
이 페이지에서는 Neural Networks API(NNAPI) 드라이버 구현 방법을 대략적으로 설명합니다. 자세한 내용은 hardware/interfaces/neuralnetworks의 HAL 정의 파일에 있는 문서를 참조하세요.
샘플 드라이버 구현은 frameworks/ml/nn/driver/sample에 있습니다.
Neural Networks API에 관한 자세한 내용은 Neural Networks API를 참고하세요.
Neural Networks HAL
Neural Networks(NN) HAL은 휴대전화나 태블릿 등의 제품에 사용되는 그래픽 처리 장치(GPU) 및 디지털 신호 프로세서(DSP)와 같은 다양한 기기의 추상화를 정의합니다. 이러한 기기의 드라이버는 NN HAL을 준수해야 합니다. 인터페이스는 hardware/interfaces/neuralnetworks에 있는 HAL 정의 파일에 지정되어 있습니다.
프레임워크와 드라이버 간의 일반적인 인터페이스 흐름은 그림 1에 묘사되어 있습니다.
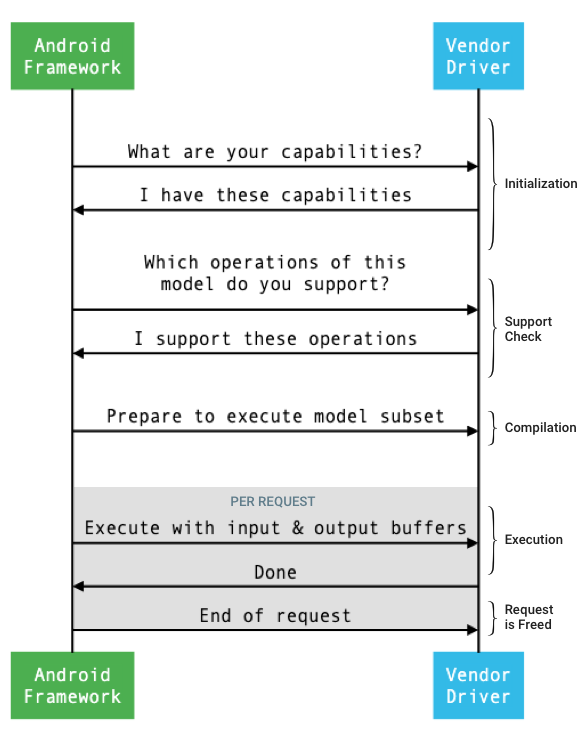
그림 1. Neural Networks 흐름
초기화
초기화 시 프레임워크는 IDevice::getCapabilities_1_3을 사용하여 드라이버 기능을 쿼리합니다.
@1.3::Capabilities 구조체는 모든 데이터 유형을 포함하며 벡터를 사용하여 완화되지 않은 성능을 표현합니다.
여러 가용한 기기에 어떻게 계산을 할당할지 결정할 때, 프레임워크는 이러한 기능을 참고하여 각 드라이버가 얼마나 신속하고 에너지 효율적인 방식으로 실행되는지 확인합니다. 이러한 정보를 제공하려면 드라이버가 참조 워크로드 실행에 따른 표준화된 성능 수치를 제공해야 합니다.
개발자는 드라이버가 IDevice::getCapabilities_1_3에 관한 응답으로 반환하는 값을 파악하려면 NNAPI 벤치마크 앱을 사용하여 관련 데이터 유형의 성능을 측정해야 합니다. MobileNet v1 및 v2, asr_float 및 tts_float 모델은 32비트 부동 소수점 값의 성능을 측정하는 데 권장되며, MobileNet v1 및 v2 양자화 모델은 8비트 양자화 값에 권장됩니다. 자세한 내용은 Android 머신러닝 테스트 모음을 참고하세요.
Android 9 이하에서는 Capabilities 구조체에 부동 소수점과 양자화 텐서의 드라이버 성능 정보만 포함되며 스칼라 데이터 유형은 포함되지 않습니다.
초기화 프로세스의 일환으로 프레임워크는 IDevice::getType, IDevice::getVersionString, IDevice:getSupportedExtensions, IDevice::getNumberOfCacheFilesNeeded를 사용하여 추가 정보를 쿼리할 수 있습니다.
제품의 재부팅 간에 프레임워크는 이 섹션에서 설명된 모든 쿼리가 특정 드라이버와 관련하여 항상 동일한 값을 보고할 것을 기대합니다. 동일한 값을 보고하지 않으면 그 드라이버를 사용하는 앱의 성능 저하니 잘못된 동작이 나타날 수 있습니다.
컴파일
프레임워크는 앱에서 요청을 수신하면 어떤 기기를 사용할지 결정합니다. Android 10에서는 프레임워크에서 선택하는 기기를 앱이 검색 및 지정할 수 있습니다. 자세한 내용은 기기 검색 및 할당을 참고하세요.
모델 컴파일 시 프레임워크는 IDevice::getSupportedOperations_1_3을 호출하여 그 모델을 각 후보 드라이버에 전송합니다.
