
Android 8.0 には、binder と hwbinder という、スループットとレイテンシに関するパフォーマンス テストが用意されています。パフォーマンスの問題を検出する方法は多数ありますが、実行に時間がかかり、システムが統合されるまで結果が得られないこともあります。提供されているパフォーマンス テストを使用すると、開発中のテスト、深刻な問題の早期の検出、ユーザー エクスペリエンスの向上が容易になります。
パフォーマンス テストには、次の 4 つのカテゴリがあります。
- binder スループット(
system/libhwbinder/vts/performance/Benchmark_binder.cppにあります) - binder レイテンシ(
frameworks/native/libs/binder/tests/schd-dbg.cppにあります) - hwbinder スループット(
system/libhwbinder/vts/performance/Benchmark.cppにあります) - hwbinder レイテンシ(
system/libhwbinder/vts/performance/Latency.cppにあります)
binder と hwbinder について
binder と hwbinder は、同じ Linux ドライバを使用する Android のプロセス間通信(IPC)インフラストラクチャですが、次のような質的な違いがあります。
| 側面 | binder | hwbinder |
|---|---|---|
| 目的 | フレームワークに汎用 IPC スキームを提供する | ハードウェアと通信する |
| プロパティ | Android フレームワークの使用に最適化 | 最小のオーバーヘッド、低レイテンシ |
| フォアグラウンドとバックグラウンドのスケジューリング ポリシーの変更 | ○ | × |
| 引数の渡し方 | Parcel オブジェクトでサポートされているシリアル化を使用 | スキャッター バッファを使用し、Parcel のシリアル化で必要なデータをコピーするためにオーバーヘッドを回避 |
| 優先度継承 | × | ○ |
binder と hwbinder のプロセス
systrace 可視化ツールを使用すると、次のようにトランザクションが表示されます。
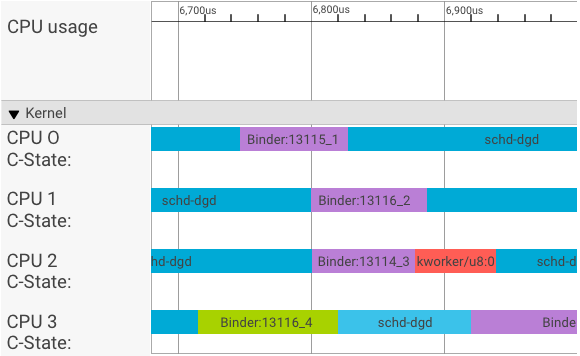
上に示した例で:
- 4 つの schd-dbg プロセスは、クライアント プロセスです。
- 4 つの binder プロセスは、サーバー プロセスです。名前の最初が Binder で、最後がシーケンス番号です。
- クライアント プロセスは、常にそのクライアント専用のサーバー プロセスとペアになっています。
- すべてのクライアントとサーバーのプロセスペアには、カーネルによって独立したスケジューリングが並行に行われます。
CPU 1 で、OS カーネルがクライアントを実行してリクエストを発行します。次に、可能なら同じ CPU を使用して、サーバー プロセスを起こして、リクエストを処理し、リクエストの完了後にコンテキスト スイッチで復帰します。
スループットとレイテンシ
理想的なトランザクションでは、クライアント プロセスとサーバー プロセスが隙間を空けずに切り替わるため、スループット テストとレイテンシ テストで得られる結果は実質的に同じものとなります。しかし、OS カーネルがハードウェアからの割り込み要求(IRQ)を処理しているとき、ロックで待っているとき、単にメッセージをすぐ処理しないときには、レイテンシ バブルが発生します。
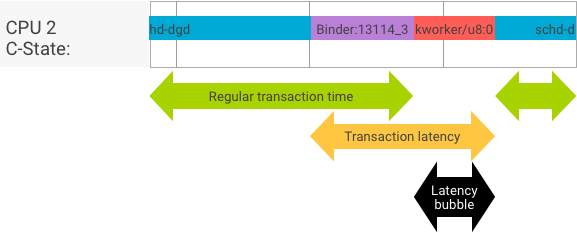
スループット テストでは、さまざまなペイロード サイズのトランザクションが多数生成され、通常のトランザクション時間の良い予測値(最もうまくいった場合)と、binder で達成できる最高スループット値が得られます。
一方、レイテンシ テストでは、ペイロードに対して通常のトランザクション時間を最小化するための操作を加えることはありません。トランザクション時間を使用して、binder のオーバーヘッドの推定、最悪ケースの統計の作成、レイテンシが指定のデッドラインに達したトランザクションの割合の算出ができます。
優先度逆転を処理する
優先度逆転は、優先度の高いスレッドが優先度の低いスレッドを論理的に待機している場合に発生します。リアルタイム(RT)アプリケーションには、下図のような優先度逆転の問題があります。
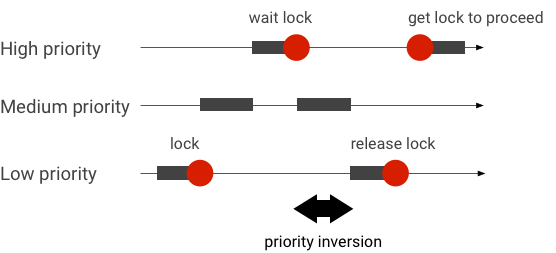
Linux の CFS(Completely Fair Scheduler)スケジューリングを使用する場合、他のスレッドより優先度が低いスレッドにも常に実行の機会が与えられます。そのため、CFS スケジューリングを使用するアプリケーションでは、優先度逆転を想定される動作として扱い、問題としては扱いません。しかし、Android フレームワークで高優先度のスレッドが持つ特権を保証するために RT スケジューリングが必要な場合は、優先度逆転を解決する必要があります。
下図は、binder トランザクション中の優先度逆転の例です。RT スレッドは、binder スレッドが処理するのを待っている間、他の CFS スレッドによって論理的にブロックされます。
