
En esta página, se describen las estructuras de datos y los métodos que se usan para comunicar de manera eficiente los búferes de operandos entre el controlador y el framework.
En el momento de la compilación del modelo, el framework proporciona los valores de los operandos constantes al controlador. Según la vida útil del operando constante, sus valores se ubican en un vector HIDL o en un grupo de memoria compartida.
- Si la vida útil es
CONSTANT_COPY, los valores se encuentran en el campooperandValuesde la estructura del modelo. Dado que los valores del vector de HIDL se copian durante la comunicación entre procesos (IPC), esto se suele usar solo para contener una pequeña cantidad de datos, como operandos escalares (por ejemplo, el escalar de activación enADD) y parámetros de tensores pequeños (por ejemplo, el tensor de forma enRESHAPE). - Si la vida útil es
CONSTANT_REFERENCE, los valores se encuentran en el campopoolsde la estructura del modelo. Durante la comunicación entre procesos, solo se duplican los identificadores de los grupos de memoria compartida, en lugar de copiar los valores sin procesar. Por lo tanto, es más eficiente almacenar una gran cantidad de datos (por ejemplo, los parámetros de peso en las convoluciones) con grupos de memoria compartida que con vectores HIDL.
En el tiempo de ejecución del modelo, el framework proporciona los búferes de los operandos de entrada y salida al controlador. A diferencia de las constantes de tiempo de compilación que se pueden enviar en un vector de HIDL, los datos de entrada y salida de una ejecución siempre se comunican a través de una colección de grupos de memoria.
El tipo de datos HIDL hidl_memory se usa tanto en la compilación como en la ejecución para representar un grupo de memoria compartida sin asignar. El controlador debe asignar la memoria de forma adecuada para que se pueda usar según el nombre del tipo de datos hidl_memory.
Los nombres de memoria admitidos son los siguientes:
ashmem: Es la memoria compartida de Android. Para obtener más detalles, consulta memoria.mmap_fd: Memoria compartida respaldada por un descriptor de archivo a través demmap.hardware_buffer_blob: Es la memoria compartida respaldada por un AHardwareBuffer con el formatoAHARDWARE_BUFFER_FORMAT_BLOB. Disponible a partir de la HAL 1.2 de Neural Networks (NN). Para obtener más detalles, consulta AHardwareBuffer.hardware_buffer: Memoria compartida respaldada por un AHardwareBuffer general que no usa el formatoAHARDWARE_BUFFER_FORMAT_BLOB. El búfer de hardware en modo no BLOB solo se admite en la ejecución del modelo.Está disponible desde la HAL 1.2 de NN. Para obtener más detalles, consulta AHardwareBuffer.
A partir de la HAL de NN 1.3, la NNAPI admite dominios de memoria que proporcionan interfaces asignables para búferes administrados por controladores. Los búferes administrados por el controlador también se pueden usar como entradas o salidas de ejecución. Para obtener más detalles, consulta Dominios de memoria.
Los controladores de NNAPI deben admitir la asignación de nombres de memoria ashmem y mmap_fd. A partir de la HAL de NN 1.3, los controladores también deben admitir la asignación de hardware_buffer_blob. La compatibilidad con el modo general no BLOB hardware_buffer y los dominios de memoria es opcional.
AHardwareBuffer
Un AHardwareBuffer es un tipo de memoria compartida que encapsula un búfer de Gralloc. En Android 10, la API de Neural Networks (NNAPI) admite el uso de AHardwareBuffer, lo que permite que el controlador realice ejecuciones sin copiar datos, lo que mejora el rendimiento y el consumo de energía de las apps. Por ejemplo, una pila de HAL de cámara puede pasar objetos AHardwareBuffer a la NNAPI para cargas de trabajo de aprendizaje automático con identificadores de AHardwareBuffer generados por las APIs de NDK de cámara y NDK de medios. Para obtener más información, consulta: ANeuralNetworksMemory_createFromAHardwareBuffer.
