
Android には、Android 仮想化フレームワークの実装に必要なコンポーネントすべてのリファレンス実装が用意されています。現在、この実装は ARM64 に限定されています。このページでは、フレームワーク アーキテクチャについて説明します。
背景
Arm アーキテクチャでは、最大 4 つの例外レベルが許可されています。例外レベル 0(EL0)は最小の権限、例外レベル 3(EL3)は最大の権限です。Android コードベースの大部分(すべてのユーザー空間コンポーネント)は EL0 で実行されます。一般に「Android」と呼ばれるものの残りは、EL1 で実行される Linux カーネルです。
EL2 レイヤにより、メモリとデバイスを EL1 / EL0 で個々の pVM に分離できる、強力な機密性と完全性が保証されたハイパーバイザの導入が可能になります。
ハイパーバイザ
保護されたカーネルベースの仮想マシン(pKVM)は Linux KVM ハイパーバイザをベースに構築されており、作成時に「保護」とマークされたゲスト仮想マシンで実行されるペイロードへのアクセスを制限する機能で拡張されています。
KVM / arm64 は、特定の CPU 機能(Virtualization Host Extensions(VHE)(ARMv8.1 以降))の可用性に応じて、さまざまな実行モードをサポートします。これらのモードの一つ(一般的には VHE 以外のモード)では、ハイパーバイザ コードは起動中にカーネル イメージから分割されて EL2 にインストールされますが、カーネル自体は EL1 で実行されます。KVM の EL2 コンポーネントは Linux コードベースの一部ですが、複数の EL1 間の切り替えを処理する小さなコンポーネントです。ハイパーバイザ コンポーネントは Linux でコンパイルされますが、vmlinux イメージの別の専用メモリ セクションに存在します。pKVM は、Android ホストカーネルとユーザー空間に制限を加え、ゲストメモリとハイパーバイザへのホストアクセスを制限できる新機能でハイパーバイザ コードを拡張することにより、この設計を活用します。
pKVM ベンダー モジュール
pKVM ベンダー モジュールは、入出力メモリ管理ユニット(IOMMU)ドライバなどのデバイス固有の機能を含むハードウェア固有のモジュールです。これらのモジュールを使用すると、pKVM への例外レベル 2(EL2)のアクセスを必要とするセキュリティ機能を移植できます。
pKVM ベンダー モジュールの実装と読み込みの方法については、pKVM ベンダー モジュールを実装するを参照してください。
起動手順
次の図は、pKVM の起動手順を示しています。
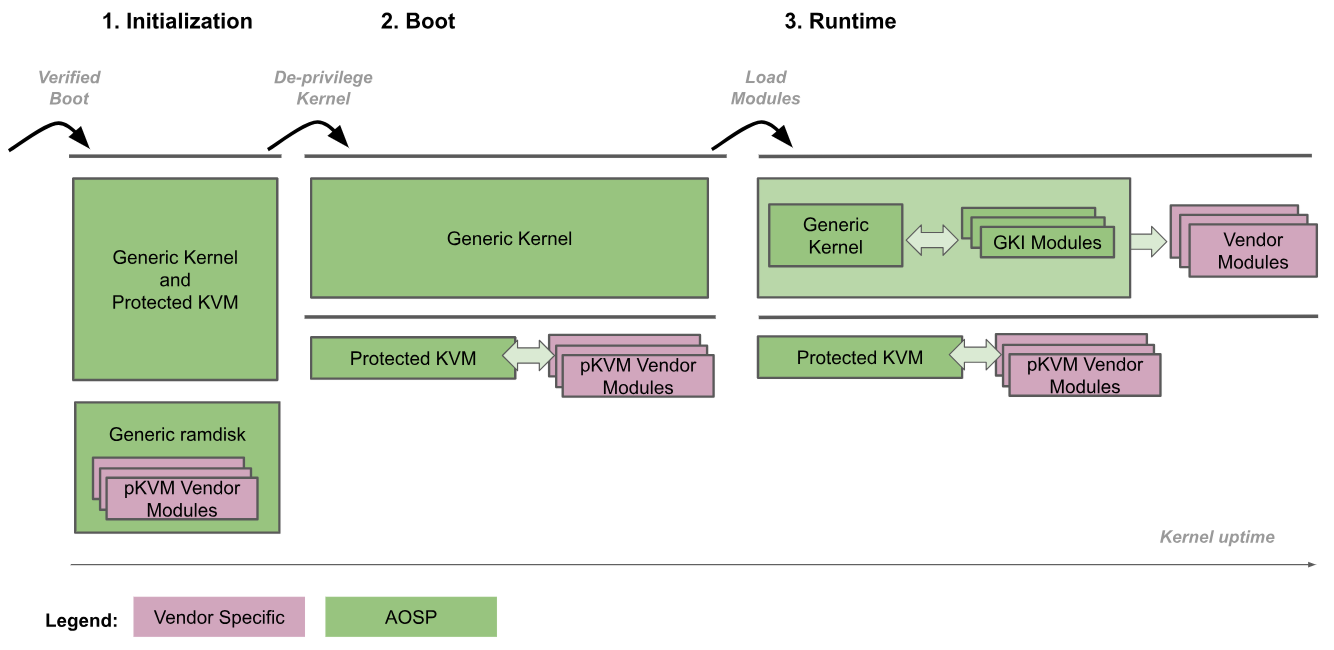
- ブートローダーは、EL2 で汎用カーネルに入ります。
- 汎用カーネルは、pKVM とそのモジュールが EL2 で実行を続けている間に、EL2 で実行されていることを検出し、EL1 の権限を解除します。さらに、この時点で pKVM ベンダー モジュールが読み込まれます。
- 汎用カーネルは、通常どおり起動し、ユーザー空間に到達するまで必要なデバイス ドライバをすべて読み込みます。この時点では、pKVM はステージ 2 のページテーブルを処理します。
この起動手順ではブートローダーを信頼して、アーリーブート時にのみカーネル イメージの整合性を維持します。カーネルが非特権である場合、ハイパーバイザによって信頼されているとは見なされなくなります。ハイパーバイザは、カーネルが侵害された場合でも自身を保護する必要があります。
Android カーネルとハイパーバイザを同じバイナリ イメージに含めることで、両者間で非常に緊密に結合された通信インターフェースを実現できます。この密結合により 2 つのコンポーネントのアトミックな更新が保証されるため、コンポーネント間のインターフェースを安定させる必要がなくなり、長期的なメンテナンス性を損なうことなく高い柔軟性を得ることができます。また、密結合により、ハイパーバイザによって提供されるセキュリティの保証に影響を与えることなく両方のコンポーネントが連携できる場合は、パフォーマンスの最適化が可能になります。
