
systrace es la herramienta principal para analizar el rendimiento de los dispositivos Android. Sin embargo, en realidad es un wrapper alrededor de otras herramientas. Es el wrapper del host alrededor de atrace, el ejecutable del dispositivo que controla el registro de usuarios y configura ftrace, y el mecanismo de registro principal en el kernel de Linux. systrace usa atrace para habilitar el registro, luego lee el búfer de ftrace y lo envuelve todo en un visor HTML autónomo. (Si bien los kernels más recientes admiten el filtro de paquetes Berkeley mejorado de Linux (eBPF), esta página se refiere al kernel 3.18 (sin eBPF), ya que es el que se usó en el Pixel o el Pixel XL).
systrace es propiedad de los equipos de Google Android y Google Chrome, y es de código abierto como parte del proyecto Catapult. Además de systrace, Catapult incluye otras utilidades útiles. Por ejemplo, ftrace tiene más funciones de las que se pueden habilitar directamente con systrace o atrace, y contiene algunas funciones avanzadas que son fundamentales para depurar problemas de rendimiento. (Estas funciones requieren acceso de raíz y, a menudo, un kernel nuevo).
Ejecuta systrace
Cuando depures el jitter en un Pixel o Pixel XL, comienza con el siguiente comando:
./systrace.py sched freq idle am wm gfx view sync binder_driver irq workq input -b 96000
Cuando se combina con los puntos de seguimiento adicionales necesarios para la actividad de la canalización de la GPU y la pantalla, esto te permite hacer un seguimiento desde la entrada del usuario hasta el fotograma que se muestra en la pantalla. Establece el tamaño del búfer en un valor grande para evitar perder eventos (ya que, sin un búfer grande, algunas CPU no contienen eventos después de cierto punto en el registro).
Cuando revises el registro del sistema, ten en cuenta que cada evento se activa por algo en la CPU.
Dado que systrace se basa en ftrace y ftrace se ejecuta en la CPU, algo en la CPU debe escribir el búfer de ftrace que registra los cambios de hardware. Esto significa que, si tienes curiosidad por saber por qué una valla de visualización cambió de estado, puedes ver qué se estaba ejecutando en la CPU en el punto exacto de su transición (algo que se ejecutaba en la CPU activó ese cambio en el registro). Este concepto es la base del análisis del rendimiento con Systrace.
Ejemplo: Marco de trabajo
En este ejemplo, se describe un registro de systrace para una canalización de IU normal. Para seguir el ejemplo, descarga el archivo ZIP de los registros (que también incluye otros registros a los que se hace referencia en esta sección), descomprímelo y abre el archivo systrace_tutorial.html en tu navegador.
Para una carga de trabajo periódica y coherente, como TouchLatency, la canalización de la IU sigue esta secuencia:
- EventThread en SurfaceFlinger activa el subproceso de IU de la app, lo que indica que es hora de renderizar un nuevo fotograma.
- La app renderiza un fotograma en el subproceso de IU, RenderThread y las tareas de HWUI, con recursos de CPU y GPU. Esta es la mayor parte de la capacidad que se usa para la IU.
- La app envía el fotograma renderizado a SurfaceFlinger con un vinculador y, luego, SurfaceFlinger se suspende.
- Un segundo EventThread en SurfaceFlinger activa SurfaceFlinger para desencadenar la composición y mostrar el resultado. Si SurfaceFlinger determina que no hay trabajo que hacer, vuelve a suspenderse.
- SurfaceFlinger controla la composición con Hardware Composer (HWC), Hardware Composer 2 (HWC2) o GL. La composición de HWC y HWC2 es más rápida y consume menos energía, pero tiene limitaciones según el sistema en chip (SoC). Por lo general, este proceso tarda entre 4 y 6 ms, pero puede superponerse con el paso 2 porque las apps para Android siempre tienen un triple búfer. (Si bien las apps siempre tienen un triple búfer, es posible que solo haya un fotograma pendiente en espera en SurfaceFlinger, lo que hace que parezca idéntico al doble búfer).
- SurfaceFlinger envía el resultado final para que se muestre con un controlador del proveedor y vuelve a suspenderse, a la espera de que se active EventThread.
Este es un ejemplo de la secuencia de fotogramas que comienza en 15409 ms:
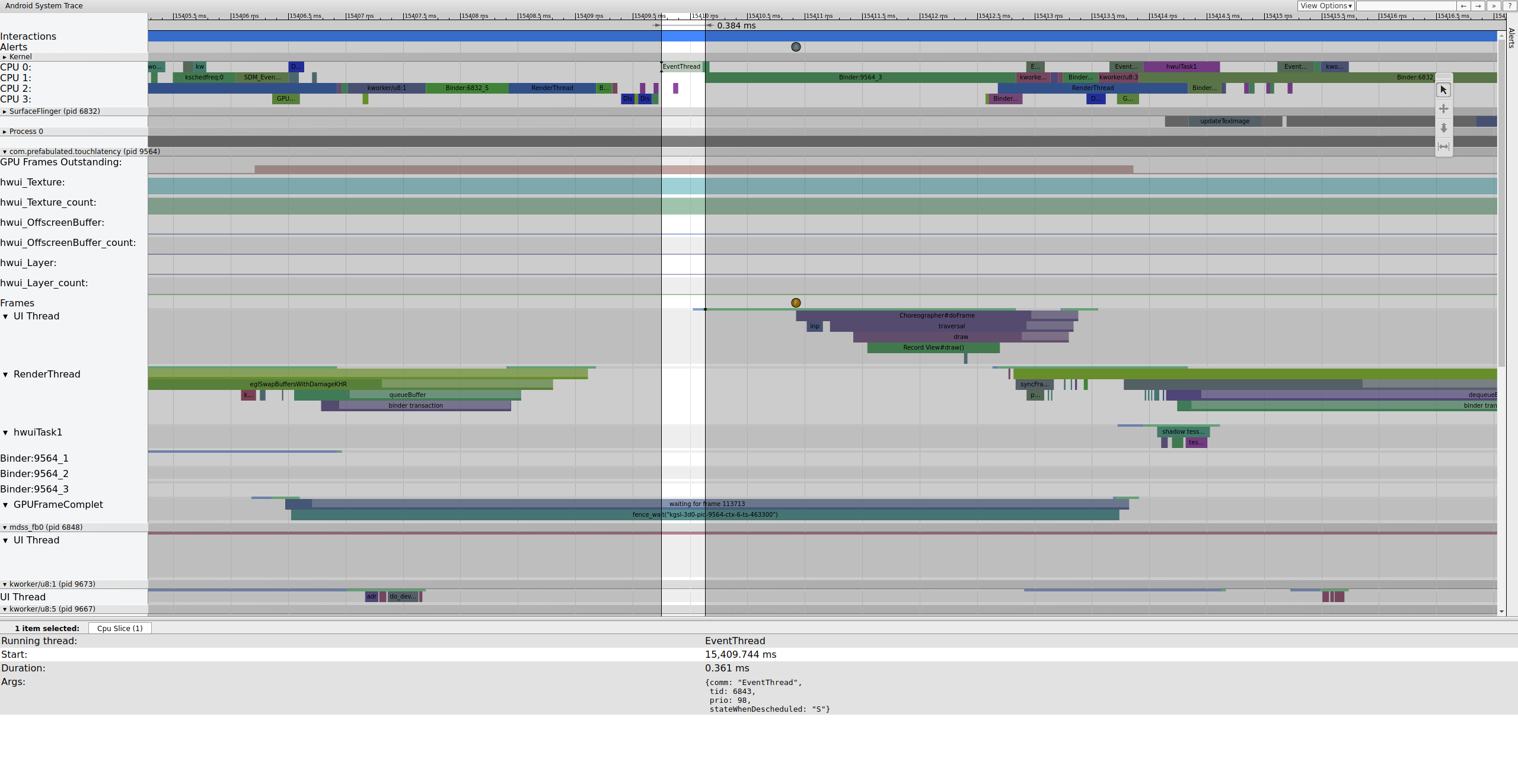
Figura 1: Canalización de IU normal, EventThread en ejecución.
La figura 1 es un fotograma normal rodeado de fotogramas normales, por lo que es un buen punto de partida para comprender cómo funciona la canalización de la IU. La fila del subproceso de IU para TouchLatency incluye diferentes colores en diferentes momentos. Las barras indican diferentes estados del hilo:
- Gris. Dormir
- Azul. Ejecutable (podría ejecutarse, pero el programador aún no lo seleccionó para que se ejecute).
- Verde. Se ejecuta de forma activa (el programador cree que se está ejecutando).
