
Android 8.0에는 처리량 및 지연 시간과 관련된 바인더 및 hwbinder 성능 테스트가 포함되어 있습니다. 인식 가능한 성능 문제를 감지하기 위한 여러 가지 시나리오가 있지만 실제로 이러한 시나리오를 테스트하는 데는 시간이 오래 걸리고 시스템 통합이 된 환경에서만 결과를 얻을 수 있는 경우가 많습니다. 따라서 Android 8.0에 포함된 성능 테스트를 사용하면 더 쉽게 개발 과정에서 테스트를 실시하고 심각한 문제를 조기에 감지하며 사용자 환경을 개선할 수 있습니다.
성능 테스트에는 다음과 같은 네 가지 카테고리가 있습니다.
- 바인더 처리량(
system/libhwbinder/vts/performance/Benchmark_binder.cpp에서 사용 가능함) - 바인더 지연 시간(
frameworks/native/libs/binder/tests/schd-dbg.cpp에서 사용 가능함) - hwbinder 처리량(
system/libhwbinder/vts/performance/Benchmark.cpp에서 사용 가능함) - hwbinder 지연 시간(
system/libhwbinder/vts/performance/Latency.cpp에서 사용 가능함)
바인더 및 hwbinder 정보
바인더 및 hwbinder는 동일한 Linux 드라이버를 공유하지만 다음과 같은 정성적 차이가 있는 Android 프로세스 간 통신(IPC) 인프라입니다.
| 특성 | 바인더 | hwbinder |
|---|---|---|
| 목적 | 프레임워크에 관한 범용 IPC 스키마 제공 | 하드웨어와 통신 |
| 속성 | Android 프레임워크 사용에 최적화됨 | 최소 오버헤드 낮은 지연 시간 |
| 포그라운드/백그라운드에 관한 스케줄링 정책 변경 | 예 | 아니요 |
| 인수 전달 | Parcel 객체에서 지원하는 직렬화 사용 | 분산 버퍼 사용 및 Parcel 직렬화에 필요한 데이터를 복사하기 위한 오버헤드 방지 |
| 우선순위 상속 | 아니요 | 예 |
바인더 및 hwbinder 프로세스
systrace 비주얼라이저는 다음과 같이 트랜잭션을 표시합니다.
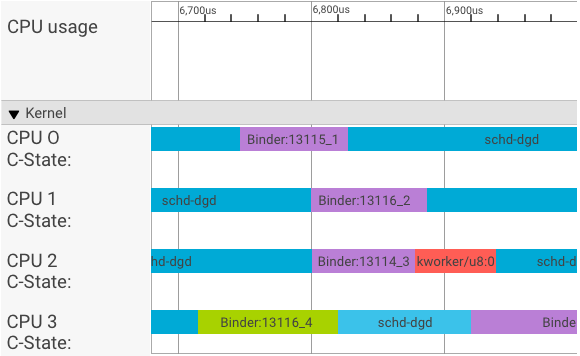
위의 예에서
- 4개의 schd-dbg 프로세스는 클라이언트 프로세스입니다.
- 4개의 바인더 프로세스는 서버 프로세스입니다(이름은 Binder로 시작하고 시퀀스 번호로 끝남).
- 클라이언트 프로세스는 클라이언트 전용 서버 프로세스와 항상 쌍을 이룹니다.
- 모든 클라이언트-서버 프로세스 쌍은 커널에 의해 개별적으로 동시 예약됩니다.
CPU 1에서 OS 커널이 클라이언트를 실행하여 요청을 보냅니다. 그런 다음 가능한 한 동일한 CPU를 사용하여 서버 프로세스의 절전 모드를 해제하고 요청을 처리한 다음 요청이 완료되면 다시 컨텍스트 전환이 이루어집니다.
처리량 vs. 지연 시간
클라이언트와 서버 프로세스가 원활히 전환되는 완벽한 트랜잭션에서는 처리량과 지연 시간 테스트에서 생성되는 메시지가 크게 다르지 않습니다. 하지만 OS 커널이 하드웨어에서 보내는 인터럽트 요청(IRQ)을 처리하거나 잠금을 기다리거나 단순히 메시지를 즉시 처리하지 않도록 선택하는 경우 지연 시간 버블이 생길 수 있습니다.
