
اندروید یک پیادهسازی مرجع از تمام اجزای مورد نیاز برای پیادهسازی چارچوب مجازیسازی اندروید ارائه میدهد. در حال حاضر این پیادهسازی محدود به ARM64 است. این صفحه معماری چارچوب را توضیح میدهد.
پیشینه
معماری Arm تا چهار سطح استثنا را مجاز میداند، که سطح استثنای ۰ (EL0) کمترین امتیاز و سطح استثنای ۳ (EL3) بیشترین امتیاز را دارد. بزرگترین بخش کدبیس اندروید (تمام اجزای فضای کاربری) در EL0 اجرا میشود. بقیهی چیزی که معمولاً "اندروید" نامیده میشود، هستهی لینوکس است که در EL1 اجرا میشود.
لایه EL2 امکان معرفی یک هایپروایزر را فراهم میکند که امکان جداسازی حافظه و دستگاهها را در pVMهای مجزا در EL1/EL0 با تضمینهای قوی محرمانگی و یکپارچگی فراهم میکند.
هایپروایزر
ماشین مجازی مبتنی بر هسته محافظتشده (pKVM) بر روی هایپروایزر KVM لینوکس ساخته شده است که با قابلیت محدود کردن دسترسی به پیلودهای در حال اجرا در ماشینهای مجازی مهمان که در زمان ایجاد با عنوان «محافظتشده» مشخص شدهاند، گسترش یافته است.
KVM/arm64 بسته به در دسترس بودن برخی از ویژگیهای CPU، یعنی Virtualization Host Extensions (VHE) (ARMv8.1 و بالاتر)، از حالتهای مختلف اجرا پشتیبانی میکند. در یکی از این حالتها، که معمولاً به عنوان حالت غیر VHE شناخته میشود، کد hypervisor در هنگام بوت از تصویر هسته جدا شده و در EL2 نصب میشود، در حالی که خود هسته در EL1 اجرا میشود. اگرچه بخشی از کد بیس لینوکس است، اما جزء EL2 KVM یک جزء کوچک است که مسئول جابجایی بین چندین EL1 است. جزء hypervisor با لینوکس کامپایل میشود، اما در یک بخش حافظه اختصاصی جداگانه از تصویر vmlinux قرار دارد. pKVM با گسترش کد hypervisor با ویژگیهای جدید، از این طراحی بهره میبرد و به آن اجازه میدهد محدودیتهایی را بر روی هسته میزبان اندروید و فضای کاربر اعمال کند و دسترسی میزبان به حافظه مهمان و hypervisor را محدود کند.
ماژولهای فروشنده pKVM
ماژول فروشنده pKVM ، یک ماژول مخصوص سختافزار است که شامل قابلیتهای مخصوص دستگاه، مانند درایورهای واحد مدیریت حافظه ورودی-خروجی (IOMMU) میشود. این ماژولها به شما امکان میدهند ویژگیهای امنیتی که نیاز به دسترسی سطح استثنا ۲ (EL2) دارند را به pKVM منتقل کنید.
برای یادگیری نحوه پیادهسازی و بارگذاری یک ماژول فروشنده pKVM، به «پیادهسازی یک ماژول فروشنده pKVM» مراجعه کنید.
روش بوت
شکل زیر روند بوت pKVM را نشان میدهد:
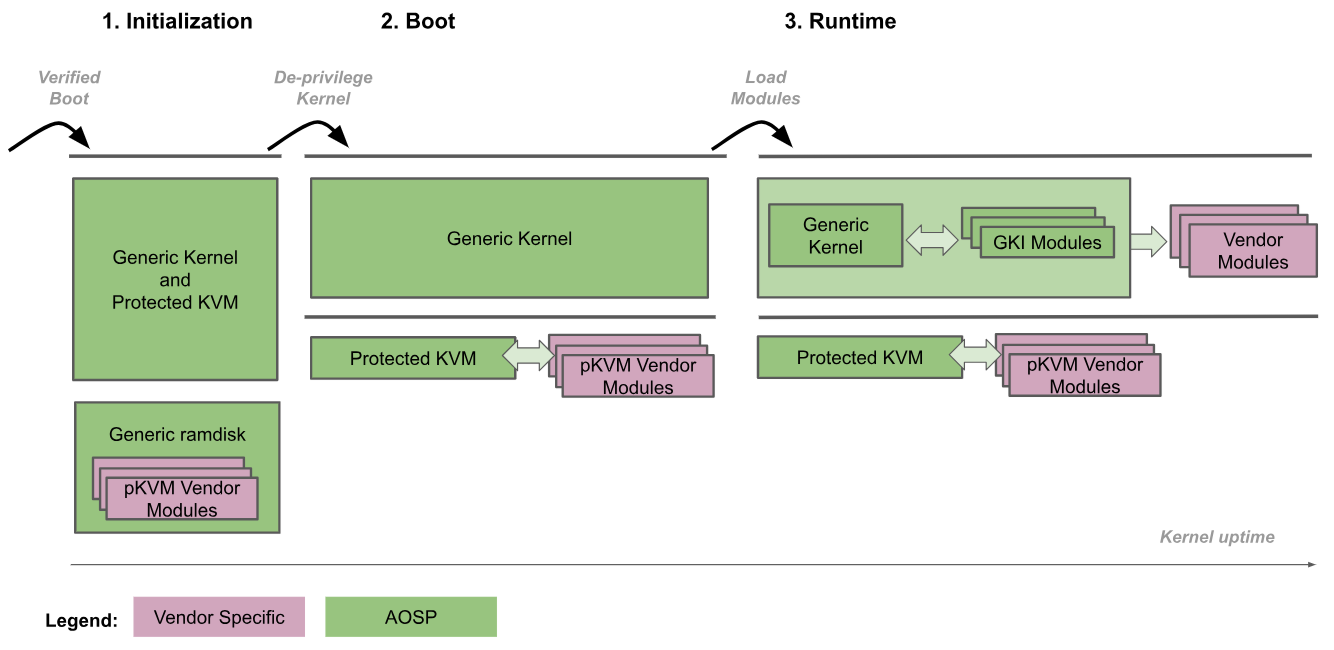
- مقداردهی اولیه: بوتلودر وارد هسته عمومی در EL2 میشود. سپس کد هسته مورد اعتماد در هر دو EL2 و EL1، pKVM و ماژولهای آن را مقداردهی اولیه میکند. در طول این مرحله، EL1 توسط EL2 مورد اعتماد قرار میگیرد، بنابراین هیچ کد غیرقابل اعتمادی اجرا نمیشود.