- Rojo. Sueño ininterrumpible (generalmente, dormir en un bloqueo del kernel) Puede ser un indicador de la carga de E/S. Es muy útil para depurar problemas de rendimiento.
- Naranja. Sueño ininterrumpido debido a la carga de E/S.
Para ver el motivo del sueño ininterrumpible (disponible desde el punto de seguimiento sched_blocked_reason), selecciona el segmento rojo de sueño ininterrumpible.
Mientras se ejecuta EventThread, el subproceso de IU para TouchLatency se vuelve ejecutable. Para ver qué lo activó, haz clic en la sección azul.
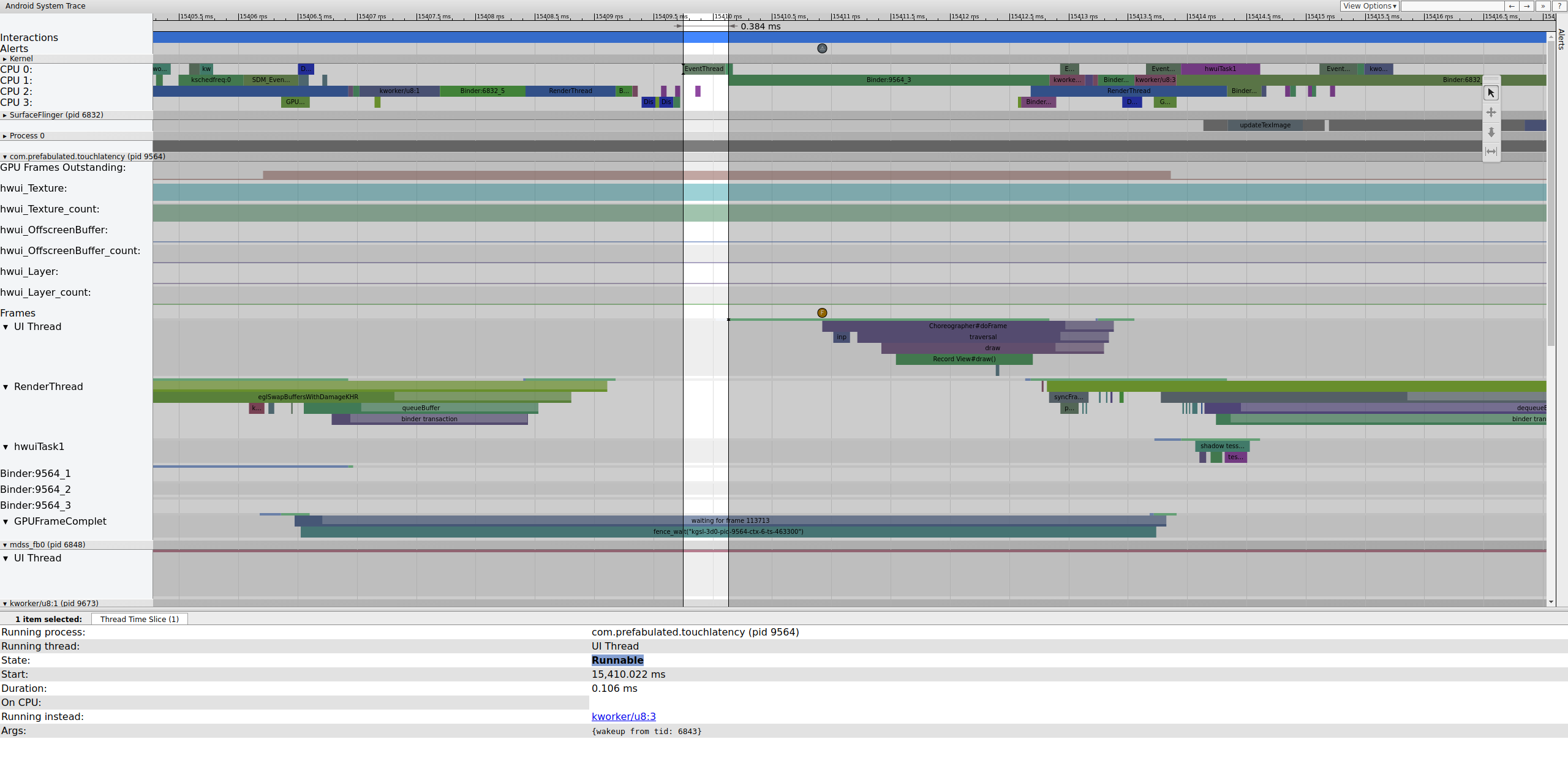
Figura 2: Es el subproceso de IU para TouchLatency.
En la figura 2, se muestra que el subproceso de IU de TouchLatency se activó con el TID 6843, que corresponde a EventThread. El subproceso de IU se activa, renderiza un fotograma y lo pone en cola para que SurfaceFlinger lo consuma.
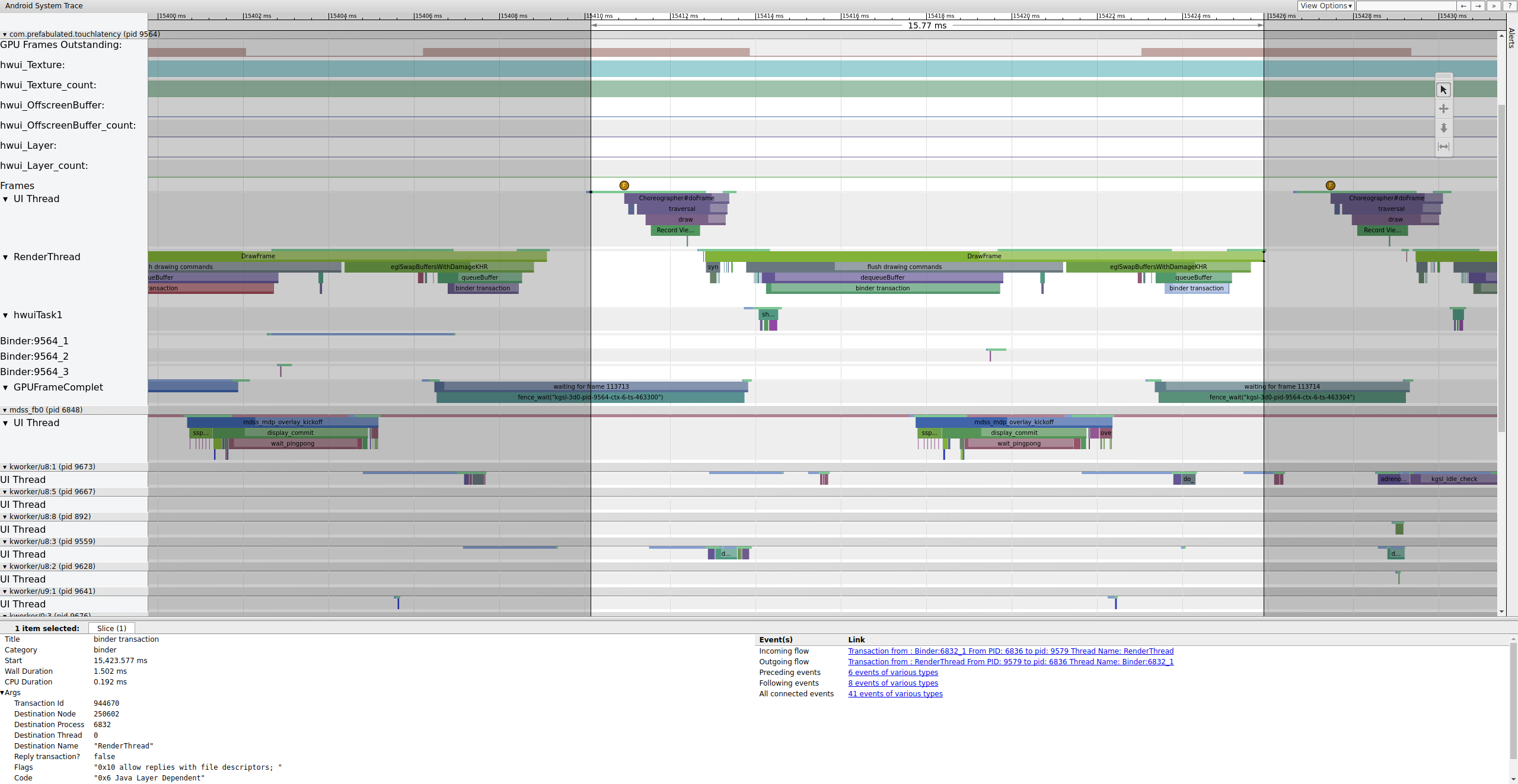
Figura 3: El subproceso de IU se activa, renderiza un fotograma y lo pone en cola para que SurfaceFlinger lo consuma.