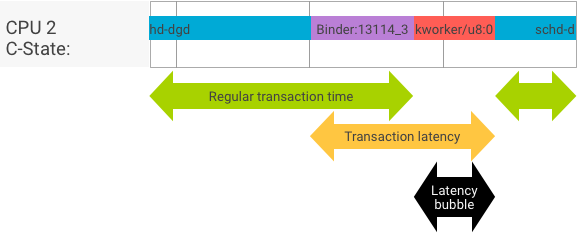
처리량 테스트는 페이로드 크기가 서로 다른 대규모 트랜잭션을 생성하고 정기 트랜잭션 시간(최상의 사례 시나리오의 경우)을 타당하게 예측하며 바인더의 최대 가능 처리량을 제공합니다.
반대로 지연 시간 테스트는 정기 트랜잭션 시간을 최소화하기 위해 페이로드에 어떠한 작업도 하지 않습니다. 트랜잭션 시간을 사용하여, 바인더 오버헤드를 추정하고 최악의 사례와 관련된 통계를 만들며 지연 시간이 지정된 기한을 맞추는 트랜잭션의 비율을 계산할 수 있습니다.
우선순위 역전 처리
우선순위가 더 높은 스레드가 우선순위가 더 낮은 스레드를 논리적으로 기다리고 있을 때 우선순위 역전이 발생합니다. 실시간(RT) 애플리케이션에는 다음과 같은 우선순위 역전 문제가 있습니다.
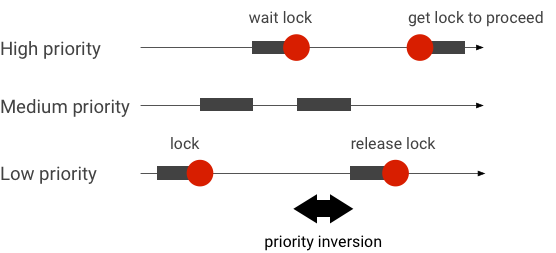
Linux CFS(Completely Fair Scheduler) 스케줄링을 사용하는 스레드는 다른 스레드가 더 높은 우선순위를 갖더라도 항상 실행될 가능성이 있습니다. 따라서 CFS 스케줄링을 사용하는 애플리케이션은 우선순위 역전을 문제가 아닌 예상된 동작으로 처리합니다. 하지만 우선순위가 높은 스레드의 권한을 보장하기 위해 Android 프레임워크에 RT 스케줄링이 필요한 경우 우선순위 역전을 해결해야 합니다.
바인더 트랜잭션 중에 발생한 우선순위 역전의 예(바인더 스레드가 처리할 때까지 대기하는 동안 RT 스레드가 다른 CFS 스레드에 의해 논리적으로 차단됨).
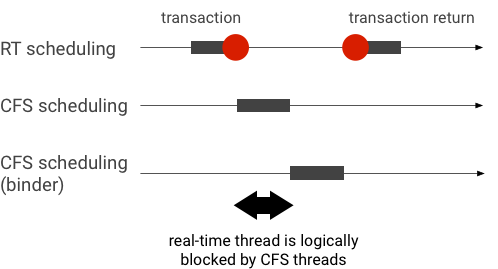
Binder 스레드가 RT 클라이언트로부터 받은 요청을 처리할 때 우선순위 상속을 사용하여 Binder 스레드를 일시적으로 RT 스레드로 에스컬레이션하면 차단 현상을 방지할 수 있습니다. RT 스케줄링은 리소스가 제한되어 있으므로 신중히 사용해야 합니다. CPU가 n개인 시스템에서 현재 RT 스레드의 최대 개수도 n개입니다. 다른 RT 스레드에서 모든 CPU를 사용하는 경우 추가 RT 스레드는 대기해야 할 수 있습니다(따라서 기한을 놓칠 수 있음).
