
Android 8.0 شامل تست های عملکرد بایندر و hwbinder برای توان عملیاتی و تأخیر است. در حالی که سناریوهای زیادی برای تشخیص مشکلات عملکرد محسوس وجود دارد، اجرای چنین سناریوهایی میتواند زمانبر باشد و نتایج اغلب تا زمانی که یک سیستم یکپارچه نشود در دسترس نیست. استفاده از تست های عملکرد ارائه شده، آزمایش را در حین توسعه آسان تر می کند، مشکلات جدی را زودتر تشخیص می دهد و تجربه کاربر را بهبود می بخشد.
تست های عملکرد شامل چهار دسته زیر است:
- توان عملیاتی بایندر (موجود در
system/libhwbinder/vts/performance/Benchmark_binder.cpp) - تأخیر بایندر (موجود در
frameworks/native/libs/binder/tests/schd-dbg.cpp) - توان عملیاتی hwbinder (موجود در
system/libhwbinder/vts/performance/Benchmark.cpp) - تأخیر hwbinder (موجود در
system/libhwbinder/vts/performance/Latency.cpp)
درباره binder و hwbinder
Binder و hwbinder زیرساختهای ارتباط بین فرآیندی اندروید (IPC) هستند که درایور لینوکس یکسانی دارند اما تفاوتهای کیفی زیر دارند:
| جنبه | کلاسور | hwbinder |
|---|---|---|
| هدف | یک طرح IPC با هدف کلی برای چارچوب ارائه دهید | با سخت افزار ارتباط برقرار کنید |
| اموال | برای استفاده از چارچوب اندروید بهینه شده است | حداقل تاخیر سربار کم |
| سیاست زمانبندی را برای پیشزمینه/پسزمینه تغییر دهید | بله | خیر |
| استدلال در حال عبور | از سریال سازی پشتیبانی شده توسط شیء Parcel استفاده می کند | از بافرهای پراکنده استفاده می کند و از سربار برای کپی داده های مورد نیاز برای سریال سازی بسته اجتناب می کند |
| وراثت اولویت دار | خیر | بله |
فرآیندهای بایندر و hwbinder
یک systrace visualizer تراکنش ها را به صورت زیر نمایش می دهد:
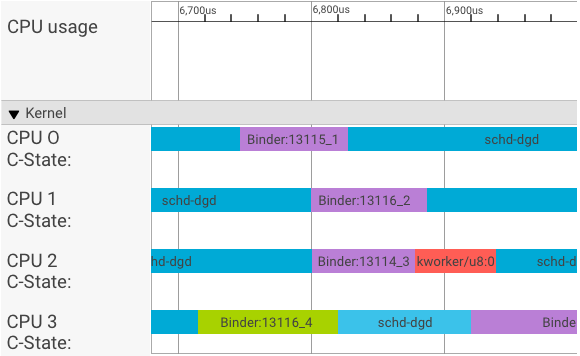
در مثال بالا:
- چهار (4) فرآیند schd-dbg فرآیندهای مشتری هستند.
- چهار (4) فرآیند بایندر فرآیندهای سرور هستند (نام با Binder شروع می شود و با یک شماره دنباله به پایان می رسد).
- یک فرآیند مشتری همیشه با یک فرآیند سرور که به مشتری آن اختصاص داده شده است، جفت می شود.
- تمام جفت های فرآیند مشتری-سرور به طور مستقل توسط هسته به طور همزمان برنامه ریزی می شوند.
در CPU 1، هسته سیستم عامل کلاینت را برای صدور درخواست اجرا می کند. سپس هر زمان که ممکن است از همان CPU برای بیدار کردن یک فرآیند سرور، رسیدگی به درخواست و سوئیچ زمینه پس از تکمیل درخواست استفاده می کند.
توان عملیاتی در مقابل تأخیر
در یک تراکنش کامل، که در آن فرآیند مشتری و سرور به طور یکپارچه جابجا میشوند، آزمایشهای توان عملیاتی و تأخیر پیامهای اساسی متفاوتی تولید نمیکنند. با این حال، هنگامی که هسته سیستم عامل در حال رسیدگی به درخواست وقفه (IRQ) از سخت افزار است، منتظر قفل است، یا صرفاً تصمیم می گیرد که بلافاصله یک پیام را مدیریت نکند، یک حباب تاخیر ایجاد می شود.
