
Auf dieser Seite erhalten Sie einen Überblick über die Implementierung eines NNAPI-Treibers (Neural Networks API). Weitere Informationen finden Sie in der Dokumentation in den HAL-Definitionsdateien unter hardware/interfaces/neuralnetworks.
Eine Beispielimplementierung des Treibers finden Sie unter frameworks/ml/nn/driver/sample.
Weitere Informationen zur Neural Networks API finden Sie unter Neural Networks API.
HAL für neuronale Netzwerke
Das Neural Networks (NN) HAL definiert eine Abstraktion der verschiedenen Geräte, z. B. Grafikprozessoren (GPUs) und digitale Signalprozessoren (DSPs), die in einem Produkt (z. B. einem Smartphone oder Tablet) enthalten sind. Die Treiber für diese Geräte müssen der NN HAL entsprechen. Die Schnittstelle wird in den HAL-Definitionsdateien in hardware/interfaces/neuralnetworks angegeben.
Der allgemeine Ablauf der Schnittstelle zwischen dem Framework und einem Treiber ist in Abbildung 1 dargestellt.
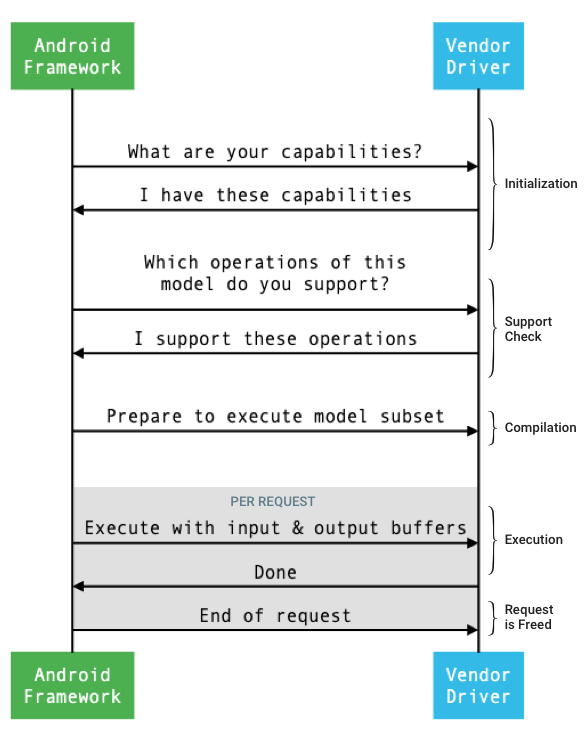
Abbildung 1. Ablauf für neuronale Netzwerke
Initialisierung
Bei der Initialisierung fragt das Framework den Treiber mit IDevice::getCapabilities_1_3 nach seinen Funktionen.
Die @1.3::Capabilities-Struktur umfasst alle Datentypen und stellt die nicht gelockerte Leistung mithilfe eines Vektors dar.
Um zu bestimmen, wie Berechnungen auf die verfügbaren Geräte verteilt werden sollen, verwendet das Framework die Funktionen, um zu verstehen, wie schnell und energieeffizient jeder Treiber eine Ausführung durchführen kann. Dazu muss der Treiber standardisierte Leistungszahlen auf Grundlage der Ausführung von Referenz-Workloads liefern.
Um die Werte zu ermitteln, die der Treiber als Reaktion auf IDevice::getCapabilities_1_3 zurückgibt, verwenden Sie die NNAPI-Benchmark-App, um die Leistung für entsprechende Datentypen zu messen. Die Modelle MobileNet v1 und v2, asr_float und tts_float werden für die Leistungsmessung für 32‑Bit-Gleitkommawerte empfohlen. Die quantisierten Modelle MobileNet v1 und v2 werden für 8‑Bit-quantisierte Werte empfohlen. Weitere Informationen finden Sie unter Android Machine Learning Test Suite.
In Android 9 und niedriger enthält die Capabilities-Struktur Informationen zur Treiberleistung nur für Gleitkomma- und quantisierte Tensoren und nicht für skalare Datentypen.
Im Rahmen der Initialisierung fragt das Framework möglicherweise weitere Informationen ab, indem es IDevice::getType, IDevice::getVersionString, IDevice:getSupportedExtensions und IDevice::getNumberOfCacheFilesNeeded verwendet.
Zwischen den Neustarts des Produkts erwartet das Framework, dass für einen bestimmten Treiber immer dieselben Werte für alle in diesem Abschnitt beschriebenen Abfragen gemeldet werden. Andernfalls kann es bei einer App, die diesen Treiber verwendet, zu Leistungseinbußen oder fehlerhaftem Verhalten kommen.
Compilation
Das Framework bestimmt, welche Geräte verwendet werden sollen, wenn es eine Anfrage von einer App erhält. In Android 10 können Apps die Geräte ermitteln und angeben, aus denen das Framework auswählt. Weitere Informationen finden Sie unter Geräteerkennung und ‑zuweisung.
Beim Kompilieren des Modells sendet das Framework das Modell an jeden Kandidatentreiber, indem es IDevice::getSupportedOperations_1_3 aufruft.
Jeder Treiber gibt ein Array von booleschen Werten zurück, die angeben, welche Vorgänge des Modells unterstützt werden. Ein Treiber kann aus verschiedenen Gründen feststellen, dass er eine bestimmte Operation nicht unterstützen kann. Beispiel:
- Der Datentyp wird vom Treiber nicht unterstützt.