Si la etiqueta binder_driver está habilitada en un registro, puedes seleccionar una transacción de Binder para ver información sobre todos los procesos involucrados en esa transacción.
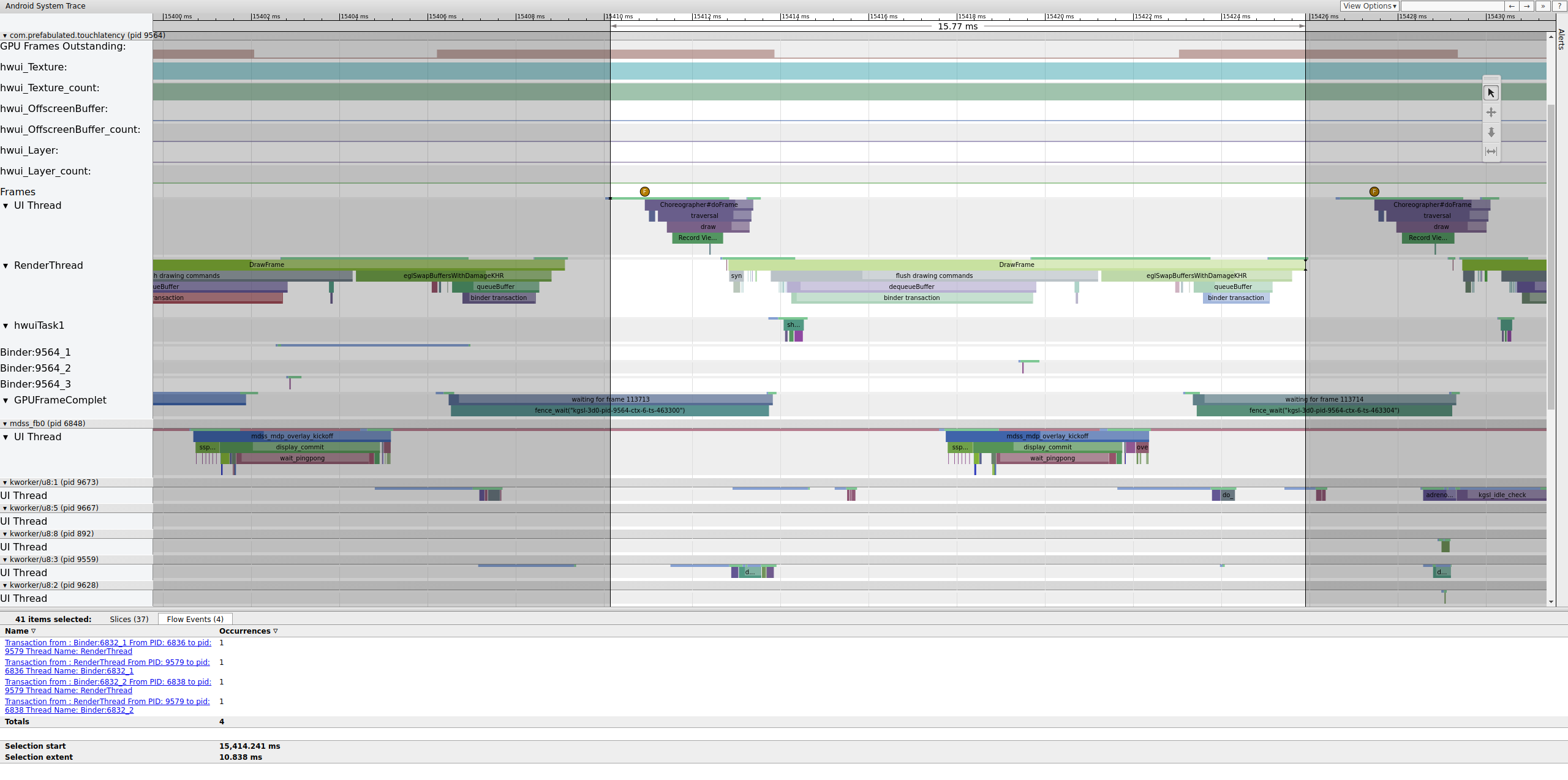
Figura 4: Es una transacción de Binder.
En la figura 4, se muestra que, a los 15,423.65 ms, Binder:6832_1 en SurfaceFlinger se vuelve ejecutable debido al TID 9579, que es el RenderThread de TouchLatency. También puedes ver queueBuffer en ambos lados de la transacción del binder.
Durante el queueBuffer del lado de SurfaceFlinger, la cantidad de fotogramas pendientes de TouchLatency pasa de 1 a 2.
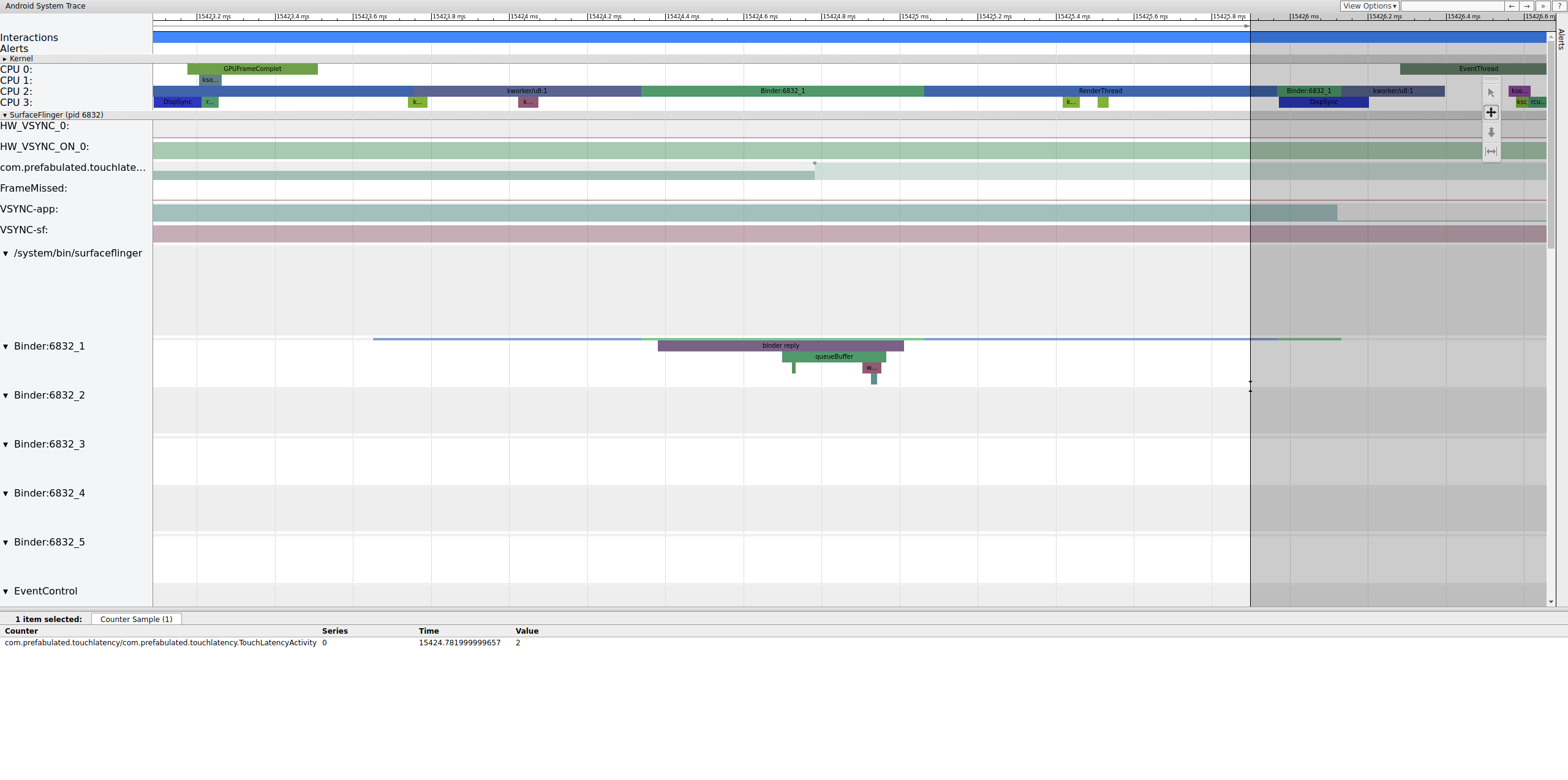
Figura 5: Los marcos pendientes van de 1 a 2.
