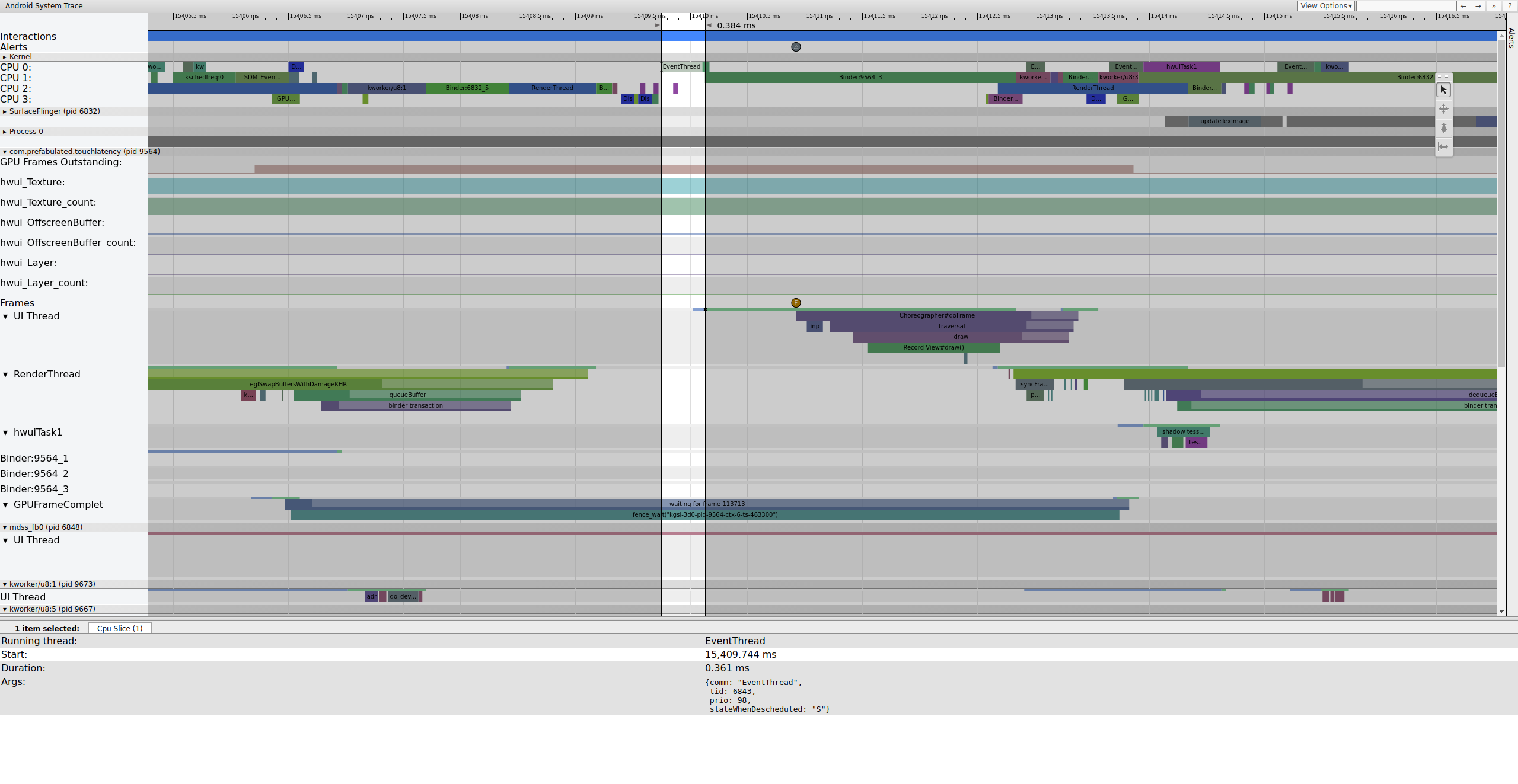
La figura 1 es un marco normal rodeado de marcos normales, por lo que es un buen punto de partida para comprender cómo funciona la canalización de la interfaz de usuario. La fila de subprocesos de la interfaz de usuario para TouchLatency incluye diferentes colores en diferentes momentos. Las barras indican diferentes estados para el hilo:
- gris Dormido.
- Azul. Ejecutable (podría ejecutarse, pero el planificador aún no lo ha elegido para ejecutarse).
- Verde. En ejecución activa (el programador cree que se está ejecutando).
- Rojo. Sueño ininterrumpido (generalmente durmiendo en un bloqueo en el kernel). Puede ser indicativo de la carga de E/S. Extremadamente útil para depurar problemas de rendimiento.
- Naranja. Suspensión ininterrumpida debido a la carga de E/S.
Para ver el motivo de la suspensión ininterrumpida (disponible desde el punto de sched_blocked_reason ), seleccione la porción roja de suspensión ininterrumpida.
Mientras se ejecuta EventThread, el subproceso de interfaz de usuario para TouchLatency se vuelve ejecutable. Para ver qué lo despertó, haga clic en la sección azul.
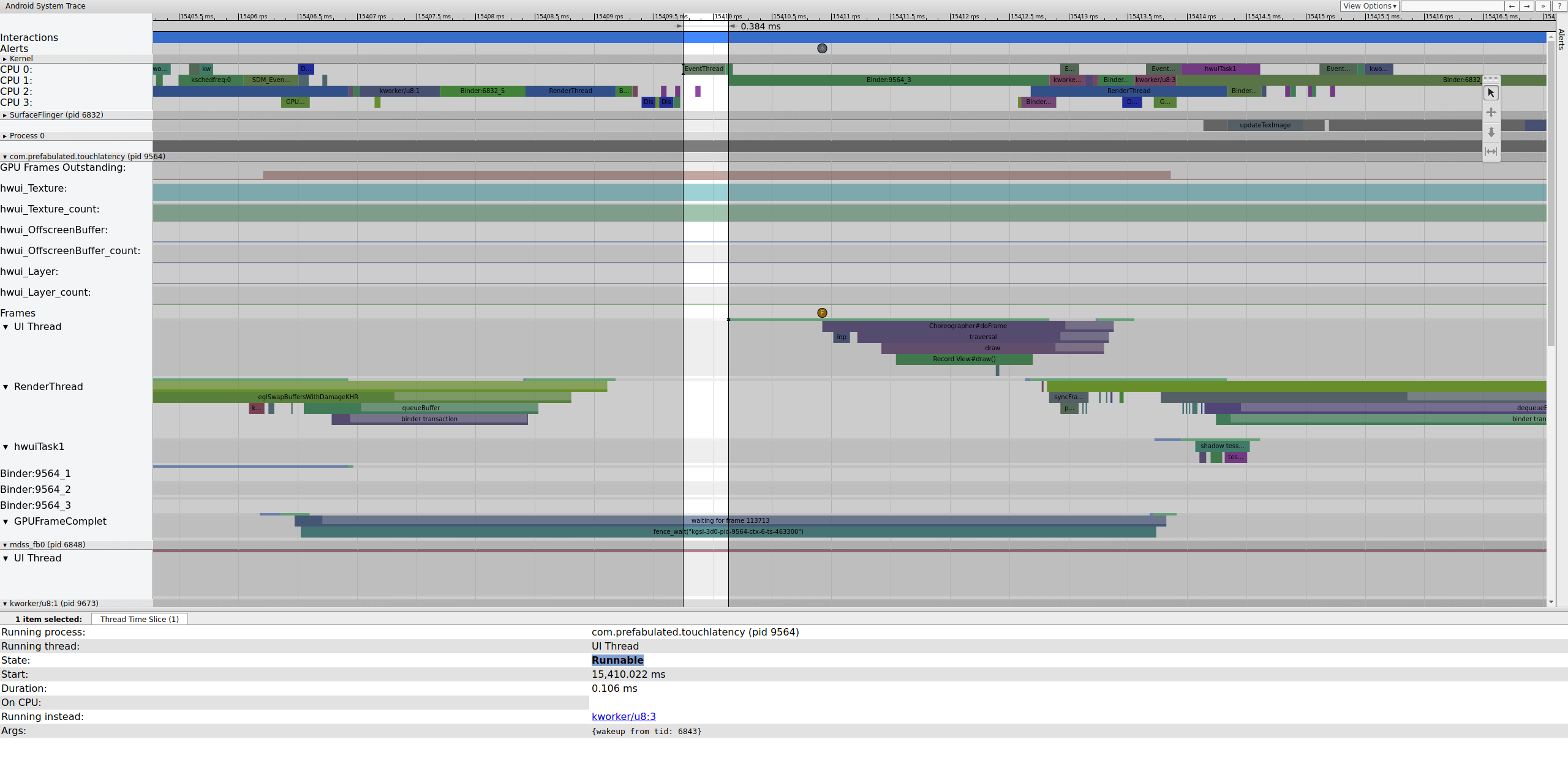
La figura 2 muestra que el subproceso de interfaz de usuario TouchLatency fue activado por tid 6843, que corresponde a EventThread. El subproceso de la interfaz de usuario se activa, representa un marco y lo pone en cola para que lo consuma SurfaceFlinger.
