
หน้านี้ให้ภาพรวมเกี่ยวกับวิธีติดตั้งใช้งานไดรเวอร์ Neural Networks API (NNAPI)
ดูรายละเอียดเพิ่มเติมได้ในเอกสารประกอบที่อยู่ในไฟล์คำจำกัดความ HAL ใน
hardware/interfaces/neuralnetworks
ตัวอย่างการใช้งานไดรเวอร์อยู่ใน
frameworks/ml/nn/driver/sample
ดูข้อมูลเพิ่มเติมเกี่ยวกับ Neural Networks API ได้ที่ Neural Networks API
HAL ของโครงข่ายระบบประสาทเทียม
HAL ของเครือข่ายประสาท (NN) จะกำหนดการแยกส่วนของอุปกรณ์ต่างๆ
เช่น หน่วยประมวลผลกราฟิก (GPU) และหน่วยประมวลผลสัญญาณดิจิทัล (DSP)
ที่อยู่ในผลิตภัณฑ์ (เช่น โทรศัพท์หรือแท็บเล็ต) ไดรเวอร์สำหรับอุปกรณ์เหล่านี้ต้องเป็นไปตาม NN HAL อินเทอร์เฟซระบุอยู่ในไฟล์คำจำกัดความ HAL
ใน
hardware/interfaces/neuralnetworks
ลำดับการทำงานทั่วไปของอินเทอร์เฟซระหว่างเฟรมเวิร์กกับไดรเวอร์แสดงอยู่ในรูปที่ 1
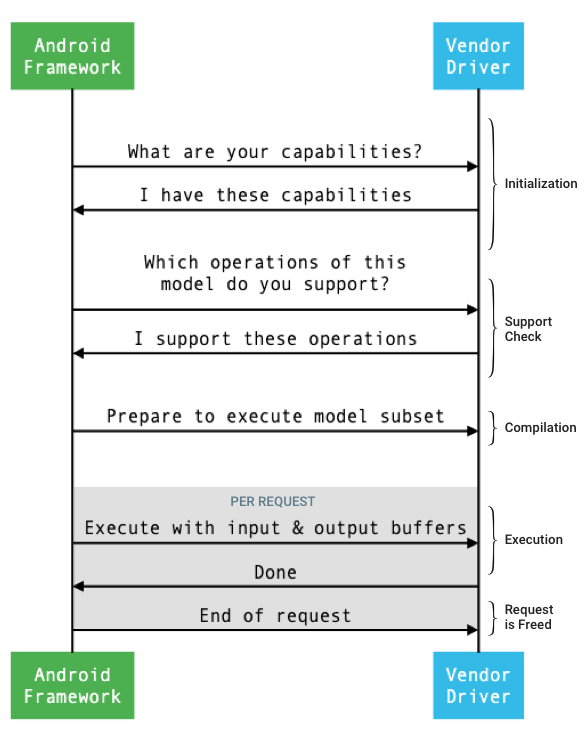
รูปที่ 1 โฟลว์ของโครงข่ายระบบประสาทเทียม
การเริ่มต้น
เมื่อเริ่มต้นใช้งาน เฟรมเวิร์กจะค้นหาความสามารถของไดรเวอร์โดยใช้ IDevice::getCapabilities_1_3
โครงสร้าง @1.3::Capabilities มีข้อมูลทุกประเภทและ
แสดงประสิทธิภาพที่ไม่ผ่อนคลายโดยใช้เวกเตอร์
เฟรมเวิร์กจะใช้ความสามารถเพื่อทำความเข้าใจว่าไดรเวอร์แต่ละตัวสามารถดำเนินการได้รวดเร็วและประหยัดพลังงานเพียงใด เพื่อกำหนดวิธีจัดสรรการคำนวณให้กับอุปกรณ์ที่พร้อมใช้งาน หากต้องการให้ข้อมูลนี้ ไดรเวอร์ต้องระบุตัวเลขประสิทธิภาพที่ได้มาตรฐานตามการดำเนินการ ของเวิร์กโหลดอ้างอิง
หากต้องการกำหนดค่าที่ไดรเวอร์ส่งคืนในการตอบกลับ IDevice::getCapabilities_1_3 ให้ใช้แอปการเปรียบเทียบ NNAPI เพื่อวัดประสิทธิภาพสำหรับประเภทข้อมูลที่เกี่ยวข้อง เราขอแนะนำให้ใช้โมเดล MobileNet v1 และ v2, asr_float,
และ tts_float ในการวัดประสิทธิภาพสำหรับค่าทศนิยมแบบ 32 บิต
และแนะนำให้ใช้โมเดล MobileNet v1 และ v2 ที่มีการวัดปริมาณ
สำหรับค่าที่วัดปริมาณแบบ 8 บิต ดูข้อมูลเพิ่มเติมได้ที่
ชุดทดสอบแมชชีนเลิร์นนิงของ Android
ใน Android 9 และเวอร์ชันที่ต่ำกว่า โครงสร้าง Capabilities จะมีข้อมูลประสิทธิภาพของไดรเวอร์
เฉพาะสำหรับเทนเซอร์แบบจุดลอยและเทนเซอร์ที่ผ่านการหาปริมาณ และไม่มี
ประเภทข้อมูลสเกลาร์
ในกระบวนการเริ่มต้น เฟรมเวิร์กอาจค้นหาข้อมูลเพิ่มเติมโดยใช้ IDevice::getType, IDevice::getVersionString, IDevice:getSupportedExtensions และ IDevice::getNumberOfCacheFilesNeeded
ในระหว่างการรีบูตผลิตภัณฑ์ เฟรมเวิร์กคาดหวังว่าการค้นหาทั้งหมดที่อธิบายไว้ในส่วนนี้จะรายงานค่าเดียวกันเสมอสำหรับไดรเวอร์ที่กำหนด ไม่เช่นนั้น แอป ที่ใช้ไดรเวอร์นั้นอาจมีประสิทธิภาพลดลงหรือทำงานไม่ถูกต้อง
การรวบรวม