さらに、Android エコシステムに GKI を導入すると、カーネルと同じバイナリで pKVM ハイパーバイザを Android デバイスに自動的にデプロイできます。
CPU メモリアクセス保護
Arm アーキテクチャは、2 つの独立したステージに分割されたメモリ管理ユニット(MMU)を指定します。どちらも、メモリのさまざまな部分に対してアドレス変換とアクセス制御を実装するために使用できます。ステージ 1 MMU は EL1 によって制御され、最初のレベルのアドレス変換を可能にします。この MMU は、各ユーザー空間プロセスと独自の仮想アドレス空間に提供される仮想アドレス空間を管理するために、Linux によって使用されます。
ステージ 2 MMU は EL2 によって制御され、ステージ 1 MMU の出力アドレスに 2 つ目のアドレス変換を適用できるため、物理アドレス(PA)が得られます。ステージ 2 の変換は、ハイパーバイザがすべてのゲスト VM からのメモリアクセスを制御および変換するために使用できます。図 2 に示すように、両方の変換ステージを有効にすると、ステージ 1 の出力アドレスが中間物理アドレス(IPA)と呼ばれます。なお、仮想アドレス(VA)は IPA に変換され、その後 PA に変換されます。
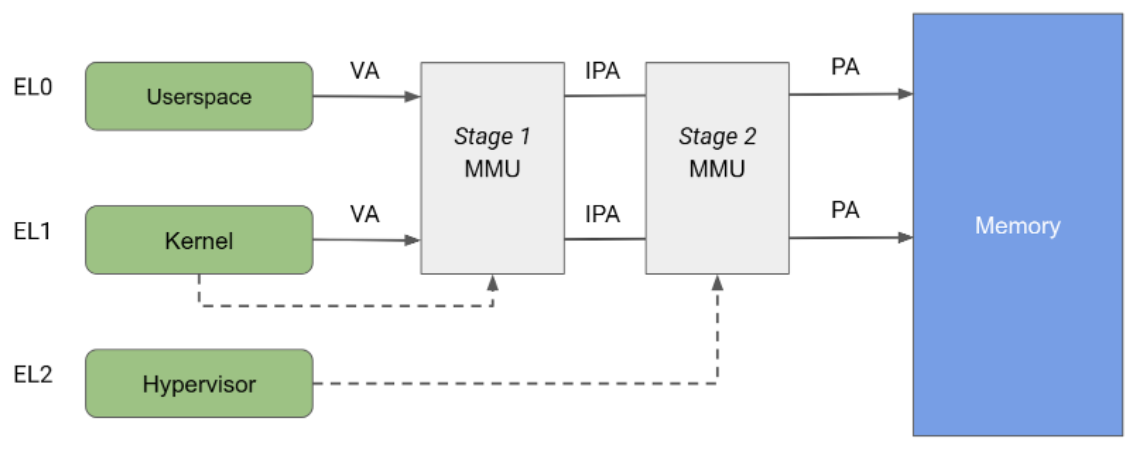
これまで、KVM は、ゲストの実行中はステージ 2 の変換を有効にして実行し、ホスト Linux カーネルの実行中はステージ 2 を無効にして実行していました。このアーキテクチャでは、ホストステージ 1 MMU からメモリアクセスがステージ 2 MMU を通過するため、ホストからゲストメモリ ページへの無制限アクセスが許可されます。一方、pKVM はホスト コンテキストでもステージ 2 の保護を有効にし、ホストではなくハイパーバイザがゲストメモリ ページを保護します。
KVM はステージ 2 でアドレス変換を最大限に活用して、ゲストの複雑な IPA / PA マッピングを実装します。これにより、物理的に断片化されたにもかかわらず、ゲストのメモリが連続的であるかのように感じられます。ただし、ホストのステージ 2 MMU の使用はアクセス制御のみに制限されます。ホストステージ 2 が ID マッピングされ、ホスト IPA 空間の連続メモリが PA 空間で連続するようになります。このアーキテクチャでは、ページテーブルで大規模なマッピングを使用できるため、変換用ルックアサイド バッファ(TLB)の負荷が軽減されます。ID マッピングは PA でインデックスに登録できるため、ホストステージ 2 はページテーブルでページの所有権を直接追跡する場合にも使用されます。
ダイレクト メモリアクセス(DMA)の保護
前述のように、ゲストメモリを保護するには、CPU ページテーブルで Linux ホストからゲストページのマッピングを解除する作業が必要ですが、これだけでは不十分です。pKVM も、ホストカーネルの制御下にある DMA 対応デバイスからのメモリアクセスや、悪意のあるホストによって DMA 攻撃が開始される可能性から保護する必要があります。このようなデバイスがゲストメモリにアクセスできないようにするには、図 3 に示すように、pKVM でシステム内のすべての DMA 対応デバイスに対する入出力メモリ管理ユニット(IOMMU)ハードウェアが必要になります。
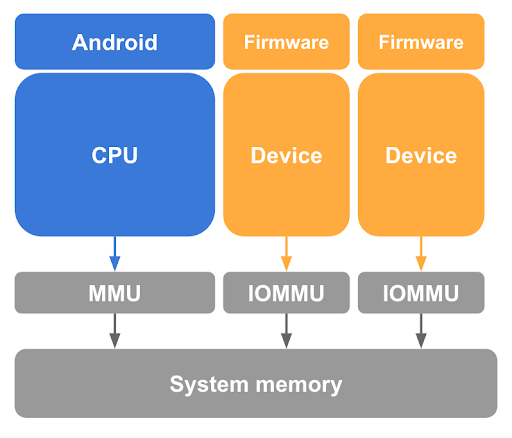
少なくとも、IOMMU ハードウェアは、物理メモリに対するデバイスの読み取り / 書き込みアクセス権をページ粒度で付与する、または取り消す手段を提供します。ただし、この IOMMU ハードウェアは、ID マッピングされたステージ 2 を想定しているため、pVM でのデバイスの使用を制限します。