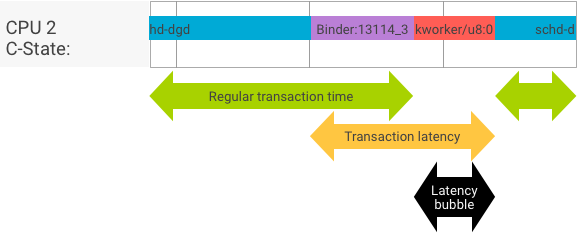
تست توان عملیاتی، تعداد زیادی تراکنش با اندازههای بار مختلف تولید میکند که تخمین خوبی برای زمان تراکنش منظم (در بهترین حالتها) و حداکثر توان عملیاتی که بایندر میتواند به دست آورد، ارائه میکند.
در مقابل، آزمون تأخیر هیچ عملی را روی بار انجام نمی دهد تا زمان تراکنش منظم را به حداقل برساند. ما میتوانیم از زمان تراکنش برای تخمین سربار بایندر استفاده کنیم، آماری را برای بدترین حالت ایجاد کنیم و نسبت تراکنشهایی را که تأخیر آنها به یک مهلت مشخص رسیده است، محاسبه کنیم.
وارونگی اولویت را مدیریت کنید
وارونگی اولویت زمانی اتفاق میافتد که رشتهای با اولویت بالاتر منطقاً منتظر رشتهای با اولویت پایینتر باشد. برنامه های بلادرنگ (RT) یک مشکل وارونگی اولویت دارند:
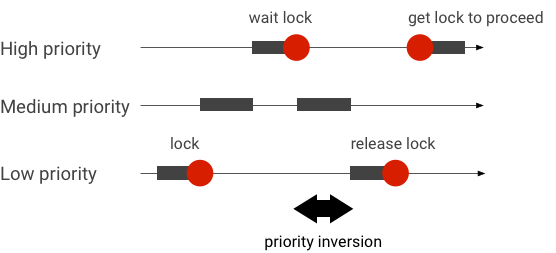
هنگام استفاده از زمانبندی کاملاً منصفانه لینوکس (CFS)، یک رشته همیشه این شانس را دارد که حتی زمانی که رشتههای دیگر اولویت بیشتری دارند اجرا شود. در نتیجه، برنامههای کاربردی با زمانبندی CFS، وارونگی اولویت را بهعنوان رفتار مورد انتظار و نه بهعنوان یک مشکل مدیریت میکنند. در مواردی که چارچوب اندروید به زمانبندی RT برای تضمین امتیاز رشتههای با اولویت بالا نیاز دارد، وارونگی اولویت باید حل شود.
مثال وارونگی اولویت در طول یک تراکنش بایندر (رشته RT به طور منطقی توسط رشتههای دیگر CFS مسدود میشود که در انتظار سرویسدهی رشته بایندر هستند):
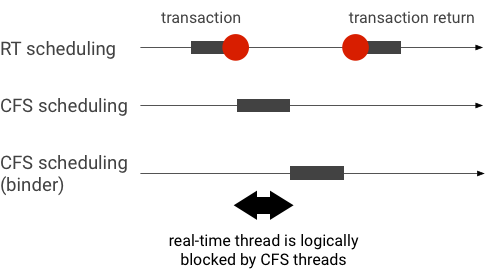
برای جلوگیری از انسداد، می توانید از وراثت اولویت استفاده کنید تا به طور موقت رشته Binder را به یک رشته RT افزایش دهید، زمانی که درخواستی از مشتری RT ارائه می دهد. به خاطر داشته باشید که زمانبندی RT منابع محدودی دارد و باید با دقت مورد استفاده قرار گیرد. در سیستمی با n CPU، حداکثر تعداد رشته های RT فعلی نیز n است. اگر تمام CPU ها توسط رشته های RT دیگر گرفته شوند، ممکن است رشته های RT اضافی باید منتظر بمانند (و در نتیجه ضرب الاجل خود را از دست بدهند).
