
O systrace é a principal ferramenta para analisar o desempenho de dispositivos Android. No entanto, ele é um wrapper de outras ferramentas. É o wrapper do lado do host em torno do atrace, o executável do lado do dispositivo que controla o rastreamento do espaço do usuário e configura o ftrace, e o principal mecanismo de rastreamento no kernel do Linux. O systrace usa o atrace para ativar o rastreamento, lê o buffer do ftrace e envolve tudo em um visualizador HTML independente. Embora os kernels mais recentes tenham suporte para o filtro de pacotes Berkeley aprimorado do Linux (eBPF), esta página se refere ao kernel 3.18 (sem eFPF), já que foi o que foi usado no Pixel ou Pixel XL.
O systrace é de propriedade das equipes do Google Android e do Google Chrome e é de código aberto como parte do projeto Catapult (link em inglês). Além do systrace, o Catapult inclui outros utilitários úteis. Por exemplo, o ftrace tem mais recursos do que podem ser ativados diretamente pelo systrace ou atrace e contém algumas funcionalidades avançadas que são essenciais para depurar problemas de desempenho. Esses recursos exigem acesso root e, muitas vezes, um novo kernel.
Executar systrace
Ao depurar instabilidade no Pixel ou Pixel XL, comece com o seguinte comando:
./systrace.py sched freq idle am wm gfx view sync binder_driver irq workq input -b 96000
Quando combinado com os tracepoints adicionais necessários para a atividade do pipeline de GPU e exibição, isso permite rastrear desde a entrada do usuário até o frame exibido na tela. Defina o tamanho do buffer como algo grande para evitar a perda de eventos. Sem um buffer grande, algumas CPUs não contêm eventos após algum ponto no rastreamento.
Ao usar o systrace, lembre-se de que todos os eventos são acionados por algo na CPU.
Como o systrace é criado com base no ftrace e o ftrace é executado na CPU, algo na CPU precisa gravar o buffer do ftrace que registra as mudanças de hardware. Isso significa que, se você quiser saber por que uma cerca de exibição mudou de estado, é possível ver o que estava sendo executado na CPU no momento exato da transição. Algo em execução na CPU acionou essa mudança no registro. Esse conceito é a base da análise de desempenho usando o systrace.
Exemplo: Working frame
Este exemplo descreve uma systrace para um pipeline de UI normal. Para acompanhar o exemplo, baixe o arquivo ZIP de rastreamentos (que também inclui outros rastreamentos mencionados nesta seção), descompacte o arquivo e abra o arquivo systrace_tutorial.html no navegador.
Para uma carga de trabalho consistente e periódica, como TouchLatency, o pipeline da interface segue esta sequência:
- O EventThread no SurfaceFlinger ativa a linha de execução da interface do app, sinalizando que é hora de renderizar um novo frame.
- O app renderiza um frame nas tarefas da linha de execução de IU, RenderThread e HWUI, usando recursos de CPU e GPU. Essa é a maior parte da capacidade gasta na interface.
- O app envia o frame renderizado para o SurfaceFlinger usando um binder. Em seguida, o SurfaceFlinger entra em modo de espera.
- Uma segunda EventThread no SurfaceFlinger ativa o SurfaceFlinger para acionar a composição e a saída da tela. Se o SurfaceFlinger determinar que não há trabalho a ser feito, ele volta a dormir.
- O SurfaceFlinger processa a composição usando o Hardware Composer (HWC), o Hardware Composer 2 (HWC2) ou o GL. A composição HWC e HWC2 é mais rápida e consome menos energia, mas tem limitações dependendo do sistema em um chip (SoC). Isso geralmente leva de 4 a 6 ms, mas pode se sobrepor à etapa 2 porque os apps Android sempre têm buffer triplo. Embora os apps sempre tenham buffer triplo, pode haver apenas um frame pendente aguardando no SurfaceFlinger, o que faz com que ele pareça idêntico ao buffer duplo.
- O SurfaceFlinger envia a saída final para exibição com um driver do fornecedor e volta a dormir, aguardando o despertar do EventThread.
Confira um exemplo da sequência de frames começando em 15409 ms:
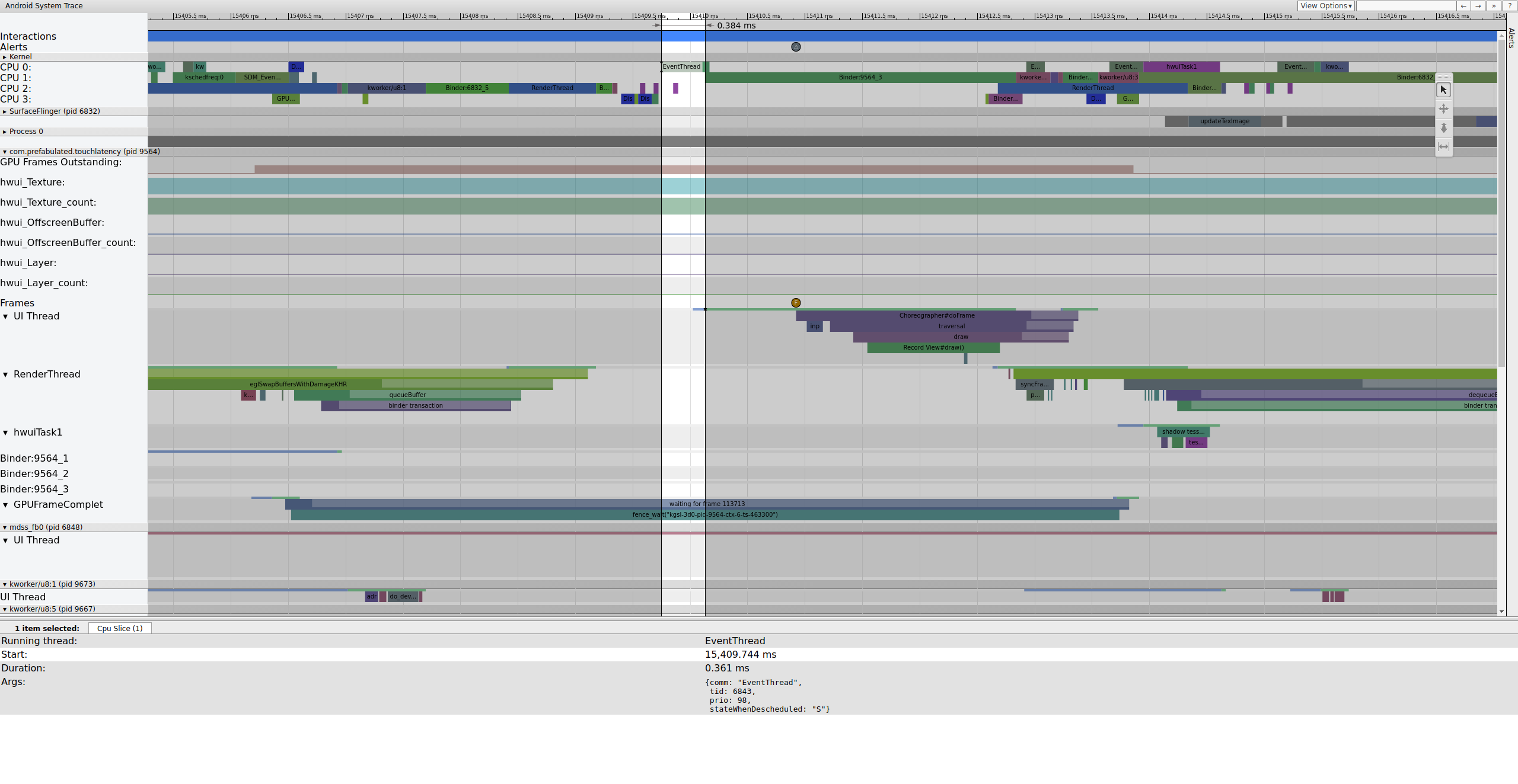
Figura 1. Pipeline de interface normal, EventThread em execução.
A Figura 1 é um frame normal cercado por frames normais. Portanto, é um bom ponto de partida para entender como o pipeline da interface funciona. A linha da UI para TouchLatency inclui cores diferentes em momentos diferentes. As barras indicam diferentes estados da linha de execução:
- Cinza. Dormindo.
- Azul. Executável (pode ser executado, mas o programador ainda não o escolheu para execução).
- Verde. Em execução ativa (o programador acha que está em execução).