- کرنلِ محرومشده: کرنل عمومی تشخیص میدهد که در حال اجرا در سطح EL2 است و خود را به سطح EL1 محروم میکند. pKVM و ماژولهای آن به اجرای خود در سطح EL2 ادامه میدهند.
- زمان اجرا : هسته عمومی به طور عادی بوت میشود و تمام درایورهای لازم دستگاه را بارگیری میکند تا به فضای کاربر برسد. در این مرحله، pKVM در جای خود قرار دارد و جداول صفحه مرحله ۲ را مدیریت میکند.
رویه بوت به بوتلودر اعتماد میکند تا صحت تصویر هسته را برای مرحله اولیهسازی تأیید و حفظ کند. پس از اینکه هسته از حالت دسترسی خارج شد، دیگر توسط هایپروایزر مورد اعتماد تلقی نمیشود، و هایپروایزر مسئول محافظت از خود حتی در صورت به خطر افتادن هسته است.
قرار گرفتن هسته اندروید و هایپروایزر در یک تصویر دودویی یکسان، امکان ایجاد یک رابط ارتباطی بسیار محکم و متصل بین آنها را فراهم میکند. این اتصال محکم، بهروزرسانیهای اتمی دو مؤلفه را تضمین میکند که از نیاز به پایدار نگه داشتن رابط بین آنها جلوگیری میکند و انعطافپذیری زیادی را بدون به خطر انداختن قابلیت نگهداری طولانیمدت ارائه میدهد. این اتصال محکم همچنین امکان بهینهسازی عملکرد را فراهم میکند، زمانی که هر دو مؤلفه میتوانند بدون تأثیر بر تضمینهای امنیتی ارائه شده توسط هایپروایزر، با یکدیگر همکاری کنند.
علاوه بر این، پذیرش GKI در اکوسیستم اندروید به طور خودکار به هایپروایزر pKVM اجازه میدهد تا در دستگاههای اندروید با همان باینری هسته مستقر شود.
محافظت از دسترسی به حافظه CPU
معماری Arm یک واحد مدیریت حافظه (MMU) را مشخص میکند که به دو مرحله مستقل تقسیم شده است، که هر دو میتوانند برای پیادهسازی ترجمه آدرس و کنترل دسترسی به بخشهای مختلف حافظه استفاده شوند. MMU مرحله ۱ توسط EL1 کنترل میشود و امکان ترجمه سطح اول آدرس را فراهم میکند. MMU مرحله ۱ توسط لینوکس برای مدیریت فضای آدرس مجازی ارائه شده به هر فرآیند فضای کاربری و فضای آدرس مجازی خود استفاده میشود.
واحد مدیریت حافظه (MMU) مرحله ۲ توسط EL2 کنترل میشود و امکان اعمال ترجمه آدرس دوم را بر روی آدرس خروجی واحد مدیریت حافظه مرحله ۱ فراهم میکند که منجر به ایجاد یک آدرس فیزیکی (PA) میشود. ترجمه مرحله ۲ میتواند توسط هایپروایزرها برای کنترل و ترجمه دسترسیهای حافظه از همه ماشینهای مجازی مهمان استفاده شود. همانطور که در شکل ۲ نشان داده شده است، هنگامی که هر دو مرحله ترجمه فعال هستند، آدرس خروجی مرحله ۱، آدرس فیزیکی میانی (IPA) نامیده میشود. توجه: آدرس مجازی (VA) به یک IPA و سپس به یک PA ترجمه میشود.
