
本頁提供如何實作 Neural Networks API (NNAPI) 驅動程式的總覽。詳情請參閱 hardware/interfaces/neuralnetworks 中 HAL 定義檔案的說明文件。frameworks/ml/nn/driver/sample 中提供驅動程式實作範例。
如要進一步瞭解 Neural Networks API,請參閱「Neural Networks API」。
Neural Networks HAL
神經網路 (NN) HAL 會定義產品 (例如手機或平板電腦) 中各種裝置 (例如圖形處理器 (GPU) 和數位訊號處理器 (DSP)) 的抽象化。這些裝置的驅動程式必須符合 NN HAL。介面是在 hardware/interfaces/neuralnetworks 的 HAL 定義檔案中指定。
圖 1 顯示架構與驅動程式之間的介面一般流程。
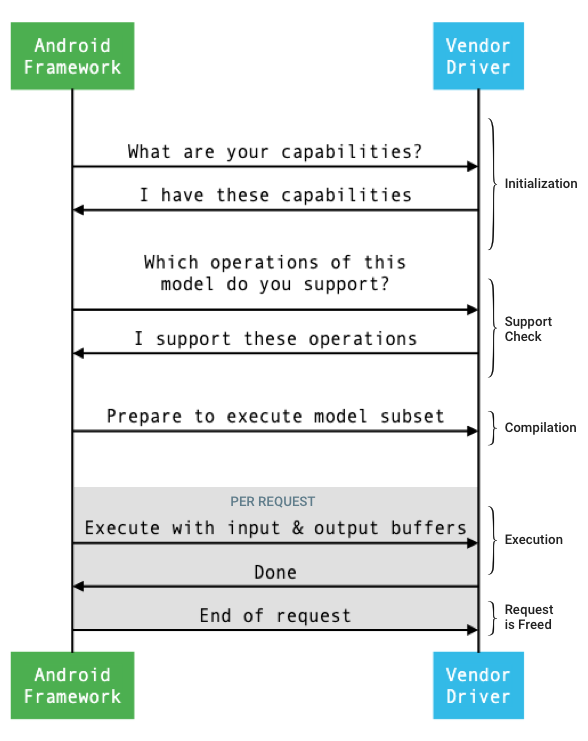
圖 1. 類神經網路流程
初始化
在初始化時,架構會使用 IDevice::getCapabilities_1_3 查詢驅動程式的功能。@1.3::Capabilities 結構包含所有資料類型,並以向量表示非寬鬆的效能。
為判斷如何將運算作業分配給可用裝置,架構會使用這些功能瞭解每個驅動程式的執行速度和能源效率。為提供這項資訊,驅動程式必須根據參考工作負載的執行情況,提供標準化效能數字。
如要判斷驅動程式在回應 IDevice::getCapabilities_1_3 時傳回的值,請使用 NNAPI 基準應用程式,評估對應資料類型的效能。建議使用 MobileNet v1 和 v2、asr_float,以及 tts_float 模型,測量 32 位元浮點值的效能;建議使用 MobileNet v1 和 v2 量化模型,測量 8 位元量化值的效能。詳情請參閱「Android Machine Learning Test Suite」。
在 Android 9 以下版本中,Capabilities 結構僅包含浮點和量化張量的驅動程式效能資訊,不包含純量資料型別。
在初始化程序中,架構可能會使用 IDevice::getType、IDevice::getVersionString、IDevice:getSupportedExtensions 和 IDevice::getNumberOfCacheFilesNeeded 查詢更多資訊。
在產品重新啟動之間,架構會預期本節所述的所有查詢,一律會針對特定驅動程式回報相同的值。否則,使用該驅動程式的應用程式可能會效能降低或行為異常。
編譯
架構會在收到應用程式的要求時,決定要使用哪些裝置。在 Android 10 中,應用程式可以探索及指定架構要選取的裝置。詳情請參閱「裝置探索與指派」。
在模型編譯期間,架構會呼叫 IDevice::getSupportedOperations_1_3,將模型傳送至每個候選驅動程式。每個驅動程式都會傳回布林值陣列,指出支援哪些模型作業。驅動程式可能會因多種原因,判斷無法支援特定作業。例如:
- 驅動程式不支援該資料類型。
- 驅動程式僅支援使用特定輸入參數的操作。舉例來說,驅動程式可能支援 3x3 和 5x5,但不支援 7x7 捲積運算。
- 驅動程式有記憶體限制,無法處理大型圖表或輸入內容。
如 OperandLifeTime 所述,在編譯期間,模型的輸入、輸出和內部運算元可能具有不明的維度或秩。詳情請參閱「輸出形狀」。
架構會呼叫 IDevice::prepareModel_1_3,指示每個選取的驅動程式準備執行模型子集。然後每個驅動程式會編譯自己的子集。舉例來說,驅動程式可能會產生程式碼,或建立權重的重新排序副本。因為模型編譯和要求執行之間可能會有相當長的時間間隔,因此不應在編譯期間指派大量裝置記憶體等資源。
如果成功,驅動程式會傳回 @1.3::IPreparedModel
控制代碼。如果驅動程式在準備模型子集時傳回失敗代碼,架構就會在 CPU 上執行整個模型。
