
systrace est l'outil principal pour analyser les performances des appareils Android. Toutefois, il s'agit en réalité d'un wrapper autour d'autres outils. Il s'agit du wrapper côté hôte autour d'atrace, l'exécutable côté appareil qui contrôle le traçage de l'espace utilisateur et configure ftrace, ainsi que le mécanisme de traçage principal dans le noyau Linux. systrace utilise atrace pour activer le traçage, puis lit le tampon ftrace et l'encapsule dans un lecteur HTML autonome. (Bien que les noyaux plus récents soient compatibles avec le filtre de paquets Berkeley étendu Linux (eBPF), cette page concerne le noyau 3.18 (sans eFPF), car c'est celui qui était utilisé sur le Pixel ou le Pixel XL.)
systrace appartient aux équipes Google Android et Google Chrome, et est open source dans le cadre du projet Catapult. En plus de systrace, Catapult inclut d'autres utilitaires utiles. Par exemple, ftrace possède plus de fonctionnalités que celles qui peuvent être directement activées par systrace ou atrace, et contient des fonctionnalités avancées essentielles pour déboguer les problèmes de performances. (Ces fonctionnalités nécessitent un accès racine et souvent un nouveau noyau.)
Exécuter systrace
Lorsque vous déboguez des saccades sur un Pixel ou un Pixel XL, commencez par la commande suivante :
./systrace.py sched freq idle am wm gfx view sync binder_driver irq workq input -b 96000
Combiné aux points de trace supplémentaires requis pour l'activité du pipeline GPU et d'affichage, cela vous permet de suivre l'entrée utilisateur jusqu'à l'image affichée à l'écran. Définissez une taille de tampon élevée pour éviter de perdre des événements (car sans un grand tampon, certains processeurs ne contiennent aucun événement après un certain point de la trace).
Lorsque vous parcourez systrace, n'oubliez pas que chaque événement est déclenché par quelque chose sur le processeur.
Étant donné que systrace est basé sur ftrace et que ftrace s'exécute sur le processeur, quelque chose sur le processeur doit écrire le tampon ftrace qui enregistre les modifications matérielles. Cela signifie que si vous souhaitez savoir pourquoi un fence d'affichage a changé d'état, vous pouvez voir ce qui s'exécutait sur le processeur au moment exact de sa transition (un élément s'exécutant sur le processeur a déclenché ce changement dans le journal). Ce concept est à la base de l'analyse des performances à l'aide de systrace.
Exemple : Cadre de travail
Cet exemple décrit une systrace pour un pipeline d'UI normal. Pour suivre l'exemple, téléchargez le fichier ZIP des traces (qui inclut également d'autres traces mentionnées dans cette section), décompressez le fichier et ouvrez le fichier systrace_tutorial.html dans votre navigateur.
Pour une charge de travail périodique et cohérente telle que TouchLatency, le pipeline d'UI suit cette séquence :
- EventThread dans SurfaceFlinger réveille le thread UI de l'application, signalant qu'il est temps de rendre un nouveau frame.
- L'application affiche un frame dans les tâches du thread UI, de RenderThread et de HWUI, en utilisant les ressources du processeur et du GPU. Il s'agit de la majeure partie de la capacité utilisée pour l'UI.
- L'application envoie le frame rendu à SurfaceFlinger à l'aide d'un binder, puis SurfaceFlinger se met en veille.
- Un deuxième EventThread dans SurfaceFlinger réveille SurfaceFlinger pour déclencher la composition et l'affichage. Si SurfaceFlinger détermine qu'il n'y a rien à faire, il se remet en veille.
- SurfaceFlinger gère la composition à l'aide de Hardware Composer (HWC), Hardware Composer 2 (HWC2) ou GL. La composition HWC et HWC2 est plus rapide et consomme moins d'énergie, mais présente des limites en fonction du système sur une puce (SoC). Cela prend généralement entre quatre et six millisecondes, mais peut chevaucher l'étape 2, car les applications Android sont toujours à triple tampon. (Bien que les applications soient toujours à triple tampon, il peut n'y avoir qu'un seul frame en attente dans SurfaceFlinger, ce qui le fait apparaître identique à la double mise en mémoire tampon.)
- SurfaceFlinger envoie la sortie finale à l'écran avec un pilote fournisseur et se remet en veille, en attendant le réveil d'EventThread.
Voici un exemple de séquence de frames commençant à 15 409 ms :
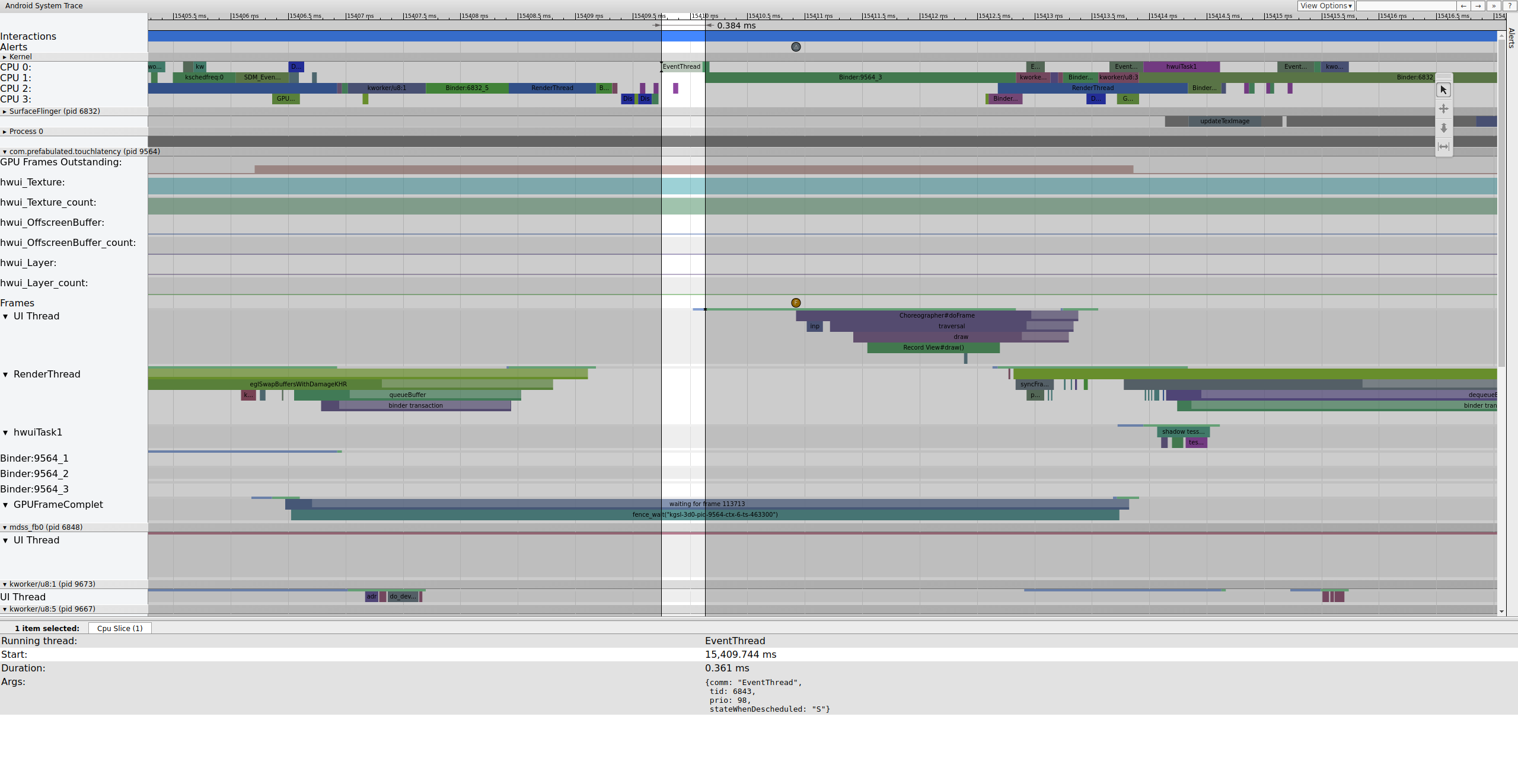
Figure 1 : Pipeline d'UI normal, EventThread en cours d'exécution.
La figure 1 est un frame normal entouré de frames normaux. C'est donc un bon point de départ pour comprendre le fonctionnement du pipeline d'UI. La ligne du thread d'UI pour TouchLatency inclut différentes couleurs à différents moments. Les barres indiquent différents états du thread :
- Gris Dormir
- Bleu. Exécutable (il pourrait s'exécuter, mais le planificateur ne l'a pas encore sélectionné).
