
O Android 8.0 inclui testes de desempenho de binder e hwbinder para taxa de transferência e latência. Embora existam muitos cenários para detectar problemas de desempenho perceptíveis, a execução desses cenários pode ser demorada, e os resultados geralmente não estão disponíveis até que um sistema seja integrado. Usar os testes de desempenho fornecidos facilita o teste durante o desenvolvimento, detecta problemas graves mais cedo e melhora a experiência do usuário.
Os testes de desempenho incluem as quatro categorias a seguir:
- Capacidade de processamento do binder (disponível em
system/libhwbinder/vts/performance/Benchmark_binder.cpp) - Latência de vinculação (disponível em
frameworks/native/libs/binder/tests/schd-dbg.cpp) - Taxa de transferência do hwbinder (disponível em
system/libhwbinder/vts/performance/Benchmark.cpp) - Latência do hwbinder (disponível em
system/libhwbinder/vts/performance/Latency.cpp)
Sobre o binder e o hwbinder
Binder e hwbinder são infraestruturas de comunicação interprocessos (IPC, na sigla em inglês) do Android que compartilham o mesmo driver do Linux, mas têm as seguintes diferenças qualitativas:
| Proporção | fichário | hwbinder |
|---|---|---|
| Objetivo | Fornecer um esquema de IPC de uso geral para o framework | Comunicar-se com hardware |
| Propriedade | Otimizado para uso do framework do Android | Latência mínima de overhead |
| Mudar a política de programação para primeiro/segundo plano | Sim | Não |
| Como passar argumentos | Usa a serialização com suporte do objeto Parcel | Usa buffers de dispersão e evita a sobrecarga para copiar dados necessários para a serialização de pacotes. |
| Herança de prioridade | Não | Sim |
Processos de binder e hwbinder
Um visualizador de systrace mostra as transações da seguinte maneira:
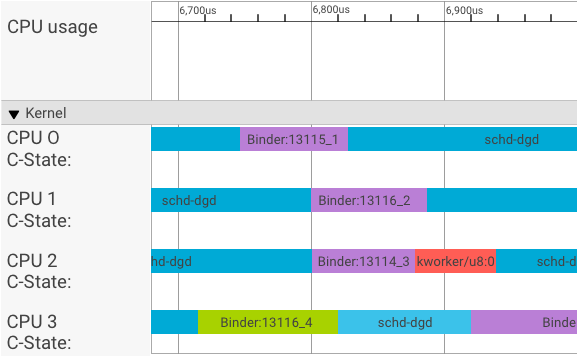
No exemplo acima:
- Os quatro (4) processos schd-dbg são processos de cliente.
- Os quatro (4) processos de vinculação são processos do servidor (o nome começa com Binder e termina com um número de sequência).
- Um processo do cliente é sempre associado a um processo do servidor, que é dedicado ao cliente.
- Todos os pares de processos cliente-servidor são programados de forma independente pelo kernel simultaneamente.
Na CPU 1, o kernel do SO executa o cliente para emitir a solicitação. Em seguida, ele usa a mesma CPU sempre que possível para ativar um processo do servidor, processar a solicitação e alternar o contexto de volta após a conclusão da solicitação.
Capacidade de processamento x latência
Em uma transação perfeita, em que o processo do cliente e do servidor muda sem problemas, os testes de throughput e latência não produzem mensagens substancialmente diferentes. No entanto, quando o kernel do SO está processando uma solicitação de interrupção (IRQ, na sigla em inglês) de hardware, aguardando bloqueios ou simplesmente escolhendo não processar uma mensagem imediatamente, uma bolha de latência pode se formar.
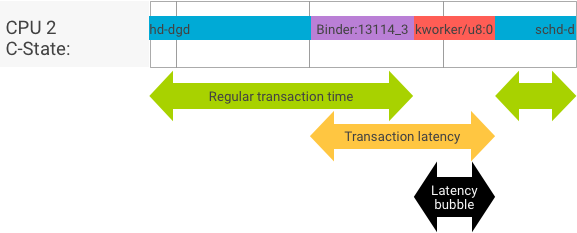
O teste de throughput gera um grande número de transações com diferentes tamanhos de payload, fornecendo uma boa estimativa para o tempo de transação normal (nos melhores cenários) e a capacidade máxima que o vinculamento pode alcançar.