為減少應用程式啟動時的編譯時間,驅動程式可以快取編譯構件。詳情請參閱編譯快取。
執行
當應用程式要求架構執行要求時,架構預設會呼叫 IPreparedModel::executeSynchronously_1_3 HAL 方法,在準備好的模型上執行同步執行作業。您也可以使用 execute_1_3 方法、executeFenced 方法 (請參閱「圍欄執行」) 或爆發執行,以非同步方式執行要求。
與非同步呼叫相比,同步執行呼叫可提升效能並減少執行緒負擔,因為只有在執行完成後,控制項才會傳回應用程式程序。也就是說,驅動程式不需要另外的機制,就能通知應用程式程序執行作業已完成。
使用非同步 execute_1_3 方法時,執行作業啟動後,控制項會返回應用程式程序,且驅動程式必須使用 @1.3::IExecutionCallback,在執行作業完成時通知架構。
傳遞至執行方法的 Request 參數會列出執行作業所用的輸入和輸出運算元。儲存運算元資料的記憶體必須使用以列為主的順序,第一個維度以最慢的速度疊代,且任何資料列結尾不得有填補。如要進一步瞭解運算元類型,請參閱運算元。
如果是 NN HAL 1.2 以上的驅動程式,要求完成時,系統會將錯誤狀態、輸出形狀和時間資訊傳回架構。執行期間,模型的輸出或內部運算元可能有一或多個未知維度或未知秩。當至少一個輸出運算元具有不明維度或等級時,驅動程式必須傳回動態大小的輸出資訊。
如果驅動程式使用 NN HAL 1.1 以下版本,要求完成時只會傳回錯誤狀態。輸入和輸出運算元的維度必須完整指定,才能順利完成執行作業。內部運算元可有一或多個未知維度,但必須指定秩。
對於跨多個驅動程式的使用者要求,架構會負責預留中繼記憶體,並排序對每個驅動程式的呼叫。
您可以在同一個 @1.3::IPreparedModel 上並行啟動多個要求。驅動程式可以並行執行要求,也可以序列化執行作業。
架構可以要求驅動程式保留多個準備好的模型。舉例來說,準備模型 m1、準備 m2、在 m1 上執行要求 r1、在 m2 上執行 r2、在 m1 上執行 r3、在 m2 上執行 r4、發布 (如「清除」一節所述) m1,以及發布 m2。
為避免首次執行速度緩慢,導致使用者體驗不佳 (例如第一格畫面出現延遲),驅動程式應在編譯階段執行大部分的初始化作業。首次執行時的初始化作業應僅限於會對系統健康狀態造成負面影響的動作 (若提早執行),例如保留大型暫時緩衝區或提高裝置的時脈頻率。如果驅動程式只能準備有限數量的並行模型,可能必須在首次執行時進行初始化。
在 Android 10 以上版本中,如果使用相同預先準備的模型連續執行多項作業,用戶端可能會選擇使用執行作業爆發物件,在應用程式和驅動程式程序之間進行通訊。詳情請參閱「爆量執行和快速訊息佇列」。
為提升連續多次執行的效能,驅動程式可以保留暫時緩衝區或提高時脈速率。建議您建立監控程式執行緒,以便在固定時間內未建立任何新要求時釋放資源。
輸出形狀
如果要求中有一或多個輸出運算元未指定所有維度,驅動程式必須在執行後提供輸出形狀清單,其中包含每個輸出運算元的維度資訊。如要進一步瞭解維度,請參閱 OutputShape。
如果執行作業因輸出緩衝區過小而失敗,驅動程式必須在輸出形狀清單中指出哪些輸出運算元的緩衝區大小不足,並盡可能回報維度資訊,對於不明的維度則使用零。
時間
在 Android 10 中,如果應用程式在編譯程序期間指定要使用的單一裝置,應用程式可以要求執行時間。詳情請參閱MeasureTiming和「探索和指派裝置」。在這種情況下,NN HAL 1.2 驅動程式必須在執行要求時測量執行時間,或回報 UINT64_MAX (表示執行時間無法使用)。驅動程式應盡量減少因測量執行時間而造成的效能損失。
驅動程式會在 Timing 結構中,以微秒為單位回報下列時間長度:
- 裝置上的執行時間:不包括在主機處理器上執行的驅動程式執行時間。
- 驅動程式的執行時間:包括裝置的執行時間。
這些時間長度必須包含執行作業暫停的時間,例如執行作業遭其他工作搶占,或是等待資源可用時。