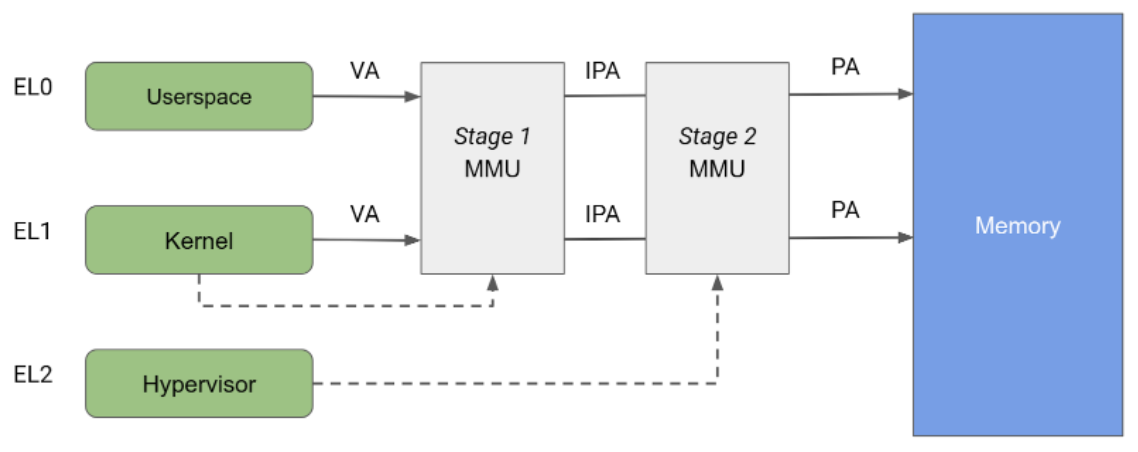
از نظر تاریخی، KVM هنگام اجرای مهمانها با ترجمه مرحله ۲ فعال و هنگام اجرای هسته لینوکس میزبان با مرحله ۲ غیرفعال اجرا میشود. این معماری اجازه میدهد تا دسترسی به حافظه از MMU مرحله ۱ میزبان از MMU مرحله ۲ عبور کند، از این رو امکان دسترسی نامحدود از میزبان به صفحات حافظه مهمان را فراهم میکند. از سوی دیگر، pKVM محافظت مرحله ۲ را حتی در زمینه میزبان فعال میکند و به جای میزبان، هایپروایزر را مسئول محافظت از صفحات حافظه مهمان قرار میدهد.
KVM در مرحله ۲ از ترجمه آدرس به طور کامل استفاده میکند تا نگاشتهای پیچیده IPA/PA را برای مهمانان پیادهسازی کند، که با وجود قطعه قطعه شدن فیزیکی، توهم حافظه پیوسته را برای مهمانان ایجاد میکند. با این حال، استفاده از MMU مرحله ۲ برای میزبان فقط به کنترل دسترسی محدود میشود. مرحله ۲ میزبان، نگاشت هویتی است و تضمین میکند که حافظه پیوسته در فضای IPA میزبان در فضای PA نیز پیوسته باشد. این معماری امکان استفاده از نگاشتهای بزرگ در جدول صفحه را فراهم میکند و در نتیجه فشار بر بافر ترجمه کناری (TLB) را کاهش میدهد. از آنجا که یک نگاشت هویت میتواند توسط PA فهرستبندی شود، مرحله ۲ میزبان همچنین برای ردیابی مالکیت صفحه به طور مستقیم در جدول صفحه استفاده میشود.
محافظت از دسترسی مستقیم به حافظه (DMA)
همانطور که قبلاً توضیح داده شد، حذف نگاشت صفحات مهمان از میزبان لینوکس در جداول صفحه CPU گامی ضروری اما ناکافی برای محافظت از حافظه مهمان است. pKVM همچنین باید در برابر دسترسیهای حافظه انجام شده توسط دستگاههای دارای قابلیت DMA تحت کنترل هسته میزبان و احتمال حمله DMA که توسط یک میزبان مخرب آغاز میشود، محافظت کند. برای جلوگیری از دسترسی چنین دستگاهی به حافظه مهمان، pKVM همانطور که در شکل 3 نشان داده شده است، به سختافزار واحد مدیریت حافظه ورودی-خروجی (IOMMU) برای هر دستگاه دارای قابلیت DMA در سیستم نیاز دارد.
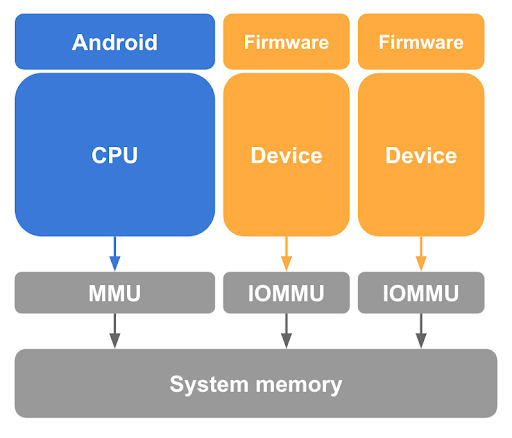
سختافزار IOMMU حداقل ابزار اعطای و لغو دسترسی خواندن/نوشتن برای یک دستگاه به حافظه فیزیکی را در سطح جزئیات صفحه فراهم میکند. با این حال، این سختافزار IOMMU استفاده از دستگاهها را در pVMها محدود میکند زیرا آنها یک مرحله ۲ نگاشت هویت را فرض میکنند.
برای اطمینان از جداسازی بین ماشینهای مجازی، تراکنشهای حافظه تولید شده از طرف موجودیتهای مختلف باید توسط IOMMU قابل تشخیص باشند تا بتوان از مجموعه مناسب جداول صفحه برای ترجمه استفاده کرد.
علاوه بر این، کاهش میزان کد مخصوص SoC در EL2 یک استراتژی کلیدی برای کاهش پایگاه محاسباتی قابل اعتماد کلی (TCB) pKVM است و با گنجاندن درایورهای IOMMU در هایپروایزر مغایرت دارد. برای کاهش این مشکل، میزبان در EL1 مسئول وظایف کمکی مدیریت IOMMU، مانند مدیریت توان، مقداردهی اولیه و در صورت لزوم، مدیریت وقفه است.
با این حال، قرار دادن میزبان در کنترل وضعیت دستگاه، الزامات اضافی را بر رابط برنامهنویسی سختافزار IOMMU اعمال میکند تا اطمینان حاصل شود که بررسیهای مجوز را نمیتوان از طریق روشهای دیگر، مثلاً پس از تنظیم مجدد دستگاه، دور زد.
