
Questa pagina fornisce una panoramica su come implementare un driver dell'API Neural Networks (NNAPI). Per ulteriori dettagli, consulta la documentazione contenuta nei file di definizione HAL in
hardware/interfaces/neuralnetworks.
Un'implementazione di esempio del driver è disponibile in
frameworks/ml/nn/driver/sample.
Per saperne di più sull'API Neural Networks, consulta API Neural Networks.
HAL Neural Networks
L'HAL Neural Networks (NN) definisce un'astrazione dei vari dispositivi,
come unità di elaborazione grafica (GPU) e processori di segnali digitali (DSP),
presenti in un prodotto (ad esempio uno smartphone o un tablet). I driver per questi
dispositivi devono essere conformi all'HAL NN. L'interfaccia è specificata nei file di definizione HAL in hardware/interfaces/neuralnetworks.
Il flusso generale dell'interfaccia tra il framework e un driver è illustrato nella figura 1.
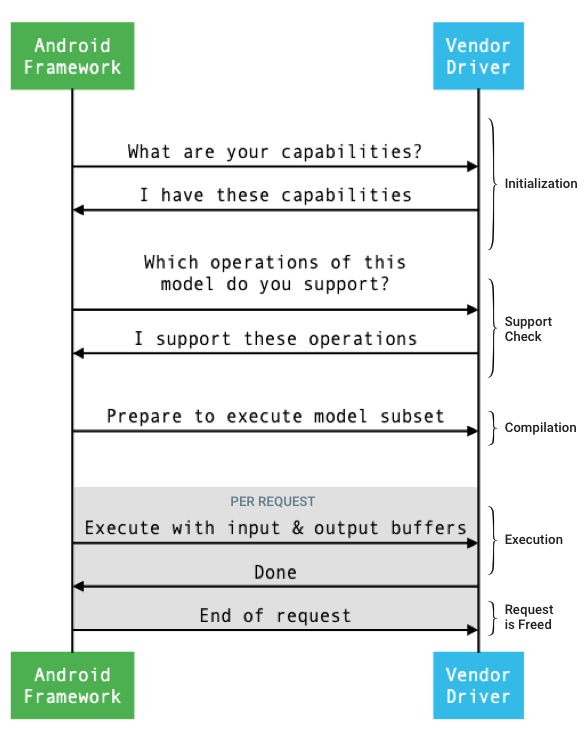
Figura 1. Flusso delle reti neurali
Inizializzazione
Durante l'inizializzazione, il framework esegue query sul driver per le sue funzionalità utilizzando
IDevice::getCapabilities_1_3.
La struttura @1.3::Capabilities include tutti i tipi di dati e
rappresenta il rendimento non rilassato utilizzando un vettore.
Per determinare come allocare i calcoli ai dispositivi disponibili, il framework utilizza le funzionalità per comprendere la velocità e l'efficienza energetica con cui ogni driver può eseguire un'esecuzione. Per fornire queste informazioni, il driver deve fornire numeri di prestazioni standardizzati basati sull'esecuzione di carichi di lavoro di riferimento.
Per determinare i valori restituiti dal driver in risposta a
IDevice::getCapabilities_1_3, utilizza l'app di benchmark NNAPI per misurare le
prestazioni per i tipi di dati corrispondenti. I modelli MobileNet v1 e v2, asr_float e tts_float sono consigliati per misurare le prestazioni per i valori in virgola mobile a 32 bit, mentre i modelli quantizzati MobileNet v1 e v2 sono consigliati per i valori quantizzati a 8 bit. Per saperne di più, consulta
Android Machine Learning Test Suite.
In Android 9 e versioni precedenti, la struttura Capabilities include informazioni sul rendimento del driver solo per tensori in virgola mobile e quantizzati e non include tipi di dati scalari.
Nell'ambito della procedura di inizializzazione, il framework potrebbe richiedere ulteriori informazioni,
utilizzando
IDevice::getType,
IDevice::getVersionString,
IDevice:getSupportedExtensions,
e
IDevice::getNumberOfCacheFilesNeeded.
Tra un riavvio del prodotto e l'altro, il framework prevede che tutte le query descritte in questa sezione riportino sempre gli stessi valori per un determinato driver. In caso contrario, un'app che utilizza quel driver potrebbe mostrare prestazioni ridotte o un comportamento errato.
Compilation
Il framework determina quali dispositivi utilizzare quando riceve una richiesta da un'app. In Android 10, le app possono rilevare e specificare i dispositivi tra cui il framework sceglie. Per ulteriori informazioni, consulta Rilevamento e assegnazione dei dispositivi.
