
このページでは、Neural Networks API(NNAPI)ドライバの実装方法を概説します。詳細については、hardware/interfaces/neuralnetworks にある HAL 定義ファイルのドキュメントを参照してください。サンプル ドライバの実装は、frameworks/ml/nn/driver/sample にあります。
Neural Networks API の詳細については、Neural Networks API をご覧ください。
ニューラル ネットワーク HAL
ニューラル ネットワーク(NN)HAL は、製品(スマートフォンやタブレットなど)のグラフィックス プロセッシング ユニット(GPU)やデジタル シグナル プロセッサ(DSP)など、さまざまなデバイスの抽象化を定義します。これらのデバイスのドライバは、NN HAL に準拠している必要があります。インターフェースは hardware/interfaces/neuralnetworks の HAL 定義ファイルで指定されます。
フレームワークとドライバ間のインターフェースの一般的なフローを図 1 に示します。
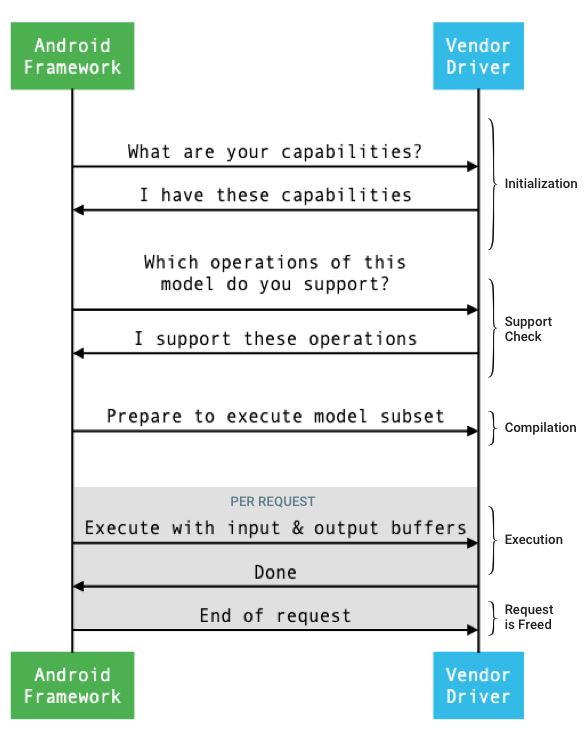
図 1. ニューラル ネットワークのフロー
初期化
初期化時に、フレームワークは IDevice::getCapabilities_1_3 を使用してドライバに機能を照会します。@1.3::Capabilities 構造体は、すべてのデータ型を含み、ベクターを使用して非緩和型のパフォーマンスを表します。
使用可能なデバイスに計算を割り当てる方法を決定するにあたり、フレームワークはこの機能を使用して各ドライバの実行速度とエネルギー効率を把握します。この情報を提供するには、ドライバは、参照ワークロードの実行に基づいて標準化されたパフォーマンスの数値を提供する必要があります。
ドライバが IDevice::getCapabilities_1_3 に応答して返す値を決定するには、NNAPI ベンチマーク アプリを使用して、対応するデータ型のパフォーマンスを測定します。MobileNet v1 および v2、asr_float、tts_float のモデルは 32 ビット浮動小数点数値のパフォーマンスの測定に、MobileNet v1 および v2 の量子化モデルは 8 ビットの量子化された値のパフォーマンスの測定に推奨されます。詳細については、Android 機械学習テストスイートをご覧ください。
Android 9 以前では、Capabilities 構造体には浮動小数点数および量子化テンソルのみのドライバ パフォーマンス情報が含まれ、スカラーデータ型は含まれません。
初期化プロセスの一環として、フレームワークは、IDevice::getType、IDevice::getVersionString、IDevice:getSupportedExtensions、IDevice::getNumberOfCacheFilesNeeded を使用して、詳細な情報を照会できます。
このフレームワークでは、製品を再起動しても、このセクションで説明しているすべてのクエリが、特定のドライバに対して常に同じ値を返すことを想定しています。値が異なると、そのドライバを使用しているアプリのパフォーマンスが低下したり、動作が正しく行われない可能性があります。
コンパイル
フレームワークは、アプリからリクエストを受信するときに使用するデバイスを決定します。Android 10 では、フレームワークが選択するデバイスをアプリが検出して指定できます。詳細については、デバイスの検出と割り当てをご覧ください。
モデルのコンパイル時に、フレームワークは IDevice::getSupportedOperations_1_3 を呼び出して各候補ドライバにモデルを送信します。各ドライバは、モデルのどの演算がサポートされているかを示すブール値の配列を返します。ドライバは、さまざまな理由で特定の演算をサポートできないと判断できます。次に例を示します。
- そのデータタイプをドライバがサポートしていない。
- ドライバが、特定の入力パラメータを持つ演算のみをサポートしている。たとえば、ドライバは 3x3 と 5x5 をサポートしていますが、7x7 の畳み込み演算はサポートしていない場合があります。
- ドライバにメモリの制約があるため、大規模なグラフや入力を処理できない。
OperandLifeTime で記述されているように、コンパイル中、モデルの入力オペランド、出力オペランド、内部オペランドには、不明なディメンションやランクを指定できます。詳細については、出力シェイプをご覧ください。
フレームワークは、選択された各ドライバに対し、IDevice::prepareModel_1_3 を呼び出してモデルのサブセットの実行を準備するように指示します。その後、各ドライバはそのサブセットをコンパイルします。たとえば、ドライバはコードを生成する、または順序変更されたウエイトのコピーを作成する場合があります。モデルのコンパイルからリクエストの実行までにはかなりの時間を要する可能性があるため、コンパイル中にデバイスメモリの大きなチャンクなどのリソースを割り当てることはできません。