如果系統未要求驅動程式測量執行時間,或發生執行錯誤,驅動程式必須將時間回報為 UINT64_MAX。即使驅動程式已要求測量執行時間長度,仍可改為回報裝置上的時間、驅動程式中的時間,或兩者皆是 UINT64_MAX。如果驅動程式回報的兩個時間長度值都不是 UINT64_MAX,驅動程式中的執行時間必須等於或超過裝置上的時間。
受限執行
在 Android 11 中,NNAPI 允許執行作業等待 sync_fence 控制代碼清單,並選擇性地傳回 sync_fence 物件,該物件會在執行作業完成時收到訊號。這可減少小型序列模型和串流應用實例的負擔。此外,封鎖執行作業還能與可發出信號或等待 sync_fence 的其他元件更有效率地互通。如要進一步瞭解 sync_fence,請參閱同步架構。
在柵欄執行作業中,架構會呼叫 IPreparedModel::executeFenced 方法,在已準備好的模型上啟動柵欄非同步執行作業,並等待同步柵欄向量。如果非同步工作在呼叫傳回前完成,系統可能會為 sync_fence 傳回空白控制代碼。此外,也必須傳回 IFencedExecutionCallback 物件,讓架構查詢錯誤狀態和時間長度資訊。
執行完成後,可透過 IFencedExecutionCallback::getExecutionInfo 查詢下列兩個時間值,測量執行作業的持續時間。
timingLaunched: 從呼叫executeFenced到executeFenced發出傳回syncFence信號的時間長度。timingFenced:從執行作業等待的所有同步柵欄收到信號,到executeFenced發出傳回syncFence的信號,這段時間的長度。
控制流程
如果是搭載 Android 11 以上版本的裝置,NNAPI 會包含兩個控制流程作業 (IF 和 WHILE),這兩個作業會將其他模型做為引數,並有條件地 (IF) 或重複地 (WHILE) 執行這些模型。如要進一步瞭解如何實作這項功能,請參閱「控制流程」。
服務品質
在 Android 11 中,NNAPI 讓應用程式可以指示模型的相對優先順序、準備模型的預計最長時間,以及完成執行的預計最長時間,從而改善服務品質 (QoS)。詳情請參閱「服務品質」。
清除
應用程式使用完畢後,架構會釋放對 @1.3::IPreparedModel 物件的參照。當 IPreparedModel 物件不再被參照時,系統會在建立該物件的驅動程式服務中自動銷毀該物件。此時,驅動程式的解構函式實作項目可以回收模型專屬資源。如果驅動程式服務希望在用戶端不再需要 IPreparedModel 物件時自動銷毀該物件,則在透過 IPreparedModelCallback::notify_1_3 傳回 IPreparedeModel 物件後,不得保留任何對 IPreparedModel 物件的參照。
CPU 使用率
驅動程式應使用 CPU 設定運算。驅動程式不應使用 CPU 執行圖表運算,因為這會干擾架構正確分配工作的能力。驅動程式應向架構回報無法處理的部分,並讓架構處理其餘部分。
架構會為所有 NNAPI 作業提供 CPU 實作,但供應商定義的作業除外。詳情請參閱供應商擴充功能。
Android 10 中導入的作業 (API 級別 29) 僅有參考 CPU 實作,可驗證 CTS 和 VTS 測試是否正確。相較於 NNAPI CPU 實作,行動裝置機器學習架構中包含的最佳化實作更受歡迎。
公用函式
NNAPI 程式碼集包含驅動程式服務可使用的公用程式函式。
frameworks/ml/nn/common/include/Utils.h 檔案包含各種公用程式函式,例如用於記錄和在不同 NN HAL 版本之間轉換的函式。
VLogging:
VLOG是 AndroidLOG周圍的包裝函式巨集,只有在debug.nn.vlog屬性中設定適當的標記時,才會記錄訊息。initVLogMask()必須在呼叫VLOG之前呼叫。VLOG_IS_ON巨集可用於檢查VLOG目前是否已啟用,如果不需要,即可略過複雜的記錄程式碼。這個屬性的值必須為以下其中一種:- 空字串,表示不應執行任何記錄作業。