- Vermelho. Sono ininterrupto (geralmente dormir em um bloqueio no kernel). Pode ser indicativo de carga de E/S. Extremamente útil para depurar problemas de desempenho.
- Laranja. Suspensão ininterrupta devido à carga de E/S.
Para conferir o motivo do sono ininterrupto (disponível no ponto de rastreamento sched_blocked_reason), selecione a fatia vermelha de sono ininterrupto.
Enquanto a EventThread está em execução, a linha de execução de UI para TouchLatency se torna executável. Para saber o que o ativou, clique na seção azul.
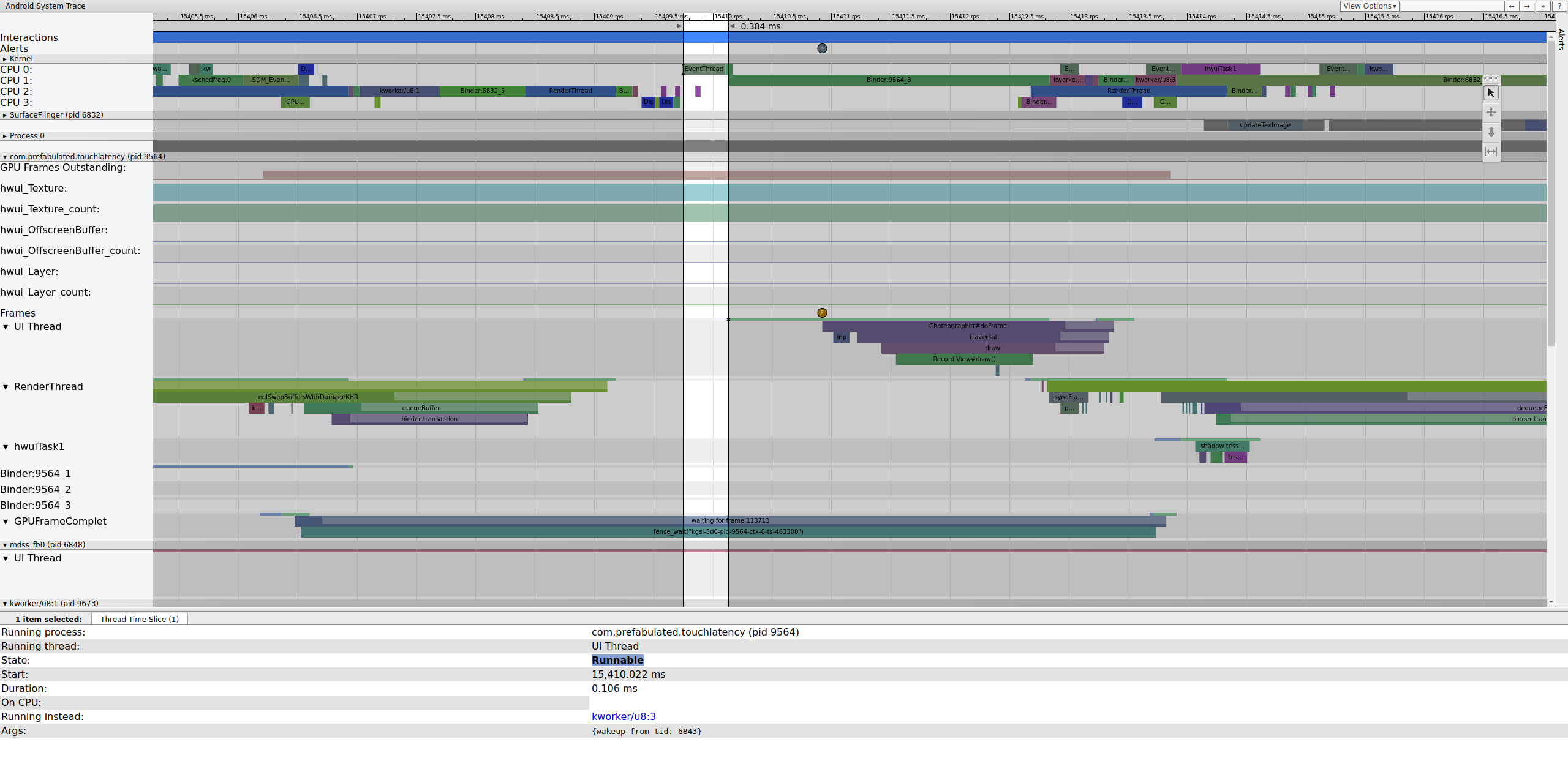
Figura 2. Linha de execução de interface para TouchLatency.
A Figura 2 mostra que a linha de execução da interface TouchLatency foi ativada pelo tid 6843, que corresponde a EventThread. A linha de execução da UI é ativada, renderiza um frame e o coloca na fila para o SurfaceFlinger consumir.
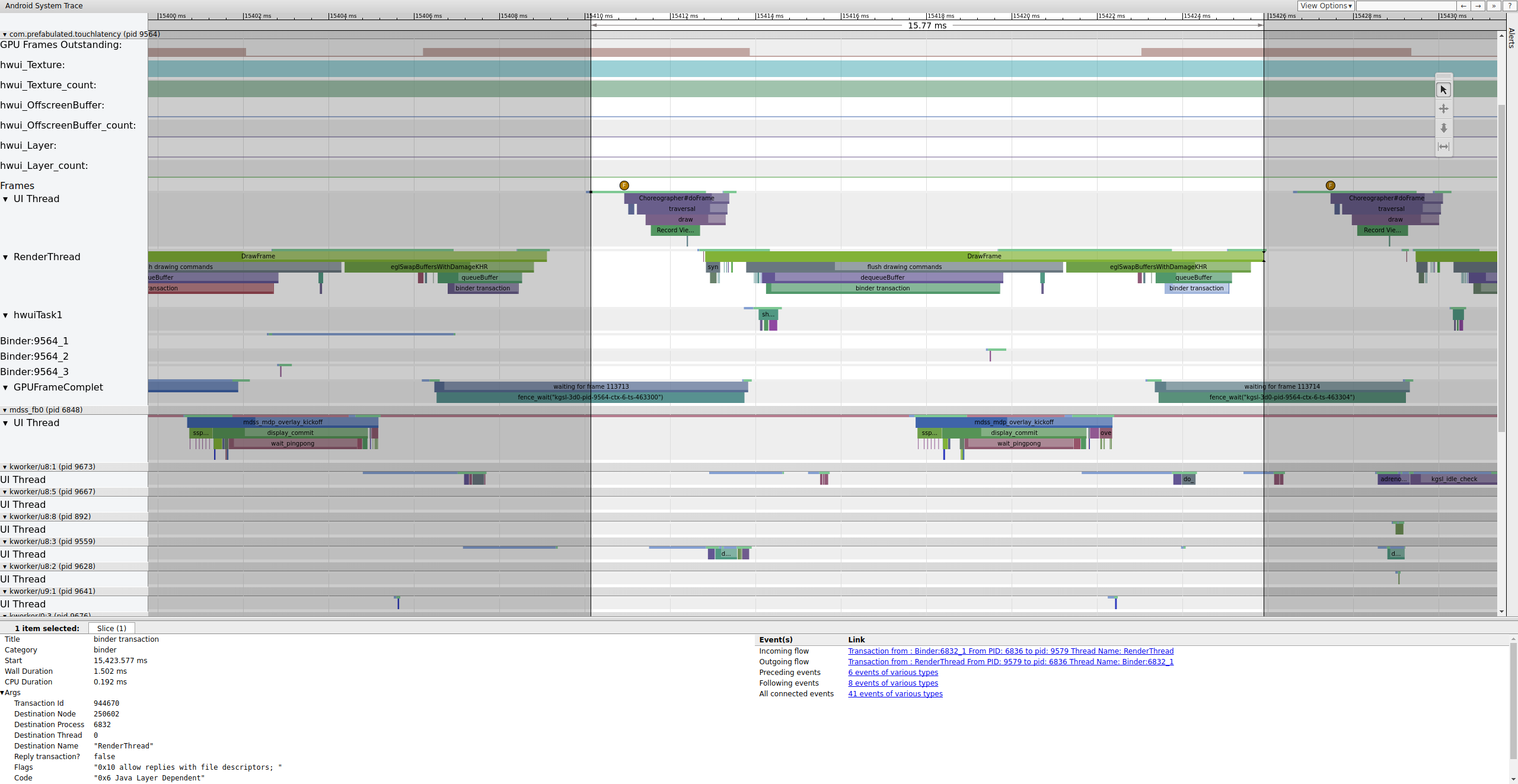
Figura 3. A linha de execução da UI é ativada, renderiza um frame e o coloca na fila para o SurfaceFlinger consumir.