En la figura 5, se muestra el almacenamiento en búfer triple, en el que hay dos fotogramas completados y la app está a punto de comenzar a renderizar un tercero. Esto se debe a que ya descartamos algunos fotogramas, por lo que la app mantiene dos fotogramas pendientes en lugar de uno para intentar evitar que se descarten más.
Poco después, un segundo EventThread activa el subproceso principal de SurfaceFlinger para que pueda generar el fotograma pendiente anterior en la pantalla:
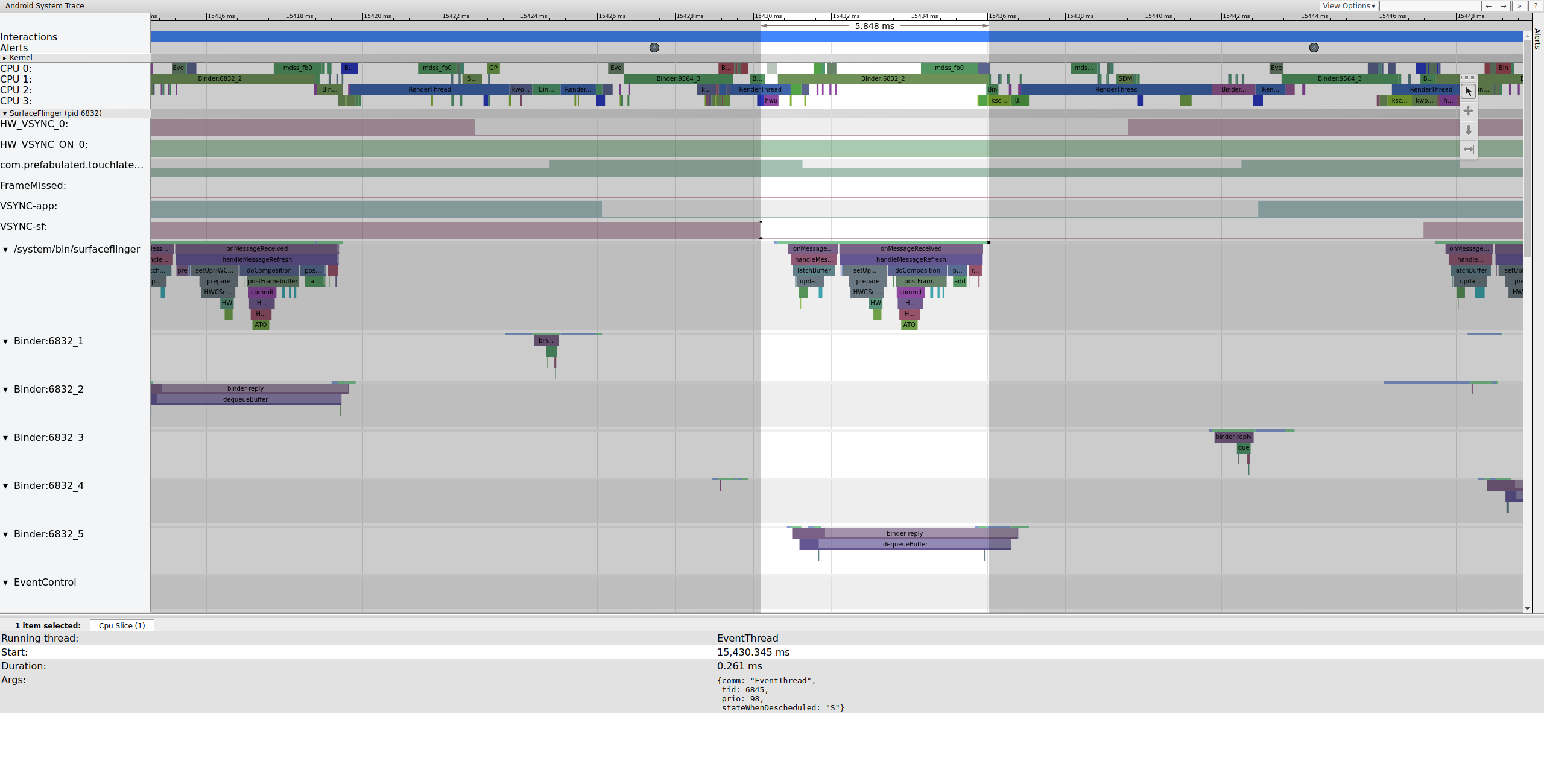
Figura 6: Un segundo EventThread activa el subproceso principal de SurfaceFlinger.
Primero, SurfaceFlinger fija el búfer pendiente más antiguo, lo que hace que el recuento de búferes pendientes disminuya de 2 a 1:
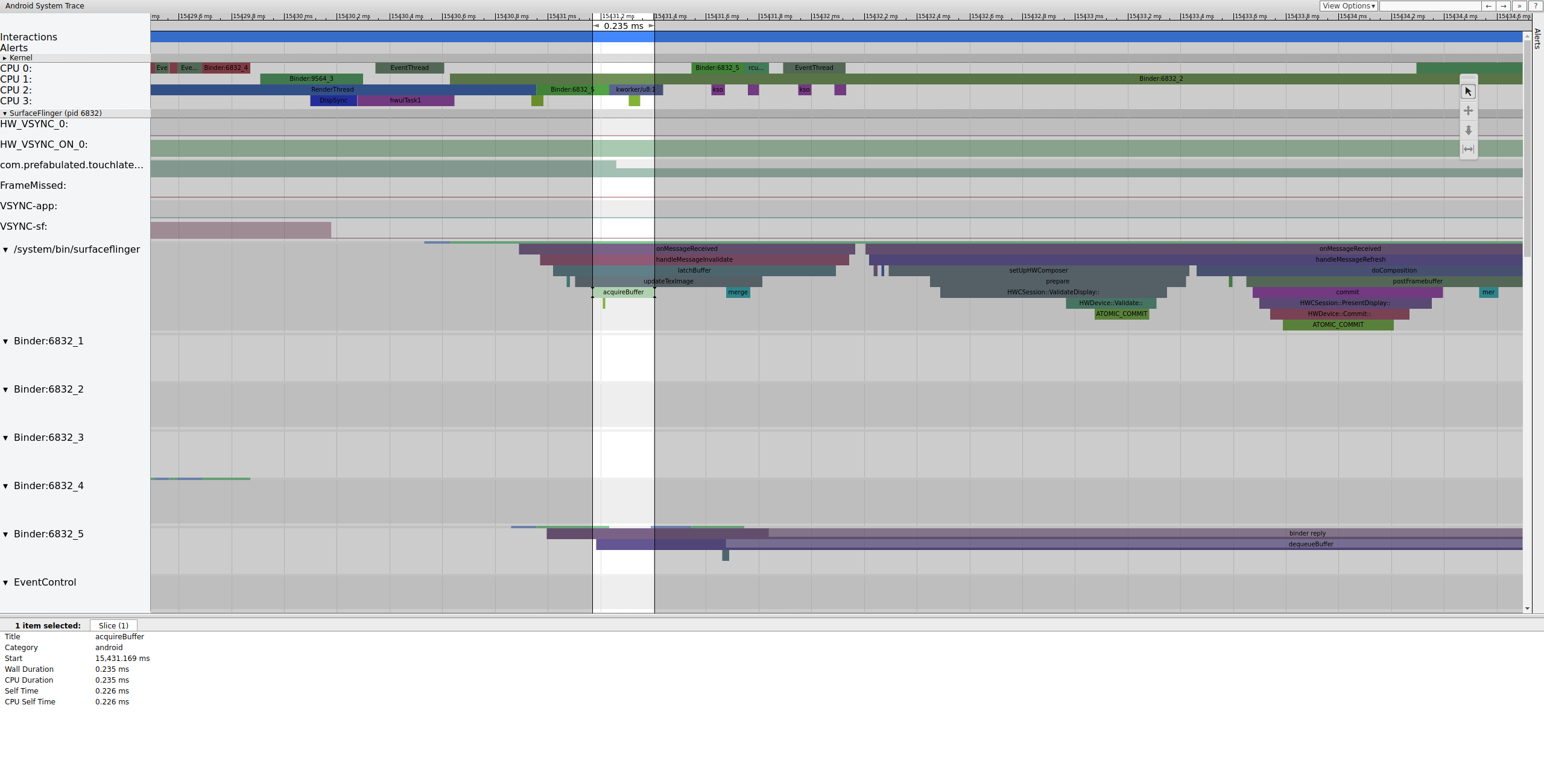
Figura 7: Primero, SurfaceFlinger se traba en el búfer pendiente más antiguo.