- 權杖
1或all,表示要完成所有記錄。 - 以空格、半形逗號或半形冒號分隔的標記清單,用於指出要執行的記錄作業。標記為
compilation、cpuexe、driver、execution、manager和model。
compliantWithV1_*:如果 NN HAL 物件可以轉換為不同 HAL 版本的相同型別,且不會遺失資訊,則傳回true。舉例來說,如果模型包含 NN HAL 1.1 或 NN HAL 1.2 中導入的作業類型,在V1_2::Model上呼叫compliantWithV1_0會傳回false。convertToV1_*:將 NN HAL 物件從一個版本轉換為另一個版本。如果轉換導致資訊遺失 (也就是說,新版型別無法完整表示值),系統就會記錄警告。功能:
nonExtensionOperandPerformance和update函式可用於建構Capabilities::operandPerformance欄位。查詢下列類型的屬性:
isExtensionOperandType、isExtensionOperationType、nonExtensionSizeOfData、nonExtensionOperandSizeOfData、nonExtensionOperandTypeIsScalar、tensorHasUnspecifiedDimensions。
frameworks/ml/nn/common/include/ValidateHal.h 檔案包含公用程式函式,可根據 NN HAL 物件的 HAL 版本規格,驗證該物件是否有效。
validate*:如果 NN HAL 物件根據其 HAL 版本規格有效,則傳回true。系統不會驗證 OEM 類型和擴充功能類型。舉例來說,如果模型包含參照不存在的運算元索引的運算,或該 HAL 版本不支援的運算,validateModel就會傳回false。
frameworks/ml/nn/common/include/Tracing.h 檔案包含巨集,可簡化將 systrace 資訊新增至神經網路程式碼的作業。如需範例,請參閱範例驅動程式中的 NNTRACE_* 巨集調用。
frameworks/ml/nn/common/include/GraphDump.h 檔案包含公用程式函式,可將 Model 的內容以圖形形式傾印,以利偵錯。
graphDump:以 Graphviz (.dot) 格式將模型表示法寫入指定串流 (如有提供),或寫入 logcat (如未提供串流)。
驗證
如要測試 NNAPI 的實作方式,請使用 Android 架構隨附的 VTS 和 CTS 測試。VTS 會直接執行驅動程式 (不使用架構),而 CTS 則會透過架構間接執行驅動程式。這些測試會測試每種 API 方法,並驗證驅動程式支援的所有作業是否正常運作,以及提供的結果是否符合精確度規定。
NNAPI 的 CTS 和 VTS 精確度規定如下:
浮點: abs(expected - actual) <= atol + rtol * abs(expected); where:
- 如果是 fp32,atol = 1e-5f, rtol = 5.0f * 1.1920928955078125e-7
- For fp16, atol = rtol = 5.0f * 0.0009765625f
量化:差一 (
mobilenet_quantized除外,差三)布林值:完全比對
CTS 測試 NNAPI 的其中一種方式,是產生固定的虛擬隨機圖形,用於測試及比較各個驅動程式的執行結果與 NNAPI 參考實作。如果驅動程式使用 NN HAL 1.2 以上版本,但結果未達到精確度標準,CTS 會回報錯誤,並在 /data/local/tmp 下傾印失敗模型的規格檔案,以供偵錯。如要進一步瞭解精確度條件,請參閱TestRandomGraph.cpp和TestHarness.h。