仮想マシンを分離するには、異なるエンティティに代わって生成されたメモリ トランザクションを IOMMU で区別できるようにして、適切なページテーブルのセットを変換に使用できるようにする必要があります。
さらに、EL2 で SoC 固有のコードの量を減らすことは、pKVM の全体的な信頼できるコンピューティング ベース(TCB)を削減するための重要な戦略であり、ハイパーバイザに IOMMU ドライバを含めることとは反対のことです。この問題を軽減するために、EL1 のホストは、電源管理、初期化、および必要に応じて割り込み処理などの補助 IOMMU 管理タスクを行います。
ただし、ホストがデバイスの状態を制御するようにすると、IOMMU ハードウェアのプログラミング インターフェースに追加の要件が加えられ、デバイスのリセット後など、他の手段によってアクセス許可チェックがバイパスできなくなります。
分離と直接割り当ての両方を可能にする Arm デバイス用の、標準的で十分にサポートされている IOMMU は、Arm System Memory Management Unit(SMMU)アーキテクチャです。このアーキテクチャは、推奨されるリファレンス ソリューションです。
メモリの所有権
起動時、非ハイパーバイザのすべてのメモリがホストによって所有されていると見なされ、ハイパーバイザによって追跡されます。pVM が生成されると、ホストはメモリページを提供して起動できるようにします。ハイパーバイザはこれらのページの所有権をホストから pVM に移行します。そのため、ハイパーバイザはホストのステージ 2 のページテーブルにアクセス制御の制限を設定し、ページに再びアクセスできないようにして、ゲストに機密性を提供します。
ホストとゲスト間の通信は、それらの間で制御されたメモリ共有によって可能になります。ゲストは、ハイパーコールを使用して、ページの一部をホストと共有できます。ハイパーバイザはホストステージ 2 のページテーブルでこれらのページを再マッピングするよう指示されます。同様に、ホストと TrustZone 間の通信は、メモリの共有やレンディング オペレーションによって可能になります。これらのオペレーションはすべて、Firmware Framework for Arm(FF-A)仕様を使用して pKVM によって密にモニタリングおよび管理されます。
pVM のメモリ要件は時間が経過しても変更が可能なため、発信者に属する特定のページの所有権を放棄してホストに返すことのできるハイパーコールが実現します。実際にはこのハイパーコールは、virtio バルーン プロトコルとともに使用され、VMM が pVM からメモリを戻すようリクエストし、pVM は放棄されたページについて特定の方法で VMM に通知できます。
ハイパーバイザは、システム内のすべてのメモリページの所有権を追跡し、それらのページが他のエンティティに共有または貸与されているかを追跡します。この状態トラッキングのほとんどは、ホストとゲストのステージ 2 のページテーブルに関連付けられたメタデータを使用して行われます。使用されるページテーブル エントリ(PTE)の予約済みビットは、その名前が示すようにソフトウェア使用のために予約されています。
ホストは、ハイパーバイザによってアクセス不能にされたページにアクセスしないようにする必要があります。不正なホストアクセスが発生すると、ハイパーバイザによって同期例外がホストに挿入され、責任のあるユーザー空間タスクが SEGV 信号を受信するか、ホストカーネルがクラッシュする可能性があります。偶発的なアクセスを防ぐため、ゲストに提供されたページは、ホストカーネルによってスワップまたは結合の対象外になります。
割り込み処理とタイマー
