
如需为一个可扩展、性能卓越且高度灵活的持续集成信息中心提供支持,就必须在充分了解数据库功能的前提下精心设计 VTS 信息中心后端。Google Cloud Datastore 是一个 NoSQL 数据库,提供事务性 ACID 保证,可确保最终一致性以及实体组内的高一致性。不过,其结构与 SQL 数据库(甚至是 Cloud Bigtable)大相径庭,因为它使用的是种类、实体和属性(而非表格、行和单元格)。
以下部分概括介绍了用于为 VTS 信息中心网络服务创建高效后端的数据结构和查询模式。
实体
以下实体会存储来自 VTS 测试运行的摘要和资源:
- 测试实体。测试实体存储与特定测试的测试运行相关的元数据。测试实体的键是测试名称,其属性包括自警报作业对其进行更新以来的失败计数、通过计数和测试用例中断情况列表。
- 测试运行实体。测试运行实体包含由特定测试的运行产生的元数据。它必须存储以下信息:测试的开始时间戳和结束时间戳、测试的 build ID、通过及失败的测试用例数、运行类型(如提交前、提交后或本地)、日志链接列表、主机名称以及覆盖率摘要计数。
- 设备信息实体。设备信息实体包含有关测试运行期间所用设备的详细信息。具体而言,它包含设备的 build ID、产品名称、build 目标、分支和 ABI 信息。系统会将该实体与测试运行实体分开存储,以便通过一对多的方式支持多设备测试运行。
- 分析点运行实体。分析点运行实体会汇总在测试运行中针对特定分析点收集的数据。它会阐明分析数据的轴标签、分析点名称、值、类型和回归模式。
- 覆盖率实体。覆盖率实体会阐明针对一个文件收集的覆盖率数据。它包含 GIT 项目信息、文件路径以及源文件中每行的覆盖率计数列表。
- 测试用例运行实体。测试用例运行实体会阐明来自测试运行的特定测试用例的结果,包括测试用例名称及其结果。
- 用户收藏实体。每份用户订阅都可采用以下实体表示:包含对测试的引用以及由 App Engine 用户服务生成的用户 ID。这样便可实现高效的双向查询(即:查询订阅某项测试的所有用户以及某个用户收藏的所有测试)。
实体分组
每个测试模块都表示一个实体组的根。测试运行实体既是该组的子项,也是与各自的测试和测试运行祖先实体相关的设备实体、分析点实体和覆盖率实体的父项。
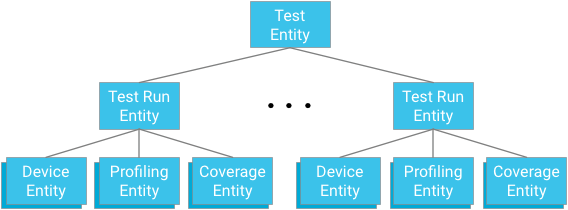
要点:设计祖先实体关系时,您必须在提供高效且一致的查询机制与遵守由数据库强制实施的限制之间取得平衡。
优势
对一致性的要求既可确保后续的操作在事务提交之前无法得知其影响,也可确保当前的操作可以了解过去的事务。在 Cloud Datastore 中,实体分组可在组内创建具有很高读写一致性的岛(在这种情况下,指的是与测试模块相关的所有测试运行和数据)。实体分组具有以下优势:
- 可将警报作业对测试模块状态的读取和更新视为原子操作
- 可在测试模块中以有保证的一致视图呈现测试用例结果
- 可在祖先实体树中更快速地查询
限制
不建议以超过每秒 1 个实体的速度向实体组写入实体,因为过快的写入操作可能会被拒绝。只要发生警报作业和上传操作的速度不超过每秒 1 次写入,结构就是稳定的,并且可以保证很高的一致性。