Se a tag binder_driver estiver ativada em um rastreamento, você poderá selecionar uma transação de binder para ver informações sobre todos os processos envolvidos nela.
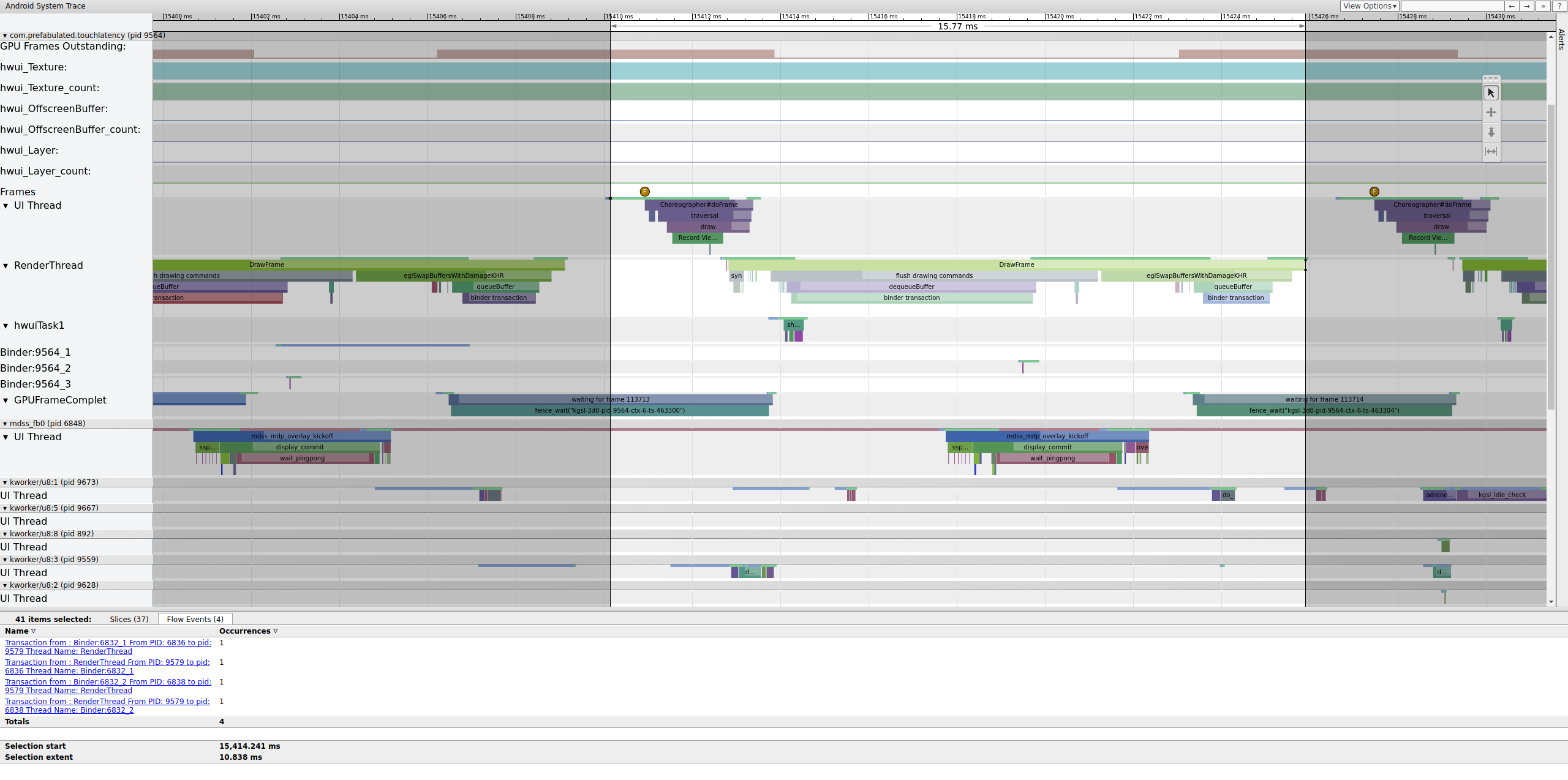
Figura 4. Transação de binder.
A Figura 4 mostra que, em 15.423,65 ms, Binder:6832_1 no SurfaceFlinger se torna executável devido ao tid 9579, que é a RenderThread do TouchLatency. Você também pode ver queueBuffer nos dois lados da transação do binder.
Durante o queueBuffer no lado do SurfaceFlinger, o número de frames pendentes do TouchLatency vai de 1 para 2.
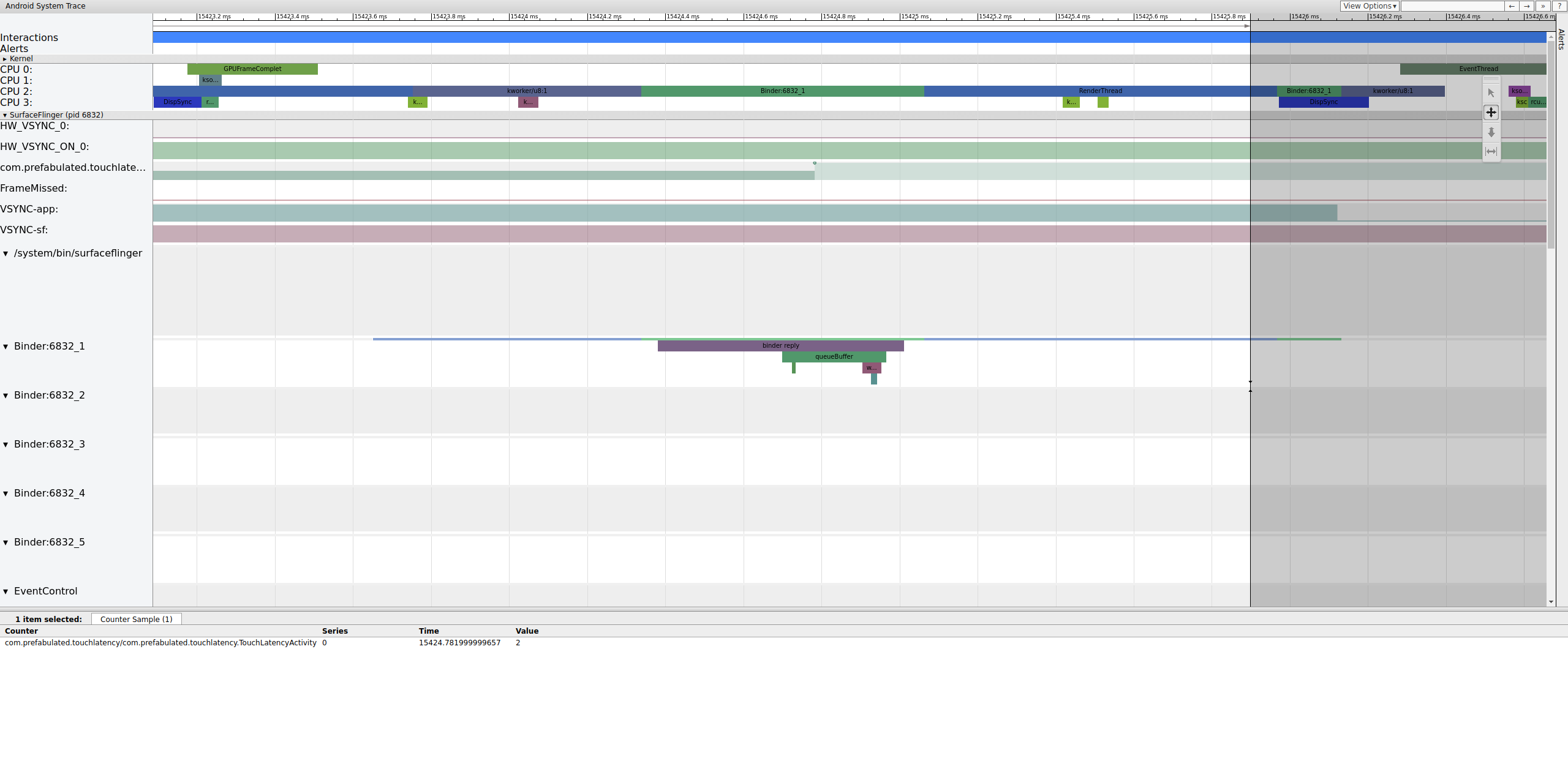
Figura 5. Os frames pendentes vão de 1 a 2.