발생할 수 있는 모든 우선순위 역전을 해결하려면 바인더와 hwbinder 모두에 우선순위 상속을 사용하면 됩니다. 그러나 바인더가 시스템 전반에 널리 사용되는 상태에서 바인더 트랜잭션에 우선순위 상속을 사용 설정하면 시스템에서 처리할 수 있는 것보다 더 많은 RT 스레드가 시스템에 넘칠 수 있습니다.
처리량 테스트 실행
처리량 테스트는 바인더/hwbinder 트랜잭션 처리량을 대상으로 실행됩니다. 오버로드되지 않은 시스템에서 지연 시간 버블은 거의 발생하지 않고, 반복 횟수가 많으면 지연 시간 버블의 영향을 없앨 수 있습니다.
- 바인더 처리량 테스트는
system/libhwbinder/vts/performance/Benchmark_binder.cpp에 있습니다. - hwbinder 처리량 테스트는
system/libhwbinder/vts/performance/Benchmark.cpp에 있습니다.
테스트 결과
서로 다른 페이로드 크기를 사용하는 트랜잭션의 처리량 테스트 결과 예:
Benchmark Time CPU Iterations --------------------------------------------------------------------- BM_sendVec_binderize/4 70302 ns 32820 ns 21054 BM_sendVec_binderize/8 69974 ns 32700 ns 21296 BM_sendVec_binderize/16 70079 ns 32750 ns 21365 BM_sendVec_binderize/32 69907 ns 32686 ns 21310 BM_sendVec_binderize/64 70338 ns 32810 ns 21398 BM_sendVec_binderize/128 70012 ns 32768 ns 21377 BM_sendVec_binderize/256 69836 ns 32740 ns 21329 BM_sendVec_binderize/512 69986 ns 32830 ns 21296 BM_sendVec_binderize/1024 69714 ns 32757 ns 21319 BM_sendVec_binderize/2k 75002 ns 34520 ns 20305 BM_sendVec_binderize/4k 81955 ns 39116 ns 17895 BM_sendVec_binderize/8k 95316 ns 45710 ns 15350 BM_sendVec_binderize/16k 112751 ns 54417 ns 12679 BM_sendVec_binderize/32k 146642 ns 71339 ns 9901 BM_sendVec_binderize/64k 214796 ns 104665 ns 6495
- Time은 실시간으로 측정된 왕복 지연을 나타냅니다.
- CPU는 CPU가 테스트용으로 예약된 경우의 누적 시간을 나타냅니다.
- Iterations는 테스트 함수가 실행된 횟수를 나타냅니다.
예를 들어 8바이트 페이로드의 경우
BM_sendVec_binderize/8 69974 ns 32700 ns 21296
바인더의 최대 가능 처리량은 다음과 같이 계산됩니다.
8바이트 페이로드일 때의 최대 처리량 = (8 * 21296)/69974 ~= 2.423b/ns ~= 2.268Gb/s
테스트 옵션
.json으로 결과를 가져오려면 --benchmark_format=json 인수를 사용하여 테스트를 실행합니다.
libhwbinder_benchmark --benchmark_format=json
{
"context": {
"date": "2017-05-17 08:32:47",
"num_cpus": 4,
"mhz_per_cpu": 19,
"cpu_scaling_enabled": true,
"library_build_type": "release"
},
"benchmarks": [
{
"name": "BM_sendVec_binderize/4",
"iterations": 32342,
"real_time": 47809,
"cpu_time": 21906,
"time_unit": "ns"
},
….
}지연 시간 테스트 실행
지연 시간 테스트는 클라이언트가 트랜잭션 초기화를 시작하고 결과를 처리하고 수신하기 위해 서버 프로세스로 전환하는 데 걸리는 시간을 측정합니다. 또한 지연 시간 테스트는 트랜잭션 지연 시간에 부정적인 영향을 줄 수 있는 것으로 알려진 잘못된 스케줄러 동작(예: 스케줄러가 우선순위 상속을 지원하지 않거나 동기화 플래그를 허용하지 않는 동작)도 찾습니다.
