
Android udostępnia implementację referencyjną wszystkich komponentów potrzebnych do wdrożenia platformy wirtualizacji Androida. Obecnie to rozwiązanie jest ograniczone do urządzeń z architekturą ARM64. Na tej stronie opisujemy architekturę platformy.
Tło
Architektura Arm umożliwia stosowanie maksymalnie 4 poziomów uprawnień, przy czym poziom 0 (EL0) ma najmniejsze uprawnienia, a poziom 3 (EL3) – największe. Największa część bazy kodu Androida (wszystkie komponenty przestrzeni użytkownika) działa na poziomie EL0. Pozostała część tego, co powszechnie nazywa się „Androidem”, to jądro systemu Linux, które działa na poziomie uprawnień EL1.
Warstwa EL2 umożliwia wprowadzenie hipernadzorcy, który pozwala na izolowanie pamięci i urządzeń w poszczególnych pVM na poziomie EL1/EL0, z solidnymi gwarancjami poufności i integralności.
Hipernadzorca
Chroniona maszyna wirtualna oparta na jądrze (pKVM) jest oparta na hipernadzorcy Linux KVM, który został rozszerzony o możliwość ograniczania dostępu do ładunków działających na gościnnych maszynach wirtualnych oznaczonych jako „chronione” w momencie tworzenia.
KVM/arm64 obsługuje różne tryby wykonywania w zależności od dostępności niektórych funkcji procesora, a mianowicie rozszerzeń hosta wirtualizacji (VHE) (ARMv8.1 i nowsze). W jednym z tych trybów, powszechnie znanym jako tryb non-VHE, kod hiperwizora jest wyodrębniany z obrazu jądra podczas uruchamiania i instalowany na poziomie EL2, a samo jądro działa na poziomie EL1. Chociaż EL2 jest częścią bazy kodu systemu Linux, jest to niewielki komponent KVM odpowiedzialny za przełączanie między wieloma poziomami EL1. Komponent hipernadzorcy jest kompilowany w systemie Linux, ale znajduje się w osobnej, dedykowanej sekcji pamięci obrazu vmlinux. pKVM wykorzystuje tę konstrukcję, rozszerzając kod hipernadzorcy o nowe funkcje, które pozwalają mu nakładać ograniczenia na jądro hosta Androida i przestrzeń użytkownika oraz ograniczać dostęp hosta do pamięci gościa i hipernadzorcy.
Moduły dostawcy pKVM
Moduł dostawcy pKVM to moduł specyficzny dla sprzętu, który zawiera funkcje specyficzne dla urządzenia, takie jak sterowniki jednostki zarządzania pamięcią wejścia-wyjścia (IOMMU). Te moduły umożliwiają przenoszenie do pKVM funkcji zabezpieczeń wymagających dostępu na poziomie wyjątku 2 (EL2).
Aby dowiedzieć się, jak wdrożyć i załadować moduł dostawcy pKVM, przeczytaj artykuł Wdrażanie modułu dostawcy pKVM.
Procedura uruchamiania
Na poniższym rysunku przedstawiono procedurę uruchamiania pKVM:
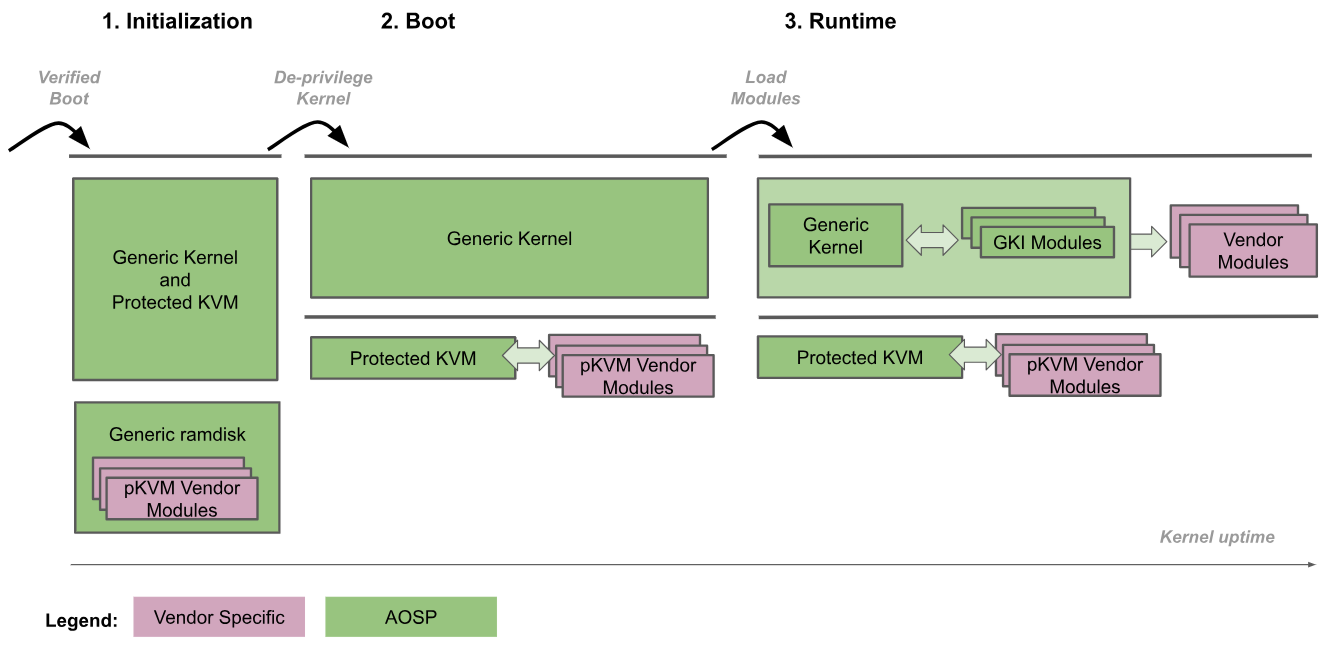
- Inicjowanie: program rozruchowy wchodzi do ogólnego jądra na poziomie uprawnień EL2. Kod zaufanego jądra na poziomach EL2 i EL1 inicjuje pKVM i jego moduły. W tej fazie EL1 jest zaufany przez EL2, więc nie jest wykonywany żaden niezaufany kod.
