
На этой странице представлен обзор реализации драйвера API нейронных сетей (NNAPI). Для получения более подробной информации см. документацию, содержащуюся в файлах определения HAL в каталоге hardware/interfaces/neuralnetworks . Пример реализации драйвера находится в frameworks/ml/nn/driver/sample .
Для получения дополнительной информации об API нейронных сетей см. раздел «API нейронных сетей» .
Нейронные сети HAL
HAL для нейронных сетей (NN) определяет абстракцию различных устройств , таких как графические процессоры (GPU) и цифровые сигнальные процессоры (DSP), которые используются в продукте (например, телефоне или планшете). Драйверы для этих устройств должны соответствовать HAL для нейронных сетей. Интерфейс описывается в файлах определения HAL в каталоге hardware/interfaces/neuralnetworks .
Общая схема взаимодействия между фреймворком и драйвером представлена на рисунке 1.
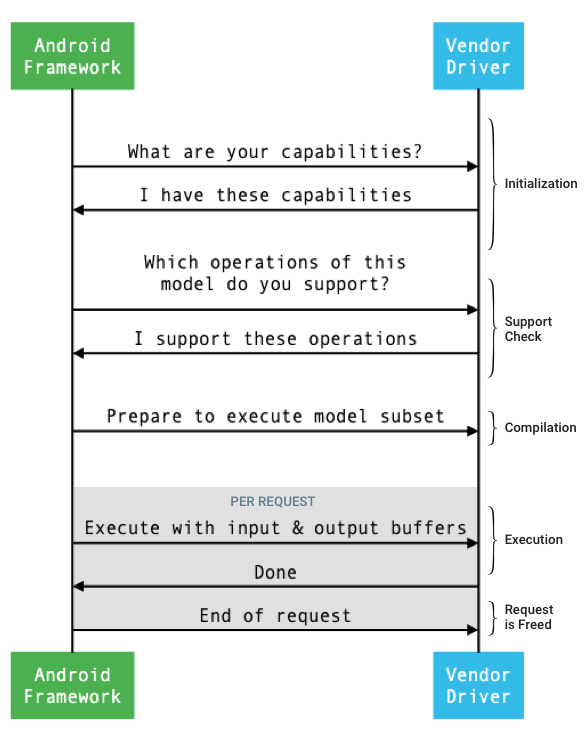
Рисунок 1. Схема работы нейронных сетей.
Инициализация
При инициализации фреймворк запрашивает у драйвера его возможности, используя IDevice::getCapabilities_1_3 . Структура @1.3::Capabilities включает все типы данных и представляет нерелаксированную производительность с помощью вектора.
Для определения того, как распределять вычисления между доступными устройствами, платформа использует возможности для понимания того, насколько быстро и энергоэффективно каждый драйвер может выполнять задачи. Для предоставления этой информации драйвер должен предоставить стандартизированные показатели производительности, основанные на выполнении эталонных рабочих нагрузок.
Чтобы определить значения, которые драйвер возвращает в ответ на вызов IDevice::getCapabilities_1_3 , используйте приложение NNAPI для измерения производительности для соответствующих типов данных. Для измерения производительности для 32-битных значений с плавающей запятой рекомендуются модели MobileNet v1 и v2, asr_float и tts_float , а для 8-битных квантованных значений — квантованные модели MobileNet v1 и v2. Для получения дополнительной информации см. Android Machine Learning Test Suite .
В Android 9 и более ранних версиях структура Capabilities содержит информацию о производительности драйвера только для тензоров с плавающей запятой и квантованных тензоров и не включает скалярные типы данных.
В рамках процесса инициализации платформа может запрашивать дополнительную информацию, используя IDevice::getType , IDevice::getVersionString , IDevice:getSupportedExtensions и IDevice::getNumberOfCacheFilesNeeded .
В промежутках между перезагрузками продукта платформа ожидает, что все запросы, описанные в этом разделе, всегда будут сообщать одни и те же значения для данного драйвера. В противном случае приложение, использующее этот драйвер, может демонстрировать снижение производительности или некорректное поведение.
Компиляция
Эта платформа определяет, какие устройства использовать при получении запроса от приложения. В Android 10 приложения могут обнаруживать и указывать устройства, которые будет использовать платформа. Для получения дополнительной информации см. раздел «Обнаружение и назначение устройств» .
На этапе компиляции модели фреймворк отправляет модель каждому потенциальному драйверу, вызывая IDevice::getSupportedOperations_1_3 . Каждый драйвер возвращает массив логических значений, указывающих, какие операции модели поддерживаются. Драйвер может определить, что он не может поддерживать данную операцию по ряду причин. Например:
- Драйвер не поддерживает данный тип данных.