- Der Treiber unterstützt nur Vorgänge mit bestimmten Eingabeparametern. Ein Treiber unterstützt möglicherweise 3×3- und 5×5-Faltungen, aber keine 7×7-Faltungen.
- Der Treiber hat Speicherbeschränkungen, die verhindern, dass er große Diagramme oder Eingaben verarbeiten kann.
Während der Kompilierung können die Ein-, Ausgabe- und internen Operanden des Modells, wie in OperandLifeTime beschrieben, unbekannte Dimensionen oder einen unbekannten Rang haben. Weitere Informationen finden Sie unter Ausgabeform.
Das Framework weist jeden ausgewählten Treiber an, sich auf die Ausführung einer Teilmenge des Modells vorzubereiten, indem IDevice::prepareModel_1_3 aufgerufen wird.
Jeder Treiber kompiliert dann seine Teilmenge. Ein Treiber kann beispielsweise Code generieren oder eine neu sortierte Kopie der Gewichte erstellen. Da zwischen der Kompilierung des Modells und der Ausführung von Anfragen viel Zeit vergehen kann, sollten Ressourcen wie große Teile des Gerätespeichers nicht während der Kompilierung zugewiesen werden.
Bei Erfolg gibt der Treiber ein @1.3::IPreparedModel-Handle zurück. Wenn der Treiber beim Vorbereiten seiner Teilmenge des Modells einen Fehlercode zurückgibt, führt das Framework das gesamte Modell auf der CPU aus.
Um die für die Kompilierung benötigte Zeit beim Start einer App zu verkürzen, kann ein Treiber Kompilierungsartefakte im Cache speichern. Weitere Informationen finden Sie unter Kompilierungs-Caching.
Ausführung
Wenn eine App das Framework auffordert, eine Anfrage auszuführen, ruft das Framework standardmäßig die HAL-Methode IPreparedModel::executeSynchronously_1_3 auf, um eine synchrone Ausführung für ein vorbereitetes Modell durchzuführen.
Eine Anfrage kann auch asynchron mit der Methode execute_1_3, der Methode executeFenced (siehe Fenced Execution) oder mit einer Burst Execution ausgeführt werden.
Synchrone Ausführungsaufrufe verbessern die Leistung und reduzieren den Threading-Overhead im Vergleich zu asynchronen Aufrufen, da die Steuerung erst nach Abschluss der Ausführung an den App-Prozess zurückgegeben wird. Das bedeutet, dass der Treiber keinen separaten Mechanismus benötigt, um den App-Prozess darüber zu informieren, dass eine Ausführung abgeschlossen ist.
Bei der asynchronen Methode execute_1_3 wird die Steuerung nach dem Start der Ausführung an den App-Prozess zurückgegeben. Der Treiber muss das Framework über die @1.3::IExecutionCallback benachrichtigen, wenn die Ausführung abgeschlossen ist.
Der Parameter Request, der an die Methode „execute“ übergeben wird, enthält die Ein- und Ausgabeargumente, die für die Ausführung verwendet werden. Der Speicher, in dem die Operanden-Daten gespeichert werden, muss die zeilenweise Reihenfolge verwenden, wobei die erste Dimension am langsamsten durchlaufen wird und am Ende einer Zeile kein Padding vorhanden ist. Weitere Informationen zu den Operandentypen finden Sie unter Operanden.
Bei NN HAL 1.2- oder höheren Treibern werden nach Abschluss einer Anfrage der Fehlerstatus, die Ausgabeform und die Zeitinformationen an das Framework zurückgegeben. Während der Ausführung können Ausgabe- oder interne Operanden des Modells eine oder mehrere unbekannte Dimensionen oder einen unbekannten Rang haben. Wenn mindestens ein Ausgabeargument einen unbekannten Rang oder eine unbekannte Dimension hat, muss der Treiber Informationen zur dynamischen Größe der Ausgabe zurückgeben.
Bei Treibern mit NN HAL 1.1 oder niedriger wird nur der Fehlerstatus zurückgegeben, wenn eine Anfrage abgeschlossen ist. Die Dimensionen für Ein- und Ausgabeargumente müssen vollständig angegeben werden, damit die Ausführung erfolgreich abgeschlossen werden kann. Interne Operanden können eine oder mehrere unbekannte Dimensionen haben, müssen aber einen angegebenen Rang haben.
Bei Nutzeranfragen, die mehrere Treiber umfassen, ist das Framework dafür verantwortlich, Zwischenspeicher zu reservieren und die Aufrufe an die einzelnen Treiber zu sequenzieren.
Es können mehrere Anfragen parallel auf demselben @1.3::IPreparedModel gestellt werden.
Der Treiber kann Anfragen parallel ausführen oder die Ausführungen serialisieren.
Das Framework kann einen Treiber auffordern, mehr als ein vorbereitetes Modell zu behalten. Beispiel: Modell m1 vorbereiten, m2 vorbereiten, Anfrage r1 für m1 ausführen, r2 für m2 ausführen, r3 für m1 ausführen, r4 für m2 ausführen, m1 freigeben (siehe Bereinigung) und m2 freigeben.