模糊測試
模糊測試的目的是找出測試中的程式碼,是否會因非預期的輸入內容等因素而導致當機、斷言、記憶體違規或一般未定義的行為。Android 會使用以 libFuzzer 為基礎的測試,進行 NNAPI 模糊測試。這類測試可有效執行模糊測試,因為會使用先前測試案例的行涵蓋範圍,產生新的隨機輸入內容。舉例來說,libFuzzer 偏好在新程式碼行執行的測試案例。這可大幅縮短測試時間,找出有問題的程式碼。
如要執行模糊測試來驗證驅動程式實作情況,請修改 AOSP 中 libneuralnetworks_driver_fuzzer 測試公用程式的 frameworks/ml/nn/runtime/test/android_fuzzing/DriverFuzzTest.cpp,加入驅動程式程式碼。如要進一步瞭解 NNAPI 模糊測試,請參閱 frameworks/ml/nn/runtime/test/android_fuzzing/README.md。
安全性
由於應用程式程序會直接與驅動程式程序通訊,因此驅動程式必須驗證收到的呼叫引數。這項驗證由 VTS 負責。驗證碼位於「frameworks/ml/nn/common/include/ValidateHal.h」中。
此外,駕駛人也應確保應用程式不會干擾同一裝置上的其他應用程式。
Android 機器學習測試套件
Android 機器學習測試套件 (MLTS) 是 CTS 和 VTS 內含的 NNAPI 基準,可驗證供應商裝置上實際模型的準確度。該基準會評估延遲時間和準確率,並針對相同的模型和資料集,將驅動程式的結果與透過 CPU 上執行的 TF Lite 取得的結果相比較。這可確保驅動程式的準確度不會低於 CPU 參考實作。
Android 平台開發人員也會使用 MLTS 評估驅動程式的延遲時間和準確度。
您可以在 AOSP 的兩個專案中找到 NNAPI 基準:
platform/test/mlts/benchmark(基準應用程式)platform/test/mlts/models(模型和資料集)
模型和資料集
NNAPI 基準會使用下列模型和資料集。
- MobileNetV1 浮點和 u8 量化,大小不同,針對 Open Images 資料集 v4 的小型子集 (1500 張圖片) 執行。
- MobileNetV2 浮點和 u8 量化,大小不同,針對 Open Images 資料集 v4 的小型子集 (1500 張圖片) 執行。
- 以長短期記憶 (LSTM) 為基礎的語音合成聲學模型,針對 CMU Arctic 集的一小部分執行。
- 以 LSTM 為基礎的自動語音辨識聲學模型,針對 LibriSpeech 資料集的一小部分執行。
詳情請參閱 platform/test/mlts/models。
壓力測試
Android 機器學習測試套件包含一系列當機測試,可驗證驅動程式在大量使用或用戶行為的極端情況下是否能正常運作。
所有當機測試都提供下列功能:
- 偵測停止回應:如果 NNAPI 用戶端在測試期間停止回應,測試會失敗,失敗原因為
HANG,測試套件會移至下一個測試。 - NNAPI 用戶端當機偵測:測試會在用戶端當機後繼續執行,並因
CRASH失敗原因而失敗。 - 驅動程式當機偵測:測試可以偵測導致 NNAPI 呼叫失敗的驅動程式當機。請注意,驅動程式程序中可能發生當機,但不會導致 NNAPI 失敗,也不會導致測試失敗。為避免這類失敗,建議您在系統記錄中執行
tail指令,找出與驅動程式相關的錯誤或當機問題。 - 指定所有可用的加速器:測試會針對所有可用的驅動程式執行。
所有撞擊測試都有以下四種可能結果:
SUCCESS:執行完成,未發生錯誤。FAILURE:執行失敗。通常是測試模型時發生失敗所致,表示驅動程式無法編譯或執行模型。HANG:測試程序沒有回應。CRASH:測試程序當機。
如要進一步瞭解壓力測試和完整的當機測試清單,請參閱platform/test/mlts/benchmark/README.txt。