เฟรมเวิร์กจะกำหนดอุปกรณ์ที่จะใช้เมื่อได้รับคำขอจากแอป ใน Android 10 แอปจะค้นหาและระบุอุปกรณ์ที่เฟรมเวิร์กเลือกได้ ดูข้อมูลเพิ่มเติมได้ที่การค้นหาและการกำหนดอุปกรณ์
เมื่อรวบรวมโมเดล เฟรมเวิร์กจะส่งโมเดลไปยังผู้ขับขี่แต่ละรายที่อาจเป็นผู้ขับขี่
โดยการเรียกใช้
IDevice::getSupportedOperations_1_3
ไดรเวอร์แต่ละตัวจะแสดงผลอาร์เรย์ของบูลีนที่ระบุว่ารองรับการดำเนินการใดของโมเดล ไดรเวอร์อาจพิจารณาว่าไม่สามารถ
รองรับการดำเนินการหนึ่งๆ ได้ด้วยเหตุผลหลายประการ เช่น
- ไดรเวอร์ไม่รองรับประเภทข้อมูล
- ไดรเวอร์รองรับเฉพาะการดำเนินการที่มีพารามิเตอร์อินพุตที่เฉพาะเจาะจง ตัวอย่างเช่น ไดรเวอร์อาจรองรับการดำเนินการ การแปลงแบบคอนโวลูชัน 3x3 และ 5x5 แต่ไม่รองรับ 7x7
- ไดรเวอร์มีข้อจำกัดด้านหน่วยความจำที่ทำให้ไม่สามารถจัดการกราฟหรืออินพุตขนาดใหญ่ได้
ในระหว่างการคอมไพล์ อินพุต เอาต์พุต และตัวถูกดำเนินการภายในของโมเดลตามที่อธิบายไว้ใน
OperandLifeTime
อาจมีมิติข้อมูลหรืออันดับที่ไม่รู้จัก ดูข้อมูลเพิ่มเติมได้ที่
รูปร่างเอาต์พุต
เฟรมเวิร์กจะสั่งให้ไดรเวอร์แต่ละตัวที่เลือกเตรียมพร้อมที่จะเรียกใช้ชุดย่อยของโมเดลโดยการเรียกใช้ IDevice::prepareModel_1_3
จากนั้นไดรเวอร์แต่ละตัวจะคอมไพล์ชุดย่อยของตัวเอง ตัวอย่างเช่น ไดรเวอร์อาจ
สร้างโค้ดหรือสร้างสำเนาของน้ำหนักที่เรียงลำดับใหม่ เนื่องจากอาจใช้เวลานานพอสมควรระหว่างการคอมไพล์โมเดลกับการ
ดำเนินการคำขอ จึงไม่ควรจัดสรรทรัพยากร เช่น หน่วยความจำของอุปกรณ์จำนวนมาก
ในระหว่างการคอมไพล์
เมื่อสำเร็จ ไดรเวอร์จะส่งคืน@1.3::IPreparedModel
แฮนเดิล หากไดรเวอร์แสดงรหัสข้อผิดพลาดเมื่อเตรียมชุดย่อยของ
โมเดล เฟรมเวิร์กจะเรียกใช้โมเดลทั้งหมดใน CPU
ไดรเวอร์สามารถแคชอาร์ติแฟกต์การคอมไพล์เพื่อลดเวลาที่ใช้ในการคอมไพล์เมื่อแอปเริ่มต้น ดูข้อมูลเพิ่มเติมได้ที่การแคช การคอมไพล์
การลงมือปฏิบัติ
เมื่อแอปขอให้เฟรมเวิร์กดำเนินการคำขอ เฟรมเวิร์กจะเรียกใช้เมธอด HAL ของ IPreparedModel::executeSynchronously_1_3
โดยค่าเริ่มต้นเพื่อดำเนินการแบบซิงโครนัสในโมเดลที่เตรียมไว้
นอกจากนี้ คุณยังเรียกใช้คำขอแบบไม่พร้อมกันได้โดยใช้เมธอด
execute_1_3
เมธอด
executeFenced (ดูการดำเนินการแบบ Fenced)
หรือเรียกใช้โดยใช้
การดำเนินการแบบกลุ่ม
การเรียกใช้แบบซิงโครนัสช่วยปรับปรุงประสิทธิภาพและลดค่าใช้จ่ายในการสร้างเธรด เมื่อเทียบกับการเรียกใช้แบบอะซิงโครนัส เนื่องจากระบบจะส่งคืนการควบคุมไปยัง กระบวนการของแอปหลังจากดำเนินการเสร็จสมบูรณ์แล้วเท่านั้น ซึ่งหมายความว่า ไดรเวอร์ไม่จำเป็นต้องมีกลไกแยกต่างหากเพื่อแจ้งกระบวนการของแอปว่า การดำเนินการเสร็จสมบูรณ์แล้ว
เมื่อใช้เมธอด execute_1_3 แบบอะซิงโครนัส การควบคุมจะกลับไปที่กระบวนการของแอปหลังจากที่การดำเนินการเริ่มต้นขึ้น และไดรเวอร์ต้องแจ้งให้เฟรมเวิร์กทราบเมื่อการดำเนินการเสร็จสมบูรณ์โดยใช้ @1.3::IExecutionCallback