Um eine langsame erste Ausführung zu vermeiden, die zu einer schlechten Nutzererfahrung führen könnte (z. B. ein ruckelndes erstes Frame), sollte der Treiber die meisten Initialisierungen in der Kompilierungsphase durchführen. Die Initialisierung bei der ersten Ausführung sollte auf Aktionen beschränkt sein, die sich negativ auf den Systemzustand auswirken, wenn sie frühzeitig ausgeführt werden, z. B. das Reservieren großer temporärer Puffer oder das Erhöhen der Taktrate eines Geräts. Treiber, die nur eine begrenzte Anzahl gleichzeitiger Modelle vorbereiten können, müssen die Initialisierung möglicherweise bei der ersten Ausführung durchführen.
Unter Android 10 oder höher kann der Client in Fällen, in denen mehrere Ausführungen mit demselben vorbereiteten Modell in schneller Folge ausgeführt werden, ein Ausführungs-Burst-Objekt verwenden, um zwischen App- und Treiberprozessen zu kommunizieren. Weitere Informationen finden Sie unter Burst Executions and Fast Message Queues.
Um die Leistung bei mehreren Ausführungen in schneller Folge zu verbessern, kann der Treiber temporäre Puffer beibehalten oder die Taktraten erhöhen. Es wird empfohlen, einen Watchdog-Thread zu erstellen, um Ressourcen freizugeben, wenn nach einem bestimmten Zeitraum keine neuen Anfragen erstellt werden.
Ausgabeform
Bei Anfragen, bei denen für einen oder mehrere Ausgabeargumente nicht alle Dimensionen angegeben sind, muss der Treiber nach der Ausführung eine Liste mit Ausgabeformenthalten, die die Dimensionsinformationen für jedes Ausgabeargument enthält. Weitere Informationen zu Dimensionen finden Sie unter OutputShape.
Wenn eine Ausführung aufgrund eines zu kleinen Ausgabepuffers fehlschlägt, muss der Treiber in der Liste der Ausgabeshapes angeben, für welche Ausgabeargumente die Puffergröße nicht ausreicht. Außerdem sollte er so viele Dimensionsinformationen wie möglich angeben und für unbekannte Dimensionen den Wert 0 verwenden.
Timing
In Android 10 kann eine App nach der Ausführungszeit fragen, wenn sie ein einzelnes Gerät für den Kompilierungsprozess angegeben hat. Weitere Informationen finden Sie unter MeasureTiming und Geräteerkennung und ‑zuweisung.
In diesem Fall muss ein NN HAL 1.2-Treiber die Ausführungsdauer messen oder UINT64_MAX melden (um anzugeben, dass die Dauer nicht verfügbar ist), wenn eine Anfrage ausgeführt wird. Der Treiber sollte alle Leistungseinbußen minimieren, die durch die Messung der Ausführungsdauer entstehen.
Der Treiber meldet die folgenden Zeiträume in Mikrosekunden in der Struktur Timing:
- Ausführungszeit auf dem Gerät:Die Ausführungszeit im Treiber, der auf dem Hostprozessor ausgeführt wird, ist nicht enthalten.
- Ausführungszeit im Treiber:Enthält die Ausführungszeit auf dem Gerät.
Diese Zeiträume müssen die Zeit umfassen, in der die Ausführung unterbrochen wird, z. B. wenn die Ausführung durch andere Aufgaben unterbrochen wurde oder wenn sie darauf wartet, dass eine Ressource verfügbar wird.
Wenn der Treiber nicht aufgefordert wurde, die Ausführungsdauer zu messen, oder wenn ein Ausführungsfehler auftritt, muss er die Dauer als UINT64_MAX melden. Auch wenn der Fahrer aufgefordert wurde, die Ausführungsdauer zu messen, kann er stattdessen UINT64_MAX für die Zeit auf dem Gerät, die Zeit im Fahrer oder beides melden. Wenn der Treiber beide Zeiträume als einen anderen Wert als UINT64_MAX meldet, muss die Ausführungszeit im Treiber der Zeit auf dem Gerät entsprechen oder sie überschreiten.
Abgegrenzte Ausführung
In Android 11 kann NNAPI Ausführungen ermöglichen, die auf eine Liste von sync_fence-Handles warten und optional ein sync_fence-Objekt zurückgeben, das signalisiert wird, wenn die Ausführung abgeschlossen ist. Dadurch wird der Overhead für kleine Sequenzmodelle und Streaming-Anwendungsfälle reduziert. Die eingeschränkte Ausführung ermöglicht auch eine effizientere Interoperabilität mit anderen Komponenten, die sync_fence signalisieren oder darauf warten können. Weitere Informationen zu sync_fence finden Sie unter Synchronisierungs-Framework.
Bei einer geschützten Ausführung ruft das Framework die Methode IPreparedModel::executeFenced auf, um eine geschützte, asynchrone Ausführung für ein vorbereitetes Modell mit einem Vektor von Synchronisationssperren zu starten, auf die gewartet werden soll. Wenn die asynchrone Aufgabe abgeschlossen ist, bevor der Aufruf zurückgegeben wird, kann für sync_fence ein leeres Handle zurückgegeben werden. Außerdem muss ein IFencedExecutionCallback-Objekt zurückgegeben werden, damit das Framework Fehlerstatus und ‑dauer abfragen kann.
