
Android 8.0 כולל בדיקות ביצועים של binder ו-hwbinder למעבר נתונים ולזמן אחזור. יש הרבה תרחישים לזיהוי בעיות ביצועים גלויות, אבל הפעלת תרחישים כאלה עשויה להיות זמן רב, ולרוב התוצאות זמינות רק אחרי שמשלבים את המערכת. בעזרת בדיקות הביצועים שסופקו, קל יותר לבדוק במהלך הפיתוח, לזהות בעיות חמורות בשלב מוקדם יותר ולשפר את חוויית המשתמש.
בדיקות הביצועים כוללות את ארבע הקטגוריות הבאות:
- תפוקת ה-binder (זמינה ב-
system/libhwbinder/vts/performance/Benchmark_binder.cpp) - זמן האחזור של Binder (זמין ב-
frameworks/native/libs/binder/tests/schd-dbg.cpp) - תפוקת hwbinder (זמינה ב-
system/libhwbinder/vts/performance/Benchmark.cpp) - זמן האחזור של hwbinder (זמין ב-
system/libhwbinder/vts/performance/Latency.cpp)
מידע על binder ו-hwbinder
Binder ו-hwbinder הן תשתית של Android לתקשורת בין תהליכים (IPC) שמשתמשות באותו מנהל Linux, אבל יש להן את ההבדלים האיכותיים הבאים:
| יחס גובה-רוחב | קלסר | hwbinder |
|---|---|---|
| המטרה | מתן סכימה כללית של IPC למסגרת | תקשורת עם חומרה |
| נכס | אופטימיזציה לשימוש במסגרת Android | זמן אחזור קצר עם תקורה מינימלית |
| שינוי מדיניות התזמון לחזית/לרקע | כן | לא |
| העברת ארגומנטים | שימוש בסריאליזציה שנתמכת על ידי אובייקט Parcel | שימוש במאגרי פיזור (scatter buffers) והימנעות מהעלות הנוספת של העתקת הנתונים הנדרשים לסריאליזציה של חבילות (Parcel) |
| ירושה של עדיפות | לא | כן |
תהליכים של Binder ו-hwbinder
ב-systrace visualizer מוצגות העסקאות באופן הבא:
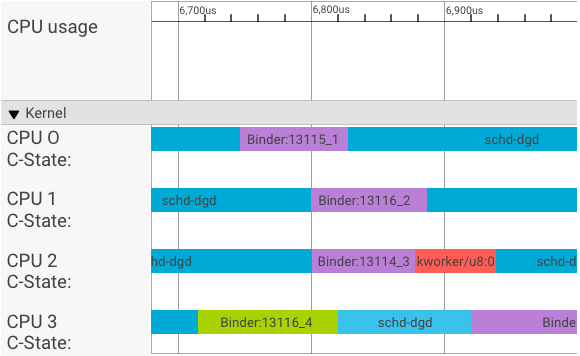
בדוגמה שלמעלה:
- ארבעת התהליכים של schd-dbg הם תהליכי לקוח.
- ארבעת תהליכי ה-binder הם תהליכי שרת (השם מתחיל ב-Binder ומסתיים במספר רצף).
- תהליך לקוח תמיד משויך לתהליך שרת, שמקדיש את עצמו ללקוח.
- כל זוגות התהליכים של לקוח-שרת מתזמנים בנפרד על ידי הליבה בו-זמנית.
ב-CPU 1, ליבה של מערכת ההפעלה מפעילה את הלקוח כדי להנפיק את הבקשה. לאחר מכן, המערכת משתמשת באותו מעבד (CPU) בכל הזדמנות אפשרית כדי להעיר תהליך שרת, לטפל בבקשה ולחזור להקשר הקודם אחרי שהבקשה תושלם.
תפוקה לעומת זמן אחזור
בעסקה מושלמת, שבה תהליך הלקוח והשרת עוברים בצורה חלקה, הבדיקות של קצב העברת הנתונים וזמן האחזור לא מניבות הודעות שונות באופן משמעותי. עם זאת, כשליבת מערכת ההפעלה מטפלת בבקשת הפסקה (IRQ) מחומרה, ממתינה לנעילת קבצים או פשוט בוחרת לא לטפל בהודעה באופן מיידי, יכולה להיווצר בועה של זמן אחזור.