归根结底,每个测试模块每秒 1 次写入的上限是合理的,因为测试运行通常都需要至少 1 分钟的时间(包括 VTS 框架的开销);除非同时在超过 60 台不同的主机上一致地执行某项测试,否则不会出现写入瓶颈问题。此外,鉴于每个模块都是测试计划的一部分,而测试计划通常需要运行 1 小时以上,所以更不可能会出现瓶颈问题。即使因多台主机同时运行测试而导致对相同主机的写入操作短时暴增,也能轻松处理相关异常情况(例如,通过捕获写入错误并重试)。
与扩缩有关的注意事项
测试运行并不一定需要将测试作为父项(例如,它可以接受其他键,并将测试名称和测试开始时间作为属性);虽然这仍会实现最终一致性,却牺牲了高一致性。例如,警报作业可能无法看到测试模块中最近测试运行的相互一致的快照;这意味着,全局状态可能无法完全准确地描述测试运行的序列。这也可能会影响测试运行在单个测试模块中的显示(未必是运行序列的一致快照)。最终,快照会是一致的,但无法保证最新数据亦是如此。
测试用例
另一个潜在瓶颈是包含很多测试用例的大型测试。两项操作限制分别是:实体组内的写入吞吐量上限为每秒 1 个,事务大小上限为 500 个实体。
一种方法是指定一个将测试运行作为祖先实体的测试用例(类似于覆盖率数据、分析数据和设备信息的存储方式):
虽然这种方法可以提供原子性和一致性,但也会对测试施加诸多强硬限制:如果事务的上限是 500 个实体,则测试的测试用例数不得超过 498 个(假设无覆盖率数据或分析数据)。 如果测试要超过这一限制,单个事务便无法一次性写入所有测试用例结果,而如果将测试用例分到不同的事务中,则可能会超出每秒 1 次迭代的实体组写入吞吐量上限。由于这种解决方案无法在不影响性能的前提下很好地扩展,因此不建议使用。
不过,您可以单独存储测试用例并将其键提供给测试运行,而无需将测试用例结果作为测试运行的子项进行存储(测试运行包含其测试用例实体的标识符列表):
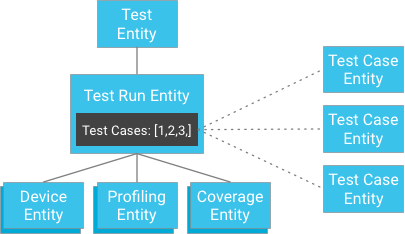
乍一看,这似乎破坏了对较高一致性的保证。不过,如果客户端具有测试运行实体和测试用例标识符列表,则无需构建查询;它可以直接按标识符获取测试用例,而这种方法始终都能保证一致性。这种方法显著减轻了对测试运行可具有的测试用例数的限制,同时也可在不会导致实体组内发生过多写入的情况下获得很高的一致性。
数据访问模式
VTS 信息中心采用以下数据访问模式:
- 用户收藏。您可通过以下方式查询用户收藏:在将特定 App Engine 用户对象作为属性的用户收藏实体上使用等式过滤器。
- 测试列表。测试列表是对测试实体的简单查询。要想减少呈现首页所需的带宽,您可使用估测值来体现通过计数和失败计数,以便略过包含失败的测试用例 ID 以及警报作业所用的其他元数据的潜在长列表。
- 测试运行。要想查询测试运行实体,除了需要对键(时间戳)进行排序,您可能还需要对测试运行属性(如 build ID、通过计数等)进行过滤。使用测试实体键执行祖先查询会使读取结果具有很高的一致性。此时,所有测试用例结果均可通过使用存储在测试运行属性中的 ID 列表进行检索;数据存储区获取操作的性质亦可保证相关结果会具有很高的一致性。
- 分析数据和覆盖率数据。查询与某项测试相关的分析数据或覆盖率数据时,您无需检索任何其他测试运行数据(例如,其他分析/覆盖率数据、测试用例数据等)。您既可借助使用测试和测试运行实体键的祖先查询来检索测试运行期间记录的所有分析点,也可通过按分析点名称或文件名过滤来检索单个分析实体或覆盖率实体。鉴于祖先查询的性质,这种操作可确保很高的一致性。
如需详细了解这些数据模式的实际界面和屏幕截图,请参阅 VTS 信息中心界面。