각 드라이버는 모델의 어떤 연산이 지원되는지 나타내는 부울 배열을 반환합니다. 드라이버는 여러 이유로 주어진 연산을 지원할 수 없다고 판단할 수 있습니다. 예:
- 드라이버가 데이터 유형을 지원하지 않습니다.
- 드라이버가 특정 입력 매개변수가 있는 연산만 지원합니다. 예를 들어 드라이버가 3x3 및 5x5는 지원하지만 7x7 컨볼루션 연산은 지원하지 않을 수 있습니다.
- 드라이버가 메모리 제약으로 인해 대형 그래프나 입력을 처리하지 못합니다.
컴파일 도중에는 OperandLifeTime에 설명된 것처럼 모델의 입력, 출력 및 내부 피연산자에 알 수 없는 측정기준이나 순위가 있을 수 있습니다. 자세한 내용은 출력 셰이프를 참고하세요.
프레임워크는 선택한 각 드라이버에 IDevice::prepareModel_1_3을 호출하여 모델의 하위 집합을 실행할 준비를 하도록 지시합니다.
그러면 각 드라이버에서 하위 집합을 컴파일합니다. 예를 들어 드라이버에서 코드를 생성하거나 가중치를 재정렬한 사본을 생성할 수 있습니다. 모델 컴파일과 요청 실행 간에 상당한 시간차가 있을 수 있으므로 컴파일 도중에는 큰 기기 메모리와 같은 리소스를 할당하면 안 됩니다.
성공 시 드라이버는 @1.3::IPreparedModel 핸들을 반환합니다. 드라이버가 모델의 하위 집합을 준비할 때 실패 코드를 반환하면 프레임워크는 CPU에서 전체 모델을 실행합니다.
앱이 시작될 때 컴파일에 소요되는 시간을 줄이기 위해 드라이버는 컴파일 아티팩트를 캐시할 수 있습니다. 자세한 내용은 컴파일 캐싱을 참고하세요.
실행
앱이 프레임워크에 요청을 실행하라고 하면 프레임워크는 준비된 모델에 동기식 실행을 하기 위해 기본적으로 IPreparedModel::executeSynchronously_1_3 HAL 메서드를 호출합니다.
요청은 execute_1_3 메서드 또는 executeFenced 메서드를 사용하여 비동기식으로 실행하거나(분리(Fenced) 실행 참고) 버스트 실행을 사용하여 실행할 수도 있습니다.
동기 실행 호출은 비동기 호출에 비해 성능을 개선하고 스레딩 오버헤드를 줄여주는데, 이는 실행이 완료된 이후에만 컨트롤이 앱 프로세스로 반환되기 때문입니다. 즉, 드라이버에 별도의 메커니즘이 없어도 앱 프로세스에 실행이 완료되었음을 알릴 수 있습니다.
비동기 execute_1_3 메서드를 사용할 경우 실행이 시작되면 컨트롤이 앱 프로세스로 반환되고, 실행이 완료되면 드라이버가 @1.3::IExecutionCallback을 사용하여 프레임워크에 내용을 알려야 합니다.
실행 메서드로 전달된 Request 매개변수는 실행에 사용된 입력 및 출력 피연산자를 나열합니다. 피연산자 데이터가 저장되는 메모리는 가장 느린 항목을 반복하는 첫 번째 측정기준에 행 위주의 순서를 사용해야 하며 어떠한 행 끝에도 패딩이 없어야 합니다. 피연산자 유형에 관한 자세한 내용은 피연산자를 참고하세요.
NN HAL 1.2 이상의 드라이버의 경우 요청이 완료되면 오류 상태, 출력 셰이프 및 타이밍 정보가 프레임워크로 반환됩니다. 실행 도중에는 모델의 출력 또는 내부 피연산자에 1개 이상의 알 수 없는 측정기준이나 순위가 포함될 수 있습니다. 1개 이상의 출력 피연산자에 알 수 없는 측정기준이나 순위가 있을 경우 드라이버는 동적으로 크기가 조정된 출력 정보를 반환해야 합니다.
NN HAL 1.1 이하를 사용하는 드라이버의 경우 요청이 완료되면 오류 상태만 반환됩니다. 입력 및 출력 피연산자의 측정기준이 완전하게 지정되어야만 실행이 정상적으로 완료됩니다. 내부 피연산자에는 1개 이상의 알 수 없는 측정기준이 포함될 수 있지만 지정된 순위가 있어야 합니다.
여러 드라이버를 포괄하는 사용자 요청의 경우 프레임워크에서 중간 메모리를 남겨 두고 각 드라이버에 대한 호출 순서를 지정해야 합니다.
동일한 @1.3::IPreparedModel에서 여러 개의 요청을 동시에 시작할 수 있습니다.
드라이버는 요청을 동시에 실행하거나 순서대로 실행할 수 있습니다.
프레임워크는 두 개 이상의 준비된 모델을 유지하도록 드라이버에 요청할 수 있습니다. 예를 들어 모델 m1을 준비하고 m2를 준비하고 m1에서 요청 r1을 실행하고 m2에서 r2를 실행하고 m1에서 r3를 실행하고 m2에서 r4를 실행한 다음, m1을 해제(정리에 설명되어 있음)하고 m2를 해제할 수 있습니다.
