
Android는 Android 가상화 프레임워크를 구현하는 데 필요한 모든 구성요소의 참조 구현을 제공합니다. 현재 이 구현은 ARM64로 제한됩니다. 이 페이지에서는 프레임워크 아키텍처에 관해 설명합니다.
배경
Arm 아키텍처에서는 최대 4개의 예외 수준을 허용하며, 예외 수준 0(EL0)이 가장 낮은 권한이고 예외 수준 3(EL3)이 가장 높은 권한입니다. Android 코드베이스의 가장 큰 부분(모든 사용자 공간 구성요소)은 EL0에서 실행됩니다. 일반적으로 'Android'라고 하는 나머지 부분은 EL1에서 실행되는 Linux 커널입니다.
EL2 레이어를 사용하면 EL1/EL0에서 개별 pVM에 메모리와 기기를 분리할 수 있는 하이퍼바이저를 도입할 수 있으며 강력한 비밀유지와 무결성이 보장됩니다.
하이퍼바이저
보호된 커널 기반 가상 머신(pKVM)은 Linux KVM 하이퍼바이저에 기반하여 구축됩니다. 이 하이퍼바이저는 생성 시 '보호됨'으로 표시된 게스트 가상 머신에서 실행되는 페이로드에 대한 액세스를 제한할 수 있는 기능으로 확장되었습니다.
KVM/arm64는 특정 CPU 기능, 즉 가상화 호스트 확장 프로그램(VHE)(ARMv8.1 이상)의 가용성에 따라 서로 다른 실행 모드를 지원합니다. 일반적으로 비 VHE 모드로 알려진 이러한 모드 중 하나에서 하이퍼바이저 코드는 부팅 중에 커널 이미지에서 분할되어 EL2에 설치되는 반면 커널 자체는 EL1에서 실행됩니다. Linux 코드베이스의 일부이지만 KVM의 EL2 구성요소는 여러 EL1 간의 전환을 담당하는 작은 구성요소로, 호스트의 커널에 의해 완전히 제어됩니다.
하이퍼바이저 구성요소는 Linux로 컴파일되지만 vmlinux 이미지의 별도 전용 메모리 섹션에 있습니다. pKVM은 Android 호스트 커널 및 사용자 공간에 제한을 둘 수 있고 게스트 메모리와 하이퍼바이저에 대한 호스트 액세스를 제한하는 새로운 기능을 사용해 하이퍼바이저 코드를 확장하는 방식으로 이 설계를 활용합니다.
부팅 절차
pKVM 부팅 절차가 그림 1에 묘사되어 있습니다. 첫 번째 단계는 EL2에서 부트로더가 pKVM 지원 Linux 커널에 진입하는 것입니다. 초기 부팅 중에 커널은 부트로더가 EL2에서 실행 중인 것을 감지하고 스스로 권한을 EL1로 해제하고 pKVM을 벗어납니다. 이 시점부터 Linux 커널은 정상적인 부팅으로 넘어가고, 사용자 공간에 도달할 때까지 필요한 모든 기기 드라이버를 로드합니다. 이러한 단계는 pKVM의 제어하에서 발생합니다.