Por outro lado, o teste de latência não realiza ações no payload para minimizar o tempo de transação normal. Podemos usar o tempo de transação para estimar o overhead do vinculador, criar estatísticas para o pior caso e calcular a proporção de transações cuja latência atende a um prazo especificado.
Processar inversões de prioridade
Uma inversão de prioridade ocorre quando uma linha de execução com prioridade mais alta está esperando por uma linha de execução com prioridade mais baixa. Os aplicativos em tempo real (RT, na sigla em inglês) têm um problema de inversão de prioridade:
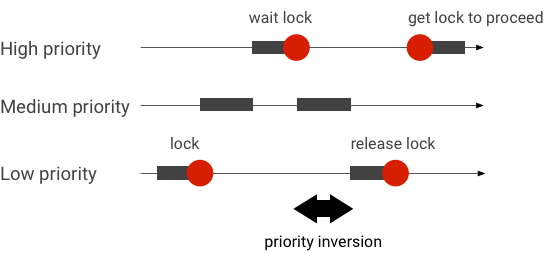
Ao usar a programação do Linux Completely Fair Scheduler (CFS), uma linha de execução sempre tem a chance de ser executada, mesmo quando outras linhas de execução têm uma prioridade mais alta. Como resultado, os aplicativos com programação de CFS processam a inversão de prioridade como comportamento esperado e não como um problema. Nos casos em que o framework do Android precisa de programação de RT para garantir o privilégio de linhas de execução de alta prioridade, a inversão de prioridade precisa ser resolvida.
Exemplo de inversão de prioridade durante uma transação de vinculação (a linha de execução de RT é logicamente bloqueada por outras linhas de execução de CFS ao aguardar que uma linha de execução de vinculação seja servida):
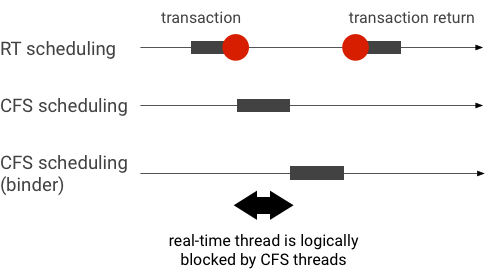
Para evitar bloqueios, use a herança de prioridade para elevar temporariamente a linha de execução do Binder para uma linha de execução RT quando ela atender uma solicitação de um cliente RT. Lembre-se de que a programação de RT tem recursos limitados e deve ser usada com cuidado. Em um sistema com n CPUs, o número máximo de linhas de execução RT atuais também é n. Outras linhas de execução RT podem precisar esperar (e, portanto, perder os prazos) se todas as CPUs estiverem ocupadas por outras linhas de execução RT.
Para resolver todas as possíveis inversões de prioridade, use a herança de prioridade para o binder e o hwbinder. No entanto, como o binder é amplamente usado em todo o sistema, ativar a herança de prioridade para transações de binder pode spammar o sistema com mais linhas de execução em tempo real do que ele pode atender.
Executar testes de capacidade
O teste de throughput é executado em relação ao throughput de transação de binder/hwbinder. Em um sistema que não está sobrecarregado, as bolhas de latência são raras, e o impacto delas pode ser eliminado desde que o número de iterações seja alto o suficiente.
- O teste de throughput do binder está em
system/libhwbinder/vts/performance/Benchmark_binder.cpp. - O teste de throughput do hwbinder está em
system/libhwbinder/vts/performance/Benchmark.cpp.
Resultados dos testes
Exemplo de resultados do teste de throughput para transações que usam diferentes tamanhos de payload:
Benchmark Time CPU Iterations --------------------------------------------------------------------- BM_sendVec_binderize/4 70302 ns 32820 ns 21054 BM_sendVec_binderize/8 69974 ns 32700 ns 21296 BM_sendVec_binderize/16 70079 ns 32750 ns 21365 BM_sendVec_binderize/32 69907 ns 32686 ns 21310 BM_sendVec_binderize/64 70338 ns 32810 ns 21398 BM_sendVec_binderize/128 70012 ns 32768 ns 21377 BM_sendVec_binderize/256 69836 ns 32740 ns 21329 BM_sendVec_binderize/512 69986 ns 32830 ns 21296 BM_sendVec_binderize/1024 69714 ns 32757 ns 21319 BM_sendVec_binderize/2k 75002 ns 34520 ns 20305 BM_sendVec_binderize/4k 81955 ns 39116 ns 17895 BM_sendVec_binderize/8k 95316 ns 45710 ns 15350 BM_sendVec_binderize/16k 112751 ns 54417 ns 12679 BM_sendVec_binderize/32k 146642 ns 71339 ns 9901 BM_sendVec_binderize/64k 214796 ns 104665 ns 6495
- Tempo indica o atraso de ida e volta medido em tempo real.
