
Binder のスレッド モデルは、呼び出しがリモート プロセスに対するものであっても、ローカル関数呼び出しを容易にするように設計されています。具体的には、ノードをホストするプロセスには、そのプロセスでホストされているノードへのトランザクションを処理するための 1 つ以上のバインダー スレッドのプールが必要です。
同期トランザクションと非同期トランザクション
Binder は、同期トランザクションと非同期トランザクションをサポートしています。以降のセクションでは、各トランザクション タイプがどのように実行されるかについて説明します。
同期トランザクション
同期トランザクションは、ノードで実行され、そのトランザクションの返信が呼び出し元によって受信されるまでブロックされます。次の図は、同期トランザクションの実行方法を示しています。
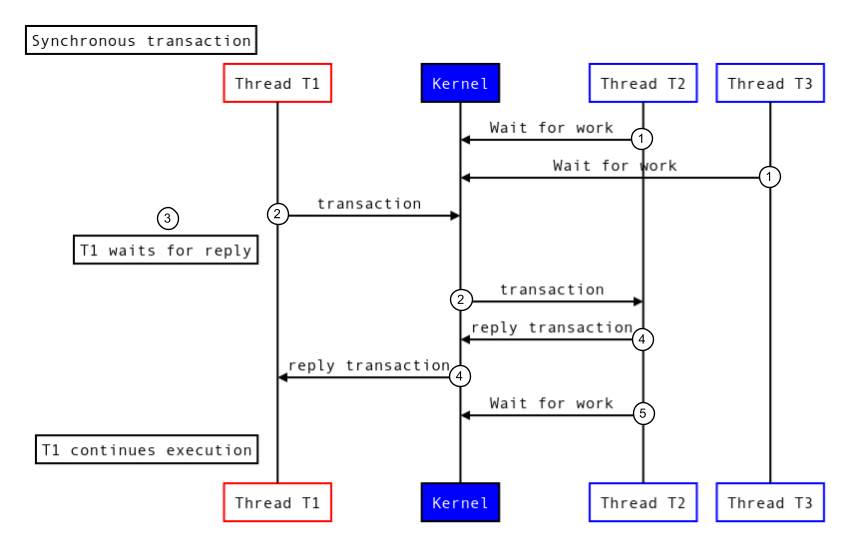
図 1.同期トランザクション。
同期トランザクションを実行するために、Binder は次の処理を行います。
- ターゲット スレッドプールのスレッド(T2 と T3)は、カーネル ドライバを呼び出して、着信した作業を待機します。
- カーネルは新しいトランザクションを受信し、ターゲット プロセスのスレッド(T2)を起動してトランザクションを処理します。
- 呼び出しスレッド(T1)はブロックされ、返信を待機します。
- ターゲット プロセスはトランザクションを実行し、返信を返します。
- ターゲット プロセスのスレッド(T2)は、カーネル ドライバを呼び出して新しい作業を待機します。
非同期トランザクション
非同期トランザクションは完了までブロックされません。トランザクションがカーネルに渡されるとすぐに、呼び出しスレッドのブロックが解除されます。次の図は、非同期トランザクションの実行方法を示しています。
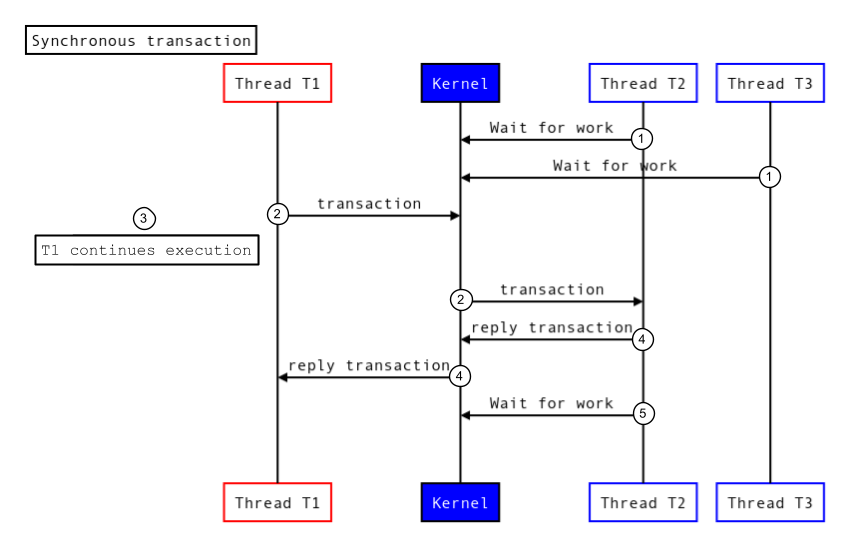
図 2.非同期トランザクション。