یک IOMMU استاندارد و با پشتیبانی خوب برای دستگاههای Arm که هم جداسازی و هم تخصیص مستقیم را ممکن میسازد، معماری واحد مدیریت حافظه سیستم Arm (SMMU) است. این معماری، راهحل مرجع پیشنهادی است.
مالکیت حافظه
در زمان بوت، فرض میشود که تمام حافظه غیر از هایپروایزر متعلق به میزبان است و توسط هایپروایزر نیز ردیابی میشود. هنگامی که یک pVM ایجاد میشود، میزبان صفحات حافظه را برای بوت شدن به آن اهدا میکند و هایپروایزر مالکیت آن صفحات را از میزبان به pVM منتقل میکند. بنابراین، هایپروایزر محدودیتهای کنترل دسترسی را در جدول صفحه مرحله ۲ میزبان اعمال میکند تا از دسترسی مجدد آن به صفحات جلوگیری کند و محرمانگی را برای مهمان فراهم کند.
ارتباط بین میزبان و مهمانها از طریق اشتراکگذاری کنترلشده حافظه بین آنها امکانپذیر میشود. به مهمانها اجازه داده میشود برخی از صفحات خود را با استفاده از یک فرافراخوان (hypercall) با میزبان به اشتراک بگذارند، که به هایپروایزر دستور میدهد تا آن صفحات را در جدول صفحه مرحله ۲ میزبان مجدداً نگاشت کند. به طور مشابه، ارتباط میزبان با TrustZone از طریق عملیات اشتراکگذاری حافظه و/یا قرض دادن امکانپذیر میشود، که همه آنها توسط pKVM با استفاده از مشخصات Firmware Framework for Arm (FF-A) به دقت نظارت و کنترل میشوند.
از آنجایی که نیازهای حافظه یک pVM میتواند با گذشت زمان تغییر کند، یک فرافراخوان ارائه میشود که اجازه میدهد مالکیت صفحات مشخص شده متعلق به فراخواننده به میزبان بازگردانده شود. در عمل، این فرافراخوان با پروتکل بالون ویرتیو استفاده میشود تا به VMM اجازه دهد حافظه را از pVM پس بگیرد و pVM به VMM صفحات واگذار شده را به روشی کنترل شده اطلاع دهد.
هایپروایزر مسئول ردیابی مالکیت تمام صفحات حافظه در سیستم و اینکه آیا آنها به اشتراک گذاشته میشوند یا به سایر نهادها قرض داده میشوند، است. بیشتر این ردیابی وضعیت با استفاده از ابردادههای متصل به جداول صفحه مرحله ۲ میزبان و مهمان، با استفاده از بیتهای رزرو شده در ورودیهای جدول صفحه (PTEs) انجام میشود که همانطور که از نامشان پیداست، برای استفاده نرمافزار رزرو شدهاند.
میزبان باید اطمینان حاصل کند که برای دسترسی به صفحاتی که توسط هایپروایزر غیرقابل دسترس شدهاند، تلاشی نمیکند. دسترسی غیرمجاز به میزبان باعث میشود که هایپروایزر یک خطای همزمان به میزبان تزریق کند که میتواند منجر به دریافت سیگنال SEGV توسط وظیفه فضای کاربری مسئول یا از کار افتادن هسته میزبان شود. برای جلوگیری از دسترسیهای تصادفی، صفحات اهدا شده به مهمانان توسط هسته میزبان غیرقابل تعویض یا ادغام میشوند.
مدیریت وقفهها و تایمرها
وقفهها بخش اساسی از نحوه تعامل یک مهمان با دستگاهها و برای ارتباط بین CPUها هستند، که در آن وقفههای بین پردازندهای (IPI) مکانیسم اصلی ارتباط هستند. مدل KVM این است که تمام مدیریت وقفه مجازی را به میزبان در EL1 واگذار کند، که برای این منظور به عنوان یک بخش غیرقابل اعتماد از hypervisor رفتار میکند.
pKVM یک شبیهسازی کامل از کنترلکننده وقفه عمومی نسخه ۳ (GICv3) را بر اساس کد KVM موجود ارائه میدهد. تایمر و IPIها به عنوان بخشی از این کد شبیهسازی غیرقابل اعتماد مدیریت میشوند.
پشتیبانی از GICv3
رابط بین EL1 و EL2 باید تضمین کند که وضعیت کامل وقفه برای میزبان EL1 قابل مشاهده باشد، از جمله کپیهایی از رجیسترهای هایپروایزر مربوط به وقفهها. این قابلیت مشاهده معمولاً با استفاده از نواحی حافظه مشترک، یکی به ازای هر CPU مجازی (vCPU)، انجام میشود.
کد پشتیبانی زمان اجرای رجیستر سیستم را میتوان ساده کرد تا فقط از ثبت وقفه تولید شده توسط نرمافزار (SGIR) و ثبت وقفه غیرفعال (DIR) پشتیبانی کند. معماری الزام میکند که این رجیسترها همیشه در EL2 ثبت شوند، در حالی که سایر ثبتها تاکنون فقط برای کاهش خطاها مفید بودهاند. همه چیز دیگر در سختافزار مدیریت میشود.
در سمت MMIO، همه چیز در EL1 شبیهسازی میشود و از تمام زیرساخت فعلی در KVM استفاده مجدد میشود. در نهایت، انتظار برای وقفه (WFI) همیشه به EL1 منتقل میشود، زیرا این یکی از ابتداییترین زمانبندیهایی است که KVM از آن استفاده میکند.