Request พารามิเตอร์ที่ส่งไปยังเมธอด execute จะแสดงรายการอินพุตและเอาต์พุต
ตัวถูกดำเนินการที่ใช้สำหรับการดำเนินการ หน่วยความจำที่จัดเก็บข้อมูลตัวถูกดำเนินการต้อง
ใช้ลำดับแถวหลักโดยที่มิติข้อมูลแรกวนซ้ำช้าที่สุด และไม่มี
การเว้นวรรคที่ท้ายแถว ดูข้อมูลเพิ่มเติมเกี่ยวกับประเภทตัวถูกดำเนินการได้ที่
ตัวถูกดำเนินการ
สำหรับไดรเวอร์ NN HAL 1.2 ขึ้นไป เมื่อคำขอเสร็จสมบูรณ์ ระบบจะส่งคืนสถานะข้อผิดพลาด รูปร่างเอาต์พุต และข้อมูลเวลาไปยังเฟรมเวิร์ก ในระหว่างการดำเนินการ เอาต์พุตหรือตัวถูกดำเนินการภายในของโมเดลอาจมีมิติข้อมูลที่ไม่รู้จักอย่างน้อย 1 รายการหรืออันดับที่ไม่รู้จัก เมื่อตัวถูกดำเนินการเอาต์พุตอย่างน้อย 1 รายการมีมิติข้อมูลหรืออันดับที่ไม่รู้จัก ไดรเวอร์ต้องแสดงข้อมูลเอาต์พุตที่มีขนาดแบบไดนามิก
สำหรับไดรเวอร์ที่มี NN HAL 1.1 หรือต่ำกว่า ระบบจะแสดงเฉพาะสถานะข้อผิดพลาดเมื่อคำขอเสร็จสมบูรณ์ ต้องระบุขนาดสำหรับตัวถูกดำเนินการอินพุตและเอาต์พุตอย่างครบถ้วน เพื่อให้การดำเนินการเสร็จสมบูรณ์ ตัวถูกดำเนินการภายในอาจมีมิติข้อมูลที่ไม่รู้จักอย่างน้อย 1 รายการ แต่ต้องมีอันดับที่ระบุ
สำหรับคำขอของผู้ใช้ที่ครอบคลุมไดรเวอร์หลายตัว เฟรมเวิร์กมีหน้าที่ จองหน่วยความจำกลางและจัดลำดับการเรียกไปยังไดรเวอร์แต่ละตัว
คุณสามารถเริ่มคำขอหลายรายการพร้อมกันใน@1.3::IPreparedModelเดียวกันได้
ไดรเวอร์สามารถดำเนินการคำขอแบบขนานหรือแบบอนุกรมได้
เฟรมเวิร์กสามารถขอให้ไดรเวอร์เก็บโมเดลที่เตรียมไว้มากกว่า 1 รายการ เช่น เตรียมโมเดล m1 เตรียม m2 ดำเนินการคำขอ r1 ใน m1 ดำเนินการ
r2 ใน m2 ดำเนินการ r3 ใน m1 ดำเนินการ r4 ใน m2 เผยแพร่ (อธิบายไว้ในการล้างข้อมูล) m1 และเผยแพร่ m2
เพื่อหลีกเลี่ยงการดำเนินการครั้งแรกที่ช้าซึ่งอาจส่งผลให้ผู้ใช้ได้รับประสบการณ์การใช้งานที่ไม่ดี (เช่น เฟรมแรกกระตุก) ไดรเวอร์ควรทำการเริ่มต้นส่วนใหญ่ในระยะการคอมไพล์ การเริ่มต้นเมื่อดำเนินการครั้งแรกควรจำกัดไว้ที่ การดำเนินการที่ส่งผลเสียต่อสถานะของระบบเมื่อดำเนินการก่อนเวลาอันควร เช่น การจองบัฟเฟอร์ชั่วคราวขนาดใหญ่หรือการเพิ่มอัตราสัญญาณนาฬิกาของอุปกรณ์ ไดรเวอร์ที่เตรียมโมเดลพร้อมกันได้ในจำนวนจำกัดอาจต้องทำการเริ่มต้นเมื่อมีการเรียกใช้ครั้งแรก
ใน Android 10 ขึ้นไป ในกรณีที่มีการดำเนินการหลายครั้งด้วยโมเดลที่เตรียมไว้เดียวกันอย่างต่อเนื่อง ไคลเอ็นต์อาจเลือกใช้ออบเจ็กต์การดำเนินการแบบกลุ่มเพื่อสื่อสารระหว่างกระบวนการของแอปและไดรเวอร์ ดูข้อมูลเพิ่มเติมได้ที่การดำเนินการแบบกลุ่มและคิวข้อความที่รวดเร็ว
ไดรเวอร์สามารถเก็บรักษาบัฟเฟอร์ชั่วคราวหรือเพิ่มอัตราสัญญาณนาฬิกาเพื่อปรับปรุงประสิทธิภาพสำหรับการดำเนินการหลายรายการอย่างรวดเร็ว ขอแนะนำให้สร้างเธรด Watchdog เพื่อปล่อยทรัพยากรหากไม่มีการสร้างคำขอใหม่หลังจากผ่านไประยะเวลาหนึ่ง