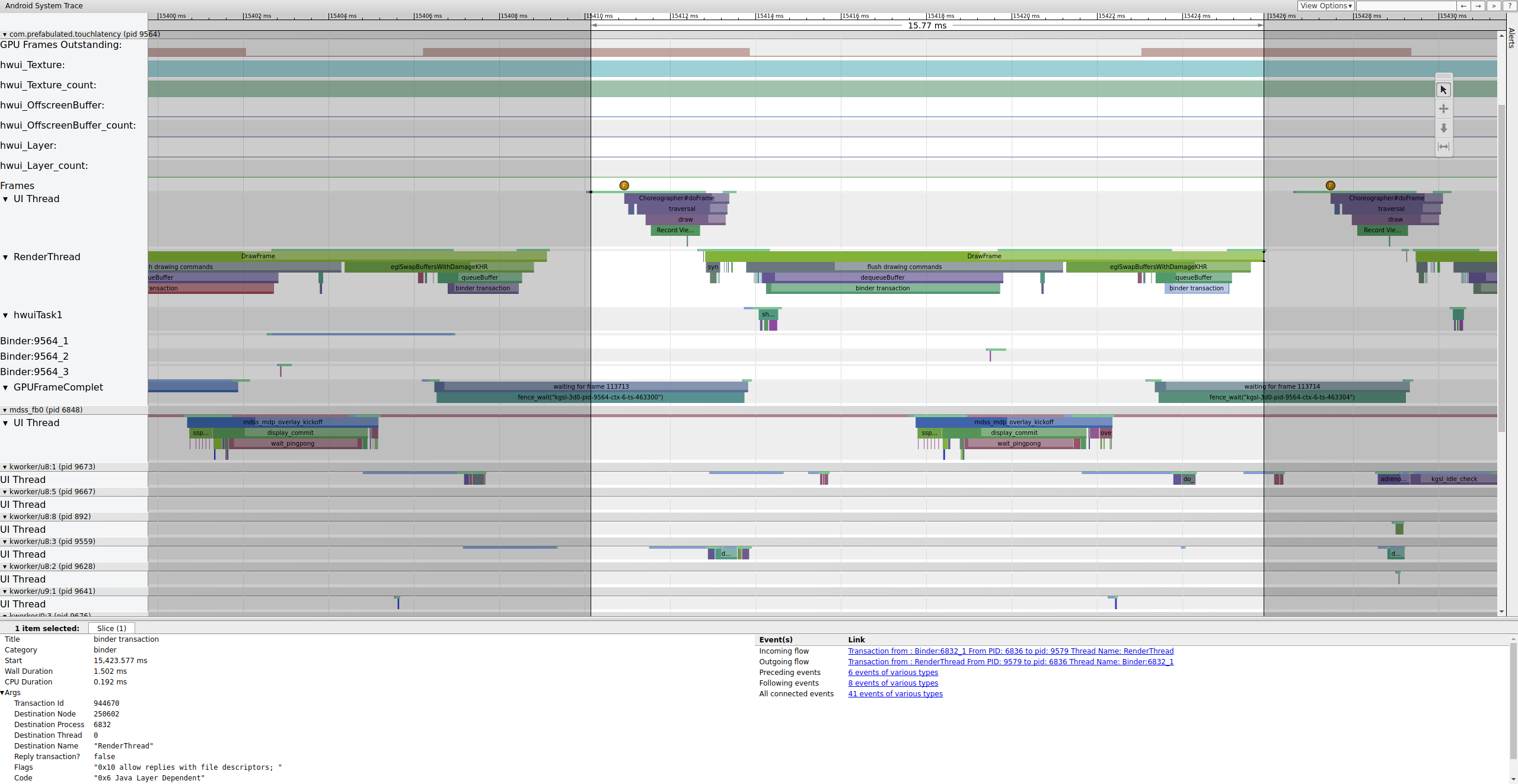
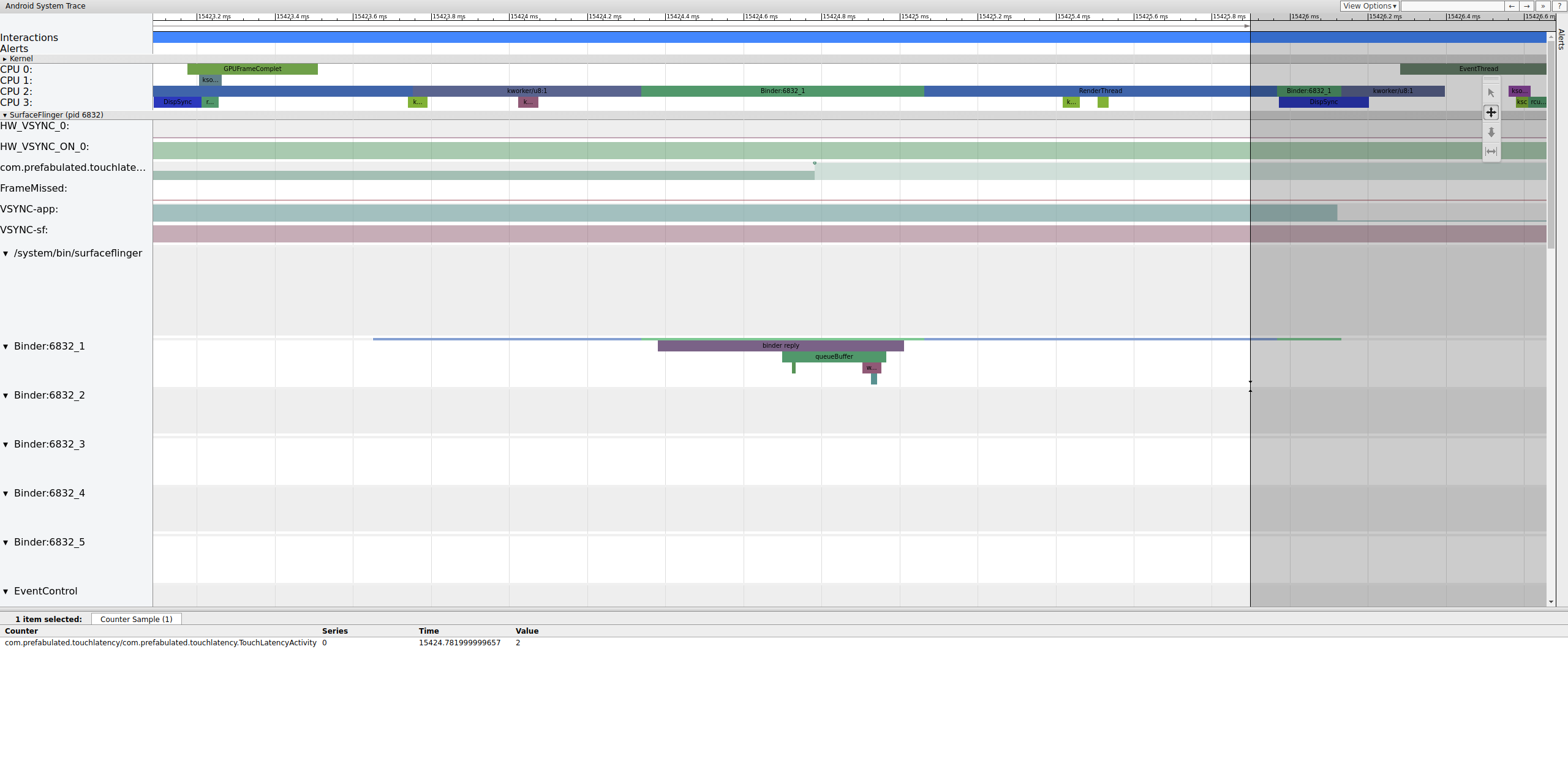
Si la etiqueta binder_driver está habilitada en un seguimiento, puede seleccionar una transacción de enlace para ver información sobre todos los procesos involucrados en esa transacción.