A Figura 5 mostra o buffer triplo, em que há dois frames concluídos e o app está prestes a começar a renderizar um terceiro. Isso acontece porque já descartamos alguns frames, então o app mantém dois frames pendentes em vez de um para tentar evitar mais descartes.
Logo depois, a linha de execução principal do SurfaceFlinger é ativada por uma segunda EventThread para que possa gerar o frame pendente mais antigo na tela:
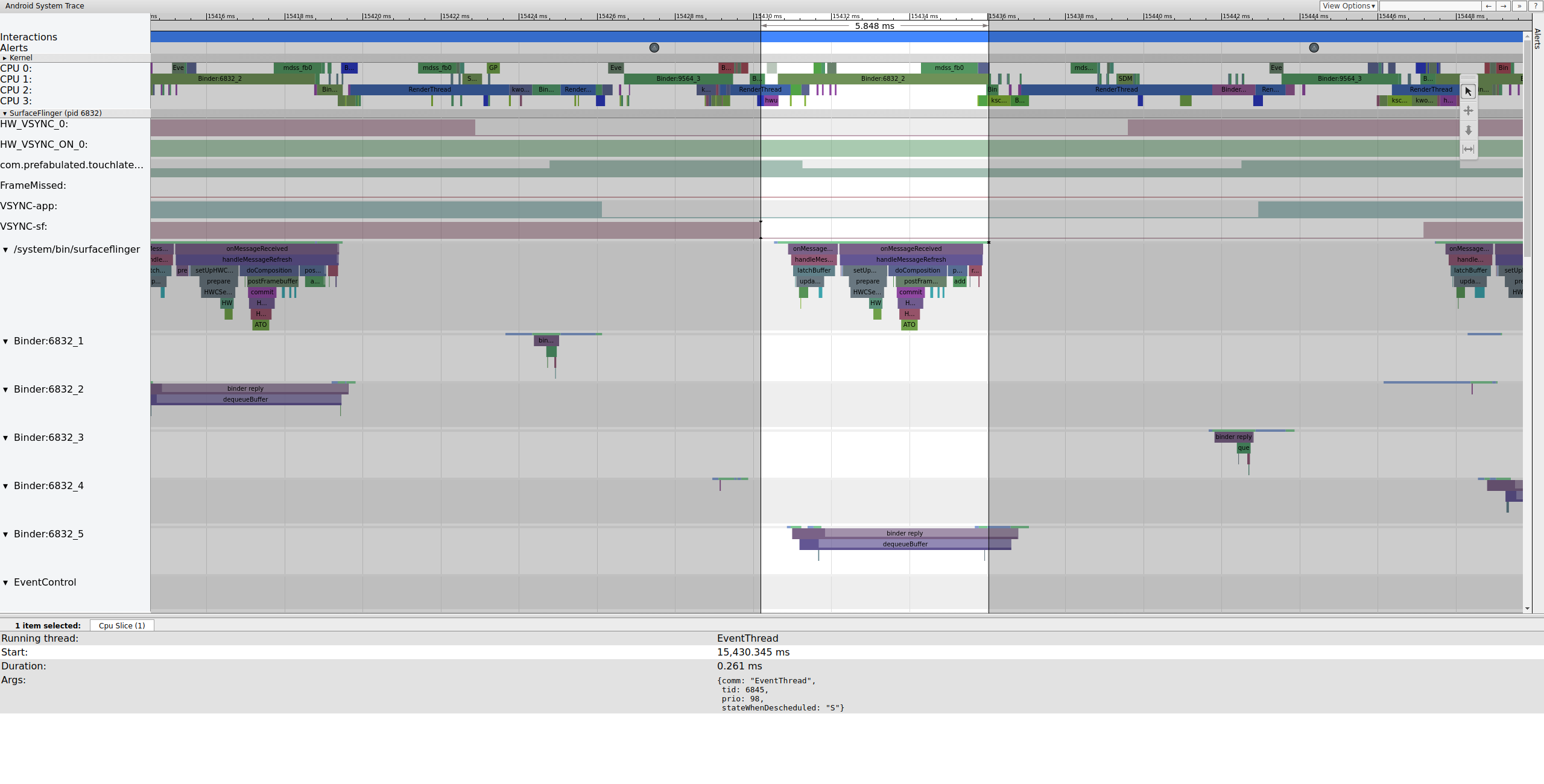
Figura 6. A linha de execução principal do SurfaceFlinger é ativada por uma segunda EventThread.
O SurfaceFlinger primeiro trava o buffer pendente mais antigo, o que faz com que a contagem de buffers pendentes diminua de 2 para 1:
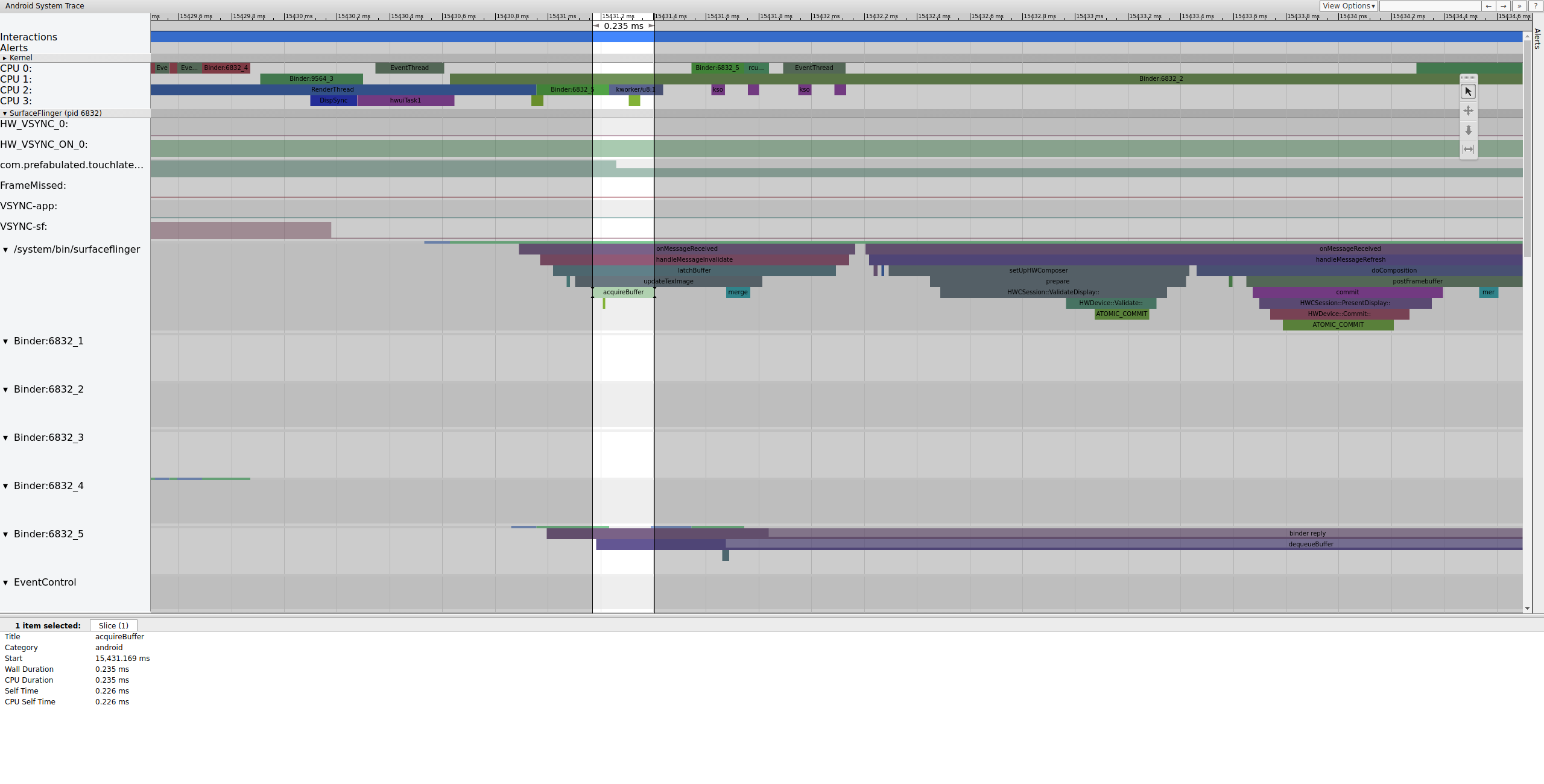
Figura 7. O SurfaceFlinger primeiro se conecta ao buffer pendente mais antigo.