برای حل همه وارونگی های اولویت ممکن، می توانید از وراثت اولویت برای هر دو بایندر و hwbinder استفاده کنید. با این حال، از آنجایی که بایندر به طور گسترده در سراسر سیستم استفاده میشود، فعال کردن وراثت اولویت برای تراکنشهای بایندر ممکن است سیستم را با رشتههای RT بیشتر از آنچه که میتواند سرویس دهد، هرزنامه کند.
تست های توان عملیاتی را اجرا کنید
تست توان عملیاتی در برابر توان عملیاتی تراکنش بایندر/hwbinder اجرا میشود. در سیستمی که بیش از حد بارگذاری نمی شود، حباب های تاخیر نادر هستند و تا زمانی که تعداد تکرارها به اندازه کافی زیاد باشد، می توان تاثیر آنها را از بین برد.
- آزمایش توان بایندر در
system/libhwbinder/vts/performance/Benchmark_binder.cppاست. - آزمایش توان عملیاتی hwbinder در
system/libhwbinder/vts/performance/Benchmark.cppاست.
نتایج تست
نمونهای از نتایج آزمایش توان عملیاتی برای تراکنشهایی که از اندازههای بار مختلف استفاده میکنند:
Benchmark Time CPU Iterations --------------------------------------------------------------------- BM_sendVec_binderize/4 70302 ns 32820 ns 21054 BM_sendVec_binderize/8 69974 ns 32700 ns 21296 BM_sendVec_binderize/16 70079 ns 32750 ns 21365 BM_sendVec_binderize/32 69907 ns 32686 ns 21310 BM_sendVec_binderize/64 70338 ns 32810 ns 21398 BM_sendVec_binderize/128 70012 ns 32768 ns 21377 BM_sendVec_binderize/256 69836 ns 32740 ns 21329 BM_sendVec_binderize/512 69986 ns 32830 ns 21296 BM_sendVec_binderize/1024 69714 ns 32757 ns 21319 BM_sendVec_binderize/2k 75002 ns 34520 ns 20305 BM_sendVec_binderize/4k 81955 ns 39116 ns 17895 BM_sendVec_binderize/8k 95316 ns 45710 ns 15350 BM_sendVec_binderize/16k 112751 ns 54417 ns 12679 BM_sendVec_binderize/32k 146642 ns 71339 ns 9901 BM_sendVec_binderize/64k 214796 ns 104665 ns 6495
- زمان نشان دهنده تاخیر رفت و برگشت است که در زمان واقعی اندازه گیری می شود.
- CPU نشان دهنده زمان انباشته زمانی است که CPU ها برای آزمایش برنامه ریزی شده اند.
- Iterations تعداد دفعات اجرای تابع تست را نشان می دهد.
به عنوان مثال، برای یک بار 8 بایتی:
BM_sendVec_binderize/8 69974 ns 32700 ns 21296
حداکثر توانی که بایندر می تواند به دست آورد به صورت زیر محاسبه می شود:
حداکثر توان عملیاتی با بار 8 بایت = (8 * 21296)/69974 ~= 2.423 b/ns ~ = 2.268 گیگابیت بر ثانیه
گزینه های تست
برای دریافت نتایج در json.، آزمون را با آرگومان --benchmark_format=json اجرا کنید:
libhwbinder_benchmark --benchmark_format=json
{
"context": {
"date": "2017-05-17 08:32:47",
"num_cpus": 4,
"mhz_per_cpu": 19,
"cpu_scaling_enabled": true,
"library_build_type": "release"
},
"benchmarks": [
{
"name": "BM_sendVec_binderize/4",
"iterations": 32342,
"real_time": 47809,
"cpu_time": 21906,
"time_unit": "ns"
},
….
}تست های تأخیر را اجرا کنید
تست تأخیر زمان لازم برای شروع اولیه تراکنش، تغییر به فرآیند سرور برای مدیریت و دریافت نتیجه را اندازه گیری می کند. این تست همچنین به دنبال رفتارهای بد زمانبندی شناخته شده است که میتوانند بر تأخیر تراکنش تأثیر منفی بگذارند، مانند زمانبندیای که از ارث بری اولویت پشتیبانی نمیکند یا پرچم همگامسازی را رعایت نمیکند.
