
Esta página fornece uma visão geral de como implementar um driver da API Neural Networks (NNAPI). Para mais detalhes, consulte a documentação encontrada nos arquivos de definição da HAL em
hardware/interfaces/neuralnetworks.
Uma implementação de driver de exemplo está em
frameworks/ml/nn/driver/sample.
Para mais informações sobre a API Neural Networks, consulte API Neural Networks.
HAL de redes neurais
A HAL de redes neurais (NN) define uma abstração dos vários dispositivos, como unidades de processamento gráfico (GPUs) e processadores de sinal digital (DSPs), que estão em um produto (por exemplo, um smartphone ou tablet). Os drivers para esses dispositivos precisam estar em conformidade com a HAL de rede neural. A interface é especificada nos arquivos de definição da HAL em
hardware/interfaces/neuralnetworks.
O fluxo geral da interface entre o framework e um driver é mostrado na figura 1.
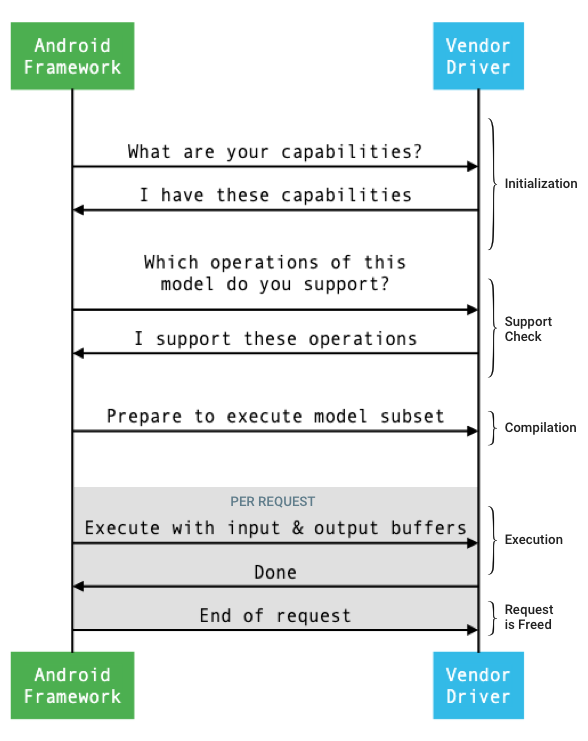
Figura 1. Fluxo de redes neurais
Inicialização
Na inicialização, o framework consulta o driver para saber as funcionalidades dele usando
IDevice::getCapabilities_1_3.
A estrutura @1.3::Capabilities inclui todos os tipos de dados e representa a performance não relaxada usando um vetor.
Para determinar como alocar computações aos dispositivos disponíveis, o framework usa as capacidades para entender a rapidez e a eficiência energética com que cada driver pode realizar uma execução. Para fornecer essas informações, o driver precisa apresentar números de desempenho padronizados com base na execução de cargas de trabalho de referência.
Para determinar os valores que o driver retorna em resposta a
IDevice::getCapabilities_1_3, use o app de comparativo de mercado da NNAPI para medir o
desempenho dos tipos de dados correspondentes. Os modelos MobileNet v1 e v2, asr_float e tts_float são recomendados para medir o desempenho de valores de ponto flutuante de 32 bits, e os modelos quantizados MobileNet v1 e v2 são recomendados para valores quantizados de 8 bits. Para mais informações, consulte
Pacote de testes de aprendizado de máquina do Android.
No Android 9 e versões anteriores, a estrutura Capabilities inclui informações de performance do driver apenas para tensores de ponto flutuante e quantizados, e não inclui tipos de dados escalares.
Como parte do processo de inicialização, o framework pode consultar mais informações usando
IDevice::getType,
IDevice::getVersionString,
IDevice:getSupportedExtensions
e
IDevice::getNumberOfCacheFilesNeeded.
Entre as reinicializações do produto, a estrutura espera que todas as consultas descritas nesta seção sempre informem os mesmos valores para um determinado driver. Caso contrário, um app que usa esse driver pode ter um desempenho reduzido ou um comportamento incorreto.
Compilação
O framework determina quais dispositivos usar quando recebe uma solicitação de um app. No Android 10, os apps podem descobrir e especificar os dispositivos que o framework escolhe. Para mais informações, consulte Descoberta e atribuição de dispositivos.