割り込みは、ゲストがデバイスとやり取りする方法、およびプロセッサ間割り込み(IPI)が主要な通信メカニズムである CPU 間の通信に不可欠な部分です。KVM モデルは、すべての仮想割り込み管理を EL1 のホストに委任します。EL1 はその目的のために、ハイパーバイザの信頼できない部分として動作します。
pKVM は、既存の KVM コードに基づく完全な Generic Interrupt Controller バージョン 3(GICv3)エミュレーションを提供します。タイマーと IPI は、この信頼できないエミュレーション コードの一部として処理されます。
GICv3 のサポート
EL1 と EL2 間のインターフェースでは、割り込みに関連するハイパーバイザ レジスタのコピーを含め、完全な割り込み状態が EL1 ホストから見えるようにする必要があります。この可視性は通常、仮想 CPU(vCPU)ごとに 1 つの共有メモリ領域を使用して実現されます。
システム レジスタのランタイム サポートコードは、ソフトウェアで生成される割り込みレジスタ(SGIR)と無効化割り込みレジスタ(DIR)のレジスタ トラップのみをサポートするよう簡略化できます。このアーキテクチャでは、これらのレジスタが常に EL2 にトラップされることが必須ですが、他のトラップはこれまでのところ、エラッタを軽減するためにのみ有効でした。それ以外はすべてハードウェアで処理されます。
MMIO 側では、すべてが EL1 でエミュレートされ、KVM の現在のインフラストラクチャがすべて再利用されます。最後に、Wait for Interrupt(WFI)が常に EL1 にリレーされます。これは、KVM で使用される基本的なスケジューリング プリミティブの一つであるためです。
タイマーのサポート
仮想タイマーのコンパレータ値がトラップ WFI ごとに EL1 に公開されて、vCPU がブロックされている間に EL1 がタイマー割り込みを挿入できるようにする必要があります。物理タイマーは完全にエミュレートされ、すべてのトラップは EL1 にリレーされます。
MMIO の処理
仮想マシンモニター(VMM)と通信し、GIC エミュレーションを実行するには、MMIO トラップを EL1 のホストにリレーして、再度トリアージする必要があります。pKVM には、次のものが必要です。
- IPA とアクセスのサイズ
- 書き込みの場合のデータ
- トラップ点での CPU のエンディアン
また、汎用レジスタ(GPR)が送信元 / 宛先であるトラップは、抽象転送疑似レジスタを使用してリレーされます。
ゲスト インターフェース
ゲストは、ハイパーコールとトラップされたリージョンへのメモリアクセスの組み合わせを使用して、保護されたゲストと通信できます。ハイパーコールは、SMCCC 標準に従って公開され、範囲は KVM によるベンダー割り当て用に予約されます。次のハイパーコールは、pKVM ゲストにとって特に重要です。
一般的なハイパーコール
- PSCI は、ゲストがオンライン化、オフライン化、システム シャットダウンなどの vCPU のライフサイクルを制御するための標準メカニズムを提供します。
- TRNG は、ゲストが EL3 への呼び出しを中継する pKVM からエントロピーをリクエストするための標準メカニズムを提供します。このメカニズムは、特に、ハードウェアの乱数ジェネレータ(RNG)の仮想化でホストを信頼できない場合に役立ちます。
pKVM ハイパーコール
- ホストとのメモリ共有。すべてのゲストメモリは、最初はホストからアクセスできませんが、共有メモリ通信や、共有バッファに依存する準仮想化デバイスにはホストアクセスが必要です。ホストとページを共有または共有解除するハイパーコールによって、ゲストは handshake を必要とせずに、メモリのどの部分を Android の他の部分からアクセス可能にするかを正確に決定できます。
- ホストへのメモリ放棄。通常、すべてのゲストメモリは、破棄されるまでゲストに属します。この状態は、時間の経過とともにメモリ要件が変わる長期的な VM にとっては不適切である場合があります。
