
systrace è lo strumento principale per analizzare le prestazioni dei dispositivi Android. Tuttavia, è un wrapper per altri strumenti. È il wrapper lato host intorno ad atrace, l'eseguibile lato dispositivo che controlla la traccia dello spazio utente e configura ftrace, il meccanismo di traccia principale nel kernel Linux. systrace utilizza atrace per attivare la traccia, quindi legge il buffer ftrace e lo racchiude in un visualizzatore HTML autonomo. Sebbene i kernel più recenti supportino Linux Enhanced Berkeley Packet Filter (eBPF), questa pagina riguarda il kernel 3.18 (senza eFPF), in quanto è quello utilizzato su Pixel o Pixel XL.
systrace è di proprietà dei team Google Android e Google Chrome ed è open source nell'ambito del progetto Catapult. Oltre a systrace, Catapult include altre utilità utili. Ad esempio, ftrace ha più funzionalità di quelle che possono essere attivate direttamente da systrace o atrace e contiene alcune funzionalità avanzate fondamentali per il debug dei problemi di prestazioni. Queste funzionalità richiedono l'accesso root e spesso un nuovo kernel.
Esegui systrace
Quando esegui il debug del jitter su Pixel o Pixel XL, inizia con il seguente comando:
./systrace.py sched freq idle am wm gfx view sync binder_driver irq workq input -b 96000
Se combinato con i punti di traccia aggiuntivi necessari per l'attività della pipeline di GPU e display, ciò consente di tracciare l'input dell'utente fino al frame visualizzato sullo schermo. Imposta le dimensioni del buffer su un valore elevato per evitare di perdere eventi (perché senza un buffer di grandi dimensioni alcune CPU non contengono eventi dopo un certo punto della traccia).
Quando esamini systrace, tieni presente che ogni evento viene attivato da qualcosa sulla CPU.
Poiché systrace si basa su ftrace e ftrace viene eseguito sulla CPU, qualcosa sulla CPU deve scrivere il buffer ftrace che registra le modifiche hardware. Ciò significa che se vuoi sapere perché lo stato di una recinzione di visualizzazione è cambiato, puoi vedere cosa era in esecuzione sulla CPU nel momento esatto della transizione (qualcosa in esecuzione sulla CPU ha attivato la modifica nel log). Questo concetto è alla base dell'analisi delle prestazioni tramite systrace.
Esempio: Working frame
Questo esempio descrive una traccia di sistema per una normale pipeline dell'interfaccia utente. Per seguire l'esempio,
scarica il file ZIP delle tracce
(che include anche altre tracce a cui si fa riferimento in questa sezione), decomprimi il file
e apri il file systrace_tutorial.html nel browser.
Per un carico di lavoro periodico e coerente come TouchLatency, la pipeline dell'interfaccia utente segue questa sequenza:
- EventThread in SurfaceFlinger riattiva il thread UI dell'app, segnalando che è il momento di eseguire il rendering di un nuovo frame.
- L'app esegue il rendering di un frame nei thread UI, RenderThread e HWUI, utilizzando le risorse di CPU e GPU. Si tratta della maggior parte della capacità utilizzata per la UI.
- L'app invia il frame sottoposto a rendering a SurfaceFlinger utilizzando un binder, quindi SurfaceFlinger va in sospensione.
- Un secondo EventThread in SurfaceFlinger riattiva SurfaceFlinger per attivare la composizione e l'output del display. Se SurfaceFlinger determina che non c'è lavoro da fare, torna in modalità sospensione.
- SurfaceFlinger gestisce la composizione utilizzando Hardware Composer (HWC) o Hardware Composer 2 (HWC2) o GL. La composizione HWC e HWC2 è più veloce e a basso consumo energetico, ma presenta limitazioni a seconda del system on a chip (SoC). In genere questa operazione richiede circa 4-6 ms, ma può sovrapporsi al passaggio 2 perché le app per Android sono sempre a tripla memorizzazione nel buffer. (Anche se le app sono sempre a triplo buffering, in SurfaceFlinger potrebbe essere presente un solo frame in attesa, il che lo fa apparire identico al doppio buffering.)
- SurfaceFlinger invia l'output finale al display con un driver del fornitore e torna inattivo, in attesa del risveglio di EventThread.
Ecco un esempio della sequenza di frame che inizia a 15409 ms:
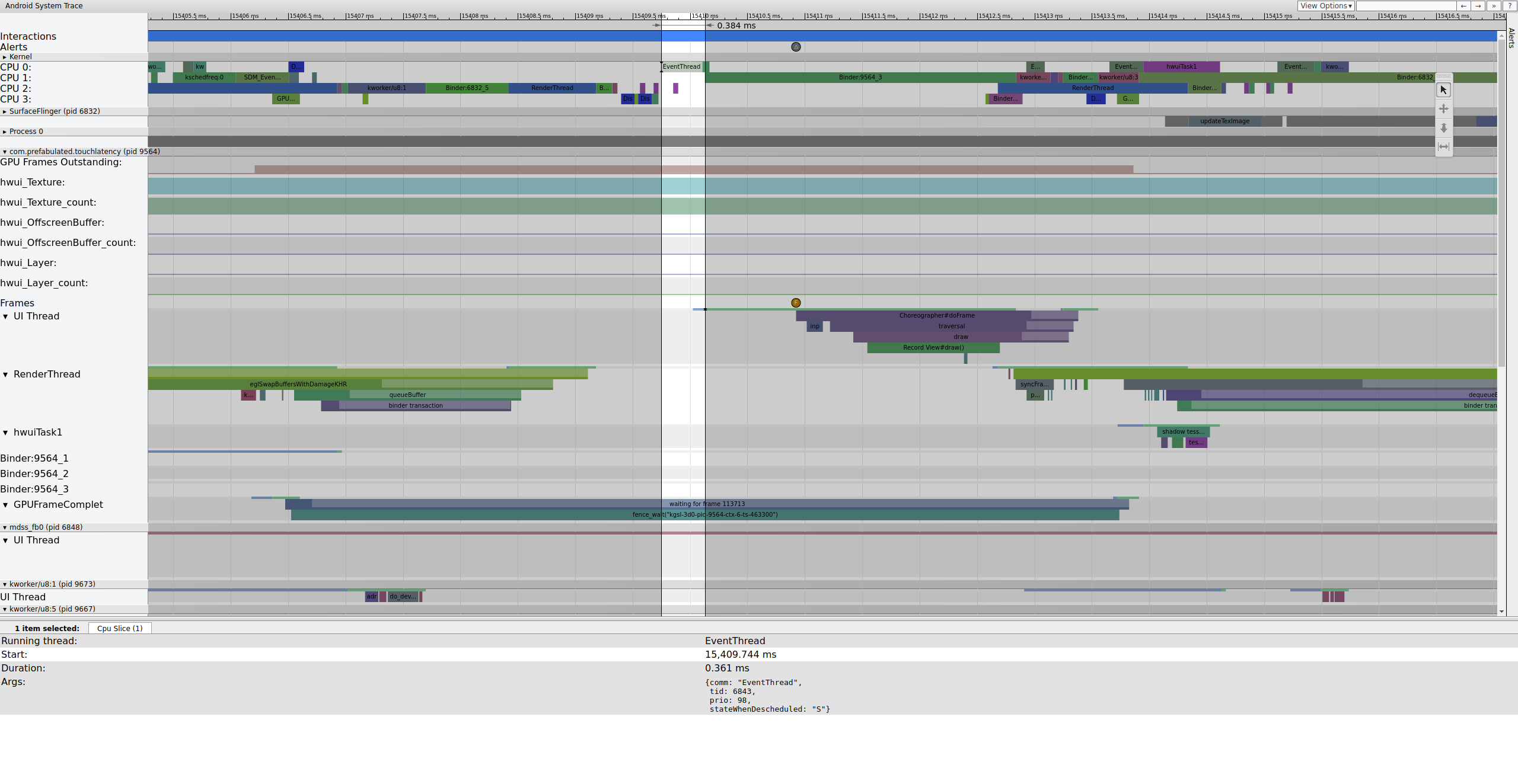
Figura 1. Pipeline UI normale, EventThread in esecuzione.