Nach Abschluss einer Ausführung können die folgenden beiden Zeitangaben, mit denen die Dauer der Ausführung gemessen wird, über IFencedExecutionCallback::getExecutionInfo abgefragt werden.
timingLaunched: Dauer vom Aufrufen vonexecuteFencedbis zum Signalisieren des zurückgegebenensyncFencedurchexecuteFenced.timingFenced: Die Dauer vom Zeitpunkt, an dem alle Synchronisations-Fences, auf die die Ausführung wartet, signalisiert werden, bisexecuteFenceddas zurückgegebenesyncFencesignalisiert.
Kontrollfluss
Für Geräte mit Android 11 oder höher enthält die NNAPI zwei Kontrollflussvorgänge, IF und WHILE, die andere Modelle als Argumente verwenden und sie bedingt (IF) oder wiederholt (WHILE) ausführen. Weitere Informationen zur Implementierung finden Sie unter Kontrollfluss.
Dienstqualität
In Android 11 bietet die NNAPI eine verbesserte Servicequalität (QoS), da eine App die relativen Prioritäten ihrer Modelle, die maximale Zeit, die für die Vorbereitung eines Modells erwartet wird, und die maximale Zeit, die für die Ausführung erwartet wird, angeben kann. Weitere Informationen finden Sie unter Quality of Service.
Bereinigen
Wenn eine App ein vorbereitetes Modell nicht mehr verwendet, gibt das Framework die Referenz zum @1.3::IPreparedModel-Objekt frei. Wenn nicht mehr auf das IPreparedModel-Objekt verwiesen wird, wird es automatisch im Treiberdienst zerstört, der es erstellt hat. Modellspezifische Ressourcen können zu diesem Zeitpunkt in der Implementierung des Destruktors durch den Treiber freigegeben werden. Wenn das IPreparedModel-Objekt automatisch zerstört werden soll, sobald es vom Client nicht mehr benötigt wird, darf der Treiberservice keine Verweise auf das IPreparedModel-Objekt enthalten, nachdem das IPreparedeModel-Objekt über IPreparedModelCallback::notify_1_3 zurückgegeben wurde.
CPU-Nutzung
Treiber verwenden die CPU, um Berechnungen einzurichten. Treiber sollten die CPU nicht für die Durchführung von Diagrammberechnungen verwenden, da dies die Fähigkeit des Frameworks beeinträchtigt, Arbeit korrekt zuzuweisen. Der Treiber sollte die Teile, die er nicht verarbeiten kann, an das Framework melden und das Framework den Rest erledigen lassen.
Das Framework bietet eine CPU-Implementierung für alle NNAPI-Vorgänge mit Ausnahme von anbieterspezifischen Vorgängen. Weitere Informationen finden Sie unter Vendor Extensions.
Die in Android 10 eingeführten Vorgänge (API-Level 29) haben nur eine Referenz-CPU-Implementierung, um zu überprüfen, ob die CTS- und VTS-Tests korrekt sind. Die optimierten Implementierungen, die in Frameworks für maschinelles Lernen auf Mobilgeräten enthalten sind, werden der NNAPI-CPU-Implementierung vorgezogen.
Hilfsfunktionen
Die NNAPI-Codebasis enthält Hilfsfunktionen, die von Treiberservices verwendet werden können.
Die Datei frameworks/ml/nn/common/include/Utils.h enthält verschiedene Dienstprogrammfunktionen, z. B. für die Protokollierung und die Konvertierung zwischen verschiedenen NN HAL-Versionen.
VLogging:
VLOGist ein Wrapper-Makro fürLOGvon Android, das die Nachricht nur protokolliert, wenn das entsprechende Tag in derdebug.nn.vlog-Eigenschaft festgelegt ist.initVLogMask()muss vor allen Aufrufen vonVLOGaufgerufen werden. Mit dem MakroVLOG_IS_ONlässt sich prüfen, obVLOGderzeit aktiviert ist. So kann komplizierter Logging-Code übersprungen werden, wenn er nicht benötigt wird. Der Wert der Eigenschaft muss einer der folgenden sein:- Ein leerer String, der angibt, dass keine Protokollierung erfolgen soll.
- Das Token
1oderall, das angibt, dass die gesamte Protokollierung erfolgen soll. - Eine durch Leerzeichen, Kommas oder Doppelpunkte getrennte Liste von Tags, die angibt, welche Protokollierung erfolgen soll. Die Tags sind
compilation,cpuexe,driver,execution,managerundmodel.
compliantWithV1_*: Gibttruezurück, wenn ein NN HAL-Objekt ohne Informationsverlust in denselben Typ einer anderen HAL-Version konvertiert werden kann. Wenn Sie beispielsweisecompliantWithV1_0für einV1_2::Modelaufrufen, wirdfalsezurückgegeben, wenn das Modell Vorgangstypen enthält, die in NN HAL 1.1 oder NN HAL 1.2 eingeführt wurden.convertToV1_*: Konvertiert ein NN HAL-Objekt von einer Version in eine andere. Eine Warnung wird protokolliert, wenn die Konvertierung zu einem Informationsverlust führt, d. h. wenn der Wert in der neuen Version des Typs nicht vollständig dargestellt werden kann.Funktionen: Mit den Funktionen
nonExtensionOperandPerformanceundupdatelässt sich das FeldCapabilities::operandPerformanceerstellen.Abfragen von Eigenschaften von Typen:
isExtensionOperandType,isExtensionOperationType,nonExtensionSizeOfData,nonExtensionOperandSizeOfData,nonExtensionOperandTypeIsScalar,tensorHasUnspecifiedDimensions.