Depois de travar o buffer, o SurfaceFlinger configura a composição e envia o
frame final à tela. Algumas dessas seções são ativadas como parte do
mdss ponto de rastreamento. Por isso, elas podem não estar incluídas no seu SoC.
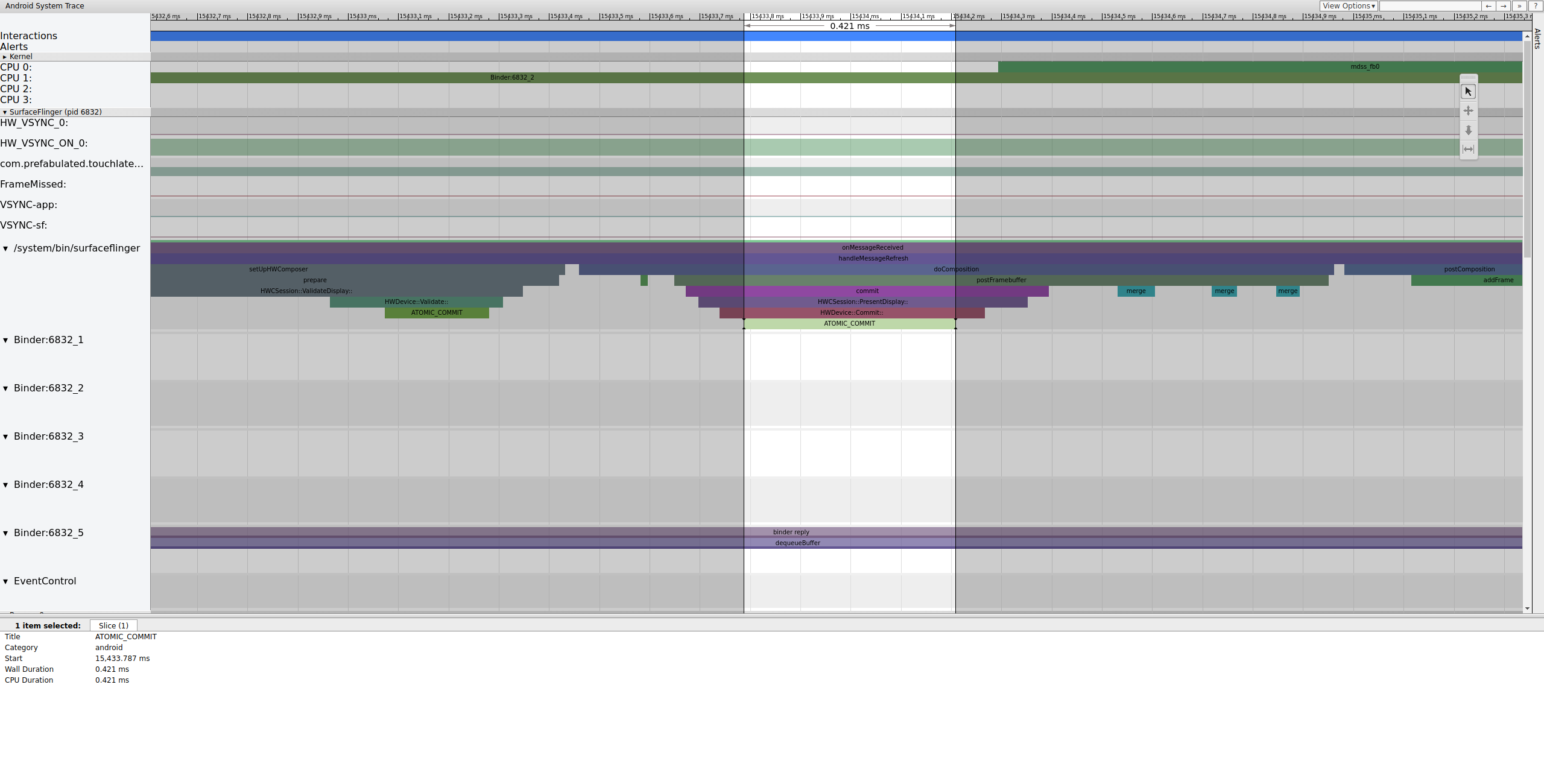
Figura 8. O SurfaceFlinger configura a composição e envia o frame final.
Em seguida, mdss_fb0 é ativado na CPU 0. mdss_fb0 é a
thread do kernel do pipeline de exibição para gerar um frame renderizado na tela.
Observe que mdss_fb0 é uma linha separada no trace. Role para baixo para ver:
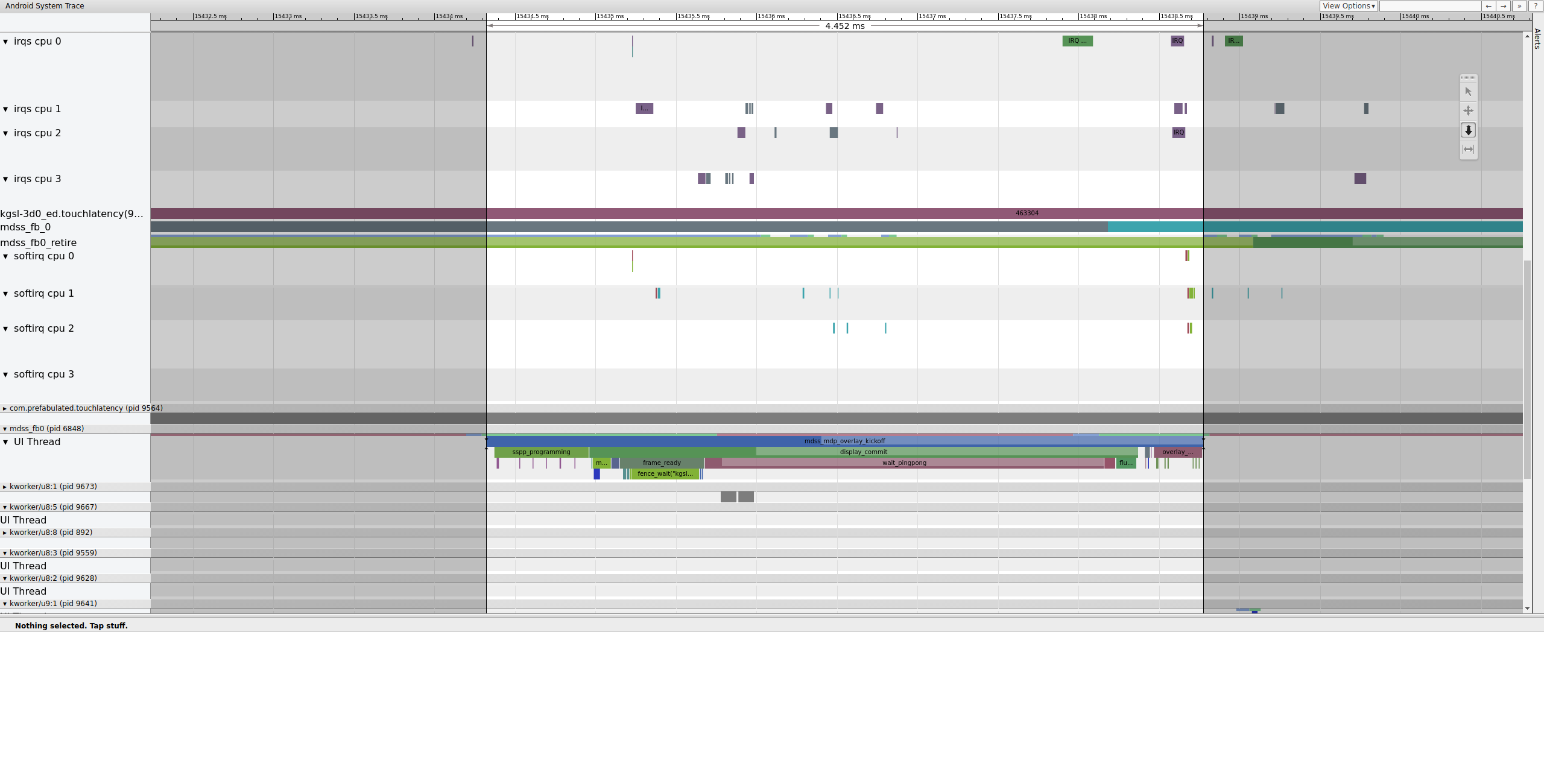
Figura 9.O mdss_fb0 é ativado na CPU 0.
mdss_fb0 acorda, funciona brevemente, entra em um estado de suspensão ininterrupta e
acorda novamente.