รูปร่างเอาต์พุต
สำหรับคำขอที่ตัวถูกดำเนินการเอาต์พุตอย่างน้อย 1 รายการไม่มีการระบุขนาดทั้งหมด
ไดรเวอร์ต้องระบุรายการรูปร่างเอาต์พุตที่มี
ข้อมูลมิติข้อมูลสำหรับตัวถูกดำเนินการเอาต์พุตแต่ละรายการหลังจากการดำเนินการ ดูข้อมูลเพิ่มเติมเกี่ยวกับมิติข้อมูลได้ที่
OutputShape
หากการดำเนินการล้มเหลวเนื่องจากบัฟเฟอร์เอาต์พุตมีขนาดเล็กเกินไป ไดรเวอร์ต้อง ระบุตัวถูกดำเนินการเอาต์พุตที่มีขนาดบัฟเฟอร์ไม่เพียงพอในรายการ รูปร่างเอาต์พุต และควรรายงานข้อมูลมิติข้อมูลให้มากที่สุด โดยใช้ 0 สำหรับมิติข้อมูลที่ไม่รู้จัก
ช่วงเวลา
ใน Android 10 แอปจะขอเวลาดำเนินการได้หากแอปได้ระบุอุปกรณ์เครื่องเดียวที่จะใช้ในระหว่างกระบวนการคอมไพล์ โปรดดูรายละเอียดที่MeasureTiming
และการค้นหาและการกำหนดอุปกรณ์
ในกรณีนี้ ไดรเวอร์ NN HAL 1.2 ต้องวัดระยะเวลาการดำเนินการหรือรายงาน UINT64_MAX (เพื่อระบุว่าระยะเวลาไม่พร้อมใช้งาน) เมื่อดำเนินการตามคำขอ ไดรเวอร์
ควรลดการลงโทษด้านประสิทธิภาพที่เกิดจากการวัดระยะเวลาการดำเนินการ
ให้เหลือน้อยที่สุด
ไดรเวอร์รายงานระยะเวลาต่อไปนี้ในหน่วยไมโครวินาทีในโครงสร้าง
Timing
- เวลาในการดำเนินการบนอุปกรณ์: ไม่รวมเวลาในการดำเนินการใน ไดรเวอร์ซึ่งทำงานบนโปรเซสเซอร์โฮสต์
- เวลาในการดำเนินการในไดรเวอร์: รวมถึงเวลาในการดำเนินการในอุปกรณ์
ระยะเวลาเหล่านี้ต้องรวมเวลาที่การดำเนินการถูกระงับด้วย เช่น เมื่อการดำเนินการถูกขัดจังหวะโดยงานอื่นๆ หรือเมื่อรอให้ทรัพยากรพร้อมใช้งาน
เมื่อไม่ได้ขอให้ไดรเวอร์วัดระยะเวลาการดำเนินการ หรือเมื่อเกิดข้อผิดพลาดในการดำเนินการ ไดรเวอร์ต้องรายงานระยะเวลาเป็น UINT64_MAX แม้ว่าระบบจะขอให้ไดรเวอร์วัดระยะเวลาการดำเนินการ แต่ไดรเวอร์อาจรายงาน UINT64_MAX สำหรับเวลาในอุปกรณ์ เวลาในไดรเวอร์ หรือทั้ง 2 อย่างแทน เมื่อไดรเวอร์รายงานระยะเวลาทั้ง 2 รายการเป็นค่าอื่นที่ไม่ใช่
UINT64_MAX เวลาในการดำเนินการในไดรเวอร์ต้องเท่ากับหรือมากกว่าเวลาใน
อุปกรณ์
การดำเนินการที่จำกัด
ใน Android 11 NNAPI อนุญาตให้การดำเนินการรอรายการแฮนเดิล sync_fence และอาจส่งคืนออบเจ็กต์ sync_fence ซึ่งจะมีการส่งสัญญาณเมื่อการดำเนินการเสร็จสมบูรณ์ ซึ่งจะช่วยลดค่าใช้จ่ายสำหรับโมเดลลำดับขนาดเล็กและกรณีการใช้งานการสตรีม การดำเนินการที่จำกัดยังช่วยให้ทำงานร่วมกับคอมโพเนนต์อื่นๆ ที่ส่งสัญญาณหรือรอ sync_fence ได้อย่างมีประสิทธิภาพมากขึ้นด้วย
ดูข้อมูลเพิ่มเติมเกี่ยวกับ sync_fence ได้ที่เฟรมเวิร์กการซิงค์
ในการดำเนินการที่จำกัด เฟรมเวิร์กจะเรียกใช้เมธอด
IPreparedModel::executeFenced