- ターゲット スレッドプールのスレッド(T2 と T3)は、カーネル ドライバを呼び出して、着信した作業を待機します。
- カーネルは新しいトランザクションを受信し、ターゲット プロセスのスレッド(T2)を起動してトランザクションを処理します。
- 呼び出しスレッド(T1)は実行を続行します。
- ターゲット プロセスはトランザクションを実行し、返信を返します。
- ターゲット プロセスのスレッド(T2)は、カーネル ドライバを呼び出して新しい作業を待機します。
同期関数または非同期関数を識別する
AIDL ファイルで oneway とマークされた関数は非同期です。例:
oneway void someCall();
関数が oneway とマークされていない場合、関数が void を返しても、その関数は同期関数です。
非同期トランザクションのシリアル化
Binder は、単一ノードからの非同期トランザクションをシリアル化します。次の図は、Binder が非同期トランザクションをシリアル化する方法を示しています。
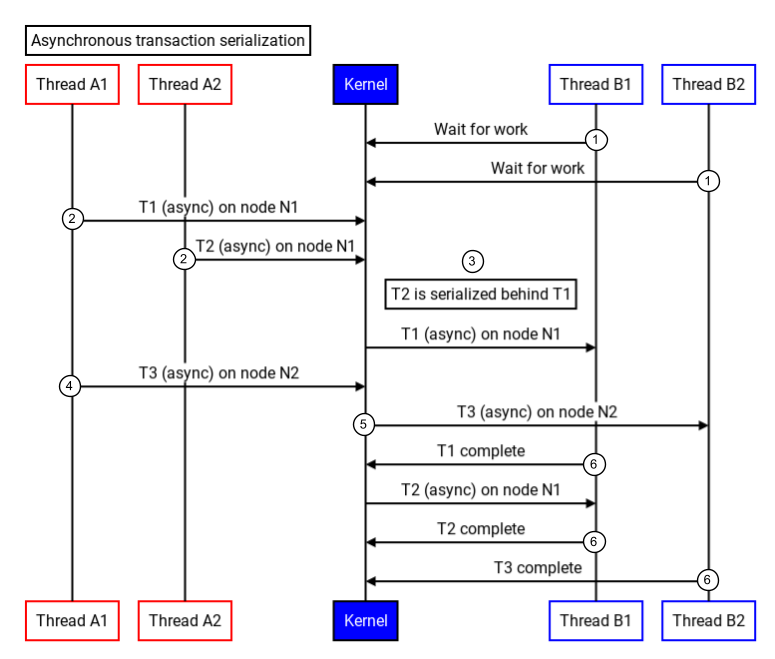
図 3.非同期トランザクションのシリアル化。
- ターゲット スレッドプールのスレッド(B1 と B2)は、カーネル ドライバを呼び出して、着信した作業を待機します。
- 同じノード(N1)上の 2 つのトランザクション(T1 と T2)がカーネルに送信されます。
- カーネルは新しいトランザクションを受信し、同じノード(N1)からのトランザクションであるため、シリアル化します。
- 別のノード(N2)の別のトランザクションがカーネルに送信されます。
- カーネルは 3 番目のトランザクションを受信し、ターゲット プロセスのスレッド(B2)を起動してトランザクションを処理します。
- ターゲット プロセスは各トランザクションを実行し、返信を返します。
ネストされたトランザクション