- Vert En cours d'exécution (le planificateur pense qu'il est en cours d'exécution).
- Rouge : Sommeil non interruptible (généralement, le sommeil est verrouillé dans le noyau). Peut indiquer une charge d'E/S. Extrêmement utile pour déboguer les problèmes de performances.
- Orange Sommeil ininterrompu en raison de la charge d'E/S.
Pour afficher le motif du sommeil ininterrompu (disponible à partir du point de trace sched_blocked_reason), sélectionnez la tranche rouge de sommeil ininterrompu.
Pendant l'exécution d'EventThread, le thread UI pour TouchLatency devient exécutable. Pour savoir ce qui a réveillé l'appareil, cliquez sur la section bleue.
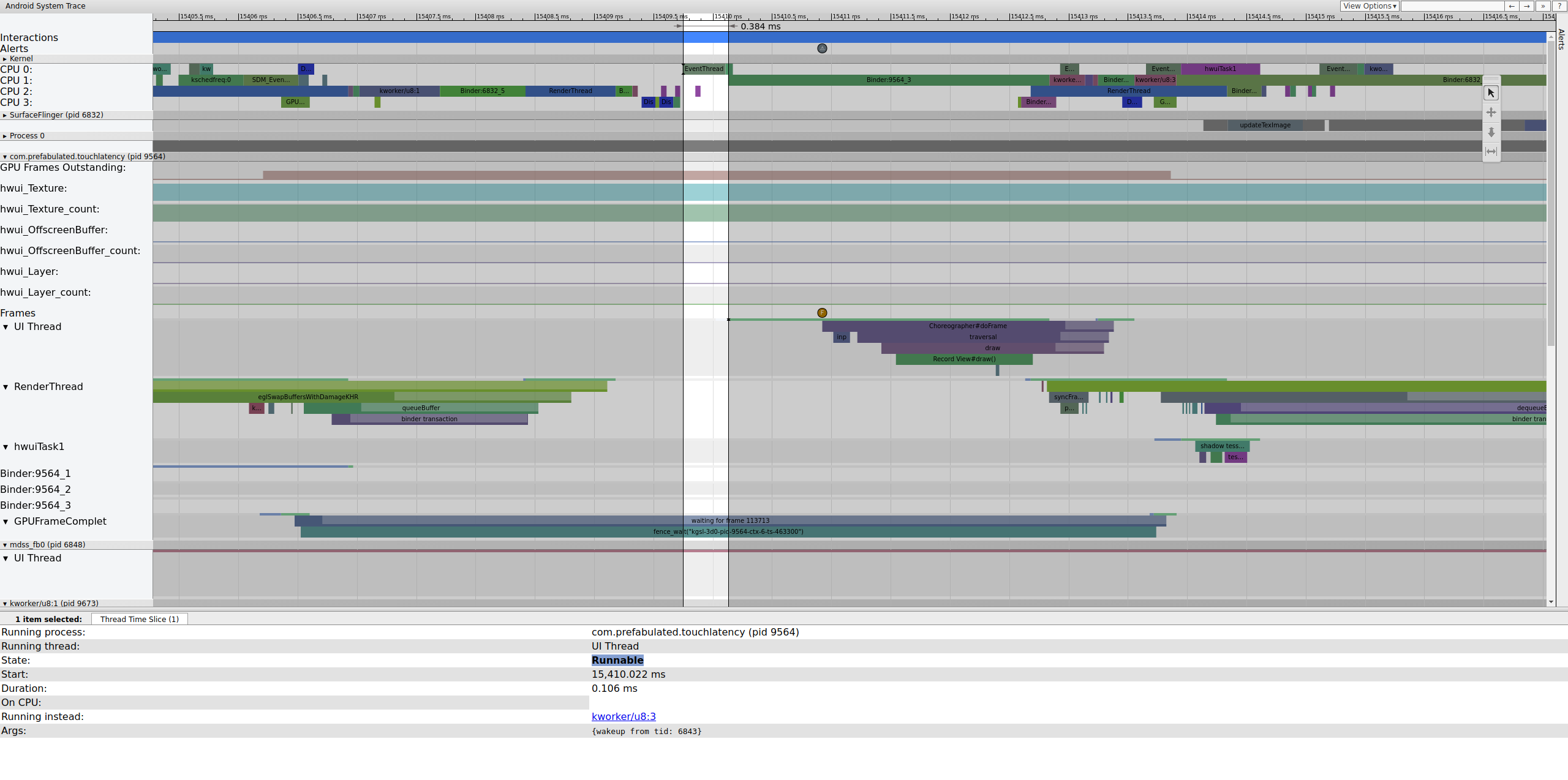
Figure 2. Thread UI pour TouchLatency.
La figure 2 montre que le thread UI TouchLatency a été réactivé par le tid 6843, qui correspond à EventThread. Le thread UI se réveille, affiche un frame et le met en file d'attente pour que SurfaceFlinger puisse l'utiliser.
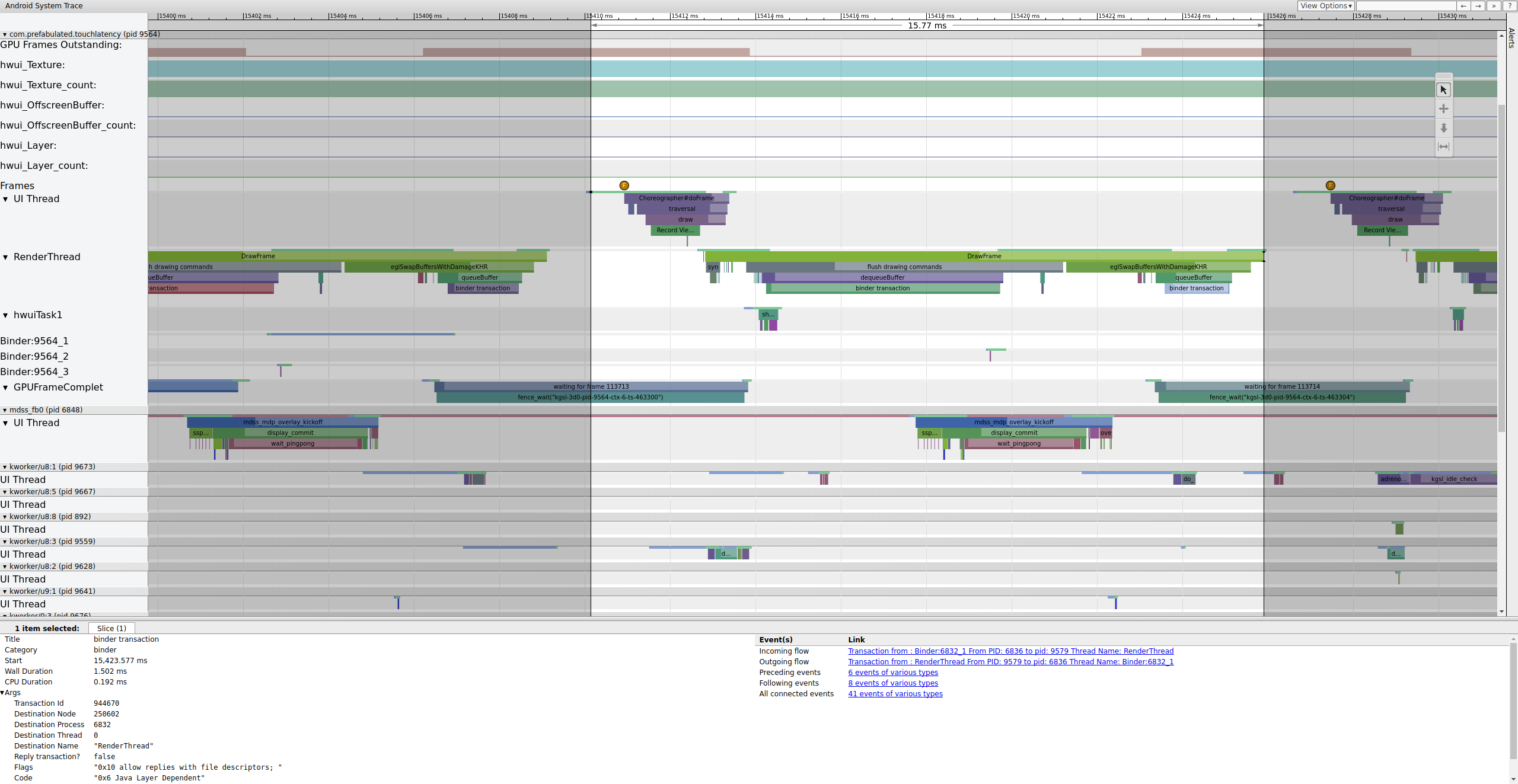
Figure 3. Le thread UI se réveille, affiche un frame et le met en file d'attente pour que SurfaceFlinger puisse l'utiliser.