- Драйвер поддерживает операции только с определенными входными параметрами. Например, драйвер может поддерживать свертки 3x3 и 5x5, но не свертки 7x7.
- У драйвера имеются ограничения по объему памяти, не позволяющие ему обрабатывать большие графы или входные данные.
В процессе компиляции входные, выходные и внутренние операнды модели, как описано в OperandLifeTime , могут иметь неизвестные размеры или ранг. Для получения дополнительной информации см. Output shape .
Данная структура инструктирует каждый выбранный драйвер подготовиться к выполнению подмножества модели, вызвав IDevice::prepareModel_1_3 . Затем каждый драйвер компилирует свое подмножество. Например, драйвер может сгенерировать код или создать переупорядоченную копию весов. Поскольку между компиляцией модели и выполнением запросов может пройти значительное количество времени, такие ресурсы, как большие объемы памяти устройства, не следует выделять во время компиляции.
В случае успеха драйвер возвращает дескриптор @1.3::IPreparedModel . Если драйвер возвращает код ошибки при подготовке своего подмножества модели, платформа запускает всю модель на ЦП.
Чтобы сократить время, затрачиваемое на компиляцию при запуске приложения, драйвер может кэшировать артефакты компиляции. Дополнительную информацию см. в разделе «Кэширование компиляции» .
Исполнение
Когда приложение запрашивает у фреймворка выполнение запроса, фреймворк по умолчанию вызывает метод HAL IPreparedModel::executeSynchronously_1_3 для выполнения синхронного выполнения над подготовленной моделью. Запрос также может быть выполнен асинхронно с помощью метода execute_1_3 , метода executeFenced (см. Выполнение с ограничением по времени ) или с помощью пакетного выполнения .
Синхронные вызовы повышают производительность и снижают накладные расходы на многопоточность по сравнению с асинхронными вызовами, поскольку управление возвращается процессу приложения только после завершения выполнения. Это означает, что драйверу не требуется отдельный механизм для уведомления процесса приложения о завершении выполнения.
При использовании асинхронного метода execute_1_3 управление возвращается процессу приложения после начала выполнения, и драйвер должен уведомить фреймворк о завершении выполнения, используя @1.3::IExecutionCallback .
Параметр Request передаваемый методу execute, перечисляет входные и выходные операнды, используемые для выполнения. Память, в которой хранятся данные операндов, должна использовать построчный порядок, при этом первое измерение должно быть самым медленным, и в конце каждой строки не должно быть выравнивания. Дополнительную информацию о типах операндов см. в разделе «Операнды» .
Для драйверов NN HAL 1.2 и выше, после завершения запроса, в фреймворк возвращается информация о статусе ошибки, форме выходных данных и времени выполнения. Во время выполнения выходные или внутренние операнды модели могут иметь одно или несколько неизвестных измерений или неизвестный ранг. Если хотя бы один выходной операнд имеет неизвестное измерение или ранг, драйвер должен возвращать информацию о выходных данных с динамическим размером.
Для драйверов с NN HAL 1.1 или ниже после завершения запроса возвращается только статус ошибки. Для успешного завершения выполнения необходимо полностью указать размерность входных и выходных операндов. Внутренние операнды могут иметь одну или несколько неизвестных размерностей, но их ранг должен быть указан.
Для запросов пользователей, охватывающих несколько драйверов, платформа отвечает за резервирование промежуточной памяти и за упорядочивание вызовов к каждому драйверу.
Несколько запросов могут быть инициированы параллельно для одного и того же объекта @1.3::IPreparedModel . Драйвер может выполнять запросы параллельно или последовательно.
Система может запросить у водителя сохранение более чем одной подготовленной модели. Например, подготовить модель m1 , подготовить m2 , выполнить запрос r1 на m1 , выполнить запрос r2 на m2 , выполнить запрос r3 на m1 , выполнить запрос r4 на m2 , освободить (описано в разделе «Очистка ») m1 и освободить m2 .
Чтобы избежать медленного выполнения на первом этапе, что может привести к ухудшению пользовательского опыта (например, к заиканию первого кадра), драйвер должен выполнять большую часть инициализации на этапе компиляции. Инициализация при первом выполнении должна ограничиваться действиями, которые негативно влияют на работоспособность системы при раннем выполнении, такими как резервирование больших временных буферов или увеличение тактовой частоты устройства. Драйверы, которые могут подготовить только ограниченное количество параллельных моделей, возможно, должны будут выполнять свою инициализацию при первом выполнении.