relinquishハイパーコールにより、ゲストはゲストの解除を求めなくても、ページの所有権をホストに明示的に戻すことができます。 - ホストへのメモリアクセスのトラップ。これまでの形の場合、KVM ゲストが有効なメモリ領域に対応しないアドレスにアクセスすると、vCPU スレッドはホストに終了し、アクセスは通常 MMIO に使用され、VMM によってユーザー空間でエミュレートされます。この処理を容易にするために、pKVM では、アドレス、登録パラメータ、場合によってはコンテンツなど、違反している命令の詳細をホストにアドバタイズする必要があります。これにより、トラップが予期されていなかった場合、保護対象となるゲストから機密データが意図せずに公開される可能性があります。pKVM は、ゲストが以前にハイパーコールを呼び出して、障害のある IPA 範囲をホストへのトラップバックが許可されているアクセスとして特定していない限り、これらの障害を致命的なものとして扱うことでこの問題を解決します。このソリューションは、MMIO ガードと呼ばれます。
仮想 I/O デバイス(virtio)
virtio は、準仮想化デバイスを実装して操作するための一般的なポータブルかつ成熟した標準です。保護対象ゲストに公開されるデバイスのほとんどは、virtio を使用して実装されています。virtio は、保護対象ゲストと Android の他の部分間の通信に使用される vsock 実装もサポートしています。
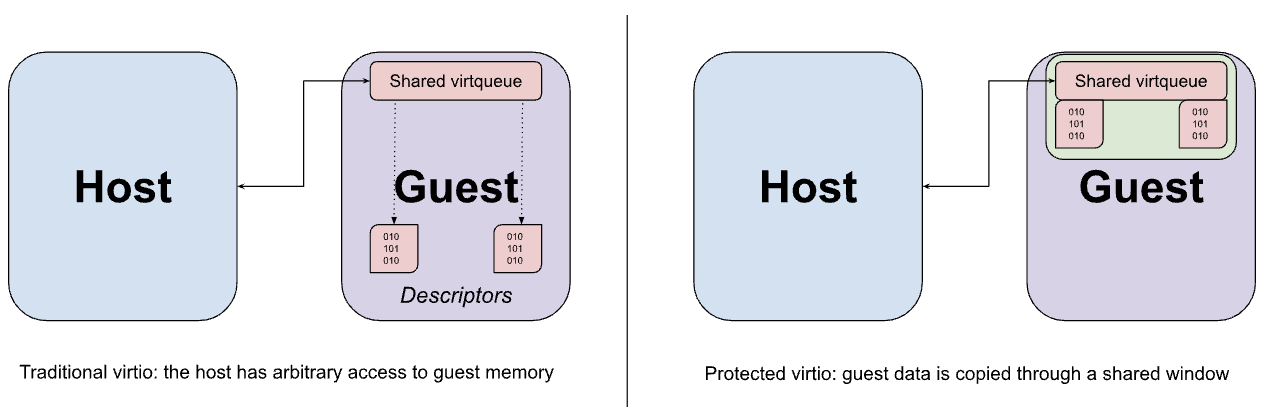
virtio デバイスは通常、VMM によってホストのユーザー空間に実装されます。VMM は、ゲストから virtio デバイスの MMIO インターフェースへのトラップされたメモリアクセスをインターセプトし、想定される動作をエミュレートします。MMIO アクセスは、デバイスにアクセスするたびに VMM との間の往復を必要とするため、比較的コストがかかります。そのため、デバイスとゲスト間の実際のデータ転送のほとんどは、メモリ内の一連の virtqueue を使用して行われます。virtio の重要な前提は、ホストがゲストメモリに任意にアクセスできることです。この前提条件は、virtqueue の設計に明確に表れており、デバイス エミュレーションが直接アクセスしようとしているゲスト内のバッファへのポインタが含まれている場合があります。
前述のメモリ共有ハイパーコールは、ゲストからホストへの virtio データバッファの共有に使用できますが、この共有は必然的にページ粒度で行われます。バッファサイズがページのサイズを下回る場合、最終的に必要以上に多くのデータが公開される可能性があります。代わりにゲストは、共有メモリの固定ウィンドウから virtqueue と対応するデータバッファの両方を割り当て、必要に応じてウィンドウとの間でデータをコピー(バウンス)するように構成されます。
TrustZone の操作
ゲストは TrustZone を直接操作することはできませんが、ホストは安全な環境に SMC 呼び出しを発行できる必要があります。これらの呼び出しは、ホストがアクセスできない物理的にアドレス指定されたメモリバッファを指定できます。安全なソフトウェアは通常、バッファのアクセシビリティを認識していないため、悪意のあるホストがこのバッファを使用して混乱した代理人攻撃(DMA 攻撃に類似)を実行する可能性があります。このような攻撃を防ぐため、pKVM はすべてのホスト SMC 呼び出しを EL2 にトラップし、EL3 でホストとセキュア モニター間のプロキシとして機能します。
ホストからの PSCI 呼び出しは、最小限の変更で EL3 ファームウェアに転送されます。具体的には、CPU がオンラインになるか一時停止から再開するためのエントリ ポイントが書き換えられ、ステージ 2 のページテーブルが EL2 でインストールされてから、EL1 のホストに戻るようにします。この保護は、起動時に pKVM によって適用されます。