첫 번째 실행이 둔화되어 사용자 환경 저하로 이어지지 않도록 하려면(예: 첫 번째 프레임의 버벅거림) 드라이버가 대부분의 초기화를 컴파일 단계에서 수행해야 합니다. 최초 실행의 초기화는 일찍 수행할 경우 시스템 상태에 부정적인 영향을 미치는 작업(예: 큰 임시 버퍼를 예약하거나 기기의 클록 속도를 높이는 작업)으로 제한해야 합니다. 제한된 수의 동시 실행 모델만 준비할 수 있는 드라이버는 최초 실행 시 초기화를 수행해야 할 수도 있습니다.
Android 10 이상에서는 준비된 동일한 모델로 여러 번의 실행이 빠르게 연속으로 진행되는 경우 클라이언트는 실행 버스트 객체를 사용하여 앱과 드라이버 프로세스 간에 통신할 수 있습니다. 자세한 내용은 버스트 실행 및 FMQ(Fast Message Queues)를 참고하세요.
드라이버는 임시 버퍼를 유지하거나 클록 속도를 높여 연속으로 여러 번 진행되는 실행 성능을 개선할 수 있습니다. 일정 기간 이후에 새 요청이 생성되지 않을 경우 watchdog 스레드를 생성하여 리소스를 해제하는 것이 좋습니다.
출력 셰이프
한 개 이상의 출력 피연산자에 지정된 측정기준의 일부가 없는 요청의 경우 드라이버는 실행 이후의 각 출력 피연산자의 측정기준 정보를 포함하는 출력 셰이프 목록을 제공해야 합니다. 측정기준에 관한 자세한 내용은 OutputShape을 참고하세요.
크기 미달의 출력 버퍼로 인해 실행이 실패하는 경우 드라이버는 출력 셰이프 목록에서 어떤 출력 피연산자의 버퍼 크기가 충분하지 않은지 표시해야 하며, 알 수 없는 측정기준에 0을 사용하여 최대한 많은 측정기준 정보를 보고해야 합니다.
시기
Android 10에서는 앱에서 컴파일 프로세스 도중에 사용하려는 단일 기기를 지정한 경우 실행 시간을 요청할 수 있습니다. 자세한 내용은 MeasureTiming 및 기기 검색 및 할당을 참고하세요.
이 경우 NN HAL 1.2 드라이버는 요청을 실행할 때 실행 기간을 측정하거나, UINT64_MAX를 보고하여 그 기간을 사용할 수 없음을 나타내야 합니다. 드라이버는 실행 기간 측정으로 인한 성능 저하를 최소화해야 합니다.
드라이버는 Timing 구조체에 다음과 같은 마이크로초 단위의 기간을 보고합니다.
- 기기 실행 시간: 호스트 프로세서에서 실행되는 드라이버의 실행 시간을 포함하지 않습니다.
- 드라이버 실행 시간: 기기 실행 시간을 포함합니다.
이러한 기간에는 실행이 정지된 시간이 포함되어야 합니다(예: 실행이 다른 작업에 의해 선점되었거나 리소스를 사용할 수 있을 때까지 대기 중인 경우).
드라이버에 실행 기간 측정 요청이 없었거나 실행 오류가 발생한 경우 드라이버는 기간을 UINT64_MAX로 보고해야 합니다. 실행 기간 측정 요청을 받은 경우에도 드라이버는 그 대신 기기 시간이나 드라이버 시간 또는 둘 다에 대해 UINT64_MAX를 보고할 수 있습니다. 드라이버가 두 기간을 UINT64_MAX 외의 값으로 보고하면 드라이버의 실행 시간이 기기 시간과 동일하거나 이를 초과해야 합니다.
분리(Fenced) 실행
Android 11에서는 NNAPI를 통해 실행 시 sync_fence 핸들 목록을 기다릴 수 있으며 실행 완료 시 신호를 받는 sync_fence 객체를 선택적으로 반환할 수 있습니다. 이렇게 하면 작은 시퀀스 모델 및 스트리밍 사용 사례의 오버헤드가 줄어듭니다. 또한 분리(Fenced) 실행을 통해 sync_fence를 신호로 보내거나 기다릴 수 있는 다른 구성요소와의 더 효율적인 상호운용성을 구현할 수 있습니다. sync_fence에 관한 자세한 내용은 동기화 프레임워크를 참고하세요.
분리 실행에서 프레임워크는 IPreparedModel::executeFenced 메서드를 호출하여, 대기할 동기화 펜스로 구성된 벡터가 있는 준비된 모델에서 비동기식 분리 실행을 시작합니다. 호출이 반환되기 전에 비동기 작업이 완료되면 sync_fence에 빈 핸들이 반환될 수 있습니다. 프레임워크에 오류 상태와 기간 정보를 쿼리하도록 허용하려면 IFencedExecutionCallback 객체도 반환되어야 합니다.