- Obniżenie uprawnień jądra: ogólne jądro wykrywa, że działa na poziomie EL2, i obniża swoje uprawnienia do poziomu EL1. pKVM i jego moduły nadal działają na poziomie EL2.
- Czas działania: ogólne jądro uruchamia się normalnie, wczytując wszystkie niezbędne sterowniki urządzenia, aż do osiągnięcia przestrzeni użytkownika. W tym momencie pKVM jest już w użyciu i obsługuje tablice stron drugiego etapu.
Procedura rozruchu ufa programowi rozruchowemu w zakresie weryfikacji i utrzymywania integralności obrazu jądra w fazie inicjowania. Po pozbawieniu jądra uprawnień hipernadzorca przestaje uważać je za zaufane. Od tego momentu to hipernadzorca odpowiada za ochronę, nawet jeśli jądro zostanie naruszone.
Umieszczenie jądra Androida i hiperwizora w tym samym obrazie binarnym umożliwia bardzo ścisłe powiązanie interfejsu komunikacyjnego między nimi. Takie ścisłe powiązanie gwarantuje atomowe aktualizacje obu komponentów, co eliminuje konieczność utrzymywania stabilnego interfejsu między nimi i zapewnia dużą elastyczność bez obniżania długoterminowej możliwości konserwacji. Ścisłe powiązanie umożliwia też optymalizację wydajności, gdy oba komponenty mogą współpracować bez wpływu na gwarancje bezpieczeństwa zapewniane przez hiperwizor.
Ponadto wdrożenie GKI w ekosystemie Androida automatycznie umożliwia wdrożenie hipernadzorcy pKVM na urządzeniach z Androidem w tym samym pliku binarnym co jądro.
Ochrona dostępu do pamięci procesora
Architektura Arm określa jednostkę zarządzania pamięcią (MMU) podzieloną na 2 niezależne etapy, z których oba mogą być używane do implementowania translacji adresów i kontroli dostępu do różnych części pamięci. Jednostka MMU etapu 1 jest kontrolowana przez poziom EL1 i umożliwia tłumaczenie adresów pierwszego poziomu. MMU etapu 1 jest używany przez system Linux do zarządzania przestrzenią adresową wirtualną udostępnianą każdemu procesowi przestrzeni użytkownika i własną przestrzenią adresową wirtualną.
MMU drugiego etapu jest kontrolowana przez EL2 i umożliwia zastosowanie drugiego tłumaczenia adresu do adresu wyjściowego MMU pierwszego etapu, co daje adres fizyczny (PA). Tłumaczenie na etapie 2 może być używane przez hiperwizory do kontrolowania i tłumaczenia dostępu do pamięci ze wszystkich maszyn wirtualnych gościa. Jak pokazano na rysunku 2, gdy oba etapy translacji są włączone, adres wyjściowy etapu 1 jest nazywany pośrednim adresem fizycznym (IPA). Uwaga: adres wirtualny (VA) jest tłumaczony na IPA, a następnie na PA.
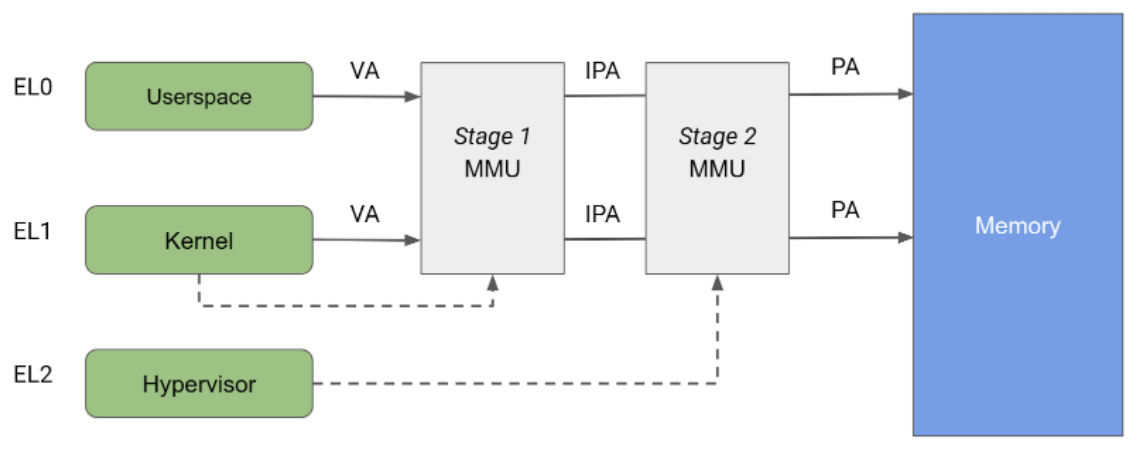
Tradycyjnie KVM działa z włączonym tłumaczeniem na poziomie 2 podczas uruchamiania gości i z wyłączonym tłumaczeniem na poziomie 2 podczas uruchamiania jądra systemu Linux na hoście. Ta architektura umożliwia przechodzenie dostępu do pamięci z jednostki MMU poziomu 1 hosta przez jednostkę MMU poziomu 2, co pozwala na nieograniczony dostęp hosta do stron pamięci gościa. Z drugiej strony pKVM umożliwia ochronę na etapie 2 nawet w kontekście hosta i powierza ochronę stron pamięci gościa hiperwizorowi, a nie hostowi.