Al momento della compilazione del modello, il framework invia il modello a ogni driver candidato chiamando IDevice::getSupportedOperations_1_3.
Ogni driver restituisce un array di valori booleani che indicano quali operazioni del modello sono supportate. Un driver può determinare di non poter
supportare una determinata operazione per diversi motivi. Ad esempio:
- Il driver non supporta il tipo di dati.
- Il driver supporta solo operazioni con parametri di input specifici. Ad esempio, un driver potrebbe supportare le operazioni di convoluzione 3x3 e 5x5, ma non 7x7.
- Il driver ha vincoli di memoria che gli impediscono di gestire grafici o input di grandi dimensioni.
Durante la compilazione, gli operandi di input, output e interni del modello, come
descritto in
OperandLifeTime,
possono avere dimensioni o rango sconosciuti. Per saperne di più, consulta Forma dell'output.
Il framework indica a ogni driver selezionato di prepararsi a eseguire un sottoinsieme del modello chiamando IDevice::prepareModel_1_3.
Ogni driver compila quindi il proprio sottoinsieme. Ad esempio, un driver potrebbe
generare codice o creare una copia riordinata dei pesi. Poiché può trascorrere un
periodo di tempo significativo tra la compilazione del modello e l'esecuzione delle richieste, le risorse come grandi blocchi di memoria del dispositivo non devono
essere assegnate durante la compilazione.
In caso di esito positivo, il driver restituisce un handle @1.3::IPreparedModel. Se il driver restituisce un codice di errore durante la preparazione del sottoinsieme del
modello, il framework esegue l'intero modello sulla CPU.
Per ridurre il tempo utilizzato per la compilazione all'avvio di un'app, un driver può memorizzare nella cache gli artefatti di compilazione. Per ulteriori informazioni, vedi Memorizzazione nella cache della compilazione.
Esecuzione
Quando un'app chiede al framework di eseguire una richiesta, il framework chiama
il metodo
IPreparedModel::executeSynchronously_1_3
HAL per impostazione predefinita per eseguire un'esecuzione sincrona su un modello preparato.
Una richiesta può essere eseguita anche in modo asincrono utilizzando il metodo execute_1_3, il metodo executeFenced (vedi Esecuzione isolata) o utilizzando un'esecuzione burst.
Le chiamate di esecuzione sincrona migliorano le prestazioni e riducono l'overhead dei thread rispetto alle chiamate asincrone perché il controllo viene restituito al processo dell'app solo dopo il completamento dell'esecuzione. Ciò significa che il driver non ha bisogno di un meccanismo separato per comunicare al processo dell'app che un'esecuzione è stata completata.
Con il metodo asincrono execute_1_3, il controllo torna al processo dell'app dopo l'avvio dell'esecuzione e il driver deve notificare al framework il completamento dell'esecuzione utilizzando @1.3::IExecutionCallback.
Il parametro Request passato al metodo execute elenca gli operandi di input e output
utilizzati per l'esecuzione. La memoria che archivia i dati degli operandi deve
utilizzare l'ordine row-major con la prima dimensione che scorre più lentamente e non deve
avere padding alla fine di ogni riga. Per saperne di più sui tipi di operandi,
vedi
Operandi.
Per i driver NN HAL 1.2 o versioni successive, quando una richiesta viene completata, lo stato di errore, la forma dell'output e le informazioni sul timing vengono restituite al framework. Durante l'esecuzione, l'output o gli operandi interni del modello possono avere una o più dimensioni sconosciute o un rango sconosciuto. Quando almeno un operando di output ha una dimensione o un rango sconosciuti, il driver deve restituire informazioni di output con dimensioni dinamiche.
Per i driver con NN HAL 1.1 o versioni precedenti, al termine di una richiesta viene restituito solo lo stato di errore. Le dimensioni degli operandi di input e output devono essere specificate completamente per il completamento corretto dell'esecuzione. Gli operandi interni possono avere una o più dimensioni sconosciute, ma devono avere un rango specificato.
Per le richieste utente che interessano più driver, il framework è responsabile di riservare la memoria intermedia e di sequenziare le chiamate a ogni driver.
È possibile avviare più richieste in parallelo sullo stesso
@1.3::IPreparedModel.
Il driver può eseguire le richieste in parallelo o serializzare le esecuzioni.
Il framework può chiedere a un driver di conservare più di un modello preparato. Ad esempio, prepara il modello m1, prepara m2, esegui la richiesta r1 su m1, esegui
r2 su m2, esegui r3 su m1, esegui r4 su m2, rilascia (descritto in
Pulizia) m1 e rilascia m2.