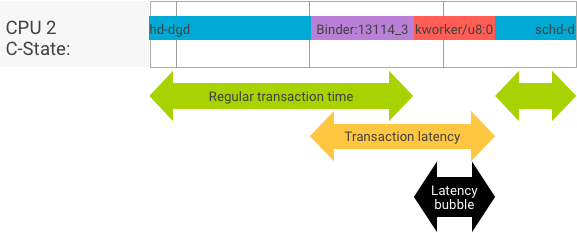
בבדיקה של קצב העברת הנתונים נוצר מספר גדול של עסקאות עם גדלים שונים של עומסי נתונים, שמספקים הערכה טובה של משך הזמן הרגיל של העסקאות (בתרחישים הטובים ביותר) וקצב העברת הנתונים המקסימלי שהמקשר יכול להשיג.
לעומת זאת, בבדיקה של זמן האחזור לא מתבצעות פעולות על עומס העבודה כדי למזער את זמן העסקה הרגיל. אנחנו יכולים להשתמש בזמן העסקה כדי להעריך את זמן האחזור של הקישור, ליצור נתונים סטטיסטיים לגבי התרחיש הגרוע ביותר ולחשב את היחס של עסקאות שהזמן שלהן עומד בלוח הזמנים שצוין.
טיפול בהיפוך עדיפות
היפוך עדיפות מתרחש כששרשור עם עדיפות גבוהה יותר ממתין באופן לוגי לשרשור עם עדיפות נמוכה יותר. באפליקציות בזמן אמת (RT) יש בעיה של היפוך תעדוף:
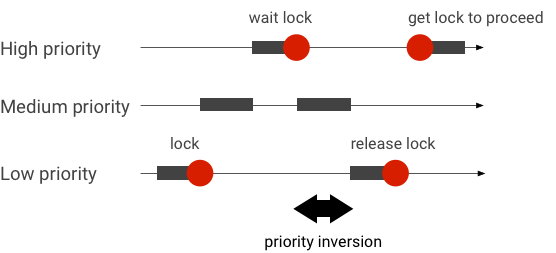
כשמשתמשים בתזמון של Linux Completely Fair Scheduler (CFS), תמיד יש סיכוי ששרשור יפעל, גם אם לשרשור אחר יש עדיפות גבוהה יותר. כתוצאה מכך, אפליקציות עם תזמון CFS מטפלות בהיפוך העדיפות כהתנהגות צפויה ולא כבעיה. עם זאת, במקרים שבהם מסגרת Android זקוקה לתזמון RT כדי להבטיח את העדיפות של חוטים בעדיפות גבוהה, צריך לפתור את היפוך העדיפויות.
דוגמה להיפוך עדיפות במהלך עסקה של Binder (שרשור RT חסום באופן לוגי על ידי שרשורי CFS אחרים בזמן ההמתנה לשירות של שרשור Binder):
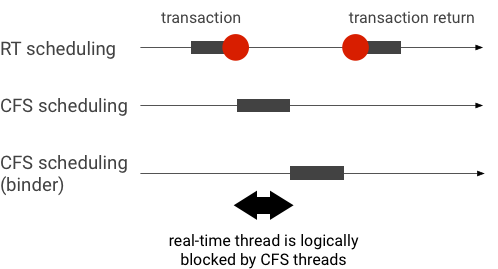
כדי למנוע חסימות, אפשר להשתמש בירושה של תעדוף כדי להעביר באופן זמני את שרשור ה-Binder לשרשור RT כשהוא מטפל בבקשה מלקוח RT. חשוב לזכור שלתזמון בזמן אמת יש משאבים מוגבלים, וצריך להשתמש בו בזהירות. במערכת עם n מעבדים, המספר המקסימלי של שרשורי RT פעילים הוא גם n. אם כל המעבדים תפוסים על ידי שרשורי RT אחרים, יכול להיות ששרשורי RT נוספים יצטרכו להמתין (וכך יפספסו את מועדי ההגשה).