부팅 절차에서는 부트로더가 초기 부팅 중에만 커널 이미지의 무결성을 유지한다고 여깁니다. 커널은 권한이 해제되면 더 이상 하이퍼바이저의 신뢰를 받지 못하는 것으로 간주되고, 그러면 하이퍼바이저는 커널이 손상된 경우에도 스스로를 보호해야 합니다.
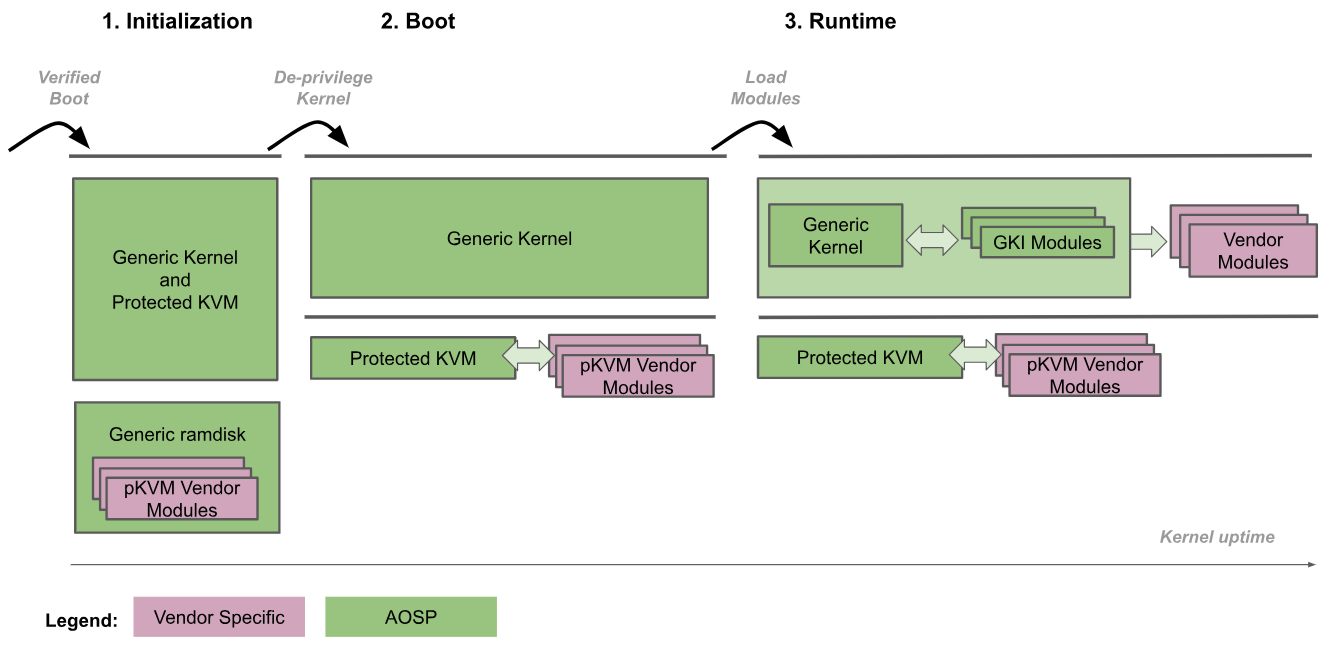
Android 커널과 하이퍼바이저를 동일한 바이너리 이미지에 두면 둘 사이에 매우 긴밀하게 연결된 통신 인터페이스가 형성됩니다. 이러한 긴밀한 결합은 두 구성요소의 원자적 업데이트를 보장합니다. 따라서 두 구성요소 간의 인터페이스를 안정적으로 유지할 필요가 없으며 장기 유지관리 가능성을 훼손시키지 않으면서 상당한 유연성을 제공합니다. 또한 긴밀한 결합에서는 두 구성요소가 협력할 수 있을 때 하이퍼바이저에서 보장하는 보안에 아무런 영향을 주지 않고도 성능이 최적화됩니다.
그 외에도 Android 생태계에 GKI를 채택하면 pKVM 하이퍼바이저를 커널과 동일한 바이너리의 Android 기기에 자동으로 배포할 수 있습니다.
CPU 메모리 액세스 차단
ARM 아키텍처는 두 개의 독립된 단계로 분할된 메모리 관리 단위(MMU)를 지정합니다. 이 두 단계는 모두 주소 변환을 구현하고 메모리의 서로 다른 부분에 대한 액세스 제어를 구현하는 데 사용할 수 있습니다. 1단계 MMU는 EL1에 의해 제어되고 첫 번째 수준의 주소 변환을 허용합니다. 1단계 MMU는 각 사용자 공간 프로세스와 자체 가상 주소 공간에 제공된 가상 주소 공간을 Linux가 관리하는 데 사용됩니다.
2단계 MMU는 EL2에 의해 제어되고, 1단계 MMU의 출력 주소에 두 번째 주소 변환을 적용함으로써 실제 주소(PA)를 생성합니다. 2단계 변환은 하이퍼바이저가 모든 게스트 VM의 메모리 액세스를 제어하고 변환하는 데 사용할 수 있습니다. 그림 2에서와 같이 변환의 두 단계가 모두 사용 설정된 경우 1단계의 출력 주소를 중간 실제 주소(IPA)라고 합니다. 참고: 가상 주소(VA)는 IPA로 변환된 다음 PA로 변환됩니다.
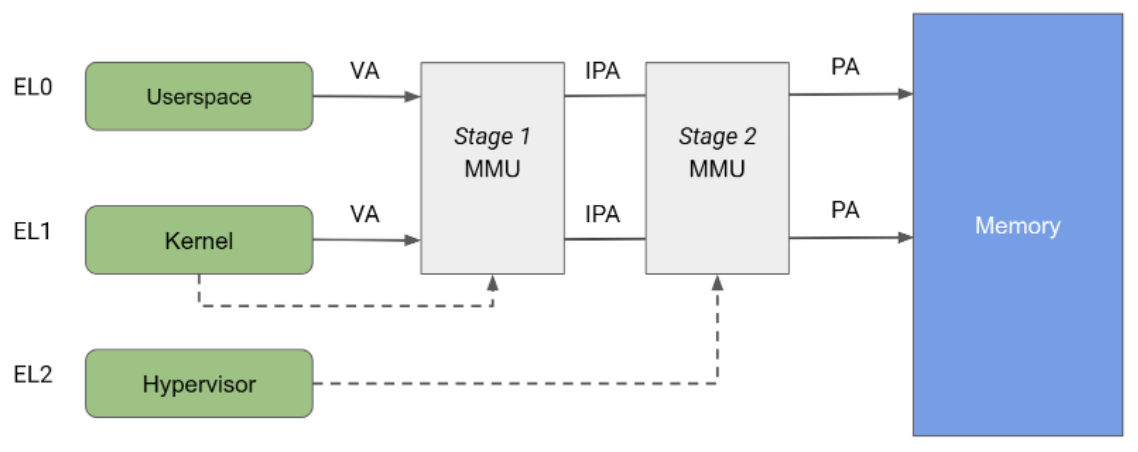
기존에 KVM은 게스트 실행 중에는 2단계 변환이 사용 설정된 상태에서 실행되었고, 호스트 Linux 커널 실행 중에는 2단계 변환이 중지된 상태에서 실행되었습니다. 이 같은 아키텍처에서는 호스트 1단계 MMU로부터의 메모리 액세스가 2단계 MMU를 통과할 수 있으므로 호스트에서 게스트 메모리 페이지로 무제한 액세스가 가능합니다. 반면 pKVM은 호스트 컨텍스트에서도 2단계 보호를 사용 설정하고 호스트 대신 하이퍼바이저에 게스트 메모리 페이지를 보호하는 역할을 맡깁니다.