成功した場合、ドライバは @1.3::IPreparedModel ハンドルを返します。ドライバがモデルのサブセットを準備するときにエラーコードを返すと、フレームワークは CPU でモデル全体を実行します。
アプリの起動時にコンパイルに要する時間を短縮するために、ドライバはコンパイルのアーティファクトをキャッシュに保存できます。詳細については、コンパイルのキャッシュ保存を参照してください。
実行
アプリがフレームワークにリクエストの実行を要求すると、フレームワークは IPreparedModel::executeSynchronously_1_3 HAL メソッドをデフォルトで呼び出して、準備されたモデルで同期実行します。リクエストは、execute_1_3 メソッド、executeFenced メソッド(フェンスを使用した実行を参照)、またはバースト実行を使用して非同期に実行することもできます。
同期実行呼び出しでは、実行が完了した後にのみ制御がアプリプロセスに返されるため、非同期呼び出しと比べてパフォーマンスが向上し、スレッドのオーバーヘッドが削減されます。つまり、ドライバは実行が完了したことをアプリプロセスに通知するメカニズムを別途必要としません。
非同期 execute_1_3 メソッドでの制御は、実行が開始した後にアプリプロセスに戻ります。ドライバは、@1.3::IExecutionCallback を使用して、実行が完了したときにフレームワークに通知する必要があります。
実行メソッドに渡される Request パラメータは、実行に使用される入力オペランドと出力オペランドをリスト表示します。オペランド データを格納するメモリは、最初のディメンションの反復処理が最も遅い行優先の順序を使用し、行の終わりにパディングがないようにする必要があります。オペランドの型の詳細については、オペランドを参照してください。
NN HAL 1.2 以降のドライバの場合、リクエストが完了すると、エラーのステータス、出力シェイプ、タイミング情報がフレームワークに返されます。実行中、モデルの出力または内部オペランドには、1 つ以上の不明なディメンションまたはランクを指定できます。少なくとも 1 つの出力オペランドに不明なディメンションまたはランクがある場合、ドライバは動的にサイズ変更される出力情報を返す必要があります。
NN HAL 1.1 以前のドライバの場合、リクエストが完了するとエラーのステータスのみが返されます。入力オペランドと出力オペランドのディメンションは、実行が正常に完了するように完全に指定する必要があります。内部オペランドには 1 つ以上の不明なディメンションを指定できますが、特定のランクが必要です。
複数のドライバにまたがるユーザー リクエストの場合、フレームワークは中間メモリの予約と、各ドライバへの呼び出しの順序付けを行います。
同じ @1.3::IPreparedModel に対して複数のリクエストを並列に開始できます。ドライバはリクエストを並列に実行したり、実行をシリアル化したりできます。
フレームワークは、複数の準備済みのモデルを保持するようドライバに要求できます。たとえば、モデル m1 を準備する、m2 を準備する、m1 でリクエスト r1 を実行する、m2 で r2 を実行する、m1 で r3 を実行する、m2 で r4 を実行する、(クリーンアップで説明されているように)m1 をリリースする、m2 をリリースする、といった要求が可能です。
最初の実行が遅くなり、ユーザー エクスペリエンスが低下すること(最初のフレームの途切れなど)を避けるため、ドライバはコンパイル フェーズでほとんどの初期化を実行する必要があります。最初の実行時の初期化は、大規模な一時バッファの確保やデバイスのクロックレートの増加など、早期実行時にシステムの健全性に悪影響を及ぼす操作に限定する必要があります。限られた数の同時実行モデルのみを準備できるドライバは、最初の実行時に初期化する必要があります。
Android 10 以降では、同じ準備済みのモデルで複数の実行が連続して行われる場合、クライアントは実行バースト オブジェクトを使用してアプリとドライバのプロセス間で通信を行えます。詳細については、バースト実行と高速メッセージ キューをご覧ください。
複数の実行のパフォーマンスを継続的に改善するために、ドライバは一時バッファを保持するか、クロックレートを引き上げることができます。一定期間が経過しても新しいリクエストが作成されない場合は、リソースを解放するためにウォッチドッグのスレッドを作成することをおすすめします。
出力シェイプ
1 つ以上の出力オペランドですべてのディメンションが指定されていないリクエストの場合、ドライバは、実行後の各出力オペランドのディメンション情報を含む出力シェイプのリストを指定する必要があります。ディメンションの詳細については、OutputShape をご覧ください。