เพื่อเปิดใช้การดำเนินการแบบอะซิงโครนัสที่จำกัดในโมเดลที่เตรียมไว้พร้อมเวกเตอร์ของรั้วการซิงค์เพื่อรอ หากงานแบบอะซิงโครนัสเสร็จสิ้นก่อนที่การเรียกจะกลับมา ระบบจะส่งคืนแฮนเดิลที่ว่างเปล่าสำหรับ sync_fence นอกจากนี้ ต้องส่งคืนออบเจ็กต์ IFencedExecutionCallback เพื่อให้เฟรมเวิร์ก
สามารถค้นหาสถานะข้อผิดพลาดและข้อมูลระยะเวลาได้
หลังจากดำเนินการเสร็จสมบูรณ์แล้ว คุณจะค้นหาค่าเวลา 2 ค่าต่อไปนี้
ซึ่งวัดระยะเวลาของการดำเนินการได้ผ่าน
IFencedExecutionCallback::getExecutionInfo
timingLaunched: ระยะเวลาตั้งแต่เรียกใช้executeFencedจนถึงเวลาที่executeFencedส่งสัญญาณsyncFenceที่ส่งคืนtimingFenced: ระยะเวลาตั้งแต่เมื่อมีการส่งสัญญาณรั้วการซิงค์ทั้งหมด ที่การดำเนินการรอจนถึงเมื่อexecuteFencedส่งสัญญาณsyncFenceที่ส่งคืน
ควบคุมโฟลว์
สำหรับอุปกรณ์ที่ใช้ Android 11 ขึ้นไป NNAPI
มีการดำเนินการควบคุมโฟลว์ 2 รายการ ได้แก่ IF และ WHILE ซึ่งรับโมเดลอื่นๆ
เป็นอาร์กิวเมนต์และดำเนินการตามเงื่อนไข (IF) หรือซ้ำๆ (WHILE) ดูข้อมูลเพิ่มเติมเกี่ยวกับวิธีใช้การดำเนินการนี้ได้ที่การควบคุมโฟลว์
คุณภาพของการบริการ
ใน Android 11 นั้น NNAPI มีคุณภาพของ บริการ (QoS) ที่ได้รับการปรับปรุงโดยอนุญาตให้แอประบุลำดับความสำคัญที่เกี่ยวข้องของโมเดล เวลาสูงสุดที่คาดไว้ในการเตรียมโมเดล และ เวลาสูงสุดที่คาดไว้ในการดำเนินการให้เสร็จสมบูรณ์ ดูข้อมูลเพิ่มเติมได้ที่ คุณภาพของบริการ
ทำความสะอาดข้อมูล
เมื่อแอปใช้โมเดลที่เตรียมไว้เสร็จแล้ว เฟรมเวิร์กจะปล่อยการอ้างอิงไปยังออบเจ็กต์ @1.3::IPreparedModel
เมื่อไม่มีการอ้างอิงออบเจ็กต์ IPreparedModel อีกต่อไป ระบบจะทำลายออบเจ็กต์โดยอัตโนมัติในบริการไดรเวอร์ที่สร้างออบเจ็กต์ คุณสามารถเรียกคืนทรัพยากรเฉพาะโมเดลได้ในขณะนี้ในการติดตั้งใช้งานตัวทำลายของไดรเวอร์ หากบริการไดรเวอร์ต้องการให้ระบบทำลายออบเจ็กต์ IPreparedModel โดยอัตโนมัติเมื่อไคลเอ็นต์ไม่ต้องการแล้ว บริการจะต้องไม่เก็บข้อมูลอ้างอิงใดๆ ไปยังออบเจ็กต์ IPreparedModel หลังจากที่ส่งคืนออบเจ็กต์ IPreparedeModel ผ่าน IPreparedModelCallback::notify_1_3
การใช้ CPU
คาดว่าไดรเวอร์จะใช้ CPU เพื่อตั้งค่าการคำนวณ ไดรเวอร์ไม่ควรใช้ CPU เพื่อทำการคำนวณกราฟเนื่องจากจะรบกวนความสามารถของเฟรมเวิร์กในการจัดสรรงานอย่างถูกต้อง ไดรเวอร์ควรรายงาน ชิ้นส่วนที่จัดการไม่ได้ไปยังเฟรมเวิร์ก และปล่อยให้เฟรมเวิร์กจัดการ ส่วนที่เหลือ
เฟรมเวิร์กมีการใช้งาน CPU สำหรับการดำเนินการ NNAPI ทั้งหมดยกเว้น การดำเนินการที่ผู้ให้บริการกำหนด ดูข้อมูลเพิ่มเติมได้ที่ ส่วนขยายของผู้ให้บริการ
การดำเนินการที่เปิดตัวใน Android 10 (API ระดับ 29) มีเพียงการติดตั้งใช้งาน CPU อ้างอิงเพื่อยืนยันว่าการทดสอบ CTS และ VTS ถูกต้อง เราขอแนะนำให้ใช้การติดตั้งใช้งานที่เพิ่มประสิทธิภาพซึ่งรวมอยู่ในเฟรมเวิร์กแมชชีนเลิร์นนิงบนอุปกรณ์เคลื่อนที่มากกว่าการติดตั้งใช้งาน CPU ของ NNAPI