KVM w pełni wykorzystuje translację adresów na etapie 2 do implementowania złożonych mapowań IPA/PA dla gości, co stwarza iluzję ciągłej pamięci dla gości pomimo fizycznej fragmentacji. Jednak użycie MMU drugiego etapu na potrzeby hosta jest ograniczone tylko do kontroli dostępu. Host na etapie 2 jest mapowany na tożsamość, co zapewnia, że ciągła pamięć w przestrzeni adresowej IPA hosta jest ciągła w przestrzeni adresowej PA. Ta architektura umożliwia stosowanie dużych mapowań w tabeli stron, co zmniejsza obciążenie bufora TLB. Mapowanie tożsamości może być indeksowane przez PA, dlatego etap 2 hosta jest też używany do śledzenia własności strony bezpośrednio w tabeli stron.
Ochrona przed bezpośrednim dostępem do pamięci (DMA)
Jak wspomnieliśmy wcześniej, usunięcie mapowania stron gościa z tabel stron hosta Linux w procesorze jest niezbędnym, ale niewystarczającym krokiem w ochronie pamięci gościa. pKVM musi też chronić przed dostępem do pamięci dokonywanym przez urządzenia obsługujące DMA pod kontrolą jądra hosta oraz przed możliwością ataku DMA zainicjowanego przez złośliwego hosta. Aby uniemożliwić takiemu urządzeniu dostęp do pamięci gościa, pKVM wymaga sprzętu jednostki zarządzania pamięcią wejścia-wyjścia (IOMMU) dla każdego urządzenia w systemie obsługującego DMA, jak pokazano na rysunku 3.
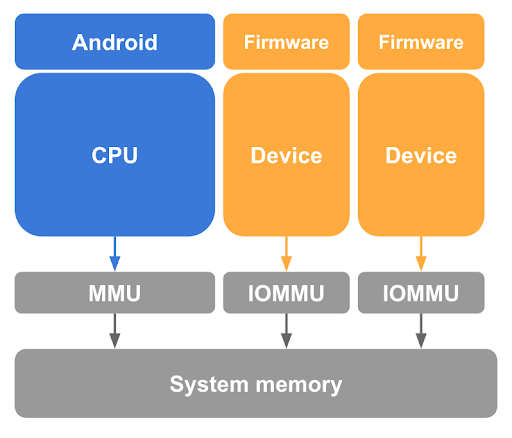
Sprzęt IOMMU zapewnia co najmniej możliwość przyznawania i cofania dostępu do odczytu/zapisu w pamięci fizycznej na poziomie strony. Sprzęt IOMMU ogranicza jednak użycie urządzeń w pVM, ponieważ zakłada on etap 2 z mapowaniem tożsamości.
Aby zapewnić izolację między maszynami wirtualnymi, transakcje pamięci generowane w imieniu różnych podmiotów muszą być rozróżnialne przez IOMMU, aby można było użyć odpowiedniego zestawu tabel stron do tłumaczenia.
Dodatkowo zmniejszenie ilości kodu specyficznego dla SoC na poziomie EL2 jest kluczową strategią ograniczania ogólnej zaufanej bazy obliczeniowej (TCB) pKVM i jest sprzeczne z uwzględnieniem sterowników IOMMU w hiperwizorze. Aby rozwiązać ten problem, host na poziomie EL1 odpowiada za pomocnicze zadania związane z zarządzaniem IOMMU, takie jak zarządzanie zasilaniem, inicjowanie i w odpowiednich przypadkach obsługa przerwań.
Jednak przekazanie hostowi kontroli nad stanem urządzenia nakłada dodatkowe wymagania na interfejs programowania sprzętu IOMMU, aby zapewnić, że kontroli uprawnień nie można pominąć w inny sposób, np. po zresetowaniu urządzenia.
Standardowym i dobrze obsługiwanym modułem IOMMU na urządzeniach z architekturą Arm, który umożliwia zarówno izolację, jak i bezpośrednie przypisywanie, jest architektura Arm System Memory Management Unit (SMMU). Ta architektura jest zalecanym rozwiązaniem referencyjnym.