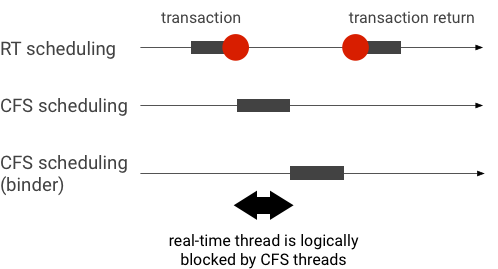
ブロックを防ぐために、binder スレッドが RT スレッドからのリクエストを処理するときに、優先度継承を使用して、binder スレッドの優先度を一時的に RT スレッドと同じ優先度に上げることができます。RT スケジューリングにはリソース制限があるため、注意して使用する必要があります。CPU が n 個のシステムでは、同時に動作する RT スレッドの最大数も n 個です。それを超える RT スレッドは、すべての CPU で他の RT スレッドが動作している場合、待機する必要があり、デッドラインに間に合わない可能性があります。
優先度逆転が発生するという問題をすべて解決するために、binder と hwbinder の両方で優先度継承を使用できます。しかし、binder はシステム全体で広く使用されているため、binder トランザクションで優先度逆転を有効にすると、システムが処理しきれない数の RT スレッドが発生することになります。
スループット テストを実行する
スループット テストは、binder と hwbinder のトランザクション スループットに対して実行されます。過負荷になっていないシステムでは、レイテンシ バブルはほとんどなく、繰り返しの回数が十分である限りその影響はありません。
- binder スループット テストは
system/libhwbinder/vts/performance/Benchmark_binder.cppにあります。 - hwbinder スループット テストは
system/libhwbinder/vts/performance/Benchmark.cppにあります。
テスト結果
さまざまなペイロード サイズを使用するトランザクションのスループット テストの結果の例を次に示します。
Benchmark Time CPU Iterations --------------------------------------------------------------------- BM_sendVec_binderize/4 70302 ns 32820 ns 21054 BM_sendVec_binderize/8 69974 ns 32700 ns 21296 BM_sendVec_binderize/16 70079 ns 32750 ns 21365 BM_sendVec_binderize/32 69907 ns 32686 ns 21310 BM_sendVec_binderize/64 70338 ns 32810 ns 21398 BM_sendVec_binderize/128 70012 ns 32768 ns 21377 BM_sendVec_binderize/256 69836 ns 32740 ns 21329 BM_sendVec_binderize/512 69986 ns 32830 ns 21296 BM_sendVec_binderize/1024 69714 ns 32757 ns 21319 BM_sendVec_binderize/2k 75002 ns 34520 ns 20305 BM_sendVec_binderize/4k 81955 ns 39116 ns 17895 BM_sendVec_binderize/8k 95316 ns 45710 ns 15350 BM_sendVec_binderize/16k 112751 ns 54417 ns 12679 BM_sendVec_binderize/32k 146642 ns 71339 ns 9901 BM_sendVec_binderize/64k 214796 ns 104665 ns 6495
- Time は、リアルタイムで測定された往復遅延を示します。
- CPU は、CPU がテストにスケジューリングされた累積時間を示します。
- Iterations は、テスト関数が実行された回数を示します。
たとえば、8 バイトのペイロードの場合、次のようになります。
BM_sendVec_binderize/8 69974 ns 32700 ns 21296
binder が達成できる最高スループットは次のように算出されます。
8 バイト ペイロードの最高スループット =(8 * 21296)/ 69974 ≒ 2.423 b/ns ≒ 2.268 Gb/s
テスト オプション
.json 形式で結果を取得するには、次のように --benchmark_format=json 引数を指定してテストを実行します。
libhwbinder_benchmark --benchmark_format=json
{
"context": {
"date": "2017-05-17 08:32:47",
"num_cpus": 4,
"mhz_per_cpu": 19,
"cpu_scaling_enabled": true,
"library_build_type": "release"
},
"benchmarks": [
{
"name": "BM_sendVec_binderize/4",
"iterations": 32342,
"real_time": 47809,
"cpu_time": 21906,
"time_unit": "ns"
},
….