La Figura 4 muestra que, a los 15 423,65 ms, Binder:6832_1 en SurfaceFlinger se vuelve ejecutable debido a tid 9579, que es RenderThread de TouchLatency. También puede ver queueBuffer en ambos lados de la transacción del enlazador.
Durante el queueBuffer en el lado de SurfaceFlinger, la cantidad de fotogramas pendientes de TouchLatency va de 1 a 2.
La figura 5 muestra el almacenamiento en búfer triple, en el que hay dos fotogramas completos y la aplicación está a punto de empezar a renderizar un tercero. Esto se debe a que ya eliminamos algunos fotogramas, por lo que la aplicación mantiene dos fotogramas pendientes en lugar de uno para intentar evitar que se pierdan más fotogramas.
Poco después, el subproceso principal de SurfaceFlinger se activa con un segundo EventThread para que pueda mostrar el marco pendiente más antiguo en la pantalla:
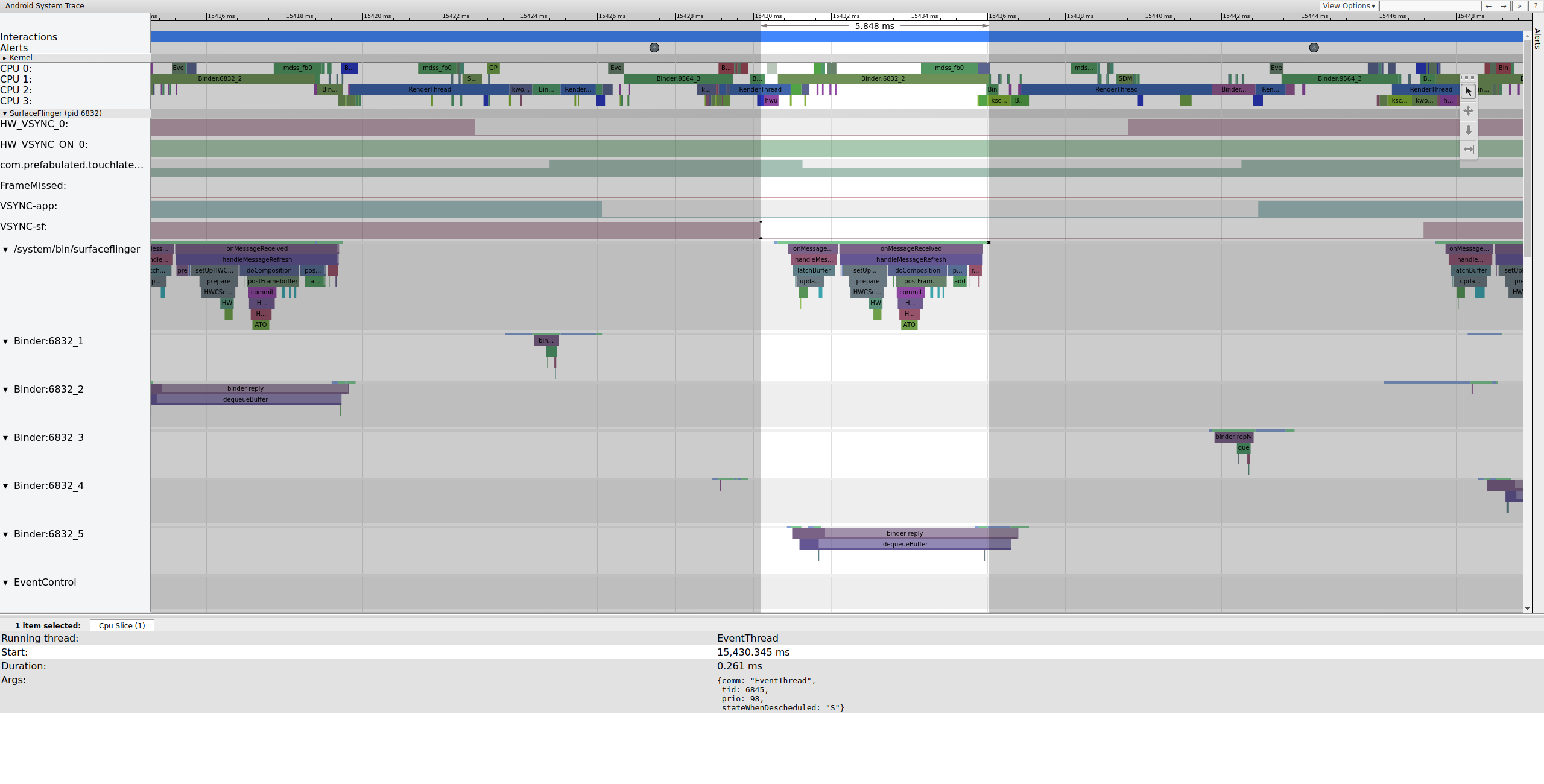
SurfaceFlinger primero bloquea el búfer pendiente más antiguo, lo que hace que el recuento del búfer pendiente disminuya de 2 a 1.