Własność pamięci
Podczas uruchamiania cała pamięć nieużywana przez hipernadzorcę jest uznawana za należącą do hosta i jest śledzona przez hipernadzorcę. Gdy uruchamiana jest maszyna pVM, host przekazuje strony pamięci, aby umożliwić jej uruchomienie, a hipernadzorca przenosi własność tych stron z hosta na maszynę pVM. Hiperwizor umieszcza w tabeli stron hosta na etapie 2 ograniczenia dostępu, aby uniemożliwić mu ponowne uzyskanie dostępu do stron, zapewniając poufność gościa.
Komunikacja między hostem a gośćmi jest możliwa dzięki kontrolowanemu udostępnianiu pamięci. Goście mogą udostępniać niektóre swoje strony gospodarzowi za pomocą wywołania hiperwywołania, które instruuje hiperwizora, aby ponownie zmapował te strony w tabeli stron drugiego etapu gospodarza. Podobnie komunikacja hosta z TrustZone jest możliwa dzięki operacjom udostępniania lub wypożyczania pamięci, które są ściśle monitorowane i kontrolowane przez pKVM za pomocą specyfikacji Firmware Framework for Arm (FF-A).
Wymagania dotyczące pamięci pVM mogą się zmieniać z czasem, dlatego udostępniamy hiperwywołanie, które umożliwia przekazanie z powrotem do hosta własności określonych stron należących do elementu wywołującego. W praktyce ten hiperwywołanie jest używane z protokołem balonu virtio, aby umożliwić VMM żądanie pamięci z pVM i powiadamianie VMM przez pVM o zwolnionych stronach w kontrolowany sposób.
Hiperwizor odpowiada za śledzenie własności wszystkich stron pamięci w systemie oraz tego, czy są one udostępniane lub wypożyczane innym podmiotom. Większość tego śledzenia stanu odbywa się za pomocą metadanych dołączonych do hosta i gości w tabelach stron drugiego etapu, z użyciem zarezerwowanych bitów w pozycjach tabeli stron (PTE), które, jak sama nazwa wskazuje, są zarezerwowane do użytku przez oprogramowanie.
Host musi dbać o to, aby nie próbować uzyskiwać dostępu do stron, które zostały udostępnione przez hiperwizor. Nielegalny dostęp do hosta powoduje wstrzyknięcie do niego przez hipernadzorcę synchronicznego wyjątku, który może spowodować wysłanie sygnału SEGV do odpowiedzialnego zadania w przestrzeni użytkownika lub awarię jądra hosta. Aby zapobiec przypadkowemu dostępowi, strony przekazane gościom są wykluczane z możliwości zamiany lub scalenia przez jądro hosta.
Obsługa przerwań i liczniki czasu
Przerwania są niezbędne do interakcji gościa z urządzeniami i do komunikacji między procesorami, w której głównym mechanizmem są przerwania międzyprocesorowe (IPI). Model KVM polega na przekazaniu całego zarządzania wirtualnymi przerwaniami do hosta w EL1, który w tym celu zachowuje się jak niezaufana część hipernadzorcy.
pKVM oferuje pełną emulację kontrolera przerwań ogólnych w wersji 3 (GICv3) na podstawie istniejącego kodu KVM. Timer i IPI są obsługiwane w ramach tego niezaufanego kodu emulacji.
Obsługa GICv3
Interfejs między EL1 a EL2 musi zapewniać, że pełny stan przerwania jest widoczny dla hosta EL1, w tym kopie rejestrów hiperwizora związanych z przerwaniami. Zwykle odbywa się to za pomocą regionów pamięci współdzielonej, po jednym na każdy procesor wirtualny (vCPU).
Kod obsługi czasu działania rejestru systemowego można uprościć, aby obsługiwał tylko pułapki rejestru przerwań generowanych przez oprogramowanie (SGIR) i rejestru dezaktywacji przerwań (DIR). Architektura wymaga, aby te rejestry zawsze powodowały pułapkę na poziomie uprawnień 2, podczas gdy inne pułapki były dotychczas przydatne tylko do łagodzenia skutków błędów. Wszystko inne jest obsługiwane przez sprzęt.
Po stronie MMIO wszystko jest emulowane na poziomie EL1, z wykorzystaniem całej obecnej infrastruktury w KVM. Na koniec instrukcja Wait for Interrupt (WFI) jest zawsze przekazywana do poziomu uprawnień EL1, ponieważ jest to jeden z podstawowych elementów planowania używanych przez KVM.
Pomoc dotycząca minutnika
Wartość komparatora wirtualnego timera musi być udostępniana na poziomie EL1 przy każdym przechwytywaniu instrukcji WFI, aby poziom EL1 mógł wstrzykiwać przerwania timera, gdy procesor wirtualny jest zablokowany. Fizyczny zegar jest w całości emulowany, a wszystkie pułapki są przekazywane do EL1.
Obsługa MMIO
Aby komunikować się z monitorem maszyny wirtualnej (VMM) i przeprowadzać emulację GIC, pułapki MMIO muszą być przekazywane z powrotem do hosta na poziomie EL1 w celu dalszej analizy. pKVM wymaga:
- IPA i rozmiar dostępu
- Dane w przypadku zapisu
- Kolejność bajtów procesora w momencie przechwycenia
Dodatkowo pułapki z rejestrem ogólnego przeznaczenia jako źródłem lub miejscem docelowym są przekazywane za pomocą abstrakcyjnego pseudorejestru transferu.