使用 MLTS
如要使用 MLTS:
- 將目標裝置連線至工作站,並確認可透過 adb 存取該裝置。如果連接了多個裝置,請匯出目標裝置
ANDROID_SERIAL環境變數。 cd複製到 Android 頂層來源目錄。source build/envsetup.sh lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available. ./test/mlts/benchmark/build_and_run_benchmark.sh基準執行結束後,結果會以 HTML 網頁的形式呈現,並傳遞至
xdg-open。
詳情請參閱 platform/test/mlts/benchmark/README.txt。
類神經網路 HAL 版本
本節說明 Android 和神經網路 HAL 版本中導入的變更。
Android 11
Android 11 導入 NN HAL 1.3,包含下列重大變更。
- NNAPI 支援帶正負號的 8 位元量化。新增
TENSOR_QUANT8_ASYMM_SIGNED運算元型別。如果驅動程式採用 NN HAL 1.3,且支援使用未簽署量化的作業,則也必須支援這些作業的已簽署變體。執行大多數量化作業的已簽署和未簽署版本時,驅動程式產生的結果必須相同,最多可有 128 的偏移量。這項規定有五個例外狀況:CAST、HASHTABLE_LOOKUP、LSH_PROJECTION、PAD_V2和QUANTIZED_16BIT_LSTM。QUANTIZED_16BIT_LSTM運算不支援帶正負號的運算元,其他四項運算則支援帶正負號的量化,但不要求結果相同。 - 支援柵欄執行作業,架構會呼叫
IPreparedModel::executeFenced方法,在準備好的模型上啟動柵欄式非同步執行作業,並等待同步柵欄向量。詳情請參閱「設限執行」。 - 支援控制流程。新增
IF和WHILE運算,這些運算會將其他模型做為引數,並有條件地 (IF) 或重複 (WHILE) 執行這些模型。詳情請參閱控制流程。 - 服務品質 (QoS) 提升:應用程式可以指出模型的相對優先順序、準備模型預計最長時間,以及完成執行的預計最長時間。詳情請參閱「服務品質」。
- 支援記憶體網域,為驅動程式管理的緩衝區提供分配器介面。這項功能可讓您在執行過程中傳送裝置原生記憶體,並在同一驅動程式中進行連續執行作業時,避免不必要的資料複製和轉換情形。詳情請參閱「記憶體網域」。
Android 10
Android 10 推出 NN HAL 1.2,包含下列重大變更。
Capabilities結構包含所有資料類型 (包括純量資料類型),並使用向量而非具名欄位來表示非寬鬆效能。- 架構可透過
getVersionString和getType方法,擷取裝置類型 (DeviceType) 和版本資訊。請參閱「探索和指派裝置」。 - 根據預設,系統會呼叫
executeSynchronously方法,以同步執行作業。execute_1_2方法會指示架構以非同步方式執行作業。請參閱「執行」。 MeasureTiming、execute_1_2和爆發執行作業的executeSynchronouslyMeasureTiming參數會指定驅動程式是否要測量執行時間。結果會以Timing結構回報。請參閱「時間」。- 支援一或多個輸出運算元具有不明維度或等級的執行作業。請參閱「輸出形狀」。
- 支援供應商擴充功能,也就是供應商定義的作業和資料類型集合。驅動程式會透過
IDevice::getSupportedExtensions方法回報支援的擴充功能。請參閱「供應商額外資訊」。 - 爆發物件可使用快速訊息佇列 (FMQ) 控制一組爆發執行作業,在應用程式和驅動程式程序之間通訊,縮短延遲時間。請參閱「爆發執行作業和快速訊息佇列」。
- 支援 AHardwareBuffer,讓驅動程式執行作業時不必複製資料。請參閱「AHardwareBuffer」。