ฟังก์ชันยูทิลิตี
โค้ดเบส NNAPI มีฟังก์ชันยูทิลิตีที่บริการไดรเวอร์ใช้ได้
ไฟล์
frameworks/ml/nn/common/include/Utils.h
มีฟังก์ชันยูทิลิตีต่างๆ เช่น ฟังก์ชันที่ใช้สำหรับการบันทึกและ
สำหรับการแปลงระหว่าง NN HAL เวอร์ชันต่างๆ
VLogging:
VLOGคือมาโคร Wrapper รอบLOGของ Android ซึ่งจะบันทึกข้อความก็ต่อเมื่อมีการตั้งค่าแท็กที่เหมาะสมในพร็อพเพอร์ตี้debug.nn.vloginitVLogMask()ต้องเรียกใช้ก่อนการเรียกใช้VLOGมาโครVLOG_IS_ONสามารถใช้เพื่อตรวจสอบว่าขณะนี้มีการเปิดใช้VLOGหรือไม่ ซึ่งจะช่วยให้ข้ามโค้ดการบันทึกที่ซับซ้อนได้หากไม่จำเป็น ค่าของพร็อพเพอร์ตี้ต้องเป็นค่าใดค่าหนึ่งต่อไปนี้- สตริงว่าง ซึ่งบ่งบอกว่าไม่ต้องทำการบันทึก
- โทเค็น
1หรือallซึ่งระบุว่าต้องทำการบันทึกทั้งหมด - รายการแท็กที่คั่นด้วยช่องว่าง คอมมา หรือโคลอน
ซึ่งระบุว่าควรบันทึกข้อมูลใด แท็กคือ
compilation,cpuexe,driver,execution,managerและmodel
compliantWithV1_*: แสดงผลtrueหากแปลงออบเจ็กต์ NN HAL เป็น HAL เวอร์ชันอื่นประเภทเดียวกันได้โดยไม่สูญเสียข้อมูล ตัวอย่างเช่น การเรียกใช้compliantWithV1_0ในV1_2::Modelจะแสดงผลfalseหากโมเดลมีประเภทการดำเนินการที่เปิดตัวใน NN HAL 1.1 หรือ NN HAL 1.2convertToV1_*: แปลงออบเจ็กต์ NN HAL จากเวอร์ชันหนึ่งเป็นอีกเวอร์ชันหนึ่ง ระบบจะบันทึกคำเตือนหากผลลัพธ์ของ Conversion ทำให้ข้อมูลสูญหาย (กล่าวคือ หากเวอร์ชันใหม่ของประเภทไม่สามารถแสดงค่าได้อย่างสมบูรณ์)ความสามารถ: คุณสามารถใช้ฟังก์ชัน
nonExtensionOperandPerformanceและupdateเพื่อช่วยสร้างฟิลด์Capabilities::operandPerformanceได้การค้นหาพร็อพเพอร์ตี้ของประเภท
isExtensionOperandType,isExtensionOperationType,nonExtensionSizeOfData,nonExtensionOperandSizeOfData,nonExtensionOperandTypeIsScalar,tensorHasUnspecifiedDimensions
ไฟล์
frameworks/ml/nn/common/include/ValidateHal.h
มีฟังก์ชันยูทิลิตีสำหรับการตรวจสอบว่าออบเจ็กต์ NN HAL ถูกต้อง
ตามข้อกำหนดของ HAL เวอร์ชันนั้นๆ
validate*: แสดงผลtrueหากออบเจ็กต์ NN HAL ใช้ได้ ตามข้อกำหนดของเวอร์ชัน HAL ระบบจะไม่ตรวจสอบประเภท OEM และประเภทส่วนขยาย เช่นvalidateModelจะแสดงผลfalseหากโมเดลมี การดำเนินการที่อ้างอิงดัชนีตัวถูกดำเนินการที่ไม่มีอยู่ หรือการดำเนินการที่ไม่รองรับใน HAL เวอร์ชันนั้น
ไฟล์
frameworks/ml/nn/common/include/Tracing.h
มีมาโครเพื่อลดความซับซ้อนในการเพิ่มข้อมูล systracing ลงในโค้ดของ Neural Networks
ดูตัวอย่างได้ที่NNTRACE_*การเรียกใช้มาโครใน
ไดรเวอร์ตัวอย่าง
ไฟล์
frameworks/ml/nn/common/include/GraphDump.h
มีฟังก์ชันยูทิลิตีเพื่อส่งออกเนื้อหาของ Model ในรูปแบบกราฟิก