Interfejsy gości
Gość może komunikować się z chronionym gościem za pomocą kombinacji wywołań hiperwywołań i dostępu do pamięci w regionach przechwyconych. Wywołania hiperwizora są udostępniane zgodnie ze standardem SMCCC, a zakres jest zarezerwowany na potrzeby przydziału dostawcy przez KVM. Następujące wywołania hiperwywołań mają szczególne znaczenie dla gości pKVM.
Ogólne wywołania hiperwywołań
- PSCI zapewnia standardowy mechanizm, za pomocą którego gość może kontrolować cykl życia swoich vCPU, w tym włączanie, wyłączanie i zamykanie systemu.
- TRNG zapewnia standardowy mechanizm, za pomocą którego gość może wysyłać do pKVM żądania dotyczące entropii. pKVM przekazuje to wywołanie do EL3. Ten mechanizm jest szczególnie przydatny w sytuacjach, gdy nie można mieć pewności, że host zwirtualizuje sprzętowy generator liczb losowych (RNG).
Hiperwywołania pKVM
- Udostępnianie pamięci hostowi. Cała pamięć gościa jest początkowo niedostępna dla hosta, ale dostęp hosta jest niezbędny do komunikacji za pomocą pamięci współdzielonej i do urządzeń parawirtualizowanych, które korzystają ze współdzielonych buforów. Wywołania hiperwizora do udostępniania i cofania udostępniania stron hostowi pozwalają gościowi dokładnie określić, które części pamięci mają być dostępne dla pozostałych części Androida, bez konieczności uzgadniania tego.
- Zwalnianie pamięci na rzecz hosta. Cała pamięć gościa zwykle należy do gościa, dopóki nie zostanie zniszczona. Ten stan może być niewystarczający w przypadku długo działających maszyn wirtualnych, których wymagania dotyczące pamięci zmieniają się z czasem.
relinquishHiperwywołanie umożliwia gościowi wyraźne przekazanie z powrotem hostowi własności stron bez konieczności zamykania gościa. - Przechwytywanie dostępu do pamięci na hoście. Zwykle, jeśli gość KVM uzyskuje dostęp do adresu, który nie odpowiada prawidłowemu regionowi pamięci, wątek vCPU kończy działanie na hoście, a dostęp jest zwykle używany w przypadku MMIO i emulowany przez VMM w przestrzeni użytkownika. Aby ułatwić obsługę, pKVM musi przekazywać do hosta szczegóły dotyczące instrukcji powodującej błąd, takie jak jej adres, parametry rejestru i potencjalnie ich zawartość, co może nieumyślnie ujawnić dane wrażliwe z chronionego gościa, jeśli pułapka nie została przewidziana. pKVM rozwiązuje ten problem, traktując te błędy jako krytyczne, chyba że gość wcześniej wydał wywołanie hiperwywołania, aby zidentyfikować zakres IPA powodujący błąd jako zakres, w przypadku którego dostęp jest dozwolony w celu przechwytywania z powrotem do hosta. To rozwiązanie nazywa się ochroną MMIO.
Wirtualne urządzenie wejścia/wyjścia (virtio)
Virtio to popularny, przenośny i sprawdzony standard implementacji urządzeń parawirtualizowanych i interakcji z nimi. Większość urządzeń udostępnianych gościom objętym ochroną jest implementowana przy użyciu virtio. Virtio jest też podstawą implementacji vsock, która służy do komunikacji między chronionym gościem a pozostałą częścią Androida.
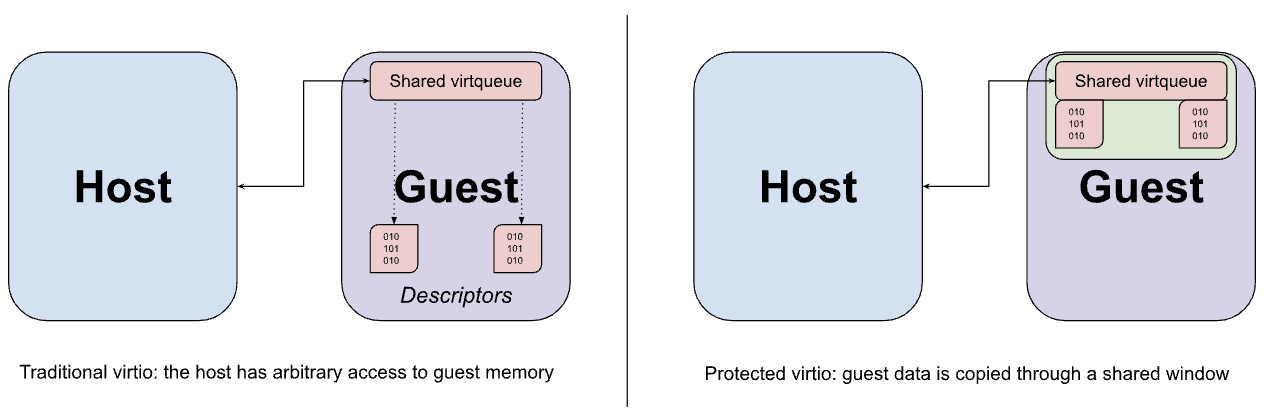
Urządzenia Virtio są zwykle implementowane w przestrzeni użytkownika hosta przez VMM, który przechwytuje pułapkowane dostępy do pamięci z gościa do interfejsu MMIO urządzenia virtio i emuluje oczekiwane zachowanie. Dostęp MMIO jest stosunkowo kosztowny, ponieważ każdy dostęp do urządzenia wymaga podróży w obie strony do VMM i z powrotem. Dlatego większość rzeczywistego przesyłania danych między urządzeniem a gościem odbywa się za pomocą zestawu kolejek wirtualnych w pamięci. Kluczowym założeniem interfejsu virtio jest to, że host może dowolnie uzyskiwać dostęp do pamięci gościa. To założenie jest widoczne w konstrukcji kolejki wirtualnej, która może zawierać wskaźniki do buforów w systemie gościa, do których emulacja urządzenia ma mieć bezpośredni dostęp.