Exemplo: quadro não funcional
Este exemplo descreve uma systrace usada para depurar o jitter do Pixel ou do Pixel XL. Para acompanhar o exemplo, baixe o arquivo ZIP de rastreamentos (que inclui outros rastreamentos mencionados nesta seção), descompacte o arquivo e abra o arquivo systrace_tutorial.html no navegador.
Ao abrir o systrace, você verá algo como a figura a seguir:

Figura 10. TouchLatency em execução no Pixel XL com a maioria das opções ativadas.
Na figura 10, a maioria das opções está ativada, incluindo pontos de rastreamento mdss e kgsl.
Ao procurar instabilidade, verifique a linha "FrameMissed" em "SurfaceFlinger".
O FrameMissed é uma melhoria na qualidade de vida fornecida pelo HWC2. Ao visualizar
systrace para outros dispositivos, a linha "FrameMissed" pode não estar presente se o dispositivo não usar o
HWC2. Em ambos os casos, FrameMissed está correlacionado com o SurfaceFlinger perdendo um dos tempos de execução regulares e uma contagem de buffers pendentes inalterada para o app (com.prefabulated.touchlatency) em um VSync.

Figura 11. Correlação entre FrameMissed e SurfaceFlinger.
A Figura 11 mostra um frame perdido em 15598, 29 ms.O SurfaceFlinger ficou ativo brevemente no intervalo de VSync e voltou a dormir sem fazer nada. Isso significa que o SurfaceFlinger determinou que não valia a pena tentar enviar um frame para a tela novamente.
Para entender por que o pipeline falhou nesse frame, primeiro revise o exemplo de frame funcional acima para ver como um pipeline normal da interface aparece no systrace. Quando tudo estiver pronto, volte ao frame perdido e trabalhe de trás para frente. Observe que o SurfaceFlinger ativa e entra em modo de espera imediatamente. Ao visualizar o número de frames pendentes do TouchLatency, há dois frames, o que ajuda a determinar o que está acontecendo.
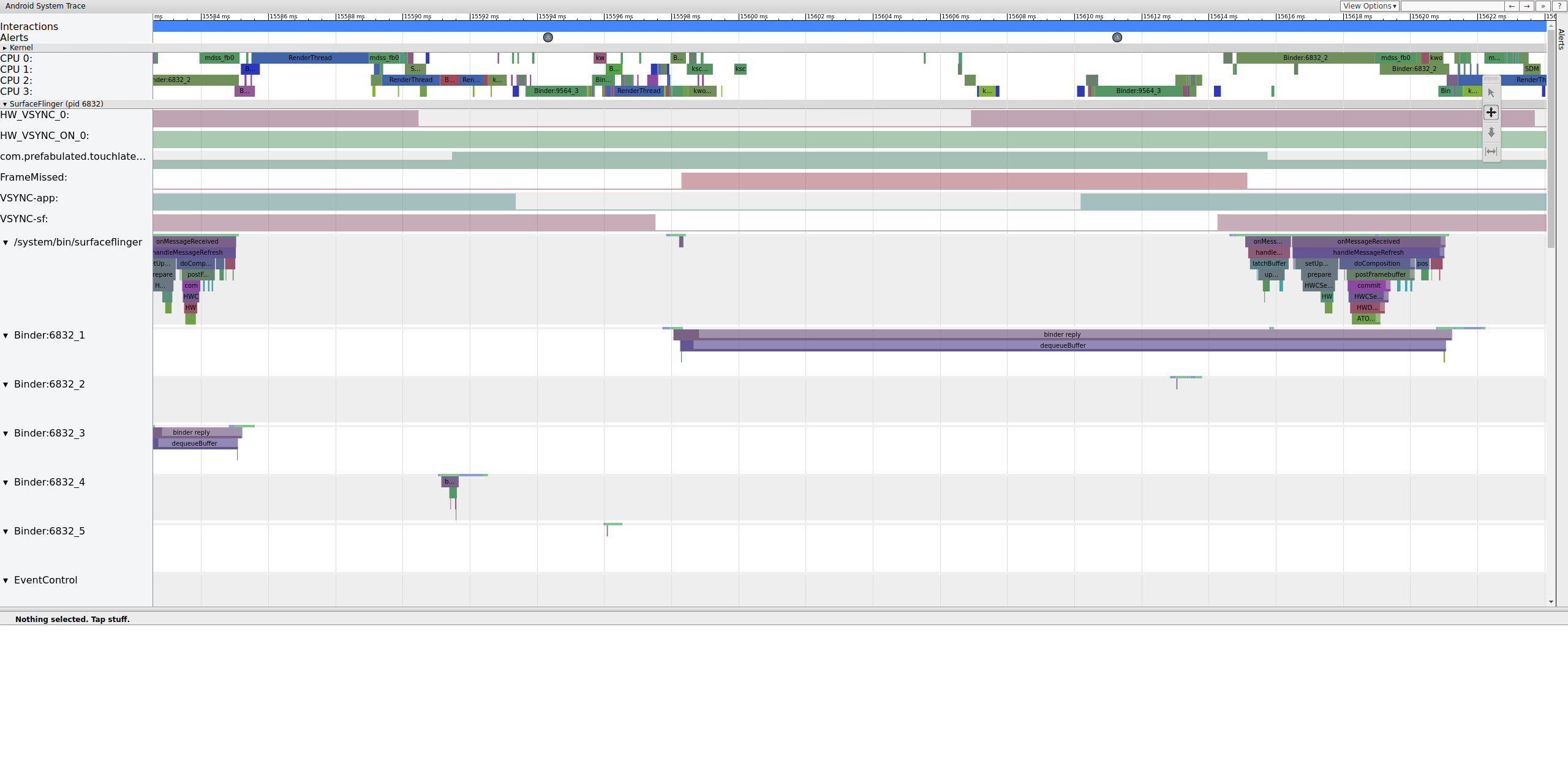
Figura 12. O SurfaceFlinger ativa e entra em suspensão imediatamente.
Como há frames no SurfaceFlinger, não é um problema do app. Além disso, o SurfaceFlinger está ativando no momento correto, então não é um problema do SurfaceFlinger. Se o SurfaceFlinger e o app parecerem normais, provavelmente é um problema de driver.
Como os tracepoints mdss e sync estão ativados,
você pode receber informações sobre as barreiras (compartilhadas entre o driver de tela e
o SurfaceFlinger) que controlam quando os frames são enviados à tela.
Essas barreiras estão listadas em mdss_fb0_retire, que
indica quando um frame está na tela. Essas barreiras são fornecidas como parte da categoria de rastreamento sync. Quais barreiras correspondem a eventos específicos no SurfaceFlinger depende do seu SOC e da pilha de drivers. Portanto, trabalhe com o fornecedor do SOC para entender o significado das categorias de barreiras nos seus rastreamentos.
