
O modelo de linhas de execução do Binder foi projetado para facilitar chamadas de função local, mesmo que essas chamadas sejam para um processo remoto. Especificamente, qualquer processo que hospede um nó precisa ter um pool de uma ou mais linhas de execução do Binder para processar transações para nós hospedados nesse processo.
Transações síncronas e assíncronas
O Binder oferece suporte a transações síncronas e assíncronas. As seções a seguir explicam como cada tipo de transação é executado.
Transações síncronas
As transações síncronas são bloqueadas até serem executadas no nó, e uma resposta para essa transação é recebida pelo autor da chamada. A figura a seguir mostra como uma transação síncrona é executada:
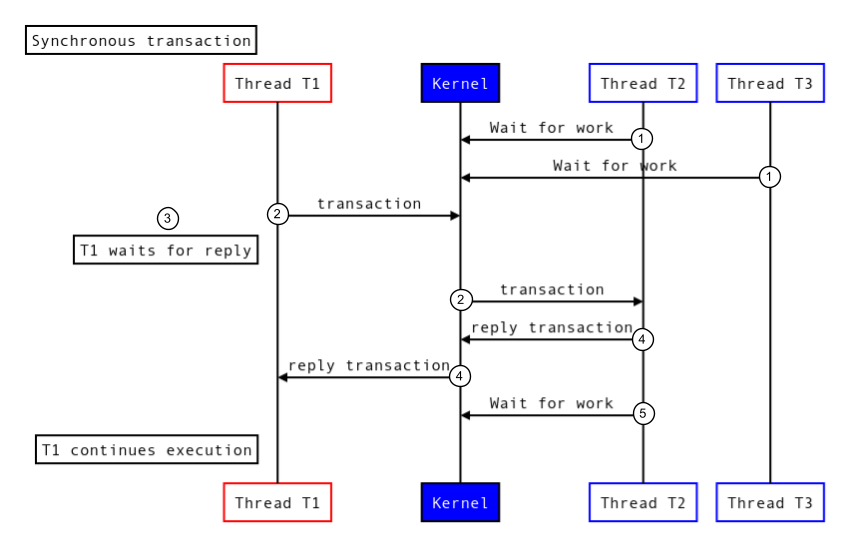
Figura 1. Transação síncrona.
Para executar uma transação síncrona, o Binder faz o seguinte:
- As linhas de execução no pool de linhas de execução de destino (T2 e T3) chamam o driver do kernel para aguardar o trabalho recebido.
- O kernel recebe uma nova transação e ativa uma linha de execução (T2) no processo de destino para processar a transação.
- A linha de execução de chamada (T1) é bloqueada e aguarda uma resposta.
- O processo de destino executa a transação e retorna uma resposta.
- A linha de execução no processo de destino (T2) chama o driver do kernel para aguardar um novo trabalho.
Transações assíncronas
As transações assíncronas não são bloqueadas para conclusão. A linha de execução de chamada é desbloqueada assim que a transação é transmitida para o kernel. A figura a seguir mostra como uma transação assíncrona é executada:
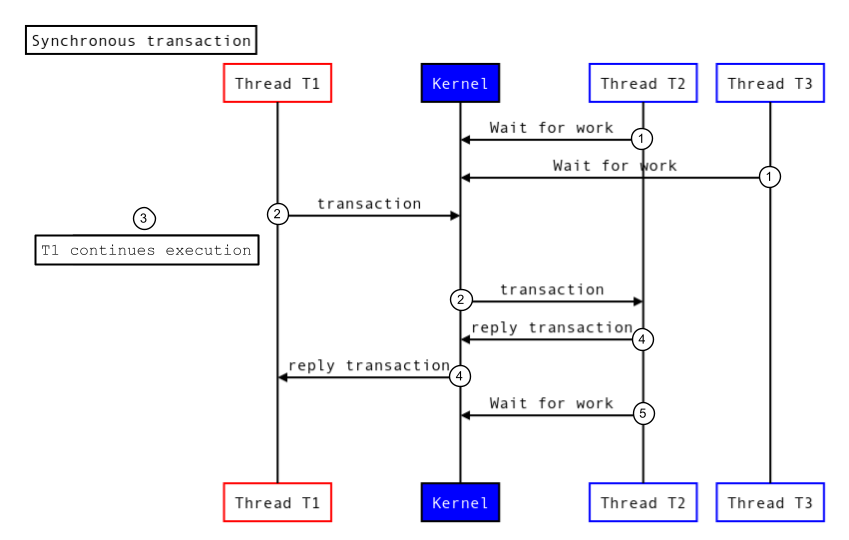
Figura 2. Transação assíncrona.