Die Datei frameworks/ml/nn/common/include/ValidateHal.h enthält Hilfsfunktionen zum Validieren, ob ein NN HAL-Objekt gemäß der Spezifikation seiner HAL-Version gültig ist.
validate*: Gibttruezurück, wenn das NN HAL-Objekt gemäß der Spezifikation seiner HAL-Version gültig ist. OEM-Typen und Erweiterungstypen werden nicht validiert.validateModelgibt beispielsweisefalsezurück, wenn das Modell einen Vorgang enthält, der auf einen nicht vorhandenen Operandenindex verweist, oder einen Vorgang, der in dieser HAL-Version nicht unterstützt wird.
Die Datei frameworks/ml/nn/common/include/Tracing.h enthält Makros, mit denen sich systracing-Informationen einfacher in den Code für neuronale Netze einfügen lassen.
Ein Beispiel finden Sie in den NNTRACE_*-Makroaufrufen im Beispieltreiber.
Die Datei frameworks/ml/nn/common/include/GraphDump.h enthält eine Dienstfunktion zum Ausgeben des Inhalts eines Model in grafischer Form zu Debugging-Zwecken.
graphDump: Schreibt eine Darstellung des Modells im Graphviz-Format (.dot) in den angegebenen Stream (falls angegeben) oder in den Logcat (falls kein Stream angegeben ist).
Validierung
Verwenden Sie zum Testen Ihrer NNAPI-Implementierung die im Android-Framework enthaltenen VTS- und CTS-Tests. VTS testet Ihre Treiber direkt (ohne das Framework zu verwenden), während CTS sie indirekt über das Framework testet. Dabei wird jede API-Methode getestet und es wird geprüft, ob alle von den Treibern unterstützten Vorgänge korrekt ausgeführt werden und Ergebnisse liefern, die den Anforderungen an die Genauigkeit entsprechen.
Die Genauigkeitsanforderungen in CTS und VTS für die NNAPI sind wie folgt:
Gleitkomma:abs(expected - actual) <= atol + rtol * abs(expected); where:
- Für fp32: atol = 1e-5f, rtol = 5.0f * 1.1920928955078125e-7
- Für fp16: atol = rtol = 5.0f * 0.0009765625f
Quantisiert:Abweichung um 1 (außer bei
mobilenet_quantized, wo die Abweichung um 3 liegt)Boolesch:genaue Übereinstimmung
Bei CTS-Tests für die NNAPI werden unter anderem feste pseudozufällige Grafiken generiert, mit denen die Ausführungsergebnisse der einzelnen Treiber mit der NNAPI-Referenzimplementierung verglichen werden. Wenn die Ergebnisse für Treiber mit NN HAL 1.2 oder höher die Genauigkeitskriterien nicht erfüllen, meldet CTS einen Fehler und speichert eine Spezifikationsdatei für das fehlgeschlagene Modell unter /data/local/tmp zur Fehlerbehebung.
Weitere Informationen zu den Genauigkeitskriterien finden Sie unter TestRandomGraph.cpp und TestHarness.h.
Fuzzing
Der Zweck von Fuzzing-Tests besteht darin, Abstürze, Assertions, Speicherverletzungen oder allgemeines undefiniertes Verhalten im zu testenden Code aufgrund von Faktoren wie unerwarteten Eingaben zu finden. Für NNAPI-Fuzzing verwendet Android Tests, die auf libFuzzer basieren. Diese sind effizient, da sie die Zeilenabdeckung früherer Testläufe nutzen, um neue zufällige Eingaben zu generieren. libFuzzer bevorzugt beispielsweise Testläufe für neue Codezeilen. Dadurch wird die Zeit, die für das Auffinden von problematischem Code benötigt wird, erheblich verkürzt.
Wenn Sie Fuzzing-Tests durchführen möchten, um Ihre Treiberimplementierung zu validieren, müssen Sie frameworks/ml/nn/runtime/test/android_fuzzing/DriverFuzzTest.cpp im libneuralnetworks_driver_fuzzer-Testprogramm in AOSP so ändern, dass Ihr Treibercode enthalten ist. Weitere Informationen zu NNAPI-Fuzz-Tests finden Sie unter frameworks/ml/nn/runtime/test/android_fuzzing/README.md.
Sicherheit
Da App-Prozesse direkt mit dem Prozess eines Treibers kommunizieren, müssen Treiber die Argumente der empfangenen Aufrufe validieren. Diese Validierung wird von VTS überprüft. Der Validierungscode befindet sich in frameworks/ml/nn/common/include/ValidateHal.h.
Außerdem müssen sie dafür sorgen, dass Apps andere Apps nicht beeinträchtigen können, wenn sie auf demselben Gerät verwendet werden.
Android Machine Learning Test Suite
Die Android Machine Learning Test Suite (MLTS) ist ein NNAPI-Benchmark, der in CTS und VTS enthalten ist, um die Genauigkeit echter Modelle auf Geräten von Anbietern zu validieren. Der Benchmark bewertet Latenz und Genauigkeit und vergleicht die Ergebnisse der Treiber mit den Ergebnissen, die mit TF Lite auf der CPU für dasselbe Modell und dieselben Datasets erzielt wurden. So wird sichergestellt, dass die Genauigkeit eines Treibers nicht schlechter ist als die CPU-Referenzimplementierung.