La Figura 1 è un frame normale circondato da frame normali, quindi è un buon punto di partenza per capire come funziona la pipeline della UI. La riga del thread dell'interfaccia utente per TouchLatency include colori diversi in momenti diversi. Le barre indicano diversi stati del thread:
- Grigio. Dormire.
- Blu. Eseguibile (potrebbe essere eseguito, ma lo scheduler non l'ha ancora selezionato per l'esecuzione).
- Verde. In esecuzione (il programma di pianificazione ritiene che sia in esecuzione).
- Rosso. Sonno non interrompibile (in genere, il dispositivo è inattivo nel kernel). Può essere indicativo del carico I/O. Estremamente utile per il debug dei problemi di prestazioni.
- Arancione. Sonno ininterrotto a causa del carico I/O.
Per visualizzare il motivo del sonno ininterrotto (disponibile dal punto di traccia sched_blocked_reason), seleziona la sezione rossa del sonno ininterrotto.
Mentre EventThread è in esecuzione, il thread UI per TouchLatency diventa eseguibile. Per vedere cosa l'ha riattivato, fai clic sulla sezione blu.
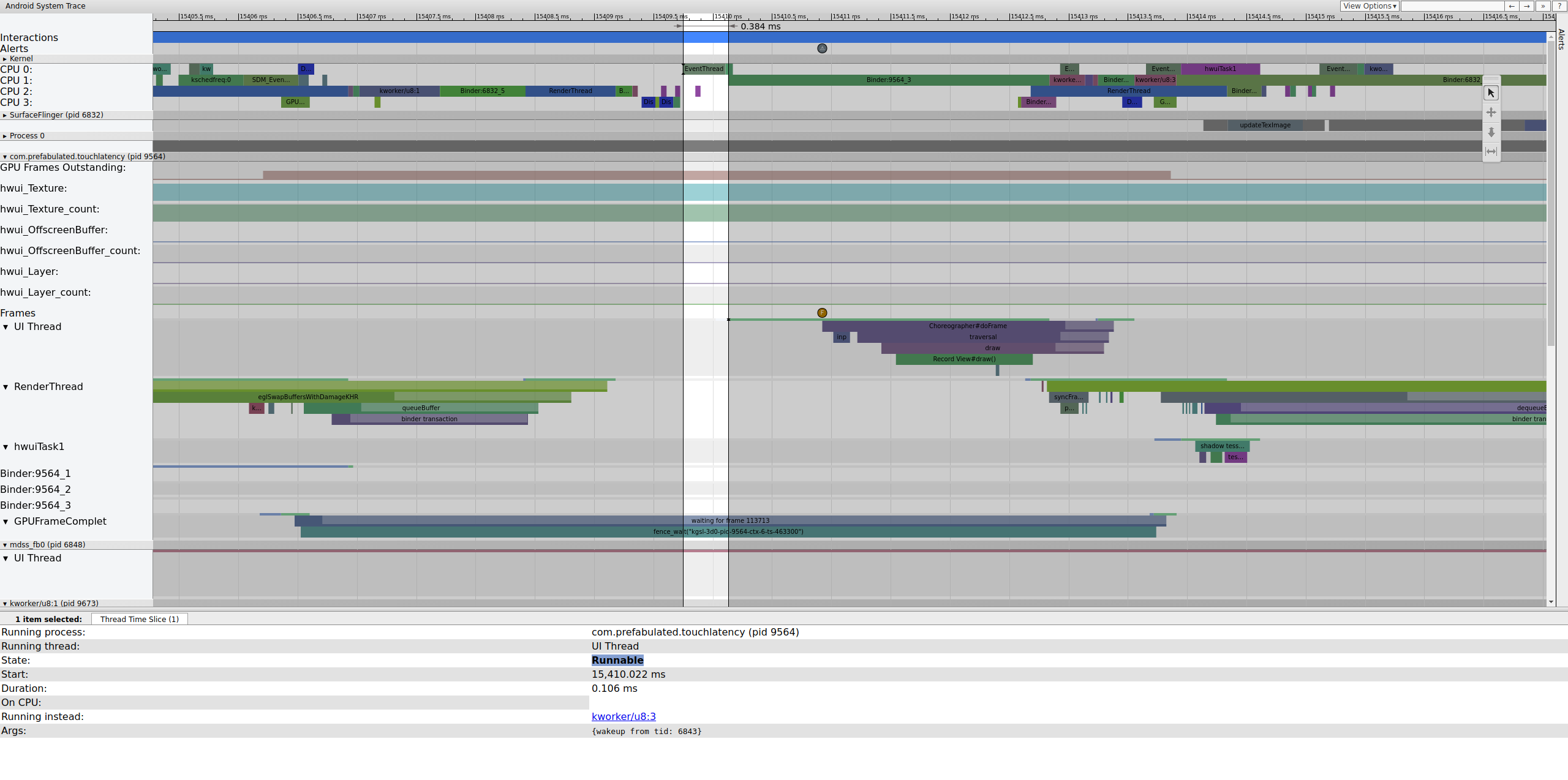
Figura 2. Thread UI per TouchLatency.
La Figura 2 mostra che il thread UI TouchLatency è stato riattivato dal tid 6843, che corrisponde a EventThread. Il thread UI si riattiva, esegue il rendering di un frame e lo mette in coda per SurfaceFlinger.
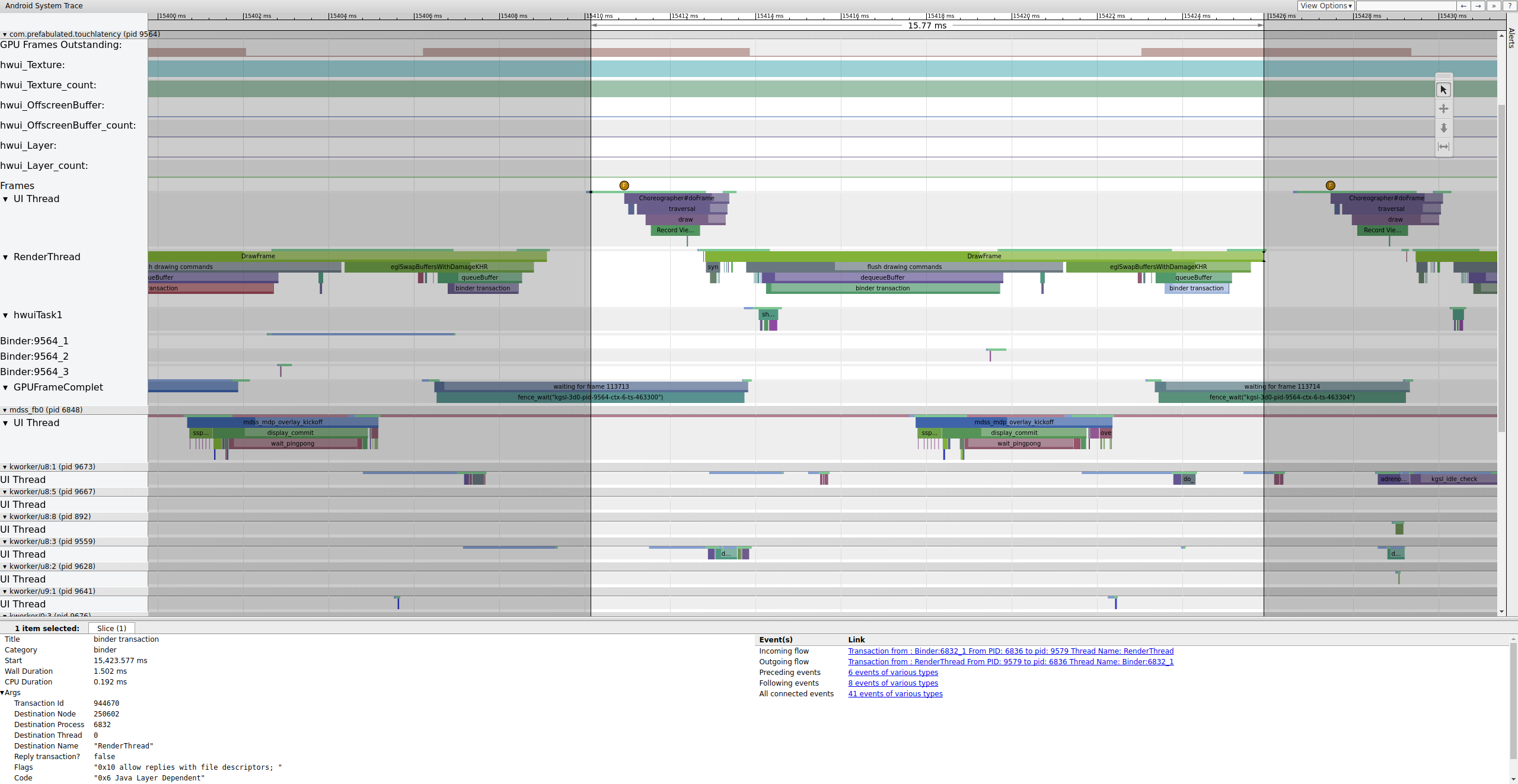
Figura 3. Il thread UI si riattiva, esegue il rendering di un frame e lo mette in coda per SurfaceFlinger.