KVM은 2단계의 주소 변환을 최대한 활용하여 게스트를 위한 복합적인 IPA/PA 매핑을 구현합니다. 그러면 물리적으로는 단편화되어 있지만 게스트를 위한 연속 메모리 효과가 생성됩니다. 그러나 호스트에 2단계 MMU를 사용하는 것은 액세스 제어에 한정됩니다. 호스트 2단계는 ID 매핑되므로, 호스트 IPA 공간의 인접 메모리가 PA 공간에 인접하게 됩니다. 이러한 아키텍처에서는 페이지 테이블에 대규모 매핑을 사용할 수 있으므로 결과적으로 TLB(Translation Lookaside Buffer)의 로드를 줄일 수 있습니다 PA가 ID 매핑의 색인을 생성할 수 있으므로 호스트 2단계는 페이지 테이블에서 페이지 소유권을 직접 추적하는 데도 사용됩니다.
직접 메모리 액세스(DMA) 방지
앞서 설명한 것처럼 CPU 페이지 테이블의 Linux 호스트에서 게스트 페이지를 매핑 해제하는 것은 게스트 메모리를 보호하는 데 반드시 필요한 단계이지만, 이것만으로는 부족합니다. 또한 pKVM은 호스트 커널의 제어하에 DMA 지원 기기에서 이루어진 메모리 액세스와 악의적인 호스트의 DMA 공격 가능성을 차단해야 합니다. 이러한 기기가 게스트 메모리에 액세스하지 못하도록 하기 위해 pKVM에는 그림 3에서와 같이 시스템의 DMA 지원 기기마다 입력-출력 메모리 관리 단위(IOMMU) 하드웨어가 필요합니다.
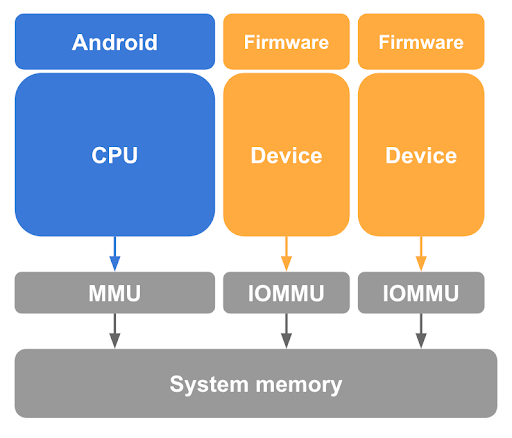
최소한 IOMMU 하드웨어는 페이지 세밀도에서 기기에 물리적 메모리에 대한 읽기/쓰기 권한을 부여 및 취소할 수 있는 방법을 제공합니다. 그러나 pVM이 ID 매핑 2단계를 가정하므로 이 IOMMU 하드웨어는 pVM에서의 기기 사용을 제한합니다.
가상 머신 간의 격리를 가능하게 하려면 다른 항목을 대신하여 생성된 메모리 트랜잭션이 IOMMU에서 구별 가능해야 합니다. 그래야 적절한 페이지 테이블 집합을 변환에 사용할 수 있기 때문입니다.
또한 EL2에서 SoC 관련 코드의 양을 줄이는 것은 pKVM의 신뢰할 수 있는 컴퓨팅 기반(TCB)을 전반적으로 줄이기 위한 핵심 전략이고, 하이퍼바이저에 IOMMU 드라이버를 포함하는 것에는 배치됩니다. 이 문제를 완화하기 위해 EL1의 호스트가 전력 관리, 초기화, 인터럽트 처리(해당하는 경우)와 같은 보조 IOMMU 관리 작업을 담당합니다.
그러나 호스트가 기기 상태를 제어하게 하려면 다른 방법으로(예:기기 초기화) 권한 확인을 우회할 수 없도록 IOMMU 하드웨어의 프로그래밍 인터페이스에 관한 추가 요구사항을 충족해야 합니다.
Arm 기기와 관련해 격리와 직접 할당을 모두 가능케 하는 표준 및 효과적으로 지원되는 IOMMU는 Arm 시스템 메모리 관리 단위(SMMU) 아키텍처입니다. 이 아키텍처는 권장되는 참조 솔루션입니다.