No momento da compilação do modelo, o framework envia o modelo para cada driver
candidato chamando
IDevice::getSupportedOperations_1_3.
Cada driver retorna uma matriz de booleanos indicando quais operações do modelo são compatíveis. Um driver pode determinar que não é possível
oferecer suporte a uma determinada operação por vários motivos. Exemplo:
- O driver não é compatível com o tipo de dados.
- O driver só é compatível com operações que têm parâmetros de entrada específicos. Por exemplo, um driver pode oferecer suporte a 3x3 e 5x5, mas não a operações de convolução 7x7.
- O driver tem restrições de memória que impedem o processamento de gráficos ou entradas grandes.
Durante a compilação, as entradas, saídas e operandos internos do modelo, conforme
descrito em
OperandLifeTime,
podem ter dimensões ou classificação desconhecidas. Para mais informações, consulte
Formato de saída.
O framework instrui cada driver selecionado a se preparar para executar um subconjunto do modelo chamando IDevice::prepareModel_1_3.
Em seguida, cada driver compila seu subconjunto. Por exemplo, um driver pode
gerar código ou criar uma cópia reordenada dos pesos. Como pode haver um
período significativo entre a compilação do modelo e a
execução de solicitações, recursos como grandes partes da memória do dispositivo não devem
ser atribuídos durante a compilação.
Em caso de sucesso, o driver retorna um identificador @1.3::IPreparedModel. Se o driver retornar um código de falha ao preparar o subconjunto do modelo, o framework vai executar todo o modelo na CPU.
Para reduzir o tempo usado na compilação quando um app é iniciado, um driver pode armazenar em cache artefatos de compilação. Para mais informações, consulte Criação de cache de compilação.
Execução
Quando um app pede ao framework para executar uma solicitação, ele chama
o método
IPreparedModel::executeSynchronously_1_3
HAL por padrão para realizar uma execução síncrona em um modelo preparado.
Uma solicitação também pode ser executada de forma assíncrona usando o método
execute_1_3,
o método
executeFenced (consulte Execução isolada)
ou usando uma
execução em burst.
As chamadas de execução síncrona melhoram o desempenho e reduzem a sobrecarga de threading em comparação com as chamadas assíncronas, porque o controle é retornado ao processo do app somente após a conclusão da execução. Isso significa que o driver não precisa de um mecanismo separado para notificar o processo do app de que uma execução foi concluída.
Com o método assíncrono execute_1_3, o controle retorna ao
processo do app depois que a execução é iniciada, e o driver precisa notificar
o framework quando a execução é concluída, usando o
@1.3::IExecutionCallback.
O parâmetro Request transmitido ao método "execute" lista os operandos de entrada e saída usados na execução. A memória que armazena os dados do operando precisa usar a ordem principal de linha com a primeira dimensão iterando mais lentamente e não ter padding no final de nenhuma linha. Para mais informações sobre os tipos de operandos, consulte Operandos.
Para drivers da HAL 1.2 ou mais recentes da NN, quando uma solicitação é concluída, o status de erro, o formato de saída e as informações de tempo são retornados ao framework. Durante a execução, a saída ou os operandos internos do modelo podem ter uma ou mais dimensões ou classificação desconhecidas. Quando pelo menos um operando de saída tem uma dimensão ou classificação desconhecida, o driver precisa retornar informações de saída dimensionadas dinamicamente.
Para drivers com NN HAL 1.1 ou versões anteriores, somente o status de erro é retornado quando uma solicitação é concluída. As dimensões dos operandos de entrada e saída precisam ser totalmente especificadas para que a execução seja concluída com êxito. Os operandos internos podem ter uma ou mais dimensões desconhecidas, mas precisam ter uma classificação especificada.
Para solicitações de usuários que abrangem vários drivers, o framework é responsável por reservar memória intermediária e sequenciar as chamadas para cada driver.
Várias solicitações podem ser iniciadas em paralelo no mesmo
@1.3::IPreparedModel.
O driver pode executar solicitações em paralelo ou serializar as execuções.
O framework pode pedir que um driver mantenha mais de um modelo preparado. Por
exemplo, prepare o modelo m1, prepare m2, execute a solicitação r1 em m1, execute
r2 em m2, execute r3 em m1, execute r4 em m2, libere (descrito em
Limpeza) m1 e libere m2.
