
Na tej stronie znajdziesz omówienie sposobu wdrażania sterownika interfejsu Neural Networks API (NNAPI). Więcej informacji znajdziesz w dokumentacji w plikach definicji HAL w hardware/interfaces/neuralnetworks.
Przykładowa implementacja sterownika znajduje się w pliku frameworks/ml/nn/driver/sample.
Więcej informacji o interfejsie Neural Networks API znajdziesz w artykule Neural Networks API.
Warstwa HAL sieci neuronowych
Warstwa HAL sieci neuronowych (NN) definiuje abstrakcję różnych urządzeń, takich jak procesory graficzne (GPU) i procesory sygnałowe (DSP), które znajdują się w produkcie (np. telefonie lub tablecie). Sterowniki tych urządzeń muszą być zgodne z NN HAL. Interfejs jest określony w plikach definicji HAL w hardware/interfaces/neuralnetworks.
Ogólny przepływ interfejsu między platformą a sterownikiem przedstawiono na rysunku 1.
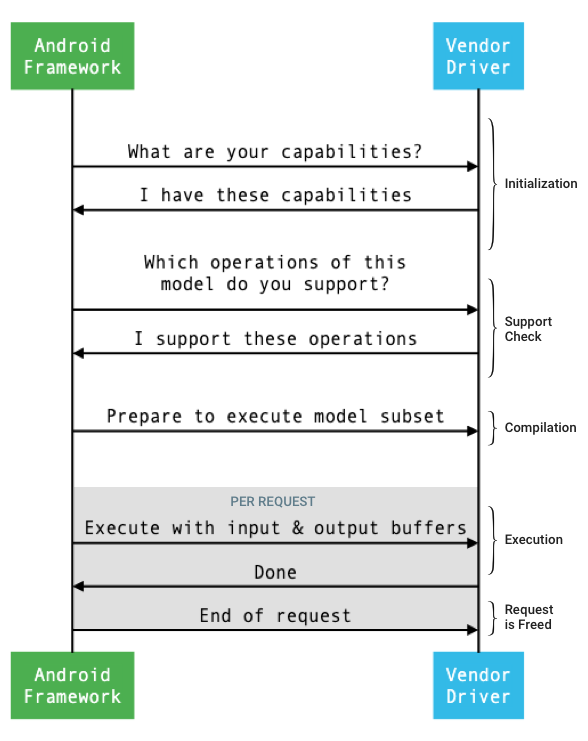
Rysunek 1. Przepływ sieci neuronowych
Inicjowanie
Podczas inicjowania platforma wysyła do sterownika zapytanie o jego możliwości za pomocą funkcji IDevice::getCapabilities_1_3.
Struktura @1.3::Capabilities obejmuje wszystkie typy danych i reprezentuje nieograniczone działanie za pomocą wektora.
Aby określić, jak rozdzielić obliczenia między dostępne urządzenia, platforma korzysta z informacji o możliwościach, aby dowiedzieć się, jak szybko i jak energooszczędnie każdy sterownik może wykonać zadanie. Aby podać te informacje, sterownik musi udostępniać standardowe wartości wydajności na podstawie wykonania referencyjnych zadań.
Aby określić wartości, które sterownik zwraca w odpowiedzi na
IDevice::getCapabilities_1_3, użyj aplikacji testowej NNAPI do pomiaru wydajności w przypadku odpowiednich typów danych. Do pomiaru wydajności w przypadku 32-bitowych wartości zmiennoprzecinkowych zalecane są modele MobileNet w wersjach 1 i 2, asr_float oraz tts_float, a do 8-bitowych wartości skwantyzowanych – modele MobileNet w wersjach 1 i 2. Więcej informacji znajdziesz w artykule Android Machine Learning Test Suite.
W Androidzie 9 i starszych wersjach struktura Capabilities zawiera informacje o wydajności sterownika tylko w przypadku tensorów zmiennoprzecinkowych i skwantyzowanych, a nie zawiera typów danych skalarnych.
W ramach procesu inicjowania platforma może wysyłać zapytania o dodatkowe informacje za pomocą funkcji IDevice::getType, IDevice::getVersionString, IDevice:getSupportedExtensions i IDevice::getNumberOfCacheFilesNeeded.
Między ponownymi uruchomieniami produktu platforma oczekuje, że wszystkie zapytania opisane w tej sekcji będą zawsze zwracać te same wartości dla danego sterownika. W przeciwnym razie aplikacja korzystająca z tego sterownika może działać wolniej lub nieprawidłowo.
Kompilacja
Gdy platforma otrzyma żądanie z aplikacji, określa, których urządzeń użyć. W Androidzie 10 aplikacje mogą wykrywać i określać urządzenia, z których platforma wybiera te, których użyje. Więcej informacji znajdziesz w artykule Wykrywanie i przypisywanie urządzeń.
Podczas kompilacji modelu platforma wysyła go do każdego potencjalnego sterownika, wywołując funkcję IDevice::getSupportedOperations_1_3.