메모리 소유권
부팅 시 모든 비 하이퍼바이저 메모리는 모두 호스트가 소유하고 있는 것으로 가정되고 보통 하이퍼바이저에 의해 추적됩니다. pVM이 생성되면 호스트는 pVM이 부팅할 수 있도록 메모리 페이지를 제공하고 하이퍼바이저는 그러한 페이지의 소유권을 호스트에서 pVM으로 전환합니다. 따라서 하이퍼바이저는 호스트가 페이지에 다시 액세스하지 못하도록 호스트의 2단계 페이지 테이블에 액세스 제어 제한을 적용하여 게스트에 기밀성을 제공합니다.
호스트와 게스트 간의 통신은 이 두 요소 간에 제어된 메모리 공유를 통해 가능합니다. 게스트는 하이퍼콜(hypercall)을 통해 호스트 2단계 페이지 테이블의 페이지를 다시 매핑하도록 하이퍼바이저에 지시하여 일부 페이지를 호스트와 다시 공유할 수 있습니다. 마찬가지로 호스트와 TrustZone의 통신은 메모리 공유 또는 대여 작업을 통해 이루어지며, 이 모든 작업은 pKVM이 Firmware Framework for Arm(FF-A) 사양을 통해 면밀히 모니터링되고 제어됩니다.
하이퍼바이저는 시스템 내 모든 메모리 페이지의 소유권을 추적하고 메모리 페이지가 다른 항목에 공유 또는 대여되었는지를 추적합니다. 이러한 상태 추적은 대부분 호스트와 게스트의 2단계 페이지 테이블에 연결된 메타데이터를 통해 이루어지며, 이때 페이지 테이블 항목(PTE)의 예약된 비트(이름에서 알 수 있듯이 소프트웨어용으로 예약됨)를 사용합니다.
호스트는 하이퍼바이저에 의해 액세스할 수 없는 페이지에 액세스하려고 해서는 안 됩니다. 잘못된 호스트 액세스가 발생하면 하이퍼바이저가 동기식 예외를 호스트에 삽입하고, 이로 인해 책임 사용자 공간 작업에서 SEGV 신호를 수신하거나 호스트 커널이 비정상 종료될 수 있습니다. 실수로 인한 액세스를 방지하기 위해 게스트에 제공된 페이지는 호스트 커널의 스왑 또는 병합 대상이 아닙니다.
인터럽트 처리 및 타이머
인터럽트는 게스트와 기기가 상호작용하는 방식과 CPU 간 통신에 필수 요소입니다. 여기서 프로세서 간 인터럽트(IPI)는 주요 통신 메커니즘입니다. KVM 모델은 모든 가상 인터럽트 관리를 EL1의 호스트에 위임하는 용도이며, 이를 위해 하이퍼바이저의 신뢰할 수 없는 부분처럼 동작합니다.
pKVM은 기존 KVM 코드를 기반으로 전체 Generic Interrupt Controller 버전 3(GICv3) 에뮬레이션을 제공합니다. 타이머와 IPI는 신뢰할 수 없는 에뮬레이션 코드의 일부로 처리됩니다.
GICv3 지원
EL1과 EL2 간의 인터페이스는 인터럽트와 관련된 하이퍼바이저 레지스터의 사본을 포함하여 전체 인터럽트 상태가 EL1 호스트에 표시되도록 해야 합니다. 이 가시성은 일반적으로 공유 메모리 영역(가상 CPU(vCPU)당 하나)을 사용하여 확보됩니다.
시스템 레지스터 런타임 지원 코드는 Software Generated Interrupt Register(SGIR) 및 Deactivate Interrupt Register(DIR) 레지스터 트래핑만 지원하도록 간소화할 수 있습니다. 아키텍처는 이러한 레지스터가 항상 EL2에 트래핑되도록 지시하지만, 다른 트랩은 지금까지 오류를 완화하는 정도로만 유용했습니다. 나머지는 모두 하드웨어에서 처리됩니다.
MMIO 측면에서 모든 요소는 KVM의 현재 인프라를 모두 재사용하며 EL1에서 에뮬레이션됩니다. 마지막으로 Wait for Interrupt(WFI)는 KVM이 사용하는 기본 예약 프리미티브 중 하나이므로 항상 EL1에 전달됩니다.
타이머 지원
가상 타이머의 비교 연산자 값은 vCPU가 차단된 상태에서 EL1이 타이머 인터럽트를 삽입할 수 있도록 각 트래핑 WFI에서 EL1에 노출되어야 합니다. 실제 타이머는 완전히 에뮬레이션되고 모든 트랩은 EL1에 전달됩니다.
MMIO 처리
가상 머신 모니터(VMM)와 통신하고 GIC 에뮬레이션을 실행하려면 추가 분류를 위해 MMIO 트랩이 EL1의 호스트에 다시 전달되어야 합니다. pKVM에는 다음이 필요합니다.
- IPA 및 액세스 크기
- 쓰기의 경우 데이터
- 트래핑 시 CPU의 엔디언
또한 범용 레지스터(GPR)를 소스/대상으로 사용하는 트랩은 추상 전송 의사 레지스터를 사용하여 전달됩니다.