پشتیبانی از تایمر
مقدار مقایسهگر برای تایمر مجازی باید در هر تله WFI در معرض EL1 قرار گیرد تا EL1 بتواند در حالی که vCPU مسدود است، وقفههای تایمر را تزریق کند. تایمر فیزیکی کاملاً شبیهسازی شده است و تمام تلهها به EL1 منتقل میشوند.
مدیریت MMIO
برای برقراری ارتباط با مانیتور ماشین مجازی (VMM) و انجام شبیهسازی GIC، تلههای MMIO باید برای اولویتبندی بیشتر به میزبان در EL1 منتقل شوند. pKVM به موارد زیر نیاز دارد:
- IPA و اندازه دسترسی
- دادهها در صورت نوشتن
- Endianness پردازنده در نقطه به دام افتادن
علاوه بر این، تلههایی با یک رجیستر عمومی (GPR) به عنوان منبع/مقصد، با استفاده از یک شبه رجیستر انتقال انتزاعی رله میشوند.
رابطهای مهمان
یک مهمان میتواند با استفاده از ترکیبی از فرافراخوانها و دسترسی به حافظه در مناطق به دام افتاده، با یک مهمان محافظتشده ارتباط برقرار کند. فرافراخوانها طبق استاندارد SMCCC در معرض دید قرار میگیرند و محدودهای برای تخصیص فروشنده توسط KVM رزرو شده است. فرافراخوانهای زیر برای مهمانهای pKVM از اهمیت ویژهای برخوردارند.
فرافراخوانهای عمومی
- PSCI یک مکانیزم استاندارد برای مهمان فراهم میکند تا چرخه حیات vCPU های خود، از جمله آنلاین شدن، آفلاین شدن و خاموش شدن سیستم را کنترل کند.
- TRNG یک مکانیزم استاندارد برای مهمان فراهم میکند تا از pKVM درخواست آنتروپی کند که این درخواست را به EL3 منتقل میکند. این مکانیزم به ویژه در جایی مفید است که نمیتوان به میزبان برای مجازیسازی یک مولد اعداد تصادفی سختافزاری (RNG) اعتماد کرد.
فرافراخوانهای pKVM
- اشتراکگذاری حافظه با میزبان. در ابتدا تمام حافظه مهمان برای میزبان غیرقابل دسترسی است، اما دسترسی میزبان برای ارتباط حافظه مشترک و برای دستگاههای شبهمجازی که به بافرهای مشترک متکی هستند، ضروری است. فرافراخوانها برای اشتراکگذاری و لغو اشتراکگذاری صفحات با میزبان به مهمان اجازه میدهند تا دقیقاً تصمیم بگیرد که کدام بخشهای حافظه برای بقیه اندروید بدون نیاز به دست دادن (handshake) قابل دسترسی باشد.
- واگذاری حافظه به میزبان. تمام حافظه مهمان معمولاً تا زمانی که از بین نرود، متعلق به مهمان است. این حالت میتواند برای ماشینهای مجازی با عمر طولانی که نیازهای حافظه آنها با گذشت زمان تغییر میکند، ناکافی باشد. هایپرکال
relinquishبه مهمان اجازه میدهد تا مالکیت صفحات را بدون نیاز به خاتمه مهمان، به صراحت به میزبان منتقل کند. - به دام انداختن دسترسی به حافظه برای میزبان. به طور سنتی، اگر یک مهمان KVM به آدرسی دسترسی پیدا کند که با یک ناحیه حافظه معتبر مطابقت ندارد، آنگاه رشته vCPU به میزبان خارج میشود و این دسترسی معمولاً برای MMIO استفاده میشود و توسط VMM در فضای کاربر شبیهسازی میشود. برای تسهیل این مدیریت، pKVM موظف است جزئیات مربوط به دستورالعمل خطادار مانند آدرس آن، پارامترهای ثبت و احتمالاً محتوای آنها را به میزبان ارسال کند، که اگر تله پیشبینی نشده باشد، میتواند ناخواسته دادههای حساس یک مهمان محافظتشده را افشا کند. pKVM این مشکل را با در نظر گرفتن این خطاها به عنوان خطاهای مهلک حل میکند، مگر اینکه مهمان قبلاً یک فرافراخوان برای شناسایی محدوده IPA خطادار به عنوان محدودهای که دسترسیها برای به دام انداختن آن به میزبان مجاز هستند، صادر کرده باشد. این راهحل به عنوان محافظ MMIO شناخته میشود.
دستگاه ورودی/خروجی مجازی (virtio)
Virtio یک استاندارد محبوب، قابل حمل و بالغ برای پیادهسازی و تعامل با دستگاههای شبهمجازی است. اکثر دستگاههایی که در معرض مهمانهای محافظتشده قرار دارند با استفاده از virtio پیادهسازی میشوند. Virtio همچنین زیربنای پیادهسازی vsock است که برای ارتباط بین یک مهمان محافظتشده و بقیه اندروید استفاده میشود.