Każdy sterownik zwraca tablicę wartości logicznych wskazujących, które operacje modelu są obsługiwane. Sterownik może stwierdzić, że nie może obsługiwać danej operacji z kilku powodów. Przykład:
- Sterownik nie obsługuje tego typu danych.
- Sterownik obsługuje tylko operacje z określonymi parametrami wejściowymi. Na przykład sterownik może obsługiwać operacje splotu 3x3 i 5x5, ale nie 7x7.
- Sterownik ma ograniczenia pamięci, które uniemożliwiają mu obsługę dużych wykresów lub danych wejściowych.
Podczas kompilacji dane wejściowe, wyjściowe i wewnętrzne operandy modelu, zgodnie z opisem w OperandLifeTime, mogą mieć nieznane wymiary lub rangę. Więcej informacji znajdziesz w artykule Kształt danych wyjściowych.
Framework instruuje każdego wybranego sterownika, aby przygotował się do wykonania podzbioru modelu, wywołując funkcję IDevice::prepareModel_1_3.
Każdy sterownik kompiluje swój podzbiór. Na przykład sterownik może wygenerować kod lub utworzyć kopię wag w innej kolejności. Między kompilacją modelu a wykonywaniem żądań może upłynąć sporo czasu, dlatego podczas kompilacji nie należy przydzielać zasobów takich jak duże fragmenty pamięci urządzenia.
Jeśli operacja się powiedzie, sterownik zwraca uchwyt@1.3::IPreparedModel. Jeśli sterownik zwróci kod błędu podczas przygotowywania podzbioru modelu, platforma uruchomi cały model na procesorze.
Aby skrócić czas kompilacji podczas uruchamiania aplikacji, sterownik może buforować artefakty kompilacji. Więcej informacji znajdziesz w sekcji Kompilacja pamięci podręcznej.
Wykonanie
Gdy aplikacja poprosi platformę o wykonanie żądania, platforma domyślnie wywoła metodę HAL IPreparedModel::executeSynchronously_1_3, aby wykonać synchroniczne działanie na przygotowanym modelu.
Żądanie można też wykonać asynchronicznie za pomocą metody
execute_1_3
lub metody
executeFenced (patrz Wykonanie w izolacji) albo za pomocą wykonania w serii.
Wywołania synchroniczne zwiększają wydajność i ograniczają narzut związany z wątkami w porównaniu z wywołaniami asynchronicznymi, ponieważ kontrola jest zwracana do procesu aplikacji dopiero po zakończeniu wykonania. Oznacza to, że sterownik nie potrzebuje osobnego mechanizmu, aby powiadomić proces aplikacji o zakończeniu wykonania.
W przypadku metody asynchronicznej execute_1_3 kontrola wraca do procesu aplikacji po rozpoczęciu wykonania, a sterownik musi powiadomić platformę o zakończeniu wykonania za pomocą metody @1.3::IExecutionCallback.
Parametr Request przekazywany do metody execute zawiera listę operandów wejściowych i wyjściowych używanych podczas wykonywania. Pamięć, w której przechowywane są dane operandu, musi używać kolejności wierszowej, w której pierwszy wymiar jest iterowany najwolniej, i nie może zawierać dopełnienia na końcu żadnego wiersza. Więcej informacji o rodzajach operandów znajdziesz w sekcji Operandy.
W przypadku sterowników NN HAL w wersji 1.2 lub nowszej po zakończeniu żądania do platformy zwracany jest stan błędu, kształt danych wyjściowych i informacje o czasie. Podczas wykonywania dane wyjściowe lub wewnętrzne operandy modelu mogą mieć co najmniej 1 nieznany wymiar lub nieznaną rangę. Jeśli co najmniej 1 operand wyjściowy ma nieznany wymiar lub rangę, sterownik musi zwrócić informacje o dynamicznie określonym rozmiarze danych wyjściowych.
W przypadku sterowników z NN HAL w wersji 1.1 lub starszej po zakończeniu żądania zwracany jest tylko stan błędu. Aby wykonanie zakończyło się pomyślnie, wymiary operandów wejściowych i wyjściowych muszą być w pełni określone. Operandy wewnętrzne mogą mieć co najmniej 1 nieznany wymiar, ale muszą mieć określony stopień.
W przypadku żądań użytkowników obejmujących wiele sterowników platforma jest odpowiedzialna za rezerwowanie pamięci pośredniej i sekwencjonowanie wywołań poszczególnych sterowników.
W ramach tego samego @1.3::IPreparedModel można równolegle inicjować wiele żądań.
Sterownik może wykonywać żądania równolegle lub szeregowo.
Platforma może poprosić sterownik o przechowywanie więcej niż 1 przygotowanego modelu. Przygotuj na przykład model m1, przygotuj m2, wykonaj żądanie r1 na m1, wykonaj r2 na m2, wykonaj r3 na m1, wykonaj r4 na m2, zwolnij (opisane w sekcji Czyszczenie) m1 i zwolnij m2.