- CPU indica o tempo acumulado quando as CPUs são programadas para o teste.
- Iterações indica o número de vezes que a função de teste foi executada.
Por exemplo, para um payload de 8 bytes:
BM_sendVec_binderize/8 69974 ns 32700 ns 21296
… a capacidade máxima de processamento que o vinculador pode alcançar é calculada como:
Capacidade MÁXIMA com payload de 8 bytes = (8 * 21296)/69974 ~= 2.423 b/ns ~= 2.268 Gb/s
Opções de teste
Para receber resultados em .json, execute o teste com o
argumento --benchmark_format=json:
libhwbinder_benchmark --benchmark_format=json
{
"context": {
"date": "2017-05-17 08:32:47",
"num_cpus": 4,
"mhz_per_cpu": 19,
"cpu_scaling_enabled": true,
"library_build_type": "release"
},
"benchmarks": [
{
"name": "BM_sendVec_binderize/4",
"iterations": 32342,
"real_time": 47809,
"cpu_time": 21906,
"time_unit": "ns"
},
….
}Executar testes de latência
O teste de latência mede o tempo que o cliente leva para começar a inicializar a transação, mudar para o processo do servidor para processamento e receber o resultado. O teste também procura comportamentos conhecidos de programadores incorretos que podem afetar negativamente a latência da transação, como um programador que não oferece suporte à herança de prioridade ou à flag de sincronização.
- O teste de latência do binder está em
frameworks/native/libs/binder/tests/schd-dbg.cpp. - O teste de latência do hwbinder está em
system/libhwbinder/vts/performance/Latency.cpp.
Resultados dos testes
Os resultados (em .json) mostram estatísticas de latência média/melhor/pior e o número de prazos perdidos.
Opções de teste
Os testes de latência têm as seguintes opções:
| Comando | Descrição |
|---|---|
-i value |
Especifique o número de iterações. |
-pair value |
Especifique o número de pares de processos. |
-deadline_us 2500 |
Especifique o prazo em minutos. |
-v |
Receba uma saída detalhada (depuração). |
-trace |
Interromper o rastreamento quando um prazo for atingido. |
As seções a seguir detalham cada opção, descrevem o uso e fornecem exemplos de resultados.
Especificar iterações
Exemplo com um grande número de iterações e saída detalhada desativada:
libhwbinder_latency -i 5000 -pair 3
{
"cfg":{"pair":3,"iterations":5000,"deadline_us":2500},
"P0":{"SYNC":"GOOD","S":9352,"I":10000,"R":0.9352,
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}
},
"P1":{"SYNC":"GOOD","S":9334,"I":10000,"R":0.9334,
"other_ms":{ "avg":0.19, "wst":2.9 , "bst":0.055, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":3.1 , "bst":0.066, "miss":1, "meetR":0.9998}
},
"P2":{"SYNC":"GOOD","S":9369,"I":10000,"R":0.9369,
"other_ms":{ "avg":0.19, "wst":4.8 , "bst":0.055, "miss":6, "meetR":0.9988},
"fifo_ms": { "avg":0.15, "wst":1.8 , "bst":0.067, "miss":0, "meetR":1}
},
"inheritance": "PASS"
}Os resultados do teste mostram o seguinte:
"pair":3- Cria um par de cliente e servidor.
"iterations": 5000- Inclui 5.000 iterações.
"deadline_us":2500- O prazo é de 2.500us (2,5 ms). A maioria das transações precisa atender a esse valor.
"I": 10000- Uma única iteração de teste inclui duas (2) transações:
- Uma transação por prioridade normal (
CFS other) - Uma transação por prioridade em tempo real (
RT-fifo)
- Uma transação por prioridade normal (
"S": 9352- 9352 das transações são sincronizadas na mesma CPU.
"R": 0.9352- Indica a proporção em que o cliente e o servidor são sincronizados na mesma CPU.