В Android 10 и более поздних версиях, в случаях, когда выполняется несколько запусков с одной и той же подготовленной моделью с небольшим интервалом, клиент может использовать объект пакетного выполнения для связи между процессами приложения и драйвера. Дополнительную информацию см. в разделах «Пакетные выполнения» и «Быстрые очереди сообщений» .
Для повышения производительности при одновременном выполнении нескольких процессов с небольшой задержкой драйвер может использовать временные буферы или увеличивать тактовую частоту. Рекомендуется создать поток-сторожевой таймер для освобождения ресурсов, если в течение определенного периода времени не поступает новых запросов.
Форма выходных данных
Для запросов, в которых для одного или нескольких выходных операндов не указаны все размеры, драйвер должен после выполнения предоставить список форм выходных данных, содержащий информацию о размерах для каждого выходного операнда. Дополнительную информацию о размерах см. в OutputShape .
Если выполнение завершается с ошибкой из-за недостаточного размера выходного буфера, драйвер должен указать, у каких выходных операндов недостаточный размер буфера в списке форм выходных данных, и должен сообщить как можно больше информации о размерах, используя ноль для неизвестных размеров.
Время
В Android 10 приложение может запросить время выполнения, если в процессе компиляции было указано единственное устройство для его использования. Подробности см. в разделах MeasureTiming » и «Обнаружение и назначение устройств» . В этом случае драйвер NN HAL 1.2 должен измерить продолжительность выполнения или сообщить UINT64_MAX (чтобы указать, что продолжительность недоступна) при выполнении запроса. Драйвер должен минимизировать любые потери производительности, возникающие в результате измерения продолжительности выполнения.
В структуре Timing драйвер сообщает следующие значения длительности в микросекундах:
- Время выполнения на устройстве: не включает время выполнения драйвера, который работает на процессоре хоста.
- Время выполнения в драйвере: включает время выполнения на устройстве.
В эти временные рамки необходимо включать время, когда выполнение приостановлено, например, когда оно было прервано другими задачами или когда оно ожидает освобождения ресурса.
Если драйверу не было предложено измерить продолжительность выполнения или если произошла ошибка выполнения, драйвер должен сообщать значения продолжительности как UINT64_MAX . Даже если драйверу было предложено измерить продолжительность выполнения, он может вместо этого сообщить UINT64_MAX для времени на устройстве, времени в драйвере или для обоих параметров. Если драйвер сообщает оба параметра как значение, отличное от UINT64_MAX , время выполнения в драйвере должно быть равно или превышать время на устройстве.
Огороженная казнь
В Android 11 NNAPI позволяет выполнять операции ожидания списка дескрипторов sync_fence и, при необходимости, возвращать объект sync_fence , который отправляется сигналом по завершении выполнения. Это снижает накладные расходы для моделей с небольшими последовательностями и сценариев потоковой обработки. Выполнение с ограничением по времени также обеспечивает более эффективное взаимодействие с другими компонентами, которые могут отправлять сигналы или ожидать sync_fence . Для получения дополнительной информации о sync_fence см. раздел «Фреймворк синхронизации» .
В режиме ожидания с ограничением по времени выполнения фреймворк вызывает метод IPreparedModel::executeFenced для запуска асинхронного выполнения с ограничением по времени на подготовленной модели с вектором синхронных ограничений, которые необходимо ожидать. Если асинхронная задача завершается до возврата вызова, для sync_fence может быть возвращен пустой дескриптор. Также необходимо вернуть объект IFencedExecutionCallback , чтобы фреймворк мог запрашивать информацию о состоянии ошибки и продолжительности.
После завершения выполнения с помощью IFencedExecutionCallback::getExecutionInfo можно получить следующие два значения времени , измеряющие продолжительность выполнения.
-
timingLaunched: Длительность от момента вызоваexecuteFencedдо момента, когдаexecuteFencedподает сигнал на возвращенныйsyncFence. -
timingFenced: Длительность от момента, когда все синхронизационные барьеры, ожидающие выполнения, будут активированы, до момента, когдаexecuteFencedактивирует возвращенныйsyncFenceбарьер.
Управление потоком
Для устройств под управлением Android 11 и выше NNAPI включает две операции управления потоком выполнения, IF и WHILE , которые принимают другие модели в качестве аргументов и выполняют их условно ( IF ) или многократно ( WHILE ). Более подробную информацию о реализации см. в разделе «Управление потоком выполнения ».
