
Untuk mendukung dasbor integrasi berkelanjutan yang skalabel, berperforma tinggi, dan fleksibel, backend Dasbor VTS harus dirancang dengan cermat dengan pemahaman yang kuat tentang fungsi database. Google Cloud Datastore adalah database NoSQL yang menawarkan jaminan ACID transaksional dan konsistensi pada akhirnya serta konsistensi yang kuat dalam grup entity. Namun, strukturnya sangat berbeda dengan database SQL (dan bahkan Cloud Bigtable); bukan tabel, baris, dan sel, ada jenis, entitas, dan properti.
Bagian berikut menguraikan struktur data dan pola kueri untuk membuat backend yang efektif bagi layanan web Dasbor VTS.
Entitas
Entitas berikut menyimpan ringkasan dan resource dari pengujian VTS yang dijalankan:
- Entitas Pengujian. Menyimpan metadata tentang pengujian yang dijalankan dari pengujian tertentu. Kuncinya adalah nama pengujian dan propertinya mencakup jumlah kegagalan, jumlah lulus, dan daftar kerusakan kasus pengujian sejak tugas pemberitahuan memperbaruinya.
- Test Run Entity. Berisi metadata dari pengujian tertentu. File ini harus menyimpan stempel waktu awal dan akhir pengujian, ID build pengujian, jumlah kasus pengujian yang lulus dan gagal, jenis operasi (misalnya, pra-pengiriman, pasca-pengiriman, atau lokal), daftar link log, nama mesin host, dan jumlah ringkasan cakupan.
- Entity Informasi Perangkat. Berisi detail tentang perangkat yang digunakan selama pengujian berjalan. Informasi ini mencakup ID build perangkat, nama produk, target build, cabang, dan informasi ABI. Data ini disimpan secara terpisah dari entitas pengujian yang dijalankan untuk mendukung pengujian multi-perangkat yang dijalankan dengan cara satu-ke-banyak.
- Profiling Point Run Entity. Merangkum data yang dikumpulkan untuk titik pembuatan profil tertentu dalam pengujian yang dijalankan. Ini menjelaskan label sumbu, nama titik pembuatan profil, nilai, jenis, dan mode regresi data pembuatan profil.
- Entitas Cakupan. Menjelaskan data cakupan yang dikumpulkan untuk satu file. File ini berisi informasi project Git, jalur file, dan daftar jumlah cakupan per baris dalam file sumber.
- Test Case Run Entity. Menjelaskan hasil kasus pengujian tertentu dari pengujian yang dijalankan, termasuk nama kasus pengujian dan hasilnya.
- Entity Favorit Pengguna. Setiap langganan pengguna dapat diwakili dalam entitas yang berisi referensi ke pengujian dan ID pengguna yang dihasilkan dari layanan pengguna App Engine. Hal ini memungkinkan kueri dua arah yang efisien (yaitu untuk semua pengguna yang berlangganan pengujian dan untuk semua pengujian yang difavoritkan oleh pengguna).
Pengelompokan entitas
Setiap modul pengujian mewakili root grup entity. Entitas pengujian adalah turunan dari grup ini dan induk untuk entitas perangkat, entitas titik profiling, dan entitas cakupan yang relevan dengan ancestor pengujian dan pengujian masing-masing.
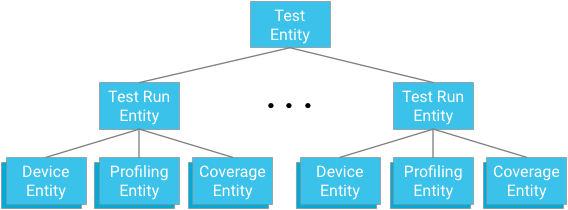
Poin Penting: Saat mendesain hubungan keturunan, Anda harus menyeimbangkan kebutuhan untuk menyediakan mekanisme kueri yang efektif dan konsisten dengan batasan yang diterapkan oleh database.
Manfaat
Persyaratan konsistensi memastikan bahwa operasi mendatang tidak akan melihat efek transaksi hingga transaksi di-commit, dan bahwa transaksi di masa lalu terlihat oleh operasi saat ini. Di Cloud Datastore, pengelompokan entity membuat pulau konsistensi baca dan tulis yang kuat dalam grup, yang dalam hal ini adalah semua pengujian yang berjalan dan data yang terkait dengan modul pengujian. Hal ini menawarkan manfaat berikut:
- Pembacaan dan pembaruan untuk menguji status modul oleh tugas pemberitahuan dapat diperlakukan sebagai atomik
- Jaminan tampilan konsisten hasil kasus pengujian dalam modul pengujian
- Kueri yang lebih cepat dalam hierarki leluhur
Batasan
Menulis ke entity group dengan kecepatan lebih cepat dari satu entity per detik tidak dianjurkan karena beberapa operasi tulis mungkin ditolak. Selama tugas pemberitahuan dan upload tidak terjadi dengan kecepatan lebih cepat dari satu operasi tulis per detik, strukturnya akan solid dan menjamin konsistensi yang kuat.
Pada akhirnya, batas satu operasi tulis per modul pengujian per detik adalah wajar karena pengujian berjalan biasanya memerlukan waktu minimal satu menit termasuk overhead framework VTS; kecuali jika pengujian secara konsisten dijalankan secara bersamaan di lebih dari 60 host yang berbeda, tidak boleh ada bottleneck operasi tulis. Hal ini menjadi lebih tidak mungkin mengingat setiap modul adalah bagian dari rencana pengujian yang sering kali memerlukan waktu lebih dari satu jam. Anomali dapat ditangani dengan mudah jika host menjalankan pengujian secara bersamaan, sehingga menyebabkan lonjakan penulisan singkat ke host yang sama (misalnya, dengan mendeteksi error penulisan dan mencoba lagi).