Android-Plattformentwickler verwenden MLTS auch, um die Latenz und Genauigkeit von Treibern zu bewerten.
Der NNAPI-Benchmark ist in zwei Projekten in AOSP verfügbar:
platform/test/mlts/benchmark(Benchmark-App)platform/test/mlts/models(Modelle und Datasets)
Modelle und Datasets
Für den NNAPI-Benchmark werden die folgenden Modelle und Datasets verwendet.
- MobileNetV1-Gleitkomma- und u8-quantisiert in verschiedenen Größen, ausgeführt für eine kleine Teilmenge (1.500 Bilder) von Open Images Dataset V4.
- MobileNetV2-Modelle mit Gleitkommazahlen und quantisiert mit u8 in verschiedenen Größen, die mit einer kleinen Teilmenge (1.500 Bilder) des Open Images Dataset v4 ausgeführt wurden.
- Auf Long Short-Term Memory (LSTM) basierendes akustisches Modell für die Sprachsynthese, das mit einer kleinen Teilmenge des CMU Arctic-Datasets ausgeführt wird.
- LSTM-basiertes akustisches Modell für die automatische Spracherkennung, das für eine kleine Teilmenge des LibriSpeech-Datasets ausgeführt wird.
Weitere Informationen finden Sie unter platform/test/mlts/models.
Stresstests
Die Android Machine Learning Test Suite umfasst eine Reihe von Absturztests, mit denen die Stabilität von Treibern bei starker Nutzung oder in Grenzsituationen des Clientverhaltens validiert wird.
Alle Absturztests bieten die folgenden Funktionen:
- Erkennung von Hängern:Wenn der NNAPI-Client während eines Tests hängen bleibt, schlägt der Test mit dem Fehlergrund
HANGfehl und die Testsuite wird mit dem nächsten Test fortgesetzt. - Erkennung von NNAPI-Clientabstürzen:Tests überstehen Clientabstürze und schlagen mit dem Fehlergrund
CRASHfehl. - Erkennung von Treiberabstürzen:Mit Tests kann ein Treiberabsturz erkannt werden, der einen Fehler bei einem NNAPI-Aufruf verursacht. Beachten Sie, dass es in Treiberprozessen zu Abstürzen kommen kann, die keinen NNAPI-Fehler und keinen Testfehler verursachen. Um diese Art von Fehler zu beheben, wird empfohlen, den Befehl
tailim Systemprotokoll nach treiberbezogenen Fehlern oder Abstürzen zu suchen. - Targeting aller verfügbaren Accelerators:Die Tests werden für alle verfügbaren Treiber ausgeführt.
Alle Absturztests haben die folgenden vier möglichen Ergebnisse:
SUCCESS: Die Ausführung wurde ohne Fehler abgeschlossen.FAILURE: Die Ausführung ist fehlgeschlagen. Wird in der Regel durch einen Fehler beim Testen eines Modells verursacht. Dies deutet darauf hin, dass der Treiber das Modell nicht kompilieren oder ausführen konnte.HANG: Der Testprozess reagierte nicht mehr.CRASH: Der Testprozess ist abgestürzt.
Weitere Informationen zu Stresstests und eine vollständige Liste der Absturztests finden Sie unter platform/test/mlts/benchmark/README.txt.
MLTS verwenden
So verwenden Sie den MLTS:
- Verbinden Sie ein Zielgerät mit Ihrer Workstation und sorgen Sie dafür, dass es über adb erreichbar ist.
Exportieren Sie die Umgebungsvariable
ANDROID_SERIALdes Zielgeräts, wenn mehr als ein Gerät verbunden ist. cdin das Android-Quellverzeichnis der obersten Ebene.source build/envsetup.sh lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available. ./test/mlts/benchmark/build_and_run_benchmark.shAm Ende eines Benchmark-Laufs werden die Ergebnisse als HTML-Seite präsentiert und an
xdg-openübergeben.
Weitere Informationen finden Sie unter platform/test/mlts/benchmark/README.txt.
HAL-Versionen für neuronale Netzwerke
In diesem Abschnitt werden die Änderungen beschrieben, die in den Android- und Neural Networks HAL-Versionen eingeführt wurden.
Android 11
Mit Android 11 wird NN HAL 1.3 eingeführt, das die folgenden wichtigen Änderungen enthält.