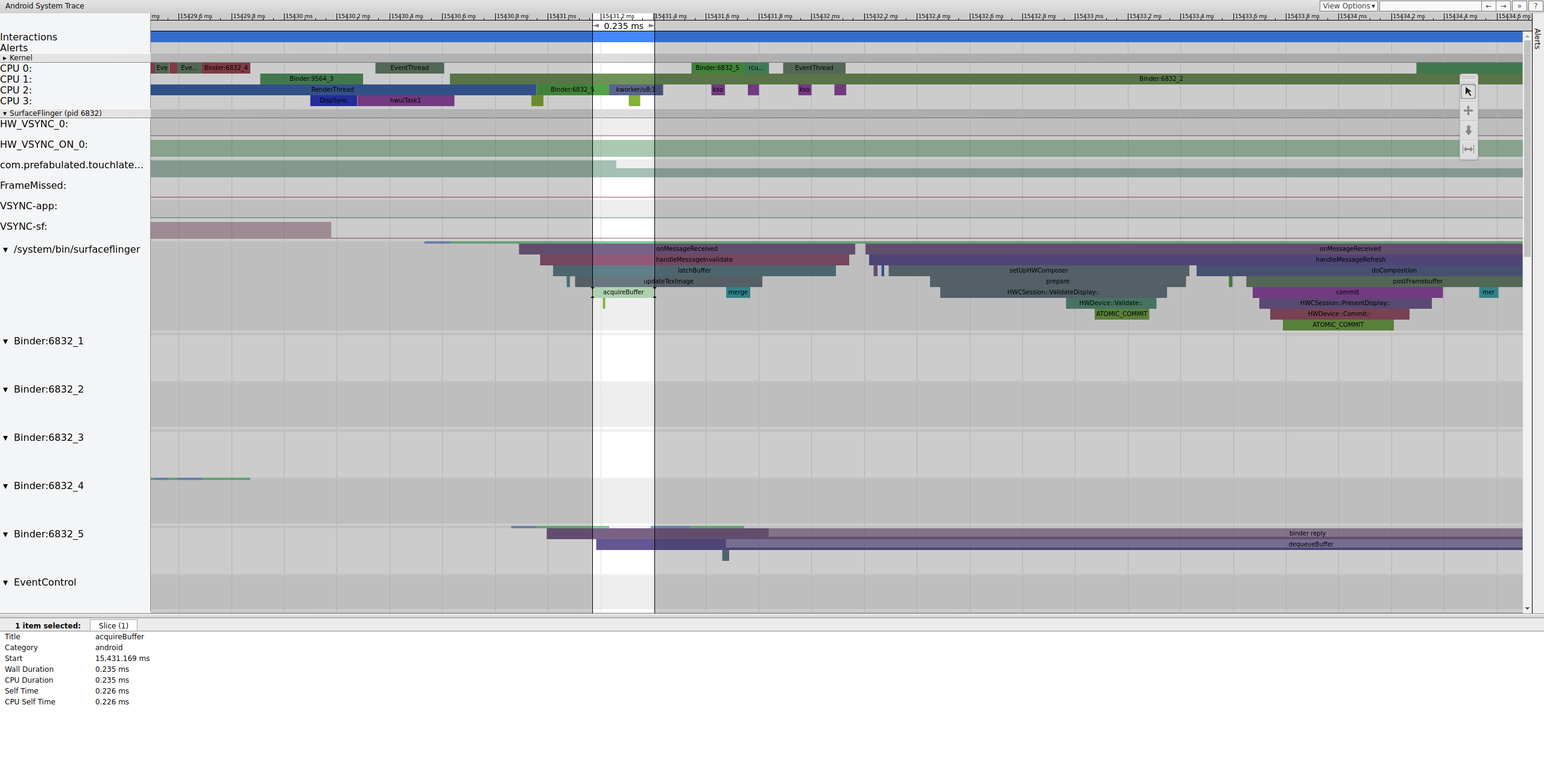
Después de bloquear el búfer, SurfaceFlinger configura la composición y envía el cuadro final a la pantalla. (Algunas de estas secciones están habilitadas como parte del punto de seguimiento de mdss , por lo que es posible que no estén incluidas en su SoC).
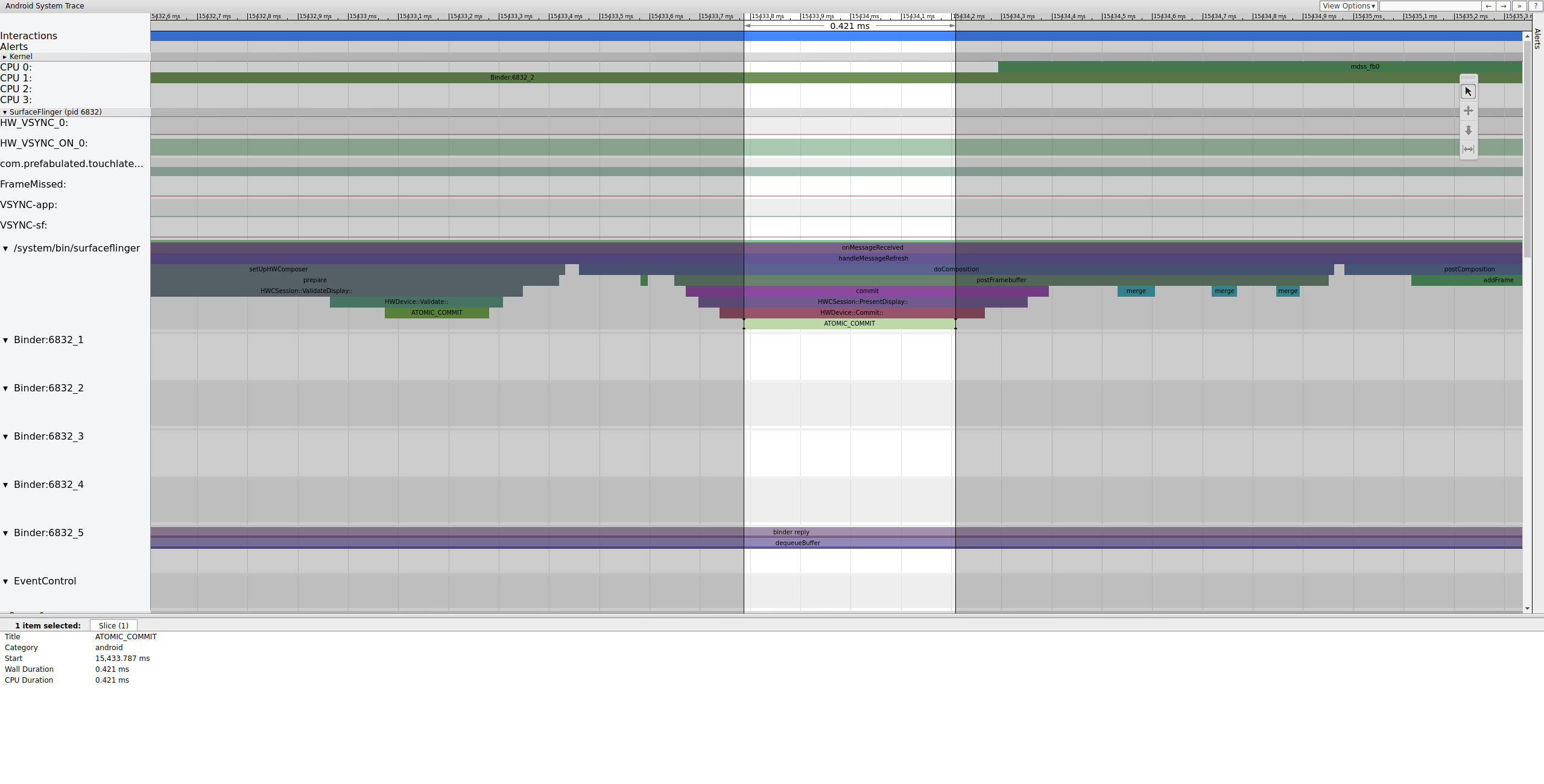
A continuación, mdss_fb0 se activa en la CPU 0. mdss_fb0 es el subproceso del núcleo de la canalización de visualización para generar un marco renderizado en la pantalla. Podemos ver mdss_fb0 como su propia fila en el seguimiento (desplácese hacia abajo para ver).