실행이 완료되면 실행 기간을 측정하는 다음 두 개의 타이밍 값을 IFencedExecutionCallback::getExecutionInfo를 통해 쿼리할 수 있습니다.
timingLaunched:executeFenced가 호출된 시점부터syncFence가 반환되었다는 신호를executeFenced가 보낸 시점까지의 기간입니다.timingFenced: 실행에서 대기 중인 모든 대상 동기화 펜스에 신호를 보낸 시점부터syncFence가 반환되었다는 신호를executeFenced가 보낸 시점까지의 기간입니다.
제어 흐름
Android 11 이상을 실행하는 기기를 위해 NNAPI에는 두 개의 제어 흐름 연산(IF 및 WHILE)이 포함되어 있습니다. 이 두 연산에서는 다른 모델을 인수로 취해 조건부로 실행(IF)하거나 반복적으로 실행(WHILE)합니다. 이를 구현 방법을 자세히 알아보려면 제어 흐름을 참고하세요.
서비스 품질
Android 11에서 NNAPI는 앱이 모델의 상대적 우선순위, 모델 준비에 예상되는 최대 시간 및 실행 완료에 예상되는 최대 시간을 표시하도록 허용함으로써 향상된 서비스 품질(QoS)을 제공합니다. 자세한 내용은 서비스 품질을 참고하세요.
정리
앱에서 준비된 모델의 사용을 마치면 프레임워크는 참조를 @1.3::IPreparedModel 객체에 방출합니다. IPreparedModel 객체가 더 이상 참조되지 않으면 객체는 생성된 드라이버 서비스에서 자동으로 삭제됩니다. 이 시점에서는 소멸자의 드라이버 구현에서 모델과 관련된 리소스를 복원할 수 있습니다. 드라이버 서비스에서 클라이언트에 더 이상 필요하지 않은 IPreparedModel 객체를 자동으로 삭제하려면 드라이버 서비스는 IPreparedeModel 객체가 IPreparedModelCallback::notify_1_3을 통해 반환되면 그 이후부터 IPreparedModel 객체에 관한 참조를 보유해서는 안 됩니다.
CPU 사용량
드라이버는 CPU를 사용하여 계산을 설정해야 합니다. 드라이버가 CPU를 사용하여 그래프 계산을 실행하면 안 되는 이유는 프레임워크의 정상적인 작업 할당 기능을 방해하기 때문입니다. 드라이버는 처리할 수 없는 부분을 프레임워크에 보고하고 프레임워크에서 나머지를 처리하도록 해야 합니다.
프레임워크는 공급업체에서 정의한 연산을 제외한 모든 NNAPI 연산의 CPU 구현을 제공해야 합니다. 자세한 내용은 공급업체 확장 프로그램을 참고하세요.
Android 10에 도입된 연산(API 수준 29)에는 CTS 및 VTS 테스트의 정확성을 확인하기 위한 참조용 CPU 구현만 포함할 수 있습니다. 모바일 머신러닝 프레임워크에 포함된 최적화된 구현이 NNAPI CPU 구현보다 선호됩니다.
유틸리티 함수
NNAPI 코드베이스에는 드라이버 서비스로 사용 가능한 유틸리티 함수가 포함됩니다.
frameworks/ml/nn/common/include/Utils.h 파일에는 로깅 및 여러 NN HAL 버전 간의 변환에 사용되는 함수를 비롯한 다양한 유틸리티 함수가 포함되어 있습니다.
VLogging:
VLOG는 적절한 태그가debug.nn.vlog속성에 설정된 경우에만 메시지를 로깅하는 Android의LOG관련 래퍼 매크로입니다.VLOG를 호출하기 전에는 반드시initVLogMask()를 호출해야 합니다.VLOG_IS_ON매크로를 사용하면VLOG가 현재 사용 설정되어 있는지 확인하여 불필요하고 복잡한 로깅 코드를 생략할 수 있습니다. 속성 값은 다음 중 하나여야 합니다.- 로깅이 필요 없음을 나타내는 빈 문자열
- 모든 로깅을 수행해야 함을 나타내는 토큰
1또는all - 어떤 로깅을 수행해야 하는지 나타내는 공백, 쉼표 또는 콜론으로 구분된 태그 목록. 태그는
compilation,cpuexe,driver,execution,manager및model입니다.
compliantWithV1_*: 정보를 잃지 않고 NN HAL 객체를 다른 HAL 버전의 동일한 유형으로 변환할 수 있는 경우true를 반환합니다. 예를 들어V1_2::Model에compliantWithV1_0을 호출하면 모델에 NN HAL 1.1 또는 NN HAL 1.2에 도입된 연산 유형이 포함된 경우false를 반환합니다.convertToV1_*: NN HAL 객체의 버전을 다른 버전으로 변환합니다. 변환으로 인해 정보가 손실되면 경고가 로깅됩니다(즉, 유형의 새 버전이 값을 온전히 나타내지 못하는 경우).기능:
nonExtensionOperandPerformance및update함수는Capabilities::operandPerformance필드를 빌드하는 데 도움이 됩니다.유형 속성 쿼리:
isExtensionOperandType,isExtensionOperationType,nonExtensionSizeOfData,nonExtensionOperandSizeOfData,nonExtensionOperandTypeIsScalar,tensorHasUnspecifiedDimensions.
frameworks/ml/nn/common/include/ValidateHal.h 파일에는 NN HAL 객체가 HAL 버전의 사양에 따라 유효한지 확인하기 위한 유틸리티 함수가 포함되어 있습니다.
validate*: NN HAL 객체가 HAL 버전의 사양에 따라 유효한 경우true를 반환합니다. OEM 유형 및 확장 프로그램 유형은 확인되지 않습니다. 예를 들어validateModel은 모델에 존재하지 않는 피연산자 색인을 참조하는 연산이나 관련 HAL 버전에서 지원되지 않는 연산이 포함된 경우false를 반환합니다.
frameworks/ml/nn/common/include/Tracing.h 파일에는 Neural Networks 코드에 systracing 정보를 추가하는 과정을 간소화하기 위한 매크로가 포함되어 있습니다.