כדי לפתור את כל האפשרויות להיפוך העדיפות, אפשר להשתמש בירושה של עדיפות גם ל-binder וגם ל-hwbinder. עם זאת, מכיוון ש-binder נמצא בשימוש נרחב במערכת, הפעלת ירושה של תעדוף לעסקאות של binder עלולה להציף את המערכת בשרשור RT יותר ממה שהיא יכולה לטפל בו.
הרצת בדיקות של תעבורת נתונים
בדיקת הקצב של העברת הנתונים מתבצעת מול קצב העברת הנתונים של עסקאות ב-binder/hwbinder. במערכת שלא עמוסה, בועות זמן אחזור הן נדירות וניתן למזער את ההשפעה שלהן כל עוד מספר החזרות מספיק גבוה.
- בדיקת הקצב של binder נמצאת ב-
system/libhwbinder/vts/performance/Benchmark_binder.cpp. - בדיקת התפוקה של hwbinder נמצאת ב-
system/libhwbinder/vts/performance/Benchmark.cpp.
תוצאות בדיקה
דוגמה לתוצאות של בדיקת תעבורת נתונים בעסקאות עם גדלים שונים של עומסי עבודה:
Benchmark Time CPU Iterations --------------------------------------------------------------------- BM_sendVec_binderize/4 70302 ns 32820 ns 21054 BM_sendVec_binderize/8 69974 ns 32700 ns 21296 BM_sendVec_binderize/16 70079 ns 32750 ns 21365 BM_sendVec_binderize/32 69907 ns 32686 ns 21310 BM_sendVec_binderize/64 70338 ns 32810 ns 21398 BM_sendVec_binderize/128 70012 ns 32768 ns 21377 BM_sendVec_binderize/256 69836 ns 32740 ns 21329 BM_sendVec_binderize/512 69986 ns 32830 ns 21296 BM_sendVec_binderize/1024 69714 ns 32757 ns 21319 BM_sendVec_binderize/2k 75002 ns 34520 ns 20305 BM_sendVec_binderize/4k 81955 ns 39116 ns 17895 BM_sendVec_binderize/8k 95316 ns 45710 ns 15350 BM_sendVec_binderize/16k 112751 ns 54417 ns 12679 BM_sendVec_binderize/32k 146642 ns 71339 ns 9901 BM_sendVec_binderize/64k 214796 ns 104665 ns 6495
- Time (זמן) מציין את זמן הנסיעה הלוך ושוב שנמדד בזמן אמת.
- CPU מציין את הזמן המצטבר שבו מעבדים מתוזמנים לבדיקה.
- חזרות – מספר הפעמים שבהן בוצעה פונקציית הבדיקה.
לדוגמה, למטען ייעודי (payload) באורך 8 בייטים:
BM_sendVec_binderize/8 69974 ns 32700 ns 21296
… הקצב המקסימלי של העברת הנתונים שהמקשר יכול להשיג מחושב לפי הנוסחה הבאה:
קצב העברת נתונים מקסימלי עם עומס נתונים של 8 בייטים = (8 * 21296)/69974 ~= 2.423 b/ns ~= 2.268 Gb/s
אפשרויות בדיקה
כדי לקבל תוצאות בפורמט .json, מריצים את הבדיקה עם הארגומנט --benchmark_format=json:
libhwbinder_benchmark --benchmark_format=json
{
"context": {
"date": "2017-05-17 08:32:47",
"num_cpus": 4,
"mhz_per_cpu": 19,
"cpu_scaling_enabled": true,
"library_build_type": "release"
},
"benchmarks": [
{
"name": "BM_sendVec_binderize/4",
"iterations": 32342,
"real_time": 47809,
"cpu_time": 21906,
"time_unit": "ns"
},
….
}הרצת בדיקות זמן אחזור
בבדיקה של זמן האחזור נמדד הזמן שחלף מהרגע שבו הלקוח מתחיל לאתחל את העסקה, עובר לתהליך הטיפול בשרת ומקבל את התוצאה. הבדיקה גם מחפשת התנהגויות ידועות של מתזמן שעלולות להשפיע לרעה על זמן האחזור של העסקאות, כמו מתזמן שלא תומך בירושה של תעדוף או לא מתייחס לדגל הסנכרון.