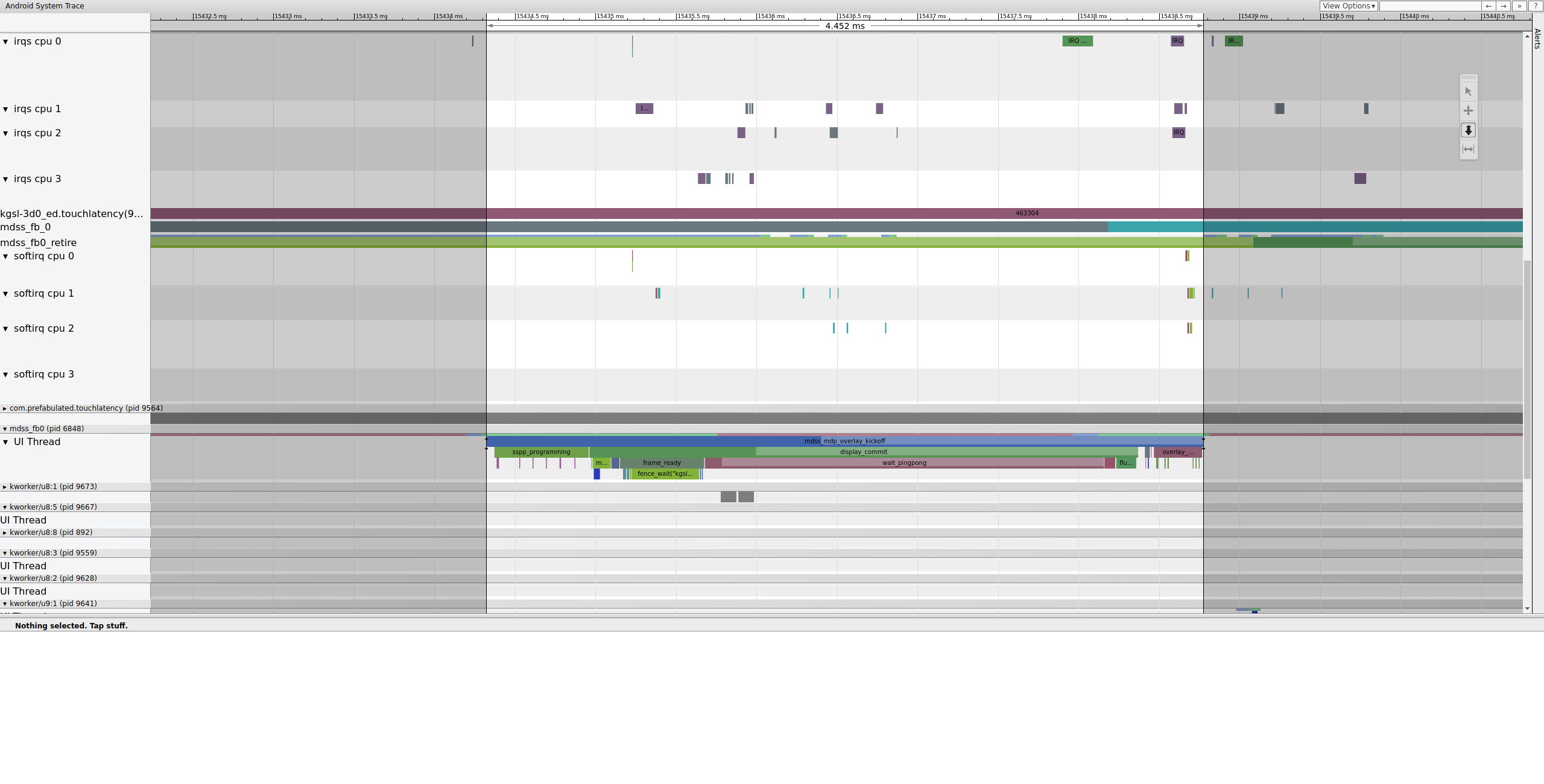
mdss_fb0 se activa, se ejecuta brevemente, entra en suspensión ininterrumpida y luego se activa nuevamente.
Ejemplo: marco que no funciona
Este ejemplo describe un systrace que se usa para depurar la inestabilidad de Pixel/Pixel XL. Para seguir con el ejemplo, descargue el archivo zip de seguimientos (que incluye otros seguimientos a los que se hace referencia en esta sección), descomprima el archivo y abra el archivo systrace_tutorial.html en su navegador.
Cuando abra el systrace, verá algo como esto:

Cuando busque bloqueos, verifique la fila FrameMissed debajo de SurfaceFlinger. FrameMissed es una mejora de la calidad de vida proporcionada por HWC2. Al ver systrace para otros dispositivos, es posible que la fila FrameMissed no esté presente si el dispositivo no usa HWC2. En cualquier caso, FrameMissed se correlaciona con SurfaceFlinger sin uno de sus tiempos de ejecución extremadamente regulares y un recuento de búfer pendiente sin cambios para la aplicación ( com.prefabulated.touchlatency ) en un vsync.
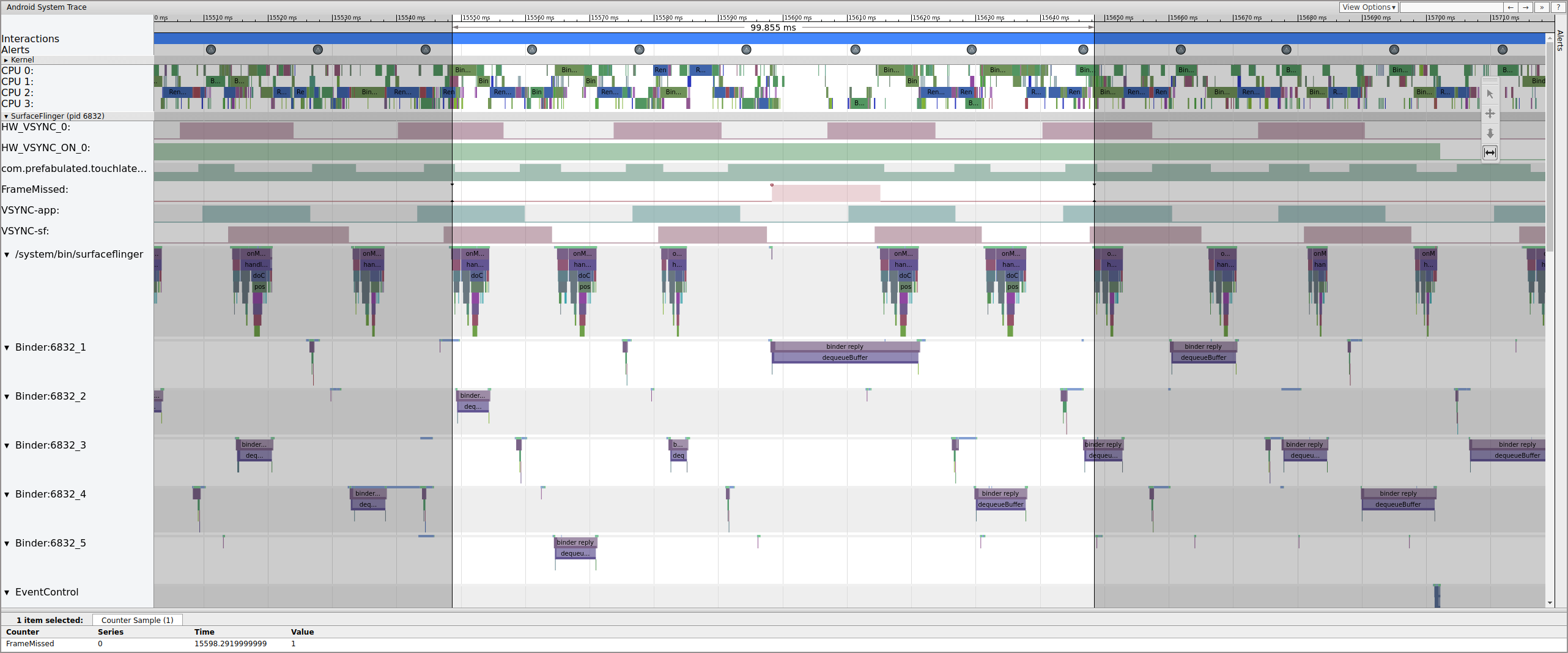
La Figura 11 muestra un marco perdido en 15598.29&nbps;ms. SurfaceFlinger se despertó brevemente en el intervalo vsync y volvió a dormir sin hacer ningún trabajo, lo que significa que SurfaceFlinger determinó que no valía la pena intentar enviar un marco a la pantalla nuevamente. ¿Por qué?
Para comprender cómo se descompuso la canalización para este marco, primero revise el ejemplo de marco de trabajo anterior para ver cómo aparece una canalización de interfaz de usuario normal en systrace. Cuando esté listo, regrese al marco perdido y trabaje hacia atrás. Observe que SurfaceFlinger se activa e inmediatamente se duerme. Al ver la cantidad de fotogramas pendientes de TouchLatency, hay dos fotogramas (una buena pista para ayudar a averiguar qué está pasando).