Aby uniknąć powolnego pierwszego wykonania, które mogłoby pogorszyć komfort użytkownika (np. zacięcie pierwszej klatki), sterownik powinien przeprowadzić większość inicjalizacji w fazie kompilacji. Inicjowanie przy pierwszym wykonaniu powinno być ograniczone do działań, które negatywnie wpływają na stan systemu, jeśli są wykonywane wcześnie, np. rezerwowanie dużych buforów tymczasowych lub zwiększanie częstotliwości zegara urządzenia. Sterowniki, które mogą przygotować tylko ograniczoną liczbę modeli równoległych, mogą wymagać inicjowania przy pierwszym wykonaniu.
W Androidzie 10 lub nowszym, w przypadku gdy kilka wykonań tego samego przygotowanego modelu jest wykonywanych w szybkiej kolejności, klient może użyć obiektu serii wykonań do komunikacji między procesami aplikacji i sterownika. Więcej informacji znajdziesz w artykule Wykonywanie serii zadań i szybkie kolejki wiadomości.
Aby poprawić wydajność w przypadku wielu wykonań w szybkiej kolejności, sterownik może przechowywać tymczasowe bufory lub zwiększać częstotliwość taktowania. Zalecamy utworzenie wątku nadzorującego, który będzie zwalniać zasoby, jeśli po upływie określonego czasu nie zostaną utworzone żadne nowe żądania.
Kształt wyjściowy
W przypadku żądań, w których co najmniej 1 operand wyjściowy nie ma określonych wszystkich wymiarów, sterownik musi po wykonaniu podać listę kształtów wyjściowych zawierającą informacje o wymiarach każdego operandu wyjściowego. Więcej informacji o wymiarach znajdziesz w sekcji OutputShape.
Jeśli wykonanie nie powiedzie się z powodu zbyt małego bufora wyjściowego, sterownik musi wskazać, które operandy wyjściowe mają niewystarczający rozmiar bufora, w liście kształtów wyjściowych i powinien podać jak najwięcej informacji o wymiarach, używając zera w przypadku nieznanych wymiarów.
Czas
W Androidzie 10 aplikacja może poprosić o czas wykonania, jeśli podczas procesu kompilacji określiła jedno urządzenie, którego ma używać. Szczegółowe informacje znajdziesz w sekcjach MeasureTiming i Wykrywanie i przypisywanie urządzeń.
W takim przypadku sterownik NN HAL 1.2 musi mierzyć czas trwania wykonania lub zgłaszać wartość UINT64_MAX (aby wskazać, że czas trwania jest niedostępny) podczas wykonywania żądania. Sterownik powinien zminimalizować wszelkie spadki wydajności wynikające z pomiaru czasu trwania wykonania.
Sterownik raportuje te czasy w mikrosekundach w strukturze Timing:
- Czas wykonania na urządzeniu: nie obejmuje czasu wykonania w sterowniku, który działa na procesorze hosta.
- Czas wykonania w sterowniku: obejmuje czas wykonania na urządzeniu.
Te okresy muszą obejmować czas, w którym wykonywanie jest zawieszone, np. gdy zostało wywłaszczone przez inne zadania lub gdy czeka na udostępnienie zasobu.
Jeśli kierowca nie został poproszony o zmierzenie czasu trwania wykonania lub jeśli wystąpił błąd wykonania, musi zgłosić czas trwania jako UINT64_MAX. Nawet jeśli sterownik został poproszony o pomiar czasu wykonania, może zamiast tego zgłosić UINT64_MAX w przypadku czasu na urządzeniu, czasu w sterowniku lub obu tych wartości. Jeśli sterownik zgłasza oba czasy trwania jako wartość inną niż UINT64_MAX, czas wykonania w sterowniku musi być równy lub dłuższy niż czas na urządzeniu.
Wykonanie w izolacji
W Androidzie 11 interfejs NNAPI umożliwia oczekiwanie na listę uchwytów sync_fence i opcjonalne zwracanie obiektu sync_fence, który jest sygnalizowany po zakończeniu wykonania. Zmniejsza to obciążenie w przypadku modeli krótkich sekwencji i przypadków użycia związanych z przesyłaniem strumieniowym. Wykonanie w izolacji umożliwia też bardziej wydajną interoperacyjność z innymi komponentami, które mogą sygnalizować lub oczekiwać na sync_fence. Więcej informacji o sync_fence znajdziesz w artykule Platforma synchronizacji.
W przypadku wykonania w izolacji platforma wywołuje metodę
IPreparedModel::executeFenced
w celu uruchomienia w izolacji wykonania asynchronicznego na przygotowanym modelu z wektorem barier synchronizacji, na które trzeba poczekać. Jeśli zadanie asynchroniczne zostanie ukończone przed zwróceniem wywołania, dla sync_fence można zwrócić pusty uchwyt. Należy też zwrócić obiekt IFencedExecutionCallback, aby umożliwić platformie sprawdzanie stanu błędu i informacji o czasie trwania.