Después de conectar el búfer, SurfaceFlinger configura la composición y envía el fotograma final a la pantalla. (Algunas de estas secciones se habilitan como parte del mdss punto de seguimiento, por lo que es posible que no se incluyan en tu SoC).
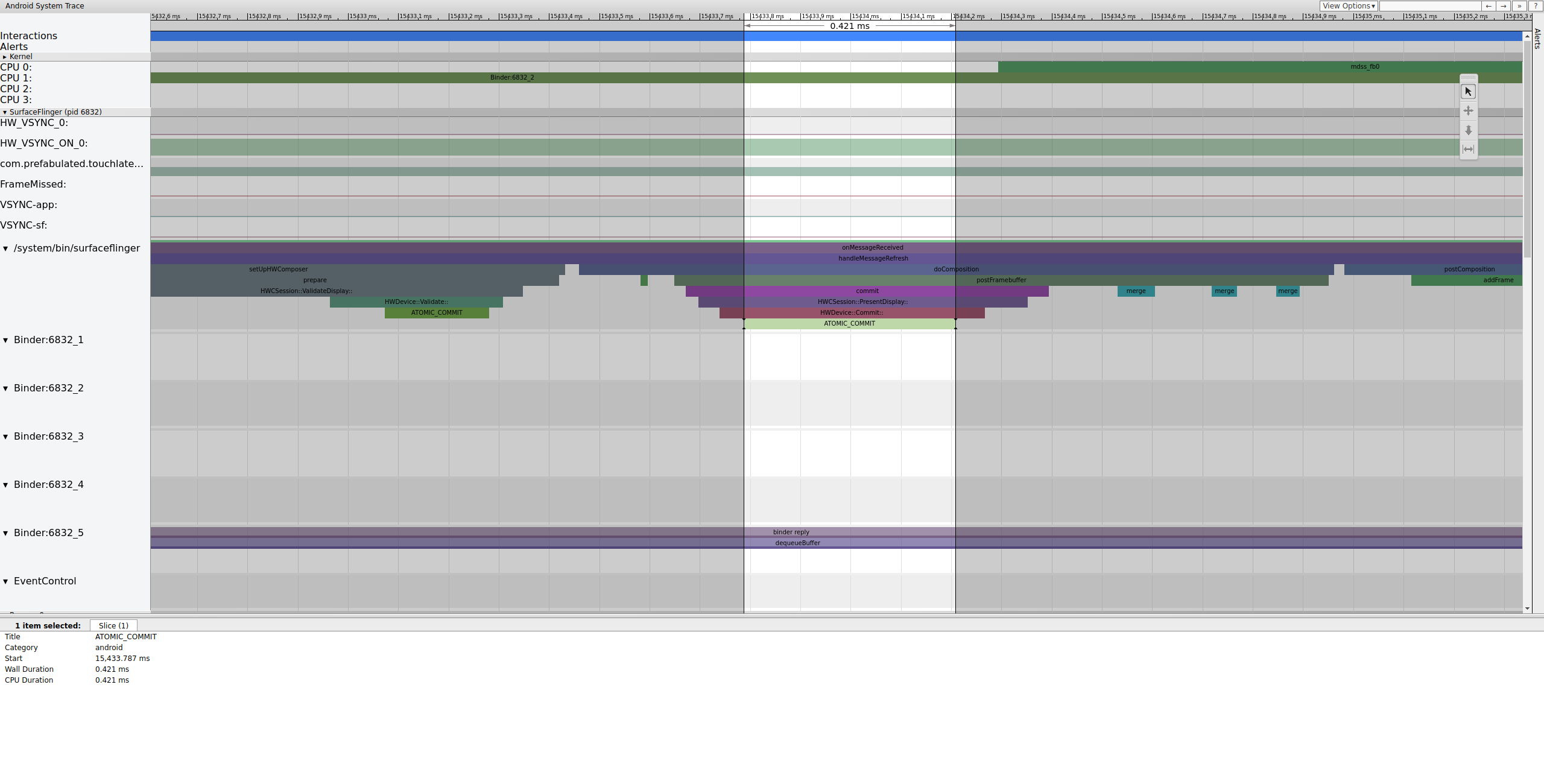
Figura 8: SurfaceFlinger configura la composición y envía el fotograma final.
A continuación, mdss_fb0 se activa en la CPU 0. mdss_fb0 es el subproceso del kernel de la canalización de visualización para generar un fotograma renderizado en la pantalla.
Ten en cuenta que mdss_fb0 se encuentra en su propia fila en el registro (desplázate hacia abajo para verlo):
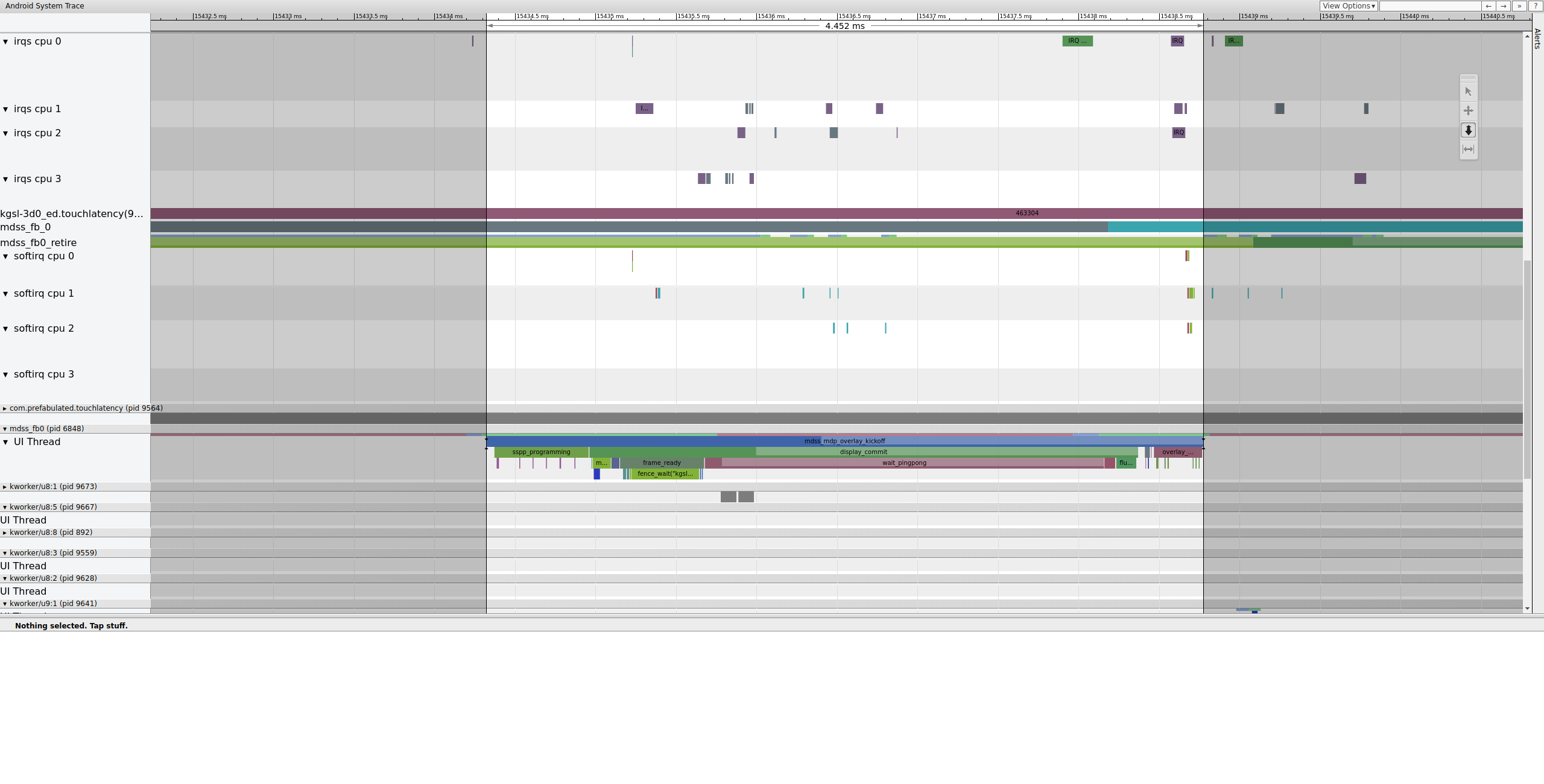
Figura 9: mdss_fb0 se activa en la CPU 0.
mdss_fb0 se despierta, corre brevemente, entra en un sueño ininterrumpible y, luego, se vuelve a despertar.