Se il tag binder_driver è attivato in una traccia, puoi selezionare una
transazione binder per visualizzare informazioni su tutti i processi coinvolti in quella
transazione.
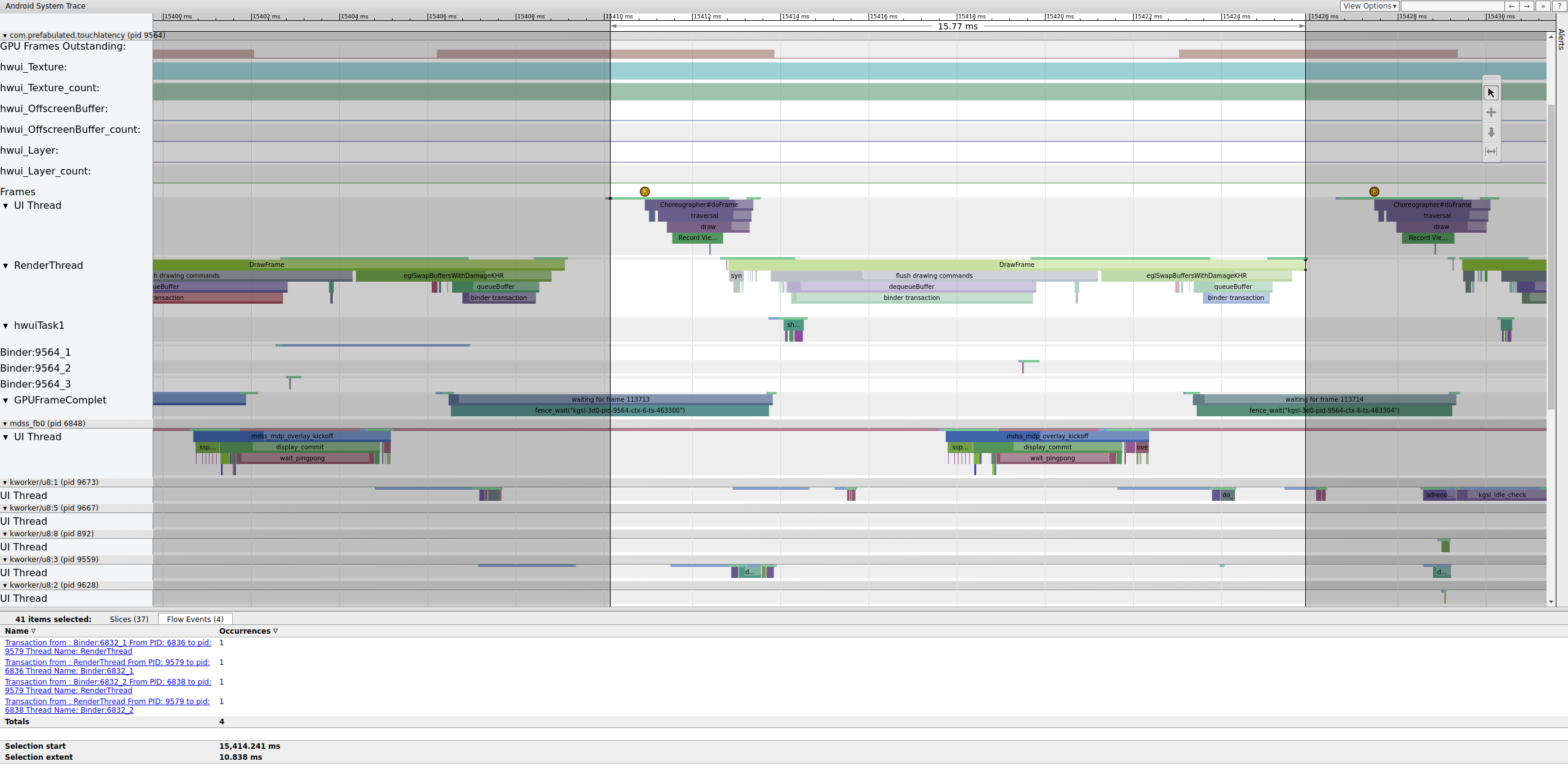
Figura 4. Transazione di prenotazione.
La figura 4 mostra che, a 15.423,65 ms Binder:6832_1 in SurfaceFlinger diventa eseguibile a causa di tid 9579, che è RenderThread di TouchLatency. Puoi anche visualizzare queueBuffer su entrambi i lati della transazione del binder.
Durante queueBuffer sul lato SurfaceFlinger, il numero di frame in attesa da TouchLatency passa da 1 a 2.
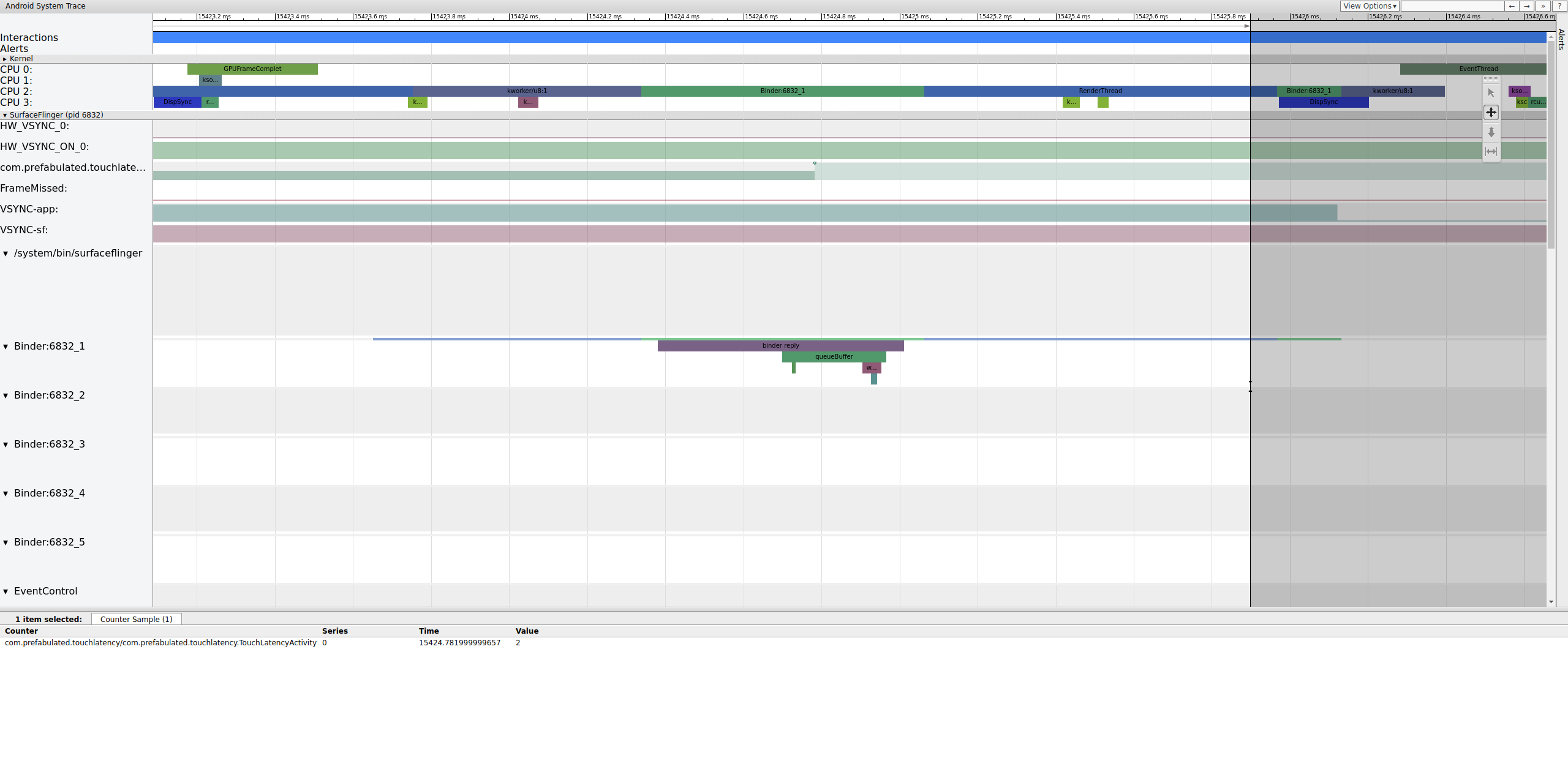
Figura 5. I fotogrammi in attesa vanno da 1 a 2.
