
Auf dieser Seite werden die Datenstrukturen und Methoden beschrieben, die verwendet werden, um Operand-Puffer effizient zwischen dem Treiber und dem Framework zu übertragen.
Bei der Modellkompilierung stellt das Framework dem Treiber die Werte der konstanten Operanden zur Verfügung. Abhängig von der Lebensdauer des konstanten Operanden befinden sich seine Werte entweder in einem HIDL-Vektor oder einem gemeinsamen Arbeitsspeicherpool.
- Wenn der Zeitraum
CONSTANT_COPYist, befinden sich die Werte im FeldoperandValuesder Modellstruktur. Da die Werte im HIDL-Vektor während der Interprozesskommunikation (IPC) kopiert werden, wird er in der Regel nur für eine kleine Datenmenge wie skalare Operanden (z. B. den Aktivierungsskalar inADD) und kleine Tensorparameter (z. B. den Formtensor inRESHAPE) verwendet. - Wenn der Zeitraum
CONSTANT_REFERENCEist, befinden sich die Werte im Feldpoolsder Modellstruktur. Beim IPC werden nur die Handles der Shared Memory-Pools dupliziert, nicht die Rohwerte. Daher ist es effizienter, eine große Menge an Daten (z. B. die Gewichtsparameter in Faltungen) mit gemeinsam genutzten Speicherpools als mit HIDL-Vektoren zu speichern.
Zur Ausführungszeit des Modells stellt das Framework dem Treiber die Puffer der Ein- und Ausgabeargumente zur Verfügung. Im Gegensatz zu den Compile-Zeit-Konstanten, die in einem HIDL-Vektor gesendet werden können, werden die Ein- und Ausgabedaten einer Ausführung immer über eine Sammlung von Speicherpools übertragen.
Der HIDL-Datentyp hidl_memory wird sowohl bei der Kompilierung als auch bei der Ausführung verwendet, um einen nicht zugeordneten Shared Memory-Pool darzustellen. Der Treiber sollte den Speicher entsprechend zuordnen, damit er basierend auf dem Namen des hidl_memory-Datentyps verwendet werden kann.
Folgende Speichernamen werden unterstützt:
ashmem: Geteilter Android-Arbeitsspeicher. Weitere Informationen finden Sie unter Arbeitsspeicher.mmap_fd: Gemeinsamer Arbeitsspeicher, der durch einen Dateideskriptor übermmapgesichert wird.hardware_buffer_blob: Gemeinsamer Arbeitsspeicher, der von einem AHardwareBuffer mit dem FormatAHARDWARE_BUFFER_FORMAT_BLOBunterstützt wird. Verfügbar ab Neural Networks (NN) HAL 1.2. Weitere Informationen finden Sie unter AHardwareBuffer.hardware_buffer: Gemeinsamer Arbeitsspeicher, der von einem allgemeinen AHardwareBuffer unterstützt wird, der nicht das FormatAHARDWARE_BUFFER_FORMAT_BLOBverwendet. Der Hardwarepuffer im Nicht-BLOB-Modus wird nur bei der Modellausführung unterstützt.Verfügbar ab NN HAL 1.2. Weitere Informationen finden Sie unter AHardwareBuffer.
Ab NN HAL 1.3 unterstützt NNAPI Speicherbereiche, die Zuweisungsschnittstellen für von Treibern verwaltete Puffer bereitstellen. Die vom Treiber verwalteten Puffer können auch als Ausführungs-Ein- oder Ausgaben verwendet werden. Weitere Informationen finden Sie unter Memory-Domains.
NNAPI-Treiber müssen die Zuordnung von ashmem- und mmap_fd-Speichernamen unterstützen. Ab NN HAL 1.3 müssen Treiber auch das Mapping von hardware_buffer_blob unterstützen. Die Unterstützung für den allgemeinen Nicht-BLOB-Modus hardware_buffer und Speicherdomains ist optional.
AHardwareBuffer
Ein AHardwareBuffer ist eine Art von gemeinsam genutztem Speicher, der einen Gralloc-Puffer umschließt. In Android 10 unterstützt die Neural Networks API (NNAPI) die Verwendung von AHardwareBuffer. So kann der Treiber Ausführungen ohne Kopieren von Daten durchführen, was die Leistung und den Stromverbrauch von Apps verbessert. Beispielsweise kann ein Kamera-HAL-Stack AHardwareBuffer-Objekte an die NNAPI für Machine-Learning-Arbeitslasten übergeben, indem er AHardwareBuffer-Handles verwendet, die von Kamera-NDK- und Media-NDK-APIs generiert werden. Weitere Informationen finden Sie unter: ANeuralNetworksMemory_createFromAHardwareBuffer.