このアーキテクチャは、可能であれば最新バージョンの TF-A を EL3 ファームウェアとして使用することで、PSCI をサポートする SoC に依存します。
Firmware Framework for Arm(FF-A)は、特に、安全なハイパーバイザが存在する場合に、通常の環境と安全な環境の間のインタラクションを標準化します。この仕様の大部分は、共通のメッセージ形式と、基盤となるページに明確に定義された権限モデルの両方を使用して、安全な環境とメモリを共有するメカニズムを定義しています。pKVM は FF-A メッセージをプロキシして、ホストが十分な権限のないセキュアサイドとのメモリ共有を試みないようにします。
このアーキテクチャは、メモリアクセス モデルを適用する安全な環境ソフトウェアに依存しています。これにより、安全な環境で実行されている信頼できるアプリおよびその他のソフトウェアは、安全な環境が独占的に所有している場合か、FF-A を使用して明示的に共有している場合のみ、メモリにアクセスできるようになります。S-EL2 を搭載したシステムでは、安全な環境のステージ 2 のページテーブルを維持する Hafnium などのセキュア パーティション マネージャー コア(SPMC)によってメモリアクセス モデルを適用する必要があります。S-EL2 のないシステムでは、TEE は代わりにステージ 1 のページテーブルを介してメモリアクセス モデルを適用できます。
EL2 への SMC 呼び出しが PSCI 呼び出しでも FF-A 定義のメッセージでもない場合、未処理の SMC は EL3 に転送されます。(必然的に信頼できる)安全なファームウェアは pVM の分離を維持するために必要な注意事項を理解しているため、未処理の SMC を安全に処理できると想定されています。
仮想マシンモニター
crosvm は Linux の KVM インターフェースを介して仮想マシンを実行する仮想マシンモニター(VMM)です。crosvm 独自の特長は安全性を重視している点で、Rust プログラミング言語と仮想デバイス周辺のサンドボックスを使用してホストカーネルを保護します。crosvm について詳しくは、こちらの公式ドキュメントをご覧ください。
ファイル記述子と ioctl
KVM は、KVM API を構成する ioctl を使用して /dev/kvm キャラクター デバイスをユーザー空間に公開します。ioctl は次のカテゴリに属します。
- システム ioctl は、KVM サブシステム全体に影響するグローバル属性に対するクエリの実行と設定を行い、pVM を作成します。
- VM ioctl は、仮想 CPU(vCPU)とデバイスを作成する属性に対するクエリの実行と設定を行い、メモリ レイアウト、仮想 CPU(vCPU)とデバイスの数など、pVM 全体に影響します。
- vCPU ioctl は、単一の仮想 CPU の動作を制御する属性に対するクエリの実行と設定を行います。
- デバイス ioctl は、単一の仮想デバイスの動作を制御する属性に対するクエリの実行と設定を行います。
各 crosvm プロセスは、仮想マシンのインスタンスを 1 つのみ実行します。このプロセスでは、KVM_CREATE_VM システム ioctl を使用して、pVM ioctl の発行に使用できる VM ファイル記述子を作成します。VM FD の KVM_CREATE_VCPU または KVM_CREATE_DEVICE ioctl は、vCPU / デバイスを作成し、新しいリソースを指すファイル記述子を返します。vCPU またはデバイス FD の ioctl を使用すると、VM FD の ioctl を使用して作成されたデバイスを制御できます。vCPU の場合は、ゲストコードを実行するという重要なタスクがあります。