Para evitar uma primeira execução lenta que possa resultar em uma experiência do usuário ruim (por exemplo, uma instabilidade no primeiro frame), o driver precisa realizar a maioria das inicializações na fase de compilação. A inicialização na primeira execução deve ser limitada a ações que afetam negativamente a integridade do sistema quando realizadas no início, como reservar grandes buffers temporários ou aumentar a taxa de clock de um dispositivo. Os drivers que podem preparar apenas um número limitado de modelos simultâneos podem precisar fazer a inicialização na primeira execução.
No Android 10 ou versões mais recentes, quando várias execuções com o mesmo modelo preparado são executadas em rápida sucessão, o cliente pode usar um objeto de burst de execução para se comunicar entre os processos do app e do driver. Para mais informações, consulte Execuções de burst e filas rápidas de mensagens.
Para melhorar o desempenho de várias execuções em rápida sucessão, o driver pode manter buffers temporários ou aumentar as taxas de clock. Recomendamos criar uma thread de watchdog para liberar recursos se nenhuma nova solicitação for criada após um período fixo.
Formato da saída
Para solicitações em que um ou mais operandos de saída não têm todas as dimensões especificadas, o driver precisa fornecer uma lista de formatos de saída com as informações de dimensão de cada operando de saída após a execução. Para mais informações sobre dimensões, consulte OutputShape.
Se uma execução falhar devido a um buffer de saída pequeno demais, o driver precisará indicar quais operandos de saída têm tamanho de buffer insuficiente na lista de formatos de saída e informar o máximo possível de informações dimensionais, usando zero para dimensões desconhecidas.
Tempo
No Android 10, um app pode pedir o tempo de
execução se tiver especificado um único dispositivo para usar durante o processo de compilação. Para
detalhes, consulte
MeasureTiming
e Descoberta e atribuição de dispositivos.
Nesse caso, um driver NN HAL 1.2 precisa medir a duração da execução ou informar UINT64_MAX (para indicar que a duração não está disponível) ao executar uma solicitação. O driver precisa minimizar qualquer penalidade de desempenho resultante da medição da duração da execução.
O driver informa as seguintes durações em microssegundos na estrutura
Timing:
- Tempo de execução no dispositivo:não inclui o tempo de execução no driver, que é executado no processador host.
- Tempo de execução no driver:inclui o tempo de execução no dispositivo.
Essas durações precisam incluir o tempo em que a execução é suspensa, por exemplo, quando ela é interrompida por outras tarefas ou quando está aguardando a disponibilidade de um recurso.
Quando o driver não for solicitado a medir a duração da execução ou quando
houver um erro de execução, ele precisará informar as durações como
UINT64_MAX. Mesmo quando o driver é solicitado a medir a duração da execução, ele pode informar UINT64_MAX para o tempo no dispositivo, no driver ou em ambos. Quando o motorista informa as duas durações como um valor diferente de
UINT64_MAX, o tempo de execução no motorista precisa ser igual ou maior que o tempo no
dispositivo.
Execução cercada
No Android 11, a NNAPI permite que as execuções aguardem uma
lista de processamentos sync_fence e, de forma opcional, retornem um objeto sync_fence, que
é sinalizado quando a execução é concluída. Isso reduz a sobrecarga para modelos de sequência pequena
e casos de uso de streaming. Essa execução também permite a interoperabilidade
mais eficiente com outros componentes que podem sinalizar ou esperar por
sync_fence. Para mais informações sobre sync_fence, consulte
Estrutura de sincronização.
Em uma execução delimitada, o framework chama o método
IPreparedModel::executeFenced
para iniciar uma execução assíncrona delimitada em um modelo preparado com um
vetor de barreiras de sincronização para aguardar. Se a tarefa assíncrona for concluída antes
do retorno da chamada, um identificador vazio poderá ser retornado para sync_fence. Um objeto IFencedExecutionCallback também precisa ser retornado para permitir que o framework consulte o status do erro e as informações de duração.
Depois que uma execução é concluída, os dois valores de tempo a seguir, que medem a duração da execução, podem ser consultados usando IFencedExecutionCallback::getExecutionInfo.
timingLaunched: duração entre o momento em queexecuteFencedé chamado e quandoexecuteFencedsinaliza osyncFenceretornado.timingFenced: duração entre o momento em que todas as barreiras de sincronização que a execução aguarda são sinalizadas e o momento em queexecuteFencedsinaliza osyncFenceretornado.