Opisane wcześniej hiperwywołania udostępniania pamięci mogą służyć do udostępniania buforów danych virtio z gościa do hosta, ale to udostępnianie jest koniecznie wykonywane z dokładnością do strony i może ujawniać więcej danych niż jest to wymagane, jeśli rozmiar bufora jest mniejszy niż rozmiar strony. Zamiast tego gość jest skonfigurowany tak, aby przydzielać zarówno wirtualne kolejki, jak i odpowiadające im bufory danych z ustalonego okna pamięci współdzielonej, przy czym dane są kopiowane (przekazywane) do i z okna w razie potrzeby.
Interakcja z TrustZone
Goście nie mogą wchodzić w interakcję bezpośrednio z TrustZone, ale host musi mieć możliwość wykonywania wywołań SMC w bezpiecznym środowisku. Połączenia te mogą określać bufory pamięci adresowane fizycznie, które są niedostępne dla hosta. Ponieważ bezpieczne oprogramowanie zwykle nie wie o dostępności bufora, złośliwy host może użyć tego bufora do przeprowadzenia ataku typu „confused deputy” (analogicznego do ataku DMA). Aby zapobiec takim atakom, pKVM przechwytuje wszystkie wywołania SMC hosta do EL2 i działa jako serwer proxy między hostem a bezpiecznym monitorem na poziomie EL3.
Wywołania PSCI z hosta są przekazywane do oprogramowania układowego EL3 z minimalnymi modyfikacjami. W szczególności punkt wejścia dla procesora, który jest włączany lub wznawia działanie po zawieszeniu, jest przepisywany tak, aby tabela stron drugiego etapu była instalowana na poziomie EL2 przed powrotem do hosta na poziomie EL1. Podczas uruchamiania ta ochrona jest egzekwowana przez pKVM.
Ta architektura wymaga, aby układ SoC obsługiwał PSCI, najlepiej za pomocą aktualnej wersji TF-A jako oprogramowania układowego EL3.
Standard Firmware Framework for Arm (FF-A) ujednolica interakcje między normalnym i bezpiecznym środowiskiem, szczególnie w przypadku obecności bezpiecznego hiperwizora. Ważna część specyfikacji określa mechanizm udostępniania pamięci w świecie bezpiecznym, który wykorzystuje wspólny format wiadomości i dobrze zdefiniowany model uprawnień dla bazowych stron. pKVM przekazuje wiadomości FF-A, aby mieć pewność, że host nie próbuje udostępniać pamięci stronie bezpiecznej, do której nie ma wystarczających uprawnień.
Ta architektura opiera się na oprogramowaniu bezpiecznego świata, które wymusza model dostępu do pamięci, aby zapewnić, że zaufane aplikacje i inne oprogramowanie działające w bezpiecznym świecie mogą uzyskiwać dostęp do pamięci tylko wtedy, gdy jest ona na wyłączność bezpiecznego świata lub została z nim wyraźnie udostępniona za pomocą FF-A. W systemie z S-EL2 egzekwowanie modelu dostępu do pamięci powinno być realizowane przez rdzeń menedżera bezpiecznej partycji (SPMC), np. Hafnium, który utrzymuje tablice stron drugiego etapu dla bezpiecznego środowiska. W systemie bez S-EL2 środowisko TEE może zamiast tego wymuszać model dostępu do pamięci za pomocą tabel stron na poziomie 1.
Jeśli wywołanie SMC do EL2 nie jest wywołaniem PSCI ani wiadomością zdefiniowaną przez FF-A, nieobsługiwane wywołania SMC są przekazywane do EL3. Zakłada się, że (koniecznie zaufane) bezpieczne oprogramowanie układowe może bezpiecznie obsługiwać nieobsługiwane wywołania SMC, ponieważ rozumie środki ostrożności potrzebne do utrzymania izolacji pVM.
Monitor maszyny wirtualnej
crosvm to monitor maszyny wirtualnej (VMM), który uruchamia maszyny wirtualne za pomocą interfejsu KVM systemu Linux. Crosvm wyróżnia się naciskiem na bezpieczeństwo dzięki użyciu języka programowania Rust i piaskownicy wokół urządzeń wirtualnych, która chroni jądro hosta. Więcej informacji o crosvm znajdziesz w oficjalnej dokumentacji tutaj.