Po zakończeniu wykonania można za pomocą IFencedExecutionCallback::getExecutionInfo odpytywać o te 2 wartości czasowe, które mierzą czas trwania wykonania:
timingLaunched: czas od wywołania funkcjiexecuteFenceddo momentu, w którym funkcjaexecuteFencedsygnalizuje zwrócony obiektsyncFence.timingFenced: czas od momentu, w którym wszystkie bariery synchronizacji, na które czeka wykonanie, zostaną zasygnalizowane, do momentu, w którymexecuteFencedzasygnalizuje zwrócony elementsyncFence.
Kontrola przepływu
W przypadku urządzeń z Androidem 11 lub nowszym interfejs NNAPI zawiera 2 operacje sterowania przepływem: IF i WHILE. Przyjmują one inne modele jako argumenty i wykonują je warunkowo (IF) lub wielokrotnie (WHILE). Więcej informacji o tym, jak to wdrożyć, znajdziesz w sekcji Sterowanie przepływem.
Jakość usługi
W Androidzie 11 interfejs NNAPI obejmuje ulepszoną jakość usług (QoS), ponieważ umożliwia aplikacji określanie względnych priorytetów modeli, maksymalnego czasu oczekiwania na przygotowanie modelu i maksymalnego czasu oczekiwania na zakończenie wykonania. Więcej informacji znajdziesz w sekcji Jakość usługi.
Czyszczenie
Gdy aplikacja skończy korzystać z przygotowanego modelu, platforma zwalnia odniesienie do obiektu @1.3::IPreparedModel. Gdy obiekt IPreparedModel nie jest już używany, jest automatycznie usuwany w usłudze sterownika, która go utworzyła. Zasoby specyficzne dla modelu można w tym momencie odzyskać w implementacji destruktora sterownika. Jeśli usługa sterownika chce, aby obiekt IPreparedModel był automatycznie niszczony, gdy klient nie będzie go już potrzebować, nie może przechowywać żadnych odwołań do obiektu IPreparedModel po zwróceniu obiektu IPreparedeModel za pomocą IPreparedModelCallback::notify_1_3.
Wykorzystanie procesora
Sterowniki powinny używać procesora do konfigurowania obliczeń. Sterowniki nie powinny używać procesora do obliczeń grafów, ponieważ zakłóca to prawidłowe przydzielanie zadań przez platformę. Sterownik powinien zgłaszać platformie części, których nie może obsłużyć, i pozwalać jej na obsługę pozostałych.
Platforma zapewnia implementację na procesorze wszystkich operacji NNAPI z wyjątkiem operacji zdefiniowanych przez dostawcę. Więcej informacji znajdziesz w sekcji Rozszerzenia dostawców.
Operacje wprowadzone w Androidzie 10 (poziom interfejsu API 29) mają tylko referencyjną implementację na procesorze, która służy do weryfikacji poprawności testów CTS i VTS. Zoptymalizowane implementacje zawarte w platformach uczenia maszynowego na urządzeniach mobilnych są preferowane w stosunku do implementacji NNAPI na CPU.
Funkcje narzędziowe
Baza kodu NNAPI zawiera funkcje narzędziowe, które mogą być używane przez usługi sterowników.
Plik
frameworks/ml/nn/common/include/Utils.h
zawiera różne funkcje narzędziowe, takie jak funkcje używane do rejestrowania i konwertowania między różnymi wersjami NN HAL.
VLogging:
VLOGto makro opakowujące funkcjęLOGna Androidzie, które rejestruje wiadomość tylko wtedy, gdy w właściwościdebug.nn.vlogustawiony jest odpowiedni tag.initVLogMask()musi zostać wywołana przed wywołaniem funkcjiVLOG. MakroVLOG_IS_ONmoże służyć do sprawdzania, czy funkcjaVLOGjest obecnie włączona. Umożliwia to pomijanie skomplikowanego kodu rejestrowania, jeśli nie jest on potrzebny. Wartość właściwości musi być jedną z tych wartości:- Pusty ciąg znaków, co oznacza, że nie należy rejestrować żadnych informacji.
- Token
1luball, który oznacza, że należy rejestrować wszystkie zdarzenia. - Lista tagów rozdzielonych spacjami, przecinkami lub dwukropkami, która wskazuje, jakie logowanie ma być wykonywane. Tagi to
compilation,cpuexe,driver,execution,managerimodel.
compliantWithV1_*: zwraca wartośćtrue, jeśli obiekt NN HAL można przekonwertować na ten sam typ innej wersji HAL bez utraty informacji. Na przykład wywołaniecompliantWithV1_0naV1_2::Modelzwracafalse, jeśli model zawiera typy operacji wprowadzone w NN HAL 1.1 lub NN HAL 1.2.convertToV1_*: konwertuje obiekt NN HAL z jednej wersji na inną. Jeśli konwersja spowoduje utratę informacji (tzn. nowa wersja typu nie może w pełni reprezentować wartości), zostanie zarejestrowane ostrzeżenie.Możliwości: funkcje
nonExtensionOperandPerformanceiupdatemogą pomóc w tworzeniu polaCapabilities::operandPerformance.Właściwości zapytań o typy:
isExtensionOperandType,isExtensionOperationType,nonExtensionSizeOfData,nonExtensionOperandSizeOfData,nonExtensionOperandTypeIsScalar,tensorHasUnspecifiedDimensions.