Los objetos AHardwareBuffer que se usan en la NNAPI se pasan al controlador a través de una estructura hidl_memory denominada hardware_buffer o hardware_buffer_blob.
La estructura hidl_memory hardware_buffer_blob representa solo objetos AHardwareBuffer con el formato AHARDWAREBUFFER_FORMAT_BLOB.
La información que requiere el framework está codificada en el campo hidl_handle de la estructura hidl_memory. El campo hidl_handle encapsula native_handle, que codifica todos los metadatos requeridos sobre un búfer de AHardwareBuffer o Gralloc.
El controlador debe decodificar correctamente el campo hidl_handle proporcionado y acceder a la memoria que describe hidl_handle. Cuando se llama al método getSupportedOperations_1_2, getSupportedOperations_1_1 o getSupportedOperations, el controlador debe detectar si puede decodificar el hidl_handle proporcionado y acceder a la memoria que describe hidl_handle. La preparación del modelo debe fallar si no se admite el campo hidl_handle que se usa para un operando constante. La ejecución debe fallar si no se admite el campo hidl_handle que se usa para un operando de entrada o salida de la ejecución. Se recomienda que el controlador devuelva un código de error GENERAL_FAILURE si falla la preparación o la ejecución del modelo.
Dominios de memoria
En el caso de los dispositivos que ejecutan Android 11 o versiones posteriores, la NNAPI admite dominios de memoria que proporcionan interfaces asignables para búferes administrados por controladores. Esto permite pasar memorias nativas del dispositivo entre ejecuciones, lo que evita la transformación y la copia innecesarias de datos entre ejecuciones consecutivas dentro del mismo controlador. Este flujo se ilustra en la figura 1.
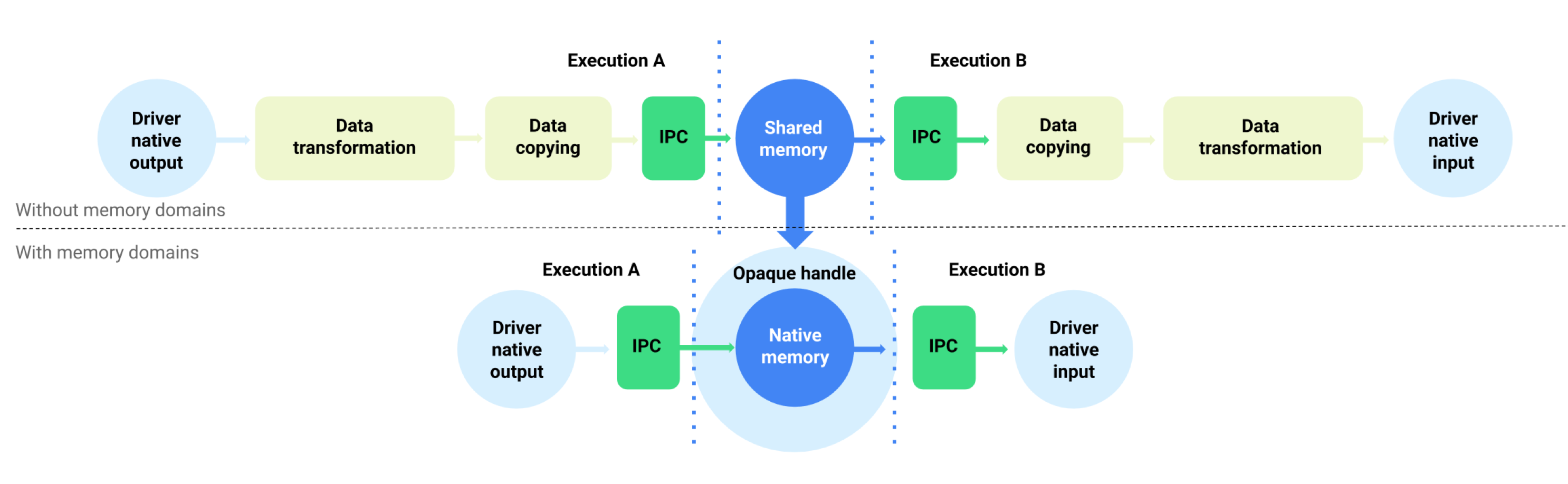
Figura 1: Cómo almacenar en búfer el flujo de datos con dominios de memoria
La función de dominio de la memoria está diseñada para tensores que son mayormente internos en el controlador y que no necesitan acceso frecuente al lado del cliente. Algunos ejemplos incluyen los tensores de estado en modelos de secuencia. Para los tensores que necesitan acceso frecuente a la CPU en el lado del cliente, es preferible usar grupos de memoria compartida.