出力バッファのサイズが小さくて実行できない場合、ドライバは、出力シェイプのリストでバッファサイズが不足している出力オペランドを指定し、できる限り多くのディメンション情報を報告する必要があります(不明なディメンションには 0 を使用)。
タイミング
Android 10 では、コンパイルの処理中に使用するデバイスを 1 つ指定している場合、アプリは実行時間を要求できます。詳しくは、MeasureTiming とデバイスの検出と割り当てを参照してください。この場合、NN HAL 1.2 ドライバは実行時間を測定するか、(継続時間が得られないことを示すために)リクエストの実行時に UINT64_MAX を報告する必要があります。ドライバは、実行時間を測定することによるパフォーマンスの低下を最小限に抑える必要があります。
ドライバは、次の継続時間を Timing 構造でマイクロ秒単位で報告します。
- デバイスでの実行時間: ホスト プロセッサ上で実行されるドライバでの実行時間は含まれません。
- ドライバでの実行時間: デバイスでの実行時間が含まれます。
これらの継続時間には、実行が他のタスクによってプリエンプトされた場合や、リソースが使用可能になるのを待機している場合など、実行が一時停止された状態にある時間も含まれる必要があります。
ドライバが実行時間の測定を求められていない場合や、実行エラーが発生した場合、ドライバは継続時間を UINT64_MAX として報告する必要があります。ドライバが実行時間を測定するように求められた場合でも、代わりに UINT64_MAX をデバイスでの時間、ドライバでの時間、またはその両方として報告できます。ドライバが両方の時間を UINT64_MAX 以外の値として報告する場合、ドライバでの実行時間はデバイスでの時間以上にする必要があります。
フェンスを使用した実行
Android 11 の NNAPI では、sync_fence ハンドルのリストを取得するまで実行を待機するように設定できます。任意で、実行完了時に sync_fence オブジェクトを返すように設定することもできます。これにより、小さいシーケンス モデルとストリーミングのユースケースでオーバーヘッドが減少します。また、実行にフェンスを使用することで、sync_fence のシグナルを送信または取得するまで待機し、他のコンポーネントとの相互運用性の効率性を改善できます。sync_fence の詳細については、同期フレームワークをご覧ください。
フェンスを使用した実行では、フレームワークは IPreparedModel::executeFenced メソッドを呼び出して、待機する同期フェンスを備えた準備済みのモデルに対するフェンスを使用する非同期実行を開始します。呼び出しに対する応答が返される前に非同期タスクが終了した場合は、sync_fence に対して空のハンドルを返すことができます。フレームワークがエラー ステータスと期間情報をクエリできるように、IFencedExecutionCallback オブジェクトも返す必要があります。
実行が完了すると、IFencedExecutionCallback::getExecutionInfo を使用して、実行時間の長さを測定する次の 2 つの timing 値をクエリできます。
timingLaunched:executeFencedが呼び出された時点から、executeFencedが返されたsyncFenceのシグナルを送信するまでの時間。timingFenced: 実行が待機するすべての同期フェンスのシグナルが送信された時点から、executeFencedが返されたsyncFenceのシグナルを送信するまでの時間。
制御フロー
Android 11 以降を搭載するデバイスの場合、NNAPI には 2 つの制御フロー オペレーション IF と WHILE があります。これらのフローは他のモデルを引数として取り、条件付きで(IF)実行するか、繰り返し(WHILE)実行します。これを実装する方法の詳細については、制御フローをご覧ください。
サービス品質
Android 11 の NNAPI では、モデルの相対的な優先度、モデルの準備に要することが想定される最大時間、実行の完了までに要することが想定される最大時間をアプリが示すことを可能にすることによって、サービス品質(QoS)を改善しています。詳細については、サービス品質をご覧ください。
クリーンアップ
アプリが準備済みモデルの使用を終了すると、フレームワークはそのリファレンスを @1.3::IPreparedModel オブジェクトにリリースします。IPreparedModel オブジェクトが参照されなくなると、作成元のドライバ サービスで自動的に破棄されます。このときのモデル固有のリソースは、ドライバのデストラクタの実装で回収できます。ドライバ サービスで、クライアントで不要になった IPreparedModel オブジェクトを自動的に破棄する場合は、IPreparedeModel オブジェクトが IPreparedModelCallback::notify_1_3 を介して返された後に IPreparedModel オブジェクトにリファレンスを保留できません。
CPU 使用状況