Per evitare una prima esecuzione lenta che potrebbe comportare un'esperienza utente scadente (ad esempio, un primo frame balbettante), il driver deve eseguire la maggior parte delle inizializzazioni nella fase di compilazione. L'inizializzazione alla prima esecuzione deve essere limitata alle azioni che influiscono negativamente sull'integrità del sistema se eseguite in anticipo, ad esempio la prenotazione di buffer temporanei di grandi dimensioni o l'aumento della frequenza di clock di un dispositivo. I driver che possono preparare solo un numero limitato di modelli simultanei potrebbero dover eseguire l'inizializzazione alla prima esecuzione.
In Android 10 o versioni successive, nei casi in cui vengono eseguite più esecuzioni con lo stesso modello preparato in rapida successione, il client può scegliere di utilizzare un oggetto burst di esecuzione per comunicare tra i processi dell'app e del driver. Per ulteriori informazioni, consulta Esecuzioni burst e code di messaggi veloci.
Per migliorare le prestazioni per più esecuzioni in rapida successione, il driver può conservare i buffer temporanei o aumentare le frequenze di clock. È consigliabile creare un thread watchdog per rilasciare le risorse se non vengono create nuove richieste dopo un periodo di tempo fisso.
Forma di output
Per le richieste in cui uno o più operandi di output non hanno tutte le dimensioni
specificate, il driver deve fornire un elenco di forme di output contenenti le
informazioni sulle dimensioni per ogni operando di output dopo l'esecuzione. Per saperne di più sulle dimensioni, consulta OutputShape.
Se un'esecuzione non va a buon fine a causa di un buffer di output sottodimensionato, il driver deve indicare quali operandi di output hanno una dimensione del buffer insufficiente nell'elenco delle forme di output e deve segnalare quante più informazioni dimensionali possibili, utilizzando zero per le dimensioni sconosciute.
Tempi
In Android 10, un'app può richiedere il tempo di esecuzione se ha specificato un singolo dispositivo da utilizzare durante il processo di compilazione. Per
maggiori dettagli, vedi
MeasureTiming
e Rilevamento e assegnazione dei dispositivi.
In questo caso, un
driver NN HAL 1.2 deve misurare la durata dell'esecuzione o segnalare UINT64_MAX (per
indicare che la durata non è disponibile) durante l'esecuzione di una richiesta. Il driver
deve ridurre al minimo qualsiasi penalità di rendimento derivante dalla misurazione della durata
dell'esecuzione.
Il driver segnala le seguenti durate in microsecondi nella struttura
Timing:
- Tempo di esecuzione sul dispositivo:non include il tempo di esecuzione nel driver, che viene eseguito sul processore host.
- Tempo di esecuzione nel driver:include il tempo di esecuzione sul dispositivo.
Queste durate devono includere il tempo in cui l'esecuzione è sospesa, ad esempio quando l'esecuzione è stata prerilasciata da altre attività o quando è in attesa che una risorsa diventi disponibile.
Quando al driver non è stato chiesto di misurare la durata dell'esecuzione o quando si verifica un errore di esecuzione, il driver deve segnalare le durate come UINT64_MAX. Anche quando al driver è stato chiesto di misurare la durata dell'esecuzione, può invece segnalare UINT64_MAX per il tempo sul dispositivo, il tempo nel driver o entrambi. Quando il driver segnala entrambe le durate come un valore diverso da
UINT64_MAX, il tempo di esecuzione nel driver deve essere uguale o superiore al tempo sul
dispositivo.
Esecuzione controllata
In Android 11, NNAPI consente alle esecuzioni di attendere un elenco di handle sync_fence e, facoltativamente, restituire un oggetto sync_fence, che viene segnalato al termine dell'esecuzione. In questo modo si riduce l'overhead per i piccoli modelli di sequenza e i casi d'uso di streaming. L'esecuzione recintata consente inoltre un'interoperabilità più efficiente con altri componenti che possono segnalare o attendere sync_fence. Per saperne di più su sync_fence, vedi
Framework di sincronizzazione.
In un'esecuzione controllata, il framework chiama il metodo
IPreparedModel::executeFenced
per avviare un'esecuzione asincrona controllata su un modello preparato con un
vettore di barriere di sincronizzazione da attendere. Se l'attività asincrona viene completata prima che la chiamata venga restituita, per sync_fence può essere restituito un handle vuoto. Deve essere restituito anche un oggetto
IFencedExecutionCallback per consentire al framework
di eseguire query sullo stato di errore e sulla durata.