Plik frameworks/ml/nn/common/include/ValidateHal.h zawiera funkcje narzędziowe do sprawdzania, czy obiekt NN HAL jest prawidłowy zgodnie ze specyfikacją wersji HAL.
validate*: zwraca wartośćtrue, jeśli obiekt NN HAL jest prawidłowy zgodnie ze specyfikacją wersji HAL. Typy OEM i typy rozszerzeń nie są weryfikowane. Na przykładvalidateModelzwracafalse, jeśli model zawiera operację, która odwołuje się do indeksu operandu, który nie istnieje, lub operację, która nie jest obsługiwana w danej wersji HAL.
Plik
frameworks/ml/nn/common/include/Tracing.h
zawiera makra, które ułatwiają dodawanie informacji o systracingu do kodu sieci neuronowych.
Przykład znajdziesz w NNTRACE_* wywołaniach makr w przykładowym sterowniku.
Plik frameworks/ml/nn/common/include/GraphDump.h zawiera funkcję użytkową do zrzucania zawartości Model w formie graficznej na potrzeby debugowania.
graphDump: zapisuje reprezentację modelu w formacie Graphviz.dotw określonym strumieniu (jeśli jest podany) lub w logcat (jeśli nie podano strumienia).
Weryfikacja
Aby przetestować implementację NNAPI, użyj testów VTS i CTS zawartych w platformie Androida. VTS testuje sterowniki bezpośrednio (bez użycia platformy), a CTS testuje je pośrednio za pomocą platformy. Testy te sprawdzają każdą metodę interfejsu API i weryfikują, czy wszystkie operacje obsługiwane przez sterowniki działają prawidłowo i dają wyniki spełniające wymagania dotyczące precyzji.
Wymagania dotyczące precyzji w testach CTS i VTS dla interfejsu NNAPI są następujące:
Reprezentacja zmiennoprzecinkowa: abs(oczekiwana – rzeczywista) <= atol + rtol * abs(oczekiwana); gdzie:
- W przypadku fp32 atol = 1e-5f, rtol = 5.0f * 1.1920928955078125e-7
- W przypadku fp16: atol = rtol = 5.0f * 0.0009765625f
Skwantyzowane: różnica o 1 (z wyjątkiem
mobilenet_quantized, gdzie różnica wynosi 3)Wartość logiczna: dopasowanie ścisłe
Jednym ze sposobów testowania NNAPI w ramach CTS jest generowanie stałych pseudolosowych grafów
używanych do testowania i porównywania wyników wykonania każdego sterownika z
referencyjną implementacją NNAPI. W przypadku sterowników z NN HAL w wersji 1.2 lub nowszej, jeśli wyniki nie spełniają kryteriów precyzji, CTS zgłasza błąd i zrzuca plik specyfikacji nieudanego modelu w folderze /data/local/tmp na potrzeby debugowania.
Więcej informacji o kryteriach precyzji znajdziesz w sekcjach TestRandomGraph.cpp i TestHarness.h.
Testowanie losowe
Testy fuzzingowe mają na celu wykrywanie awarii, asercji, naruszeń pamięci lub ogólnego niezdefiniowanego zachowania w testowanym kodzie z powodu takich czynników jak nieoczekiwane dane wejściowe. Do testowania NNAPI Android używa testów opartych na bibliotece libFuzzer, które są skuteczne w testowaniu, ponieważ wykorzystują pokrycie wierszy poprzednich przypadków testowych do generowania nowych losowych danych wejściowych. Na przykład libFuzzer preferuje przypadki testowe, które działają w nowych wierszach kodu. Znacznie skraca to czas potrzebny testom na znalezienie problematycznego kodu.
Aby przeprowadzić testowanie fuzzingowe w celu sprawdzenia implementacji sterownika, zmodyfikuj
frameworks/ml/nn/runtime/test/android_fuzzing/DriverFuzzTest.cpp
w narzędziu testowym libneuralnetworks_driver_fuzzer znajdującym się w AOSP, aby uwzględnić
kod sterownika. Więcej informacji o testowaniu NNAPI znajdziesz w frameworks/ml/nn/runtime/test/android_fuzzing/README.md.
Bezpieczeństwo
Ponieważ procesy aplikacji komunikują się bezpośrednio z procesem kierowcy, kierowcy muszą weryfikować argumenty otrzymywanych wywołań. Ta weryfikacja jest sprawdzana przez VTS. Kod weryfikacyjny znajdziesz w wiadomości wysłanej na adres frameworks/ml/nn/common/include/ValidateHal.h.
Kierowcy powinni też zadbać o to, aby aplikacje nie zakłócały działania innych aplikacji na tym samym urządzeniu.
Android Machine Learning Test Suite
Android Machine Learning Test Suite (MLTS) to test NNAPI uwzględniony w CTS i VTS, który służy do weryfikowania dokładności rzeczywistych modeli na urządzeniach dostawców. Test porównawczy ocenia opóźnienie i dokładność oraz porównuje wyniki sterowników z wynikami uzyskanymi przy użyciu TF Lite działającego na procesorze w przypadku tego samego modelu i zestawów danych. Dzięki temu dokładność sterownika nie będzie gorsza niż w przypadku implementacji referencyjnej procesora.