Качество обслуживания
В Android 11 NNAPI обеспечивает улучшенное качество обслуживания (QoS), позволяя приложению указывать относительные приоритеты своих моделей, максимальное время, ожидаемое для подготовки модели, и максимальное время, ожидаемое для завершения выполнения. Дополнительную информацию см. в разделе «Качество обслуживания» .
Уборка
Когда приложение завершает использование подготовленной модели, фреймворк освобождает ссылку на объект @1.3::IPreparedModel . Когда на объект IPreparedModel больше не ссылаются, он автоматически уничтожается в службе драйвера, которая его создала. В этот момент в реализации деструктора драйвера можно освободить ресурсы, специфичные для модели. Если служба драйвера хочет, чтобы объект IPreparedModel автоматически уничтожался, когда он больше не нужен клиенту, она не должна хранить никаких ссылок на объект IPreparedModel после того, как объект IPreparedeModel был возвращен через IPreparedModelCallback::notify_1_3 .
использование ЦП
Предполагается, что драйверы будут использовать ЦП для организации вычислений. Драйверы не должны использовать ЦП для выполнения вычислений на графах, поскольку это мешает фреймворку правильно распределять работу. Драйвер должен сообщать фреймворку о тех частях, которые он не может обработать, и позволить фреймворку обработать остальное.
Данная платформа предоставляет реализацию для ЦП для всех операций NNAPI, за исключением операций, определяемых поставщиком. Для получения дополнительной информации см. раздел «Расширения поставщика» .
Операции, представленные в Android 10 (уровень API 29), имеют только эталонную реализацию для ЦП, предназначенную для проверки корректности тестов CTS и VTS. Оптимизированные реализации, включенные в мобильные фреймворки машинного обучения, предпочтительнее реализации NNAPI для ЦП.
Вспомогательные функции
Код NNAPI включает в себя вспомогательные функции, которые могут использоваться службами драйверов.
Файл frameworks/ml/nn/common/include/Utils.h содержит различные вспомогательные функции, например, используемые для ведения журналов и для преобразования между различными версиями NN HAL.
VLogging:
VLOG— это макрос-обертка надLOGв Android, который записывает сообщение только в том случае, если соответствующий тег установлен в свойствеdebug.nn.vlog. Перед любыми вызовамиVLOGнеобходимо вызватьinitVLogMask(). МакросVLOG_IS_ONможно использовать для проверки того, включен ли в данный моментVLOG, что позволяет пропускать сложный код логирования, если он не нужен. Значение свойства должно быть одним из следующих:- Пустая строка, указывающая на то, что ведение журнала не предусмотрено.
- Токен
1илиallуказывает на то, что все действия по логированию должны быть выполнены. - Список тегов, разделённых пробелами, запятыми или двоеточиями, указывающих, какое именно логирование необходимо выполнить. Теги:
compilation,cpuexe,driver,execution,managerиmodel.
compliantWithV1_*: Возвращаетtrue, если объект NN HAL может быть преобразован в тот же тип другой версии HAL без потери информации. Например, вызовcompliantWithV1_0дляV1_2::Modelвозвращаетfalseесли модель включает типы операций, введенные в NN HAL 1.1 или NN HAL 1.2.convertToV1_*: Преобразует объект NN HAL из одной версии в другую. Предупреждение регистрируется, если преобразование приводит к потере информации (то есть, если новая версия типа не может полностью представить значение).Возможности: Функции
nonExtensionOperandPerformanceиupdateмогут использоваться для создания поляCapabilities::operandPerformance.Запрос свойств типов:
isExtensionOperandType,isExtensionOperationType,nonExtensionSizeOfData,nonExtensionOperandSizeOfData,nonExtensionOperandTypeIsScalar,tensorHasUnspecifiedDimensions.
Файл frameworks/ml/nn/common/include/ValidateHal.h содержит вспомогательные функции для проверки того, соответствует ли объект NN HAL спецификации его версии HAL.
-
validate*: Возвращаетtrueесли объект NN HAL действителен в соответствии со спецификацией его версии HAL. Типы OEM и типы расширений не проверяются. Например,validateModelвозвращаетfalseесли модель содержит операцию, которая ссылается на несуществующий индекс операнда, или операцию, которая не поддерживается в данной версии HAL.
Файл frameworks/ml/nn/common/include/Tracing.h содержит макросы, упрощающие добавление информации о трассировке в код нейронных сетей. Пример можно увидеть в вызовах макроса NNTRACE_* в примере драйвера .
Файл frameworks/ml/nn/common/include/GraphDump.h содержит вспомогательную функцию для вывода содержимого Model в графическом виде в целях отладки.