게스트 인터페이스
게스트는 트랩된 영역에 대한 메모리 액세스와 하이퍼콜의 조합을 사용하여 보호된 게스트와 통신할 수 있습니다. 하이퍼콜은 SMCCC 표준에 따라 노출되고, KVM의 공급업체 할당을 위해 예약된 범위를 갖습니다. 다음 하이퍼콜은 pKVM 게스트에 특히 중요합니다.
일반 하이퍼콜
- PSCI는 온라인 처리, 오프라인 처리, 시스템 종료를 비롯한 vCPU의 수명 주기를 제어하는 표준 메커니즘을 게스트에 제공합니다.
- TRNG는 호출을 EL3에 전달하는 pKVM에서 엔트로피를 요청하는 표준 메커니즘을 게스트에 제공합니다. 이 메커니즘은 하드웨어 랜덤 숫자 생성기(RNG)를 가상화할 때 호스트를 신뢰할 수 없는 경우에 특히 유용합니다.
pKVM 하이퍼콜
- 호스트와 메모리 공유. 처음에 모든 게스트 메모리는 호스트에 액세스할 수 없습니다. 하지만 공유 메모리 통신 및 공유 버퍼를 사용하는 반가상화된 기기에는 호스트 액세스가 필요합니다. 호스트와 페이지를 공유하거나 공유 취소를 위한 하이퍼콜을 사용하면, 게스트가 핸드셰이크 없이도 메모리의 어떤 부분을 Android의 나머지 부분에 액세스할 수 있도록 할지 정확히 결정할 수 있습니다.
- 호스트에 대한 메모리 액세스 트래핑 일반적으로 KVM 게스트가 유효한 메모리 영역에 해당하지 않는 주소에 액세스하는 경우, vCPU 스레드는 호스트 방향으로 나가고 일반적으로 MMIO에 액세스가 사용되고 사용자 공간에서 VMM에 의해 에뮬레이션됩니다. 이 처리를 용이하게 하려면 pKVM은 주소, 레지스터 매개변수, 호스트에 다시 전송되는 콘텐츠 등 결함이 있는 지침에 관한 세부정보를 알려야 합니다. 트랩이 예상되지 않더라도 보호된 게스트에서 의도치 않게 민감한 정보가 노출될 수 있기 때문입니다. 결함이 있는 IPA 범위를 호스트에 대한 트래핑 액세스가 허용된 범위로 식별하기 위해 게스트가 이전에 하이퍼콜을 호출한 경우를 제외하고, pKVM은 이러한 결함을 심각한 결함으로 처리하여 이 문제를 해결합니다. 이러한 해결 방식을 MMIO 보호라고 합니다.
가상 I/O 기기(virtio)
Virtio는 반가상화된 기기를 구현하고 이와 상호작용하기 위해 여러 환경에서 널리 사용되는 보편적인 표준입니다. 보호되는 게스트에 노출되는 대부분의 기기는 virtio를 사용하여 구현됩니다. Virtio는 또한 보호된 게스트와 Android의 나머지 요소 간의 통신에 사용되는 vsock 구현을 강화합니다.
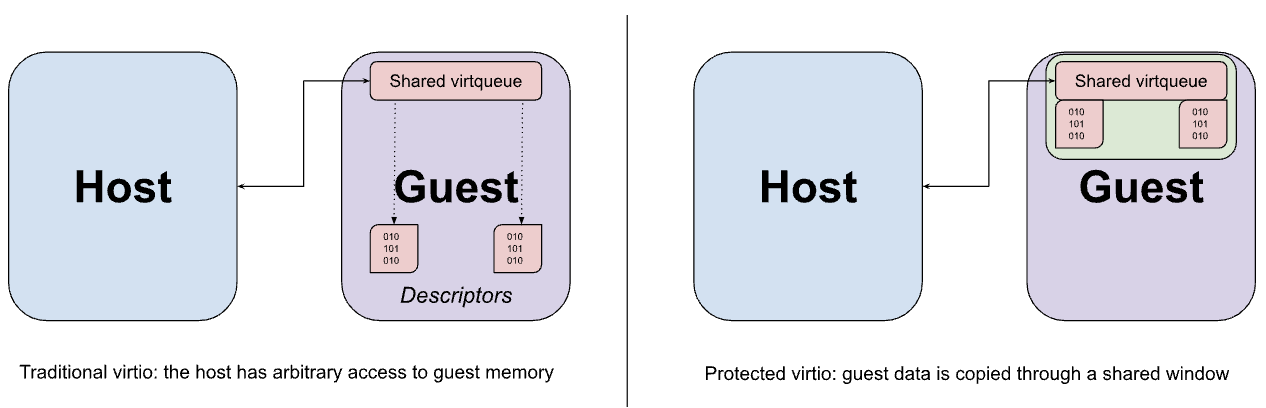
Virtio 기기는 일반적으로 VMM에 의해 호스트의 사용자 공간에 구현되며, VMM은 virtio 기기의 MMIO 인터페이스에 대한 게스트의 트래핑된 메모리 액세스를 가로채고 예상되는 동작을 에뮬레이션합니다. 기기에 각각 액세스하려면 VMM에 한 번씩 왕복해야 하므로 MMIO 액세스에는 비교적 비용이 많이 듭니다. 따라서 기기와 게스트 간의 실제 데이터 전송의 대부분은 메모리의 virtqueue를 사용하여 발생합니다. Virtio의 주요 가정은 호스트가 게스트 메모리에 임의로 액세스할 수 있다는 것입니다. 이 가정은 virtqueue 설계에서 명확하게 드러나며, 이러한 설계에는 기기 에뮬레이션에서 직접 액세스하도록 되어 있는 게스트 내 버퍼를 가리키는 포인터가 포함될 수 있습니다.