Si le tag binder_driver est activé dans une trace, vous pouvez sélectionner une transaction de binder pour afficher des informations sur tous les processus impliqués dans cette transaction.
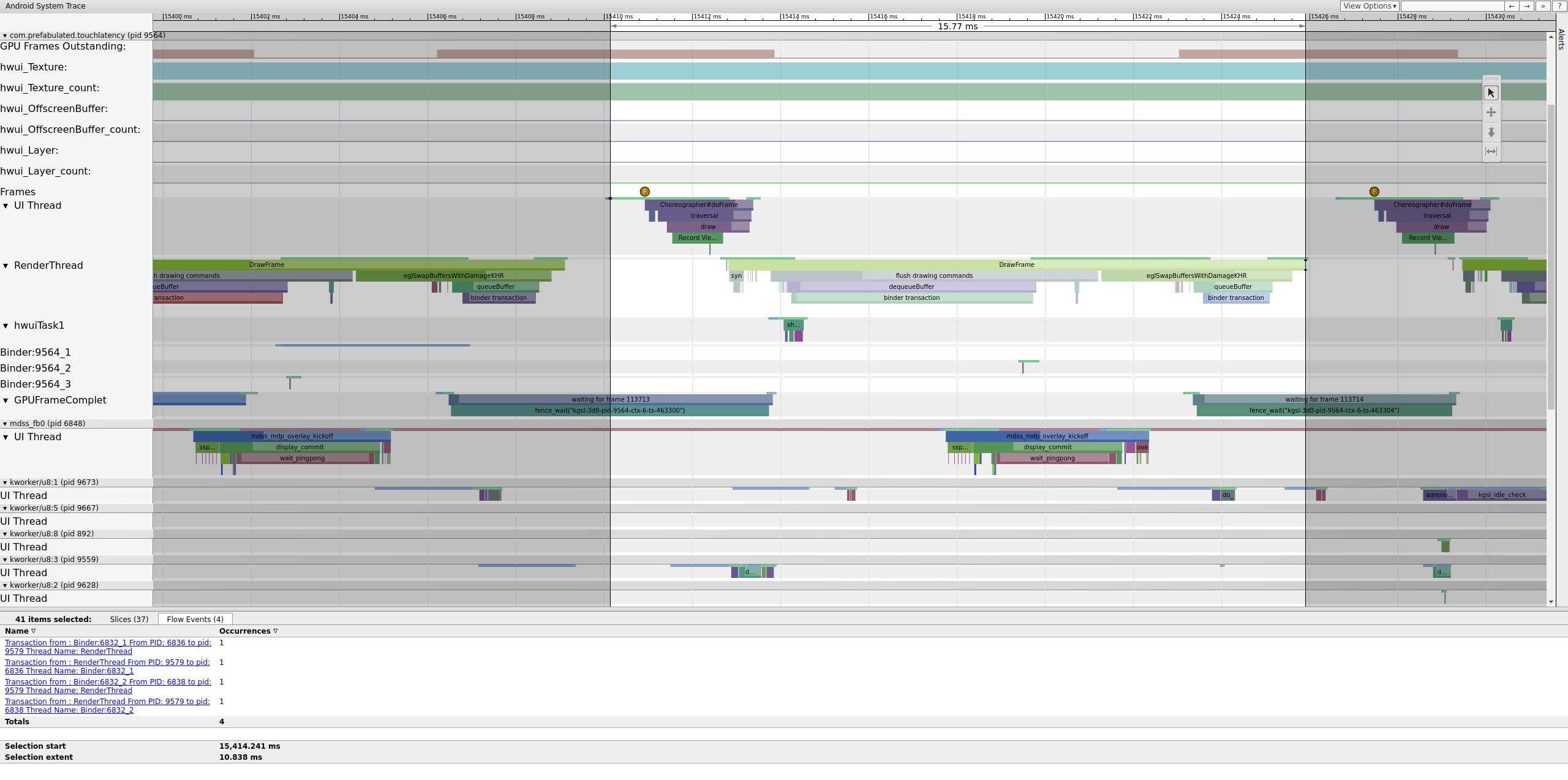
Figure 4. Transaction de liaison.
La figure 4 montre qu'à 15 423, 65 ms,Binder:6832_1 dans SurfaceFlinger devient exécutable en raison du tid 9579, qui est le RenderThread de TouchLatency. Vous pouvez également voir queueBuffer des deux côtés de la transaction Binder.
Lors de la mise en file d'attente de queueBuffer côté SurfaceFlinger, le nombre de frames en attente de TouchLatency passe de 1 à 2.
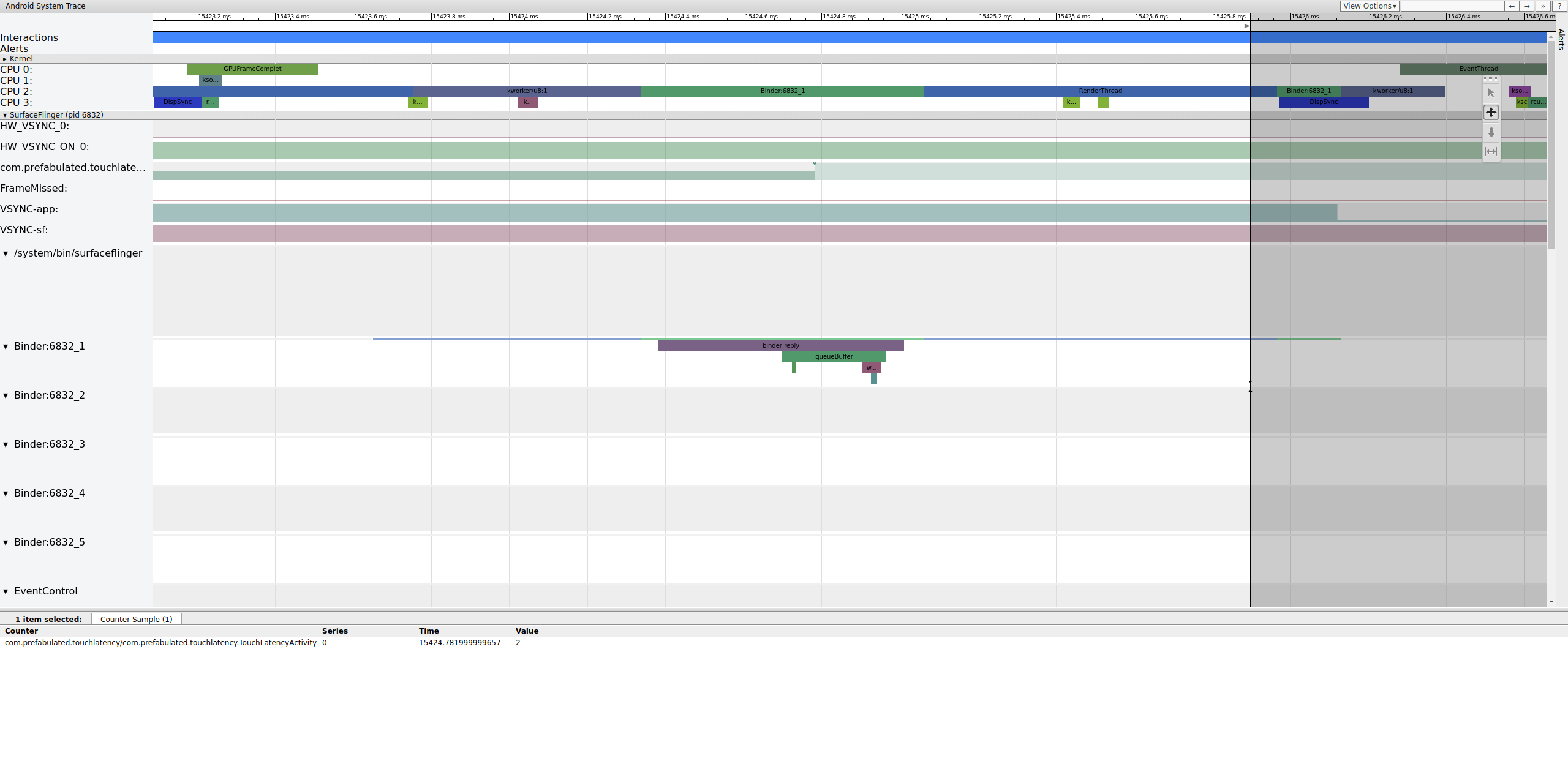
Figure 5. Le nombre de frames en attente est compris entre 1 et 2.