ドライバは、CPU を使用して計算を設定することが想定されています。作業を正しく割り当てるフレームワークの機能と干渉するため、ドライバは、グラフ計算の実行に CPU を使用すべきではありません。処理できない部分をフレームワークに報告し、残りをフレームワークに処理させる必要があります。
フレームワークは、ベンダー定義の演算以外のすべての NNAPI 演算の CPU を実装できます。詳細については、ベンダー拡張機能をご覧ください。
Android 10 で導入された演算(API レベル 29)は、CTS テストと VTS テストが正しいことを確認するための参照 CPU のみを実装しています。モバイル機械学習フレームワークに含まれる最適化された実装が、NNAPI CPU 実装よりも優先されます。
ユーティリティ関数
NNAPI コードベースには、ドライバ サービスで使用できるユーティリティ関数が含まれています。
frameworks/ml/nn/common/include/Utils.h ファイルには、複数の NN HAL バージョン間でのロギングと変換に使用されるものなど、さまざまなユーティリティ関数が含まれています。
VLogging:
VLOGは、debug.nn.vlogプロパティに適切なタグが設定されている場合のみメッセージを記録する、Android のLOG向けのラッパーマクロです。initVLogMask()はVLOGの呼び出しの前に呼び出す必要があります。VLOG_IS_ONマクロを使用して、VLOGが現在有効かどうかを確認し、複雑なロギングコードが必要ない場合はスキップできます。プロパティの値は、次のいずれかにする必要があります。- 空の文字列。ロギングが行われないことを示します。
- トークン
1またはall。すべてのロギングが行われることを示します。 - スペース、カンマ、またはコロンで区切られたタグのリスト。どのロギングが行われるかを示します。タグは
compilation、cpuexe、driver、execution、manager、modelです。
compliantWithV1_*: 情報を失うことなく NN HAL オブジェクトを同じタイプの別の HAL バージョンに変換できる場合に、trueを返します。たとえば、V1_2::ModelでcompliantWithV1_0を呼び出すと、NN HAL 1.1 または NN HAL 1.2 で導入された演算タイプがモデルに含まれる場合に、falseが返されます。convertToV1_*: NN HAL オブジェクトを、あるバージョンから別のバージョンに変換します。変換によって情報が失われる場合(つまり、新しいバージョンのタイプが値を完全に表すことができない場合)は、警告が記録されます。機能:
nonExtensionOperandPerformance関数とupdate関数を使用して、Capabilities::operandPerformanceフィールドをビルドできます。タイプのプロパティのクエリ:
isExtensionOperandType、isExtensionOperationType、nonExtensionSizeOfData、nonExtensionOperandSizeOfData、nonExtensionOperandTypeIsScalar、tensorHasUnspecifiedDimensions。
frameworks/ml/nn/common/include/ValidateHal.h ファイルには、HAL バージョンの仕様に従って NN HAL オブジェクトが有効であることを検証するユーティリティ関数が含まれています。
validate*: NN HAL オブジェクトが HAL バージョンの仕様に従って有効である場合に、trueを返します。OEM タイプと拡張機能タイプは検証されません。たとえば、存在しないオペランド インデックスを参照する演算や、その HAL のバージョンでサポートされていない演算がモデルに含まれる場合、validateModelはfalseを返します。
frameworks/ml/nn/common/include/Tracing.h ファイルには、シストレース情報をニューラル ネットワークのコードに簡単に追加するマクロが含まれています。例としては、サンプル ドライバの NNTRACE_* マクロの呼び出しをご覧ください。
frameworks/ml/nn/common/include/GraphDump.h ファイルには、デバッグを目的としてグラフィカル形式の Model のコンテンツをダンプするユーティリティ関数が含まれています。
graphDump: 指定したストリーム(指定されている場合)または logcat(ストリームが指定されていない場合)にモデルの表現を Graphviz(.dot)形式で書き込みます。
検証
NNAPI の実装をテストするには、Android フレームワークに含まれる VTS テストと CTS テストを使用します。VTS はフレームワークを使用せずにドライバを直接実行しますが、CTS はフレームワークを通じて間接的にドライバを実行します。これらは各 API メソッドをテストして、ドライバでサポートされるすべての演算が正しく機能し、精度要件を満たす結果を示していることを確認します。