- As linhas de execução no pool de linhas de execução de destino (T2 e T3) chamam o driver do kernel para aguardar o trabalho recebido.
- O kernel recebe uma nova transação e ativa uma linha de execução (T2) no processo de destino para processar a transação.
- A linha de execução de chamada (T1) continua a execução.
- O processo de destino executa a transação e retorna uma resposta.
- A linha de execução no processo de destino (T2) chama o driver do kernel para aguardar um novo trabalho.
Identificar uma função síncrona ou assíncrona
As funções marcadas como oneway no arquivo AIDL são assíncronas. Exemplo:
oneway void someCall();
Se uma função não estiver marcada como oneway, ela será síncrona, mesmo que retorne void.
Serialização de transações assíncronas
O Binder serializa transações assíncronas de qualquer nó único. A figura a seguir mostra como o Binder serializa transações assíncronas:
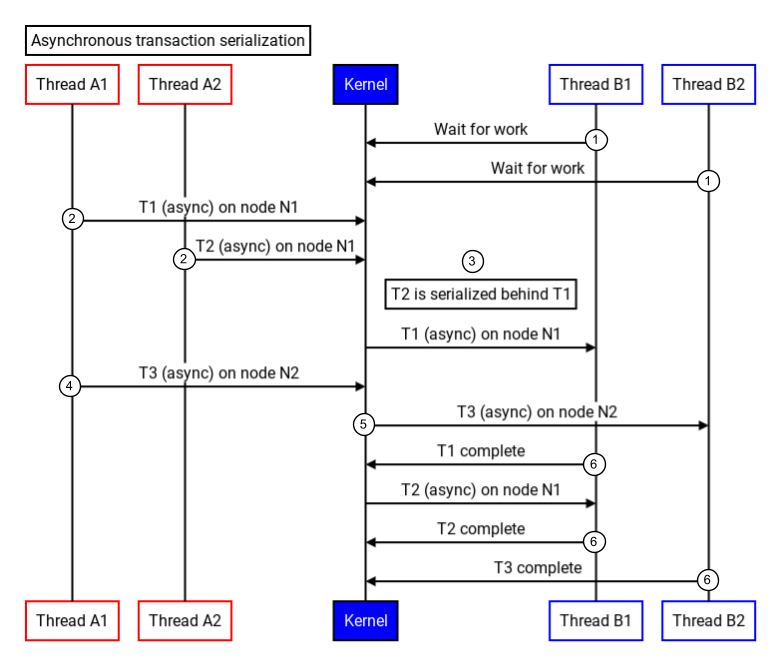
Figura 3. Serialização de transações assíncronas.
- As linhas de execução no pool de linhas de execução de destino (B1 e B2) chamam o driver do kernel para aguardar o trabalho recebido.
- Duas transações (T1 e T2) no mesmo nó (N1) são enviadas ao kernel.
- O kernel recebe novas transações e, como elas são do mesmo nó (N1), as serializa.
- Outra transação em um nó diferente (N2) é enviada ao kernel.
- O kernel recebe a terceira transação e ativa uma linha de execução (B2) no processo de destino para processar a transação.
- Os processos de destino executam cada transação e retornam uma resposta.
