
Cette page décrit les structures de données et les méthodes utilisées pour communiquer efficacement les tampons d'opérandes entre le pilote et le framework.
Au moment de la compilation du modèle, le framework fournit les valeurs des opérandes constants au pilote. En fonction de la durée de vie de l'opérande constant, ses valeurs se trouvent dans un vecteur HIDL ou dans un pool de mémoire partagée.
- Si la durée de vie est
CONSTANT_COPY, les valeurs se trouvent dans le champoperandValuesde la structure du modèle. Étant donné que les valeurs du vecteur HIDL sont copiées lors de la communication inter-processus (IPC), ce vecteur n'est généralement utilisé que pour contenir une petite quantité de données telles que des opérandes scalaires (par exemple, le scalaire d'activation dansADD) et de petits paramètres de tenseur (par exemple, le tenseur de forme dansRESHAPE). - Si la durée de vie est
CONSTANT_REFERENCE, les valeurs se trouvent dans le champpoolsde la structure du modèle. Seuls les handles des pools de mémoire partagée sont dupliqués lors de l'IPC, au lieu de copier les valeurs brutes. Il est donc plus efficace de conserver une grande quantité de données (par exemple, les paramètres de pondération dans les convolutions) à l'aide de pools de mémoire partagée que de vecteurs HIDL.
Lors de l'exécution du modèle, le framework fournit les tampons des opérandes d'entrée et de sortie au pilote. Contrairement aux constantes de compilation qui peuvent être envoyées dans un vecteur HIDL, les données d'entrée et de sortie d'une exécution sont toujours communiquées via une collection de pools de mémoire.
Le type de données HIDL hidl_memory est utilisé à la fois pour la compilation et l'exécution afin de représenter un pool de mémoire partagée non mappé. Le pilote doit mapper la mémoire en conséquence pour la rendre utilisable en fonction du nom du type de données hidl_memory.
Voici les noms de mémoire acceptés :
ashmem: mémoire partagée Android. Pour en savoir plus, consultez mémoire.mmap_fd: mémoire partagée soutenue par un descripteur de fichier viammap.hardware_buffer_blob: mémoire partagée soutenue par un AHardwareBuffer au formatAHARDWARE_BUFFER_FORMAT_BLOB. Disponible à partir de NN HAL 1.2. Pour en savoir plus, consultez AHardwareBuffer.hardware_buffer: mémoire partagée soutenue par un AHardwareBuffer général qui n'utilise pas le formatAHARDWARE_BUFFER_FORMAT_BLOB. Le tampon matériel en mode non-BLOB n'est pris en charge que dans l'exécution du modèle.Disponible à partir de NN HAL 1.2. Pour en savoir plus, consultez AHardwareBuffer.
À partir de NN HAL 1.3, NNAPI est compatible avec les domaines de mémoire qui fournissent des interfaces d'allocation pour les tampons gérés par le pilote. Les tampons gérés par le pilote peuvent également être utilisés comme entrées ou sorties d'exécution. Pour en savoir plus, consultez Domaines de mémoire.
Les pilotes NNAPI doivent être compatibles avec le mappage des noms de mémoire ashmem et mmap_fd. À partir de NN HAL 1.3, les pilotes doivent également être compatibles avec le mappage de hardware_buffer_blob. La compatibilité avec le mode non-BLOB général hardware_buffer et les domaines de mémoire est facultative.
AHardwareBuffer
AHardwareBuffer est un type de mémoire partagée qui encapsule un tampon Gralloc. Dans Android 10, l'API Neural Networks (NNAPI) est compatible avec l'utilisation d'AHardwareBuffer, ce qui permet au pilote d'effectuer des exécutions sans copier de données, ce qui améliore les performances et la consommation d'énergie des applications. Par exemple, une pile HAL de l'appareil photo peut transmettre des objets AHardwareBuffer à la NNAPI pour les charges de travail de machine learning à l'aide de handles AHardwareBuffer générés par les API NDK de l'appareil photo et NDK du module multimédia. Pour en savoir plus, consultez la section ANeuralNetworksMemory_createFromAHardwareBuffer.