Deskryptory plików i ioctl
KVM udostępnia urządzenie znakowe /dev/kvm przestrzeni użytkownika za pomocą wywołań ioctl, które składają się na interfejs KVM API. Te ioctle należą do tych kategorii:
- Wykonują zapytania ioctl systemu i ustawiają atrybuty globalne, które wpływają na cały podsystem KVM, oraz tworzą pVM.
- Wywołania systemowe VM ioctl służą do wysyłania zapytań i ustawiania atrybutów, które tworzą wirtualne procesory (vCPU) i urządzenia, oraz wpływają na całą maszynę pVM, np. na układ pamięci oraz liczbę wirtualnych procesorów (vCPU) i urządzeń.
- Wywołania ioctl procesora wirtualnego służą do wysyłania zapytań o atrybuty, które kontrolują działanie pojedynczego procesora wirtualnego, i do ustawiania tych atrybutów.
- Wywołania ioctl urządzenia wysyłają zapytania i ustawiają atrybuty, które kontrolują działanie pojedynczego urządzenia wirtualnego.
Każdy proces crosvm uruchamia dokładnie 1 instancję maszyny wirtualnej. Ten proces używa wywołania systemowego KVM_CREATE_VM do utworzenia deskryptora pliku maszyny wirtualnej, którego można używać do wydawania wywołań ioctl pVM. Wywołanie KVM_CREATE_VCPU lub KVM_CREATE_DEVICE ioctl na deskryptorze pliku maszyny wirtualnej tworzy wirtualny procesor lub urządzenie i zwraca deskryptor pliku wskazujący nowe zasoby. Wywołania ioctl na deskryptorze pliku wirtualnego procesora lub urządzenia mogą służyć do sterowania urządzeniem utworzonym za pomocą wywołania ioctl na deskryptorze pliku maszyny wirtualnej. W przypadku procesorów wirtualnych obejmuje to ważne zadanie, jakim jest uruchamianie kodu gościa.
Wewnętrznie crosvm rejestruje deskryptory plików maszyny wirtualnej w jądrze za pomocą interfejsu epoll wyzwalanego zboczem. Jądro powiadamia crosvm, gdy w dowolnym deskryptorze pliku pojawi się nowe zdarzenie.
pKVM dodaje nową funkcję KVM_CAP_ARM_PROTECTED_VM, która może służyć do uzyskiwania informacji o środowisku pVM i konfigurowania trybu chronionego dla maszyny wirtualnej. crosvm używa tej funkcji podczas tworzenia pVM, jeśli przekazana jest flaga --protected-vm, aby wysyłać zapytania i rezerwować odpowiednią ilość pamięci dla oprogramowania sprzętowego pVM, a następnie włączać tryb chroniony.
Alokacja pamięci
Jednym z głównych zadań VMM jest przydzielanie pamięci maszyny wirtualnej i zarządzanie jej układem. crosvm generuje stały układ pamięci, który został ogólnie opisany w tabeli poniżej.
| FDT w trybie normalnym | PHYS_MEMORY_END - 0x200000
|
| Zwolnij miejsce | ...
|
| Ramdysk | ALIGN_UP(KERNEL_END, 0x1000000)
|
| Bąbelki | 0x80080000
|
| Program rozruchowy | 0x80200000
|
| FDT w trybie BIOS | 0x80000000
|
| Podstawa pamięci fizycznej | 0x80000000
|
| Oprogramowanie pVM | 0x7FE00000
|
| Pamięć urządzenia | 0x10000 - 0x40000000
|
Pamięć fizyczna jest przydzielana za pomocą funkcji mmap, a następnie przekazywana do maszyny wirtualnej w celu wypełnienia jej regionów pamięci, zwanych memslots, za pomocą wywołania systemowego KVM_SET_USER_MEMORY_REGION. Cała pamięć pVM gościa jest przypisywana do instancji crosvm, która nią zarządza, co może spowodować zabicie procesu (zakończenie działania maszyny wirtualnej), jeśli na hoście zacznie brakować wolnej pamięci. Gdy maszyna wirtualna zostanie zatrzymana, hiperwizor automatycznie wyczyści pamięć i zwróci ją do jądra hosta.
W przypadku zwykłego KVM menedżer maszyn wirtualnych zachowuje dostęp do całej pamięci gościa. W przypadku pKVM pamięć gościa jest odłączana od przestrzeni adresowej fizycznej hosta, gdy jest przekazywana gościowi. Jedynym wyjątkiem jest pamięć jawnie udostępniona przez gościa, np. w przypadku urządzeń virtio.
Regiony MMIO w przestrzeni adresowej gościa pozostają nieprzypisane. Dostęp gościa do tych regionów jest blokowany i powoduje zdarzenie wejścia/wyjścia na deskryptorze pliku maszyny wirtualnej. Ten mechanizm służy do implementowania urządzeń wirtualnych. W trybie chronionym gość musi potwierdzić, że region jego przestrzeni adresowej jest używany do MMIO, za pomocą wywołania hiperwywołania, aby zmniejszyć ryzyko przypadkowego wycieku informacji.