La figura 5 mostra il buffering triplo, in cui sono presenti due frame completati e l'app sta per iniziare il rendering di un terzo. Questo perché abbiamo già eliminato alcuni frame, quindi l'app mantiene due frame in attesa anziché uno per cercare di evitare ulteriori frame eliminati.
Poco dopo, il thread principale di SurfaceFlinger viene riattivato da un secondo EventThread in modo che possa inviare il frame in attesa precedente al display:
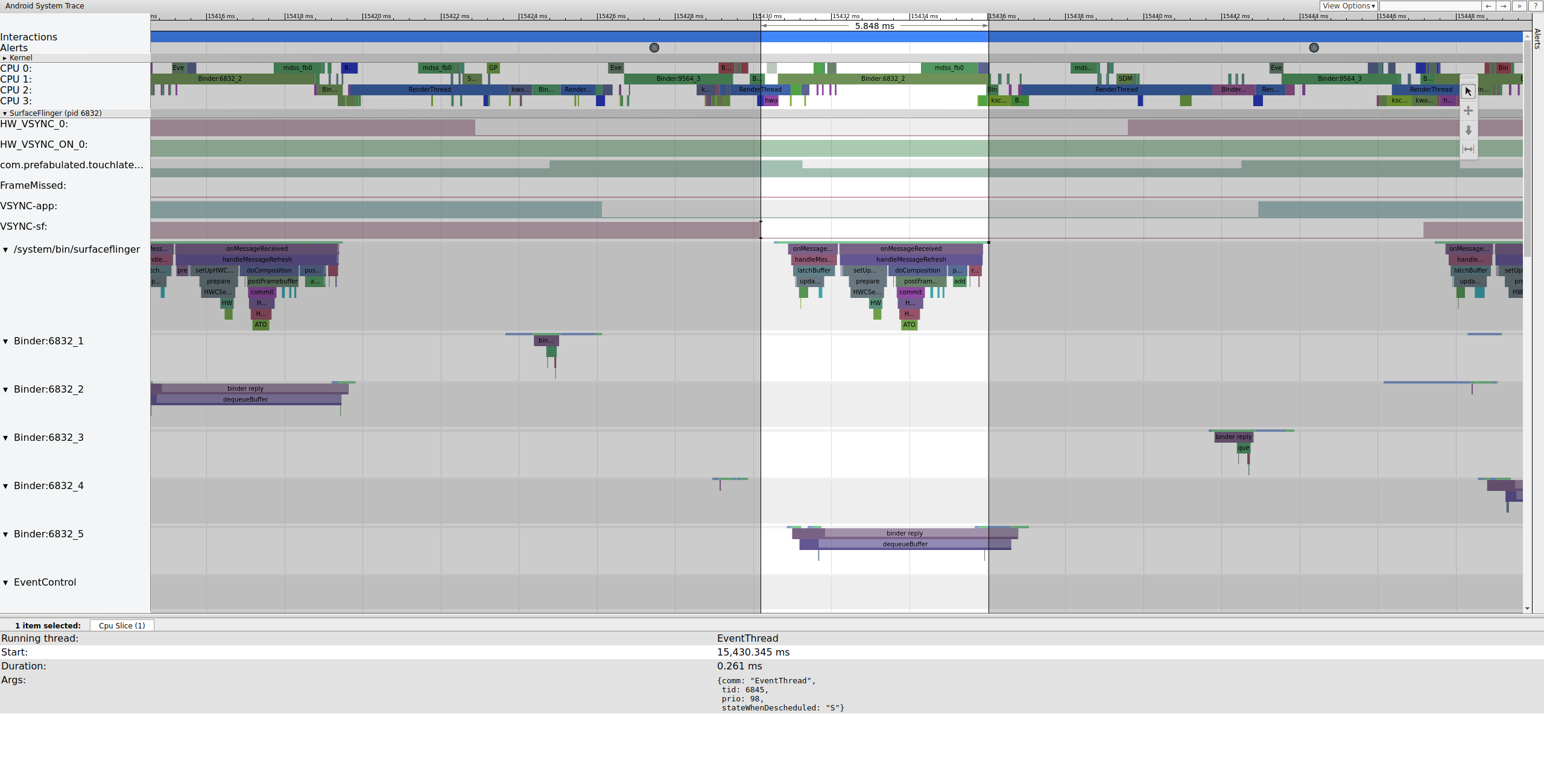
Figura 6. Il thread principale di SurfaceFlinger viene riattivato da un secondo EventThread.
SurfaceFlinger aggancia prima il buffer in attesa precedente, il che fa diminuire il conteggio dei buffer in attesa da 2 a 1:
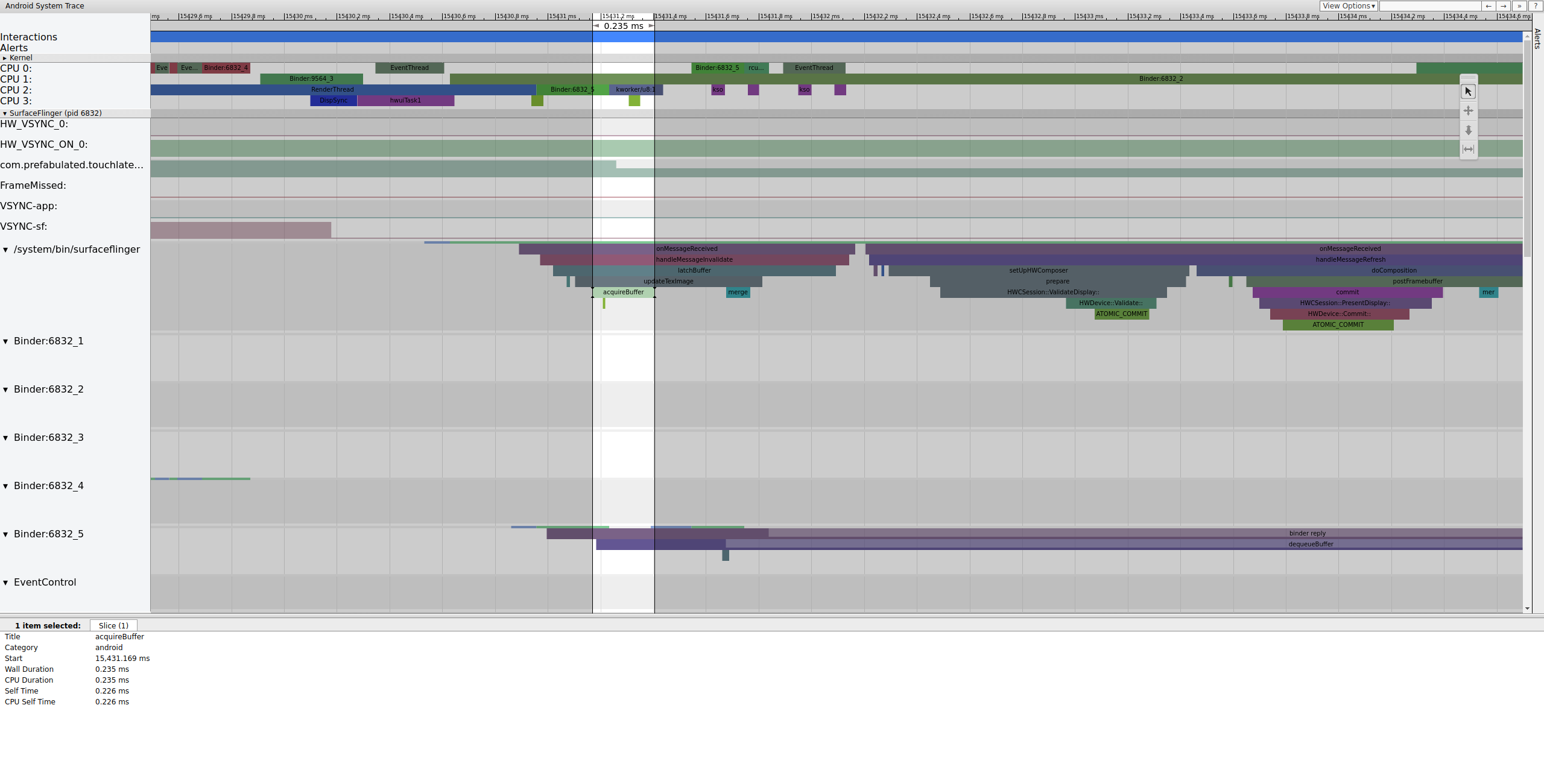
Figura 7. SurfaceFlinger aggancia prima il buffer in attesa meno recente.