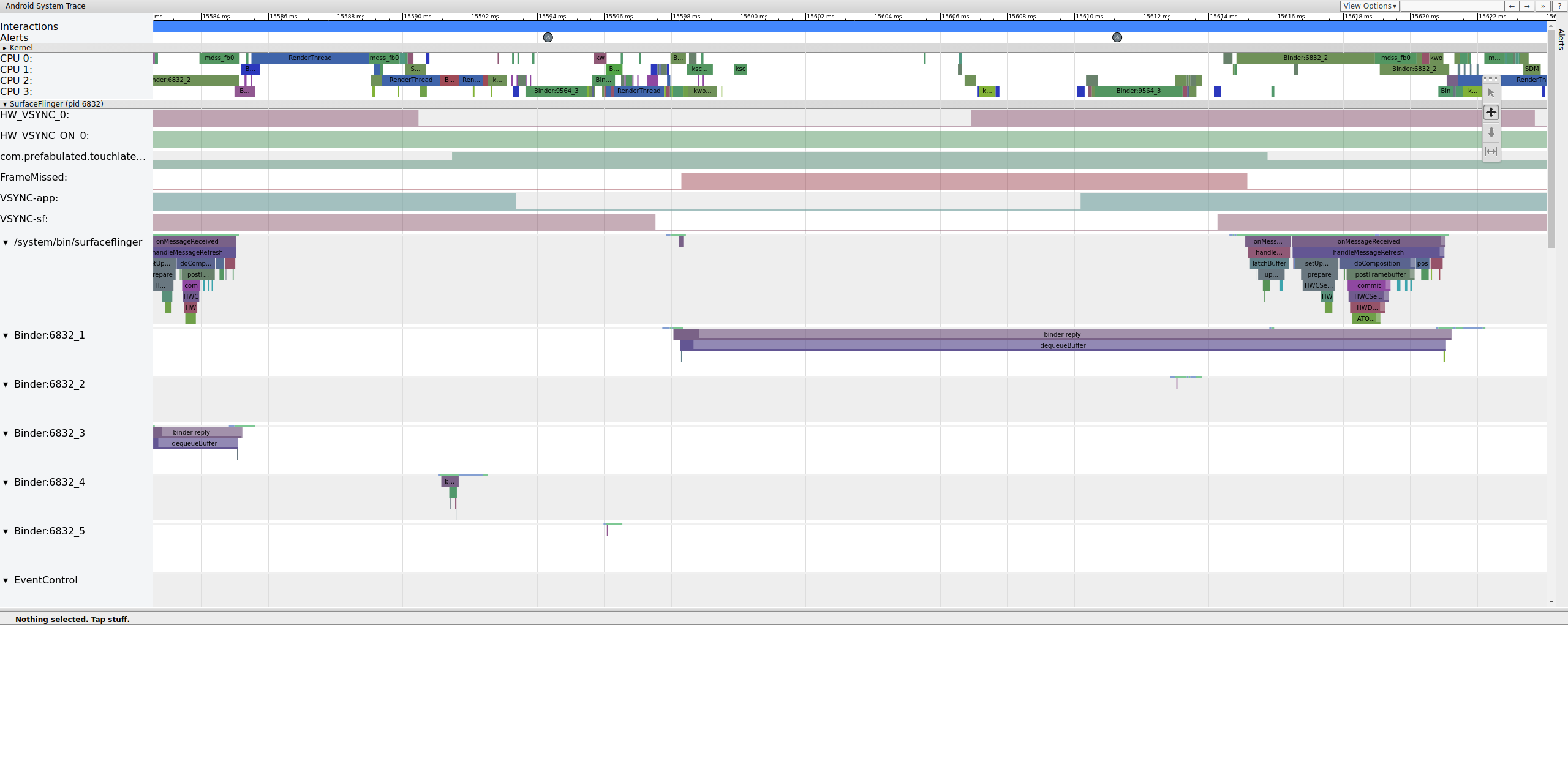
Debido a que tenemos marcos en SurfaceFlinger, no es un problema de la aplicación. Además, SurfaceFlinger se activa a la hora correcta, por lo que no es un problema de SurfaceFlinger. Si SurfaceFlinger y la aplicación parecen normales, probablemente sea un problema con el controlador.
Debido a que los puntos de mdss y sync están habilitados, podemos obtener información sobre las vallas (compartidas entre el controlador de pantalla y SurfaceFlinger) que controlan cuándo se envían los marcos a la pantalla. Estas vallas se enumeran en mdss_fb0_retire , lo que indica cuándo hay un marco en la pantalla. Estas vallas se proporcionan como parte de la categoría de seguimiento de sync . Qué vallas corresponden a eventos particulares en SurfaceFlinger depende de su SOC y su pila de controladores, así que trabaje con su proveedor de SOC para comprender el significado de las categorías de vallas en sus seguimientos.
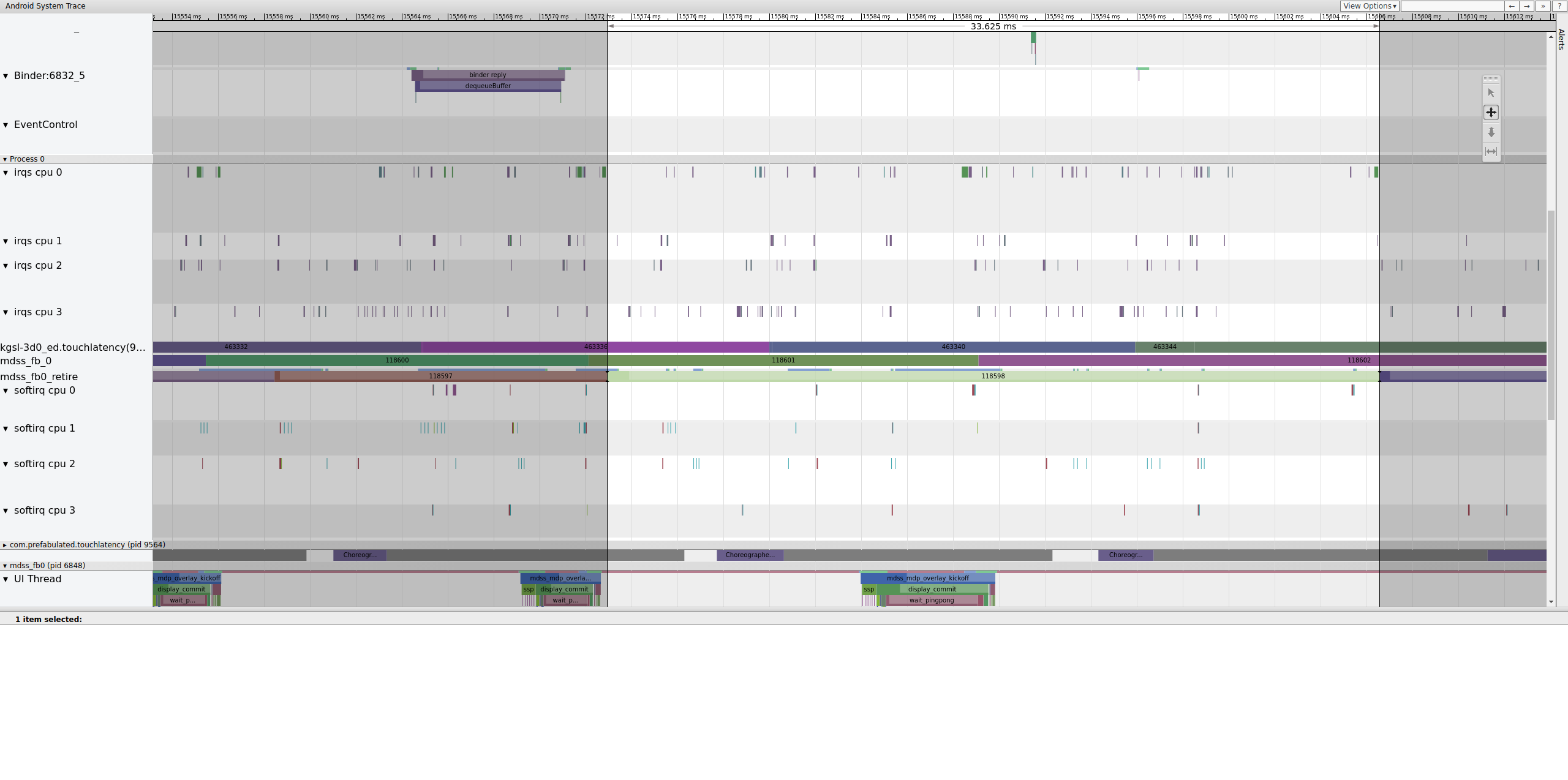
La figura 13 muestra un cuadro que se mostró durante 33 ms, no durante los 16,7 ms que se esperaba. A la mitad de ese corte, ese marco debería haber sido reemplazado por uno nuevo, pero no fue así. Mira el cuadro anterior y busca cualquier cosa.