- 改善編譯構件的快取支援功能,減少應用程式啟動時的編譯時間。請參閱「編譯快取」。
Android 10 導入下列運算元型別和作業。
-
ANEURALNETWORKS_BOOLANEURALNETWORKS_FLOAT16ANEURALNETWORKS_TENSOR_BOOL8ANEURALNETWORKS_TENSOR_FLOAT16ANEURALNETWORKS_TENSOR_QUANT16_ASYMMANEURALNETWORKS_TENSOR_QUANT16_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL
-
ANEURALNETWORKS_ABSANEURALNETWORKS_ARGMAXANEURALNETWORKS_ARGMINANEURALNETWORKS_AXIS_ALIGNED_BBOX_TRANSFORMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_RNNANEURALNETWORKS_BOX_WITH_NMS_LIMITANEURALNETWORKS_CASTANEURALNETWORKS_CHANNEL_SHUFFLEANEURALNETWORKS_DETECTION_POSTPROCESSINGANEURALNETWORKS_EQUALANEURALNETWORKS_EXPANEURALNETWORKS_EXPAND_DIMSANEURALNETWORKS_GATHERANEURALNETWORKS_GENERATE_PROPOSALSANEURALNETWORKS_GREATERANEURALNETWORKS_GREATER_EQUALANEURALNETWORKS_GROUPED_CONV_2DANEURALNETWORKS_HEATMAP_MAX_KEYPOINTANEURALNETWORKS_INSTANCE_NORMALIZATIONANEURALNETWORKS_LESSANEURALNETWORKS_LESS_EQUALANEURALNETWORKS_LOGANEURALNETWORKS_LOGICAL_ANDANEURALNETWORKS_LOGICAL_NOTANEURALNETWORKS_LOGICAL_ORANEURALNETWORKS_LOG_SOFTMAXANEURALNETWORKS_MAXIMUMANEURALNETWORKS_MINIMUMANEURALNETWORKS_NEGANEURALNETWORKS_NOT_EQUALANEURALNETWORKS_PAD_V2ANEURALNETWORKS_POWANEURALNETWORKS_PRELUANEURALNETWORKS_QUANTIZEANEURALNETWORKS_QUANTIZED_16BIT_LSTMANEURALNETWORKS_RANDOM_MULTINOMIALANEURALNETWORKS_REDUCE_ALLANEURALNETWORKS_REDUCE_ANYANEURALNETWORKS_REDUCE_MAXANEURALNETWORKS_REDUCE_MINANEURALNETWORKS_REDUCE_PRODANEURALNETWORKS_REDUCE_SUMANEURALNETWORKS_RESIZE_NEAREST_NEIGHBORANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_ROI_POOLINGANEURALNETWORKS_RSQRTANEURALNETWORKS_SELECTANEURALNETWORKS_SINANEURALNETWORKS_SLICEANEURALNETWORKS_SPLITANEURALNETWORKS_SQRTANEURALNETWORKS_TILEANEURALNETWORKS_TOPK_V2ANEURALNETWORKS_TRANSPOSE_CONV_2DANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_RNN