Programiści platformy Androida używają też MLTS do oceny opóźnienia i dokładności sterowników.
Test NNAPI można znaleźć w 2 projektach w AOSP:
platform/test/mlts/benchmark(aplikacja testowa)platform/test/mlts/models(modele i zbiory danych)
Modele i zbiory danych
Test porównawczy NNAPI korzysta z tych modeli i zbiorów danych.
- Model MobileNetV1 w wersji zmiennoprzecinkowej i skwantowanej do 8 bitów w różnych rozmiarach, przetestowany na małym podzbiorze (1500 obrazów) zbioru danych Open Images Dataset v4.
- Model MobileNetV2 w wersji zmiennoprzecinkowej i skwantowanej do 8 bitów w różnych rozmiarach, uruchomiony na małym podzbiorze (1500 obrazów) zbioru danych Open Images Dataset w wersji 4.
- Model akustyczny oparty na długiej pamięci krótkotrwałej (LSTM) do syntezy mowy, testowany na małym podzbiorze zbioru CMU Arctic.
- Model akustyczny oparty na LSTM do automatycznego rozpoznawania mowy, uruchamiany na małym podzbiorze zbioru danych LibriSpeech.
Więcej informacji znajdziesz w sekcji platform/test/mlts/models.
Testy obciążeniowe
Zestaw testów uczenia maszynowego na Androidzie zawiera serię testów awaryjnych, które sprawdzają odporność sterowników w warunkach intensywnego użytkowania lub w przypadku nietypowych zachowań klientów.
Wszystkie testy zderzeniowe mają te funkcje:
- Wykrywanie zawieszenia: jeśli klient NNAPI zawiesi się podczas testu, test zakończy się niepowodzeniem z powodu
HANG, a pakiet testów przejdzie do następnego testu. - Wykrywanie awarii klienta NNAPI: testy przetrwają awarie klienta, a testy
zakończą się niepowodzeniem z powodu
CRASH. - Wykrywanie awarii sterownika: testy mogą wykryć awarię sterownika, która powoduje niepowodzenie wywołania NNAPI. Pamiętaj, że w procesach sterownika mogą występować awarie, które nie powodują błędu NNAPI ani nie powodują niepowodzenia testu. Aby zapobiec tego rodzaju awariom, zalecamy uruchomienie polecenia
tailw dzienniku systemowym w przypadku błędów lub awarii związanych ze sterownikami. - Kierowanie na wszystkie dostępne akceleratory: testy są przeprowadzane na wszystkich dostępnych sterownikach.
Wszystkie testy zderzeniowe mogą mieć 4 możliwe wyniki:
SUCCESS: Wykonanie zakończone bez błędu.FAILURE: nie udało się wykonać. Zwykle jest to spowodowane błędem podczas testowania modelu, co oznacza, że sterownik nie skompilował lub nie wykonał modelu.HANG: proces testowania przestał odpowiadać.CRASH: Proces testowania uległ awarii.
Więcej informacji o testach obciążeniowych i pełną listę testów zderzeniowych znajdziesz w platform/test/mlts/benchmark/README.txt.
Korzystanie z MLTS
Aby użyć MLTS:
- Podłącz urządzenie docelowe do stacji roboczej i upewnij się, że jest ono dostępne za pomocą adb.
Wyeksportuj zmienną środowiskową urządzenia docelowego
ANDROID_SERIAL, jeśli połączonych jest więcej niż jedno urządzenie. cddo katalogu źródłowego najwyższego poziomu Androida.source build/envsetup.sh lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available. ./test/mlts/benchmark/build_and_run_benchmark.shPo zakończeniu testu porównawczego wyniki są prezentowane jako strona HTML i przekazywane do
xdg-open.
Więcej informacji znajdziesz w sekcji platform/test/mlts/benchmark/README.txt.
Wersje HAL sieci neuronowych
W tej sekcji opisano zmiany wprowadzone w wersjach Androida i warstwy HAL sieci neuronowych.