Dopo aver agganciato il buffer, SurfaceFlinger configura la composizione e invia il
frame finale al display. Alcune di queste sezioni sono attivate nell'ambito del
mdss tracepoint, pertanto potrebbero non essere incluse nel SoC.
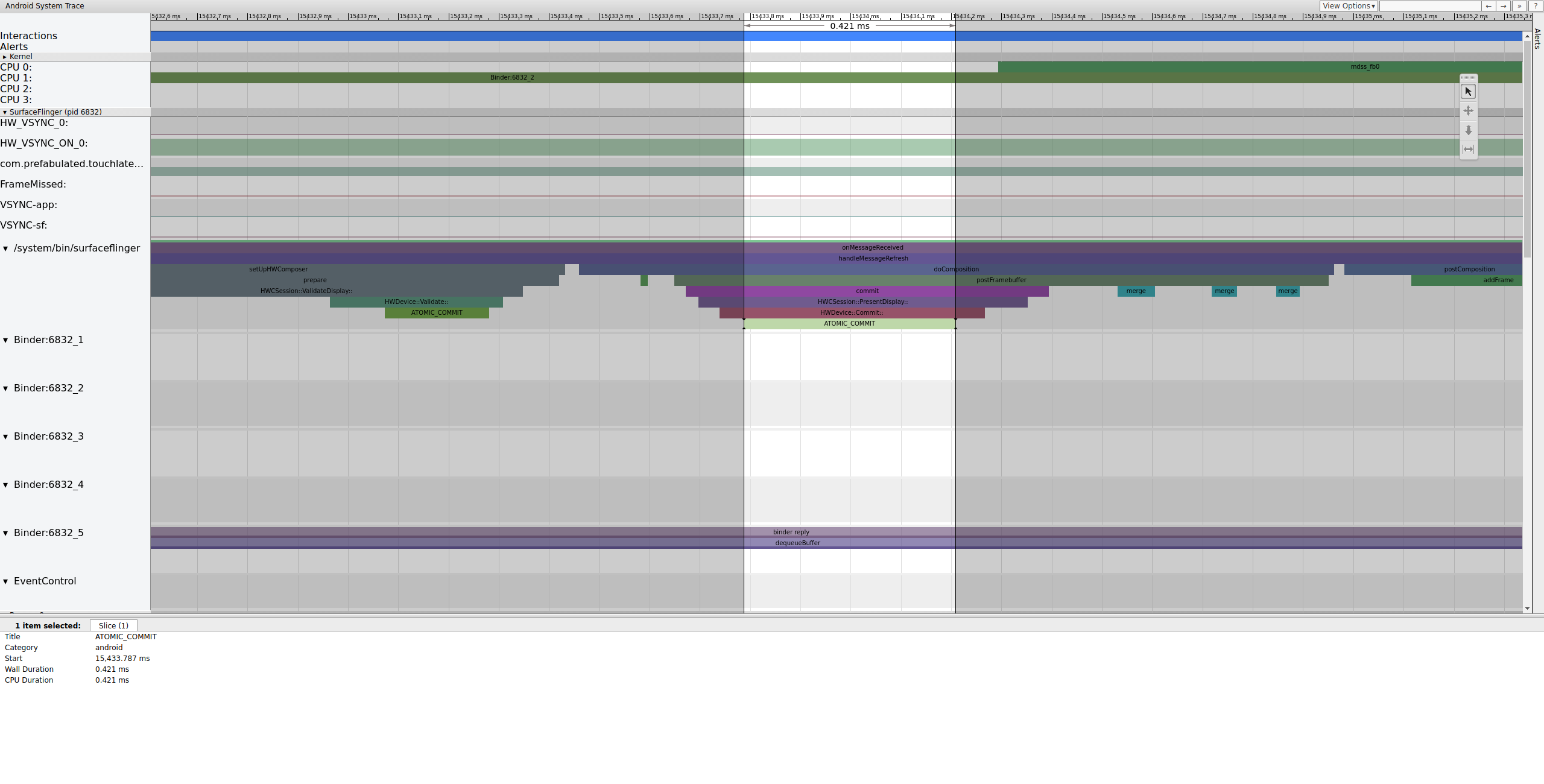
Figura 8. SurfaceFlinger configura la composizione e invia il frame finale.
Successivamente, mdss_fb0 si riattiva sulla CPU 0. mdss_fb0 è il
thread del kernel della pipeline di visualizzazione per l'output di un frame sottoposto a rendering sul display.