Transações aninhadas
As transações síncronas podem ser aninhadas. Uma linha de execução que está processando uma transação pode emitir uma nova transação. A transação aninhada pode ser para um processo diferente ou para o mesmo processo em que você recebeu a transação atual. Esse comportamento imita chamadas de função local. Por exemplo, suponha que você tenha uma função com funções aninhadas:
def outer_function(x):
def inner_function(y):
def inner_inner_function(z):
Se forem chamadas locais, elas serão executadas na mesma linha de execução.
Especificamente, se o autor da chamada de inner_function também for o processo
que hospeda o nó que implementa inner_inner_function, a chamada para
inner_inner_function será executada na mesma linha de execução.
A figura a seguir mostra como o Binder processa transações aninhadas:
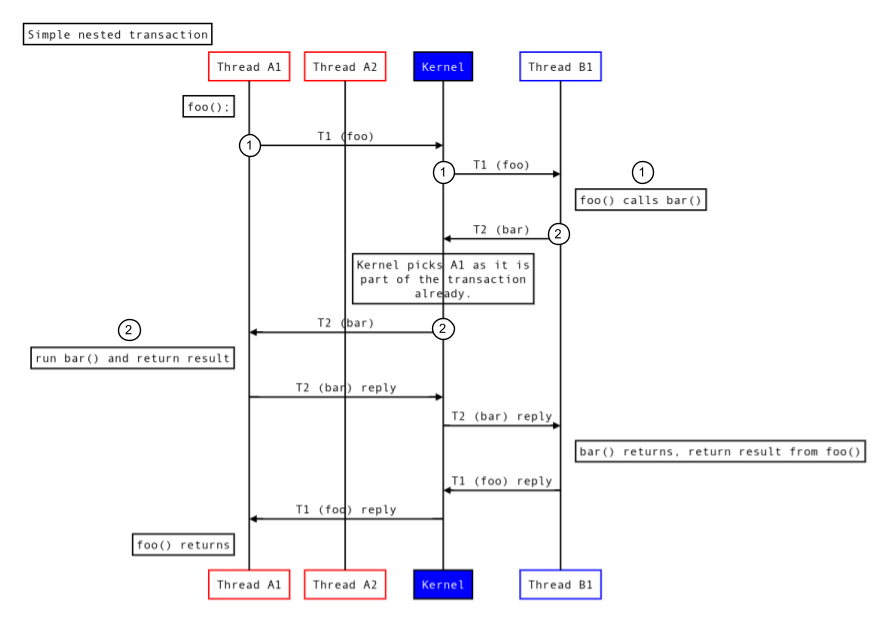
Figura 4. Transações aninhadas.
- A linha de execução A1 solicita a execução de
foo(). - Como parte dessa solicitação, a linha de execução B1 executa
bar(), que A executa na mesma linha de execução A1.
A figura a seguir mostra a execução da linha de execução se o nó que implementa bar() estiver em um processo diferente:
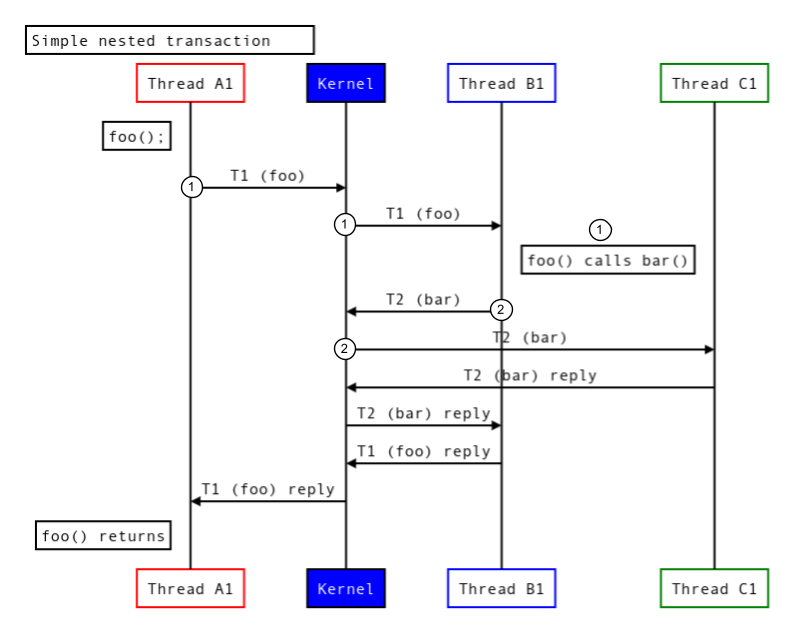
Figura 5. Transações aninhadas em processos diferentes.