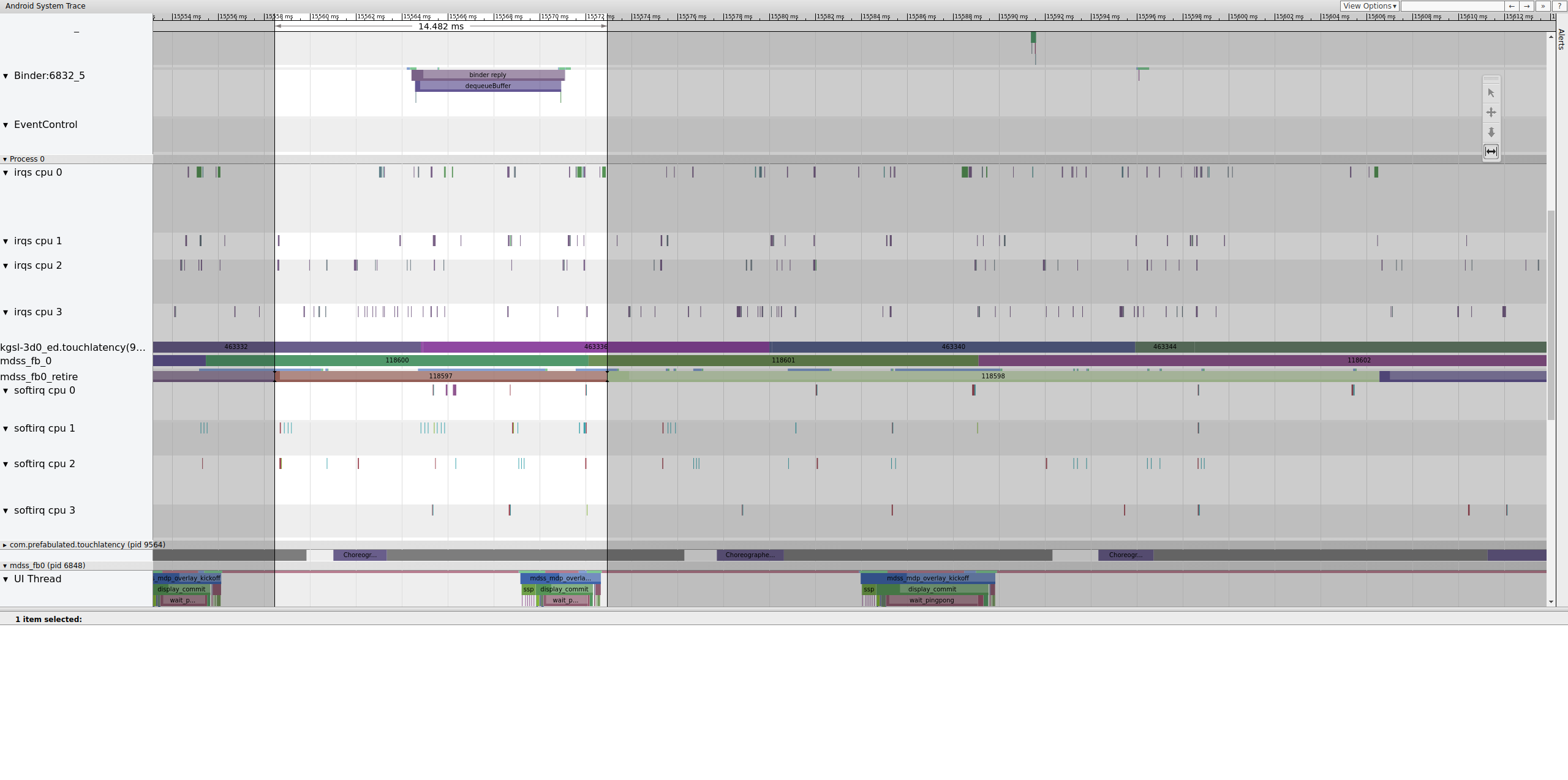
La figura 14 muestra 14,482 ms por trama. El segmento roto de dos fotogramas fue de 33,6 ms, que es aproximadamente lo que esperaríamos para dos fotogramas (representamos a 60 Hz, 16,7 ms por fotograma, que está cerca). Pero 14,482 ms no se acerca en absoluto a 16,7 ms, lo que sugiere que algo anda muy mal con la tubería de visualización.
Investiga exactamente dónde termina esa valla para determinar qué la controla.