}レイテンシ テストを実行する
レイテンシ テストでは、クライアントがトランザクションの初期化を開始してから、処理のサーバー プロセスに切り替え、結果を受け取るまでの時間を測定します。このテストでは、優先度継承をサポートしない、または同期フラグを無視するスケジューラなど、トランザクションのレイテンシに悪影響を及ぼす既知の不適切なスケジューラの動作の検出も行われます。
- binder レイテンシ テストは
frameworks/native/libs/binder/tests/schd-dbg.cppにあります。 - hwbinder レイテンシ テストは
system/libhwbinder/vts/performance/Latency.cppにあります。
テスト結果
結果(.json 形式)には、平均遅延、最長遅延、最短遅延、デッドライン超過の回数に関する統計情報が示されます。
テスト オプション
レイテンシ テストには、次のオプションがあります。
| コマンド | 説明 |
|---|---|
-i value |
繰り返し回数を指定します。 |
-pair value |
プロセスペアの数を指定します。 |
-deadline_us 2500 |
デッドラインをマイクロ秒単位で指定します。 |
-v |
詳細(デバッグ用)出力を表示します。 |
-trace |
デッドラインに達したときにトレースを停止します。 |
以下のセクションでは、各オプションの詳細、使用方法、結果の例を示します。
繰り返しを指定する
繰り返し回数に大きな数を指定し、詳細な出力を無効にした例を次に示します。
libhwbinder_latency -i 5000 -pair 3
{
"cfg":{"pair":3,"iterations":5000,"deadline_us":2500},
"P0":{"SYNC":"GOOD","S":9352,"I":10000,"R":0.9352,
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}
},
"P1":{"SYNC":"GOOD","S":9334,"I":10000,"R":0.9334,
"other_ms":{ "avg":0.19, "wst":2.9 , "bst":0.055, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":3.1 , "bst":0.066, "miss":1, "meetR":0.9998}
},
"P2":{"SYNC":"GOOD","S":9369,"I":10000,"R":0.9369,
"other_ms":{ "avg":0.19, "wst":4.8 , "bst":0.055, "miss":6, "meetR":0.9988},
"fifo_ms": { "avg":0.15, "wst":1.8 , "bst":0.067, "miss":0, "meetR":1}
},
"inheritance": "PASS"
}これらのテスト結果の意味は次のとおりです。
"pair":3- クライアントとサーバーのペアを 1 個作成します。
"iterations": 5000- 5,000 回繰り返した結果が含まれています。
"deadline_us":2500- デッドラインは 2,500 マイクロ秒(2.5 ミリ秒)です。ほとんどのトランザクションはこの値を満たすと想定されます。
"I": 10000- 繰り返しの 1 回には、2 回のトランザクションがあります。
- 通常の優先度(
CFS other)でのトランザクションが 1 回 - リアルタイム優先度(
RT-fifo)でのトランザクション 1 回
- 通常の優先度(
"S": 9352- 9,352 回のトランザクションが同じ CPU 内に同期されています。
"R": 0.9352- クライアントとサーバーが同じ CPU に同期されている割合を示します。
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996}- 通常優先度の呼び出し元により発行されたすべてのトランザクションの平均(
avg)、最長(wst)、最短(bst)のケースです。2 回のトランザクションがデッドラインをmiss(超過)したため、デッドラインの遵守率(meetR)は 0.9996 となります。 "fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}rt_fifo優先度のクライアントにより発行されたトランザクションということ以外は、other_msと同様です。常にではありませんが、fifo_msの方がother_msよりも良い結果になります。具体的には、avgとwstの値が小さく、meetRが大きくなります(バックグラウンドの負荷が大きいほど差が大きくなります)。
注: バックグラウンドでの負荷が、スループットの結果とレイテンシ テストの other_ms の値に影響する可能性があります。fifo_ms だけは、バックグラウンドの負荷の優先度が RT-fifo 優先度より低い場合に限り、同じような結果になります。
ペア数を指定する