دستگاههای Virtio معمولاً در فضای کاربری میزبان توسط VMM پیادهسازی میشوند، که دسترسیهای حافظهی به دام افتاده از مهمان به رابط MMIO دستگاه virtio را رهگیری میکند و رفتار مورد انتظار را شبیهسازی میکند. دسترسی MMIO نسبتاً گران است زیرا هر دسترسی به دستگاه نیاز به یک رفت و برگشت به VMM و برعکس دارد، بنابراین بیشتر انتقال دادههای واقعی بین دستگاه و مهمان با استفاده از مجموعهای از صفهای مجازی در حافظه رخ میدهد. یک فرض کلیدی virtio این است که میزبان میتواند به طور دلخواه به حافظه مهمان دسترسی داشته باشد. این فرض در طراحی صف مجازی مشهود است، که ممکن است حاوی اشارهگرهایی به بافرهایی در مهمان باشد که شبیهسازی دستگاه قرار است مستقیماً به آنها دسترسی داشته باشد.
اگرچه میتوان از فرافراخوانهای اشتراکگذاری حافظه که قبلاً توضیح داده شد، برای اشتراکگذاری بافرهای داده virtio از مهمان به میزبان استفاده کرد، اما این اشتراکگذاری لزوماً در سطح جزئیات صفحه انجام میشود و اگر اندازه بافر کمتر از اندازه یک صفحه باشد، میتواند منجر به افشای دادههای بیشتر از حد مورد نیاز شود. در عوض، مهمان طوری پیکربندی شده است که هم صفهای مجازی و هم بافرهای داده مربوطه را از یک پنجره ثابت از حافظه مشترک اختصاص دهد، و دادهها در صورت نیاز به پنجره کپی (بازگشت) و از آن خارج شوند.
تعامل با TrustZone
اگرچه مهمانان قادر به تعامل مستقیم با TrustZone نیستند، میزبان همچنان باید بتواند فراخوانیهای SMC را به دنیای امن ارسال کند. این فراخوانیها میتوانند بافرهای حافظه با آدرس فیزیکی را مشخص کنند که برای میزبان غیرقابل دسترسی هستند. از آنجا که نرمافزار امن عموماً از دسترسی به بافر بیاطلاع است، یک میزبان مخرب میتواند از این بافر برای انجام یک حملهی معاون گیجکننده (مشابه حملهی DMA) استفاده کند. برای جلوگیری از چنین حملاتی، pKVM تمام فراخوانیهای SMC میزبان را به EL2 به دام میاندازد و به عنوان یک پروکسی بین میزبان و مانیتور امن در EL3 عمل میکند.
فراخوانیهای PSCI از میزبان با حداقل تغییرات به میانافزار EL3 ارسال میشوند. بهطور خاص، نقطه ورود برای یک CPU که آنلاین میشود یا از حالت تعلیق از سر گرفته میشود، بازنویسی میشود تا جدول صفحه مرحله ۲ قبل از بازگشت به میزبان در EL1، در EL2 نصب شود. در طول بوت، این محافظت توسط pKVM اعمال میشود.
این معماری به SoC پشتیبانیکننده از PSCI متکی است، ترجیحاً از طریق استفاده از یک نسخه بهروز از TF-A به عنوان میانافزار EL3 خود.
چارچوب میانافزار برای آرم (FF-A) تعاملات بین دنیای عادی و امن را، بهویژه در حضور یک هایپروایزر امن، استانداردسازی میکند. بخش عمدهای از مشخصات، مکانیزمی را برای اشتراکگذاری حافظه با دنیای امن تعریف میکند که هم از یک قالب پیام مشترک و هم از یک مدل مجوز تعریفشده برای صفحات زیرین استفاده میکند. pKVM پیامهای FF-A را پروکسی میکند تا اطمینان حاصل شود که میزبان سعی در اشتراکگذاری حافظه با سمت امن که مجوزهای کافی برای آن را ندارد، ندارد.
این معماری به نرمافزار دنیای امن متکی است که مدل دسترسی به حافظه را اجرا میکند تا اطمینان حاصل شود که برنامههای قابل اعتماد و هر نرمافزار دیگری که در دنیای امن اجرا میشود، تنها در صورتی میتوانند به حافظه دسترسی داشته باشند که یا منحصراً متعلق به دنیای امن باشد یا با استفاده از FF-A به صراحت با آن به اشتراک گذاشته شده باشد. در سیستمی با S-EL2، اجرای مدل دسترسی به حافظه باید توسط یک هسته مدیر پارتیشن امن (SPMC)، مانند Hafnium ، انجام شود که جداول صفحه مرحله 2 را برای دنیای امن نگهداری میکند. در سیستمی بدون S-EL2، TEE میتواند به جای آن، یک مدل دسترسی به حافظه را از طریق جداول صفحه مرحله 1 خود اجرا کند.
اگر فراخوانی SMC به EL2 یک فراخوانی PSCI یا پیام تعریفشدهی FF-A نباشد، SMCهای مدیریتنشده به EL3 ارسال میشوند. فرض بر این است که میانافزار امن (لزوماً قابل اعتماد) میتواند SMCهای مدیریتنشده را با خیال راحت مدیریت کند، زیرا میانافزار اقدامات احتیاطی لازم برای حفظ ایزولهسازی pVM را درک میکند.
مانیتور ماشین مجازی
crosvm یک مانیتور ماشین مجازی (VMM) است که ماشینهای مجازی را از طریق رابط KVM لینوکس اجرا میکند. چیزی که crosvm را منحصر به فرد میکند، تمرکز آن بر ایمنی با استفاده از زبان برنامهنویسی Rust و یک محیط امن (sandbox) در اطراف دستگاههای مجازی برای محافظت از هسته میزبان است. برای اطلاعات بیشتر در مورد crosvm، به مستندات رسمی آن در اینجا مراجعه کنید.