Ejemplo: Cuadro que no funciona
En este ejemplo, se describe un registro de systrace que se usa para depurar la fluctuación de un Pixel o Pixel XL. Para seguir el ejemplo, descarga el archivo ZIP de registros (que incluye otros registros a los que se hace referencia en esta sección), descomprímelo y abre el archivo systrace_tutorial.html en tu navegador.
Cuando abres el registro del sistema, ves algo similar a la siguiente figura:

Figura 10: TouchLatency ejecutándose en un Pixel XL con la mayoría de las opciones habilitadas.
En la figura 10, la mayoría de las opciones están habilitadas, incluidos los puntos de seguimiento mdss y kgsl.
Cuando busques jank, revisa la fila FrameMissed en SurfaceFlinger.
FrameMissed es una mejora en la calidad de vida que proporciona HWC2. Cuando visualizas systrace para otros dispositivos, es posible que la fila FrameMissed no esté presente si el dispositivo no usa HWC2. En ambos casos, FrameMissed se correlaciona con el hecho de que SurfaceFlinger no ejecuta uno de sus tiempos de ejecución normales y con un recuento de búferes pendientes sin cambios para la app (com.prefabulated.touchlatency) en una sincronización vertical.

Figura 11: Correlación de FrameMissed con SurfaceFlinger.
En la figura 11, se muestra un fotograma perdido en 15598.29 ms. SurfaceFlinger se activó brevemente en el intervalo de VSync y volvió a suspenderse sin realizar ningún trabajo, lo que significa que SurfaceFlinger determinó que no valía la pena intentar enviar un fotograma a la pantalla nuevamente.
Para comprender por qué se interrumpió la canalización en este fotograma, primero revisa el ejemplo de fotograma en funcionamiento anterior para ver cómo aparece una canalización de IU normal en systrace. Cuando esté todo listo, vuelve al fotograma que omitiste y trabaja hacia atrás. Observa que SurfaceFlinger se activa y se suspende de inmediato. Cuando se visualiza la cantidad de fotogramas pendientes de TouchLatency, hay dos fotogramas (una buena pista para ayudar a determinar qué sucede).
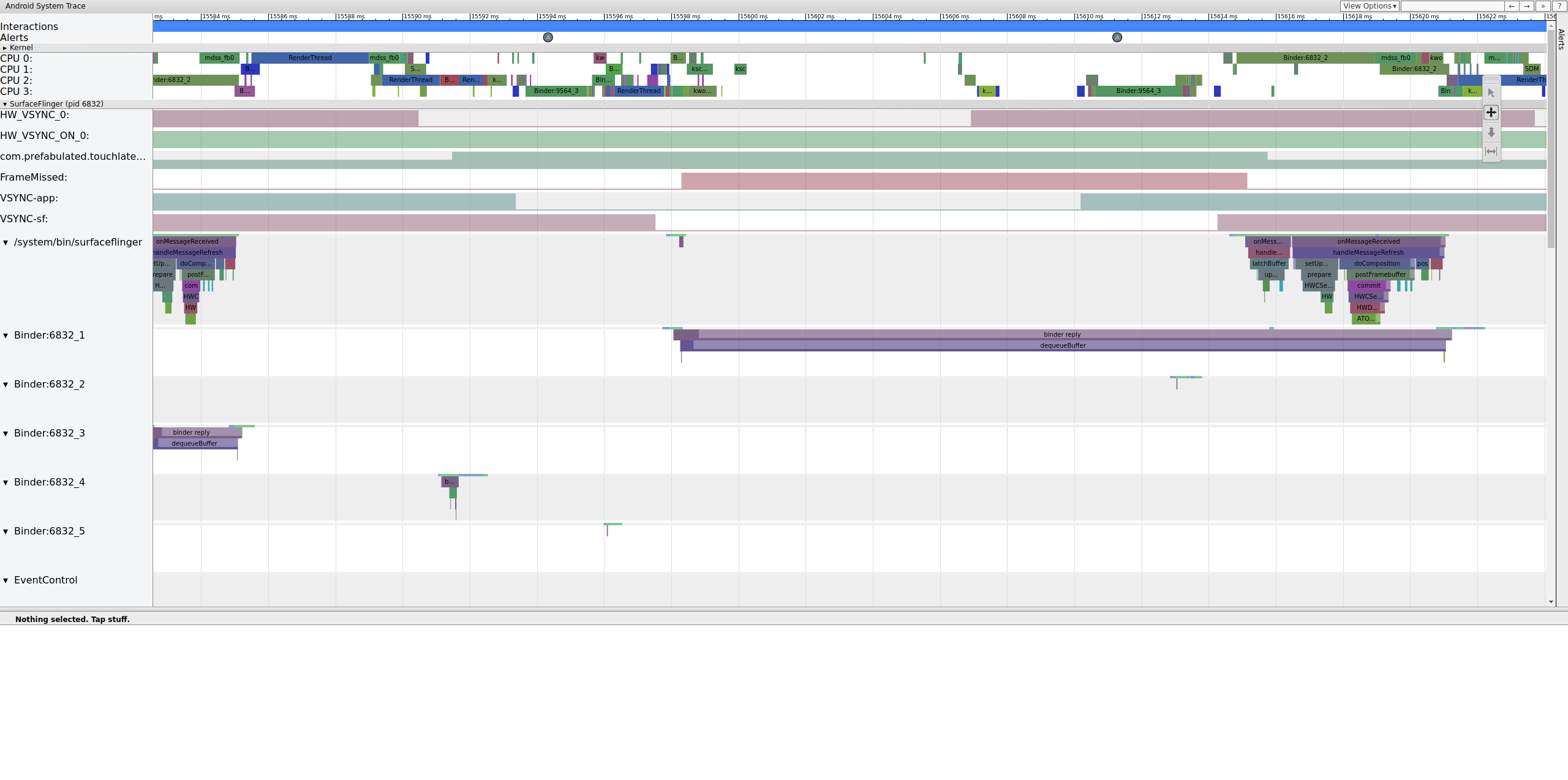
Figura 12: SurfaceFlinger se activa y se suspende de inmediato.
Como hay fotogramas en SurfaceFlinger, no se trata de un problema de la app. Además, SurfaceFlinger se activa en el momento correcto, por lo que no se trata de un problema de SurfaceFlinger. Si SurfaceFlinger y la app se ven normales, es probable que se trate de un problema del controlador.
Como los puntos de seguimiento mdss y sync están habilitados, puedes obtener información sobre las barreras (compartidas entre el controlador de pantalla y SurfaceFlinger) que controlan cuándo se envían los fotogramas a la pantalla.
Estas barreras se enumeran en mdss_fb0_retire, que indica cuándo un fotograma está en la pantalla. Estas vallas se proporcionan como parte de la categoría de seguimiento sync. Las barreras que corresponden a eventos particulares en SurfaceFlinger dependen de tu SoC y de la pila de controladores, por lo que debes trabajar con tu proveedor de SoC para comprender el significado de las categorías de barreras en tus registros.