同期トランザクションはネストできます。トランザクションを処理するスレッドは、新しいトランザクションを発行できます。ネストされたトランザクションは、別のプロセスに送信することも、現在のトランザクションを受信したプロセスに送信することもできます。この動作は、ローカル関数呼び出しを模倣しています。たとえば、ネストされた関数を持つ関数があるとします。
def outer_function(x):
def inner_function(y):
def inner_inner_function(z):
これらがローカル呼び出しの場合、同じスレッドで実行されます。
具体的には、inner_function の呼び出し元が inner_inner_function を実装するノードをホストするプロセス
でもある場合、
inner_inner_function の呼び出しは同じスレッドで実行されます。
次の図は、Binder がネストされたトランザクションを処理する方法を示しています。
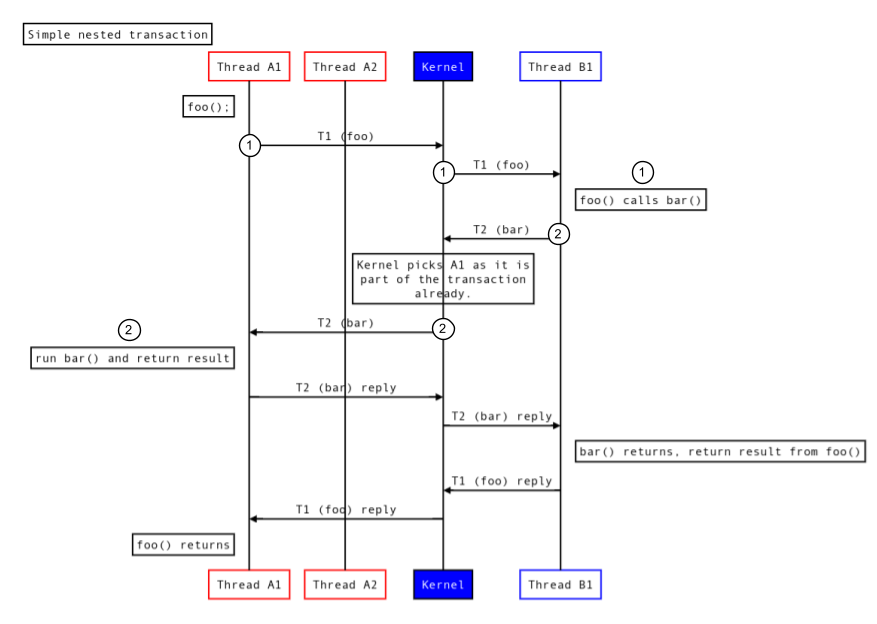
図 4.ネストされたトランザクション。
- スレッド A1 は
foo()の実行をリクエストします。 - このリクエストの一部として、スレッド B1 は
bar()を実行します。これは、同じスレッド A1 で実行されます。
次の図は、bar() を実装するノードが別のプロセスにある場合のスレッド実行を示しています。
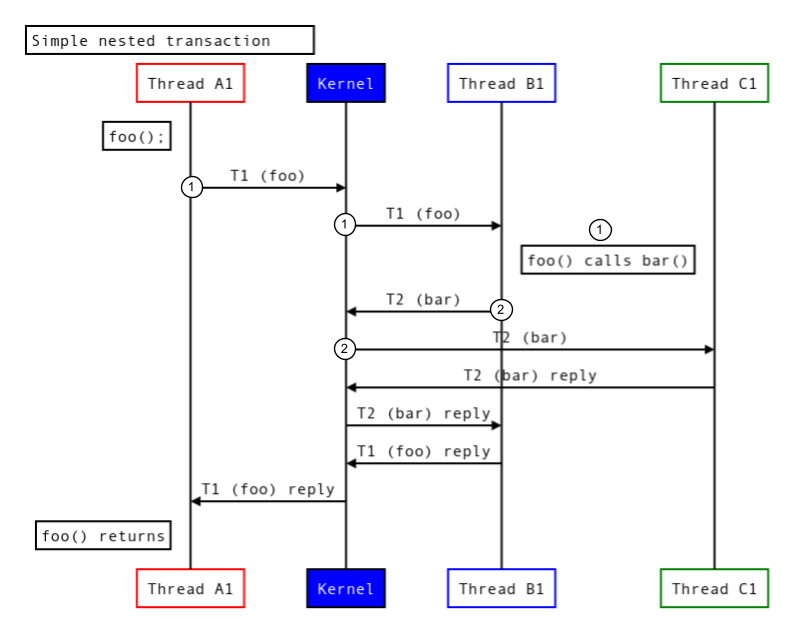
図 5.異なるプロセスでのネストされたトランザクション。
- スレッド A1 は
foo()の実行をリクエストします。 - このリクエストの一部として、スレッド B1 は別のスレッド C1 で実行される
bar()を実行します。
次の図は、トランザクション チェーン内の任意の場所でスレッドが同じプロセスを再利用する方法を示しています。
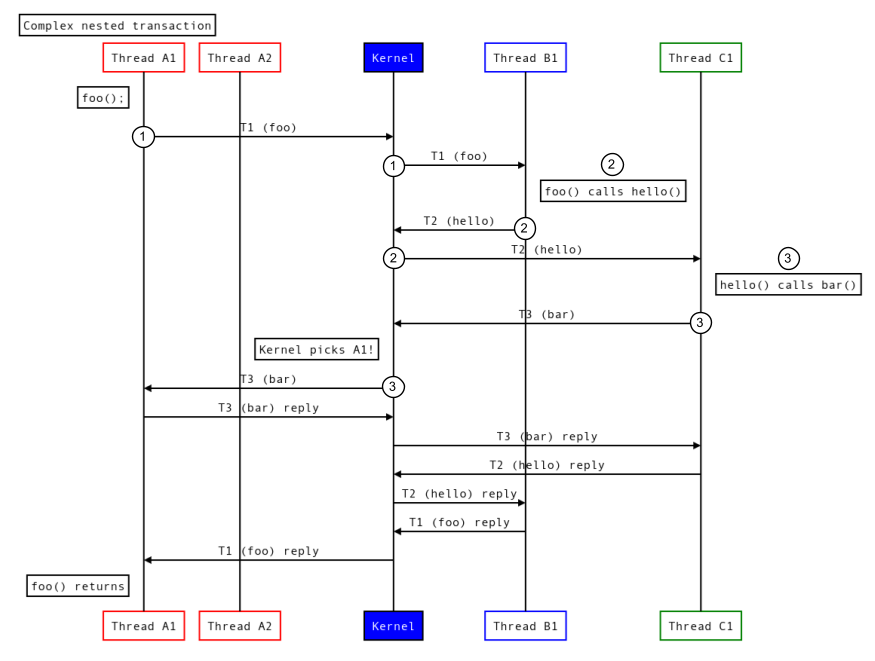
図 6.スレッドを再利用するネストされたトランザクション。
- プロセス A はプロセス B を呼び出します。