In NNAPI verwendete AHardwareBuffer-Objekte werden über eine hidl_memory-Struktur namens hardware_buffer oder hardware_buffer_blob an den Treiber übergeben.
Die hidl_memory-Struktur hardware_buffer_blob stellt nur AHardwareBuffer-Objekte mit dem AHARDWAREBUFFER_FORMAT_BLOB-Format dar.
Die vom Framework benötigten Informationen sind im Feld hidl_handle des Structs hidl_memory codiert. Das Feld hidl_handle umschließt native_handle, das alle erforderlichen Metadaten zu AHardwareBuffer- oder Gralloc-Puffern enthält.
Der Treiber muss das bereitgestellte Feld hidl_handle richtig decodieren und auf den durch hidl_handle beschriebenen Speicher zugreifen. Wenn die Methode getSupportedOperations_1_2, getSupportedOperations_1_1 oder getSupportedOperations aufgerufen wird, sollte der Treiber erkennen, ob er den bereitgestellten hidl_handle decodieren und auf den durch hidl_handle beschriebenen Speicher zugreifen kann. Die Modellvorbereitung muss fehlschlagen, wenn das Feld hidl_handle, das für einen konstanten Operanden verwendet wird, nicht unterstützt wird. Die Ausführung muss fehlschlagen, wenn das Feld hidl_handle, das für einen Eingabe- oder Ausgabeoperanden der Ausführung verwendet wird, nicht unterstützt wird. Es wird empfohlen, dass der Treiber einen GENERAL_FAILURE-Fehlercode zurückgibt, wenn die Modellvorbereitung oder -ausführung fehlschlägt.
Erinnerungsdomains
Auf Geräten mit Android 11 oder höher unterstützt NNAPI Speicherdome, die Zuweisungsschnittstellen für treiberverwaltete Puffer bereitstellen. So können geräteinterne Speicher über Ausführungen hinweg weitergegeben werden, wodurch unnötiges Kopieren und Transformieren von Daten zwischen aufeinanderfolgenden Ausführungen auf demselben Treiber unterdrückt wird. Dieser Ablauf ist in Abbildung 1 dargestellt.
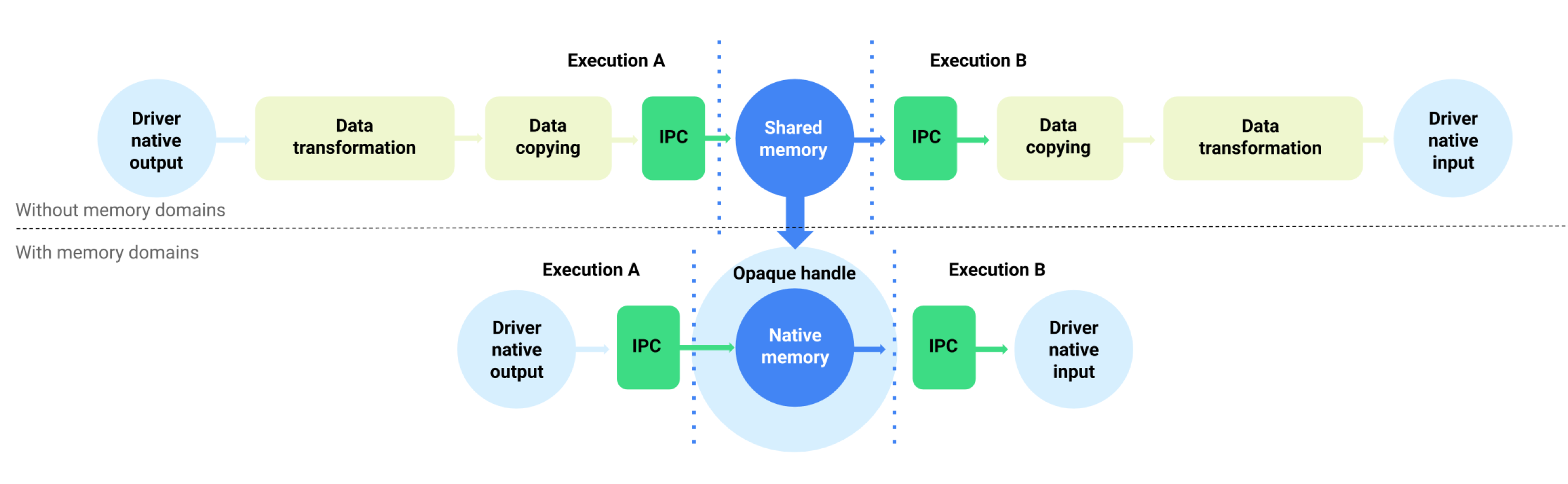
Abbildung 1. Datenfluss mit Speicherbereichen puffern
Die Funktion „Memory Domain“ ist für Tensoren vorgesehen, die hauptsächlich intern im Treiber verwendet werden und auf die auf Clientseite nicht häufig zugegriffen werden muss. Beispiele für solche Tensoren sind die Status-Tensoren in Sequenzmodellen. Für Tensoren, die häufigen CPU-Zugriff auf der Clientseite benötigen, ist es besser, Shared-Memory-Pools zu verwenden.
