
VTS ダッシュボード バックエンドは、スケーラビリティ、パフォーマンス、柔軟性に優れた継続的インテグレーション ダッシュボードをサポートできるよう、データベースの機能を十分に理解したうえで慎重に設計する必要があります。Google Cloud Datastore は、トランザクション ACID 保証と、エンティティ グループ内での結果整合性、強整合性を提供する NoSQL データベースです。 ただし、SQL データベースとは(そして Cloud Bigtable とさえも)大きく構造が異なります。テーブル、行、セルの代わりに、種類、エンティティ、プロパティを使用します。
以降のセクションでは、VTS ダッシュボード ウェブサービスに有効なバックエンドを作成するためのデータ構造とクエリパターンの概要を説明します。
エンティティ
次のエンティティは、VTS テスト実行からのサマリーとリソースを格納します。
- テスト エンティティ。特定のテストのテスト実行に関するメタデータを格納します。キーはテスト名です。プロパティには、アラートジョブが更新したときからの、不合格の数、合格の数、テストケースの中断のリストが含まれています。
- テスト実行エンティティ。特定のテストの実行に関するメタデータを格納します。テストの開始と終了のタイムスタンプ、テストビルド ID、テストケースの数、実行のタイプ(送信前、送信後、ローカル)、ログリンクのリスト、ホストマシン名、カバレッジ サマリーの数を格納しなければなりません。
- デバイス情報エンティティ。テスト実行中に使用されたデバイスの詳細が含まれます。デバイスビルド ID、製品名、ビルド ターゲット、ブランチ、ABI 情報などです。テスト実行エンティティとは別に格納され、1 対多の形でマルチデバイスのテスト実行をサポートします。
- ポイント実行エンティティのプロファイリング。テスト実行内の特定のプロファイリング ポイントで収集されたデータの集計結果です。プロファイリング データの軸ラベル、プロファイリング ポイント名、値、タイプ、回帰モードが示されます。
- カバレッジ エンティティ。1 つのファイルに対して収集されたカバレッジ データを示します。Git のプロジェクト情報、ファイルパス、ソースファイル内の 1 行ごとのカバレッジ数のリストが含まれています。
- テストケース実行エンティティ。テスト実行における特定のテストケースの結果(テストケース名とその結果など)を示します。
- ユーザーのお気に入りエンティティ。各ユーザー サブスクリプションは、テストへの参照と App Engine ユーザー サービスから生成されたユーザー ID を含むエンティティで表すことができます。これにより、効率的な双方向クエリが可能になります。つまり、テストに登録されたすべてのユーザーに対してと、ユーザーがお気に入りに登録したすべてのテストに対してです。
エンティティのグループ化
各テスト モジュールは、エンティティ グループのルートを表します。テスト実行エンティティは、このグループの子であると同時に、それぞれのテストとテスト実行の祖先に関連するデバイス エンティティ、プロファイリング ポイント エンティティ、カバレッジ エンティティの親でもあります。
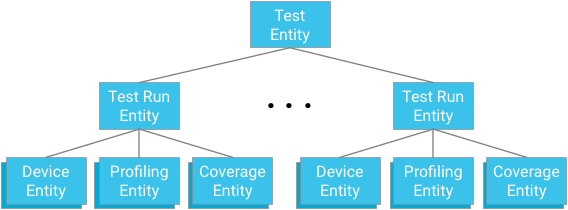
重要な点: 系図を設計する際は、効率的で整合性のあるクエリ メカニズムを提供する必要性と、データベースによって適用される制限との間でバランスをとる必要があります。
メリット
整合性の要件により、トランザクションの結果は commit されるまで未来のオペレーションから見えず、過去のトランザクションは現在のオペレーションから見えます。Cloud Datastore では、エンティティのグループ化により、グループ内で読み書きの強整合性アイランドを作成します。この場合は、すべてのテスト実行とテスト モジュールに関するデータです。これには次の利点があります。
- アラートジョブによるテスト モジュールの状態の読み取りと更新は、アトミックなものとして扱うことができます。
- テスト モジュール内のテストケース結果が整合性のある状態で示されることが保証されます。
- 系図の木構造内でのクエリが高速化されます。
制限事項
エンティティ グループへの書き込みを 1 秒あたり 1 エンティティを超える速度で行うと、書き込みが拒否される可能性があるため、推奨されません。アラートジョブとアップロードによる書き込みが 1 秒あたり 1 回を超える速度で行われない限り、構造は破綻せず、強整合性が保証されます。
最終的には、1 テスト モジュール、1 秒あたり 1 回の書き込みという上限は妥当です。通常、テスト実行には VTS フレームワークのオーバーヘッドを含めて 1 分以上かかります。60 台以上のホストで同時にテストを実行しない限り、書き込みのボトルネックは発生しません。各モジュールが 1 時間以上かかるテストプランの一部である場合、このようなことが起こる可能性はさらに低くなります。ホストが同時にテストを実行し、同じホストへのバースト書き込みを引き起こす場合、異常に対処するのは簡単です(例: 書き込みエラーを捉えて再試行するなど)。