Al termine di un'esecuzione, è possibile eseguire query sui due valori di tempistica seguenti che misurano la durata dell'esecuzione tramite IFencedExecutionCallback::getExecutionInfo.
timingLaunched: Durata dal momento in cui viene chiamatoexecuteFencedal momento in cuiexecuteFencedsegnalasyncFencerestituito.timingFenced: Durata dal momento in cui tutte le barriere di sincronizzazione che l'esecuzione attende vengono segnalate al momento in cuiexecuteFencedsegnalasyncFencerestituito.
Flusso di controllo
Per i dispositivi con Android 11 o versioni successive, l'NNAPI
include due operazioni di flusso di controllo, IF e WHILE, che prendono altri modelli
come argomenti e li eseguono in modo condizionale (IF) o ripetuto (WHILE). Per
maggiori informazioni su come implementare questa funzionalità, consulta
Flusso di controllo.
Qualità del servizio
In Android 11, la NNAPI include una qualità del servizio (QoS) migliorata consentendo a un'app di indicare le priorità relative dei suoi modelli, il tempo massimo previsto per la preparazione di un modello e il tempo massimo previsto per il completamento di un'esecuzione. Per maggiori informazioni, consulta Qualità del servizio.
Esegui la pulizia
Quando un'app ha finito di utilizzare un modello preparato, il framework rilascia
il riferimento all'oggetto
@1.3::IPreparedModel. Quando l'oggetto IPreparedModel non viene più referenziato, viene
eliminato automaticamente nel servizio di gestione che lo ha creato. Le risorse specifiche del modello possono essere recuperate in questo momento nell'implementazione del distruttore del driver. Se il servizio di driver vuole che l'oggetto IPreparedModel venga distrutto automaticamente quando non è più necessario al client, non deve contenere riferimenti all'oggetto IPreparedModel dopo che l'oggetto IPreparedeModel è stato restituito tramite IPreparedModelCallback::notify_1_3.
Utilizzo CPU
I driver devono utilizzare la CPU per configurare i calcoli. I driver non devono utilizzare la CPU per eseguire i calcoli del grafico perché ciò interferisce con la capacità del framework di allocare correttamente il lavoro. Il driver deve segnalare al framework le parti che non può gestire e lasciare che il framework gestisca il resto.
Il framework fornisce un'implementazione della CPU per tutte le operazioni NNAPI, ad eccezione di quelle definite dal fornitore. Per saperne di più, consulta la sezione Estensioni fornitore.
Le operazioni introdotte in Android 10 (livello API 29) hanno solo un'implementazione della CPU di riferimento per verificare che i test CTS e VTS siano corretti. Le implementazioni ottimizzate incluse nei framework di machine learning mobile sono preferite all'implementazione della CPU NNAPI.
Funzioni di utilità
Il codebase NNAPI include funzioni di utilità che possono essere utilizzate dai servizi di driver.
Il file
frameworks/ml/nn/common/include/Utils.h
contiene varie funzioni di utilità, ad esempio quelle utilizzate per la registrazione e
per la conversione tra diverse versioni di NN HAL.
VLogging:
VLOGè una macro wrapper intorno aLOGdi Android che registra il messaggio solo se il tag appropriato è impostato nella proprietàdebug.nn.vlog.initVLogMask()deve essere chiamato prima di qualsiasi chiamata aVLOG. La macroVLOG_IS_ONpuò essere utilizzata per verificare seVLOGè attualmente abilitato, consentendo di ignorare il codice di logging complesso se non è necessario. Il valore della proprietà deve essere uno dei seguenti:- Una stringa vuota, che indica che non deve essere eseguito alcun logging.
- Il token
1oall, che indica che deve essere eseguita tutta la registrazione. - Un elenco di tag, delimitati da spazi, virgole o due punti,
che indicano quale registrazione deve essere eseguita. I tag sono
compilation,cpuexe,driver,execution,manageremodel.
compliantWithV1_*: Restituiscetruese un oggetto HAL NN può essere convertito nello stesso tipo di una versione HAL diversa senza perdere informazioni. Ad esempio, la chiamata dicompliantWithV1_0suV1_2::Modelrestituiscefalsese il modello include tipi di operazioni introdotti in NN HAL 1.1 o NN HAL 1.2.convertToV1_*: converte un oggetto NN HAL da una versione a un'altra. Viene registrato un avviso se la conversione comporta una perdita di informazioni (ovvero se la nuova versione del tipo non può rappresentare completamente il valore).Funzionalità: le funzioni
nonExtensionOperandPerformanceeupdatepossono essere utilizzate per creare il campoCapabilities::operandPerformance.Esecuzione di query sulle proprietà dei tipi:
isExtensionOperandType,isExtensionOperationType,nonExtensionSizeOfData,nonExtensionOperandSizeOfData,nonExtensionOperandTypeIsScalar,tensorHasUnspecifiedDimensions.