이전에 설명한 메모리 공유 하이퍼콜을 사용하여 게스트에서 호스트로 virtio 데이터 버퍼를 공유할 수 있습니다. 하지만 이 공유는 페이지 세밀도에서 필수적으로 이루어지며, 버퍼 크기가 페이지의 크기보다 작은 경우 필요한 것보다 더 많은 데이터를 노출할 수 있습니다. 대신 게스트는 공유 메모리의 고정된 창에서 virtqueues와 이에 상응하는 데이터 버퍼를 모두 할당하도록 구성되고, 데이터는 필요에 따라 창에(서) 복사(반송)됩니다.
TrustZone과의 상호작용
게스트는 TrustZone과 직접 상호작용할 수 없지만 호스트는 계속 SMC 호출을 보안 환경으로 보낼 수 있어야 합니다. 이러한 호출은 호스트에 액세스할 수 없는, 물리적으로 주소 지정된 메모리 버퍼를 지정할 수 있습니다. 보안 소프트웨어가 일반적으로 버퍼의 접근성을 인식하지 못하므로 악성 호스트는 이 버퍼를 사용하여 혼동되는 대리인 공격(DMA 공격과 유사)을 실행할 수 있습니다. 이러한 공격을 방지하기 위해 pKVM은 모든 호스트 SMC 호출을 EL2에 트래핑하고 EL3에서 호스트와 보안 모니터 간의 프록시 역할을 합니다.
호스트로부터의 PSCI 호출은 최소한의 수정으로 EL3 펌웨어에 전달됩니다. 특히 온라인으로 전환되거나 정지 상태에서 재개되는 CPU의 진입점이 재작성됩니다. 그래야 EL1에서 호스트로 돌아가기 전에 2단계 페이지 테이블이 EL2에 설치되기 때문입니다. 부팅 중 이 보호 기능은 pKVM에 의해 실행됩니다.
이 아키텍처는 가급적 최신 버전의 TF-A를 EL3 펌웨어로 사용함으로써, PSCI 지원 SoC를 사용합니다.
Firmware Framework for Arm(FF-A)은 일반 환경와 보안 환경 간의 상호작용을 표준화하며, 특히 보안 하이퍼바이저가 있을 때 더욱 그러합니다. 사양의 주요 부분에서는 일반 메시지 형식은 물론, 기본 페이지에 관해 잘 정의된 권한 모델을 사용하여 메모리를 보안 환경과 공유하는 메커니즘이 정의됩니다. pKVM은 FF-A 메시지를 프록시하여 호스트가 충분한 권한이 없는 보안 측과 메모리를 공유하지 않도록 보장합니다.
이 아키텍처는 메모리 액세스 모델을 적용하는 보안 환경 소프트웨어를 사용합니다. 그래서 메모리가 보안 환경에 배타적으로 소유되었거나 FF-A를 사용하여 명시적으로 공유된 경우에만 신뢰할 수 있는 앱과 보안 환경에서 실행되는 기타 모든 소프트웨어가 메모리에 액세스할 수 있도록 합니다. S-EL2가 있는 시스템에서 메모리 액세스 모델 적용은 Hafnium 같이 보안 환경을 위해 2단계 페이지를 유지관리하는 SPMC(Secure Partition Manager Core)에 의해 이루어져야 합니다. S-EL2가 없는 시스템에서는 TEE가 대신 1단계 페이지 테이블을 통해 메모리 액세스 모델을 적용할 수 있습니다.
SM2에 대한 SMC 호출이 PSCI 호출 또는 FF-A 정의 메시지가 아닌 경우 처리되지 않은 SMC가 EL3에 전달됩니다. 이때 (반드시 신뢰할 수 있는) 보안 펌웨어가 처리되지 않은 SMC를 안전하게 처리할 수 있다고 가정됩니다. 펌웨어가 pVM 격리를 유지하는 데 필요한 예방 조치를 이해하기 때문입니다.
가상 머신 모니터
crosvm은 Linux의 KVM 인터페이스를 통해 가상 머신을 실행하는 가상 머신 모니터(VMM)입니다. crosvm이 특별한 이유는 Rust 프로그래밍 언어와 가상 기기 주변의 샌드박스를 사용하여 안전에 중점을 두며 호스트 커널을 보호하기 때문입니다. crosvm에 관한 자세한 내용은 여기에 있는 공식 문서를 참고하세요.