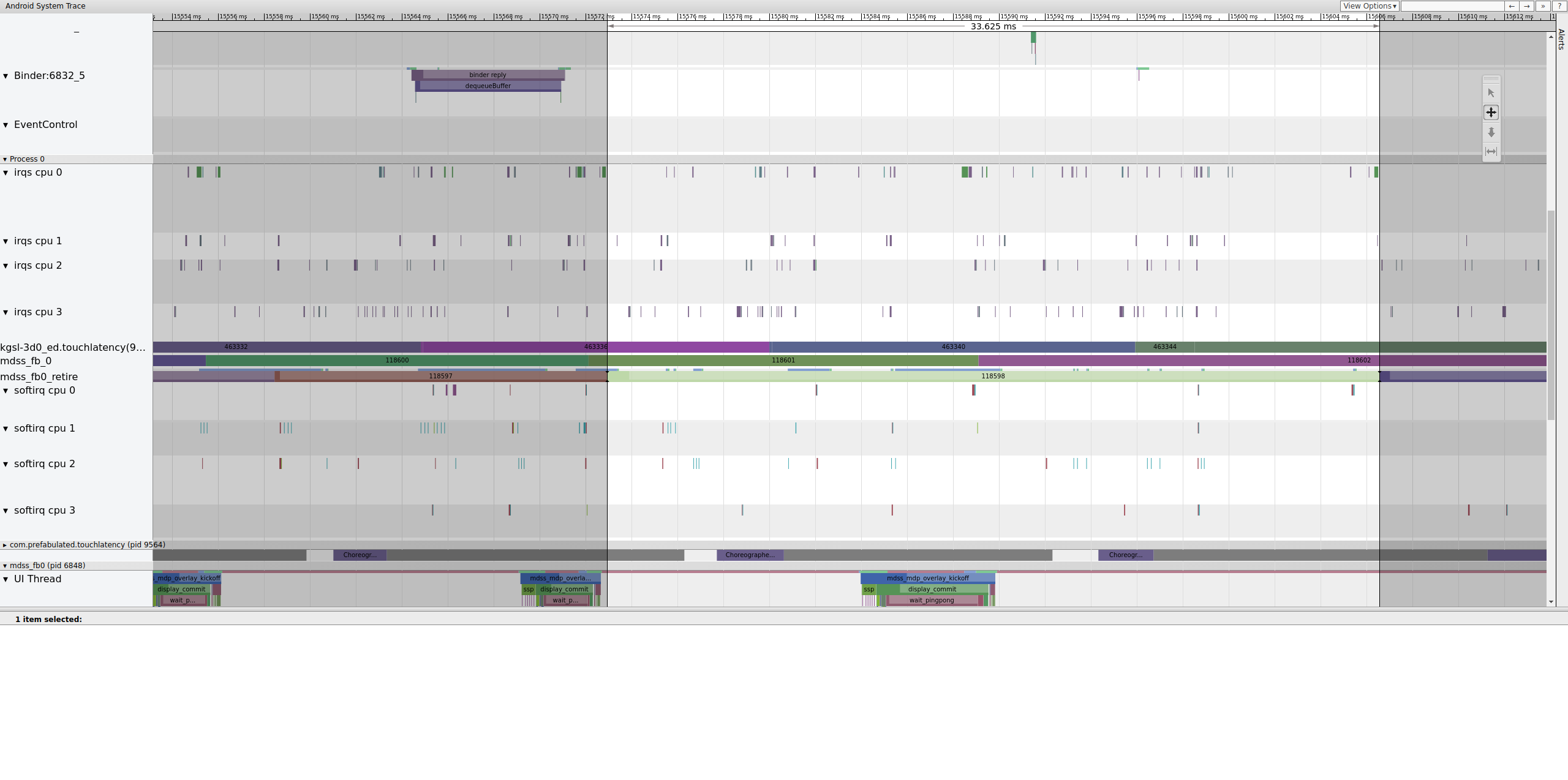
Figura 13: mdss_fb0_retire fences.
En la figura 13, se muestra un fotograma que se mostró durante 33 ms, no durante los 16.7 ms esperados. A mitad de ese segmento, ese fotograma debería haberse reemplazado por uno nuevo, pero no fue así. Mira el fotograma anterior y busca cualquier cosa.
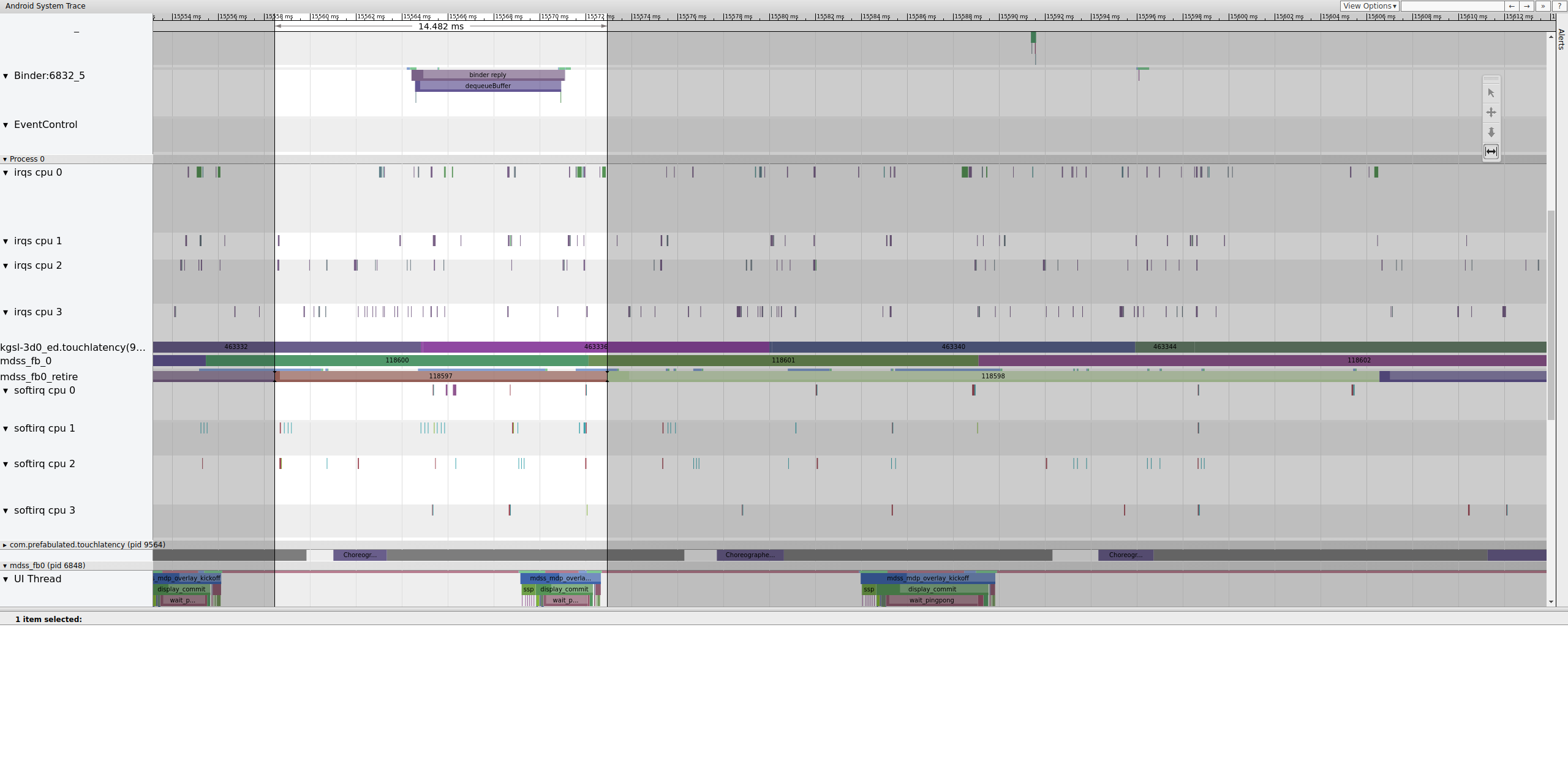
Figura 14: Es el fotograma anterior al fotograma dañado.
En la figura 14, se muestra un fotograma de 14.482 ms. El segmento de dos fotogramas interrumpido duró 33.6 ms, lo que coincide con lo que se espera para dos fotogramas (renderizados a 60 Hz, 16.7 ms por fotograma, lo que es cercano). Sin embargo, 14.482 ms no se acerca a 16.7 ms, lo que sugiere que hay un problema con la canalización de pantalla.