Les objets AHardwareBuffer utilisés dans NNAPI sont transmis au pilote via une structure hidl_memory nommée hardware_buffer ou hardware_buffer_blob.
La structure hidl_memory hardware_buffer_blob ne représente que les objets AHardwareBuffer
avec le format AHARDWAREBUFFER_FORMAT_BLOB.
Les informations requises par le framework sont encodées dans le champ hidl_handle de la structure hidl_memory. Le champ hidl_handle encapsule native_handle, qui encode toutes les métadonnées requises concernant AHardwareBuffer ou le tampon Gralloc.
Le pilote doit décoder correctement le champ hidl_handle fourni et accéder à la mémoire décrite par hidl_handle. Lorsque la méthode getSupportedOperations_1_2, getSupportedOperations_1_1 ou getSupportedOperations est appelée, le pilote doit détecter s'il peut décoder le hidl_handle fourni et accéder à la mémoire décrite par hidl_handle. La préparation du modèle doit échouer si le champ hidl_handle utilisé pour un opérande constant n'est pas pris en charge. L'exécution doit échouer si le champ hidl_handle utilisé pour un opérande d'entrée ou de sortie de l'exécution n'est pas compatible. Il est recommandé au pilote de renvoyer un code d'erreur GENERAL_FAILURE en cas d'échec de la préparation ou de l'exécution du modèle.
Domaines de mémoire
Pour les appareils exécutant Android 11 ou version ultérieure, NNAPI est compatible avec les domaines de mémoire qui fournissent des interfaces d'allocation pour les tampons gérés par le pilote. Cela permet de transmettre les mémoires natives d'appareils lors des exécutions, en supprimant la copie et la transformation inutiles des données entre les exécutions consécutives sur le même pilote. Ce flux est illustré dans la figure 1.
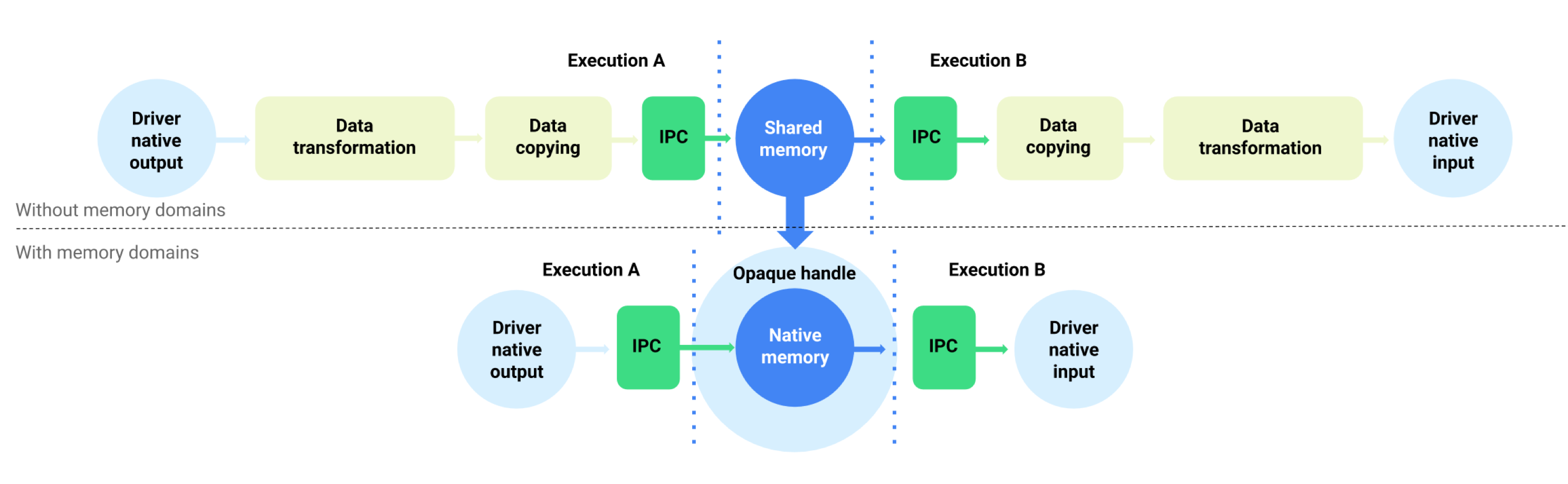
Figure 1. Mettre en mémoire tampon le flux de données à l'aide de domaines de mémoire
La fonctionnalité de domaine de mémoire est destinée aux tenseurs principalement internes pour le pilote et qui n'ont pas besoin d'un accès fréquent côté client. Parmi ces tenseurs, citons les tenseurs d'état dans les modèles de séquence. Pour les tenseurs qui nécessitent un accès fréquent au processeur côté client, il est préférable d'utiliser des pools de mémoire partagés.