Pertimbangan penskalaan
Pengujian yang dijalankan tidak harus memiliki pengujian sebagai induknya (misalnya, pengujian dapat menggunakan beberapa kunci lain dan memiliki nama pengujian, waktu mulai pengujian sebagai properti); tetapi, hal ini akan menukar konsistensi yang kuat dengan konsistensi akhir. Misalnya, tugas pemberitahuan mungkin tidak melihat snapshot yang konsisten dari pengujian terbaru yang berjalan dalam modul pengujian, yang berarti status global mungkin tidak menampilkan representasi urutan pengujian yang sepenuhnya akurat. Hal ini juga dapat memengaruhi tampilan pengujian yang berjalan dalam satu modul pengujian, yang mungkin tidak selalu merupakan snapshot yang konsisten dari urutan operasi. Pada akhirnya, snapshot akan konsisten, tetapi tidak ada jaminan bahwa data terbaru akan konsisten.
Kasus pengujian
Bottleneck potensial lainnya adalah pengujian besar dengan banyak kasus pengujian. Dua batasan operasional adalah throughput operasi tulis maksimum dalam satu entity group sebesar satu per detik, beserta ukuran transaksi maksimum 500 entity.
Salah satu pendekatannya adalah menentukan kasus pengujian yang memiliki pengujian yang dijalankan sebagai ancestor (mirip dengan cara penyimpanan data cakupan, data pembuatan profil, dan informasi perangkat):
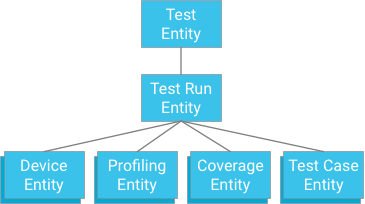
Meskipun pendekatan ini menawarkan atomitas dan konsistensi, pendekatan ini memberlakukan batasan yang kuat pada pengujian: Jika transaksi dibatasi hingga 500 entitas, pengujian tidak boleh memiliki lebih dari 498 kasus pengujian (dengan asumsi tidak ada data cakupan atau pembuatan profil). Jika pengujian melebihi batas ini, satu transaksi tidak dapat menulis semua hasil kasus pengujian sekaligus, dan membagi kasus pengujian menjadi transaksi terpisah dapat melebihi throughput operasi tulis entity group maksimum sebesar satu iterasi per detik. Karena solusi ini tidak akan diskalakan dengan baik tanpa mengorbankan performa, solusi ini tidak direkomendasikan.
Namun, alih-alih menyimpan hasil kasus pengujian sebagai turunan dari pengujian yang dijalankan, kasus pengujian dapat disimpan secara independen dan kuncinya diberikan ke pengujian yang dijalankan (pengujian yang dijalankan berisi daftar ID ke entitas kasus pengujiannya):
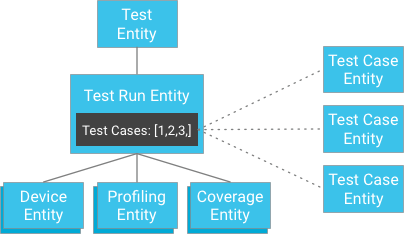
Sepintas, hal ini mungkin tampak melanggar jaminan konsistensi yang kuat. Namun, jika klien memiliki entitas pengujian yang dijalankan dan daftar ID kasus pengujian, klien tidak perlu membuat kueri; klien dapat langsung mendapatkan kasus pengujian berdasarkan ID-nya, yang selalu dijamin konsisten. Pendekatan ini sangat mengurangi batasan jumlah kasus pengujian yang mungkin dijalankan pengujian sekaligus mendapatkan konsistensi yang kuat tanpa mengancam operasi tulis yang berlebihan dalam entity group.
Pola akses data
Dasbor VTS menggunakan pola akses data berikut:
- Favorit pengguna. Dapat dikueri menggunakan filter kesetaraan pada entity favorit pengguna yang memiliki objek Pengguna App Engine tertentu sebagai properti.
- Listingan pengujian. Kueri sederhana untuk entity pengujian. Untuk mengurangi bandwidth guna merender halaman beranda, proyeksi dapat digunakan pada jumlah yang lulus dan gagal sehingga menghapus listingan ID kasus pengujian yang gagal dan metadata lainnya yang digunakan oleh tugas pemberitahuan yang berpotensi panjang.
- Pengujian berjalan. Membuat kueri untuk entity pengujian memerlukan pengurutan pada kunci (stempel waktu) dan kemungkinan pemfilteran pada properti pengujian seperti ID build, jumlah yang lulus, dll. Dengan melakukan kueri ancestor dengan kunci entity pengujian, pembacaan akan sangat konsisten. Pada tahap ini, semua hasil kasus pengujian dapat diambil menggunakan daftar ID yang disimpan di properti pengujian; hal ini juga dijamin akan menjadi hasil yang sangat konsisten karena sifat operasi pengambilan datastore.
- Data pembuatan profil dan cakupan. Membuat kueri untuk data pembuatan profil atau cakupan yang terkait dengan pengujian dapat dilakukan tanpa mengambil data pengujian lainnya (seperti data pembuatan profil/cakupan lainnya, data kasus pengujian, dll.). Kueri ancestor yang menggunakan kunci entitas pengujian pengujian dan pengujian berjalan akan mengambil semua titik pembuatan profil yang dicatat selama pengujian berjalan; dengan juga memfilter nama titik pembuatan profil atau nama file, satu entitas pembuatan profil atau cakupan dapat diambil. Berdasarkan sifat kueri ancestor, operasi ini sangat konsisten.
Untuk mengetahui detail tentang UI dan screenshot pola data ini yang sedang digunakan, lihat UI Dasbor VTS.