Investiga exactamente dónde termina esa valla para determinar qué la controla:
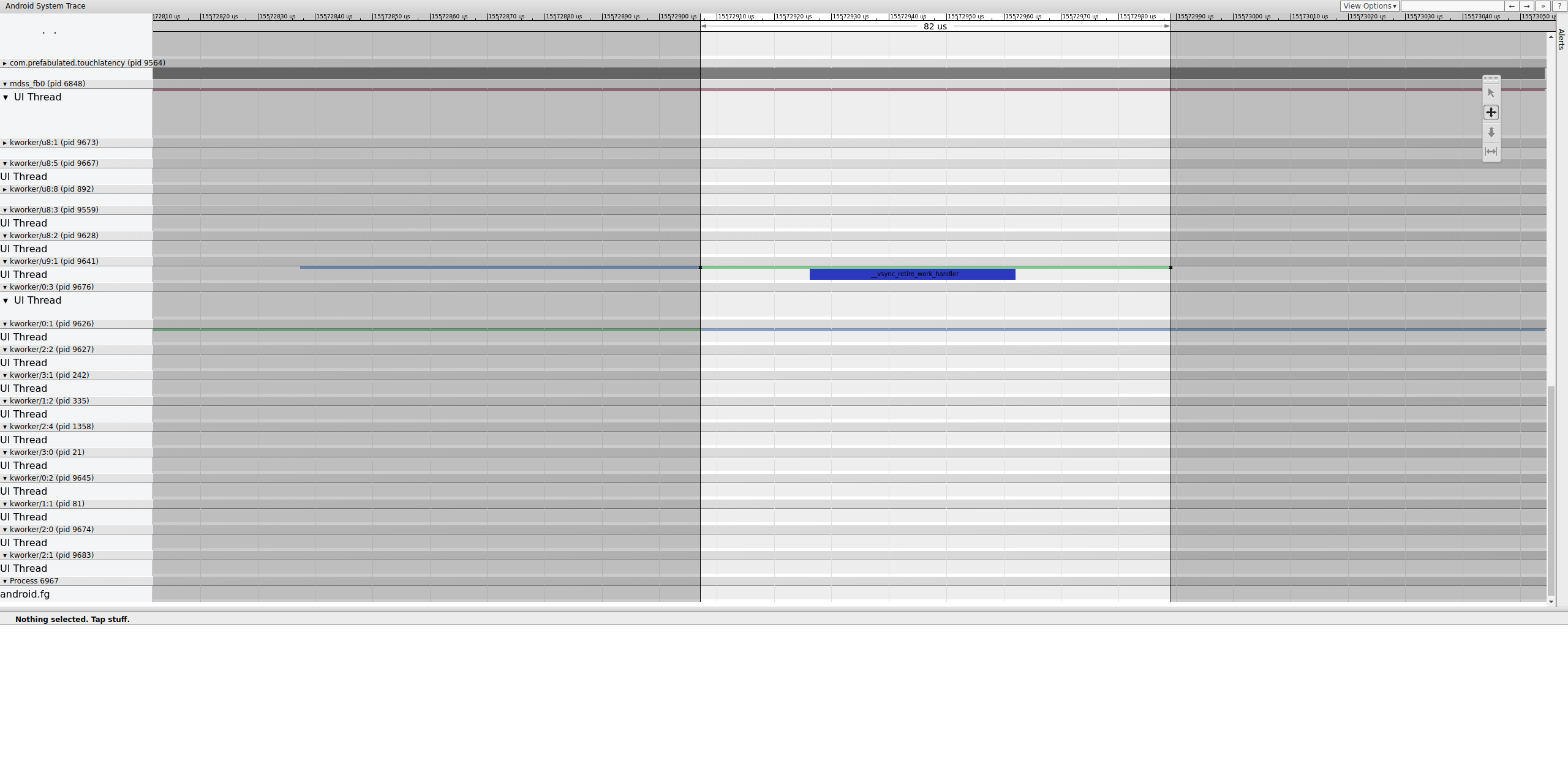
Figura 15: Investiga el extremo de la valla.
Una fila de trabajo contiene __vsync_retire_work_handler, que se ejecuta cuando cambia la barrera. Si revisas el código fuente del kernel, puedes ver que forma parte del controlador de pantalla. Parece estar en la ruta crítica de la canalización de visualización, por lo que debe ejecutarse lo más rápido posible. Se puede ejecutar durante unos 70 μs (no es un retraso de programación largo), pero es una cola de trabajo y es posible que no se programe con precisión.
Revisa el fotograma anterior para determinar si contribuyó al problema. A veces, la fluctuación puede acumularse con el tiempo y, finalmente, provocar que se incumpla el plazo:
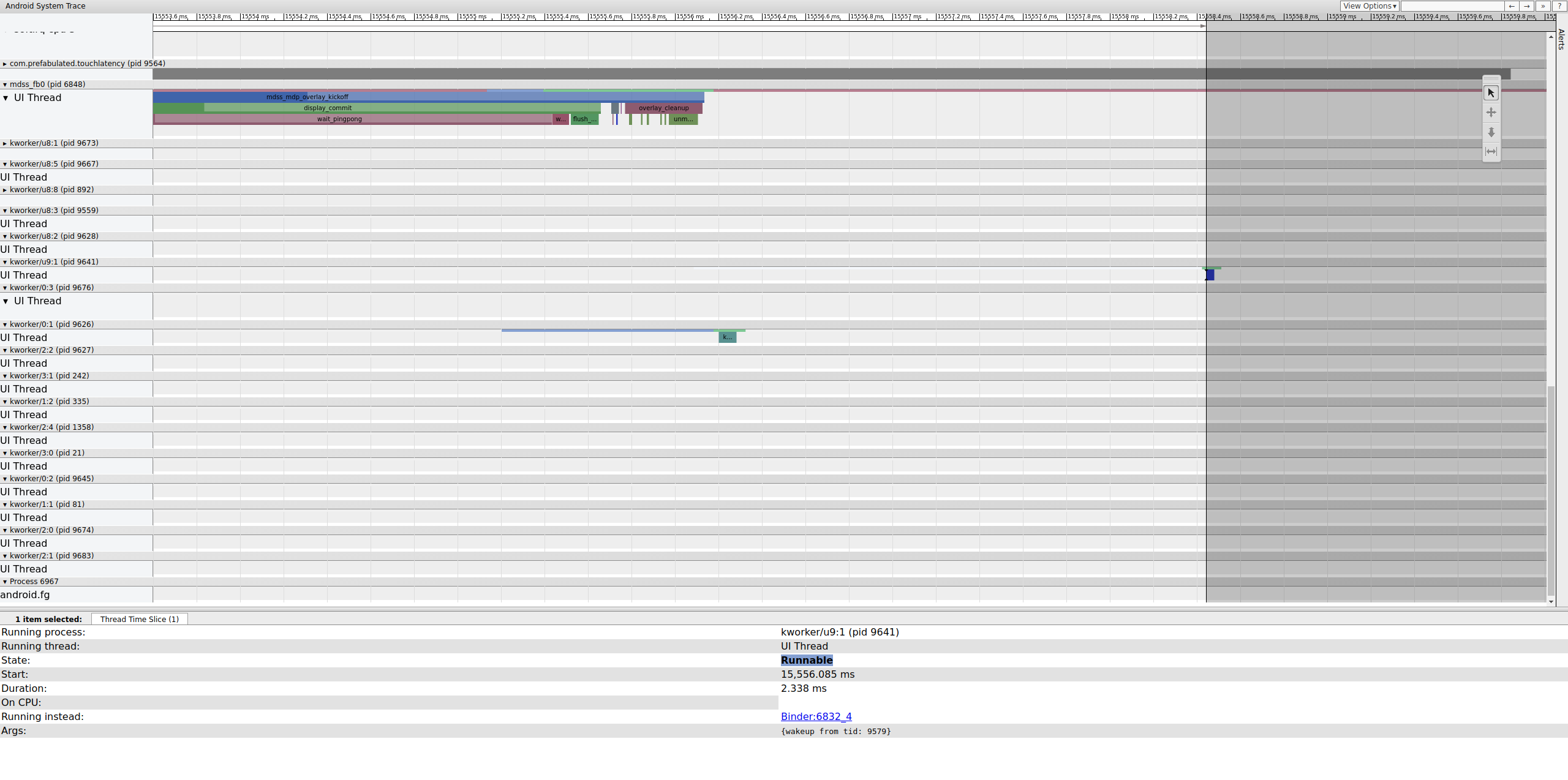
Figura 16: Fotograma anterior
La línea ejecutable en kworker no se ve porque el visualizador la pone blanca cuando se selecciona, pero las estadísticas cuentan la historia: 2.3 ms de retraso del programador para parte de la ruta crítica de la canalización de visualización es malo.
Antes de continuar, corrige la demora. Para ello, mueve esta parte de la ruta crítica de la canalización de visualización de una cola de trabajo (que se ejecuta como un subproceso de SCHED_OTHER CFS) a un kthread de SCHED_FIFO dedicado. Esta función necesita garantías de sincronización que las workqueues no pueden proporcionar (y no están diseñadas para hacerlo).
No está claro que este sea el motivo del jank. Fuera de los casos fáciles de diagnosticar, como la contención de bloqueo del kernel que hace que los subprocesos críticos para la pantalla se suspendan, los registros no suelen especificar el problema. Este jitter podría haber sido la causa de la pérdida de fotograma. Los tiempos de barrera deberían ser de 16.7 ms, pero no se acercan a ese valor en los fotogramas anteriores al fotograma descartado. Dado lo estrechamente acoplado que está el canal de procesamiento de la pantalla, es posible que la fluctuación alrededor de los tiempos de la barrera haya provocado una pérdida de fotogramas.
En este ejemplo, la solución implica convertir __vsync_retire_work_handler de una cola de trabajo a un kthread dedicado. Esto genera mejoras notables en el jitter y reduce el jank en la prueba de la pelota que rebota. Los seguimientos posteriores muestran tiempos de valla que se acercan mucho a los 16.7 ms.