La figure 5 montre une mise en mémoire tampon triple, où deux frames sont terminés et l'application est sur le point de commencer à en afficher un troisième. En effet, nous avons déjà supprimé des frames. L'application conserve donc deux frames en attente au lieu d'un pour essayer d'éviter d'autres frames supprimés.
Peu de temps après, le thread principal de SurfaceFlinger est réactivé par un deuxième EventThread afin qu'il puisse afficher l'ancien frame en attente :
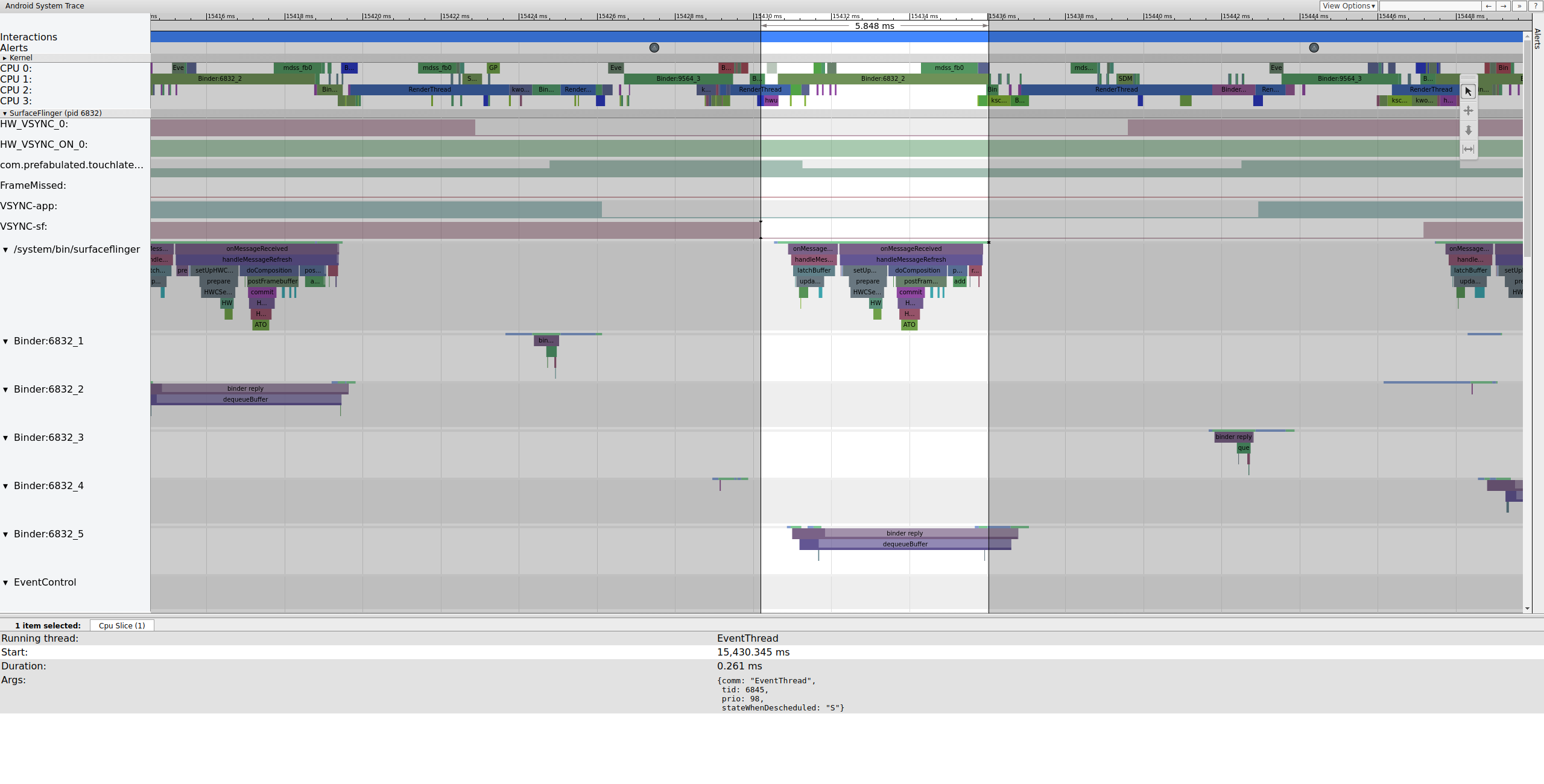
Figure 6. Le thread principal de SurfaceFlinger est réactivé par un deuxième EventThread.
SurfaceFlinger verrouille d'abord l'ancien tampon en attente, ce qui fait passer le nombre de tampons en attente de 2 à 1 :
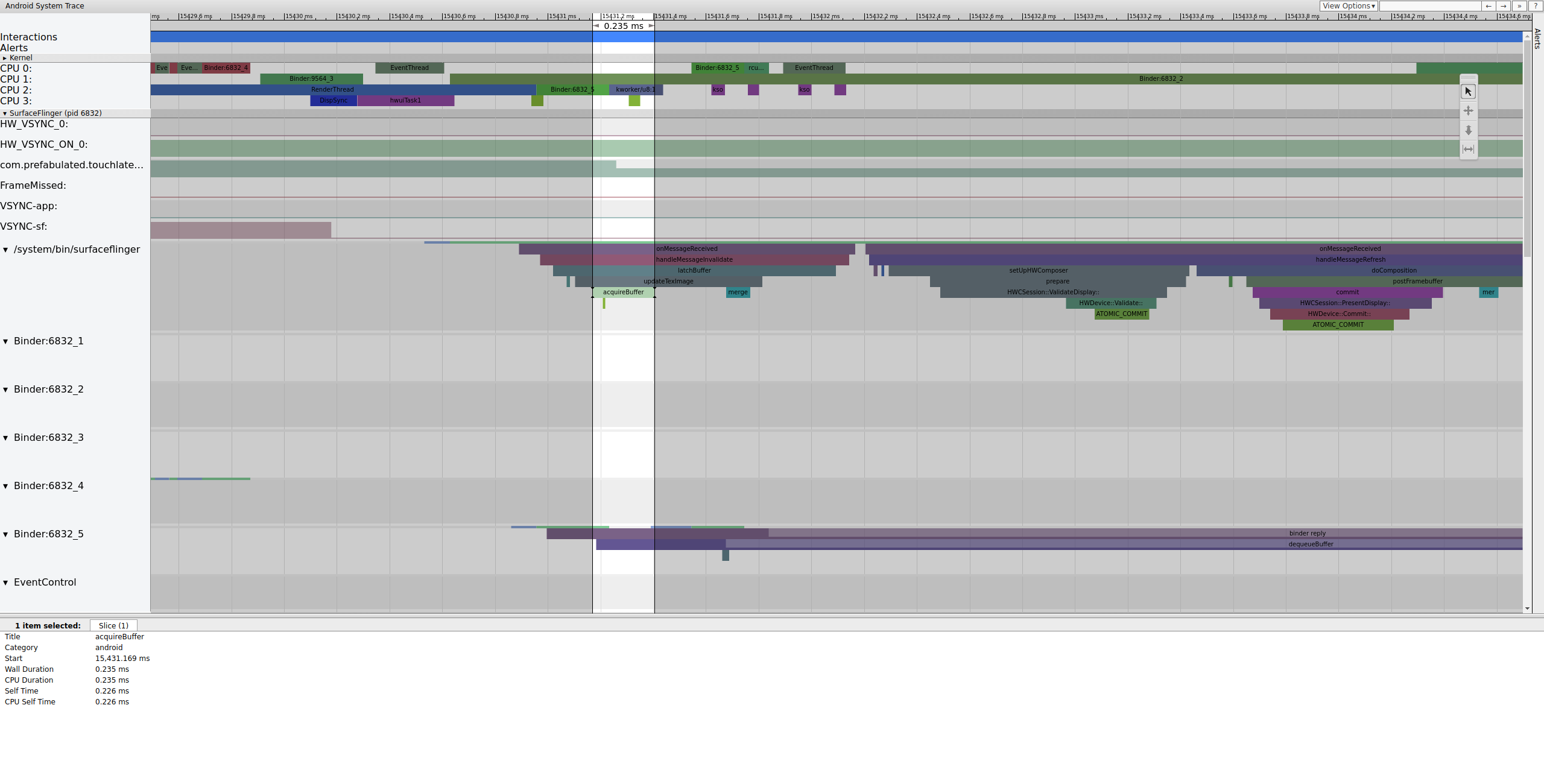
Figure 7. SurfaceFlinger s'accroche d'abord à l'ancien tampon en attente.
