
This page describes the data structures and methods used to efficiently communicate operand buffers between the driver and the framework.
At model compilation time, the framework provides the values of the constant operands to the driver. Depending on the lifetime of the constant operand, its values are located either in a HIDL vector or a shared memory pool.
- If the lifetime is
CONSTANT_COPY, the values are located in theoperandValuesfield of the model structure. Because the values in the HIDL vector are copied during interprocess communication (IPC), this is typically used only to hold a small amount of data such as scalar operands (for example, the activation scalar inADD) and small tensor parameters (for example, the shape tensor inRESHAPE). - If the lifetime is
CONSTANT_REFERENCE, the values are located in thepoolsfield of the model structure. Only the handles of the shared memory pools are duplicated during IPC rather than copying the raw values. Therefore, it's more efficient to hold a large amount of data (for example, the weight parameters in convolutions) using shared memory pools than HIDL vectors.
At model execution time, the framework provides the buffers of the input and output operands to the driver. Unlike the compile-time constants that might be sent in a HIDL vector, the input and output data of an execution is always communicated through a collection of memory pools.
The HIDL data type hidl_memory is used in both compilation and execution to
represent an unmapped shared memory pool. The driver should map the memory
accordingly to make it usable based on the name of the hidl_memory data type.
The supported memory names are:
ashmem: Android shared memory. For more details, see memory.mmap_fd: Shared memory backed by a file descriptor throughmmap.hardware_buffer_blob: Shared memory backed by a AHardwareBuffer with the formatAHARDWARE_BUFFER_FORMAT_BLOB. Available from Neural Networks (NN) HAL 1.2. For more details, see AHardwareBuffer.hardware_buffer: Shared memory backed by a general AHardwareBuffer that doesn't use the formatAHARDWARE_BUFFER_FORMAT_BLOB. The non-BLOB mode hardware buffer is only supported in model execution.Available from NN HAL 1.2. For more details, see AHardwareBuffer.
From NN HAL 1.3, NNAPI supports memory domains that provide allocator interfaces for driver-managed buffers. The driver-managed buffers can also be used as execution inputs or outputs. For more details, see Memory domains.
NNAPI drivers must support mapping of ashmem and mmap_fd memory names. From
NN HAL 1.3, drivers must also support mapping of hardware_buffer_blob. Support
for general non-BLOB mode hardware_buffer and memory domains is optional.
AHardwareBuffer
AHardwareBuffer is a type of shared memory that wraps a
Gralloc buffer. In Android
10, the Neural Networks API (NNAPI) supports using
AHardwareBuffer,
allowing the driver to perform executions without copying data, which improves
performance and power consumption for apps. For example, a camera HAL
stack can pass AHardwareBuffer objects to the NNAPI for machine learning
workloads using AHardwareBuffer handles generated by camera NDK and media NDK
APIs. For more information, see
ANeuralNetworksMemory_createFromAHardwareBuffer.
AHardwareBuffer objects used in NNAPI are passed to the driver through a
hidl_memory struct named either hardware_buffer or hardware_buffer_blob.
The hidl_memory struct hardware_buffer_blob represents only AHardwareBuffer
objects with the AHARDWAREBUFFER_FORMAT_BLOB format.
The information required by the framework is encoded in the hidl_handle field
of the hidl_memory struct. The hidl_handle field wraps native_handle,
which encodes all of the required metadata about AHardwareBuffer or Gralloc
buffer.
The driver must properly decode the provided hidl_handle field and access the
memory described by hidl_handle. When the getSupportedOperations_1_2,
getSupportedOperations_1_1, or getSupportedOperations method is
called, the driver should detect whether it can decode the provided
hidl_handle and access the memory described by hidl_handle. The model
preparation must fail if the hidl_handle field used for a constant operand
isn't supported. The execution must fail if the hidl_handle field used for an
input or output operand of the execution isn't supported. It's recommended
for the driver to return a GENERAL_FAILURE error code if the model preparation
or execution fails.
Memory domains
For devices running Android 11 or higher, NNAPI supports memory domains that provide allocator interfaces for driver-managed buffers. This allows for passing device native memories across executions, suppressing unnecessary data copying and transformation between consecutive executions on the same driver. This flow is illustrated in Figure 1.