توصیفگرهای فایل و ioctls
KVM دستگاه کاراکتری /dev/kvm را با ioctls که API KVM را تشکیل میدهند، در معرض فضای کاربری قرار میدهد. ioctls به دستههای زیر تعلق دارند:
- پرس و جوهای ioctls سیستم و تنظیم ویژگیهای سراسری که بر کل زیرسیستم KVM تأثیر میگذارند و ایجاد pVMها.
- VM ioctls پرس و جو میکند و ویژگیهایی را تنظیم میکند که CPUهای مجازی (vCPU) و دستگاههای مجازی را ایجاد میکنند و بر کل pVM تأثیر میگذارند، مانند طرحبندی حافظه و تعداد CPUهای مجازی (vCPU) و دستگاهها.
- vCPU ioctls پرس و جو میکند و ویژگیهایی را تنظیم میکند که عملکرد یک CPU مجازی واحد را کنترل میکنند.
- پرس و جو و تنظیم ویژگیهای ioctls دستگاه که عملکرد یک دستگاه مجازی واحد را کنترل میکنند.
هر فرآیند crosvm دقیقاً یک نمونه از یک ماشین مجازی را اجرا میکند. این فرآیند از سیستم KVM_CREATE_VM ioctl برای ایجاد یک توصیفگر فایل ماشین مجازی استفاده میکند که میتواند برای صدور pVM ioctls استفاده شود. یک KVM_CREATE_VCPU یا KVM_CREATE_DEVICE ioctl در یک VM FD یک vCPU/device ایجاد میکند و یک توصیفگر فایل را که به منبع جدید اشاره میکند، برمیگرداند. ioctls در یک vCPU یا FD دستگاه میتواند برای کنترل دستگاهی که با استفاده از ioctl در VM FD ایجاد شده است، استفاده شود. برای vCPUها، این شامل وظیفه مهم اجرای کد مهمان است.
به صورت داخلی، crosvm توصیفگرهای فایل ماشین مجازی را با استفاده از رابط epoll فعالشده توسط لبه در هسته ثبت میکند. سپس هسته هر زمان که رویداد جدیدی در هر یک از توصیفگرهای فایل در حال انتظار باشد، به crosvm اطلاع میدهد.
pKVM قابلیت جدیدی به نام KVM_CAP_ARM_PROTECTED_VM اضافه میکند که میتواند برای دریافت اطلاعات در مورد محیط pVM و تنظیم حالت محافظتشده برای یک ماشین مجازی استفاده شود. crosvm در صورت ارسال پرچم --protected-vm ، از این قابلیت در هنگام ایجاد pVM برای پرسوجو و رزرو مقدار مناسب حافظه برای میانافزار pVM و سپس فعال کردن حالت محافظتشده استفاده میکند.
تخصیص حافظه
یکی از مسئولیتهای اصلی یک VMM تخصیص حافظه ماشین مجازی و مدیریت طرح حافظه آن است. crosvm یک طرح حافظه ثابت ایجاد میکند که به طور خلاصه در جدول زیر توضیح داده شده است.
| FDT در حالت عادی | PHYS_MEMORY_END - 0x200000 |
| فضای آزاد | ... |
| رمدیسک | ALIGN_UP(KERNEL_END, 0x1000000) |
| هسته | 0x80080000 |
| بوت لودر | 0x80200000 |
| FDT در حالت BIOS | 0x80000000 |
| پایه حافظه فیزیکی | 0x80000000 |
| میانافزار pVM | 0x7FE00000 |
| حافظه دستگاه | 0x10000 - 0x40000000 |
حافظه فیزیکی با mmap تخصیص داده میشود و حافظه به ماشین مجازی اهدا میشود تا نواحی حافظه آن، به نام memslots ، را با KVM_SET_USER_MEMORY_REGION ioctl پر کند. بنابراین، تمام حافظه pVM مهمان به نمونه crosvm که آن را مدیریت میکند، نسبت داده میشود و اگر میزبان شروع به پر شدن از حافظه آزاد کند، میتواند منجر به از بین رفتن فرآیند (خاتمه دادن به ماشین مجازی) شود. هنگامی که یک ماشین مجازی متوقف میشود، حافظه به طور خودکار توسط hypervisor پاک شده و به هسته میزبان بازگردانده میشود.
در KVM معمولی، VMM دسترسی به تمام حافظه مهمان را حفظ میکند. با pKVM، حافظه مهمان هنگام اهدای فضای آدرس فیزیکی میزبان به مهمان، از آن جدا میشود. تنها استثنا، حافظهای است که به صراحت توسط مهمان به اشتراک گذاشته میشود، مانند دستگاههای virtio.
نواحی MMIO در فضای آدرس مهمان بدون نگاشت رها میشوند. دسترسی مهمان به این نواحی محدود شده و منجر به یک رویداد ورودی/خروجی (I/O) در VM FD میشود. این مکانیزم برای پیادهسازی دستگاههای مجازی استفاده میشود. در حالت محافظتشده، مهمان باید با استفاده از یک فرافراخوان (hypercall) تأیید کند که ناحیهای از فضای آدرسش برای MMIO استفاده میشود تا خطر نشت تصادفی اطلاعات کاهش یابد.