Android 10 更新了許多現有的作業。主要更新內容如下:
- 支援 NCHW 記憶體配置
- 支援 softmax 和正規化作業中,階數不為 4 的張量
- 支援擴張卷積
- 支援在
ANEURALNETWORKS_CONCATENATION中使用混合量化輸入
下表列出 Android 10 中修改的作業。如要查看異動的完整詳細資料,請參閱 NNAPI 參考文件中的「OperationCode」。
ANEURALNETWORKS_ADDANEURALNETWORKS_AVERAGE_POOL_2DANEURALNETWORKS_BATCH_TO_SPACE_NDANEURALNETWORKS_CONCATENATIONANEURALNETWORKS_CONV_2DANEURALNETWORKS_DEPTHWISE_CONV_2DANEURALNETWORKS_DEPTH_TO_SPACEANEURALNETWORKS_DEQUANTIZEANEURALNETWORKS_DIVANEURALNETWORKS_FLOORANEURALNETWORKS_FULLY_CONNECTEDANEURALNETWORKS_L2_NORMALIZATIONANEURALNETWORKS_L2_POOL_2DANEURALNETWORKS_LOCAL_RESPONSE_NORMALIZATIONANEURALNETWORKS_LOGISTICANEURALNETWORKS_LSH_PROJECTIONANEURALNETWORKS_LSTMANEURALNETWORKS_MAX_POOL_2DANEURALNETWORKS_MEANANEURALNETWORKS_MULANEURALNETWORKS_PADANEURALNETWORKS_RELUANEURALNETWORKS_RELU1ANEURALNETWORKS_RELU6ANEURALNETWORKS_RESHAPEANEURALNETWORKS_RESIZE_BILINEARANEURALNETWORKS_RNNANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_SOFTMAXANEURALNETWORKS_SPACE_TO_BATCH_NDANEURALNETWORKS_SPACE_TO_DEPTHANEURALNETWORKS_SQUEEZEANEURALNETWORKS_STRIDED_SLICEANEURALNETWORKS_SUBANEURALNETWORKS_SVDFANEURALNETWORKS_TANHANEURALNETWORKS_TRANSPOSE
Android 9
Android 9 導入了 NN HAL 1.1,並包含下列重大變更。
IDevice::prepareModel_1_1包含ExecutionPreference參數。駕駛人可根據這項資訊調整準備工作,瞭解應用程式偏好節省電量,或將在快速連續的呼叫中執行模型。- 新增九項作業:
BATCH_TO_SPACE_ND、DIV、MEAN、PAD、SPACE_TO_BATCH_ND、SQUEEZE、STRIDED_SLICE、SUB、TRANSPOSE。 - 應用程式可以將
Model.relaxComputationFloat32toFloat16設為true,指定使用 16 位元浮點範圍和/或精確度執行 32 位元浮點運算。這個Capabilitiesstruct 具有額外欄位relaxedFloat32toFloat16Performance,因此驅動程式可以向架構回報放寬的效能。
Android 8.1
初始的 Neural Networks HAL (1.0) 是在 Android 8.1 中發布。詳情請參閱 /neuralnetworks/1.0/。