内部的には、crosvm はエッジによってトリガーされる epoll インターフェースを使用して、VM のファイル記述子をカーネルに登録します。いずれかのファイル記述子で新しいイベントが保留になるたびに、カーネルは crosvm に通知します。
pKVM に、KVM_CAP_ARM_PROTECTED_VM という新機能が追加されました。この機能を使用すると、pVM 環境に関する情報を取得し、VM に対して保護モードを設定できます。--protected-vm フラグが渡された場合、crosvm は pVM の作成中にこの機能を使用して、pVM ファームウェア用の適切な量のメモリに対してクエリの実行と予約を行い、保護モードを有効にします。
メモリ割り当て
VMM の主な役割の一つは、VM のメモリを割り当て、メモリ レイアウトを管理することです。crosvm では、以下の表で大まかに説明される固定メモリ レイアウトが生成されます。
| 通常モードの FDT | PHYS_MEMORY_END - 0x200000
|
| 空き容量 | ...
|
| RAM ディスク | ALIGN_UP(KERNEL_END, 0x1000000)
|
| カーネル | 0x80080000
|
| ブートローダー | 0x80200000
|
| BIOS モードの FDT | 0x80000000
|
| 物理メモリベース | 0x80000000
|
| pVM ファームウェア | 0x7FE00000
|
| デバイスメモリ | 0x10000 - 0x40000000
|
物理メモリが mmap で割り当てられ、そのメモリが VM に提供されてメモリ領域(memslots)に KVM_SET_USER_MEMORY_REGION ioctl が設定されます。そのため、すべてのゲスト pVM メモリは、それを管理する crosvm インスタンスに結び付けられており、ホストの空きメモリが不足し始めると、プロセスが強制終了される(VM が終了する)可能性があります。VM が停止すると、ハイパーバイザによってメモリが自動的にワイプされ、ホストカーネルに戻されます。
通常の KVM では、VMM はすべてのゲストメモリへのアクセスを保持します。pKVM を使用すると、ゲストに提供されるときに、ゲストメモリはホストの物理アドレス空間からマッピングされなくなります。唯一の例外は、virtio デバイスなど、ゲストによって明示的に共有されるメモリです。
ゲストのアドレス空間の MMIO リージョンは、マッピングされないままになります。ゲストによるこれらのリージョンへのアクセスはトラップされ、VM FD で I/O イベントが発生します。このメカニズムは、仮想デバイスを実装するために使用されます。保護モードでは、ゲストは、アドレス空間のリージョンがハイパーコールを使用して MMIO に使用されていることを確認し、偶発的な情報漏洩のリスクを軽減する必要があります。
予約
各仮想 CPU は POSIX スレッドで表され、ホストの Linux スケジューラによってスケジュールされます。スレッドが vCPU FD で KVM_RUN ioctl を呼び出します。これにより、ハイパーバイザがゲスト vCPU のコンテキストに切り替わります。ホスト スケジューラは、ゲスト コンテキストで費やされた時間を、対応する vCPU のスレッドによって使用された時間として考慮します。KVM_RUN は、I/O、割り込みの終了、vCPU の停止など、VMM が処理する必要があるイベントがある場合に返されます。VMM がイベントを処理し、KVM_RUN を再度呼び出します。
KVM_RUN の間、プリエンプティブルではない EL2 ハイパーバイザ コードの実行を除き、スレッドはホスト スケジューラによってプリエンプティブルのままです。ゲスト pVM 自体には、この動作を制御するためのメカニズムはありません。