Android 11
Android 11 wprowadza NN HAL 1.3, który zawiera te ważne zmiany:
- Obsługa kwantyzacji 8-bitowej ze znakiem w interfejsie NNAPI. Dodaje typ operandu
TENSOR_QUANT8_ASYMM_SIGNED. Sterowniki z NN HAL 1.3, które obsługują operacje z kwantyzacją bez znaku, muszą też obsługiwać warianty tych operacji ze znakiem. Podczas wykonywania podpisanych i niepodpisanych wersji większości operacji kwantyzowanych sterowniki muszą generować te same wyniki z odchyleniem do 128. Od tego wymagania jest 5 wyjątków:CAST,HASHTABLE_LOOKUP,LSH_PROJECTION,PAD_V2iQUANTIZED_16BIT_LSTM. OperacjaQUANTIZED_16BIT_LSTMnie obsługuje operandów ze znakiem, a pozostałe 4 operacje obsługują kwantyzację ze znakiem, ale nie wymagają, aby wyniki były takie same. - Obsługa wykonywania w izolacji, w którym platforma wywołuje metodę
IPreparedModel::executeFenced, aby uruchomić w izolacji asynchroniczne wykonywanie na przygotowanym modelu z wektorem barier synchronizacji, na które trzeba poczekać. Więcej informacji znajdziesz w artykule Fenced execution (w języku angielskim). - Obsługa przepływu sterowania. Dodaje operacje
IFiWHILE, które przyjmują inne modele jako argumenty i wykonują je warunkowo (IF) lub wielokrotnie (WHILE). Więcej informacji znajdziesz w sekcji Przepływ sterowania. - Lepsza jakość usług (QoS), ponieważ aplikacje mogą wskazywać względne priorytety swoich modeli, maksymalny czas oczekiwania na przygotowanie modelu i maksymalny czas oczekiwania na zakończenie wykonania. Więcej informacji znajdziesz w artykule Jakość usługi.
- Obsługa domen pamięci, które udostępniają interfejsy alokatora dla buforów zarządzanych przez sterownik. Umożliwia to przekazywanie natywnych pamięci urządzenia między wykonaniami, co eliminuje niepotrzebne kopiowanie i przekształcanie danych między kolejnymi wykonaniami na tym samym sterowniku. Więcej informacji znajdziesz w artykule Domeny pamięci.
Android 10
Android 10 wprowadza NN HAL 1.2, który zawiera te ważne zmiany:
- Struktura
Capabilitieszawiera wszystkie typy danych, w tym skalarne typy danych, i reprezentuje wydajność bez ograniczeń za pomocą wektora, a nie nazwanych pól. - Metody
getVersionStringigetTypeumożliwiają platformie pobieranie informacji o typie (DeviceType) i wersji urządzenia. Zobacz Odkrywanie i przypisywanie urządzeń. - Metoda
executeSynchronouslyjest domyślnie wywoływana w celu synchronicznego wykonania. Metodaexecute_1_2informuje platformę, że ma wykonać działanie asynchronicznie. Zobacz Wykonanie. - Parametr
MeasureTimingw przypadkuexecuteSynchronously,execute_1_2i wykonywania w seriach określa, czy sterownik ma mierzyć czas trwania wykonywania. Wyniki są raportowane w strukturzeTiming. Zobacz Kody czasowe. - Obsługa wykonań, w których co najmniej 1 operand wyjściowy ma nieznany wymiar lub rangę. Zobacz Kształt danych wyjściowych.
- Obsługa rozszerzeń dostawców, czyli zbiorów zdefiniowanych przez dostawcę operacji i typów danych. Sterownik zgłasza obsługiwane rozszerzenia za pomocą metody
IDevice::getSupportedExtensions. Zobacz Rozszerzenia dostawcy. - Możliwość kontrolowania przez obiekt pakietowy zestawu wykonań pakietowych za pomocą szybkich kolejek wiadomości (FMQ) do komunikacji między procesami aplikacji i sterownika, co zmniejsza opóźnienie. Zobacz Wykonywanie pakietowe i szybkie kolejki wiadomości.
- Obsługa AHardwareBuffer, która umożliwia sterownikowi wykonywanie operacji bez kopiowania danych. Zobacz AHardwareBuffer.
- Ulepszone wsparcie buforowania artefaktów kompilacji, aby skrócić czas kompilacji podczas uruchamiania aplikacji. Patrz buforowanie kompilacji.
Android 10 wprowadza te typy operandów i operacje.