Nota che mdss_fb0 è una riga a parte nella traccia (scorri verso il basso per
visualizzarla):
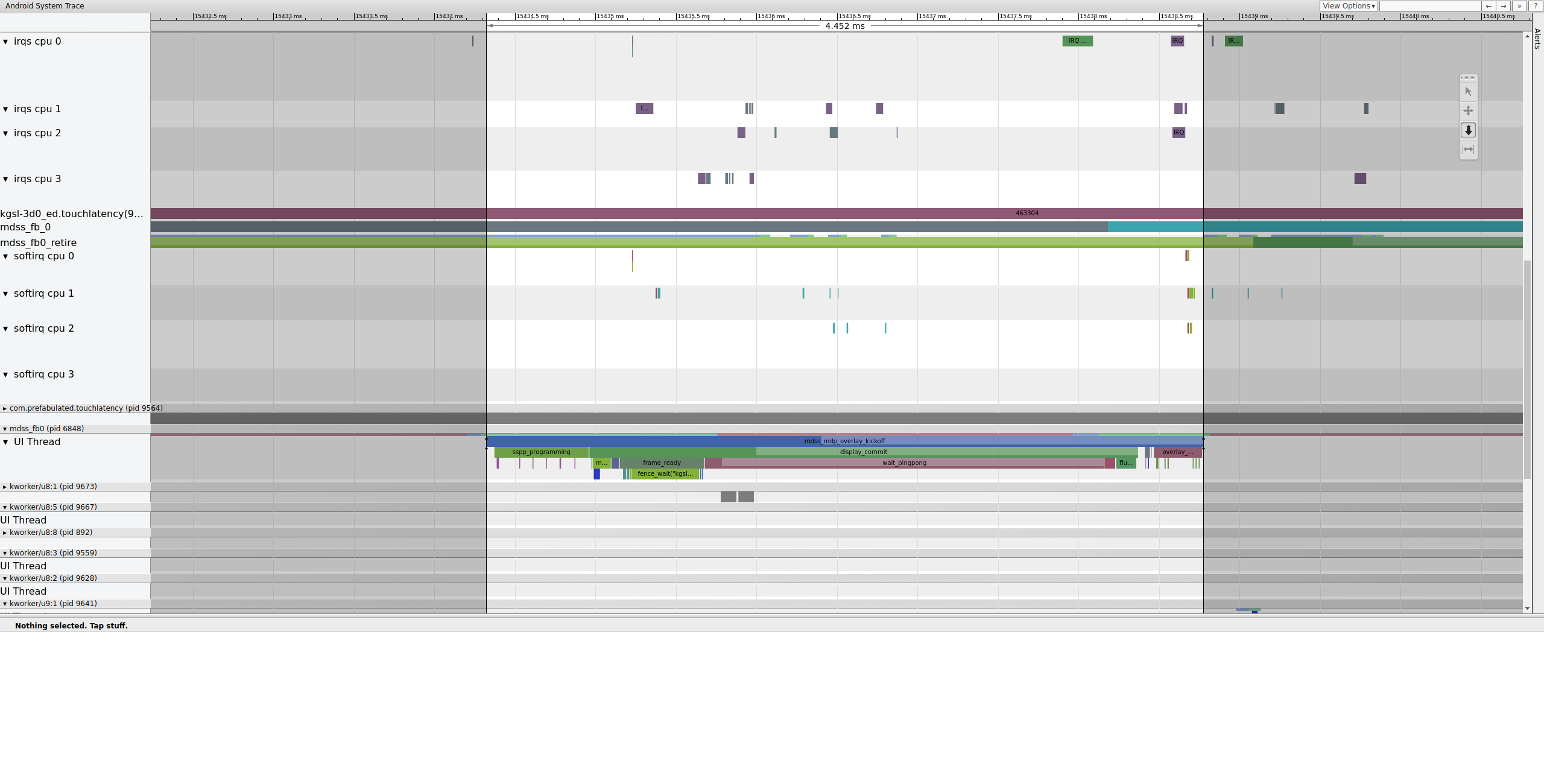
Figura 9. mdss_fb0 si riattiva sulla CPU 0.
mdss_fb0 si sveglia, corre brevemente, entra in modalità di sonno ininterrotto,
poi si sveglia di nuovo.
Esempio: Nonworking frame
Questo esempio descrive una traccia di sistema utilizzata per eseguire il debug del jitter di Pixel o Pixel XL. Per
seguire l'esempio, scarica il file
ZIP delle tracce (che include altre tracce a cui si fa riferimento in questa
sezione), decomprimi il file e apri il file systrace_tutorial.html nel
browser.
Quando apri il file systrace, viene visualizzata una schermata simile alla seguente:

Figura 10. TouchLatency in esecuzione su Pixel XL con la maggior parte delle opzioni attive.
Nella figura 10, la maggior parte delle opzioni è abilitata, inclusi i punti di traccia mdss e kgsl.
Quando cerchi jank, controlla la riga FrameMissed in SurfaceFlinger.
FrameMissed è un miglioramento della qualità della vita fornito da HWC2. Quando visualizzi
systrace per altri dispositivi, la riga FrameMissed potrebbe non essere presente se il dispositivo non utilizza
HWC2. In entrambi i casi, FrameMissed è correlato alla mancata esecuzione di uno dei suoi runtime regolari da parte di SurfaceFlinger e a un conteggio dei buffer in attesa invariato per l'app (com.prefabulated.touchlatency) a un VSync.

Figura 11. Correlazione tra FrameMissed e SurfaceFlinger.
La figura 11 mostra un frame mancante a 15598,29 ms. SurfaceFlinger si è riattivato brevemente all'intervallo VSync ed è tornato inattivo senza eseguire alcuna operazione, il che significa che SurfaceFlinger ha stabilito che non valeva la pena provare a inviare di nuovo un frame al display.
Per capire perché la pipeline non ha funzionato per questo frame, esamina prima l'esempio di frame funzionante riportato sopra per vedere come appare una normale pipeline UI in systrace. Quando è tutto pronto, torna al frame mancante e procedi a ritroso. Tieni presente che SurfaceFlinger si riattiva e si spegne immediatamente. Quando visualizzi il numero di frame in attesa da TouchLatency, ci sono due frame (un buon indizio per aiutarti a capire cosa sta succedendo).

Figura 12. SurfaceFlinger si riattiva e si spegne immediatamente.
Poiché ci sono frame in SurfaceFlinger, non si tratta di un problema dell'app. Inoltre, SurfaceFlinger si attiva al momento giusto, quindi non si tratta di un problema di SurfaceFlinger. Se SurfaceFlinger e l'app hanno un aspetto normale, probabilmente si tratta di un problema di driver.
Poiché i punti di traccia mdss e sync sono abilitati,
puoi ottenere informazioni sulle barriere (condivise tra il driver di visualizzazione e
SurfaceFlinger) che controllano quando i frame vengono inviati al display.
Queste recinzioni sono elencate in mdss_fb0_retire, che
indica quando un frame è sul display. Questi recinti sono forniti
nell'ambito della categoria di tracce sync. Quali recinzioni corrispondono a
determinati eventi in SurfaceFlinger dipende dal SOC e dallo stack di driver, quindi
collabora con il fornitore del SOC per comprendere il significato delle categorie di recinzioni nelle
tracce.
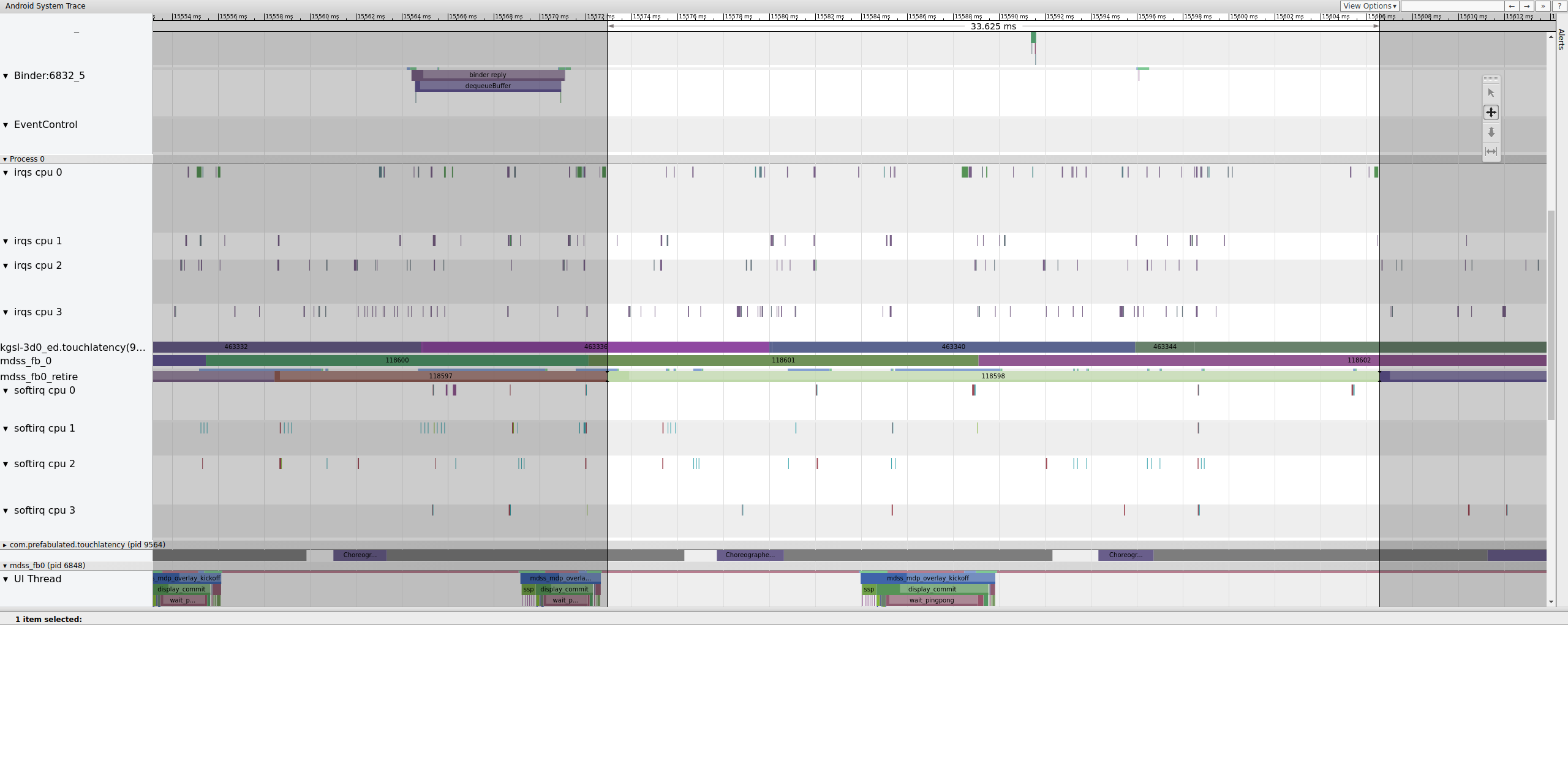
Figura 13. mdss_fb0_retire fences.