Fluxo de controle
Para dispositivos com Android 11 ou mais recente, a NNAPI
inclui duas operações de fluxo de controle, IF e WHILE, que usam outros modelos
como argumentos e os executam de forma condicional (IF) ou repetida (WHILE). Para
mais informações sobre como implementar isso, consulte
Fluxo de controle.
Qualidade de serviço
No Android 11, a NNAPI inclui uma qualidade de serviço (QoS) melhorada ao permitir que um app indique as prioridades relativas dos modelos, o tempo máximo esperado para um modelo ser preparado e o tempo máximo esperado para uma execução ser concluída. Para mais informações, consulte Qualidade de serviço.
Limpeza
Quando um app termina de usar um modelo preparado, o framework libera
a referência ao objeto
@1.3::IPreparedModel. Quando o objeto IPreparedModel não é mais referenciado, ele é
destruído automaticamente no serviço de driver que o criou. Os recursos específicos do modelo podem ser recuperados nesse momento na implementação do destruidor pelo driver. Se o serviço de driver quiser que o objeto IPreparedModel seja
destruído automaticamente quando não for mais necessário para o cliente, ele não poderá manter
referências ao objeto IPreparedModel depois que o objeto IPreparedeModel
for retornado por
IPreparedModelCallback::notify_1_3.
Uso da CPU
Os drivers usam a CPU para configurar cálculos. Os drivers não devem usar a CPU para realizar cálculos de gráficos, porque isso interfere na capacidade do framework de alocar o trabalho corretamente. O driver precisa informar ao framework as partes que não consegue processar e deixar que ele cuide do restante.
O framework oferece uma implementação de CPU para todas as operações da NNAPI, exceto as definidas pelo fornecedor. Para mais informações, consulte Extensões de fornecedor.
As operações introduzidas no Android 10 (nível 29 da API) têm apenas uma implementação de CPU de referência para verificar se os testes do CTS e do VTS estão corretos. As implementações otimizadas incluídas em frameworks de aprendizado de máquina para dispositivos móveis são preferíveis à implementação da CPU da NNAPI.
Funções utilitárias
A base de código da NNAPI inclui funções utilitárias que podem ser usadas por serviços de driver.
O arquivo
frameworks/ml/nn/common/include/Utils.h
contém várias funções utilitárias, como as usadas para registro em log e
para conversão entre diferentes versões da HAL de rede neural.
VLogging:
VLOGé uma macro de wrapper em torno deLOGdo Android que só registra a mensagem se a tag apropriada estiver definida na propriedadedebug.nn.vlog.initVLogMask()precisa ser chamado antes de qualquer chamada paraVLOG. A macroVLOG_IS_ONpode ser usada para verificar seVLOGestá ativado no momento, permitindo que o código de geração de registros complicado seja ignorado se não for necessário. O valor da propriedade precisa ser um dos seguintes:- Uma string vazia, indicando que nenhum registro em log deve ser feito.
- O token
1ouall, indicando que todo o registro em registros precisa ser feito. - Uma lista de tags, delimitadas por espaços, vírgulas ou dois-pontos, que indicam qual registro em log deve ser feito. As tags são
compilation,cpuexe,driver,execution,manageremodel.
compliantWithV1_*: retornatruese um objeto NN HAL puder ser convertido para o mesmo tipo de uma versão HAL diferente sem perder informações. Por exemplo, chamarcompliantWithV1_0em umV1_2::Modelretornafalsese o modelo incluir tipos de operação introduzidos no NN HAL 1.1 ou NN HAL 1.2.convertToV1_*: converte um objeto NN HAL de uma versão para outra. Um aviso é registrado se a conversão resultar em perda de informações, ou seja, se a nova versão do tipo não puder representar totalmente o valor.Recursos: as funções
nonExtensionOperandPerformanceeupdatepodem ser usadas para ajudar a criar o campoCapabilities::operandPerformance.Consultar propriedades dos tipos:
isExtensionOperandType,isExtensionOperationType,nonExtensionSizeOfData,nonExtensionOperandSizeOfData,nonExtensionOperandTypeIsScalar,tensorHasUnspecifiedDimensions.
O arquivo
frameworks/ml/nn/common/include/ValidateHal.h
contém funções utilitárias para validar se um objeto HAL de rede neural é válido
de acordo com a especificação da versão do HAL.
validate*: retornatruese o objeto HAL de rede neural for válido de acordo com a especificação da versão do HAL. Os tipos de OEM e de extensão não são validados. Por exemplo,validateModelretornafalsese o modelo contiver uma operação que faça referência a um índice de operando que não existe ou uma operação que não seja compatível com essa versão da HAL.