เพื่อวัตถุประสงค์ในการแก้ไขข้อบกพร่อง
graphDump: เขียนการแสดงโมเดลในรูปแบบ Graphviz (.dot) ไปยังสตรีมที่ระบุ (หากระบุ) หรือไปยัง Logcat (หาก ไม่ได้ระบุสตรีม)
การตรวจสอบความถูกต้อง
หากต้องการทดสอบการใช้งาน NNAPI ให้ใช้การทดสอบ VTS และ CTS ที่รวมอยู่ใน เฟรมเวิร์ก Android VTS จะทดสอบไดรเวอร์โดยตรง (โดยไม่ใช้ เฟรมเวิร์ก) ในขณะที่ CTS จะทดสอบไดรเวอร์โดยอ้อมผ่านเฟรมเวิร์ก ซึ่งจะ ทดสอบแต่ละเมธอดของ API และยืนยันว่าการดำเนินการทั้งหมดที่ไดรเวอร์รองรับทำงานได้อย่างถูกต้องและให้ผลลัพธ์ที่เป็นไปตามข้อกำหนดด้านความแม่นยำ
ข้อกำหนดด้านความแม่นยำใน CTS และ VTS สำหรับ NNAPI มีดังนี้
จุดลอยตัว: abs(expected - actual) <= atol + rtol * abs(expected) โดยที่
- สำหรับ fp32, atol = 1e-5f, rtol = 5.0f * 1.1920928955078125e-7
- สำหรับ fp16 atol = rtol = 5.0f * 0.0009765625f
เชิงปริมาณ: ปิดทีละ 1 (ยกเว้น
mobilenet_quantizedซึ่งปิดทีละ 3)บูลีน: การทำงานแบบตรงทั้งหมด
วิธีหนึ่งที่ CTS ใช้ทดสอบ NNAPI คือการสร้างกราฟแบบสุ่มเทียมที่กำหนดไว้
ซึ่งใช้เพื่อทดสอบและเปรียบเทียบผลการดำเนินการจากไดรเวอร์แต่ละตัวกับ
การใช้งานอ้างอิงของ NNAPI สำหรับไดรเวอร์ที่มี NN HAL 1.2 ขึ้นไป หากผลลัพธ์ไม่เป็นไปตามเกณฑ์ความแม่นยำ CTS จะรายงานข้อผิดพลาดและทิ้งไฟล์ข้อมูลจำเพาะสำหรับโมเดลที่ไม่สำเร็จไว้ใน /data/local/tmp เพื่อการแก้ไขข้อบกพร่อง
ดูรายละเอียดเพิ่มเติมเกี่ยวกับเกณฑ์ความแม่นยำได้ที่
TestRandomGraph.cpp
และ
TestHarness.h
การทดสอบแบบฟัซ
วัตถุประสงค์ของการทดสอบแบบฟัซคือการค้นหาข้อขัดข้อง การยืนยัน การละเมิดหน่วยความจำ หรือลักษณะการทำงานทั่วไปที่ไม่ได้กำหนดไว้ในโค้ดที่อยู่ระหว่างการทดสอบเนื่องจากปัจจัยต่างๆ เช่น อินพุตที่ไม่คาดคิด สำหรับการทดสอบแบบฟัซ NNAPI นั้น Android จะใช้การทดสอบที่อิงตาม libFuzzer ซึ่งมีประสิทธิภาพในการทดสอบแบบฟัซเนื่องจากใช้ความครอบคลุมของบรรทัดของกรณีทดสอบก่อนหน้าเพื่อสร้างอินพุตแบบสุ่มใหม่ เช่น libFuzzer จะให้ความสำคัญกับกรณีทดสอบที่ทำงาน ในโค้ดบรรทัดใหม่ ซึ่งจะช่วยลดเวลาที่ใช้ในการทดสอบเพื่อค้นหาโค้ดที่มีปัญหาได้อย่างมาก
หากต้องการทำการทดสอบแบบฟัซเพื่อตรวจสอบการติดตั้งใช้งานไดรเวอร์ ให้แก้ไข
frameworks/ml/nn/runtime/test/android_fuzzing/DriverFuzzTest.cpp
ในlibneuralnetworks_driver_fuzzerยูทิลิตีการทดสอบที่พบใน AOSP เพื่อรวม
โค้ดไดรเวอร์ ดูข้อมูลเพิ่มเติมเกี่ยวกับการทดสอบแบบฟัซ NNAPI ได้ที่
frameworks/ml/nn/runtime/test/android_fuzzing/README.md
ความปลอดภัย
เนื่องจากกระบวนการของแอปสื่อสารกับกระบวนการของไดรเวอร์โดยตรง
ไดรเวอร์จึงต้องตรวจสอบอาร์กิวเมนต์ของการเรียกที่ได้รับ การตรวจสอบนี้