-
ANEURALNETWORKS_BOOLANEURALNETWORKS_FLOAT16ANEURALNETWORKS_TENSOR_BOOL8ANEURALNETWORKS_TENSOR_FLOAT16ANEURALNETWORKS_TENSOR_QUANT16_ASYMMANEURALNETWORKS_TENSOR_QUANT16_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL
-
ANEURALNETWORKS_ABSANEURALNETWORKS_ARGMAXANEURALNETWORKS_ARGMINANEURALNETWORKS_AXIS_ALIGNED_BBOX_TRANSFORMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_RNNANEURALNETWORKS_BOX_WITH_NMS_LIMITANEURALNETWORKS_CASTANEURALNETWORKS_CHANNEL_SHUFFLEANEURALNETWORKS_DETECTION_POSTPROCESSINGANEURALNETWORKS_EQUALANEURALNETWORKS_EXPANEURALNETWORKS_EXPAND_DIMSANEURALNETWORKS_GATHERANEURALNETWORKS_GENERATE_PROPOSALSANEURALNETWORKS_GREATERANEURALNETWORKS_GREATER_EQUALANEURALNETWORKS_GROUPED_CONV_2DANEURALNETWORKS_HEATMAP_MAX_KEYPOINTANEURALNETWORKS_INSTANCE_NORMALIZATIONANEURALNETWORKS_LESSANEURALNETWORKS_LESS_EQUALANEURALNETWORKS_LOGANEURALNETWORKS_LOGICAL_ANDANEURALNETWORKS_LOGICAL_NOTANEURALNETWORKS_LOGICAL_ORANEURALNETWORKS_LOG_SOFTMAXANEURALNETWORKS_MAXIMUMANEURALNETWORKS_MINIMUMANEURALNETWORKS_NEGANEURALNETWORKS_NOT_EQUALANEURALNETWORKS_PAD_V2ANEURALNETWORKS_POWANEURALNETWORKS_PRELUANEURALNETWORKS_QUANTIZEANEURALNETWORKS_QUANTIZED_16BIT_LSTMANEURALNETWORKS_RANDOM_MULTINOMIALANEURALNETWORKS_REDUCE_ALLANEURALNETWORKS_REDUCE_ANYANEURALNETWORKS_REDUCE_MAXANEURALNETWORKS_REDUCE_MINANEURALNETWORKS_REDUCE_PRODANEURALNETWORKS_REDUCE_SUMANEURALNETWORKS_RESIZE_NEAREST_NEIGHBORANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_ROI_POOLINGANEURALNETWORKS_RSQRTANEURALNETWORKS_SELECTANEURALNETWORKS_SINANEURALNETWORKS_SLICEANEURALNETWORKS_SPLITANEURALNETWORKS_SQRTANEURALNETWORKS_TILEANEURALNETWORKS_TOPK_V2ANEURALNETWORKS_TRANSPOSE_CONV_2DANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_RNN
Android 10 wprowadza aktualizacje wielu dotychczasowych operacji. Aktualizacje dotyczą głównie tych kwestii:
- Obsługa układu pamięci NCHW
- Obsługa tensorów o randze innej niż 4 w operacjach softmax i normalizacji
- Obsługa rozszerzonych splotów
- Obsługa danych wejściowych z mieszaną kwantyzacją w
ANEURALNETWORKS_CONCATENATION
Poniższa lista zawiera operacje, które zostały zmodyfikowane w Androidzie 10. Szczegółowe informacje o zmianach znajdziesz w OperationCode w dokumentacji NNAPI.
ANEURALNETWORKS_ADDANEURALNETWORKS_AVERAGE_POOL_2DANEURALNETWORKS_BATCH_TO_SPACE_NDANEURALNETWORKS_CONCATENATIONANEURALNETWORKS_CONV_2DANEURALNETWORKS_DEPTHWISE_CONV_2DANEURALNETWORKS_DEPTH_TO_SPACEANEURALNETWORKS_DEQUANTIZEANEURALNETWORKS_DIVANEURALNETWORKS_FLOORANEURALNETWORKS_FULLY_CONNECTEDANEURALNETWORKS_L2_NORMALIZATIONANEURALNETWORKS_L2_POOL_2DANEURALNETWORKS_LOCAL_RESPONSE_NORMALIZATIONANEURALNETWORKS_LOGISTICANEURALNETWORKS_LSH_PROJECTIONANEURALNETWORKS_LSTMANEURALNETWORKS_MAX_POOL_2DANEURALNETWORKS_MEANANEURALNETWORKS_MULANEURALNETWORKS_PADANEURALNETWORKS_RELUANEURALNETWORKS_RELU1ANEURALNETWORKS_RELU6ANEURALNETWORKS_RESHAPEANEURALNETWORKS_RESIZE_BILINEARANEURALNETWORKS_RNNANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_SOFTMAXANEURALNETWORKS_SPACE_TO_BATCH_NDANEURALNETWORKS_SPACE_TO_DEPTHANEURALNETWORKS_SQUEEZEANEURALNETWORKS_STRIDED_SLICEANEURALNETWORKS_SUBANEURALNETWORKS_SVDFANEURALNETWORKS_TANHANEURALNETWORKS_TRANSPOSE
Android 9
W Androidzie 9 wprowadzono NN HAL 1.1, który zawiera te ważne zmiany:
IDevice::prepareModel_1_1zawiera parametrExecutionPreference. Dzięki temu sterownik może dostosować przygotowanie, wiedząc, że aplikacja woli oszczędzać baterię lub będzie wykonywać model w szybkich kolejnych wywołaniach.- Dodaliśmy 9 nowych operacji:
BATCH_TO_SPACE_ND,DIV,MEAN,PAD,SPACE_TO_BATCH_ND,SQUEEZE,STRIDED_SLICE,SUB,TRANSPOSE. - Aplikacja może określić, że obliczenia zmiennoprzecinkowe 32-bitowe mogą być wykonywane przy użyciu zakresu lub precyzji zmiennoprzecinkowej 16-bitowej, ustawiając wartość
Model.relaxComputationFloat32toFloat16natrue.CapabilitiesStruktura ma dodatkowe polerelaxedFloat32toFloat16Performance, dzięki czemu sterownik może zgłaszać do platformy swoje obniżone wymagania dotyczące wydajności.
Android 8.1
Pierwsza wersja HAL sieci neuronowych (1.0) została opublikowana w Androidzie 8.1. Więcej informacji znajdziesz w sekcji /neuralnetworks/1.0/.