NNAPI の CTS と VTS の精度要件は次のとおりです。
浮動小数点: abs(expected - actual) <= atol + rtol * abs(expected)。それぞれ以下のようになります。
- fp32 の場合、atol = 1e-5f、rtol = 5.0f * 1.1920928955078125e-7
- fp16 の場合、atol = rtol = 5.0f * 0.0009765625f
量子化: off-by-one(ただし、
mobilenet_quantizedの場合は off-by-two)ブール値: 完全一致
CTS が NNAPI をテストする方法の 1 つは、固定擬似ランダムグラフを生成して、これを利用して各ドライバの実行結果をテストし、NNAPI リファレンス実装と比較することです。NN HAL 1.2 以降のドライバで、結果が精度基準を満たさない場合、CTS はエラーを報告し、デバッグ用に /data/local/tmp の下で失敗したモデルの仕様ファイルをダンプします。精度基準の詳細については、TestRandomGraph.cpp と TestHarness.h をご覧ください。
ファズテスト
ファズテストの目的は、予期しない入力などの要因による、テスト対象のコード内におけるクラッシュ、アサーション、メモリ違反、一般的な未定義動作を見つけることです。NNAPI ファズテストの場合、Android は libFuzzer に基づくテストを使用します。これは、以前のテストケースのライン カバレッジを使用して新しいランダム入力を生成するため、ファジングに効率的です。たとえば、libFuzzer はコードの新しい行で実行されるテストケースを優先します。これにより、テストが問題のあるコードを見つけるのに要する時間を大幅に短縮できます。
ドライバ実装を検証するためにファズテストを実行するには、AOSP にある libneuralnetworks_driver_fuzzer テスト ユーティリティで frameworks/ml/nn/runtime/test/android_fuzzing/DriverFuzzTest.cpp を変更して、ドライバコードを追加します。NNAPI ファズテストの詳細については、frameworks/ml/nn/runtime/test/android_fuzzing/README.md をご覧ください。
セキュリティ
アプリのプロセスはドライバのプロセスと直接通信するため、ドライバは受け取った呼び出しの引数を検証する必要があります。この検証は VTS によって行われます。検証コードは frameworks/ml/nn/common/include/ValidateHal.h にあります。
また、ドライバは同じデバイスを使用しているときにアプリが他のアプリと干渉しないようにする必要があります。
Android 機械学習テストスイート
Android 機械学習テストスイート(MLTS)は、ベンダーのデバイスでの実際のモデルの精度を検証するために CTS と VTS に含まれる NNAPI のベンチマークです。このベンチマークでは、レイテンシと精度を評価し、同じモデルやデータセットの CPU で実行されている TF Lite を使用した場合の結果とドライバの結果を比較します。これにより、ドライバの精度が CPU のリファレンス実装よりも低下しないようにします。
Android プラットフォームのデベロッパーは、MLTS を使用してドライバのレイテンシと精度も評価します。
NNAPI ベンチマークは AOSP の 2 つのプロジェクトにあります。
platform/test/mlts/benchmark(ベンチマーク アプリ)platform/test/mlts/models(モデルとデータセット)
モデルとデータセット
NNAPI ベンチマークでは、次のモデルとデータセットを使用します。
- 異なるサイズの MobileNetV1 の浮動小数点と u8 の量子化。Open Images Dataset v4 の小さなサブセット(1500 個の画像)の実行対象となります。
- 異なるサイズの MobileNetV2 の浮動小数点と u8 の量子化。Open Images Dataset v4 の小さなサブセット(1500 個の画像)の実行対象となります。
- テキスト読み上げ用の長・短期記憶(LSTM)ベースの音響モデル。CMU Arctic セットの小さなサブセットの実行対象となります。
- 自動音声認識用の LSTM ベースの音響モデル。LibriSpeech データセットの小さなサブセットの実行対象となります。
詳細については、platform/test/mlts/models をご覧ください。
ストレステスト
Android 機械学習テストスイートには、過度な使用条件やクライアントの動作に関する例外的な状況におけるドライバの復元力を検証する一連のクラッシュ テストが用意されています。