Harmonogram
Każdy wirtualny procesor jest reprezentowany przez wątek POSIX i planowany przez harmonogram hosta Linux. Wątek wywołuje KVM_RUN ioctl na FD procesora wirtualnego, co powoduje, że hipernadzorca przełącza się na kontekst procesora wirtualnego gościa. Harmonogram hosta
uwzględnia czas spędzony w kontekście gościa jako czas wykorzystany przez odpowiedni
wątek procesora wirtualnego. KVM_RUN jest zwracana, gdy wystąpi zdarzenie, które musi zostać obsłużone przez VMM, np. operacja wejścia/wyjścia, koniec przerwania lub zatrzymanie wirtualnego procesora. Menedżer maszyn wirtualnych obsługuje zdarzenie i ponownie wywołuje funkcję KVM_RUN.
W trakcie KVM_RUN wątek może być wywłaszczany przez harmonogram hosta, z wyjątkiem wykonywania kodu hiperwizora EL2, który nie może być wywłaszczany. Sama maszyna wirtualna gościa nie ma mechanizmu kontrolującego to zachowanie.
Wszystkie wątki procesora wirtualnego są planowane jak inne zadania przestrzeni użytkownika, dlatego podlegają wszystkim standardowym mechanizmom jakości usług. Każdy wątek wirtualnego procesora może być powiązany z fizycznymi procesorami, umieszczony w zestawach procesorów, wzmocniony lub ograniczony za pomocą ograniczenia wykorzystania, mieć zmienioną politykę priorytetu lub planowania i nie tylko.
Urządzenia wirtualne
crosvm obsługuje wiele urządzeń, w tym:
- virtio-blk w przypadku złożonych obrazów dysków, tylko do odczytu lub odczytu i zapisu
- vhost-vsock do komunikacji z hostem,
- virtio-pci jako transport virtio
- pl030 real time clock (RTC)
- UART 16550a do komunikacji szeregowej
Oprogramowanie pVM
Oprogramowanie układowe pVM (pvmfw) to pierwszy kod wykonywany przez pVM, podobnie jak pamięć ROM rozruchu urządzenia fizycznego. Głównym celem pvmfw jest uruchomienie bezpiecznego rozruchu i uzyskanie unikalnego klucza tajnego pVM. Oprogramowanie pvmfw nie jest ograniczone do używania z żadnym konkretnym systemem operacyjnym, takim jak Microdroid, o ile system operacyjny jest obsługiwany przez crosvm i został prawidłowo podpisany.
Plik binarny pvmfw jest przechowywany w partycji flash o tej samej nazwie i jest aktualizowany za pomocą OTA.
Uruchamianie urządzenia
Do procedury uruchamiania urządzenia z włączoną technologią pKVM dodawana jest ta sekwencja działań:
- Program ładujący Androida (ABL) wczytuje pvmfw z partycji do pamięci i weryfikuje obraz.
- ABL pobiera tajne klucze DICE (Device Identifier Composition Engine) (złożone identyfikatory urządzenia (CDI) i łańcuch certyfikatów DICE) ze źródła zaufania.
- ABL uzyskuje niezbędne CDI dla pvmfw i dołącza je do pliku binarnego pvmfw.
- ABL dodaje do DT węzeł
linux,pkvm-guest-firmware-memoryreserved memory region, który opisuje lokalizację i rozmiar pliku binarnego pvmfw oraz wygenerowane w poprzednim kroku klucze tajne. - ABL przekazuje kontrolę do systemu Linux, który inicjuje pKVM.
- pKVM usuwa mapowanie regionu pamięci pvmfw z tabel stron poziomu 2 hosta i chroni go przed hostem (i gośćmi) przez cały czas działania urządzenia.
Po uruchomieniu urządzenia Microdroid jest uruchamiany zgodnie z instrukcjami w sekcji Sekwencja uruchamiania dokumentu Microdroid.
Rozruch pVM
Podczas tworzenia pVM crosvm (lub inny VMM) musi utworzyć wystarczająco duży memslot, który będzie wypełniony obrazem pvmfw przez hiperwizor. Monitor maszyn wirtualnych ma też ograniczenia dotyczące listy rejestrów, których wartość początkową może ustawić (x0–x14 w przypadku głównego procesora wirtualnego, brak w przypadku dodatkowych procesorów wirtualnych). Pozostałe rejestry są zarezerwowane i stanowią część interfejsu ABI hypervisor-pvmfw.
Po uruchomieniu pVM hiperwizor najpierw przekazuje kontrolę nad głównym procesorem wirtualnym do pvmfw. Oprogramowanie sprzętowe oczekuje, że crosvm załaduje do pamięci jądro podpisane za pomocą AVB (może to być program rozruchowy lub dowolny inny obraz) oraz niepodpisany FDT pod znanymi adresami. pvmfw weryfikuje podpis AVB i w przypadku powodzenia generuje z otrzymanego FDT zaufane drzewo urządzeń, usuwa z pamięci swoje dane tajne i przechodzi do punktu wejścia ładunku. Jeśli jeden z etapów weryfikacji zakończy się niepowodzeniem, oprogramowanie układowe wyda hiperwywołanie PSCI SYSTEM_RESET.
Między uruchomieniami informacje o instancji pVM są przechowywane na partycji (urządzenie virtio-blk) i szyfrowane za pomocą klucza tajnego pvmfw, aby po ponownym uruchomieniu klucz tajny był udostępniany prawidłowej instancji.