- تست تأخیر بایندر در
frameworks/native/libs/binder/tests/schd-dbg.cppاست. - تست تأخیر hwbinder در
system/libhwbinder/vts/performance/Latency.cppاست.
نتایج تست
نتایج (به .json) آمار متوسط/بهترین/بدترین تاخیر و تعداد مهلتهای از دست رفته را نشان میدهد.
گزینه های تست
تست تاخیر گزینه های زیر را انجام می دهد:
| فرمان | توضیحات |
|---|---|
-i value | تعداد تکرارها را مشخص کنید. |
-pair value | تعداد جفت های فرآیند را مشخص کنید. |
-deadline_us 2500 | مهلت را در ما مشخص کنید. |
-v | خروجی پرمخاطب (اشکال زدایی) دریافت کنید. |
-trace | ردیابی را در یک ضرب الاجل متوقف کنید. |
بخشهای زیر هر گزینه را به تفصیل شرح میدهند، استفاده را توضیح میدهند و نتایج نمونه را ارائه میدهند.
تکرارها را مشخص کنید
مثال با تعداد زیادی تکرار و خروجی پرمخاطب غیرفعال:
libhwbinder_latency -i 5000 -pair 3
{
"cfg":{"pair":3,"iterations":5000,"deadline_us":2500},
"P0":{"SYNC":"GOOD","S":9352,"I":10000,"R":0.9352,
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}
},
"P1":{"SYNC":"GOOD","S":9334,"I":10000,"R":0.9334,
"other_ms":{ "avg":0.19, "wst":2.9 , "bst":0.055, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":3.1 , "bst":0.066, "miss":1, "meetR":0.9998}
},
"P2":{"SYNC":"GOOD","S":9369,"I":10000,"R":0.9369,
"other_ms":{ "avg":0.19, "wst":4.8 , "bst":0.055, "miss":6, "meetR":0.9988},
"fifo_ms": { "avg":0.15, "wst":1.8 , "bst":0.067, "miss":0, "meetR":1}
},
"inheritance": "PASS"
}این نتایج آزمایش موارد زیر را نشان می دهد:
-
"pair":3 - یک جفت کلاینت و سرور ایجاد می کند.
-
"iterations": 5000 - شامل 5000 تکرار
-
"deadline_us":2500 - مهلت 2500 us (2.5ms) است. انتظار می رود اکثر معاملات این مقدار را برآورده کنند.
-
"I": 10000 - یک تکرار آزمایشی شامل دو (2) تراکنش است:
- یک تراکنش با اولویت عادی (
CFS other) - یک تراکنش بر اساس اولویت زمان واقعی (
RT-fifo)
- یک تراکنش با اولویت عادی (
-
"S": 9352 - 9352 تراکنش در همان CPU همگام سازی می شوند.
-
"R": 0.9352 - نسبتی که کلاینت و سرور با هم در یک CPU همگام می شوند را نشان می دهد.
-
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996} - میانگین (
avg)، بدترین (wst) و بهترین (bst) مورد برای همه تراکنشهای صادر شده توسط تماسگیرنده با اولویت عادی. دو تراکنش ضرب الاجل راmiss، و نسبت ملاقات (meetR) 0.9996 است. -
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1} - مشابه
other_ms، اما برای تراکنش های صادر شده توسط مشتری با اولویتrt_fifo. به احتمال زیاد (اما الزامی نیست) کهfifo_msنتیجه بهتری نسبت بهother_msداشته باشد، با مقادیرavgوwstکمتر وmeetRبالاتر (تفاوت میتواند حتی با بارگذاری در پسزمینه مهمتر باشد).
توجه: بار پسزمینه ممکن است بر نتیجه توان و تاپل other_ms در آزمون تأخیر تأثیر بگذارد. فقط fifo_ms ممکن است نتایج مشابهی را نشان دهد تا زمانی که بار پسزمینه اولویت کمتری نسبت به RT-fifo داشته باشد.
مقادیر جفت را مشخص کنید
هر فرآیند مشتری با یک فرآیند سرور اختصاص داده شده برای مشتری جفت می شود و هر جفت ممکن است به طور مستقل برای هر CPU برنامه ریزی شود. با این حال، تا زمانی که پرچم SYNC honor است، انتقال CPU نباید در طول تراکنش اتفاق بیفتد.