- A linha de execução A1 solicita a execução de
foo(). - Como parte dessa solicitação, a linha de execução B1 executa
bar(), que é executada em outra linha de execução C1.
A figura a seguir mostra como a linha de execução reutiliza o mesmo processo em qualquer lugar da cadeia de transações:
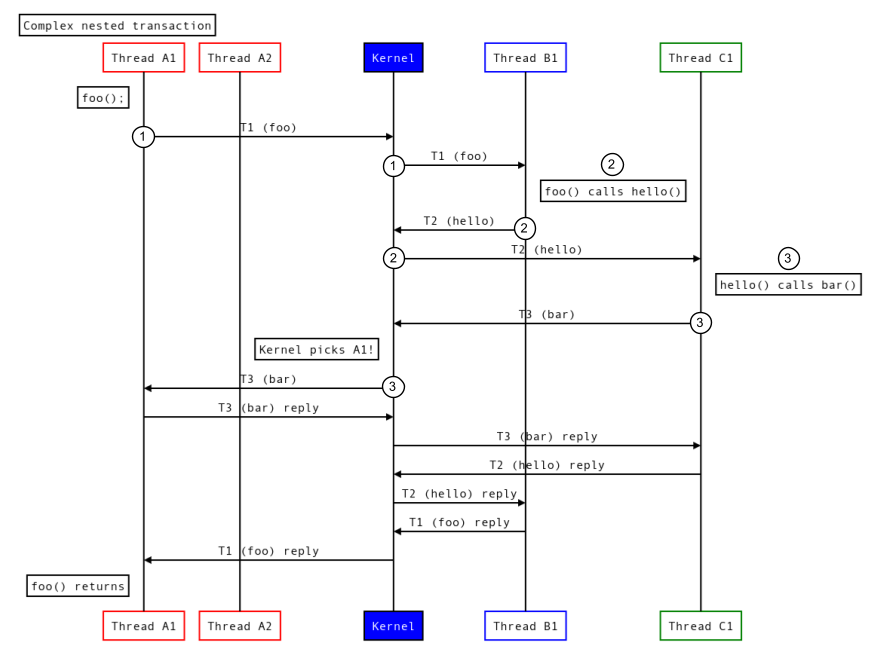
Figura 6. Transações aninhadas reutilizando uma linha de execução.
- O processo A chama o processo B.
- O processo B chama o processo C.
- O processo C faz uma chamada de volta ao processo A, e o kernel reutiliza a linha de execução A1 no processo A que faz parte da cadeia de transações.
Para transações assíncronas, o aninhamento não desempenha um papel. O cliente não aguarda o resultado de uma transação assíncrona, então não há aninhamento. Se o handler de uma transação assíncrona fizer uma chamada para o processo que emitiu essa transação assíncrona, ela poderá ser processada em qualquer linha de execução livre nesse processo.