- בדיקת זמן האחזור של ה-binder נמצאת ב-
frameworks/native/libs/binder/tests/schd-dbg.cpp. - בדיקת זמן האחזור של hwbinder נמצאת ב-
system/libhwbinder/vts/performance/Latency.cpp.
תוצאות בדיקה
בתוצאות (בפורמט .json) מוצגים נתונים סטטיסטיים לגבי זמן האחזור הממוצע/הטוב ביותר/הגרוע ביותר ומספר הדד-ליינים שלא נענו.
אפשרויות בדיקה
בבדיקות זמן האחזור נלקחות בחשבון האפשרויות הבאות:
| הוראה | תיאור |
|---|---|
-i value |
מציינים את מספר החזרות. |
-pair value |
מציינים את מספר זוגות התהליכים. |
-deadline_us 2500 |
מציינים את מועד ההגשה בשעות ארה"ב. |
-v |
קבלת פלט מפורט (לניפוי באגים). |
-trace |
עצירת המעקב כשמתרחש אירוע של הגעה למועד אחרון. |
בקטעים הבאים מפורטות כל האפשרויות, מתוארים אופן השימוש בהן ומופיעות תוצאות לדוגמה.
ציון חזרות
דוגמה עם מספר רב של חזרות ופלט מפורט מושבת:
libhwbinder_latency -i 5000 -pair 3
{
"cfg":{"pair":3,"iterations":5000,"deadline_us":2500},
"P0":{"SYNC":"GOOD","S":9352,"I":10000,"R":0.9352,
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}
},
"P1":{"SYNC":"GOOD","S":9334,"I":10000,"R":0.9334,
"other_ms":{ "avg":0.19, "wst":2.9 , "bst":0.055, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":3.1 , "bst":0.066, "miss":1, "meetR":0.9998}
},
"P2":{"SYNC":"GOOD","S":9369,"I":10000,"R":0.9369,
"other_ms":{ "avg":0.19, "wst":4.8 , "bst":0.055, "miss":6, "meetR":0.9988},
"fifo_ms": { "avg":0.15, "wst":1.8 , "bst":0.067, "miss":0, "meetR":1}
},
"inheritance": "PASS"
}תוצאות הבדיקה האלה מראות את הפרטים הבאים:
"pair":3- יצירת זוג אחד של לקוח ושרת.
"iterations": 5000- כולל 5,000 חזרות.
"deadline_us":2500- הזמן הקצוב לביצוע הוא 2,500us (2.5ms). רוב העסקאות צפויות לעמוד בערך הזה.
"I": 10000- מחזור בדיקה יחיד כולל שתי (2) עסקאות:
- עסקה אחת בעדיפות רגילה (
CFS other) - עסקה אחת לפי עדיפות בזמן אמת (
RT-fifo)
- עסקה אחת בעדיפות רגילה (
"S": 9352- 9,352 מהעסקאות מסונכרנות באותו מעבד.
"R": 0.9352- היחס שבו הלקוח והשרת מסתנכרנים יחד באותו מעבד.
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996}- המקרה הממוצע (
avg), המקרה הגרוע ביותר (wst) והמקרה הטוב ביותר (bst) לכל העסקאות שהונפקו על ידי מבצע קריאה בעדיפות רגילה. שתי עסקאותmissמועד היעד, כך שיחס העמידה בלוחות הזמנים (meetR) הוא 0.9996. "fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}- דומה ל-
other_ms, אבל לעסקאות שהלקוח הנפיק עם תעדוףrt_fifo. סביר להניח (אבל לא חובה) שהתוצאה שלfifo_msתהיה טובה יותר מזו שלother_ms, עם ערכים נמוכים יותר שלavgו-wstועםmeetRגבוה יותר (ההבדל יכול להיות משמעותי עוד יותר כשיש עומס ברקע).
הערה: עומס ברקע עלול להשפיע על תוצאת הקצב וכן על הטופל (tuple) other_ms בבדיקת זמן האחזור. רק התג fifo_ms עשוי להציג תוצאות דומות, כל עוד לעומס הרקע יש עדיפות נמוכה יותר מאשר ל-RT-fifo.
ציון ערכי הצמד
כל תהליך לקוח משויך לתהליך שרת ייעודי לאותו לקוח, וניתן לתזמן כל זוג בנפרד לכל מעבד. עם זאת, העברת המעבד לא אמורה להתרחש במהלך עסקה כל עוד הדגל SYNC הוא honor.