- 바인더 지연 시간 테스트는
frameworks/native/libs/binder/tests/schd-dbg.cpp에 있습니다. - hwbinder 지연 시간 테스트는
system/libhwbinder/vts/performance/Latency.cpp에 있습니다.
테스트 결과
결과(.json 형식)에는 평균/최상/최악 지연 시간과 기한을 놓친 횟수에 관한 통계가 나와 있습니다.
테스트 옵션
지연 시간 테스트에는 다음과 같은 옵션이 있습니다.
| 명령어 | 설명 |
|---|---|
-i value |
반복 횟수를 지정합니다. |
-pair value |
프로세스 쌍의 개수를 지정합니다. |
-deadline_us 2500 |
기한을 지정합니다(단위: us). |
-v |
상세(디버깅) 출력을 가져옵니다. |
-trace |
기한에 도달하면 추적을 중지합니다. |
다음 섹션에서는 각 옵션의 세부정보를 제공하고 사용법을 설명하며 결과에 관한 예를 제시합니다.
반복 지정
대규모 반복과 상세 출력이 비활성화된 예:
libhwbinder_latency -i 5000 -pair 3
{
"cfg":{"pair":3,"iterations":5000,"deadline_us":2500},
"P0":{"SYNC":"GOOD","S":9352,"I":10000,"R":0.9352,
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}
},
"P1":{"SYNC":"GOOD","S":9334,"I":10000,"R":0.9334,
"other_ms":{ "avg":0.19, "wst":2.9 , "bst":0.055, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":3.1 , "bst":0.066, "miss":1, "meetR":0.9998}
},
"P2":{"SYNC":"GOOD","S":9369,"I":10000,"R":0.9369,
"other_ms":{ "avg":0.19, "wst":4.8 , "bst":0.055, "miss":6, "meetR":0.9988},
"fifo_ms": { "avg":0.15, "wst":1.8 , "bst":0.067, "miss":0, "meetR":1}
},
"inheritance": "PASS"
}이 테스트 결과의 항목은 다음과 같습니다.
"pair":3- 한 개의 클라이언트와 서버 쌍을 만듭니다.
"iterations": 5000- 반복을 5,000번 포함합니다.
"deadline_us":2500- 기한이 2,500us(2.5ms)입니다. 대부분의 트랜잭션이 이 값을 충족할 것으로 예상됩니다.
"I": 10000- 단일 테스트 반복에 두 개의 트랜잭션이 포함됩니다.
- 일반적인 우선순위에 의한 한 개의 트랜잭션(
CFS other) - 실시간 우선순위에 의한 한 개의 트랜잭션(
RT-fifo)
- 일반적인 우선순위에 의한 한 개의 트랜잭션(
"S": 9352- 9,352번의 트랜잭션이 동일한 CPU에서 동기화됩니다.
"R": 0.9352- 클라이언트와 서버가 동일한 CPU에서 함께 동기화된 비율을 나타냅니다.
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996}- 일반적인 우선순위 호출자에 의해 실행된 모든 트랜잭션의 평균(
avg), 최악(wst) 및 최상(bst) 사례. 트랜잭션 2개가 기한을miss해서 충족도(meetR)가 0.9996입니다. "fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}other_ms와 유사하지만 우선순위가rt_fifo인 클라이언트에서 실행한 트랜잭션의 경우입니다.fifo_ms가avg값과wst값이 더 낮고meetR값이 더 높아(백그라운드에 부하가 있는 경우 차이가 훨씬 더 클 수 있음)other_ms보다 결과가 더 좋을 수 있습니다(반드시 그러한 것은 아님).
참고: 백그라운드 부하는 지연 시간 테스트의 처리량 결과와 other_ms 튜플에 영향을 줄 수 있습니다. 백그라운드 부하의 우선순위가 RT-fifo보다 낮은 한 fifo_ms에만 유사 결과가 나타날 수 있습니다.
쌍 값 지정
각 클라이언트 프로세스는 클라이언트 전용 서버 프로세스와 쌍을 이루고 각 쌍은 CPU에 개별적으로 예약될 수 있습니다. 하지만 SYNC 플래그가 honor인 한 트랜잭션 중에는 CPU 이전이 발생해서는 안 됩니다.