Il file
frameworks/ml/nn/common/include/ValidateHal.h
contiene funzioni di utilità per verificare che un oggetto NN HAL sia valido
in base alla specifica della sua versione HAL.
validate*: restituiscetruese l'oggetto NN HAL è valido in base alla specifica della versione HAL. I tipi di OEM e di estensione non vengono convalidati. Ad esempio,validateModelrestituiscefalsese il modello contiene un'operazione che fa riferimento a un indice operando inesistente o a un'operazione non supportata in quella versione HAL.
Il file
frameworks/ml/nn/common/include/Tracing.h
contiene macro per semplificare l'aggiunta
di informazioni systracing al codice delle reti neurali.
Per un esempio, consulta le invocazioni della macro NNTRACE_* nel
driver di esempio.
Il file
frameworks/ml/nn/common/include/GraphDump.h
contiene una funzione di utilità per scaricare i contenuti di un Model in formato grafico
a scopo di debug.
graphDump: scrive una rappresentazione del modello nel formato Graphviz (.dot) nel flusso specificato (se fornito) o in logcat (se non viene fornito alcun flusso).
Convalida
Per testare l'implementazione dell'NNAPI, utilizza i test VTS e CTS inclusi nel framework Android. VTS esegue test sui driver direttamente (senza utilizzare il framework), mentre CTS li esegue indirettamente tramite il framework. Questi testano ogni metodo API e verificano che tutte le operazioni supportate dai driver funzionino correttamente e forniscano risultati che soddisfino i requisiti di precisione.
I requisiti di precisione in CTS e VTS per la NNAPI sono i seguenti:
Rappresentazione in virgola mobile: abs(expected - actual) <= atol + rtol * abs(expected); where:
- Per fp32, atol = 1e-5f, rtol = 5.0f * 1.1920928955078125e-7
- Per fp16, atol = rtol = 5.0f * 0.0009765625f
Quantizzato:errore di 1 (tranne per
mobilenet_quantized, che è di 3)Booleano:corrispondenza esatta
Un modo in cui CTS testa NNAPI è generando grafici pseudocasuali fissi
utilizzati per testare e confrontare i risultati di esecuzione di ogni driver con l'implementazione di riferimento di NNAPI. Per i driver con NN HAL 1.2 o versioni successive, se i risultati non soddisfano i criteri di precisione, CTS segnala un errore e scarica un file di specifiche per il modello non riuscito in /data/local/tmp per il debug.
Per ulteriori dettagli sui criteri di precisione, consulta
TestRandomGraph.cpp
e
TestHarness.h.
Fuzz testing
Lo scopo del fuzzing è trovare arresti anomali, asserzioni, violazioni di memoria o comportamenti indefiniti generali nel codice in fase di test a causa di fattori quali input imprevisti. Per il fuzzing NNAPI, Android utilizza test basati su libFuzzer, che sono efficienti nel fuzzing perché utilizzano la copertura delle righe dei precedenti scenari di test per generare nuovi input casuali. Ad esempio, libFuzzer privilegia i casi di test che vengono eseguiti su nuove righe di codice. In questo modo si riduce notevolmente il tempo necessario ai test per trovare il codice problematico.
Per eseguire il fuzz testing per convalidare l'implementazione del driver, modifica
frameworks/ml/nn/runtime/test/android_fuzzing/DriverFuzzTest.cpp
nell'utilità di test libneuralnetworks_driver_fuzzer disponibile in AOSP per includere
il codice del driver. Per saperne di più sul fuzzing NNAPI, consulta
frameworks/ml/nn/runtime/test/android_fuzzing/README.md.
Sicurezza
Poiché i processi delle app comunicano direttamente con il processo di un driver,
i driver devono convalidare gli argomenti delle chiamate che ricevono. Questa convalida
è verificata da VTS. Il codice di convalida si trova in
frameworks/ml/nn/common/include/ValidateHal.h.
I conducenti devono anche assicurarsi che le app non interferiscano con altre app quando utilizzano lo stesso dispositivo.
Android Machine Learning Test Suite
La suite di test di machine learning (MLTS) di Android è un benchmark NNAPI incluso in CTS e VTS per convalidare l'accuratezza dei modelli reali sui dispositivi dei fornitori. Il benchmark valuta la latenza e l'accuratezza e confronta i risultati dei driver con i risultati ottenuti utilizzando TF Lite in esecuzione sulla CPU, per lo stesso modello e gli stessi set di dati. In questo modo, si garantisce che la precisione di un driver non sia peggiore dell'implementazione di riferimento della CPU.
Gli sviluppatori della piattaforma Android utilizzano MLTS anche per valutare la latenza e l'accuratezza dei driver.