- プロセス B はプロセス C を呼び出します。
- プロセス C はプロセス A にコールバックし、カーネルはトランザクション チェーンの一部であるプロセス A のスレッド A1 を再利用します。
非同期トランザクションの場合、ネストは役割を果たしません。クライアントは非同期トランザクションの結果を待機しないため、ネストはありません。 非同期トランザクションのハンドラが、その非同期トランザクションを発行したプロセスを呼び出す場合、そのトランザクションは、そのプロセスの空きスレッドで処理できます。
デッドロックを回避する
次の図は、一般的なデッドロックを示しています。
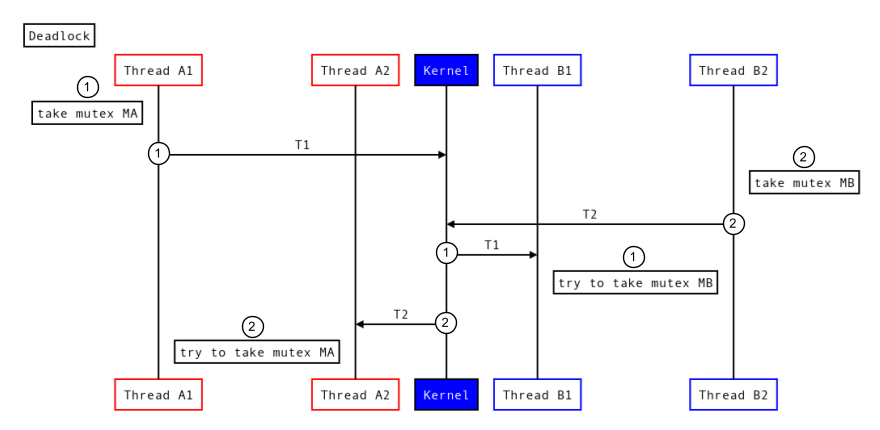
図 7.一般的なデッドロック。
- プロセス A は mutex MA を取得し、プロセス B にバインダー呼び出し(T1)を行います。プロセス B も mutex MB の取得を試みます。
- 同時に、プロセス B は mutex MB を取得し、プロセス A にバインダー呼び出し(T2)を行います。プロセス A は mutex MA の取得を試みます。
これらのトランザクションが重複する場合、各トランザクションは、他のプロセスが mutex を解放するのを待機している間に、プロセス内の mutex を取得する可能性があるため、デッドロックが発生します。
Binder を使用中にデッドロックを回避するには、バインダー呼び出しを行うときにロックを保持しないでください。
ロック順序ルールとデッドロック
単一の実行環境では、ロック順序ルールによってデッドロックが回避されることがよくあります。ただし、プロセス間やコードベース間で呼び出しを行う場合、特にコードが更新されると、順序ルールを維持して調整することはできません。
単一の mutex とデッドロック
ネストされたトランザクションでは、プロセス B は mutex を保持しているプロセス A の同じスレッドに直接コールバックできます。そのため、予期しない再帰により、単一の mutex でデッドロックが発生する可能性があります。