Pour prendre en charge la fonctionnalité de domaine de mémoire, implémentez IDevice::allocate afin de permettre au framework de demander l'allocation de mémoire tampon gérée par le pilote. Lors de l'allocation, le framework fournit les propriétés et les modèles d'utilisation suivants pour le tampon :
BufferDescdécrit les propriétés requises du tampon.BufferRoledécrit le modèle d'utilisation potentiel du tampon en tant qu'entrée ou sortie d'un modèle préparé. Plusieurs rôles peuvent être spécifiés lors de l'allocation du tampon, et le tampon alloué ne peut être utilisé que pour les rôles spécifiés.
La mémoire tampon allouée est interne au pilote. Un pilote peut choisir n'importe quel emplacement de mémoire tampon ou mise en page de données. Une fois le tampon alloué, le client du pilote peut référencer le tampon ou interagir avec lui à l'aide du jeton renvoyé ou de l'objet IBuffer.
Le jeton de IDevice::allocate est fourni lorsque le tampon est référencé comme l'un des objets MemoryPool dans la structure Request d'une exécution. Pour empêcher un processus d'essayer d'accéder au tampon alloué dans un autre processus, le pilote doit appliquer une validation appropriée à chaque utilisation du tampon. Le pilote doit valider que l'utilisation du tampon correspond à l'un des rôles BufferRole fournis lors de l'allocation et doit immédiatement échouer l'exécution si l'utilisation est illégale.
L'objet IBuffer est utilisé pour la copie explicite de la mémoire. Dans certaines situations, le client du pilote doit initialiser le tampon géré par le pilote à partir d'un pool de mémoire partagée ou copier le tampon dans un pool de mémoire partagée. Voici quelques exemples de cas d'utilisation :
- Initialisation du Tensor d'état
- Mettre en cache les résultats intermédiaires
- Exécution de secours sur le CPU
Pour prendre en charge ces cas d'utilisation, le pilote doit implémenter IBuffer::copyTo et IBuffer::copyFrom avec ashmem, mmap_fd et hardware_buffer_blob s'il prend en charge l'allocation de domaine de mémoire. Le pilote peut choisir de prendre en charge le mode non-BLOB hardware_buffer.
Lors de l'allocation de mémoire tampon, les dimensions de la mémoire tampon peuvent être déduites des opérandes de modèle correspondants de tous les rôles spécifiés par BufferRole et des dimensions fournies dans BufferDesc. Avec toutes les informations dimensionnelles combinées, la mémoire tampon peut avoir des dimensions ou un rang inconnus. Dans ce cas, le tampon est dans un état flexible où les dimensions sont fixes lorsqu'il est utilisé comme entrée de modèle et dans un état dynamique lorsqu'il est utilisé comme sortie de modèle. Le même tampon peut être utilisé avec différentes formes de sorties lors de différentes exécutions, et le pilote doit gérer correctement le redimensionnement du tampon.
Le domaine de mémoire est une fonctionnalité facultative. Un pilote peut déterminer qu'il ne peut pas prendre en charge une demande d'allocation donnée pour plusieurs raisons. Exemple :
- La mémoire tampon demandée a une taille dynamique.
- Le pilote présente des contraintes de mémoire qui l'empêchent de gérer les grands tampons.
Il est possible que plusieurs threads différents lisent simultanément le tampon géré par le pilote. L'accès simultané au tampon pour l'écriture ou la lecture/écriture n'est pas défini, mais il ne doit pas planter le service de pilote ni bloquer l'appelant indéfiniment. Le pilote peut renvoyer une erreur ou laisser le contenu du tampon dans un état indéterminé.