Il benchmark NNAPI è disponibile in due progetti in AOSP:
platform/test/mlts/benchmark(app di benchmark)platform/test/mlts/models(modelli e set di dati)
Modelli e set di dati
Il benchmark NNAPI utilizza i seguenti modelli e set di dati.
- MobileNetV1 float e u8 quantizzati in dimensioni diverse, eseguiti su un piccolo sottoinsieme (1500 immagini) del set di dati Open Images v4.
- MobileNetV2 float e u8 quantizzati in dimensioni diverse, eseguiti su un piccolo sottoinsieme (1500 immagini) di Open Images Dataset v4.
- Modello acustico basato su LSTM (Long Short-Term Memory) per la sintesi vocale, eseguito su un piccolo sottoinsieme del set CMU Arctic.
- Modello acustico basato su LSTM per il riconoscimento vocale automatico, eseguito su un piccolo sottoinsieme del set di dati LibriSpeech.
Per saperne di più, vedi platform/test/mlts/models.
Stress test
La suite di test di machine learning di Android include una serie di test di arresto anomalo per convalidare la resilienza dei driver in condizioni di utilizzo intenso o in casi limite del comportamento dei client.
Tutti i crash test forniscono le seguenti funzionalità:
- Rilevamento del blocco: se il client NNAPI si blocca durante un test, il test non riesce con il motivo dell'errore
HANGe la suite di test passa al test successivo. - Rilevamento arresto anomalo del client NNAPI:i test sopravvivono agli arresti anomali del client e i test
non riescono con il motivo dell'errore
CRASH. - Rilevamento arresto anomalo del driver: i test possono rilevare un arresto anomalo del driver
che causa un errore in una chiamata NNAPI. Tieni presente che potrebbero verificarsi arresti anomali nei
processi del driver che non causano un errore NNAPI e non causano l'esito negativo del test. Per coprire questo tipo di errore, ti consigliamo di eseguire il comando
tailnel log di sistema per errori o arresti anomali correlati ai driver. - Targeting di tutti gli acceleratori disponibili: i test vengono eseguiti su tutti i driver disponibili.
Tutti i crash test hanno i seguenti quattro possibili risultati:
SUCCESS: l'esecuzione è stata completata senza errori.FAILURE: esecuzione non riuscita. In genere causato da un errore durante il test di un modello, che indica che il driver non è riuscito a compilare o eseguire il modello.HANG: il processo di test non risponde più.CRASH: il processo di test è andato in arresto anomalo.
Per saperne di più sui test di stress e per visualizzare un elenco completo dei test di arresto anomalo, consulta
platform/test/mlts/benchmark/README.txt.
Utilizzare MLTS
Per utilizzare MLTS:
- Collega un dispositivo di destinazione alla workstation e assicurati che sia
raggiungibile tramite
adb.
Esporta la variabile di ambiente
ANDROID_SERIALdel dispositivo di destinazione se sono connessi più dispositivi. cdnella directory di origine di primo livello di Android.source build/envsetup.sh lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available. ./test/mlts/benchmark/build_and_run_benchmark.shAl termine di un'esecuzione del benchmark, i risultati vengono presentati come pagina HTML e inviati a
xdg-open.
Per saperne di più, vedi platform/test/mlts/benchmark/README.txt.
Versioni HAL delle reti neurali
Questa sezione descrive le modifiche introdotte nelle versioni di Android e Neural Networks HAL.
Android 11
Android 11 introduce NN HAL 1.3, che include le seguenti modifiche importanti.
- Supporto della quantizzazione a 8 bit con segno in NNAPI. Aggiunge il tipo di operando
TENSOR_QUANT8_ASYMM_SIGNED. I driver con NN HAL 1.3 che supportano operazioni con quantizzazione non firmata devono supportare anche le varianti firmate di queste operazioni. Quando vengono eseguite versioni firmate e non firmate della maggior parte delle operazioni di quantizzazione, i driver devono produrre gli stessi risultati fino a un offset di 128. Esistono cinque eccezioni a questo requisito:CAST,HASHTABLE_LOOKUP,LSH_PROJECTION,PAD_V2eQUANTIZED_16BIT_LSTM. L'operazioneQUANTIZED_16BIT_LSTMnon supporta gli operandi con segno e le altre quattro operazioni supportano la quantizzazione con segno, ma non richiedono che i risultati siano gli stessi. - Supporto per le esecuzioni recintate in cui il framework chiama il metodo
IPreparedModel::executeFencedper avviare un'esecuzione asincrona recintata su un modello preparato con un vettore di recinti di sincronizzazione da attendere. Per saperne di più, consulta Esecuzione controllata. - Supporto per il flusso di controllo. Aggiunge le operazioni
IFeWHILE, che accettano altri modelli come argomenti e li eseguono in modo condizionale (IF) o ripetutamente (WHILE). Per saperne di più, consulta Flusso di controllo. - Migliore qualità del servizio (QoS), in quanto le app possono indicare le priorità relative dei propri modelli, il tempo massimo previsto per la preparazione di un modello e il tempo massimo previsto per il completamento di un'esecuzione. Per saperne di più, consulta Qualità del servizio.