- Unterstützung für die signierte 8‑Bit-Quantisierung in NNAPI. Fügt den Operandentyp
TENSOR_QUANT8_ASYMM_SIGNEDhinzu. Treiber mit NN HAL 1.3, die Operationen mit Quantisierung ohne Vorzeichen unterstützen, müssen auch die Varianten mit Vorzeichen dieser Operationen unterstützen. Wenn signierte und nicht signierte Versionen der meisten quantisierten Vorgänge ausgeführt werden, müssen Treiber bis zu einem Offset von 128 dieselben Ergebnisse liefern. Es gibt fünf Ausnahmen von dieser Anforderung:CAST,HASHTABLE_LOOKUP,LSH_PROJECTION,PAD_V2undQUANTIZED_16BIT_LSTM. DerQUANTIZED_16BIT_LSTM-Vorgang unterstützt keine signierten Operanden und die anderen vier Vorgänge unterstützen die signierte Quantisierung, erfordern jedoch nicht, dass die Ergebnisse gleich sind. - Unterstützung für eingeschränkte Ausführungen, bei denen das Framework die Methode
IPreparedModel::executeFencedaufruft, um eine eingeschränkte, asynchrone Ausführung für ein vorbereitetes Modell mit einem Vektor von Synchronisierungs-Fences zu starten, auf die gewartet werden soll. Weitere Informationen finden Sie unter Abgeschirmte Ausführung. - Unterstützung für den Kontrollfluss. Fügt die Vorgänge
IFundWHILEhinzu, die andere Modelle als Argumente verwenden und sie bedingt (IF) oder wiederholt (WHILE) ausführen. Weitere Informationen finden Sie unter Ablaufsteuerung. - Verbesserte Dienstqualität (QoS), da Apps die relativen Prioritäten ihrer Modelle, die maximale Zeit, die für die Vorbereitung eines Modells benötigt wird, und die maximale Zeit, die für die Ausführung benötigt wird, angeben können. Weitere Informationen finden Sie unter Quality of Service.
- Unterstützung für Speicherbereiche, die Zuweisungsschnittstellen für treiberverwaltete Puffer bereitstellen. So können geräteinterne Speicher über Ausführungen hinweg weitergegeben werden, wodurch unnötiges Kopieren und Transformieren von Daten zwischen aufeinanderfolgenden Ausführungen auf demselben Treiber unterdrückt wird. Weitere Informationen finden Sie unter Speicherbereiche.
Android 10
Mit Android 10 wird NN HAL 1.2 eingeführt, das die folgenden wichtigen Änderungen enthält.
- Der Struct
Capabilitiesenthält alle Datentypen, einschließlich skalarer Datentypen, und stellt die nicht gelockerte Leistung mit einem Vektor anstelle von benannten Feldern dar. - Mit den Methoden
getVersionStringundgetTypekann das Framework Informationen zum Gerätetyp (DeviceType) und zur Version abrufen. Weitere Informationen finden Sie unter Geräteerkennung und ‑zuweisung. - Die Methode
executeSynchronouslywird standardmäßig aufgerufen, um eine Ausführung synchron durchzuführen. Dieexecute_1_2-Methode weist das Framework an, eine Ausführung asynchron durchzuführen. Siehe Ausführung. - Der Parameter
MeasureTimingfürexecuteSynchronously,execute_1_2und die Burst-Ausführung gibt an, ob der Treiber die Ausführungsdauer messen soll. Die Ergebnisse werden in derTiming-Struktur zurückgegeben. Weitere Informationen finden Sie unter Zeitangaben. - Unterstützung für Ausführungen, bei denen mindestens ein Ausgabeargument eine unbekannte Dimension oder einen unbekannten Rang hat. Siehe Ausgabeform.
- Unterstützung für Anbietererweiterungen, die Sammlungen von anbieterdefinierten Vorgängen und Datentypen sind. Der Treiber meldet unterstützte Erweiterungen über die Methode
IDevice::getSupportedExtensions. Weitere Informationen finden Sie unter Vendor Extensions. - Ein Burst-Objekt kann eine Reihe von Burst-Ausführungen steuern. Dazu werden Fast Message Queues (FMQs) für die Kommunikation zwischen App- und Treiberprozessen verwendet, wodurch die Latenz reduziert wird. Weitere Informationen finden Sie unter Burst Executions and Fast Message Queues.
- Unterstützung für AHardwareBuffer, damit der Treiber Ausführungen ohne Kopieren von Daten durchführen kann. Siehe AHardwareBuffer.
- Die Unterstützung für das Caching von Kompilierungsartefakten wurde verbessert, um die für die Kompilierung benötigte Zeit beim Start einer App zu verkürzen. Weitere Informationen finden Sie unter Kompilierungs-Caching.
Mit Android 10 werden die folgenden Operandentypen und ‑vorgänge eingeführt.