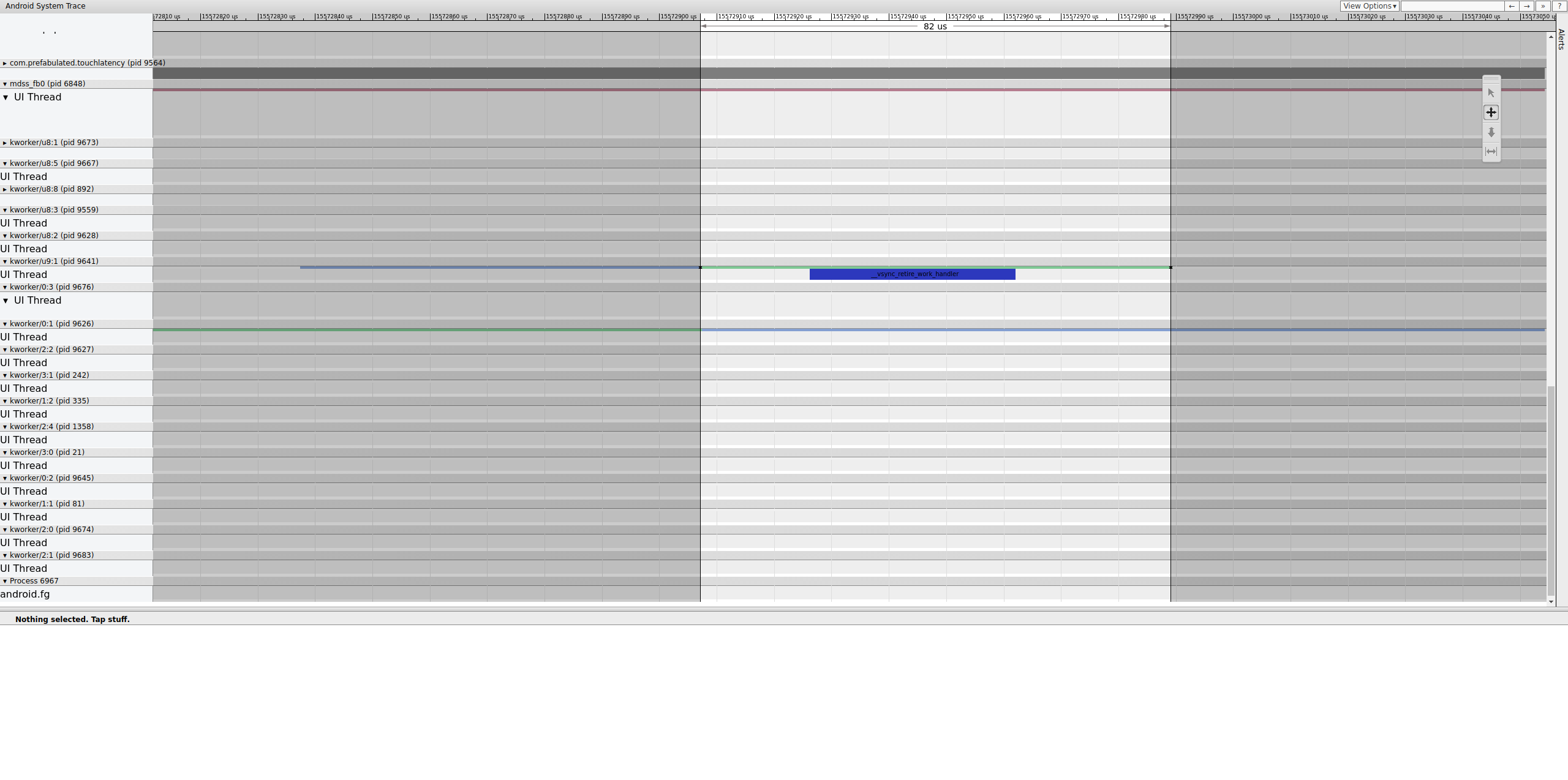
Una cola de trabajo contiene __vsync_retire_work_handler , que se ejecuta cuando cambia la valla. Mirando a través de la fuente del kernel, puede ver que es parte del controlador de pantalla. Parece estar en la ruta crítica de la canalización de visualización, por lo que debe ejecutarse lo más rápido posible. Se puede ejecutar durante 70 us aproximadamente (no es un gran retraso en la programación), pero es una cola de trabajo y es posible que no se programe con precisión.
Verifique el cuadro anterior para determinar si eso contribuyó; a veces, el nerviosismo puede acumularse con el tiempo y, finalmente, causar una fecha límite incumplida.
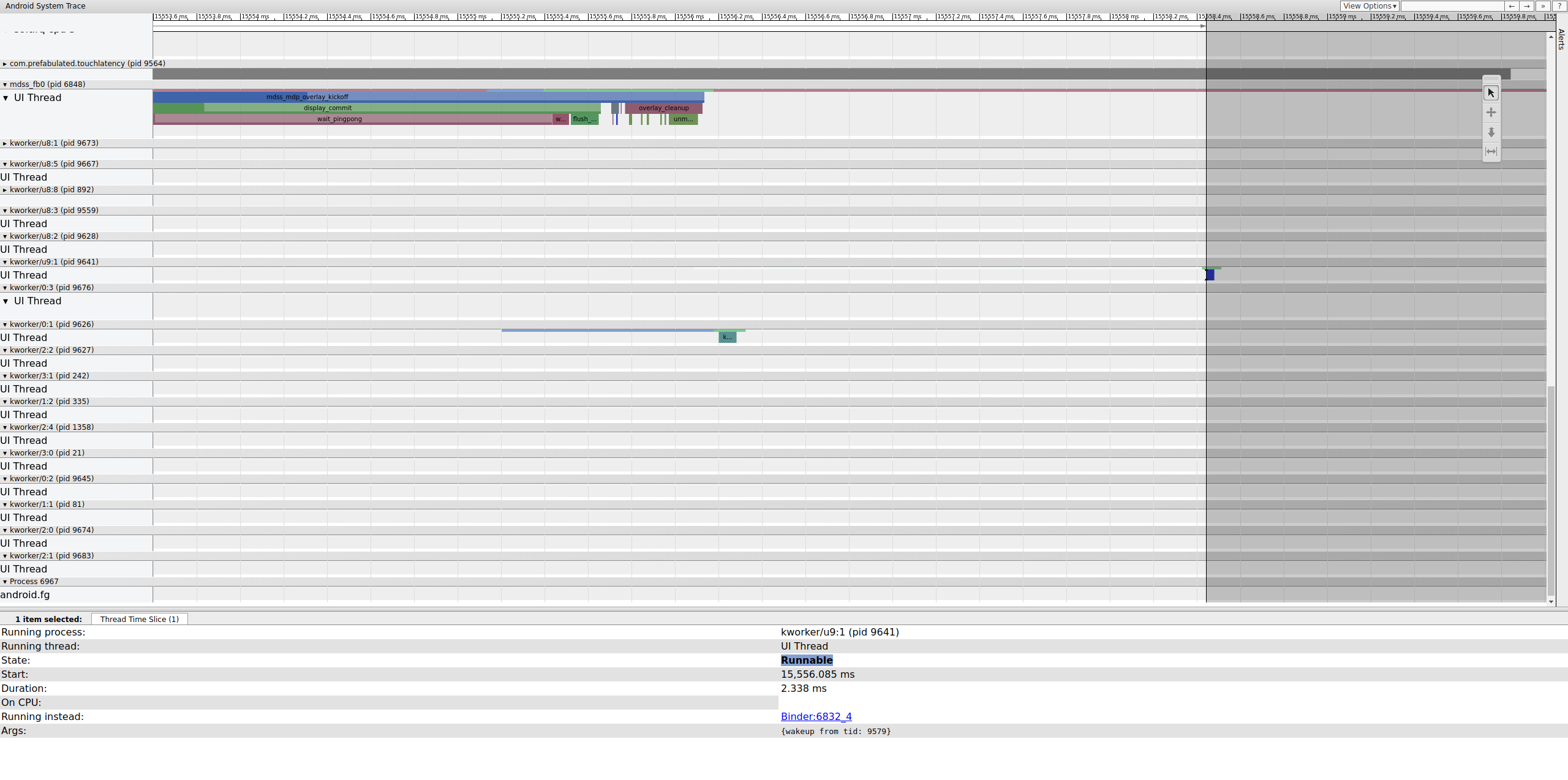
La línea ejecutable en el kworker no es visible porque el visor se vuelve blanco cuando se selecciona, pero las estadísticas cuentan la historia: 2,3 ms de retraso del programador para parte de la ruta crítica de la canalización de visualización es incorrecta . Antes de continuar, solucione el retraso que se produce al mover esta parte de la ruta crítica de canalización de visualización de una cola de trabajo (que se ejecuta como un SCHED_OTHER CFS) a un SCHED_FIFO SCHED_FIFO dedicado. Esta función necesita garantías de tiempo que las colas de trabajo no pueden (y no están destinadas a) proporcionar.
¿Es esta la razón del jank? Es difícil decirlo de manera concluyente. Fuera de los casos fáciles de diagnosticar, como la contención de bloqueo del kernel que hace que los subprocesos críticos para la visualización se suspendan, los seguimientos generalmente no especifican el problema. ¿Podría esta inestabilidad haber sido la causa de la pérdida de fotogramas? Absolutamente. Los tiempos de valla deben ser de 16,7 ms, pero no se acercan a eso en absoluto en los fotogramas que conducen al fotograma perdido. Dado lo estrechamente acoplado que está el canal de visualización, es posible que la fluctuación alrededor de los tiempos de la cerca haya dado como resultado un marco caído.
En este ejemplo, la solución implicó convertir __vsync_retire_work_handler de una cola de trabajo a un kthread dedicado. Esto dio como resultado mejoras notables en el jitter y una reducción de los bloqueos en la prueba de la pelota que rebota. Los seguimientos posteriores muestran tiempos de valla que rondan muy cerca de 16,7 ms.