- Supporto per i domini di memoria che forniscono interfacce di allocazione per buffer gestiti dai driver. Ciò consente di passare le memorie native del dispositivo tra le esecuzioni, eliminando la copia e la trasformazione non necessarie dei dati tra esecuzioni consecutive sullo stesso driver. Per ulteriori informazioni, vedi Domini di memoria.
Android 10
Android 10 introduce NN HAL 1.2, che include le seguenti modifiche importanti.
- La struct
Capabilitiesinclude tutti i tipi di dati, inclusi i tipi di dati scalari, e rappresenta le prestazioni non rilassate utilizzando un vettore anziché campi denominati. - I metodi
getVersionStringegetTypeconsentono al framework di recuperare il tipo di dispositivo (DeviceType) e le informazioni sulla versione. Vedi Rilevamento e assegnazione dei dispositivi. - Il metodo
executeSynchronouslyviene chiamato per impostazione predefinita per eseguire un'esecuzione in modo sincrono. Il metodoexecute_1_2indica al framework di eseguire un'esecuzione in modo asincrono. Vedi Esecuzione. - Il parametro
MeasureTimingperexecuteSynchronously,execute_1_2e l'esecuzione burst specifica se il driver deve misurare la durata dell'esecuzione. I risultati vengono riportati nella strutturaTiming. Vedi Tempistiche. - Supporto per le esecuzioni in cui uno o più operandi di output hanno una dimensione o un rango sconosciuti. Vedi Forma dell'output.
- Supporto per le estensioni del fornitore, che sono raccolte di operazioni e tipi di dati definiti dal fornitore. Il driver segnala le estensioni supportate tramite
il metodo
IDevice::getSupportedExtensions. Consulta Estensioni fornitore. - Possibilità per un oggetto burst di controllare un insieme di esecuzioni burst utilizzando code di messaggi veloci (FMQ) per comunicare tra i processi dell'app e del driver, riducendo la latenza. Consulta Esecuzioni burst e code di messaggi veloci.
- Supporto di AHardwareBuffer per consentire al driver di eseguire le esecuzioni senza copiare i dati. Vedi AHardwareBuffer.
- Miglioramento del supporto per la memorizzazione nella cache degli artefatti di compilazione per ridurre il tempo utilizzato per la compilazione all'avvio di un'app. Vedi Memorizzazione nella cache della compilazione.
Android 10 introduce i seguenti tipi di operandi e operazioni.
-
ANEURALNETWORKS_BOOLANEURALNETWORKS_FLOAT16ANEURALNETWORKS_TENSOR_BOOL8ANEURALNETWORKS_TENSOR_FLOAT16ANEURALNETWORKS_TENSOR_QUANT16_ASYMMANEURALNETWORKS_TENSOR_QUANT16_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL
-
ANEURALNETWORKS_ABSANEURALNETWORKS_ARGMAXANEURALNETWORKS_ARGMINANEURALNETWORKS_AXIS_ALIGNED_BBOX_TRANSFORMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_RNNANEURALNETWORKS_BOX_WITH_NMS_LIMITANEURALNETWORKS_CASTANEURALNETWORKS_CHANNEL_SHUFFLEANEURALNETWORKS_DETECTION_POSTPROCESSINGANEURALNETWORKS_EQUALANEURALNETWORKS_EXPANEURALNETWORKS_EXPAND_DIMSANEURALNETWORKS_GATHERANEURALNETWORKS_GENERATE_PROPOSALSANEURALNETWORKS_GREATERANEURALNETWORKS_GREATER_EQUALANEURALNETWORKS_GROUPED_CONV_2DANEURALNETWORKS_HEATMAP_MAX_KEYPOINTANEURALNETWORKS_INSTANCE_NORMALIZATIONANEURALNETWORKS_LESSANEURALNETWORKS_LESS_EQUALANEURALNETWORKS_LOGANEURALNETWORKS_LOGICAL_ANDANEURALNETWORKS_LOGICAL_NOTANEURALNETWORKS_LOGICAL_ORANEURALNETWORKS_LOG_SOFTMAXANEURALNETWORKS_MAXIMUMANEURALNETWORKS_MINIMUMANEURALNETWORKS_NEGANEURALNETWORKS_NOT_EQUALANEURALNETWORKS_PAD_V2ANEURALNETWORKS_POWANEURALNETWORKS_PRELUANEURALNETWORKS_QUANTIZEANEURALNETWORKS_QUANTIZED_16BIT_LSTMANEURALNETWORKS_RANDOM_MULTINOMIALANEURALNETWORKS_REDUCE_ALLANEURALNETWORKS_REDUCE_ANYANEURALNETWORKS_REDUCE_MAXANEURALNETWORKS_REDUCE_MINANEURALNETWORKS_REDUCE_PRODANEURALNETWORKS_REDUCE_SUMANEURALNETWORKS_RESIZE_NEAREST_NEIGHBORANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_ROI_POOLINGANEURALNETWORKS_RSQRTANEURALNETWORKS_SELECTANEURALNETWORKS_SINANEURALNETWORKS_SLICEANEURALNETWORKS_SPLITANEURALNETWORKS_SQRTANEURALNETWORKS_TILEANEURALNETWORKS_TOPK_V2ANEURALNETWORKS_TRANSPOSE_CONV_2DANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_RNN
Android 10 introduce aggiornamenti a molte delle operazioni esistenti. Gli aggiornamenti riguardano principalmente quanto segue:
- Supporto del layout di memoria NCHW
- Supporto per tensori con rango diverso da 4 nelle operazioni softmax e di normalizzazione
- Supporto per le convoluzioni dilatate
- Supporto per input con quantizzazione mista in
ANEURALNETWORKS_CONCATENATION
L'elenco seguente mostra le operazioni modificate in Android 10. Per tutti i dettagli delle modifiche, consulta OperationCode nella documentazione di riferimento di NNAPI.
ANEURALNETWORKS_ADDANEURALNETWORKS_AVERAGE_POOL_2DANEURALNETWORKS_BATCH_TO_SPACE_NDANEURALNETWORKS_CONCATENATIONANEURALNETWORKS_CONV_2DANEURALNETWORKS_DEPTHWISE_CONV_2DANEURALNETWORKS_DEPTH_TO_SPACEANEURALNETWORKS_DEQUANTIZEANEURALNETWORKS_DIVANEURALNETWORKS_FLOORANEURALNETWORKS_FULLY_CONNECTEDANEURALNETWORKS_L2_NORMALIZATIONANEURALNETWORKS_L2_POOL_2DANEURALNETWORKS_LOCAL_RESPONSE_NORMALIZATIONANEURALNETWORKS_LOGISTICANEURALNETWORKS_LSH_PROJECTIONANEURALNETWORKS_LSTMANEURALNETWORKS_MAX_POOL_2DANEURALNETWORKS_MEANANEURALNETWORKS_MULANEURALNETWORKS_PADANEURALNETWORKS_RELUANEURALNETWORKS_RELU1ANEURALNETWORKS_RELU6ANEURALNETWORKS_RESHAPEANEURALNETWORKS_RESIZE_BILINEARANEURALNETWORKS_RNNANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_SOFTMAXANEURALNETWORKS_SPACE_TO_BATCH_NDANEURALNETWORKS_SPACE_TO_DEPTHANEURALNETWORKS_SQUEEZEANEURALNETWORKS_STRIDED_SLICEANEURALNETWORKS_SUBANEURALNETWORKS_SVDFANEURALNETWORKS_TANHANEURALNETWORKS_TRANSPOSE
Android 9
L'HAL NN 1.1 è stato introdotto in Android 9 e include le seguenti modifiche notevoli.
IDevice::prepareModel_1_1include un parametroExecutionPreference. Un conducente può utilizzare questo parametro per regolare la preparazione, sapendo che l'app preferisce risparmiare batteria o eseguirà il modello in chiamate rapide successive.- Sono state aggiunte nove nuove operazioni:
BATCH_TO_SPACE_ND,DIV,MEAN,PAD,SPACE_TO_BATCH_ND,SQUEEZE,STRIDED_SLICE,SUB,TRANSPOSE. - Un'app può specificare che i calcoli in virgola mobile a 32 bit possono essere eseguiti
utilizzando l'intervallo e/o la precisione in virgola mobile a 16 bit impostando
Model.relaxComputationFloat32toFloat16sutrue. La strutturaCapabilitiesha il campo aggiuntivorelaxedFloat32toFloat16Performancein modo che il driver possa segnalare le sue prestazioni rilassate al framework.
Android 8.1
L'HAL Neural Networks (1.0) iniziale è stato rilasciato in Android 8.1. Per saperne
di più, vedi
/neuralnetworks/1.0/.