Après avoir verrouillé le tampon, SurfaceFlinger configure la composition et envoie le frame final à l'écran. (Certaines de ces sections sont activées dans le cadre du point de trace mdss. Il est donc possible qu'elles ne soient pas incluses dans votre SoC.)
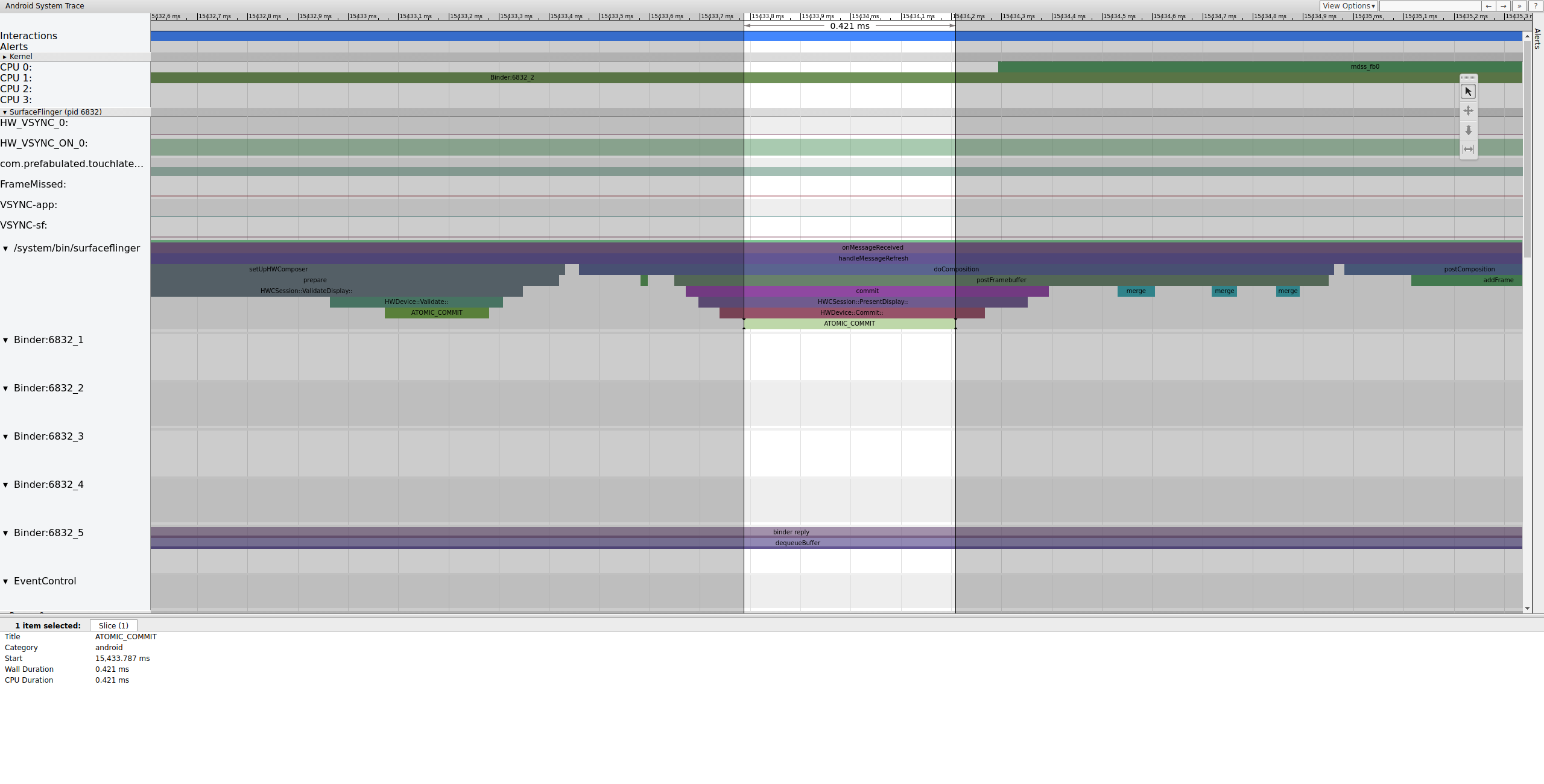
Figure 8. SurfaceFlinger configure la composition et envoie le frame final.
Ensuite, mdss_fb0 se réveille sur le processeur 0. mdss_fb0 est le thread de noyau du pipeline d'affichage pour la sortie d'un frame rendu sur l'écran.
Notez que mdss_fb0 se trouve sur sa propre ligne dans la trace (faites défiler la page vers le bas pour l'afficher) :
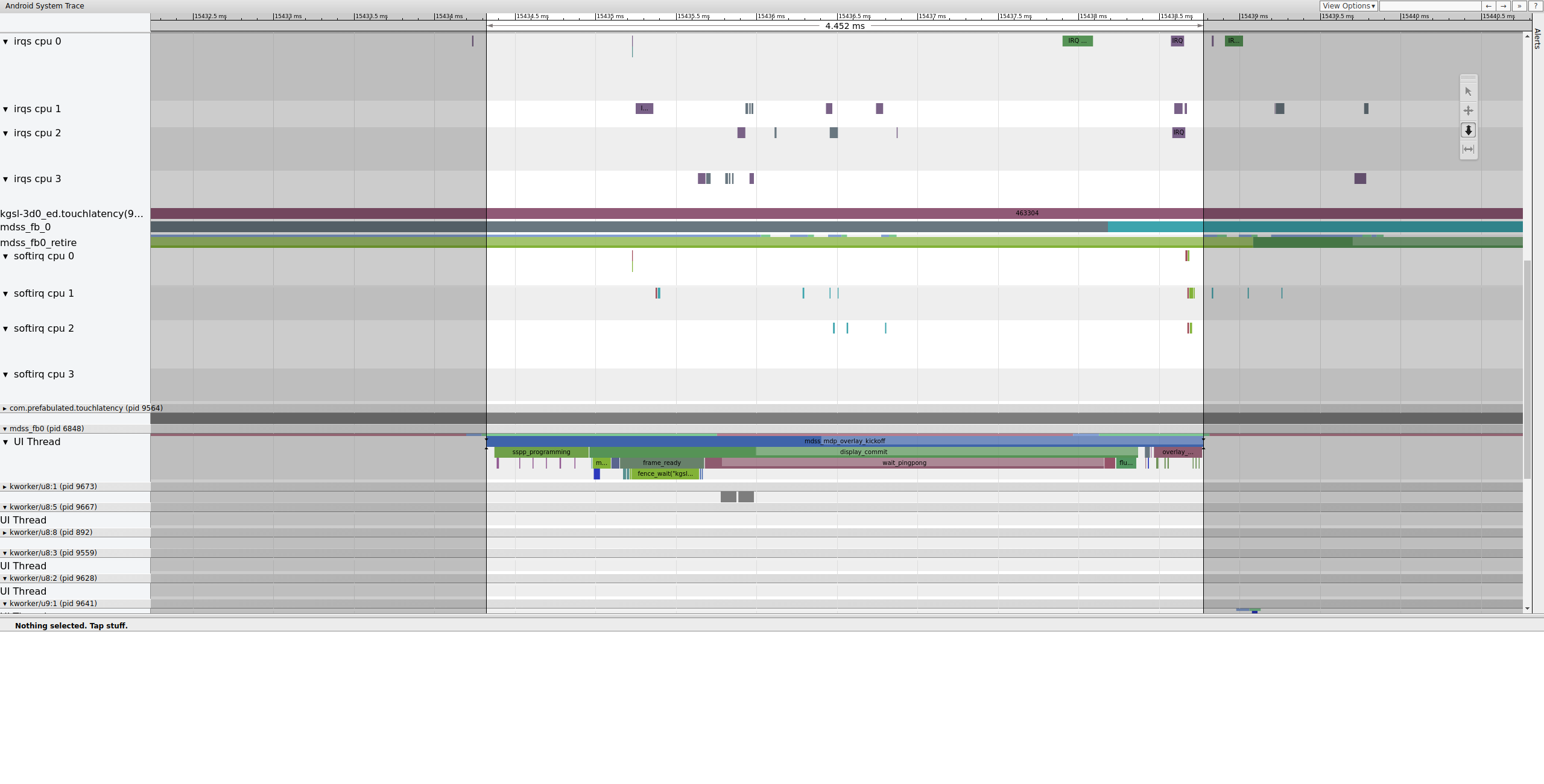
Figure 9.mdss_fb0 se réveille sur le CPU 0.
mdss_fb0 se réveille, s'exécute brièvement, entre en veille prolongée non interruptible, puis se réveille à nouveau.