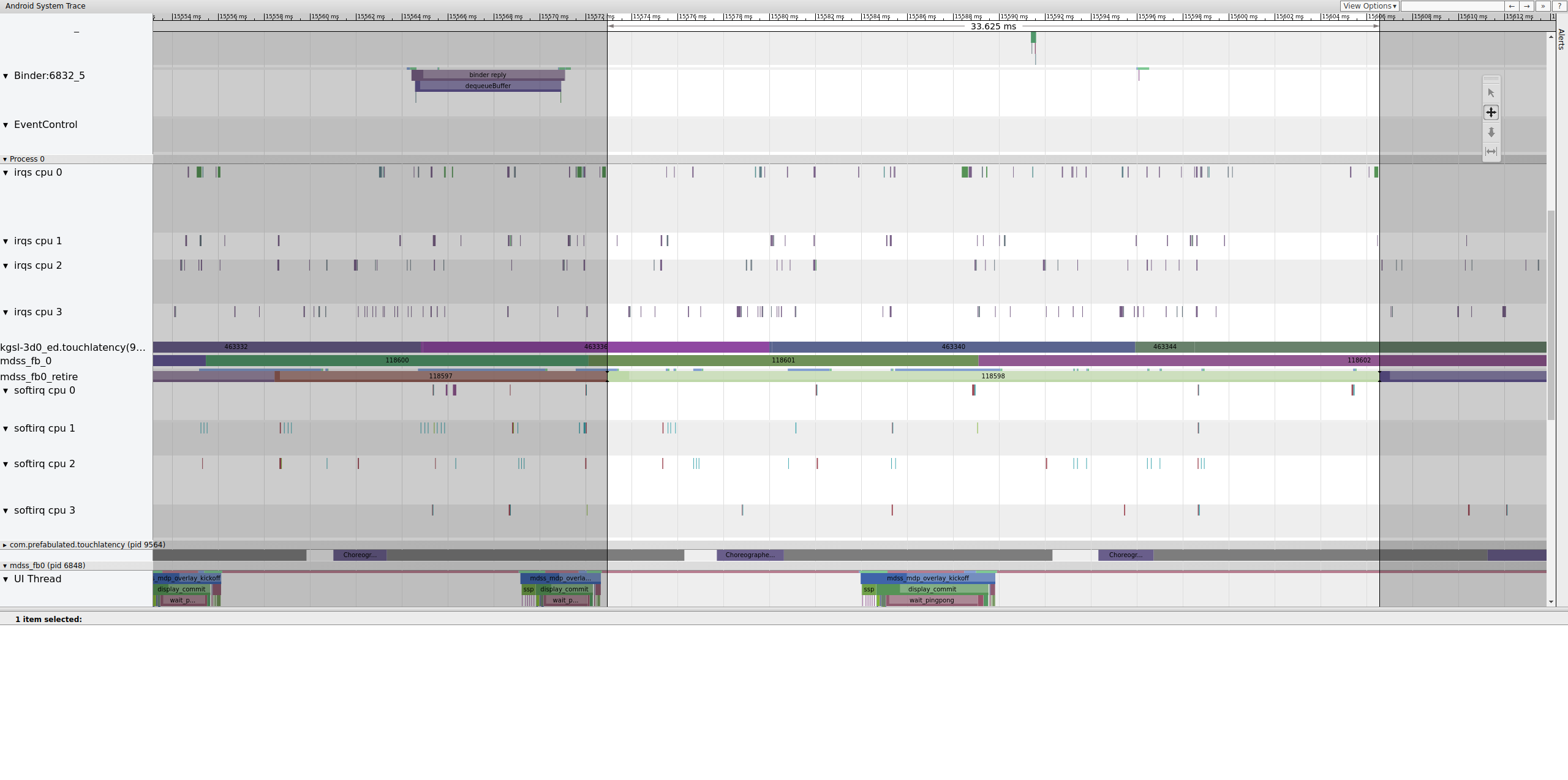
Figura 13.mdss_fb0_retire fences.
A Figura 13 mostra um frame que foi exibido por 33 ms, não 16,7 ms, como esperado. Na metade dessa parte, o frame deveria ter sido substituído por um novo, mas não foi. Confira o frame anterior e procure algo.
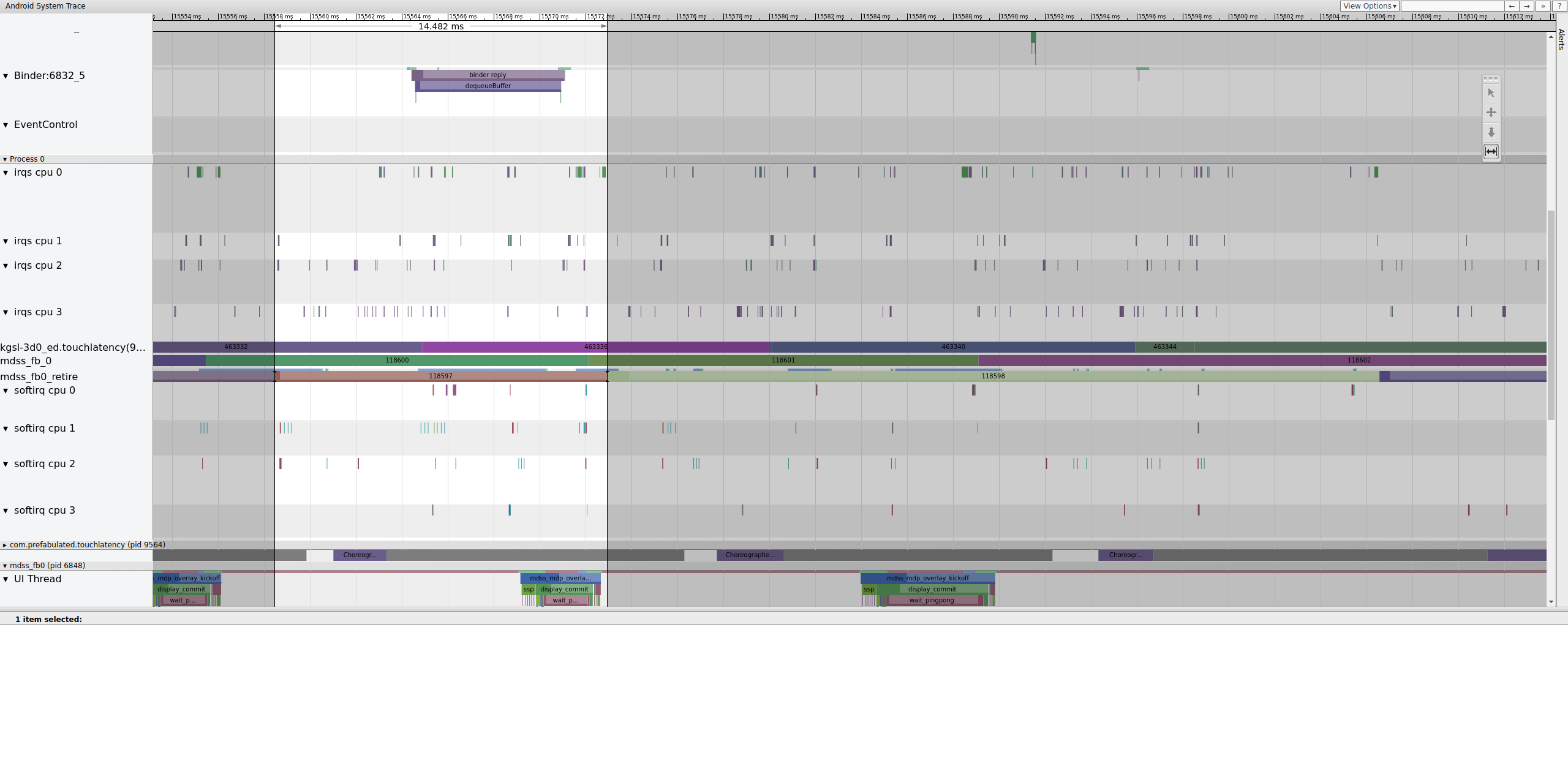
Figura 14. Frame anterior ao frame danificado.
A Figura 14 mostra um frame de 14.482 ms. O segmento de dois frames corrompido tinha 33,6 ms, o que é aproximadamente o esperado para dois frames (renderizados a 60 Hz, 16,7 ms por frame, o que é próximo). Mas 14.482 ms não está perto de 16,7 ms, o que sugere que há algo errado com o pipeline de exibição.