예를 보려면 샘플 드라이버의 NNTRACE_* 매크로 호출을 참고하세요.
frameworks/ml/nn/common/include/GraphDump.h 파일에는 디버깅 목적으로 그래픽 형식의 Model 콘텐츠를 덤프하는 유틸리티 함수가 포함되어 있습니다.
graphDump: Graphviz(.dot) 형식 모델의 표현을 지정된 스트림(제공된 경우) 또는 logcat(스트림이 제공되지 않은 경우)에 작성합니다.
유효성 검사
NNAPI의 구현을 테스트하려면 Android 프레임워크에 포함된 VTS 및 CTS 테스트를 사용하세요. VTS는 프레임워크를 사용하지 않고 드라이버를 직접 실행하는 반면 CTS는 프레임워크를 통해 간접적으로 드라이버를 실행합니다. 이는 각 API 메서드를 테스트하여 드라이버에 의해 지원되는 모든 연산이 정상적으로 작동하는지 확인하고 정밀도 요구사항을 충족하는 결과를 제공합니다.
NNAPI 관련 CTS 및 VTS의 정밀도 요구사항은 다음과 같습니다.
부동 소수점: abs(예상값 - 실제값) <= atol + rtol * abs(예상값), 설명:
- fp32의 경우, atol = 1e-5f, rtol = 5.0f * 1.1920928955078125e-7
- fp16의 경우, atol = rtol = 5.0f * 0.0009765625f
양자화: off-by-one(off-by-three인
mobilenet_quantized는 예외)부울: 정확히 일치
CTS가 NNAPI를 테스트하는 한 방법은 NNAPI 참조 구현을 사용하여 각 드라이버의 실행 결과를 테스트하고 비교하는 데 사용되는 고정된 의사 난수 그래프를 생성하는 것입니다. NN HAL 1.2 이상을 사용하는 드라이버의 경우 결과가 정밀도 기준을 충족하지 않으면 CTS는 오류를 보고하고 디버깅을 위해 실패한 모델의 사양 파일을 /data/local/tmp에 덤프합니다.
정밀도 기준에 관한 자세한 내용은 TestRandomGraph.cpp 및 TestHarness.h를 참고하세요.
퍼징 테스트
퍼징 테스트의 목적은 예기치 않은 입력과 같은 요인으로 인해 테스트 중인 코드에 비정상 종료, 어설션, 메모리 위반 또는 정의되지 않은 일반적인 동작이 있는지 찾는 것입니다. NNAPI 퍼징 테스트의 경우 Android는 libFuzzer에 기반한 테스트를 사용합니다. 이러한 테스트는 이전 테스트 사례의 라인 범위를 사용해 새로운 임의 입력을 생성하기 때문에 퍼징에 효율적입니다. 예를 들어 libFuzzer는 새로운 코드 라인에서 실행되는 테스트 사례를 선호합니다. 이 경우 테스트에서 문제가 있는 코드를 찾는 데 걸리는 시간이 크게 줄어듭니다.
퍼징 테스트를 실행하여 드라이버 구현을 확인하려면 AOSP에 있는 libneuralnetworks_driver_fuzzer 테스트 유틸리티에서 frameworks/ml/nn/runtime/test/android_fuzzing/DriverFuzzTest.cpp를 수정하여 드라이버 코드를 포함합니다. NNAPI 퍼징 테스트에 관한 자세한 내용은 frameworks/ml/nn/runtime/test/android_fuzzing/README.md를 참고하세요.
보안
앱 프로세스는 드라이버의 프로세스와 직접적으로 통신합니다. 따라서 드라이버는 수신한 호출의 인수를 검증해야 합니다. 이러한 검증은 VTS에 의해 확인됩니다. 검증 코드는 frameworks/ml/nn/common/include/ValidateHal.h에 있습니다.
드라이버는 같은 기기 사용 시 앱이 다른 앱을 방해하지 않는지도 확인해야 합니다.
Android 머신러닝 테스트 모음
Android 머신러닝 테스트 도구 모음(MLTS)은 공급업체 기기에서 실제 모델의 정확성을 확인하기 위해 CTS 및 VTS에 포함되어 있는 NNAPI 벤치마크입니다. 벤치마크는 지연 시간과 정확성을 평가하고 드라이버의 결과를 동일한 모델 및 데이터 세트에 대해 CPU에서 실행되는 TF Lite를 사용한 결과와 비교합니다. 그러면 드라이버의 정확성이 CPU 참조 구현보다 떨어지지 않도록 할 수 있습니다.