すべてのクラッシュ テストでは、次の機能を利用できます。
- ハング検出: テスト中に NNAPI クライアントがハングする場合、テストは失敗理由
HANGにより失敗し、テストスイートは次のテストに進みます。 - NNAPI クライアント クラッシュ検出: テストはクライアントのクラッシュによって停止せず、失敗理由
CRASHによって失敗します。 - ドライバのクラッシュ検出: テストにより、NNAPI 呼び出しが失敗する原因となったドライバのクラッシュを検出できます。なお、NNAPI の障害の原因とならないクラッシュがドライバのプロセスで発生し、テストの失敗につながらない可能性もあります。このタイプのエラーに対応するには、システムログで
tailコマンドを実行し、ドライバ関連のエラーまたはクラッシュを確認することをおすすめします。 - 使用可能なすべてのアクセラレータのターゲット設定: 使用可能なすべてのドライバに対してテストが実行されます。
すべてのクラッシュ テストの結果は、次の 4 つに該当することが考えられます。
SUCCESS: エラーなしで実行が完了しました。FAILURE: 実行に失敗しました。通常は、モデルをテストする際に発生したエラーが原因です。ドライバがモデルのコンパイルまたは実行に失敗したことを示します。HANG: テストプロセスが応答しなくなりました。CRASH: テストプロセスがクラッシュしました。
ストレステストの詳細とクラッシュ テストの全一覧については、platform/test/mlts/benchmark/README.txt をご覧ください。
MLTS の使用
MLTS を使用するには:
- ターゲット デバイスをワークステーションに接続して、adb 経由でアクセスできることを確認します。複数のデバイスが接続されている場合は、ターゲット デバイスの
ANDROID_SERIAL環境変数をエクスポートします。 cdを実行して、Android のトップレベルのソース ディレクトリに移動します。source build/envsetup.sh lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available. ./test/mlts/benchmark/build_and_run_benchmark.shベンチマークの終了時に、結果が HTML ページとして
xdg-openに渡されます。
詳細については、platform/test/mlts/benchmark/README.txt をご覧ください。
ニューラル ネットワーク HAL のバージョン
このセクションでは、Android とニューラル ネットワーク HAL の各バージョンに導入された変更について説明します。
Android 11
Android 11 には NN HAL 1.3 が導入されました。主な変更点は次のとおりです。
- NNAPI における符号付き 8 ビットの量子化のサポート。
TENSOR_QUANT8_ASYMM_SIGNEDオペランド型を追加しました。符号なしの量子化演算をサポートしている NN HAL 1.3 のドライバは、それらの演算の符号付きバリアントもサポートする必要があります。ほとんどの量子化演算を符号付きと符号なしで実行する場合、ドライバは最大 128 のオフセットで同じ結果を生成する必要があります。この要件には、CAST、HASHTABLE_LOOKUP、LSH_PROJECTION、PAD_V2、QUANTIZED_16BIT_LSTMの 5 つの例外があります。QUANTIZED_16BIT_LSTM演算は符号付きオペランドをサポートしていません。他の 4 つの演算は符号付き量子化をサポートしますが、結果が同一であることを要件としません。 - フレームワークが
IPreparedModel::executeFencedメソッドを呼び出して、待機する同期フェンスのベクターを備えた準備済みのモデルに対する非同期実行を行う、フェンスを使用した実行をサポートします。詳細については、フェンスを使用した実行をご覧ください。 - 制御フローをサポートします。他のモデルを引数として取り、条件付きで(
IF)または繰り返し(WHILE)実行するIF演算とWHILE演算を追加しました。詳細については、制御フローをご覧ください。 - アプリが、モデルの相対的な優先度、モデルの準備に要することが想定される最大時間、実行を完了するのに要することが想定される最大時間を示すことによるサービス品質(QoS)の改善。詳細については、サービス品質をご覧ください。
- ドライバ管理バッファのアロケータ インターフェースを備えたメモリドメインのサポート。これを使用すると、実行間でデバイスのネイティブ メモリを受け渡しできるようになり、同じドライバでの連続した実行間で不要にデータをコピーまたは変換することが抑制されます。詳細については、メモリドメインをご覧ください。
Android 10
Android 10 には NN HAL 1.2 が導入されました。主な変更点は次のとおりです。