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996}- O caso médio (
avg), o pior (wst) e o melhor (bst) para todas as transações emitidas por um autor da chamada de prioridade normal. Duas transaçõesmisso prazo, fazendo com que a proporção de atendimento (meetR) seja 0,9996. "fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}- Semelhante a
other_ms, mas para transações emitidas pelo cliente com prioridadert_fifo. É provável (mas não obrigatório) que ofifo_mstenha um resultado melhor do que oother_ms, com valoresavgewstmais baixos e ummeetRmais alto. A diferença pode ser ainda mais significativa com a carga em segundo plano.
Observação:a carga em segundo plano pode afetar o resultado de
capacidade e a tupla other_ms no teste de latência. Somente o
fifo_ms pode mostrar resultados semelhantes, desde que a carga em segundo plano tenha
uma prioridade menor que RT-fifo.
Especificar valores de par
Cada processo do cliente é associado a um processo do servidor dedicado ao cliente,
e cada par pode ser programado de forma independente para qualquer CPU. No entanto, a migração da CPU
não deve acontecer durante uma transação, desde que a flag SYNC seja
honor.
Verifique se o sistema não está sobrecarregado. Embora a latência alta em um sistema
sobrecarregado seja esperada, os resultados do teste para um sistema sobrecarregado não fornecem informações
úteis. Para testar um sistema com pressão mais alta, use -pair
#cpu-1 (ou -pair #cpu com cuidado). Testar usando
-pair n com n > #cpu sobrecarrega o
sistema e gera informações inúteis.
Especificar valores de prazo
Após testes extensivos de cenários de usuário (execução do teste de latência em um produto qualificado), determinamos que 2,5 ms é o prazo a ser atendido. Para novos aplicativos com requisitos mais altos (como 1.000 fotos/segundo), esse valor de prazo vai mudar.
Especificar saída detalhada
O uso da opção -v exibe uma saída detalhada. Exemplo:
libhwbinder_latency -i 1 -v-------------------------------------------------- service pid: 8674 tid: 8674 cpu: 1 SCHED_OTHER 0-------------------------------------------------- main pid: 8673 tid: 8673 cpu: 1 -------------------------------------------------- client pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0-------------------------------------------------- fifo-caller pid: 8677 tid: 8678 cpu: 0 SCHED_FIFO 99 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 ??? 99-------------------------------------------------- other-caller pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 SCHED_OTHER 0
- A linha de execução de serviço é criada com uma
prioridade
SCHED_OTHERe executada emCPU:1compid 8674. - A primeira transação é iniciada por um
fifo-caller. Para atender a essa transação, o hwbinder faz upgrade da prioridade do servidor (pid: 8674 tid: 8676) para 99 e também a marca com uma classe de programação temporária (impresso como???). O programador coloca o processo do servidor emCPU:0para execução e o sincroniza com a mesma CPU com o cliente. - O autor da chamada da segunda transação tem uma
prioridade
SCHED_OTHER. O servidor é rebaixado e atende o autor da chamada com prioridadeSCHED_OTHER.
Usar o rastreamento para depuração
É possível especificar a opção -trace para depurar problemas de latência. Quando
usado, o teste de latência interrompe a gravação do tracelog no momento em que uma latência
inadequada é detectada. Exemplo:
atrace --async_start -b 8000 -c sched idle workq binder_driver sync freqlibhwbinder_latency -deadline_us 50000 -trace -i 50000 -pair 3deadline triggered: halt ∓ stop trace log:/sys/kernel/debug/tracing/trace
Os componentes a seguir podem afetar a latência:
- Modo de build do Android. O modo Eng geralmente é mais lento que o modo userdebug.
- Framework. Como o serviço de framework usa
ioctlpara configurar o vinculador? - Driver de vinculação. O driver oferece suporte a bloqueio de granularidade fina? Ele contém todos os patches de mudança de desempenho?
- Versão do kernel. Quanto melhor for a capacidade do kernel em tempo real, melhores serão os resultados.
- Configuração do kernel. A configuração do kernel contém
configurações
DEBUG, comoDEBUG_PREEMPTeDEBUG_SPIN_LOCK? - Programador do kernel. O kernel tem um programador com
economia de energia (EAS) ou um programador de processamento
heterogêneo (HMP, na sigla em inglês)? Algum driver do kernel (
cpu-freq,cpu-idle,cpu-hotplugetc.) afeta o programador?