-
graphDump: Записывает представление модели в формате Graphviz (.dot) в указанный поток (если он предоставлен) или в logcat (если поток не указан).
Проверка
Для проверки вашей реализации NNAPI используйте тесты VTS и CTS, входящие в состав фреймворка Android. VTS проверяет ваши драйверы напрямую (без использования фреймворка), тогда как CTS проверяет их косвенно через фреймворк. Эти тесты проверяют каждый метод API и подтверждают, что все операции, поддерживаемые драйверами, работают корректно и предоставляют результаты, соответствующие требованиям к точности.
Требования к точности в системах CTS и VTS для NNAPI следующие:
Число с плавающей запятой: abs(ожидаемое - фактическое) <= atol + rtol * abs(ожидаемое); где:
- Для fp32 atol = 1e-5f, rtol = 5.0f * 1.1920928955078125e-7
- Для fp16 atol = rtol = 5.0f * 0.0009765625f
Квантование: с погрешностью в единицу (за исключением
mobilenet_quantized, где погрешность составляет три)Логическое значение: точное совпадение
Один из способов тестирования NNAPI с помощью CTS — генерация фиксированных псевдослучайных графов, используемых для тестирования и сравнения результатов выполнения каждого драйвера с эталонной реализацией NNAPI. Для драйверов с NN HAL 1.2 или выше, если результаты не соответствуют критериям точности, CTS сообщает об ошибке и выгружает файл спецификации для неисправной модели в /data/local/tmp для отладки. Более подробную информацию о критериях точности см. в TestRandomGraph.cpp и TestHarness.h .
Фазз-тестирование
Цель фаззинг-тестирования — обнаружение сбоев, утверждений, нарушений памяти или общего неопределенного поведения в тестируемом коде, вызванных такими факторами, как неожиданные входные данные. Для фаззинг-тестирования NNAPI Android использует тесты на основе libFuzzer , которые эффективны, поскольку используют покрытие строк предыдущих тестовых случаев для генерации новых случайных входных данных. Например, libFuzzer отдает предпочтение тестовым случаям, которые выполняются на новых строках кода. Это значительно сокращает время, необходимое для обнаружения проблемного кода.
Для проведения фаззингового тестирования с целью проверки реализации вашего драйвера, внесите изменения в файл frameworks/ml/nn/runtime/test/android_fuzzing/DriverFuzzTest.cpp в утилите тестирования libneuralnetworks_driver_fuzzer входящей в состав AOSP, добавив в него код вашего драйвера. Дополнительную информацию о фаззинговом тестировании NNAPI см. в файле frameworks/ml/nn/runtime/test/android_fuzzing/README.md .
Безопасность
Поскольку процессы приложения взаимодействуют напрямую с процессом драйвера, драйверы должны проверять аргументы получаемых вызовов. Эта проверка осуществляется системой VTS. Код проверки находится в frameworks/ml/nn/common/include/ValidateHal.h .
Водители также должны убедиться, что приложения не могут конфликтовать с другими приложениями при использовании одного и того же устройства.
Набор тестов машинного обучения для Android
Тестовый набор Android Machine Learning Test Suite (MLTS) — это бенчмарк NNAPI, включенный в CTS и VTS, предназначенный для проверки точности реальных моделей на устройствах производителей. Бенчмарк оценивает задержку и точность, а также сравнивает результаты драйверов с результатами, полученными с помощью TF Lite , работающего на ЦП, для той же модели и наборов данных. Это гарантирует, что точность драйвера не будет хуже, чем у эталонной реализации на ЦП.
Разработчики платформы Android также используют MLTS для оценки задержки и точности работы драйверов.
Эталонный тест NNAPI можно найти в двух проектах AOSP:
-
platform/test/mlts/benchmark(приложение для бенчмаркинга) -
platform/test/mlts/models(модели и наборы данных)
Модели и наборы данных
В бенчмарке NNAPI используются следующие модели и наборы данных.
- MobileNetV1 с использованием чисел с плавающей запятой и квантованных значений u8 разных размеров, запущен на небольшом подмножестве (1500 изображений) Open Images Dataset v4.
- MobileNetV2 с использованием чисел с плавающей запятой и квантованных значений u8 разных размеров, запущен на небольшом подмножестве (1500 изображений) Open Images Dataset v4.
- Акустическая модель преобразования текста в речь на основе долговременной кратковременной памяти (LSTM), протестированная на небольшом подмножестве данных из набора CMU Arctic.
- Акустическая модель на основе LSTM для автоматического распознавания речи, протестированная на небольшом подмножестве набора данных LibriSpeech.