파일 설명자 및 ioctl
KVM은 KVM API를 구성하는 ioctl을 사용하여 /dev/kvm 문자 기기를 사용자 공간에 노출합니다. ioctl은 다음 카테고리에 속합니다.
- 시스템 ioctl은 전체 KVM 하위 시스템에 영향을 미치는 전역 속성을 쿼리하고 설정하고 pVM을 만듭니다.
- VM ioctl은 가상 CPU(vCPU)와 기기를 만드는 속성을 쿼리하고 설정하고, 메모리 레이아웃과 가상 CPU(vCPU) 수와 기기 수 등을 포함하여 전체 pVM에 영향을 미칩니다.
- vCPU ioctl은 단일 가상 CPU의 작업을 제어하는 속성을 쿼리하고 설정합니다.
- 기기 ioctl은 단일 가상 기기의 작업을 제어하는 속성을 쿼리하고 설정합니다.
각 crosvm 프로세스는 정확히 하나의 가상 머신 인스턴스를 실행합니다. 이 프로세스는 KVM_CREATE_VM 시스템 ioctl을 사용하여, pVM ioctl을 실행하는 데 사용할 수 있는 VM 파일 설명자를 생성합니다. VM FD의 KVM_CREATE_VCPU 또는 KVM_CREATE_DEVICE ioctl은 vCPU/기기를 생성하고 새 리소스를 가리키는 파일 설명자를 반환합니다. vCPU 또는 기기 FD의 ioctl은 VM FD의 ioctl을 사용하여 생성된 기기를 제어하는 데 사용할 수 있습니다. vCPU의 경우 여기에는 게스트 코드를 실행하는 중요한 작업이 포함됩니다.
내부적으로 crosvm은 에지에 의해 트리거된 epoll 인터페이스를 사용하여 VM의 파일 설명자를 커널에 등록합니다. 그러면 파일 설명자에 대기 중인 새 이벤트가 있을 때마다 커널이 crosvm에 알립니다.
pKVM은 새로운 기능 KVM_CAP_ARM_PROTECTED_VM을 추가합니다. 이 기능은 pVM 환경 정보를 가져오고 VM에 보호 모드를 설정하는 데 사용할 수 있습니다. --protected-vm 플래그가 전달된 경우 crosvm은 pVM 생성 중에 이 기능을 사용하여, pVM 펌웨어에 적절한 양의 메모리를 쿼리하고 예약한 다음 보호 모드를 사용 설정합니다.
메모리 할당
VMM의 주요 역할 중 하나는 VM의 메모리를 할당하고 메모리 레이아웃을 관리하는 것입니다. crosvm은 아래 표에 대략 설명된 것처럼 고정 메모리 레이아웃을 생성합니다.
| 일반 모드의 FDT | PHYS_MEMORY_END - 0x200000
|
| 여유 공간 | ...
|
| 램디스크 | ALIGN_UP(KERNEL_END, 0x1000000)
|
| 커널 | 0x80080000
|
| 부트로더 | 0x80200000
|
| BIOS 모드의 FDT | 0x80000000
|
| 실제 메모리 베이스 | 0x80000000
|
| pVM 펌웨어 | 0x7FE00000
|
| 기기 메모리 | 0x10000 - 0x40000000
|
실제 메모리는 mmap로 할당되고, 그 메모리는 memslots라는 메모리 영역을 KVM_SET_USER_MEMORY_REGION ioctl로 채우기 위해 VM에 제공됩니다. 따라서 모든 게스트 pVM 메모리는 메모리를 관리하는 crosvm 인스턴스에 귀속되고, 호스트의 여유 메모리가 부족해지면 프로세스가 종료될 수 있습니다(VM 종료). VM이 중지되면 메모리가 하이퍼바이저에 의해 자동으로 완전 삭제되고 호스트 커널로 반환됩니다.
일반 KVM에서 VMM은 모든 게스트 메모리에 대한 액세스 권한을 유지합니다. pKVM을 사용하면 게스트 메모리가 게스트에게 제공될 때 호스트의 실제 주소 공간에서 매핑 해제됩니다. 단, virtio 기기와 같은 게스트가 명시적으로 다시 공유하는 메모리는 예외입니다.
게스트의 주소 공간에 있는 MMIO 영역은 매핑되지 않은 채 유지됩니다. 이러한 영역에 대한 게스트 액세스는 트래핑되고 VM FD에서 I/O 이벤트가 발생합니다. 이 메커니즘은 가상 기기를 구현하는 데 사용됩니다. 보호 모드에서 게스트는 하이퍼콜을 사용하여 MMIO에 주소 공간 영역이 사용되는지 인식해야 합니다. 그래야 실수로 인한 정보 유출 위험을 줄일 수 있습니다.