O arquivo
frameworks/ml/nn/common/include/Tracing.h
contém macros para simplificar a adição de informações de
systracing ao código de redes neurais.
Por exemplo, consulte as invocações de macro NNTRACE_* no
driver de amostra.
O arquivo
frameworks/ml/nn/common/include/GraphDump.h
contém uma função utilitária para despejar o conteúdo de um Model de forma
gráfica para fins de depuração.
graphDump: grava uma representação do modelo no formato Graphviz (.dot) no fluxo especificado (se fornecido) ou no logcat (se nenhum fluxo for fornecido).
Validação
Para testar sua implementação da NNAPI, use os testes de VTS e CTS incluídos no framework do Android. O VTS exercita os drivers diretamente (sem usar o framework), enquanto o CTS os exercita indiretamente pelo framework. Esses testam cada método de API e verificam se todas as operações compatíveis com os drivers funcionam corretamente e fornecem resultados que atendem aos requisitos de precisão.
Os requisitos de precisão no CTS e no VTS para a NNAPI são os seguintes:
Ponto flutuante:abs(esperado - real) <= atol + rtol * abs(esperado), em que:
- Para fp32, atol = 1e-5f, rtol = 5.0f * 1.1920928955078125e-7
- Para fp16, atol = rtol = 5.0f * 0.0009765625f
Quantizado:diferença de um (exceto para
mobilenet_quantized, que tem uma diferença de três)Booleano:correspondência exata
Uma maneira de o CTS testar a NNAPI é gerando gráficos pseudorrandômicos fixos
usados para testar e comparar os resultados de execução de cada driver com a
implementação de referência da NNAPI. Para drivers com NN HAL 1.2 ou mais recente, se os
resultados não atenderem aos critérios de precisão, o CTS vai informar um erro e despejar um
arquivo de especificação para o modelo com falha em /data/local/tmp para depuração.
Para mais detalhes sobre os critérios de precisão, consulte
TestRandomGraph.cpp
e
TestHarness.h.
Teste de fuzz
O objetivo do teste de fuzzing é encontrar falhas, asserções, violações de memória ou comportamento indefinido geral no código em teste devido a fatores como entradas inesperadas. Para testes de fuzz da NNAPI, o Android usa testes baseados na libFuzzer, que são eficientes em fuzzing porque usam a cobertura de linhas de casos de teste anteriores para gerar novas entradas aleatórias. Por exemplo, o libFuzzer prefere casos de teste que são executados em novas linhas de código. Isso reduz muito o tempo que os testes levam para encontrar códigos problemáticos.
Para realizar testes de fuzz e validar a implementação do driver, modifique
frameworks/ml/nn/runtime/test/android_fuzzing/DriverFuzzTest.cpp
no utilitário de teste libneuralnetworks_driver_fuzzer encontrado no AOSP para incluir
o código do driver. Para mais informações sobre o teste de fuzzing da NNAPI, consulte
frameworks/ml/nn/runtime/test/android_fuzzing/README.md.
Segurança
Como os processos do app se comunicam diretamente com o processo de um motorista,
os motoristas precisam validar os argumentos das chamadas que recebem. Essa validação
é verificada pelo VTS. O código de validação está em
frameworks/ml/nn/common/include/ValidateHal.h.
Os motoristas também precisam garantir que os apps não interfiram em outros aplicativos ao usar o mesmo dispositivo.
Pacote de testes de aprendizado de máquina do Android
O Android Machine Learning Test Suite (MLTS) é um comparativo de NNAPI incluído no CTS e no VTS para validar a acurácia de modelos reais em dispositivos de fornecedores. O comparativo de mercado avalia a latência e a precisão e compara os resultados dos drivers com os resultados usando o TF Lite em execução na CPU, para o mesmo modelo e conjuntos de dados. Isso garante que a precisão de um driver não seja pior do que a implementação de referência da CPU.
Os desenvolvedores da plataforma Android também usam o MLTS para avaliar a latência e a precisão dos drivers.
O comparativo de mercado da NNAPI pode ser encontrado em dois projetos no AOSP:
platform/test/mlts/benchmark(app de comparativo)platform/test/mlts/models(modelos e conjuntos de dados)
Modelos e conjuntos de dados
O comparativo de mercado da NNAPI usa os seguintes modelos e conjuntos de dados.