Для получения более подробной информации см. platform/test/mlts/models .
Стресс-тестирование
Пакет тестов Android Machine Learning Test Suite включает в себя серию краш-тестов для проверки устойчивости драйверов к интенсивной эксплуатации или к нестандартным ситуациям, возникающим при поведении клиентов.
Все краш-тесты включают следующие функции:
- Обнаружение зависаний: Если клиент NNAPI зависает во время теста, тест завершается с ошибкой по причине
HANG, и набор тестов переходит к следующему тесту. - Обнаружение сбоев клиента NNAPI: тесты сохраняются при сбоях клиента, а некоторые тесты завершаются с ошибкой по причине
CRASH. - Обнаружение сбоев драйвера: Тесты могут обнаружить сбой драйвера, который приводит к ошибке при вызове NNAPI. Обратите внимание, что могут быть сбои в процессах драйвера, которые не приводят к ошибке NNAPI и не вызывают сбоя теста. Для обработки таких сбоев рекомендуется запускать команду
tailдля просмотра системного журнала на предмет ошибок или сбоев, связанных с драйвером. - Целенаправленное тестирование с использованием всех доступных ускорителей: Тесты проводятся со всеми доступными драйверами.
Все краш-тесты имеют следующие четыре возможных результата:
-
SUCCESS: Выполнение завершено без ошибок. -
FAILURE: Выполнение завершилось неудачей. Обычно это происходит из-за ошибки при тестировании модели, указывающей на то, что драйвер не смог скомпилировать или выполнить модель. -
HANG: Тестовый процесс перестал отвечать. -
CRASH: Процесс тестирования завершился с ошибкой.
Для получения дополнительной информации о стресс-тестировании и полного списка краш-тестов см. platform/test/mlts/benchmark/README.txt .
Используйте MLTS
Для использования MLTS:
- Подключите целевое устройство к рабочей станции и убедитесь, что оно доступно через adb . Экспортируйте переменную среды
ANDROID_SERIALцелевого устройства, если подключено более одного устройства. Перейдите в корневой каталог исходных файлов Android с помощью
cd.source build/envsetup.sh lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available. ./test/mlts/benchmark/build_and_run_benchmark.shПо завершении выполнения теста результаты отображаются в виде HTML-страницы и передаются в
xdg-open.
Для получения более подробной информации см. platform/test/mlts/benchmark/README.txt .
Версии HAL для нейронных сетей
В этом разделе описываются изменения, внесенные в версии Android и HAL для нейронных сетей.
Android 11
В Android 11 представлена версия NN HAL 1.3, которая включает в себя следующие существенные изменения.
- Поддержка знакового 8-битного квантования в NNAPI. Добавляет тип операнда
TENSOR_QUANT8_ASYMM_SIGNED. Драйверы с NN HAL 1.3, поддерживающие операции с беззнаковым квантованием, должны также поддерживать знаковые варианты этих операций. При выполнении знаковых и беззнаковых версий большинства квантованных операций драйверы должны выдавать одинаковые результаты до смещения 128. Существует пять исключений из этого требования:CAST,HASHTABLE_LOOKUP,LSH_PROJECTION,PAD_V2иQUANTIZED_16BIT_LSTM. ОперацияQUANTIZED_16BIT_LSTMне поддерживает знаковые операнды, а остальные четыре операции поддерживают знаковое квантование, но не требуют одинаковых результатов. - Поддержка выполнения с ограничением по времени, при котором фреймворк вызывает метод
IPreparedModel::executeFencedдля запуска асинхронного выполнения с ограничением по времени на подготовленной модели с вектором синхронных ограничений, которых необходимо дождаться. Для получения дополнительной информации см. раздел «Выполнение с ограничением по времени» . - Поддержка управления потоком выполнения. Добавляет операции
IFиWHILE, которые принимают другие модели в качестве аргументов и выполняют их условно (IF) или многократно (WHILE). Для получения дополнительной информации см. раздел «Управление потоком выполнения ». - Улучшенное качество обслуживания (QoS) достигается за счет возможности приложений указывать относительные приоритеты своих моделей, максимальное время, ожидаемое для подготовки модели, и максимальное время, ожидаемое для завершения выполнения. Дополнительную информацию см. в разделе «Качество обслуживания» .
- Поддержка доменов памяти, предоставляющих интерфейсы распределителя для буферов, управляемых драйвером. Это позволяет передавать собственную память устройства между выполнениями, подавляя ненужное копирование и преобразование данных между последовательными выполнениями на одном и том же драйвере. Для получения дополнительной информации см. раздел «Домены памяти» .