-
ANEURALNETWORKS_BOOLANEURALNETWORKS_FLOAT16ANEURALNETWORKS_TENSOR_BOOL8ANEURALNETWORKS_TENSOR_FLOAT16ANEURALNETWORKS_TENSOR_QUANT16_ASYMMANEURALNETWORKS_TENSOR_QUANT16_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL
-
ANEURALNETWORKS_ABSANEURALNETWORKS_ARGMAXANEURALNETWORKS_ARGMINANEURALNETWORKS_AXIS_ALIGNED_BBOX_TRANSFORMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_RNNANEURALNETWORKS_BOX_WITH_NMS_LIMITANEURALNETWORKS_CASTANEURALNETWORKS_CHANNEL_SHUFFLEANEURALNETWORKS_DETECTION_POSTPROCESSINGANEURALNETWORKS_EQUALANEURALNETWORKS_EXPANEURALNETWORKS_EXPAND_DIMSANEURALNETWORKS_GATHERANEURALNETWORKS_GENERATE_PROPOSALSANEURALNETWORKS_GREATERANEURALNETWORKS_GREATER_EQUALANEURALNETWORKS_GROUPED_CONV_2DANEURALNETWORKS_HEATMAP_MAX_KEYPOINTANEURALNETWORKS_INSTANCE_NORMALIZATIONANEURALNETWORKS_LESSANEURALNETWORKS_LESS_EQUALANEURALNETWORKS_LOGANEURALNETWORKS_LOGICAL_ANDANEURALNETWORKS_LOGICAL_NOTANEURALNETWORKS_LOGICAL_ORANEURALNETWORKS_LOG_SOFTMAXANEURALNETWORKS_MAXIMUMANEURALNETWORKS_MINIMUMANEURALNETWORKS_NEGANEURALNETWORKS_NOT_EQUALANEURALNETWORKS_PAD_V2ANEURALNETWORKS_POWANEURALNETWORKS_PRELUANEURALNETWORKS_QUANTIZEANEURALNETWORKS_QUANTIZED_16BIT_LSTMANEURALNETWORKS_RANDOM_MULTINOMIALANEURALNETWORKS_REDUCE_ALLANEURALNETWORKS_REDUCE_ANYANEURALNETWORKS_REDUCE_MAXANEURALNETWORKS_REDUCE_MINANEURALNETWORKS_REDUCE_PRODANEURALNETWORKS_REDUCE_SUMANEURALNETWORKS_RESIZE_NEAREST_NEIGHBORANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_ROI_POOLINGANEURALNETWORKS_RSQRTANEURALNETWORKS_SELECTANEURALNETWORKS_SINANEURALNETWORKS_SLICEANEURALNETWORKS_SPLITANEURALNETWORKS_SQRTANEURALNETWORKS_TILEANEURALNETWORKS_TOPK_V2ANEURALNETWORKS_TRANSPOSE_CONV_2DANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_RNN
In Android 10 wurden viele der vorhandenen Vorgänge aktualisiert. Die Aktualisierungen beziehen sich hauptsächlich auf Folgendes:
- Unterstützung für das NCHW-Speicherlayout
- Unterstützung für Tensoren mit einem anderen Rang als 4 bei Softmax- und Normalisierungsvorgängen
- Unterstützung für erweiterte Faltungen
- Unterstützung für Eingaben mit gemischter Quantisierung in
ANEURALNETWORKS_CONCATENATION
In der folgenden Liste sind die Vorgänge aufgeführt, die in Android 10 geändert wurden. Ausführliche Informationen zu den Änderungen finden Sie in der NNAPI-Referenzdokumentation unter OperationCode.
ANEURALNETWORKS_ADDANEURALNETWORKS_AVERAGE_POOL_2DANEURALNETWORKS_BATCH_TO_SPACE_NDANEURALNETWORKS_CONCATENATIONANEURALNETWORKS_CONV_2DANEURALNETWORKS_DEPTHWISE_CONV_2DANEURALNETWORKS_DEPTH_TO_SPACEANEURALNETWORKS_DEQUANTIZEANEURALNETWORKS_DIVANEURALNETWORKS_FLOORANEURALNETWORKS_FULLY_CONNECTEDANEURALNETWORKS_L2_NORMALIZATIONANEURALNETWORKS_L2_POOL_2DANEURALNETWORKS_LOCAL_RESPONSE_NORMALIZATIONANEURALNETWORKS_LOGISTICANEURALNETWORKS_LSH_PROJECTIONANEURALNETWORKS_LSTMANEURALNETWORKS_MAX_POOL_2DANEURALNETWORKS_MEANANEURALNETWORKS_MULANEURALNETWORKS_PADANEURALNETWORKS_RELUANEURALNETWORKS_RELU1ANEURALNETWORKS_RELU6ANEURALNETWORKS_RESHAPEANEURALNETWORKS_RESIZE_BILINEARANEURALNETWORKS_RNNANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_SOFTMAXANEURALNETWORKS_SPACE_TO_BATCH_NDANEURALNETWORKS_SPACE_TO_DEPTHANEURALNETWORKS_SQUEEZEANEURALNETWORKS_STRIDED_SLICEANEURALNETWORKS_SUBANEURALNETWORKS_SVDFANEURALNETWORKS_TANHANEURALNETWORKS_TRANSPOSE
Android 9
NN HAL 1.1 wurde in Android 9 eingeführt und enthält die folgenden wichtigen Änderungen.
IDevice::prepareModel_1_1enthält einenExecutionPreference-Parameter. Ein Fahrer kann dies nutzen, um seine Vorbereitung anzupassen, da er weiß, dass die App den Akku schonen möchte oder das Modell in schnellen aufeinanderfolgenden Aufrufen ausführt.- Es wurden neun neue Vorgänge hinzugefügt:
BATCH_TO_SPACE_ND,DIV,MEAN,PAD,SPACE_TO_BATCH_ND,SQUEEZE,STRIDED_SLICE,SUB,TRANSPOSE. - Eine App kann angeben, dass 32‑Bit-Gleitkomma-Berechnungen mit einem 16‑Bit-Gleitkomma-Bereich und/oder einer 16‑Bit-Gleitkomma-Genauigkeit ausgeführt werden können, indem
Model.relaxComputationFloat32toFloat16auftruegesetzt wird. DieCapabilities-Struktur hat das zusätzliche FeldrelaxedFloat32toFloat16Performance, damit der Treiber seine entspannte Leistung an das Framework melden kann.
Android 8.1
Das erste Neural Networks HAL (1.0) wurde in Android 8.1 veröffentlicht. Weitere Informationen finden Sie unter /neuralnetworks/1.0/.