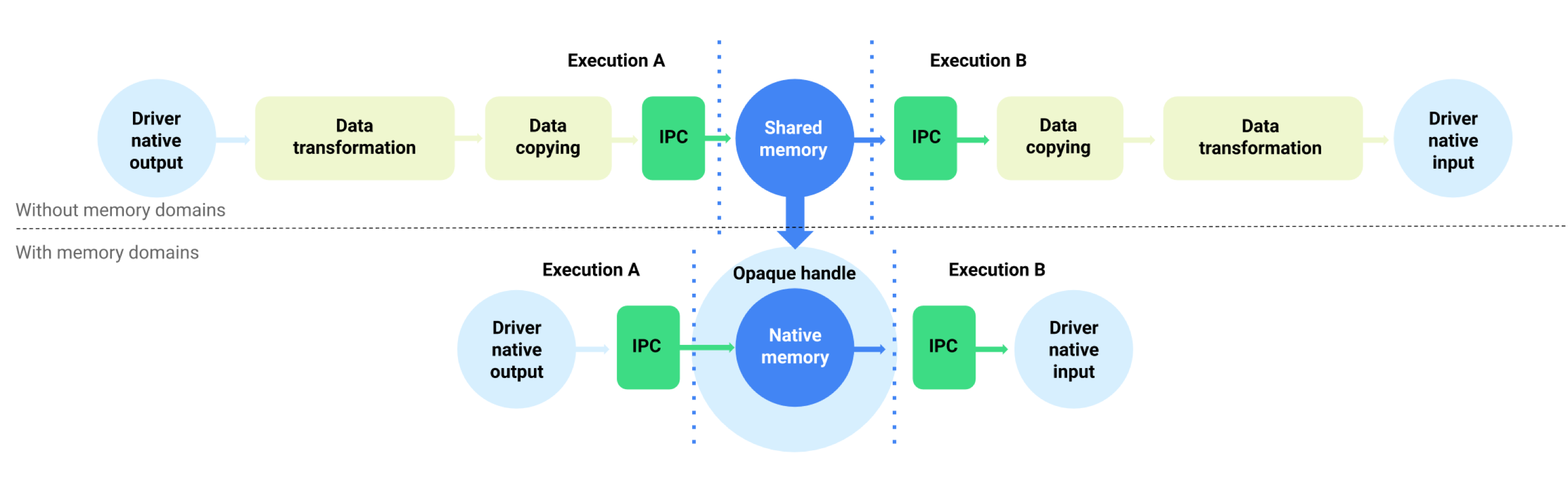
Figure 1. Buffer data flow using memory domains
The memory domain feature is intended for tensors that are mostly internal to the driver and don't need frequent access on the client side. Examples of such tensors include the state tensors in sequence models. For tensors that need frequent CPU access on the client side, it's preferable to use shared memory pools.
To support the memory domain feature, implement
IDevice::allocate
to allow the framework to request for driver-managed buffer allocation. During
the allocation, the framework provides the following properties and usage
patterns for the buffer:
BufferDescdescribes the required properties of the buffer.BufferRoledescribes the potential usage pattern of the buffer as an input or output of a prepared model. Multiple roles can be specified during the buffer allocation, and the allocated buffer can be used only as those specified roles.
The allocated buffer is internal to the driver. A driver can choose any buffer
location or data layout. When the buffer is successfully allocated,
the client of the driver can reference or interact with the buffer using the
returned token or the IBuffer object.
The token from IDevice::allocate is provided when referencing the buffer as
one of the
MemoryPool
objects in the
Request
structure of an execution. To prevent a process from trying to access the buffer
allocated in another process, the driver must apply proper validation upon every
use of the buffer. The driver must validate that the buffer usage is one of the
BufferRole roles provided during the allocation and must fail the execution
immediately if the usage is illegal.
The
IBuffer
object is used for explicit memory copying. In certain situations, the client of
the driver must initialize the driver-managed buffer from a shared memory pool
or copy the buffer out to a shared memory pool. Example use cases include:
- Initialization of the state tensor
- Caching intermediate results
- Fallback execution on CPU
To support these use cases, the driver must implement
IBuffer::copyTo
and
IBuffer::copyFrom
with ashmem, mmap_fd, and hardware_buffer_blob if it supports memory
domain allocation. It's optional for the driver to support non-BLOB mode
hardware_buffer.
During buffer allocation, the dimensions of the buffer can be deduced from the
corresponding model operands of all the roles specified by BufferRole, and the
dimensions provided in BufferDesc. With all the dimensional information
combined, the buffer might have unknown dimensions or rank. In such a
case, the buffer is in a flexible state where the dimensions are fixed when used
as a model input and in a dynamic state when used as a model output. The same
buffer can be used with different shapes of outputs in different executions and
the driver must handle the buffer resizing properly.
Memory domain is an optional feature. A driver can determine that it can't support a given allocation request for a number of reasons. For example:
- The requested buffer has a dynamic size.
- The driver has memory constraints preventing it from handling large buffers.
It's possible for several different threads to read from the driver-managed buffer concurrently. Accessing the buffer simultaneously for write or read/write is undefined, but it must not crash the driver service or block the caller indefinitely. The driver can return an error or leave the buffer's content in an indeterminate state.