- MobileNetV1 float e u8 quantizados em tamanhos diferentes, executados em um pequeno subconjunto (1.500 imagens) do Open Images Dataset v4.
- MobileNetV2 ponto flutuante e u8 quantizados em tamanhos diferentes, executados em um pequeno subconjunto (1.500 imagens) do conjunto de dados Open Images v4.
- Modelo acústico baseado em memória de curto prazo longa (LSTM, na sigla em inglês) para conversão de texto em voz, executado em um pequeno subconjunto do conjunto CMU Arctic.
- Modelo acústico baseado em LSTM para reconhecimento automático de fala, executado em um pequeno subconjunto do conjunto de dados LibriSpeech.
Para saber mais, consulte
platform/test/mlts/models.
Teste de estresse
O conjunto de testes de aprendizado de máquina do Android inclui uma série de testes de falha para validar a resiliência dos drivers em condições de uso intenso ou em casos específicos de comportamento dos clientes.
Todos os testes de falha oferecem os seguintes recursos:
- Detecção de bloqueio:se o cliente da NNAPI ficar bloqueado durante um teste, o teste vai falhar com o motivo
HANG, e o conjunto de testes vai passar para o próximo teste. - Detecção de falhas do cliente NNAPI:os testes sobrevivem a falhas do cliente e falham com o motivo
CRASH. - Detecção de falha de driver:os testes podem detectar uma falha de driver
que causa uma falha em uma chamada da NNAPI. Pode haver falhas em
processos de driver que não causam uma falha na NNAPI e não fazem com que o teste
falhe. Para evitar esse tipo de falha, recomendamos executar o comando
tailno registro do sistema para erros ou falhas relacionados a drivers. - Segmentação de todos os aceleradores disponíveis:os testes são executados em todos os drivers disponíveis.
Todos os testes de colisão têm quatro resultados possíveis:
SUCCESS: a execução foi concluída sem erros.FAILURE: falha na execução. Normalmente causado por uma falha ao testar um modelo, indicando que o driver não compilou ou executou o modelo.HANG: o processo de teste parou de responder.CRASH: o processo de teste falhou.
Para mais informações sobre testes de estresse e uma lista completa de testes de falha, consulte
platform/test/mlts/benchmark/README.txt.
Usar o MLTS
Para usar o MLTS:
- Conecte um dispositivo de destino à estação de trabalho e verifique se ele está
acessível por
adb.
Exporte a variável de ambiente
ANDROID_SERIALdo dispositivo de destino se mais de um dispositivo estiver conectado. cdno diretório de origem de nível superior do Android.source build/envsetup.sh lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available. ./test/mlts/benchmark/build_and_run_benchmark.shNo final de uma execução de comparativo de mercado, os resultados são apresentados como uma página HTML e transmitidos para
xdg-open.
Para saber mais, consulte
platform/test/mlts/benchmark/README.txt.
Versões da HAL de redes neurais
Esta seção descreve as mudanças introduzidas nas versões do Android e da HAL de redes neurais.
Android 11
O Android 11 apresenta a HAL de redes neurais 1.3, que inclui as seguintes mudanças importantes.
- Suporte à quantização assinada de 8 bits na NNAPI. Adiciona o tipo de operando
TENSOR_QUANT8_ASYMM_SIGNED. Os drivers com NN HAL 1.3 que oferecem suporte a operações com quantização não assinada também precisam oferecer suporte às variantes assinadas dessas operações. Ao executar versões com e sem sinal da maioria das operações quantizadas, os drivers precisam produzir os mesmos resultados até um deslocamento de 128. Há cinco exceções a esse requisito:CAST,HASHTABLE_LOOKUP,LSH_PROJECTION,PAD_V2eQUANTIZED_16BIT_LSTM. A operaçãoQUANTIZED_16BIT_LSTMnão aceita operandos com sinal, e as outras quatro operações aceitam quantização com sinal, mas não exigem que os resultados sejam iguais. - Suporte para execuções isoladas em que o framework chama o método
IPreparedModel::executeFencedpara iniciar uma execução assíncrona isolada em um modelo preparado com um vetor de isolamentos de sincronização para aguardar. Para mais informações, consulte Execução isolada. - Suporte para fluxo de controle. Adiciona as operações
IFeWHILE, que usam outros modelos como argumentos e os executam condicionalmente (IF) ou repetidamente (WHILE). Para mais informações, consulte Fluxo de controle. - Melhor qualidade de serviço (QoS) porque os apps podem indicar as prioridades relativas dos modelos, o tempo máximo esperado para um modelo ser preparado e o tempo máximo esperado para uma execução ser concluída. Para mais informações, consulte Qualidade de serviço.