La Figura 13 mostra un frame visualizzato per 33 ms, non per 16,7 ms come previsto. A metà di questa sezione, il frame avrebbe dovuto essere sostituito da uno nuovo, ma non è successo. Visualizza il frame precedente e cerca qualcosa.
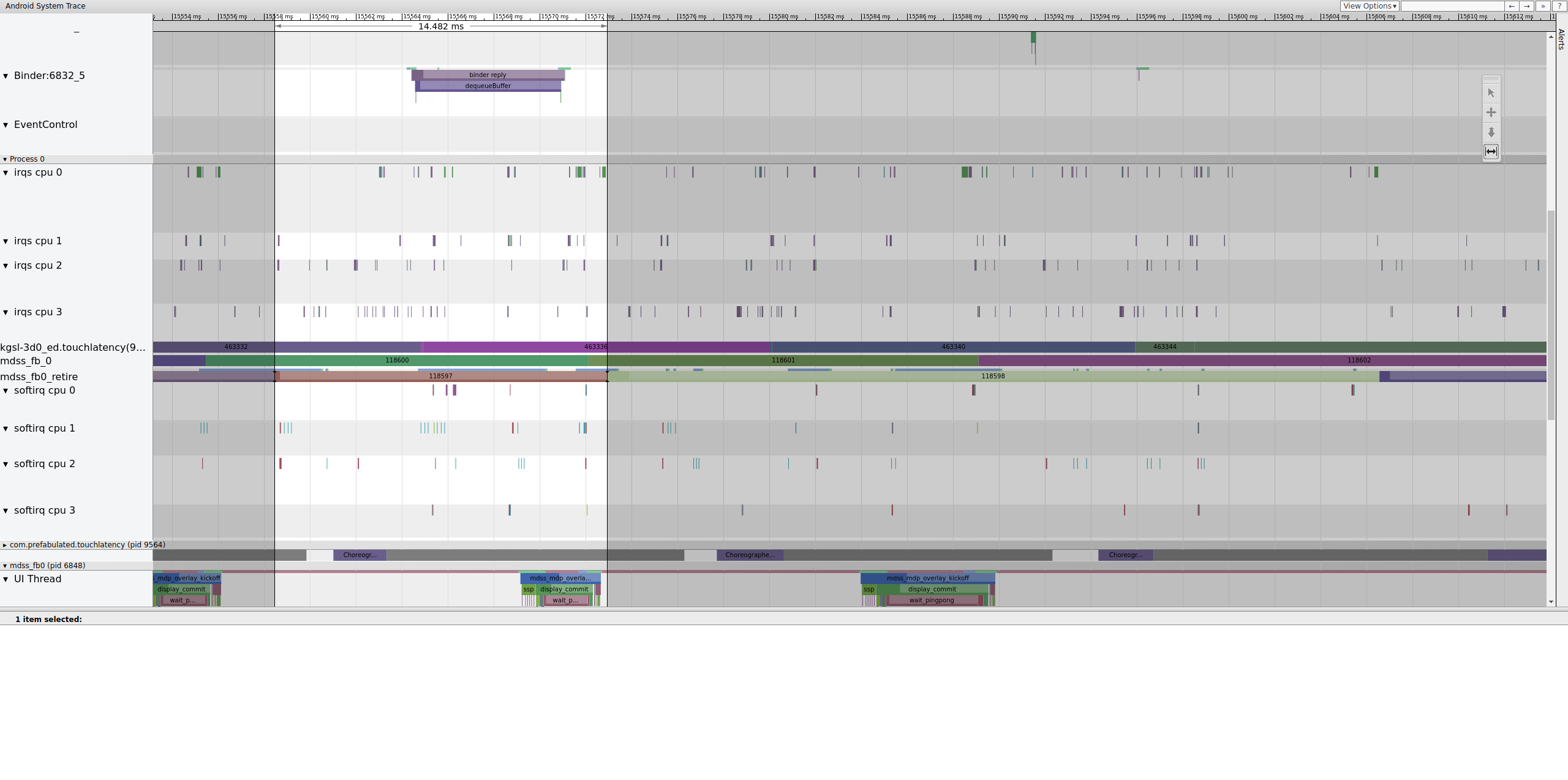
Figura 14. Frame precedente a quello danneggiato.
La figura 14 mostra un frame di 14.482 ms. Il segmento di due frame danneggiato era di 33,6 ms, che è più o meno quanto previsto per due frame (renderizzati a 60 Hz, 16,7 ms per frame, che è un valore simile). Tuttavia, 14.482 ms non si avvicinano a 16,7 ms, il che suggerisce che qualcosa non va nella pipeline di visualizzazione.
Indaga esattamente dove termina la recinzione per determinare cosa la controlla:
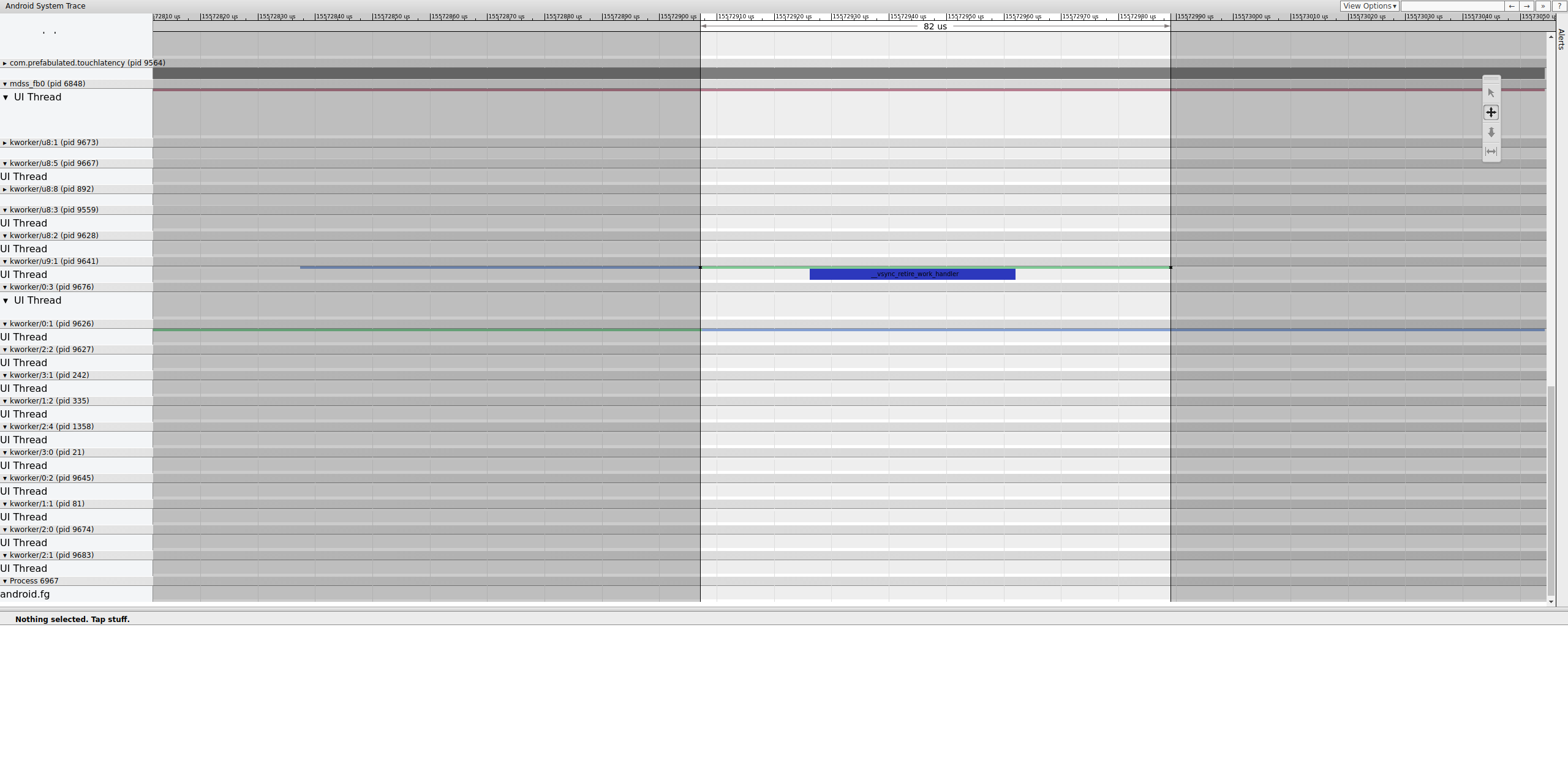
Figura 15. Esamina la fine della recinzione.