스케줄링
각 가상 CPU는 POSIX 스레드로 표시되고 호스트 Linux 스케줄러에 의해 예약됩니다. 스레드가 vCPU FD에 KVM_RUN ioctl을 호출하면 하이퍼바이저가 게스트 vCPU 컨텍스트로 전환됩니다. 호스트 스케줄러는 게스트 컨텍스트에 소비된 시간을 그에 상응하는 vCPU 스레드에 사용된 시간으로 처리합니다. I/O, 인터럽트 종료 또는 중지된 vCPU와 같이 VMM에서 처리해야 하는 이벤트가 있으면 KVM_RUN이 반환됩니다. VMM이 그 이벤트를 처리하고 KVM_RUN을 다시 호출합니다.
KVM_RUN 중에 스레드는 호스트 스케줄러에 의해 선점 가능 상태로 유지됩니다. 단, 선점 가능하지 않은 EL2 하이퍼바이저 코드 실행에는 예외입니다. 게스트 pVM 자체에는 이 동작을 제어하는 메커니즘이 없습니다.
모든 vCPU 스레드는 다른 사용자 공간 작업과 마찬가지로 예약되므로 모든 표준 QoS 메커니즘의 영향을 받습니다. 특히 각 vCPU 스레드는 물리적 CPU에 밀접하게 결합되거나 cpuset에 배치될 수 있고, 사용률 클램프로 부스트 또는 한도 적용이 가능하며, 우선순위/스케쥴링 정책을 변경하는 등 다양한 작업을 할 수 있습니다.
가상 기기
crosvm은 다음을 포함한 다양한 기기를 지원합니다.
- 복합 디스크 이미지, 읽기 전용 또는 읽기-쓰기의 virtio-blk
- 호스트와의 통신을 위한 vhost-vsock
- virtio-pci를 virtio로 전송
- pl030 실시간 시계(RTC)
- 직렬 통신을 위한 16550a UART
pVM 펌웨어
pVM 펌웨어(pvmfw)는 pVM에서 처음 실행되는 코드로, 실제 기기의 부팅 ROM과 유사합니다. pvmfw의 주된 목표는 안전한 부팅을 부트스트랩하고 pVM의 고유한 보안 비밀을 파생하는 것입니다. pvmfw는 OS가 crosvm에서 지원되고 적절하게 서명되어 있다면 Microdroid와 같은 특정 OS에서만 사용하도록 제한되지 않습니다.
pvmfw 바이너리는 같은 이름의 플래시 파티션에 저장되고 OTA를 사용하여 업데이트됩니다.
기기 부팅
pKVM 지원 기기의 부팅 절차에 일련의 다음 단계가 추가됩니다.
- Android 부트로더(ABL)가 파티션에서 메모리로 pvmfw를 로드하고 이미지를 확인합니다.
- ABL이 신뢰할 수 있는 루트에서 Device Identifier Composition Engine(DICE) 보안 비밀(복합 기기 식별자(CDI) 및 부팅 인증 체인(BCC))을 가져옵니다.
- ABL이 pvmfw의 보안 비밀(CDI)과 관련해 측정과 DICE 파생을 실행하고 이를 pvmfw 바이너리에 추가합니다.
- ABL이 pvmfw 바이너리의 위치와 크기, 그리고 이전 단계에서 파생한 보안 비밀을 설명하며
linux,pkvm-guest-firmware-memory예약 메모리 영역 노드를 DT에 추가합니다. - ABL이 Linux에 제어권을 넘기고 Linux가 pKVM을 초기화합니다.
- pKVM이 호스트의 2단계 페이지 테이블에서 pvmfw 메모리 영역을 매핑 해제하고 기기 업타임 동안 호스트(및 게스트)로부터 이를 보호합니다.
기기 부팅 후에는 Microdroid가 Microdroid 문서의 부팅 시퀀스 섹션에 안내된 단계에 따라 부팅됩니다.
pVM 부팅
pVM을 만들 때 crosvm(또는 다른 VMM)은 하이퍼바이저에 의해 pvmfw 이미지로 채워질 만큼 충분히 큰 memslot을 만들어야 합니다. VMM은 초기 값을 설정할 수 있는 레지스터 목록에서도 제한됩니다(기본 vCPU의 경우 x0~x14, 보조 vCPU의 경우 없음). 나머지 레지스터는 예약되며 hypervisor-pvmfw ABI의 일부입니다.
pVM이 실행되면 하이퍼바이저가 먼저 기본 vCPU에 관한 제어권을 pvmfw에 넘깁니다. 펌웨어는 crosvm이 AVB 서명 커널(부트로더 또는 기타 이미지일 수 있음)과 서명되지 않은 FDT를 알려진 오프셋에서 메모리에 로드했다고 예상합니다. pvmfw가 AVB 서명을 검증하고 통과되면 수신된 FDT에서 신뢰할 수 있는 기기 트리를 생성하고, 메모리에서 보안 비밀을 삭제하며, 페이로드의 진입점으로 분기됩니다. 검증 단계 중 하나가 실패하면 펌웨어는 PSCI SYSTEM_RESET 하이퍼콜을 실행합니다.
다음 부팅으로 넘어갈 때 pVM 인스턴스 정보는 파티션(virtio-blk 기기)에 저장되고, 재부팅 후에 보안 비밀이 올바른 인스턴스에 프로비저닝되도록 pvmfw의 보안 비밀로 암호화됩니다.