- Compatibilidade com domínios de memória que oferecem interfaces para alocar buffers gerenciados pelo driver. Isso permite transmitir as memórias nativas do dispositivo entre as execuções ao suprimir a cópia e a transformação de dados desnecessários entre execuções consecutivas no mesmo driver. Para mais informações, consulte Domínios de memória.
Android 10
O Android 10 apresenta a HAL de redes neurais 1.2, que inclui as seguintes mudanças importantes.
- A struct
Capabilitiesinclui todos os tipos de dados, incluindo tipos de dados escalares, e representa a performance não relaxada usando um vetor em vez de campos nomeados. - Os métodos
getVersionStringegetTypepermitem que o framework recupere o tipo de dispositivo (DeviceType) e as informações de versão. Consulte Descoberta e atribuição de dispositivos. - O método
executeSynchronouslyé chamado por padrão para realizar uma execução de forma síncrona. O métodoexecute_1_2informa ao framework para realizar uma execução de forma assíncrona. Consulte Execução. - O parâmetro
MeasureTimingparaexecuteSynchronously,execute_1_2e execução de burst especifica se o driver vai medir a duração da execução. Os resultados são informados na estruturaTiming. Consulte Timing. - Suporte para execuções em que um ou mais operandos de saída têm uma dimensão ou classificação desconhecida. Consulte Formato da saída.
- Suporte para extensões de fornecedores, que são coleções de operações e tipos de dados definidos pelo fornecedor. O driver informa as extensões compatíveis usando o método
IDevice::getSupportedExtensions. Consulte Extensões do fornecedor. - Capacidade de um objeto de burst controlar um conjunto de execuções de burst usando filas de mensagens rápidas (FMQs) para comunicação entre processos de app e driver, reduzindo a latência. Consulte Execuções de burst e filas rápidas de mensagens.
- Suporte para AHardwareBuffer para permitir que o driver execute ações sem copiar dados. Consulte AHardwareBuffer.
- Melhoria no suporte ao armazenamento em cache de artefatos de compilação para reduzir o tempo usado na compilação quando um app é iniciado. Consulte Armazenamento em cache de compilação.
O Android 10 introduz os seguintes tipos de operandos e operações.
-
ANEURALNETWORKS_BOOLANEURALNETWORKS_FLOAT16ANEURALNETWORKS_TENSOR_BOOL8ANEURALNETWORKS_TENSOR_FLOAT16ANEURALNETWORKS_TENSOR_QUANT16_ASYMMANEURALNETWORKS_TENSOR_QUANT16_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL
-
ANEURALNETWORKS_ABSANEURALNETWORKS_ARGMAXANEURALNETWORKS_ARGMINANEURALNETWORKS_AXIS_ALIGNED_BBOX_TRANSFORMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_RNNANEURALNETWORKS_BOX_WITH_NMS_LIMITANEURALNETWORKS_CASTANEURALNETWORKS_CHANNEL_SHUFFLEANEURALNETWORKS_DETECTION_POSTPROCESSINGANEURALNETWORKS_EQUALANEURALNETWORKS_EXPANEURALNETWORKS_EXPAND_DIMSANEURALNETWORKS_GATHERANEURALNETWORKS_GENERATE_PROPOSALSANEURALNETWORKS_GREATERANEURALNETWORKS_GREATER_EQUALANEURALNETWORKS_GROUPED_CONV_2DANEURALNETWORKS_HEATMAP_MAX_KEYPOINTANEURALNETWORKS_INSTANCE_NORMALIZATIONANEURALNETWORKS_LESSANEURALNETWORKS_LESS_EQUALANEURALNETWORKS_LOGANEURALNETWORKS_LOGICAL_ANDANEURALNETWORKS_LOGICAL_NOTANEURALNETWORKS_LOGICAL_ORANEURALNETWORKS_LOG_SOFTMAXANEURALNETWORKS_MAXIMUMANEURALNETWORKS_MINIMUMANEURALNETWORKS_NEGANEURALNETWORKS_NOT_EQUALANEURALNETWORKS_PAD_V2ANEURALNETWORKS_POWANEURALNETWORKS_PRELUANEURALNETWORKS_QUANTIZEANEURALNETWORKS_QUANTIZED_16BIT_LSTMANEURALNETWORKS_RANDOM_MULTINOMIALANEURALNETWORKS_REDUCE_ALLANEURALNETWORKS_REDUCE_ANYANEURALNETWORKS_REDUCE_MAXANEURALNETWORKS_REDUCE_MINANEURALNETWORKS_REDUCE_PRODANEURALNETWORKS_REDUCE_SUMANEURALNETWORKS_RESIZE_NEAREST_NEIGHBORANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_ROI_POOLINGANEURALNETWORKS_RSQRTANEURALNETWORKS_SELECTANEURALNETWORKS_SINANEURALNETWORKS_SLICEANEURALNETWORKS_SPLITANEURALNETWORKS_SQRTANEURALNETWORKS_TILEANEURALNETWORKS_TOPK_V2ANEURALNETWORKS_TRANSPOSE_CONV_2DANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_RNN
O Android 10 introduz atualizações em muitas das operações atuais. As atualizações estão relacionadas principalmente a:
- Suporte para o layout de memória NCHW
- Suporte a tensores com classificação diferente de 4 em operações de softmax e normalização
- Suporte para convoluções dilatadas
- Suporte para entradas com quantização mista em
ANEURALNETWORKS_CONCATENATION
A lista abaixo mostra as operações modificadas no Android 10. Para conferir todos os detalhes das mudanças, consulte OperationCode na documentação de referência da NNAPI.
ANEURALNETWORKS_ADDANEURALNETWORKS_AVERAGE_POOL_2DANEURALNETWORKS_BATCH_TO_SPACE_NDANEURALNETWORKS_CONCATENATIONANEURALNETWORKS_CONV_2DANEURALNETWORKS_DEPTHWISE_CONV_2DANEURALNETWORKS_DEPTH_TO_SPACEANEURALNETWORKS_DEQUANTIZEANEURALNETWORKS_DIVANEURALNETWORKS_FLOORANEURALNETWORKS_FULLY_CONNECTEDANEURALNETWORKS_L2_NORMALIZATIONANEURALNETWORKS_L2_POOL_2DANEURALNETWORKS_LOCAL_RESPONSE_NORMALIZATIONANEURALNETWORKS_LOGISTICANEURALNETWORKS_LSH_PROJECTIONANEURALNETWORKS_LSTMANEURALNETWORKS_MAX_POOL_2DANEURALNETWORKS_MEANANEURALNETWORKS_MULANEURALNETWORKS_PADANEURALNETWORKS_RELUANEURALNETWORKS_RELU1ANEURALNETWORKS_RELU6ANEURALNETWORKS_RESHAPEANEURALNETWORKS_RESIZE_BILINEARANEURALNETWORKS_RNNANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_SOFTMAXANEURALNETWORKS_SPACE_TO_BATCH_NDANEURALNETWORKS_SPACE_TO_DEPTHANEURALNETWORKS_SQUEEZEANEURALNETWORKS_STRIDED_SLICEANEURALNETWORKS_SUBANEURALNETWORKS_SVDFANEURALNETWORKS_TANHANEURALNETWORKS_TRANSPOSE
Android 9
A NN HAL 1.1 foi introduzida no Android 9 e inclui as seguintes mudanças notáveis.
IDevice::prepareModel_1_1inclui um parâmetroExecutionPreference. Um driver pode usar isso para ajustar a preparação, sabendo que o app prefere economizar bateria ou vai executar o modelo em chamadas rápidas e sucessivas.- Adicionamos nove novas operações:
BATCH_TO_SPACE_ND,DIV,MEAN,PAD,SPACE_TO_BATCH_ND,SQUEEZE,STRIDED_SLICE,SUB,TRANSPOSE. - Um app pode especificar que cálculos de ponto flutuante de 32 bits podem ser executados
usando o intervalo e/ou a precisão de ponto flutuante de 16 bits ao definir
Model.relaxComputationFloat32toFloat16comotrue. A structCapabilitiestem o campo adicionalrelaxedFloat32toFloat16Performancepara que o driver possa informar a performance reduzida ao framework.
Android 8.1
A HAL de redes neurais inicial (1.0) foi lançada no Android 8.1. Para mais informações, consulte /neuralnetworks/1.0/.