Para admitir la función de dominio de memoria, implementa IDevice::allocate para permitir que el framework solicite la asignación de búferes administrados por el controlador. Durante la asignación, el framework proporciona las siguientes propiedades y patrones de uso para el búfer:
BufferDescdescribe las propiedades requeridas del búfer.BufferRoledescribe el patrón de uso potencial del búfer como entrada o salida de un modelo preparado. Se pueden especificar varios roles durante la asignación del búfer, y el búfer asignado solo se puede usar como los roles especificados.
El búfer asignado es interno para el controlador. Un controlador puede elegir cualquier ubicación de búfer o diseño de datos. Cuando el búfer se asigna correctamente, el cliente del controlador puede hacer referencia al búfer o interactuar con él usando el token devuelto o el objeto IBuffer.
El token de IDevice::allocate se proporciona cuando se hace referencia al búfer como uno de los objetos MemoryPool en la estructura Request de una ejecución. Para evitar que un proceso intente acceder al búfer asignado en otro proceso, el controlador debe aplicar la validación adecuada cada vez que se use el búfer. El controlador debe validar que el uso del búfer sea uno de los roles BufferRole proporcionados durante la asignación y debe fallar la ejecución de inmediato si el uso es ilegal.
El objeto IBuffer se usa para la copia explícita de memoria. En ciertas situaciones, el cliente del controlador debe inicializar el búfer administrado por el controlador desde un grupo de memoria compartida o copiar el búfer en un grupo de memoria compartida. Como ejemplo, se incluyen los siguientes casos prácticos:
- Inicialización del tensor de estado
- Almacena en caché los resultados intermedios
- Ejecución de resguardo en la CPU
Para admitir estos casos de uso, el controlador debe implementar IBuffer::copyTo y IBuffer::copyFrom con ashmem, mmap_fd y hardware_buffer_blob si admite la asignación de dominio de memoria. Es opcional que el controlador admita el modo no BLOB hardware_buffer.
Durante la asignación del búfer, las dimensiones del búfer se pueden deducir de los operandos del modelo correspondientes de todos los roles especificados por BufferRole y las dimensiones proporcionadas en BufferDesc. Con toda la información dimensional combinada, el búfer podría tener dimensiones o rango desconocidos. En ese caso, el búfer se encuentra en un estado flexible en el que las dimensiones se fijan cuando se usa como entrada del modelo y en un estado dinámico cuando se usa como salida del modelo. El mismo búfer se puede usar con diferentes formas de salidas en diferentes ejecuciones, y el controlador debe controlar el cambio de tamaño del búfer de forma adecuada.
El dominio de memoria es una función opcional. Un controlador puede determinar que no puede admitir una solicitud de asignación determinada por varios motivos. Por ejemplo:
- El búfer solicitado tiene un tamaño dinámico.
- El controlador tiene restricciones de memoria que le impiden controlar búferes grandes.
Es posible que varios subprocesos diferentes lean del búfer administrado por el controlador de forma simultánea. El acceso simultáneo al búfer para escritura o lectura/escritura no está definido, pero no debe fallar el servicio del controlador ni bloquear al llamador de forma indefinida. El controlador puede devolver un error o dejar el contenido del búfer en un estado indeterminado.