Implementieren Sie IDevice::allocate, um die Funktion für die Speicherdomain zu unterstützen und dem Framework zu ermöglichen, die Zuweisung von treiberverwalteten Puffern anzufordern. Während der Zuweisung stellt das Framework die folgenden Eigenschaften und Nutzungsmuster für den Puffer bereit:
BufferDescbeschreibt die erforderlichen Eigenschaften des Puffers.BufferRolebeschreibt das potenzielle Nutzungsmuster des Puffers als Eingabe oder Ausgabe eines vorbereiteten Modells. Bei der Pufferzuweisung können mehrere Rollen angegeben werden. Der zugewiesene Puffer kann nur für die angegebenen Rollen verwendet werden.
Der zugewiesene Puffer ist intern im Treiber. Ein Treiber kann einen beliebigen Pufferort oder ein beliebiges Datenlayout auswählen. Wenn der Puffer erfolgreich zugewiesen wurde, kann der Client des Treibers mit dem zurückgegebenen Token oder dem IBuffer-Objekt auf den Puffer verweisen oder mit ihm interagieren.
Das Token aus IDevice::allocate wird bereitgestellt, wenn auf den Puffer als eines der MemoryPool-Objekte in der Request-Struktur einer Ausführung verwiesen wird. Damit ein Prozess nicht versucht, auf den in einem anderen Prozess zugewiesenen Puffer zuzugreifen, muss der Treiber bei jeder Verwendung des Puffers eine entsprechende Validierung durchführen. Der Treiber muss prüfen, ob die Pufferverwendung eine der BufferRole-Rollen ist, die bei der Zuweisung angegeben wurden, und die Ausführung sofort beenden, wenn die Verwendung unzulässig ist.
Das Objekt IBuffer wird für das explizite Kopieren von Arbeitsspeicher verwendet. In bestimmten Situationen muss der Client des Treibers den vom Treiber verwalteten Puffer aus einem gemeinsam genutzten Speicherpool initialisieren oder den Puffer in einen gemeinsam genutzten Speicherpool kopieren. Beispiel-Anwendungsfälle umfassen Folgendes:
- Initialisierung des Status-Tensors
- Zwischenergebnisse im Cache speichern
- Fallback-Ausführung auf der CPU
Zur Unterstützung dieser Anwendungsfälle muss der Treiber IBuffer::copyTo und IBuffer::copyFrom mit ashmem, mmap_fd und hardware_buffer_blob implementieren, wenn er die Zuweisung von Speicherbereichen unterstützt. Es ist optional für den Treiber, den Nicht-BLOB-Modus zu unterstützen hardware_buffer.
Bei der Pufferzuweisung können die Dimensionen des Puffers aus den entsprechenden Modelloperanden aller von BufferRole angegebenen Rollen und den in BufferDesc angegebenen Dimensionen abgeleitet werden. Wenn alle Dimensionsinformationen kombiniert werden, hat der Puffer möglicherweise unbekannte Dimensionen oder einen unbekannten Rang. In diesem Fall befindet sich der Puffer in einem flexiblen Zustand, in dem die Dimensionen bei Verwendung als Modelleingabe festgelegt sind und bei Verwendung als Modellausgabe dynamisch sind. Derselbe Puffer kann bei verschiedenen Ausführungen mit unterschiedlichen Ausgabegrößen verwendet werden. Der Treiber muss die Pufferanpassung richtig verarbeiten.
Die Funktion „Gemerkte Informationen“ ist optional. Ein Treiber kann aus verschiedenen Gründen feststellen, dass er eine bestimmte Zuweisungsanfrage nicht unterstützen kann. Beispiel:
- Der angeforderte Puffer hat eine dynamische Größe.
- Der Treiber hat Arbeitsspeicherbeschränkungen, die verhindern, dass er große Puffer verarbeiten kann.
Mehrere Threads können gleichzeitig aus dem vom Treiber verwalteten Puffer lesen. Der gleichzeitige Zugriff auf den Puffer zum Schreiben oder Lesen/Schreiben ist nicht definiert, darf aber nicht zum Absturz des Treibers oder zum unbegrenzten Blockieren des Aufrufers führen. Der Treiber kann einen Fehler zurückgeben oder den Inhalt des Puffers in einem unbestimmten Zustand belassen.