زمانبندی
هر CPU مجازی توسط یک نخ POSIX نمایش داده میشود و توسط زمانبند لینوکس میزبان زمانبندی میشود. این نخ، ioctl مربوط به KVM_RUN را در FD vCPU فراخوانی میکند و در نتیجه، هایپروایزر به زمینه vCPU مهمان تغییر وضعیت میدهد. زمانبند میزبان، زمان صرف شده در یک زمینه مهمان را به عنوان زمان استفاده شده توسط نخ vCPU مربوطه در نظر میگیرد. KVM_RUN زمانی برمیگردد که رویدادی وجود داشته باشد که باید توسط VMM مدیریت شود، مانند I/O، پایان وقفه یا توقف vCPU. VMM این رویداد را مدیریت میکند و دوباره KVM_RUN را فراخوانی میکند.
در طول KVM_RUN ، نخ توسط زمانبند میزبان قابل قبضه شدن باقی میماند، به جز اجرای کد هایپروایزر EL2 که قابل قبضه شدن نیست. خود pVM مهمان هیچ مکانیزمی برای کنترل این رفتار ندارد.
از آنجا که تمام رشتههای vCPU مانند سایر وظایف فضای کاربری زمانبندی میشوند، تابع تمام مکانیسمهای استاندارد QoS هستند. به طور خاص، هر رشته vCPU میتواند به پردازندههای فیزیکی متصل شود، در cpusetها قرار گیرد، با استفاده از محدود کردن استفاده، تقویت یا محدود شود، سیاست اولویت/زمانبندی آن تغییر کند و موارد دیگر.
دستگاههای مجازی
crosvm از تعدادی دستگاه پشتیبانی میکند، از جمله موارد زیر:
- virtio-blk برای ایمیجهای دیسک ترکیبی، فقط خواندنی یا خواندنی-نوشتنی
- vhost-vsock برای ارتباط با میزبان
- virtio-pci به عنوان انتقال virtio
- ساعت بلادرنگ pl030 (RTC)
- ۱۶۵۵۰a UART برای ارتباط سریال
میانافزار pVM
فریمور pVM (pvmfw) اولین کدی است که توسط pVM اجرا میشود، مشابه boot ROM یک دستگاه فیزیکی. هدف اصلی pvmfw راهاندازی بوت امن و استخراج رمز منحصر به فرد pVM است. pvmfw محدود به استفاده با هیچ سیستم عامل خاصی مانند Microdroid نیست، مادامی که سیستم عامل توسط crosvm پشتیبانی شود و به درستی امضا شده باشد.
فایل باینری pvmfw در یک پارتیشن فلش با همین نام ذخیره میشود و با استفاده از OTA بهروزرسانی میشود.
بوت شدن دستگاه
توالی مراحل زیر به رویه بوت یک دستگاه دارای قابلیت pKVM اضافه میشود:
- بوت لودر اندروید (ABL) فایل pvmfw را از پارتیشن خود در حافظه بارگذاری کرده و ایمیج را تأیید میکند.
- ABL اطلاعات محرمانهی موتور ترکیب شناسهی دستگاه (DICE) خود (شناسههای دستگاه ترکیبی (CDI) و زنجیرهی گواهی DICE) را از یک ریشهی اعتماد (Root of Trust) دریافت میکند.
- ABL، CDI های لازم برای pvmfw را استخراج کرده و آنها را به فایل باینری pvmfw اضافه میکند.
- ABL یک گره ناحیه حافظه رزرو شده
linux,pkvm-guest-firmware-memoryرا به DT اضافه میکند که مکان و اندازه فایل باینری pvmfw و رمزهای استخراج شده در مرحله قبل را توصیف میکند. - ABL کنترل را به لینوکس واگذار میکند و لینوکس pKVM را راهاندازی اولیه میکند.
- pKVM ناحیه حافظه pvmfw را از جداول صفحه مرحله ۲ میزبان unmap میکند و در طول زمان روشن بودن دستگاه، از آن در برابر میزبان (و مهمانان) محافظت میکند.
پس از بوت شدن دستگاه، میکرودروید طبق مراحل ذکر شده در بخش «توالی بوت» در سند میکرودروید بوت میشود.
بوت pVM
هنگام ایجاد یک pVM، crosvm (یا یک VMM دیگر) باید یک memslot به اندازه کافی بزرگ ایجاد کند تا توسط hypervisor با تصویر pvmfw پر شود. VMM همچنین در لیست ثباتهایی که میتواند مقدار اولیه آنها را تنظیم کند، محدود است (x0-x14 برای vCPU اصلی، هیچ ثباتی برای vCPU های ثانویه وجود ندارد). ثباتهای باقی مانده رزرو شده و بخشی از hypervisor-pvmfw ABI هستند.
وقتی pVM اجرا میشود، هایپروایزر ابتدا کنترل vCPU اصلی را به pvmfw میدهد. فریمور انتظار دارد که crosvm یک هسته امضا شده با AVB، که میتواند یک بوت لودر یا هر تصویر دیگری باشد، و یک FDT امضا نشده را در حافظه با آفستهای مشخص بارگذاری کرده باشد. pvmfw امضای AVB را اعتبارسنجی میکند و در صورت موفقیت، یک درخت دستگاه قابل اعتماد از FDT دریافتی ایجاد میکند، اسرار آن را از حافظه پاک میکند و به نقطه ورود بار داده منشعب میشود. اگر یکی از مراحل تأیید با شکست مواجه شود، فریمور یک فراخوان PSCI SYSTEM_RESET صادر میکند.
بین بوتها، اطلاعات مربوط به نمونه pVM در یک پارتیشن (دستگاه virtio-blk) ذخیره شده و با رمز pvmfw رمزگذاری میشود تا اطمینان حاصل شود که پس از راهاندازی مجدد، رمز به نمونه صحیح اختصاص داده میشود.