Android 10
В Android 10 представлена версия NN HAL 1.2, которая включает в себя следующие существенные изменения.
- Структура
Capabilitiesвключает все типы данных, в том числе скалярные, и представляет собой нерелексную производительность, используя вектор, а не именованные поля. - Методы
getVersionStringиgetTypeпозволяют фреймворку получать информацию о типе устройства (DeviceType) и его версии. См. раздел «Обнаружение и назначение устройств» . - Метод
executeSynchronouslyвызывается по умолчанию для синхронного выполнения. Методexecute_1_2указывает фреймворку на необходимость асинхронного выполнения. См. раздел «Выполнение» . - Параметр
MeasureTimingдляexecuteSynchronously,execute_1_2и burst execution определяет, следует ли драйверу измерять продолжительность выполнения. Результаты отображаются в структуреTiming. См. Timing . - Поддержка выполнения операций, в которых один или несколько выходных операндов имеют неизвестные размеры или ранг. См. Форма выходных данных .
- Поддержка расширений поставщика, представляющих собой наборы определенных поставщиком операций и типов данных. Драйвер сообщает о поддерживаемых расширениях через метод
IDevice::getSupportedExtensions. См. раздел «Расширения поставщика» . - Возможность для объекта пакетной обработки управлять набором пакетных выполнений с использованием быстрых очередей сообщений (FMQ) для связи между процессами приложения и драйвера, что снижает задержку. См. Пакетные выполнения и Быстрые очереди сообщений .
- Поддержка AHardwareBuffer позволяет драйверу выполнять операции без копирования данных. См. AHardwareBuffer .
- Улучшена поддержка кэширования артефактов компиляции для сокращения времени, затрачиваемого на компиляцию при запуске приложения. См. раздел «Кэширование компиляции» .
В Android 10 представлены следующие типы операндов и операции.
-
ANEURALNETWORKS_BOOL -
ANEURALNETWORKS_FLOAT16 -
ANEURALNETWORKS_TENSOR_BOOL8 -
ANEURALNETWORKS_TENSOR_FLOAT16 -
ANEURALNETWORKS_TENSOR_QUANT16_ASYMM -
ANEURALNETWORKS_TENSOR_QUANT16_SYMM -
ANEURALNETWORKS_TENSOR_QUANT8_SYMM -
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL
-
-
ANEURALNETWORKS_ABS -
ANEURALNETWORKS_ARGMAX -
ANEURALNETWORKS_ARGMIN -
ANEURALNETWORKS_AXIS_ALIGNED_BBOX_TRANSFORM -
ANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_LSTM -
ANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_RNN -
ANEURALNETWORKS_BOX_WITH_NMS_LIMIT -
ANEURALNETWORKS_CAST -
ANEURALNETWORKS_CHANNEL_SHUFFLE -
ANEURALNETWORKS_DETECTION_POSTPROCESSING -
ANEURALNETWORKS_EQUAL -
ANEURALNETWORKS_EXP -
ANEURALNETWORKS_EXPAND_DIMS -
ANEURALNETWORKS_GATHER -
ANEURALNETWORKS_GENERATE_PROPOSALS -
ANEURALNETWORKS_GREATER -
ANEURALNETWORKS_GREATER_EQUAL -
ANEURALNETWORKS_GROUPED_CONV_2D -
ANEURALNETWORKS_HEATMAP_MAX_KEYPOINT -
ANEURALNETWORKS_INSTANCE_NORMALIZATION -
ANEURALNETWORKS_LESS -
ANEURALNETWORKS_LESS_EQUAL -
ANEURALNETWORKS_LOG -
ANEURALNETWORKS_LOGICAL_AND -
ANEURALNETWORKS_LOGICAL_NOT -
ANEURALNETWORKS_LOGICAL_OR -
ANEURALNETWORKS_LOG_SOFTMAX -
ANEURALNETWORKS_MAXIMUM -
ANEURALNETWORKS_MINIMUM -
ANEURALNETWORKS_NEG -
ANEURALNETWORKS_NOT_EQUAL -
ANEURALNETWORKS_PAD_V2 -
ANEURALNETWORKS_POW -
ANEURALNETWORKS_PRELU -
ANEURALNETWORKS_QUANTIZE -
ANEURALNETWORKS_QUANTIZED_16BIT_LSTM -
ANEURALNETWORKS_RANDOM_MULTINOMIAL -
ANEURALNETWORKS_REDUCE_ALL -
ANEURALNETWORKS_REDUCE_ANY -
ANEURALNETWORKS_REDUCE_MAX -
ANEURALNETWORKS_REDUCE_MIN -
ANEURALNETWORKS_REDUCE_PROD -
ANEURALNETWORKS_REDUCE_SUM -
ANEURALNETWORKS_RESIZE_NEAREST_NEIGHBOR -
ANEURALNETWORKS_ROI_ALIGN -
ANEURALNETWORKS_ROI_POOLING -
ANEURALNETWORKS_RSQRT -
ANEURALNETWORKS_SELECT -
ANEURALNETWORKS_SIN -
ANEURALNETWORKS_SLICE -
ANEURALNETWORKS_SPLIT -
ANEURALNETWORKS_SQRT -
ANEURALNETWORKS_TILE -
ANEURALNETWORKS_TOPK_V2 -
ANEURALNETWORKS_TRANSPOSE_CONV_2D -
ANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_LSTM -
ANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_RNN
-
Android 10 вносит обновления во многие существующие функции. Обновления в основном касаются следующих аспектов:
- Поддержка структуры памяти NCHW
- Поддержка тензоров с рангом, отличным от 4, в операциях softmax и нормализации.