Android 플랫폼 개발자 역시 MLTS를 사용하여 드라이버의 지연 시간과 정확성을 평가합니다.
NNAPI 벤치마크는 AOSP의 두 프로젝트에서 찾을 수 있습니다.
platform/test/mlts/benchmark(벤치마크 앱)platform/test/mlts/models(모델 및 데이터 세트)
모델 및 데이터 세트
NNAPI 벤치마크는 다음과 같은 모델과 데이터 세트를 사용합니다.
- MobileNetV1 float 및 u8은 다른 크기로 양자화되며 일부의 Open Images Dataset v4 이미지(1,500개)를 기준으로 실행됩니다.
- MobileNetV2 float 및 u8은 다른 크기로 양자화되며 일부의 Open Images Dataset v4(이미지 1,500개)를 기준으로 실행됩니다.
- TTS(텍스트 음성 변환)와 관련된 LSTM(Long short-term memory) 기반 어쿠스틱 모델은 일부의 CMU Arctic 집합을 기준으로 실행됩니다.
- 자동 음성 인식과 관련된 LSTM 기반 어쿠스틱 모델은 일부의 LibriSpeech 데이터 세트를 기준으로 실행됩니다.
자세한 내용은 platform/test/mlts/models를 참고하세요.
스트레스 테스트
Android 머신러닝 테스트 모음에는 사용량이 많은 상황이나 비정상적인 클라이언트 동작 상황에서 드라이버의 탄력성을 검증하기 위한 일련의 장애 테스트가 포함되어 있습니다.
모든 장애 테스트에서는 다음과 같은 기능이 제공됩니다.
- 중단 감지: 테스트 중에 NNAPI 클라이언트가 중단되면
HANG라는 실패 원인으로 테스트가 실패하고 테스트 모음이 다음 테스트로 넘어갑니다. - NNAPI 클라이언트 장애 감지: 테스트가 클라이언트 장애를 유지하다가
CRASH라는 실패 원인으로 실패합니다. - 드라이버 장애 감지: 테스트는 NNAPI 호출 시 오류를 야기하는 드라이버 장애를 감지할 수 있습니다. 참고로, 드라이버 프로세스 장애 중에는 NNAPI 오류를 야기하거나 테스트 실패를 유도하지 않는 장애도 있습니다. 이러한 유형의 오류도 다루려면 시스템 로그에서
tail명령어를 실행하여 드라이버 관련 오류나 장애를 처리하는 것이 좋습니다. - 사용 가능한 모든 액셀러레이터 타겟팅: 사용 가능한 모든 드라이버를 기준으로 테스트가 실행됩니다.
모든 장애 테스트에서는 다음과 같은 네 가지 결과가 있을 수 있습니다.
SUCCESS: 오류 없이 실행이 완료됨.FAILURE: 실행에 실패함. 일반적으로 모델을 테스트할 때 오류가 발생한 것이 원인입니다. 드라이버가 모델을 컴파일하거나 실행하지 못했음을 나타냅니다.HANG: 테스트 프로세스가 응답하지 않음.CRASH: 테스트 프로세스가 비정상 종료됨.
스트레스 테스트 및 장애 테스트의 전체 목록에 관한 자세한 내용은 platform/test/mlts/benchmark/README.txt를 참고하세요.
MLTS 사용
MLTS 사용 방법:
- 대상 기기를 워크스테이션에 연결하고 adb를 통해 연결 가능한지 확인합니다.
2개 이상의 기기가 연결된 경우 대상 기기
ANDROID_SERIAL환경 변수를 내보냅니다. Android 최상위 소스 디렉터리로
cd합니다.source build/envsetup.sh lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available. ./test/mlts/benchmark/build_and_run_benchmark.sh벤치마크 실행이 끝나면 결과가 HTML 페이지로 표시되고
xdg-open으로 전달됩니다.
자세한 내용은 platform/test/mlts/benchmark/README.txt를 참고하세요.
Neural Networks HAL 버전
이 섹션에서는 Android 및 Neural Networks HAL 버전에 도입된 변경사항에 관해 설명합니다.
Android 11
Android 11에는 다음과 같은 눈에 띄는 변경사항이 포함된 NN HAL 1.3이 도입되었습니다.
- NNAPI에서 부호 있는 8비트 양자화를 지원합니다.
TENSOR_QUANT8_ASYMM_SIGNED피연산자 유형이 추가되었습니다. NN HAL 1.3을 사용하는 드라이버 중 부호 없는 양자화 연산을 지원하는 드라이버는 이러한 연산의 부호 있는 버전도 지원해야 합니다. 대부분 양자화 연산의 부호 있는 버전과 부호 없는 버전을 실행할 경우 드라이버는 최대 128 오프셋의 동일한 결과를 생성해야 합니다. 단,CAST,HASHTABLE_LOOKUP,LSH_PROJECTION,PAD_V2,QUANTIZED_16BIT_LSTM의 5가지는 이 요구사항에서 제외됩니다.QUANTIZED_16BIT_LSTM연산은 부호 있는 피연산자를 지원하지 않고, 나머지 4개 연산은 부호 있는 양자화를 지원하기는 하지만 결과가 반드시 동일할 필요는 없습니다. - 분리 실행을 지원합니다. 분리 실행에서 프레임워크는
IPreparedModel::executeFenced메서드를 호출하여, 준비된 모델에서 대기 중인 대상 동기화 펜스로 구성된 벡터로 비동기식 분리 실행을 시작합니다. 자세한 내용은 분리(Fenced) 실행을 참고하세요. - 제어 흐름이 지원됩니다.