Investigue exatamente onde essa cerca termina para determinar o que a controla:
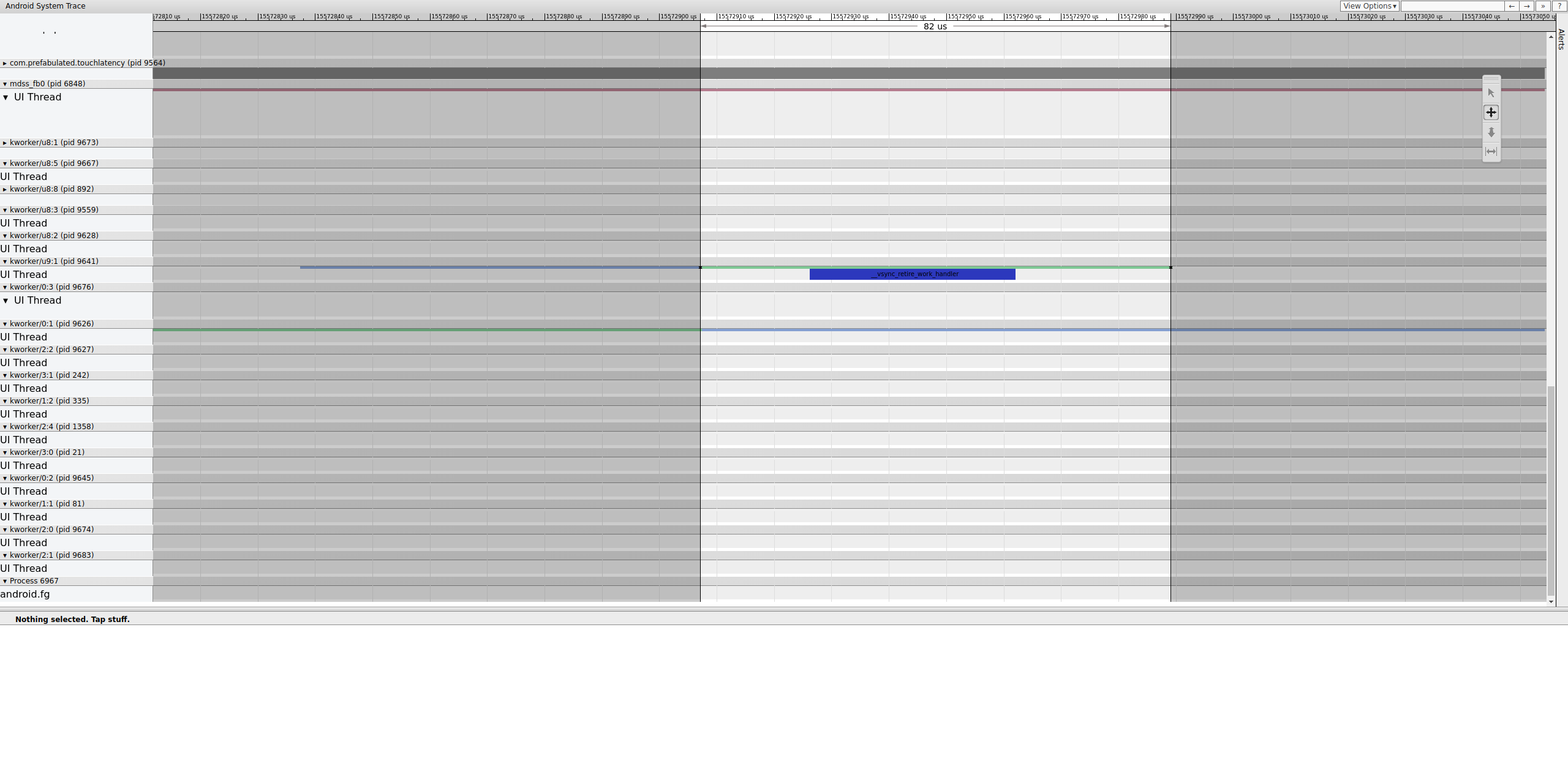
Figura 15. Investigue o fim da cerca.
Uma fila de trabalho contém __vsync_retire_work_handler, que é
executada quando a cerca muda. Ao analisar a origem do kernel, você pode ver que ele faz parte do driver de exibição. Ele parece estar no caminho crítico do pipeline de exibição, então precisa ser executado o mais rápido possível. Ele pode ser executado por cerca de 70 μs (não é um longo atraso de programação), mas é uma fila de trabalho e pode não ser programado com precisão.
Verifique o frame anterior para determinar se isso contribuiu. Às vezes, o jitter pode se acumular com o tempo e causar um prazo perdido:
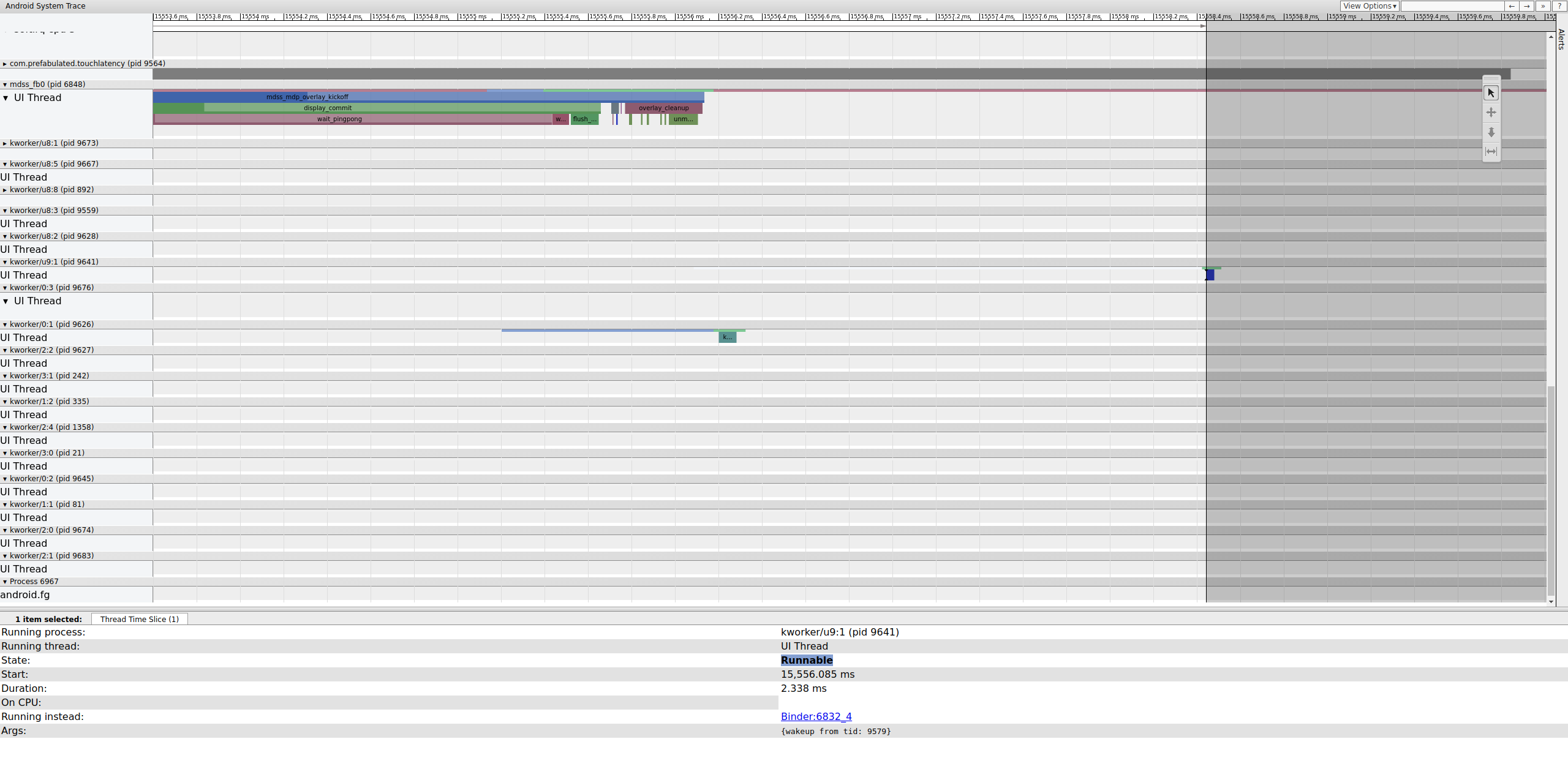
Figura 16. Frame anterior.
A linha executável no kworker não fica visível porque o visualizador a deixa branca quando ela é selecionada, mas as estatísticas mostram que 2,3 ms de atraso do programador para parte do caminho crítico do pipeline de exibição é ruim.
Antes de continuar, corrija o atraso movendo essa parte do
caminho crítico do pipeline de exibição de uma fila de trabalho (que é executada como uma
thread SCHED_OTHER do CFS) para uma kthread SCHED_FIFO
dedicada. Essa função precisa de garantias de tempo que as filas de trabalho não podem (e não
devem) fornecer.
Não está claro que esse é o motivo do jank. Fora de casos fáceis de diagnosticar, como disputa de bloqueio do kernel fazendo com que as linhas de execução críticas para a exibição entrem em espera, os rastreamentos geralmente não especificam o problema. Essa variação pode ter sido a causa da perda do frame. Os tempos de cerca deveriam ser de 16,7 ms, mas não chegam perto disso nos frames que antecedem o frame descartado. Devido ao acoplamento estreito do pipeline de exibição, é possível que o jitter nos tempos de cerca tenha resultado em um frame perdido.
Neste exemplo, a solução envolve a conversão de
__vsync_retire_work_handler de uma fila de trabalho para uma
kthread dedicada. Isso resulta em melhorias perceptíveis no jitter e redução do jank no
teste da bola quicando. Os traces subsequentes mostram tempos de cerca que ficam muito próximos
de 16,7 ms.