スケーリングに関する考慮事項
テスト実行がテストを親として持つ必要は必ずしもありません。たとえば、他のキーを取り、プロパティとしてテスト名やテスト開始時刻を持つこともできます。ただし、強整合性はなくなり、結果整合性に留まることになります。たとえば、アラートジョブから見て、テスト モジュール内にある最新のテスト実行のスナップショットに、テスト実行間での相互の整合性がない可能性があります。これは、グローバルな状態に表れるテスト実行のシーケンスは完全に正確なものではない可能性があるということです。このことは、実行シーケンスの整合性のあるスナップショットでは必ずしもない、単一のテスト モジュール内におけるテスト実行の見え方にも影響します。最終的なスナップショットは整合性のあるものになりますが、最新のデータでは保証されません。
テストケース
もう一つの潜在的なボトルネックは、多数のテストケースがある大規模なテストです。書き込みスループットの最大値を 1 秒あたり 1 エンティティ グループに制限することと、最大トランザクション サイズを 500 エンティティに制限することが効果的です。
一つの方法は、テスト実行を祖先として持つテストケースを指定することです。カバレッジ データ、プロファイリング データ、デバイス情報の保存方法と同様です。
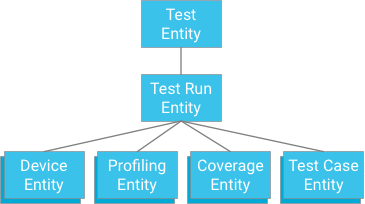
この方法でアトミック性と整合性が得られますが、トランザクションが 500 エンティティに制限されている場合、テストに 498 個を超えるテストケース(カバレッジやプロファイリング データはないものとする)を持たせることができないという強い制限が発生します。 テストがこれを超える場合、1 つのトランザクションでテストケースの結果を一度にすべて書き込むことができず、テストケースを別々のトランザクションに分割すると 1 秒あたり 1 回というエンティティ グループ書き込みの最大スループットを超える可能性があります。この方法は、パフォーマンスを犠牲にすることなくスケールさせることができないため、推奨されません。
ただし、テストケースの結果をテスト実行の子として保存する代わりに、下図のように、テストケースを独立に保存し、そのキーをテスト実行に渡すこともできます(テスト実行にそのテストケース エンティティの ID のリストを持たせます)。
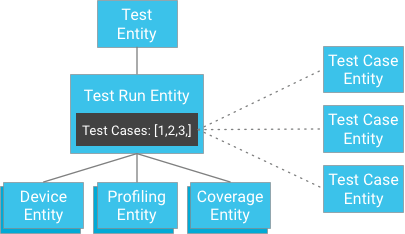
一見すると、これは強整合性の保証を破るように見えるかもしれません。 しかし、クライアントがテスト実行エンティティとテストケースの ID のリストを持っている場合、クエリを作成する必要はありません。テストケースを ID で直接取得することができ、常に整合性が保証されます。この方法により、エンティティ グループ内で過度の書き込みが発生する恐れなしに強整合性を獲得しながら、テスト実行が持つことのできるテストケースの数の制限を大幅に緩和します。
データアクセス パターン
VTS ダッシュボードでは、次のデータアクセス パターンが使用されます。
- ユーザーのお気に入り。特定の App Engine ユーザー オブジェクトをプロパティとして持つユーザーのお気に入りエンティティに関する等値フィルタを使用して、クエリを実行できます。
- テストリスト。テスト エンティティの単純なクエリ。ホームページのレンダリングに使用される帯域幅を減らすために、合格と不合格の数に予測値を使用して、アラートジョブで使用される不合格になったテストケースの ID とその他のメタデータの長いリストを省略できます。
- テスト実行。テスト実行エンティティにクエリを実行するには、キー(タイムスタンプ)での並べ替えと、ビルド ID、合格回数などのテスト実行プロパティでの適当なフィルタリングが必要です。テスト エンティティ キーを使用して祖先クエリを実行すると、読み取りは強整合となります。この時点で、すべてのテストケースの結果は、テスト実行プロパティに格納されている ID のリストを使用して取得できます。これもデータストアの get オペレーションの性質によって強整合性が保証されます。
- プロファイリングとカバレッジ データ。テストに関連するプロファイリング データやカバレッジ データに対するクエリを、他のテスト実行データ(他のプロファイリング データやカバレッジ データ、テストケース データなど)を取得することなく、実行できます。テストとテスト実行エンティティ キーを使用する祖先クエリでは、テスト実行中に記録されたすべてのプロファイリング ポイントが取得されます。プロファイリング ポイント名またはファイル名でのフィルタリングも行うことで、単一のプロファイリング エンティティまたはカバレッジ エンティティを取得できます。祖先クエリの性質により、このオペレーションには強整合性があります。
これらのデータパターンの実際の UI とスクリーンショットの詳細については、VTS ダッシュボードの UI をご覧ください。