Evitar impasses
A imagem a seguir mostra um impasse comum:
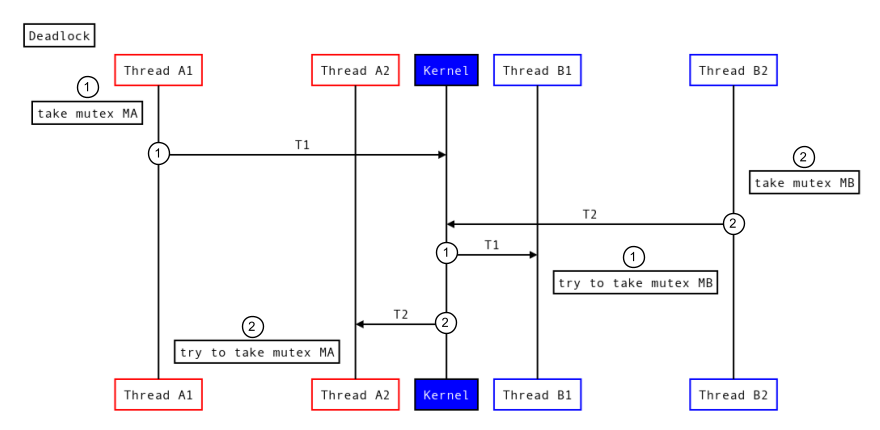
Figura 7. Impasse comum.
- O processo A usa o mutex MA e faz uma chamada do Binder (T1) para o processo B, que também tenta usar o mutex MB.
- Simultaneamente, o processo B usa o mutex MB e faz uma chamada do Binder (T2) para o processo A, que tenta usar o mutex MA.
Se essas transações se sobrepuserem, cada transação poderá usar um mutex no processo enquanto aguarda que o outro processo libere um mutex, resultando em um impasse.
Para evitar impasses ao usar o Binder, não mantenha nenhum bloqueio ao fazer uma chamada do Binder.
Regras de ordenação de bloqueio e impasses
Em um único ambiente de execução, o impasse é evitado com uma regra de ordenação de bloqueio. No entanto, ao fazer chamadas entre processos e entre bases de código, especialmente à medida que o código é atualizado, é impossível manter e coordenar uma regra de ordenação.
Mutex único e impasses
Com transações aninhadas, o processo B pode chamar diretamente a mesma linha de execução no processo A que mantém um mutex. Portanto, devido à recursão inesperada, ainda é possível ter um impasse com um único mutex.
Chamadas assíncronas e impasses
Embora as chamadas assíncronas do Binder não sejam bloqueadas para conclusão, também é necessário evitar manter um bloqueio para chamadas assíncronas. Se você mantiver um bloqueio, poderá ter problemas de bloqueio se uma chamada unidirecional for alterada acidentalmente para uma chamada síncrona.
Linha de execução única do Binder e impasses
O modelo de transação do Binder permite a reentrância. Portanto, mesmo que um processo tenha uma única linha de execução do Binder, ainda é necessário o bloqueio. Por exemplo, suponha que você esteja iterando uma lista em um processo A de linha de execução única. Para cada item na lista, você faz uma transação de saída do Binder. Se a implementação da função que você está chamando fizer uma nova transação do Binder para um nó hospedado no processo A, essa transação será processada na mesma linha de execução que estava iterando a lista. Se a implementação dessa transação modificar a mesma lista, você poderá ter problemas ao continuar iterando a lista mais tarde.
Configurar o tamanho do pool de linhas de execução
Quando um serviço tem vários clientes, adicionar mais linhas de execução ao pool de linhas de execução pode reduzir a contenção e atender mais chamadas em paralelo. Depois de lidar corretamente com a simultaneidade, você pode adicionar mais linhas de execução. Um problema que pode ser causado pela adição de mais linhas de execução é que algumas linhas de execução podem não ser usadas durante cargas de trabalho silenciosas.
As linhas de execução são geradas sob demanda até um máximo configurado. Depois que uma linha de execução do Binder é gerada, ela permanece ativa até que o processo que a hospeda termine.
A biblioteca libbinder tem um padrão de 15 linhas de execução. Use setThreadPoolMaxThreadCount para mudar esse valor:
using ::android::ProcessState;
ProcessState::self()->setThreadPoolMaxThreadCount(size_t maxThreads);