Exemple : Cadre non fonctionnel
Cet exemple décrit une systrace utilisée pour déboguer le jitter sur Pixel ou Pixel XL. Pour suivre l'exemple, téléchargez le fichier ZIP des traces (qui inclut d'autres traces mentionnées dans cette section), décompressez le fichier et ouvrez le fichier systrace_tutorial.html dans votre navigateur.
Lorsque vous ouvrez systrace, un résultat semblable à celui de la figure suivante s'affiche :

Figure 10. TouchLatency exécuté sur un Pixel XL avec la plupart des options activées.
Dans la figure 10, la plupart des options sont activées, y compris les points de trace mdss et kgsl.
Lorsque vous recherchez des saccades, consultez la ligne "FrameMissed" sous SurfaceFlinger.
FrameMissed est une amélioration de la qualité de vie fournie par HWC2. Lorsque vous consultez systrace pour d'autres appareils, il est possible que la ligne "FrameMissed" ne soit pas présente si l'appareil n'utilise pas HWC2. Dans les deux cas, FrameMissed est corrélé à l'absence d'un des temps d'exécution réguliers de SurfaceFlinger et à un nombre de tampons en attente inchangé pour l'application (com.prefabulated.touchlatency) lors d'un VSync.

Figure 11 : Corrélation FrameMissed avec SurfaceFlinger.
La figure 11 montre un frame manqué à 15 598,29 ms. SurfaceFlinger s'est réveillé brièvement à l'intervalle VSync et s'est rendormi sans rien faire, ce qui signifie que SurfaceFlinger a déterminé qu'il n'était pas utile d'essayer d'envoyer à nouveau un frame à l'écran.
Pour comprendre pourquoi le pipeline s'est arrêté pour ce frame, commencez par examiner l'exemple de frame fonctionnel ci-dessus pour voir à quoi ressemble un pipeline d'UI normal dans systrace. Lorsque vous êtes prêt, revenez à la frame manquante et travaillez à rebours. Notez que SurfaceFlinger se réveille et se met immédiatement en veille. Lorsque vous consultez le nombre de frames en attente de TouchLatency, vous voyez qu'il y en a deux (un bon indice pour déterminer ce qui se passe).
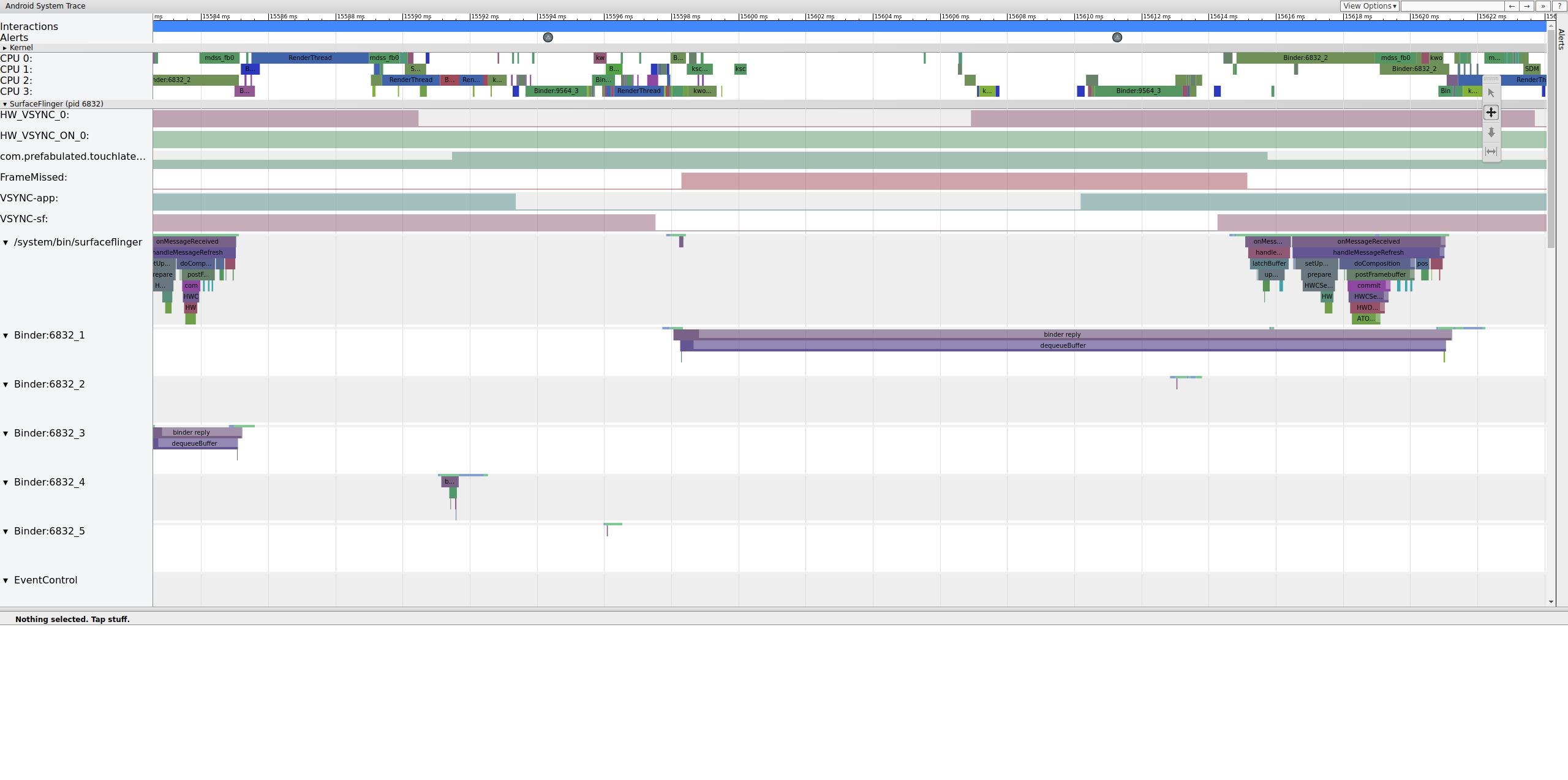
Figure 12. SurfaceFlinger se réveille et se met immédiatement en veille.
Comme il y a des frames dans SurfaceFlinger, il ne s'agit pas d'un problème lié à l'application. De plus, SurfaceFlinger se réveille au bon moment. Il ne s'agit donc pas d'un problème lié à SurfaceFlinger. Si SurfaceFlinger et l'application semblent fonctionner normalement, il s'agit probablement d'un problème de pilote.
Étant donné que les points de trace mdss et sync sont activés, vous pouvez obtenir des informations sur les clôtures (partagées entre le pilote d'affichage et SurfaceFlinger) qui contrôlent le moment où les frames sont envoyées à l'écran.
Ces clôtures sont listées sous mdss_fb0_retire, qui indique quand un frame est affiché. Ces clôtures sont fournies dans la catégorie de trace sync. Les clôtures qui correspondent à des événements spécifiques dans SurfaceFlinger dépendent de votre SOC et de votre pile de pilotes. Par conséquent, contactez votre fournisseur de SOC pour comprendre la signification des catégories de clôtures dans vos traces.