非同期呼び出しとデッドロック
非同期バインダー呼び出しは完了までブロックされませんが、非同期呼び出しのロックを保持することも避ける必要があります。ロックを保持すると、一方向の呼び出しが誤って同期呼び出しに変更された場合に、ロックの問題が発生する可能性があります。
単一のバインダー スレッドとデッドロック
Binder のトランザクション モデルでは再入が可能であるため、プロセスに単一のバインダー スレッドがある場合でも、ロックが必要です。たとえば、シングル スレッド プロセス A でリストを反復処理しているとします。リスト内のアイテムごとに、送信バインダー トランザクションを作成します。呼び出す関数の実装で、プロセス A でホストされているノードへの新しいバインダー トランザクションが作成される場合、そのトランザクションはリストを反復処理していた同じスレッドで処理されます。そのトランザクションの実装で同じリストが変更されると、後でリストの反復処理を続行するときに問題が発生する可能性があります。
スレッドプール サイズを構成する
サービスに複数のクライアントがある場合、スレッドプールにスレッドを追加すると、競合が減り、より多くの呼び出しを並行して処理できます。同時実行を正しく処理したら、スレッドを追加できます。スレッドを追加すると、ワークロードが少ないときに一部のスレッドが使用されないという問題が発生する可能性があります。
スレッドは、構成された最大値までオンデマンドで生成されます。バインダー スレッドが生成されると、そのスレッドをホストするプロセスが終了するまで存続します。
libbinder ライブラリのデフォルトは 15 スレッドです。この値を変更するには、setThreadPoolMaxThreadCount を使用します。
using ::android::ProcessState;
ProcessState::self()->setThreadPoolMaxThreadCount(size_t maxThreads);