すべての vCPU スレッドは、他のユーザー空間タスクと同様にスケジュールされるため、すべての標準 QoS メカニズムの対象になります。具体的には、vCPU スレッドごとに、物理 CPU に関連付ける、cpuset に配置する、使用率クランプを使用してブーストまたは上限を設定する、優先度 / スケジューリング ポリシーを変更する、といったことが可能です。
仮想デバイス
crosvm では、次のようなさまざまなデバイスがサポートされています。
- 複合ディスク イメージ、読み取り専用、読み取り / 書き込み用の virtio-blk
- ホストとの通信用の vhost-vsock
- virtio トランスポートとしての virtio-pci
- pl030 リアルタイム クロック(RTC)
- シリアル通信用の 16550a UART
pVM ファームウェア
pVM ファームウェア(pvmfw)は、物理デバイスのブート ROM と同様に、pVM で実行される最初のコードです。pvmfw の主な目的は、セキュアブートをブートストラップして pVM の一意のシークレットを導出することです。OS が crosvm でサポートされていて、適切に署名されている限り、pvmfw は Microdroid などの特定の OS での使用に限定されません。
pvmfw バイナリは、同じ名前のフラッシュ パーティションに保存され、OTA を使用して更新されます。
デバイスの起動
pKVM 対応デバイスの起動手順には、次の一連の手順が追加されています。
- Android ブートローダー(ABL)が、pvmfw をそのパーティションからメモリに読み込んで、イメージを検証します。
- ABL はルート オブ トラストからデバイス識別子構成エンジン(DICE)シークレット(複合デバイス識別子(CDI)と DICE 証明書チェーン)を取得します。
- ABL は pvmfw に必要な CDI を取得し、この CDI を pvmfw バイナリに追加します。
- ABL は
linux,pkvm-guest-firmware-memory予約済みメモリ リージョン ノードを DT に追加し、pvmfw バイナリの場所とサイズ、および前のステップで導出したシークレットを記述します。 - ABL が制御を Linux に渡し、Linux が pKVM を初期化します。
- pKVM は、pvmfw メモリのリージョンをホストのステージ 2 のページテーブルからマッピング解除し、デバイスの稼働時間全体を通してホスト(およびゲスト)から保護します。
デバイスの起動後、Microdroid ドキュメントの起動シーケンスのセクションの手順で Microdroid が起動します。
pVM の起動
pVM の作成時、crosvm(または別の VMM)は、ハイパーバイザによって pvmfw イメージが取り込まれるのに十分の大きさを持つ memslot を作成する必要があります。また、初期値を設定できるレジスタのリストでも VMM が制限されます(プライマリ vCPU の場合は x0~x14、セカンダリ vCPU の場合はなし)。残りのレジスタは予約済みで、hypervisor-pvmfw ABI の一部です。
pVM が実行されると、ハイパーバイザは最初にプライマリ vCPU の制御を pvmfw に渡します。このファームウェアでは、crosvm で AVB 署名付きカーネル(ブートローダーなどのイメージ)と、既知のオフセットで未署名の FDT がメモリに読み込まれると想定されます。pvmfw は AVB 署名を検証し、成功した場合は、受信 FDT から信頼できるデバイスツリーを生成し、そのシークレットをメモリからワイプして、ペイロードのエントリ ポイントまで分岐します。検証手順のいずれかが失敗すると、ファームウェアは PSCI SYSTEM_RESET ハイパーコールを発行します。
起動後、pVM インスタンスに関する情報がパーティション(virtio-blk デバイス)に保存され、pvmfw のシークレットで暗号化されるため、再起動時にシークレットが正しいインスタンスにプロビジョニングされるようになります。