IF및WHILE연산이 추가되었습니다. 이 두 연산에서는 다른 모델을 인수로 취해 조건부로 실행(IF)하거나 반복적으로 실행합니다(WHILE). 자세한 내용은 제어 흐름을 참고하세요. - 앱이 모델의 상대적 우선순위, 모델 준비에 예상되는 최대 시간 및 실행 완료에 예상되는 최대 시간을 표시할 수 있기 때문에 서비스 품질(QoS)이 향상되었습니다. 자세한 내용은 서비스 품질을 참고하세요.
- 드라이버 관리 버퍼의 할당자 인터페이스를 제공하는 메모리 도메인을 지원합니다. 이를 통해 실행 간에 기기 네이티브 메모리를 전달할 수 있으며, 동일한 드라이버에서 연속 실행 간의 불필요한 데이터 복사 및 변환을 억제할 수 있습니다. 자세한 내용은 메모리 도메인을 참고하세요.
Android 10
Android 10에는 다음과 같은 눈에 띄는 변경사항이 포함된 NN HAL 1.2가 도입되었습니다.
Capabilities구조체는 스칼라 데이터 유형을 비롯한 모든 데이터 유형을 포함하며, 이름이 지정된 필드 대신 벡터를 사용하여 완화되지 않은 성능을 표시합니다.getVersionString및getType메서드를 사용하면 프레임워크에서 기기 유형(DeviceType) 및 버전 정보를 가져올 수 있습니다. 기기 검색 및 할당을 참고하세요.- 동기식 실행을 위해서는 기본적으로
executeSynchronously메서드가 호출됩니다.execute_1_2메서드는 프레임워크에 비동기식 실행을 지시합니다. 실행을 참고하세요. executeSynchronously,execute_1_2및 버스트 실행과 관련된MeasureTiming매개변수는 드라이버의 실행 기간 측정 여부를 지정합니다. 결과는Timing구조체에 보고됩니다. 시기를 참고하세요.- 1개 이상의 출력 피연산자에 알 수 없는 측정기준이나 순위가 있는 실행이 지원됩니다. 출력 셰이프를 참고하세요.
- 공급업체에서 정의한 연산 및 데이터 유형이 모여있는 공급업체 확장 프로그램이 지원됩니다. 드라이버는
IDevice::getSupportedExtensions메서드를 통해 지원되는 확장 프로그램을 보고합니다. 공급업체 확장 프로그램을 참고하세요. - 앱과 드라이버 프로세스 간의 통신에 FMQ(fast message queue)를 사용하여 버스트 실행 집합을 제어하고 지연 시간을 줄이는 버스트 객체 기능이 있습니다. 버스트 실행 및 FMQ(Fast Message Queues)를 참고하세요.
- 드라이버가 데이터를 복사하지 않고도 실행할 수 있도록 AHardwareBuffer를 지원합니다. AHardwareBuffer를 참고하세요.
- 앱 시작 시 컴파일에 사용되는 시간을 줄이기 위해 컴파일 아티팩트의 캐싱에 관한 지원을 개선했습니다. 컴파일 캐싱을 참고하세요.
Android 10에는 다음과 같은 피연산자 유형과 연산이 도입되었습니다.