Capabilities構造体は、すべてのデータ型(スカラーデータ型を含む)を含み、名前付きフィールドではなくベクターを使用して非緩和型のパフォーマンスを表します。getVersionStringおよびgetTypeの各メソッドにより、フレームワークがデバイスタイプ(DeviceType)とバージョン情報を取得できるようになります。デバイスの検出と割り当てを参照してください。executeSynchronouslyメソッドは、デフォルトで呼び出され、同期的に実行します。execute_1_2メソッドは、フレームワークに非同期的な実行を指示します。実行を参照してください。executeSynchronously、execute_1_2、バースト実行に対するMeasureTimingパラメータは、ドライバが実行時間を測定するかどうかを指定します。結果はTiming構造体で報告されます。タイミングを参照してください。- 1 つ以上の出力オペランドが不明なディメンションまたはランクを持つ実行をサポートします。出力シェイプを参照してください。
- ベンダー定義の演算とデータ型の集合であるベンダー拡張機能をサポートします。ドライバは、サポートされている拡張機能を
IDevice::getSupportedExtensionsメソッド経由で報告します。ベンダー拡張機能を参照してください。 - バースト オブジェクトは、高速メッセージ キュー(FMQ)を使用して一連のバースト実行を制御し、アプリとドライバのプロセス間で通信して、レイテンシを短縮できます。バースト実行と高速メッセージ キューを参照してください。
- ドライバがデータをコピーせずに実行できるようにする AHardwareBuffer をサポートします。AHardwareBuffer を参照してください。
- アプリの起動時にコンパイルに要する時間を短縮するために、コンパイル アーティファクトのキャッシュのサポートが強化されています。コンパイルのキャッシュを参照してください。
Android 10 では、次のオペランド型と演算が導入されています。
-
ANEURALNETWORKS_BOOLANEURALNETWORKS_FLOAT16ANEURALNETWORKS_TENSOR_BOOL8ANEURALNETWORKS_TENSOR_FLOAT16ANEURALNETWORKS_TENSOR_QUANT16_ASYMMANEURALNETWORKS_TENSOR_QUANT16_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL
-
ANEURALNETWORKS_ABSANEURALNETWORKS_ARGMAXANEURALNETWORKS_ARGMINANEURALNETWORKS_AXIS_ALIGNED_BBOX_TRANSFORMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_RNNANEURALNETWORKS_BOX_WITH_NMS_LIMITANEURALNETWORKS_CASTANEURALNETWORKS_CHANNEL_SHUFFLEANEURALNETWORKS_DETECTION_POSTPROCESSINGANEURALNETWORKS_EQUALANEURALNETWORKS_EXPANEURALNETWORKS_EXPAND_DIMSANEURALNETWORKS_GATHERANEURALNETWORKS_GENERATE_PROPOSALSANEURALNETWORKS_GREATERANEURALNETWORKS_GREATER_EQUALANEURALNETWORKS_GROUPED_CONV_2DANEURALNETWORKS_HEATMAP_MAX_KEYPOINTANEURALNETWORKS_INSTANCE_NORMALIZATIONANEURALNETWORKS_LESSANEURALNETWORKS_LESS_EQUALANEURALNETWORKS_LOGANEURALNETWORKS_LOGICAL_ANDANEURALNETWORKS_LOGICAL_NOTANEURALNETWORKS_LOGICAL_ORANEURALNETWORKS_LOG_SOFTMAXANEURALNETWORKS_MAXIMUMANEURALNETWORKS_MINIMUMANEURALNETWORKS_NEGANEURALNETWORKS_NOT_EQUALANEURALNETWORKS_PAD_V2ANEURALNETWORKS_POWANEURALNETWORKS_PRELUANEURALNETWORKS_QUANTIZEANEURALNETWORKS_QUANTIZED_16BIT_LSTMANEURALNETWORKS_RANDOM_MULTINOMIALANEURALNETWORKS_REDUCE_ALLANEURALNETWORKS_REDUCE_ANYANEURALNETWORKS_REDUCE_MAXANEURALNETWORKS_REDUCE_MINANEURALNETWORKS_REDUCE_PRODANEURALNETWORKS_REDUCE_SUMANEURALNETWORKS_RESIZE_NEAREST_NEIGHBORANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_ROI_POOLINGANEURALNETWORKS_RSQRTANEURALNETWORKS_SELECTANEURALNETWORKS_SINANEURALNETWORKS_SLICEANEURALNETWORKS_SPLITANEURALNETWORKS_SQRTANEURALNETWORKS_TILEANEURALNETWORKS_TOPK_V2ANEURALNETWORKS_TRANSPOSE_CONV_2DANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_RNN
Android 10 では、既存の演算の多くが更新されています。更新内容は、主に次の項目に関連しています。
- NCHW メモリ レイアウトのサポート
- softmax および正規化演算の 4 以外のランクのテンソルのサポート
- 拡張された畳み込みのサポート
ANEURALNETWORKS_CONCATENATIONの量子化を混在させた入力のサポート
Android 10 で変更されている演算を次の一覧に示します。変更の詳細については、NNAPI リファレンス ドキュメントの OperationCode を参照してください。
ANEURALNETWORKS_ADDANEURALNETWORKS_AVERAGE_POOL_2DANEURALNETWORKS_BATCH_TO_SPACE_NDANEURALNETWORKS_CONCATENATIONANEURALNETWORKS_CONV_2DANEURALNETWORKS_DEPTHWISE_CONV_2DANEURALNETWORKS_DEPTH_TO_SPACEANEURALNETWORKS_DEQUANTIZEANEURALNETWORKS_DIVANEURALNETWORKS_FLOORANEURALNETWORKS_FULLY_CONNECTEDANEURALNETWORKS_L2_NORMALIZATIONANEURALNETWORKS_L2_POOL_2DANEURALNETWORKS_LOCAL_RESPONSE_NORMALIZATIONANEURALNETWORKS_LOGISTICANEURALNETWORKS_LSH_PROJECTIONANEURALNETWORKS_LSTMANEURALNETWORKS_MAX_POOL_2DANEURALNETWORKS_MEANANEURALNETWORKS_MULANEURALNETWORKS_PADANEURALNETWORKS_RELUANEURALNETWORKS_RELU1ANEURALNETWORKS_RELU6ANEURALNETWORKS_RESHAPEANEURALNETWORKS_RESIZE_BILINEARANEURALNETWORKS_RNNANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_SOFTMAXANEURALNETWORKS_SPACE_TO_BATCH_NDANEURALNETWORKS_SPACE_TO_DEPTHANEURALNETWORKS_SQUEEZEANEURALNETWORKS_STRIDED_SLICEANEURALNETWORKS_SUBANEURALNETWORKS_SVDFANEURALNETWORKS_TANHANEURALNETWORKS_TRANSPOSE
Android 9
Android 9 では NN HAL 1.1 が導入されました。主な変更点は次のとおりです。
IDevice::prepareModel_1_1にはExecutionPreferenceパラメータが含まれます。ドライバはこのパラメータを使用して、アプリが電池の消費の節約を優先するか、連続した呼び出しでモデルを実行するかを把握して、その準備を調整できます。- 9 つの新しい演算(
BATCH_TO_SPACE_ND、DIV、MEAN、PAD、SPACE_TO_BATCH_ND、SQUEEZE、STRIDED_SLICE、SUB、TRANSPOSE)が追加されました。 - アプリでは
Model.relaxComputationFloat32toFloat16をtrueに設定して、32 ビット浮動小数点演算が 16 ビット浮動小数点数の範囲や精度で実行されるように指定できます。Capabilities構造体には追加のフィールドrelaxedFloat32toFloat16Performanceがあるため、ドライバは緩和されたパフォーマンスをフレームワークに報告できます。
Android 8.1
最初のニューラル ネットワーク HAL(1.0)は Android 8.1 でリリースされました。詳細については、/neuralnetworks/1.0/ をご覧ください。