اطمینان حاصل کنید که سیستم بیش از حد بارگذاری نشده است! در حالی که تاخیر بالایی در یک سیستم بارگذاری شده انتظار می رود، نتایج آزمایش برای یک سیستم بارگذاری شده اطلاعات مفیدی را ارائه نمی دهد. برای آزمایش سیستمی با فشار بالاتر، -pair #cpu-1 (یا -pair #cpu با احتیاط) استفاده کنید. آزمایش با استفاده از -pair n با n > #cpu سیستم را بارگذاری می کند و اطلاعات بی فایده تولید می کند.
مقادیر ضرب الاجل را مشخص کنید
پس از آزمایش گسترده سناریوی کاربر (اجرای آزمایش تأخیر روی یک محصول واجد شرایط)، تعیین کردیم که 2.5 میلیثانیه آخرین مهلت رسیدن به آن است. برای برنامه های جدید با نیازهای بالاتر (مانند 1000 عکس در ثانیه)، این مقدار مهلت تغییر خواهد کرد.
خروجی مفصل را مشخص کنید
استفاده از گزینه -v خروجی پرمخاطب را نمایش می دهد. مثال:
libhwbinder_latency -i 1 -v-------------------------------------------------- service pid: 8674 tid: 8674 cpu: 1 SCHED_OTHER 0-------------------------------------------------- main pid: 8673 tid: 8673 cpu: 1 -------------------------------------------------- client pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0-------------------------------------------------- fifo-caller pid: 8677 tid: 8678 cpu: 0 SCHED_FIFO 99 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 ??? 99-------------------------------------------------- other-caller pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 SCHED_OTHER 0
- رشته سرویس با اولویت
SCHED_OTHERایجاد شده و درCPU:1باpid 8674اجرا میشود. - سپس اولین تراکنش توسط یک
fifo-callerشروع می شود. برای انجام این تراکنش، hwbinder اولویت سرور (pid: 8674 tid: 8676) را به 99 ارتقا میدهد و همچنین آن را با یک کلاس زمانبندی گذرا (چاپ شده به عنوان???) علامتگذاری میکند. سپس زمانبند، فرآیند سرور را درCPU:0قرار میدهد تا اجرا شود و آن را با همان CPU با مشتری خود همگامسازی میکند. - تماس گیرنده تراکنش دوم دارای اولویت
SCHED_OTHERاست. سرور خود را تنزل می دهد و با اولویتSCHED_OTHERبه تماس گیرنده سرویس می دهد.
از ردیابی برای اشکال زدایی استفاده کنید
میتوانید گزینه -trace را برای رفع اشکال مشکلات تأخیر مشخص کنید. هنگام استفاده، تست تأخیر ضبط ردیابی را در لحظه ای که تأخیر بد شناسایی می شود متوقف می کند. مثال:
atrace --async_start -b 8000 -c sched idle workq binder_driver sync freqlibhwbinder_latency -deadline_us 50000 -trace -i 50000 -pair 3deadline triggered: halt ∓ stop trace log:/sys/kernel/debug/tracing/trace
مؤلفه های زیر می توانند بر تأخیر تأثیر بگذارند:
- حالت ساخت اندروید . حالت Eng معمولا کندتر از حالت userdebug است.
- چارچوب . چگونه سرویس فریمورک از
ioctlبرای پیکربندی بایندر استفاده می کند؟ - راننده کلاسور . آیا درایور از قفل ریزدانه پشتیبانی می کند؟ آیا شامل تمام وصله های چرخشی عملکردی است؟
- نسخه کرنل . هر چه هسته قابلیت زمان واقعی بهتری داشته باشد، نتایج بهتری خواهد داشت.
- پیکربندی هسته آیا پیکربندی هسته حاوی تنظیمات
DEBUGمانندDEBUG_PREEMPTوDEBUG_SPIN_LOCKاست؟ - زمانبندی کرنل آیا هسته دارای یک زمانبندی آگاه از انرژی (EAS) یا زمانبندی چند پردازشی ناهمگن (HMP) است؟ آیا درایورهای هسته (درایور
cpu-freq، درایورcpu-idle،cpu-hotplugو غیره) بر زمانبندی تأثیر می گذارند؟