- Поддержка расширенных сверток
- Поддержка входных данных со смешанным квантованием в
ANEURALNETWORKS_CONCATENATION
Ниже приведен список операций, измененных в Android 10. Полную информацию об изменениях см. в разделе OperationCode в справочной документации NNAPI.
-
ANEURALNETWORKS_ADD -
ANEURALNETWORKS_AVERAGE_POOL_2D -
ANEURALNETWORKS_BATCH_TO_SPACE_ND -
ANEURALNETWORKS_CONCATENATION -
ANEURALNETWORKS_CONV_2D -
ANEURALNETWORKS_DEPTHWISE_CONV_2D -
ANEURALNETWORKS_DEPTH_TO_SPACE -
ANEURALNETWORKS_DEQUANTIZE -
ANEURALNETWORKS_DIV -
ANEURALNETWORKS_FLOOR -
ANEURALNETWORKS_FULLY_CONNECTED -
ANEURALNETWORKS_L2_NORMALIZATION -
ANEURALNETWORKS_L2_POOL_2D -
ANEURALNETWORKS_LOCAL_RESPONSE_NORMALIZATION -
ANEURALNETWORKS_LOGISTIC -
ANEURALNETWORKS_LSH_PROJECTION -
ANEURALNETWORKS_LSTM -
ANEURALNETWORKS_MAX_POOL_2D -
ANEURALNETWORKS_MEAN -
ANEURALNETWORKS_MUL -
ANEURALNETWORKS_PAD -
ANEURALNETWORKS_RELU -
ANEURALNETWORKS_RELU1 -
ANEURALNETWORKS_RELU6 -
ANEURALNETWORKS_RESHAPE -
ANEURALNETWORKS_RESIZE_BILINEAR -
ANEURALNETWORKS_RNN -
ANEURALNETWORKS_ROI_ALIGN -
ANEURALNETWORKS_SOFTMAX -
ANEURALNETWORKS_SPACE_TO_BATCH_ND -
ANEURALNETWORKS_SPACE_TO_DEPTH -
ANEURALNETWORKS_SQUEEZE -
ANEURALNETWORKS_STRIDED_SLICE -
ANEURALNETWORKS_SUB -
ANEURALNETWORKS_SVDF -
ANEURALNETWORKS_TANH -
ANEURALNETWORKS_TRANSPOSE
Android 9
В Android 9 представлена версия NN HAL 1.1, включающая следующие существенные изменения.
-
IDevice::prepareModel_1_1включает параметрExecutionPreference. Драйвер может использовать его для настройки подготовки, зная, что приложение предпочитает экономить заряд батареи или будет выполнять модель быстрыми последовательными вызовами. - Добавлено девять новых операций:
BATCH_TO_SPACE_ND,DIV,MEAN,PAD,SPACE_TO_BATCH_ND,SQUEEZE,STRIDED_SLICE,SUB,TRANSPOSE. - Приложение может указать, что вычисления с 32-битными числами с плавающей запятой могут выполняться с использованием 16-битного диапазона и/или точности чисел с плавающей запятой, установив
Model.relaxComputationFloat32toFloat16вtrue. СтруктураCapabilitiesимеет дополнительное полеrelaxedFloat32toFloat16Performance, чтобы драйвер мог сообщать фреймворку о своей производительности в расслабленном режиме.
Android 8.1
Первоначальная версия интерфейса нейронных сетей HAL (1.0) была выпущена в Android 8.1. Для получения дополнительной информации см. /neuralnetworks/1.0/ .