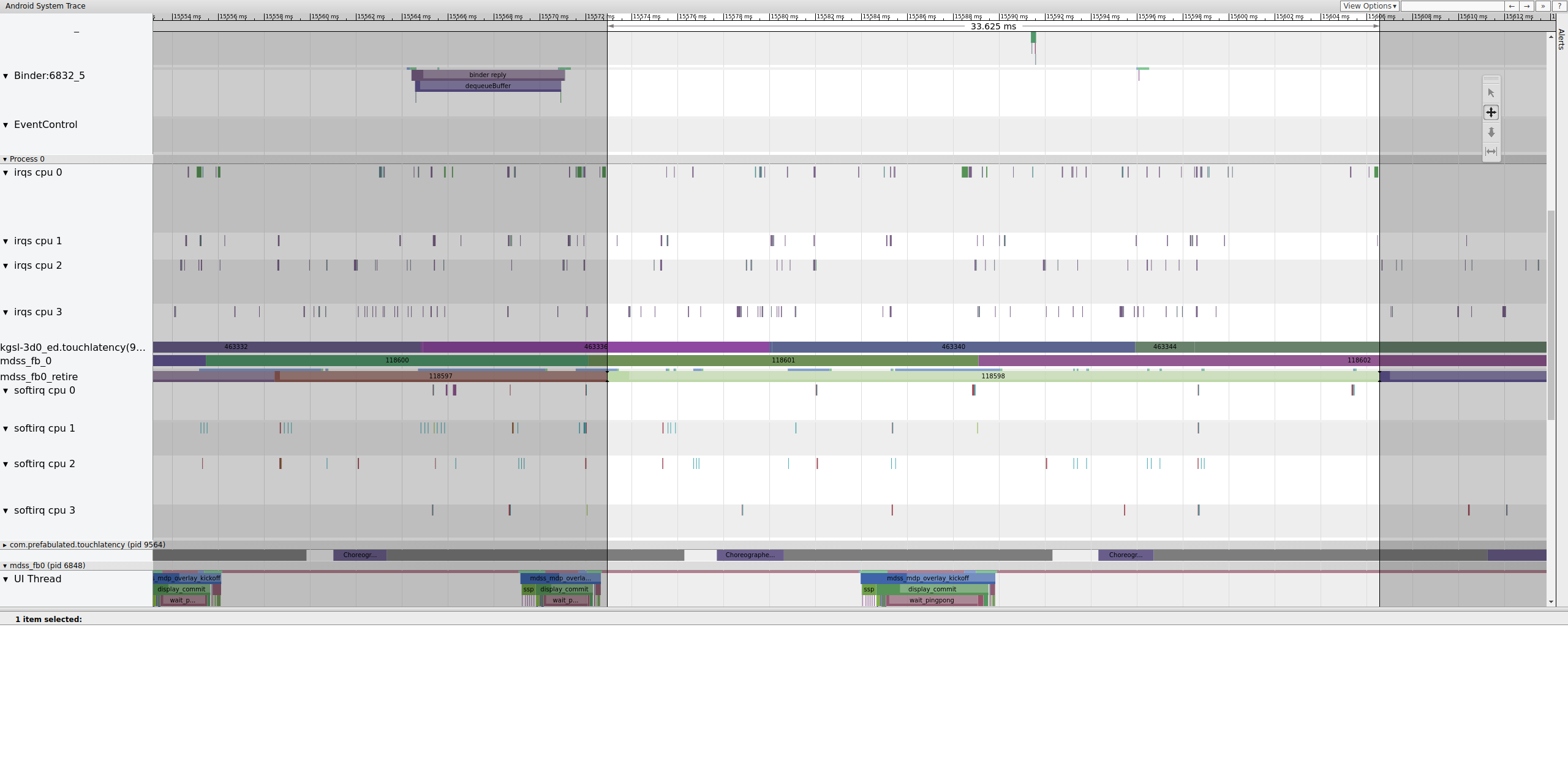
Figure 13 : mdss_fb0_retire fences.
La figure 13 montre un frame qui a été affiché pendant 33 ms, et non 16,7 ms comme prévu. À mi-chemin de cette tranche, ce frame aurait dû être remplacé par un nouveau, mais ce n'est pas le cas. Affichez l'image précédente et recherchez tout ce qui pourrait être suspect.
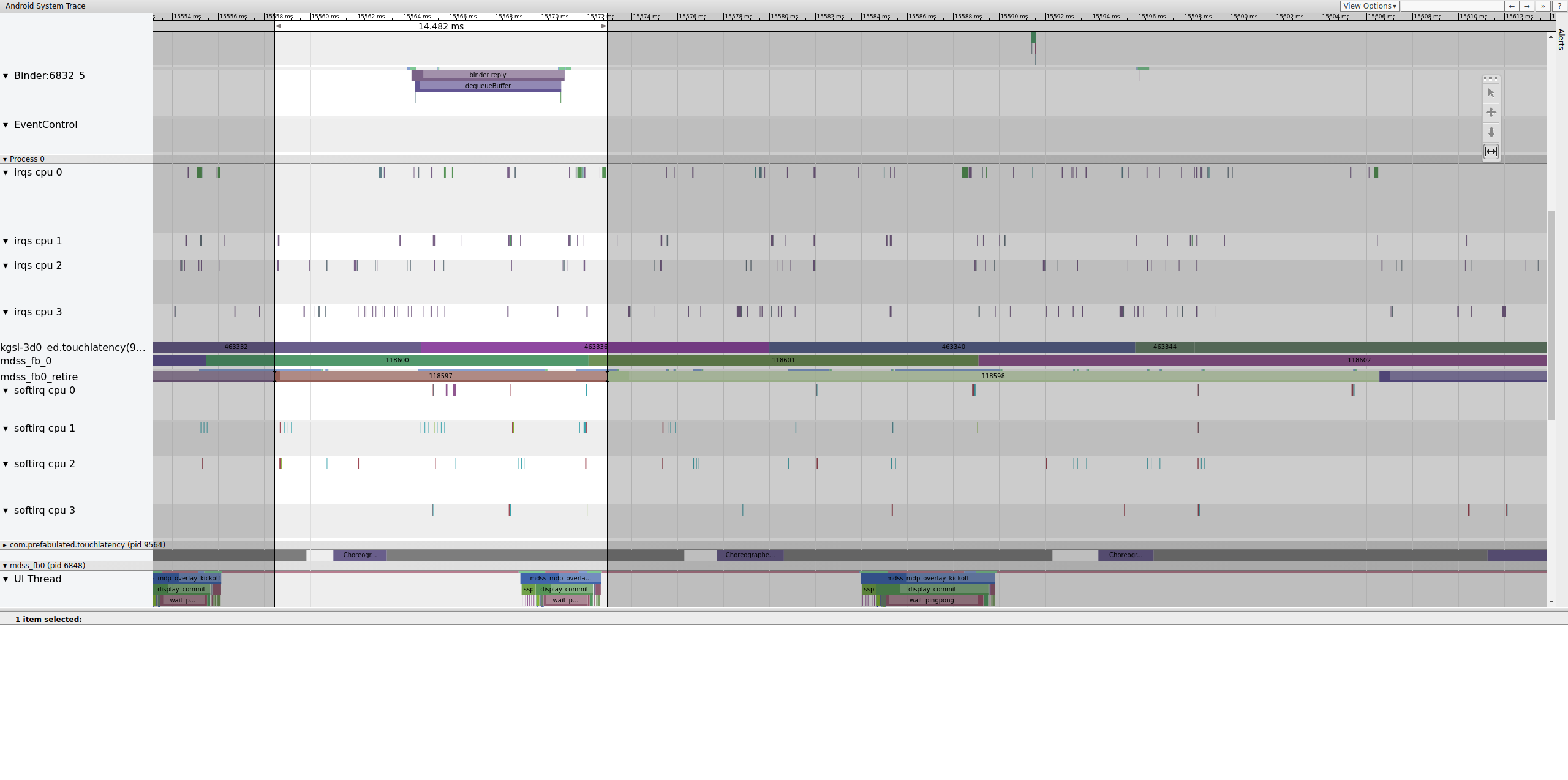
Figure 14. Image précédant l'image défectueuse.
La figure 14 montre un frame de 14,482 ms. Le segment de deux frames cassés était de 33,6 ms, ce qui correspond à peu près à ce qui est attendu pour deux frames (rendus à 60 Hz, 16,7 ms par frame, ce qui est proche). Toutefois, 14,482 ms n'est pas proche de 16,7 ms, ce qui suggère qu'il y a un problème avec le pipeline d'affichage.