各クライアント プロセスは、そのクライアント専用のサーバー プロセスとペアにされ、各ペアは任意の CPU に対して独立してスケジューリングされます。ただし、SYNC フラグが honor である限り、CPU の移行は発生しません。
システムが過負荷にならないようにしてください。過負荷なシステムでは大きなレイテンシが予想されますが、過負荷なシステムのテスト結果から有用な情報は得られません。システムに強いストレスを与えてテストする場合は、-pair
#cpu-1(または -pair #cpu を注意して)使用してください。-pair n と n > #cpu を併用してテストすると、システムが過負荷になり、生成される情報は有用性が損なわれます。
デッドライン値を指定する
広範なユーザー シナリオでのテスト(認定済み製品でレイテンシ テストを実行)の結果、2.5 ミリ秒のデッドラインが必要だとわかりました。より高い要件のある新しいアプリケーション(1 秒あたり 1,000 枚の写真など)では、このデッドライン値は異なります。
詳細な出力を指定する
-v オプションを使用すると、詳細な出力が表示されます。例:
libhwbinder_latency -i 1 -v-------------------------------------------------- service pid: 8674 tid: 8674 cpu: 1 SCHED_OTHER 0-------------------------------------------------- main pid: 8673 tid: 8673 cpu: 1 -------------------------------------------------- client pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0-------------------------------------------------- fifo-caller pid: 8677 tid: 8678 cpu: 0 SCHED_FIFO 99 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 ??? 99-------------------------------------------------- other-caller pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 SCHED_OTHER 0
- サービス スレッドは、
SCHED_OTHER優先度で作成され、CPU:1のpid 8674で実行されています。 - 次に、最初のトランザクションが、
fifo-callerによって開始されます。このトランザクションを処理するために、hwbinder はサーバー(pid: 8674 tid: 8676)の優先度を 99 に上げ、一時的なスケジューリング クラスであるとしてマークを付けます(???と表示)。次に、スケジューラがサーバー プロセスをCPU:0に移動して動作し、クライアントと同じ CPU に同期します。 - 2 番目のトランザクションの呼び出し元の優先度は、
SCHED_OTHERです。サーバーは自身の優先度を下げ、呼び出し元にSCHED_OTHER優先度を与えます。
トレースを使用してデバッグする
-trace オプションを指定して、レイテンシの問題をデバッグできます。これを使用すると、レイテンシ テストは、好ましくないレイテンシが検出された時点でトレースログの記録を停止します。例:
atrace --async_start -b 8000 -c sched idle workq binder_driver sync freqlibhwbinder_latency -deadline_us 50000 -trace -i 50000 -pair 3deadline triggered: halt ∓ stop trace log:/sys/kernel/debug/tracing/trace
レイテンシに影響を与える可能性があるのは、次のコンポーネントです。
- Android のビルドモード: 通常、eng モードは userdebug モードよりも遅くなります。
- フレームワーク: フレームワーク サービスが binder を設定する際の
ioctlの使用方法が影響します。 - binder ドライバ: ドライバが細粒度ロックをサポートしているかを確認してください。パフォーマンスを改善するパッチをすべて適用しているかを確認してください。
- カーネル バージョン: カーネルのリアルタイム対応が進んでいるほど、良い結果が得られます。
- カーネル構成: カーネル構成に
DEBUG_PREEMPTやDEBUG_SPIN_LOCKなどのDEBUG構成がないかを確認してください。 - カーネル スケジューラ: カーネルに、Energy-Aware Scheduler(EAS)スケジューラ、あるいは Heterogeneous Multi-Processing(HMP)スケジューラがあるか確認してください。
cpu-freqドライバ、cpu-idleドライバ、cpu-hotplugなどのカーネル ドライバがスケジューラに影響を与えていないかを確認してください。