-
ANEURALNETWORKS_BOOLANEURALNETWORKS_FLOAT16ANEURALNETWORKS_TENSOR_BOOL8ANEURALNETWORKS_TENSOR_FLOAT16ANEURALNETWORKS_TENSOR_QUANT16_ASYMMANEURALNETWORKS_TENSOR_QUANT16_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL
-
ANEURALNETWORKS_ABSANEURALNETWORKS_ARGMAXANEURALNETWORKS_ARGMINANEURALNETWORKS_AXIS_ALIGNED_BBOX_TRANSFORMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_RNNANEURALNETWORKS_BOX_WITH_NMS_LIMITANEURALNETWORKS_CASTANEURALNETWORKS_CHANNEL_SHUFFLEANEURALNETWORKS_DETECTION_POSTPROCESSINGANEURALNETWORKS_EQUALANEURALNETWORKS_EXPANEURALNETWORKS_EXPAND_DIMSANEURALNETWORKS_GATHERANEURALNETWORKS_GENERATE_PROPOSALSANEURALNETWORKS_GREATERANEURALNETWORKS_GREATER_EQUALANEURALNETWORKS_GROUPED_CONV_2DANEURALNETWORKS_HEATMAP_MAX_KEYPOINTANEURALNETWORKS_INSTANCE_NORMALIZATIONANEURALNETWORKS_LESSANEURALNETWORKS_LESS_EQUALANEURALNETWORKS_LOGANEURALNETWORKS_LOGICAL_ANDANEURALNETWORKS_LOGICAL_NOTANEURALNETWORKS_LOGICAL_ORANEURALNETWORKS_LOG_SOFTMAXANEURALNETWORKS_MAXIMUMANEURALNETWORKS_MINIMUMANEURALNETWORKS_NEGANEURALNETWORKS_NOT_EQUALANEURALNETWORKS_PAD_V2ANEURALNETWORKS_POWANEURALNETWORKS_PRELUANEURALNETWORKS_QUANTIZEANEURALNETWORKS_QUANTIZED_16BIT_LSTMANEURALNETWORKS_RANDOM_MULTINOMIALANEURALNETWORKS_REDUCE_ALLANEURALNETWORKS_REDUCE_ANYANEURALNETWORKS_REDUCE_MAXANEURALNETWORKS_REDUCE_MINANEURALNETWORKS_REDUCE_PRODANEURALNETWORKS_REDUCE_SUMANEURALNETWORKS_RESIZE_NEAREST_NEIGHBORANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_ROI_POOLINGANEURALNETWORKS_RSQRTANEURALNETWORKS_SELECTANEURALNETWORKS_SINANEURALNETWORKS_SLICEANEURALNETWORKS_SPLITANEURALNETWORKS_SQRTANEURALNETWORKS_TILEANEURALNETWORKS_TOPK_V2ANEURALNETWORKS_TRANSPOSE_CONV_2DANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_RNN
Android 10에는 여러 기존 연산의 업데이트가 도입되었습니다. 업데이트는 주로 다음과 관련이 있습니다.
- NCHW 메모리 레이아웃 지원
- softmax 및 정규화 연산에서 4 이외의 다른 순위를 갖는 텐서 지원
- 확장된 컨볼루션 지원
ANEURALNETWORKS_CONCATENATION의 혼합 양자화가 포함된 입력 지원
아래 목록은 Android 10에서 수정된 연산을 보여줍니다. 변경사항에 관한 자세한 내용은 NNAPI 참조 문서의 OperationCode를 참고하세요.
ANEURALNETWORKS_ADDANEURALNETWORKS_AVERAGE_POOL_2DANEURALNETWORKS_BATCH_TO_SPACE_NDANEURALNETWORKS_CONCATENATIONANEURALNETWORKS_CONV_2DANEURALNETWORKS_DEPTHWISE_CONV_2DANEURALNETWORKS_DEPTH_TO_SPACEANEURALNETWORKS_DEQUANTIZEANEURALNETWORKS_DIVANEURALNETWORKS_FLOORANEURALNETWORKS_FULLY_CONNECTEDANEURALNETWORKS_L2_NORMALIZATIONANEURALNETWORKS_L2_POOL_2DANEURALNETWORKS_LOCAL_RESPONSE_NORMALIZATIONANEURALNETWORKS_LOGISTICANEURALNETWORKS_LSH_PROJECTIONANEURALNETWORKS_LSTMANEURALNETWORKS_MAX_POOL_2DANEURALNETWORKS_MEANANEURALNETWORKS_MULANEURALNETWORKS_PADANEURALNETWORKS_RELUANEURALNETWORKS_RELU1ANEURALNETWORKS_RELU6ANEURALNETWORKS_RESHAPEANEURALNETWORKS_RESIZE_BILINEARANEURALNETWORKS_RNNANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_SOFTMAXANEURALNETWORKS_SPACE_TO_BATCH_NDANEURALNETWORKS_SPACE_TO_DEPTHANEURALNETWORKS_SQUEEZEANEURALNETWORKS_STRIDED_SLICEANEURALNETWORKS_SUBANEURALNETWORKS_SVDFANEURALNETWORKS_TANHANEURALNETWORKS_TRANSPOSE
Android 9
Android 9에 도입된 NN HAL 1.1에는 다음과 같은 눈에 띄는 변경사항이 포함되어 있습니다.
IDevice::prepareModel_1_1에는ExecutionPreference매개변수가 포함되어 있습니다. 드라이버가 앱이 배터리 보존을 선호하거나 모델이 빠른 연속적 호출로 실행된다는 점을 인지한 상태에서 이 매개변수를 사용하여 준비를 조정할 수 있습니다.BATCH_TO_SPACE_ND,DIV,MEAN,PAD,SPACE_TO_BATCH_ND,SQUEEZE,STRIDED_SLICE,SUB,TRANSPOSE등 9개의 연산이 새로 추가되었습니다.- 앱에서
Model.relaxComputationFloat32toFloat16을true로 설정하여, 16비트 부동 범위 또는 정밀도를 사용하는 32비트 부동 계산을 실행할 수 있음을 명시할 수 있습니다.Capabilities구조체에는 드라이버가 완화된 성능을 프레임워크에 보고할 수 있는 추가 필드relaxedFloat32toFloat16Performance가 있습니다.
Android 8.1
초기 Neural Networks HAL(1.0)은 Android 8.1에서 출시되었습니다. 자세한 내용은 /neuralnetworks/1.0/를 참고하세요.