Una coda di lavoro contiene __vsync_retire_work_handler, che è
in esecuzione quando cambia la recinzione. Esaminando il codice sorgente del kernel, puoi vedere che
fa parte del driver del display. Sembra che si trovi nel percorso critico
della pipeline di visualizzazione, quindi deve essere eseguito il più rapidamente possibile. È
eseguibile per circa 70 μs (non un lungo ritardo di pianificazione), ma è una coda di lavoro e
potrebbe non essere pianificata con precisione.
Controlla il frame precedente per determinare se ha contribuito. A volte il jitter può accumularsi nel tempo e alla fine causare il mancato rispetto di una scadenza:
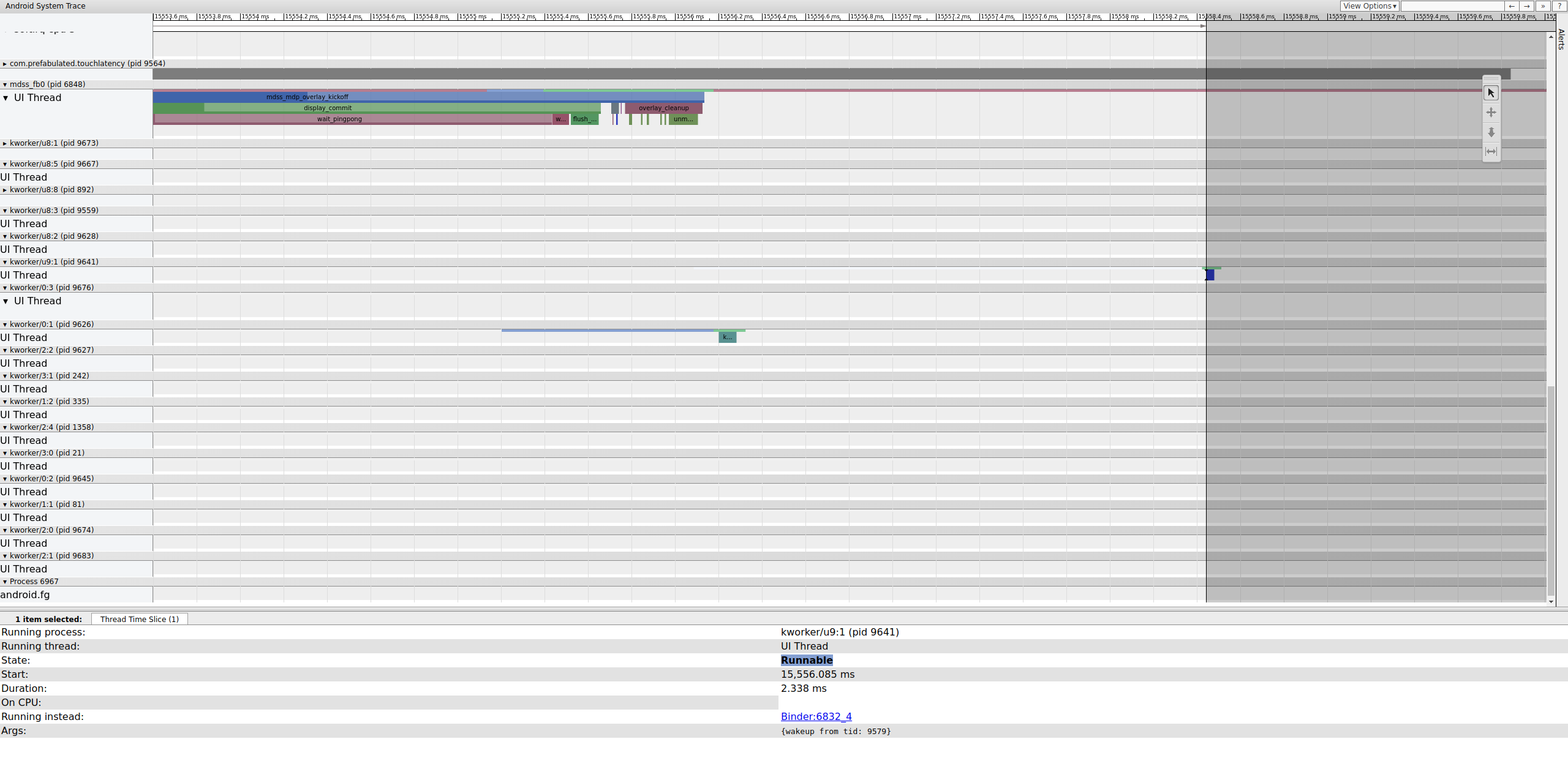
Figura 16. Fotogramma precedente.
La riga eseguibile su kworker non è visibile perché il visualizzatore la rende
bianca quando viene selezionata, ma le statistiche parlano chiaro: 2,3 ms di ritardo dello scheduler
per parte del percorso critico della pipeline di visualizzazione sono negativi.
Prima di continuare, correggi il ritardo spostando questa parte del
percorso critico della pipeline di visualizzazione da una workqueue (che viene eseguita come
thread SCHED_OTHER CFS) a un SCHED_FIFO
kthread dedicato. Questa funzione richiede garanzie di sincronizzazione che le code di lavoro non possono fornire (e non sono destinate a fornire).
Non è chiaro se questo sia il motivo del problema. Al di fuori dei casi facili da diagnosticare, come la contesa del blocco del kernel che causa la sospensione dei thread critici per la visualizzazione, le tracce di solito non specificano il problema. Questo jitter potrebbe essere stato la causa del frame eliminato. I tempi di sincronizzazione dovrebbero essere di 16,7 ms, ma non si avvicinano affatto a questo valore nei frame che precedono il frame eliminato. Data la stretta correlazione della pipeline di visualizzazione, è possibile che il jitter intorno alle tempistiche della barriera abbia comportato la perdita di un frame.
In questo esempio, la soluzione prevede la conversione
di __vsync_retire_work_handler da una workqueue a un kthread
dedicato. Ciò comporta miglioramenti notevoli del jitter e una riduzione dei problemi nel
test della palla che rimbalza. Le tracce successive mostrano tempi di recinzione molto vicini a 16,7 ms.