시스템이 오버로드되지 않았는지 확인합니다. 오버로드된 시스템에서 긴 지연 시간이 예상되지만 오버로드된 시스템에 관한 테스트 결과에서 유용한 정보가 제공되지 않습니다. 시스템을 더 높은 압력으로 테스트하려면 -pair
#cpu-1(또는 주의하여 -pair #cpu)을 사용합니다. n > #cpu인 -pair n을 사용하여 테스트하면 시스템이 오버로드되고 쓸모없는 정보가 생성됩니다.
기한 값 지정
광범위한 사용자 시나리오 테스트(검증된 제품에서 지연 시간 테스트 실행)를 거친 후 2.5ms를 충족해야 할 기한으로 정했습니다. 더 높은 수준의 요구사항을 갖는 새 애플리케이션(예: 초당 1,000장의 사진)의 경우 이 기한 값은 변경됩니다.
상세 출력 지정
-v 옵션을 사용하면 상세 출력이 표시됩니다. 예:
libhwbinder_latency -i 1 -v-------------------------------------------------- service pid: 8674 tid: 8674 cpu: 1 SCHED_OTHER 0-------------------------------------------------- main pid: 8673 tid: 8673 cpu: 1 -------------------------------------------------- client pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0-------------------------------------------------- fifo-caller pid: 8677 tid: 8678 cpu: 0 SCHED_FIFO 99 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 ??? 99-------------------------------------------------- other-caller pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 SCHED_OTHER 0
- 서비스 스레드가
SCHED_OTHER우선순위로 생성되고CPU:1에서pid 8674인 상태로 실행됩니다. - 그런 다음 첫 번째 트랜잭션이
fifo-caller에 의해 시작됩니다. 이 트랜잭션을 처리하기 위해 hwbinder는 서버의 우선순위(pid: 8674 tid: 8676)를 99로 업그레이드하고 서버를 임시 스케줄링 클래스로 표시(???로 표시됨)합니다. 그러면 스케줄러가 실행할 서버 프로세스를CPU:0에 두고 그 서버 프로세스를 클라이언트가 있는 동일한 CPU와 동기화합니다. - 두 번째 트랜잭션 호출자의 우선순위는
SCHED_OTHER입니다. 서버가 자체적으로 다운그레이드되어 우선순위가SCHED_OTHER인 호출자를 처리합니다.
디버깅에 트레이스 사용
-trace 옵션을 지정하여 지연 시간 문제를 디버그할 수 있습니다. 이 옵션을 사용하면 잘못된 지연 시간이 감지되는 순간 지연 시간 테스트에서 tracelog 기록을 중지합니다. 예:
atrace --async_start -b 8000 -c sched idle workq binder_driver sync freqlibhwbinder_latency -deadline_us 50000 -trace -i 50000 -pair 3deadline triggered: halt ∓ stop trace log:/sys/kernel/debug/tracing/trace
지연 시간에 영향을 줄 수 있는 구성요소는 다음과 같습니다.
- Android 빌드 모드 대개 Eng 모드는 userdebug 모드보다 느립니다.
- 프레임워크 프레임워크 서비스가
ioctl을 사용하여 어떻게 바인더에 구성되나요? - 바인더 드라이버 드라이버가 정밀한 잠금을 지원하나요? 드라이버에 모든 성능 조정 패치가 들어 있나요?
- 커널 버전 커널의 실시간 기능이 좋을수록 결과가 더 좋습니다.
- 커널 구성 커널 구성에
DEBUG_PREEMPT,DEBUG_SPIN_LOCK같은DEBUG구성이 들어 있나요? - 커널 스케줄러 커널에 EAS(Energy-Aware Scheduler) 또는 HMP(Heterogeneous Multi-Processing) 스케줄러가 있나요? 커널 드라이버(
cpu-freq드라이버,cpu-idle드라이버,cpu-hotplug등)가 스케줄러에 영향을 미치나요?