Examinez précisément où se termine cette clôture pour déterminer ce qui la contrôle :
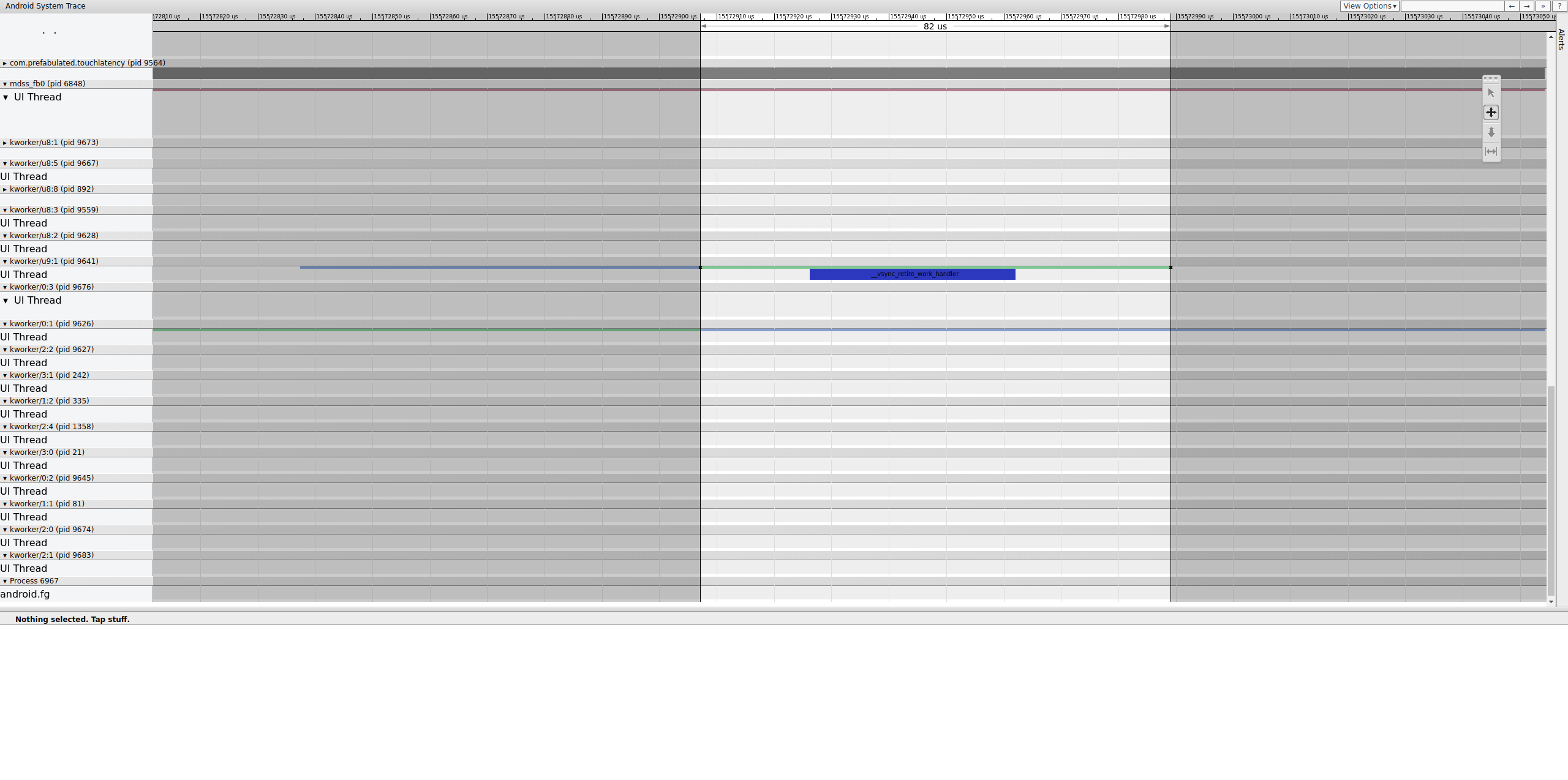
Figure 15. Examinez la fin de la clôture.
Une file d'attente de tâches contient __vsync_retire_work_handler, qui s'exécute lorsque la clôture change. En examinant la source du noyau, vous pouvez voir qu'il fait partie du pilote d'affichage. Il semble se trouver sur le chemin critique du pipeline d'affichage. Il doit donc s'exécuter le plus rapidement possible. Il peut s'exécuter pendant environ 70 μs (délai de planification non long), mais il s'agit d'une file de travail et il est possible qu'il ne soit pas planifié avec précision.
Vérifiez l'image précédente pour déterminer si elle a contribué au problème. Parfois, le jitter peut s'accumuler au fil du temps et finir par entraîner un dépassement du délai :
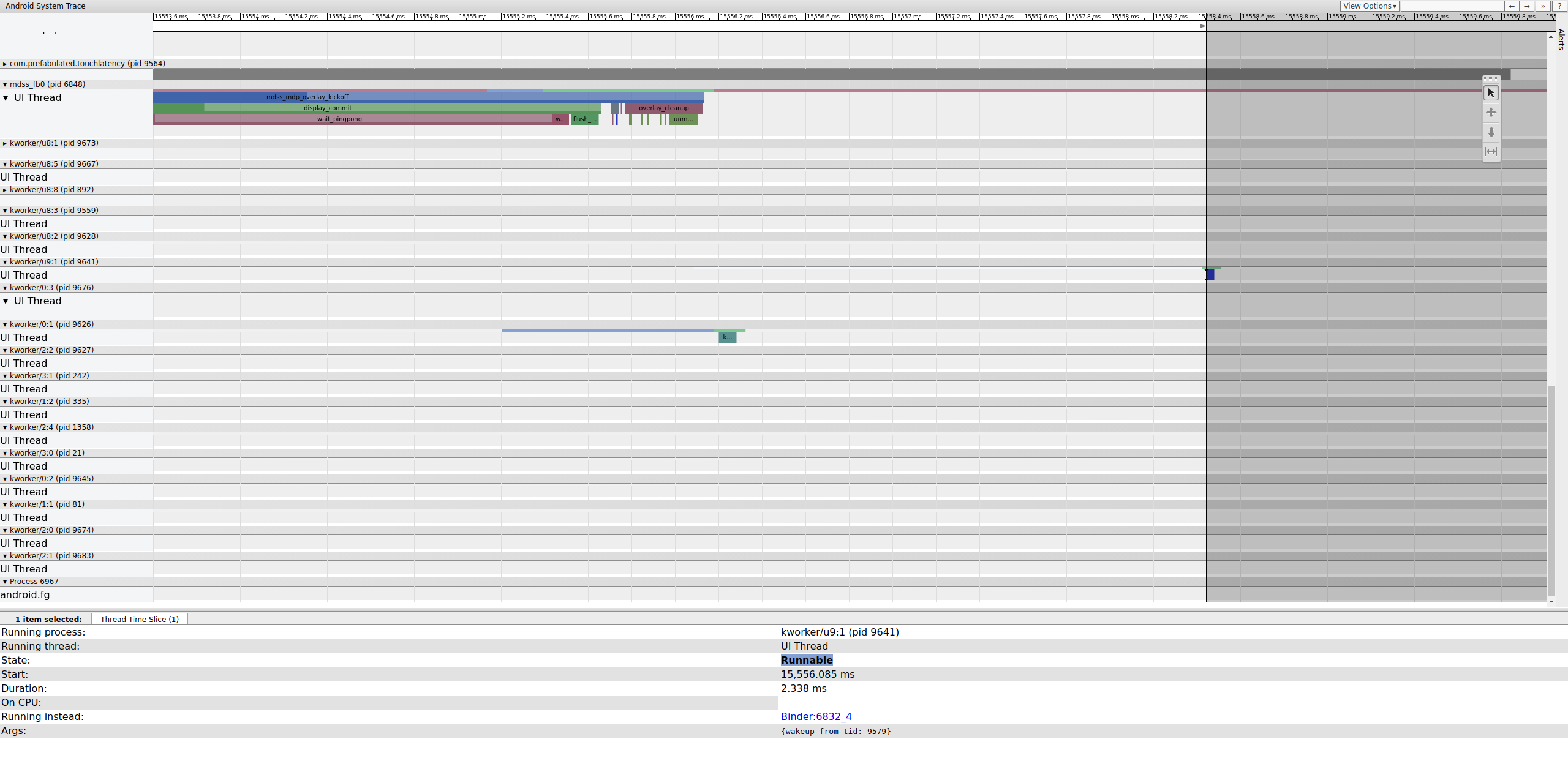
Figure 16. Image précédente.
La ligne exécutable sur le kworker n'est pas visible, car le lecteur la rend blanche lorsqu'elle est sélectionnée.Toutefois, les statistiques parlent d'elles-mêmes : un délai de planification de 2,3 ms pour une partie du chemin critique du pipeline d'affichage est mauvais.
Avant de continuer, corrigez le retard en déplaçant cette partie du chemin critique du pipeline d'affichage d'une file d'attente de travail (qui s'exécute en tant que thread CFS SCHED_OTHER) vers un kthread SCHED_FIFO dédié. Cette fonction a besoin de garanties de timing que les workqueues ne peuvent pas fournir (et ne sont pas censées fournir).
Il n'est pas certain que ce soit la raison du problème. En dehors des cas faciles à diagnostiquer, comme la contention de verrouillage du noyau qui provoque la mise en veille des threads essentiels à l'affichage, les traces ne spécifient généralement pas le problème. Ce jitter est peut-être à l'origine de la perte d'image. Les temps de clôture devraient être de 16,7 ms, mais ils sont loin de l'être dans les frames précédant le frame supprimé. Étant donné le couplage étroit du pipeline d'affichage, il est possible que le jitter autour des timings de clôture ait entraîné une perte d'image.
Dans cet exemple, la solution consiste à convertir __vsync_retire_work_handler d'une file d'attente de travail en kthread dédié. Cela permet d'améliorer considérablement le jitter et de réduire les saccades dans le test de la balle rebondissante. Les traces suivantes affichent des timings de clôture très proches de 16,7 ms.