חשוב לוודא שהמערכת לא עמוסה מדי. זמן אחזור גבוה צפוי במערכת עמוסה, אבל תוצאות הבדיקה של מערכת עמוסה לא מספקות מידע שימושי. כדי לבדוק מערכת עם לחץ גבוה יותר, משתמשים ב--pair
#cpu-1 (או ב--pair #cpu בזהירות). בדיקה באמצעות -pair n עם n > #cpu יוצרת עומס יתר על המערכת ומייצרת מידע חסר תועלת.
ציון ערכי מועדים אחרונים
אחרי בדיקות מקיפות של תרחישי משתמשים (הרצת בדיקת זמן האחזור במוצר מתאים), קבענו ש-2.5ms הוא המועד האחרון שצריך לעמוד בו. באפליקציות חדשות עם דרישות גבוהות יותר (כמו 1,000 תמונות לשנייה), ערך המועד האחרון ישתנה.
ציון פלט מפורט
שימוש באפשרות -v מציג פלט מפורט. דוגמה:
libhwbinder_latency -i 1 -v-------------------------------------------------- service pid: 8674 tid: 8674 cpu: 1 SCHED_OTHER 0-------------------------------------------------- main pid: 8673 tid: 8673 cpu: 1 -------------------------------------------------- client pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0-------------------------------------------------- fifo-caller pid: 8677 tid: 8678 cpu: 0 SCHED_FIFO 99 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 ??? 99-------------------------------------------------- other-caller pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 SCHED_OTHER 0
- שרשור השירות נוצר עם עדיפות
SCHED_OTHERופועל ב-CPU:1עםpid 8674. - לאחר מכן,
fifo-callerמתחיל את העסקה הראשונה. כדי לטפל בעסקה הזו, ה-hwbinder משדרג את העדיפות של השרת (pid: 8674 tid: 8676) ל-99 ומסמן אותו גם ככיתת תזמון זמנית (מודפסת כ-???). לאחר מכן, מתזמן המשימות מעביר את תהליך השרת ל-CPU:0כדי להריץ אותו ומסנכרן אותו עם אותו מעבד של הלקוח. - למבצע הקריאה החוזרת של העסקה השנייה יש עדיפות
SCHED_OTHER. השרת מוריד את רמת הגרסה שלו ומטפל בקריאה עם עדיפותSCHED_OTHER.
שימוש ב-trace לניפוי באגים
אפשר לציין את האפשרות -trace כדי לנפות באגים בבעיות שקשורות לזמן אחזור. כשמשתמשים בו, בדיקת זמן האחזור מפסיקה את ההקלטה ביומן המעקב ברגע שזוהתה זמני אחזור ארוכים. דוגמה:
atrace --async_start -b 8000 -c sched idle workq binder_driver sync freqlibhwbinder_latency -deadline_us 50000 -trace -i 50000 -pair 3deadline triggered: halt ∓ stop trace log:/sys/kernel/debug/tracing/trace
הרכיבים הבאים יכולים להשפיע על זמן האחזור:
- Android build mode. בדרך כלל, המצב Eng איטי יותר מהמצב userdebug.
- Framework. איך שירות המסגרת משתמש ב-
ioctlכדי להגדיר את הקישור? - מַנהל קישורים. האם הנהג תומך בנעילה ברמת פירוט גבוהה? האם הוא מכיל את כל התיקונים לשיפור הביצועים?
- גרסת הליבה. ככל שהליבה תהיה בעלת יכולות טובות יותר בזמן אמת, כך התוצאות יהיו טובות יותר.
- Kernel config. האם קובץ התצורה של הליבה מכיל הגדרות
DEBUGכמוDEBUG_PREEMPTו-DEBUG_SPIN_LOCK? - מתזמן הליבה. האם לליבה יש מתזמן שמתחשב באנרגיה (EAS) או מתזמן של עיבוד מרובים הטרוגני (HMP)? האם מנהלי התקנים של הליבה (
cpu-freqdriver,cpu-idledriver,cpu-hotplugוכו') משפיעים על מתזמן המשימות?