ได้รับการยืนยันโดย VTS รหัสการตรวจสอบคือ
frameworks/ml/nn/common/include/ValidateHal.h
นอกจากนี้ ผู้ขับขี่ควรตรวจสอบว่าแอปไม่สามารถรบกวนแอปอื่นๆ เมื่อใช้อุปกรณ์เดียวกัน
ชุดทดสอบแมชชีนเลิร์นนิงของ Android
ชุดทดสอบแมชชีนเลิร์นนิง (MLTS) ของ Android คือการทดสอบประสิทธิภาพ NNAPI ที่รวมอยู่ใน CTS และ VTS เพื่อตรวจสอบความถูกต้องของโมเดลจริงในอุปกรณ์ของผู้ให้บริการ การทดสอบประสิทธิภาพจะประเมินเวลาในการตอบสนองและความแม่นยำ และเปรียบเทียบผลลัพธ์ของไดรเวอร์กับ ผลลัพธ์ที่ใช้ TF Lite ที่ทำงานบน CPU สำหรับโมเดลและชุดข้อมูลเดียวกัน ซึ่งจะช่วยให้มั่นใจว่าความแม่นยำของไดรเวอร์จะไม่แย่กว่าการใช้งานอ้างอิงของ CPU
นักพัฒนาแพลตฟอร์ม Android ยังใช้ MLTS เพื่อประเมินเวลาในการตอบสนองและความแม่นยำ ของไดรเวอร์ด้วย
การทดสอบ NNAPI จะอยู่ใน 2 โปรเจ็กต์ใน AOSP ดังนี้
platform/test/mlts/benchmark(แอปทดสอบประสิทธิภาพ)platform/test/mlts/models(โมเดลและชุดข้อมูล)
โมเดลและชุดข้อมูล
การเปรียบเทียบ NNAPI ใช้โมเดลและชุดข้อมูลต่อไปนี้
- MobileNetV1 แบบ Float และแบบ Quantized u8 ในขนาดต่างๆ ทำงานกับ ชุดข้อมูลย่อยขนาดเล็ก (รูปภาพ 1, 500 รูป) ของชุดข้อมูล Open Images v4
- MobileNetV2 แบบ Float และแบบ Quantized u8 ในขนาดต่างๆ ทำงานกับ ชุดข้อมูลย่อยขนาดเล็ก (รูปภาพ 1, 500 รูป) ของชุดข้อมูล Open Images v4
- โมเดลเสียงที่อิงตามหน่วยความจำระยะสั้นแบบยาว (LSTM) สำหรับการแปลงข้อความเป็นคำพูด ทำงานกับชุดข้อมูล CMU Arctic กลุ่มย่อยขนาดเล็ก
- โมเดลเสียงที่อิงตาม LSTM สำหรับการรู้จำคำพูดอัตโนมัติ ซึ่งทำงานกับ ชุดข้อมูลย่อยขนาดเล็กของชุดข้อมูล LibriSpeech
ดูข้อมูลเพิ่มเติมได้ที่
platform/test/mlts/models
การทดสอบความเครียด
ชุดทดสอบแมชชีนเลิร์นนิงของ Android มีการทดสอบการขัดข้องหลายชุดเพื่อ ตรวจสอบความยืดหยุ่นของไดรเวอร์ภายใต้สภาวะการใช้งานหนักหรือในกรณี ที่พฤติกรรมของไคลเอ็นต์มีความซับซ้อน
การทดสอบการหยุดทำงานทั้งหมดมีฟีเจอร์ต่อไปนี้
- การตรวจหาการแฮงก์: หากไคลเอ็นต์ NNAPI แฮงก์ระหว่างการทดสอบ การทดสอบจะล้มเหลวโดยมีสาเหตุที่ทำให้ล้มเหลวเป็น
HANGและชุดการทดสอบจะ ย้ายไปที่การทดสอบถัดไป - การตรวจหาการขัดข้องของไคลเอ็นต์ NNAPI: การทดสอบจะยังคงทำงานได้แม้ว่าไคลเอ็นต์จะขัดข้อง และการทดสอบจะล้มเหลวพร้อมระบุสาเหตุที่ล้มเหลว
CRASH - การตรวจจับไดรเวอร์ขัดข้อง: การทดสอบสามารถตรวจจับไดรเวอร์ขัดข้อง
ที่ทำให้การเรียก NNAPI ล้มเหลว โปรดทราบว่าอาจเกิดข้อขัดข้องในกระบวนการของไดรเวอร์ซึ่งไม่ทำให้ NNAPI ล้มเหลวและไม่ทำให้การทดสอบล้มเหลว เราขอแนะนําให้เรียกใช้
tailในบันทึกของระบบเพื่อดูข้อผิดพลาดหรือข้อขัดข้องที่เกี่ยวข้องกับไดรเวอร์ เพื่อให้ครอบคลุมความล้มเหลวประเภทนี้ - การกำหนดเป้าหมายของ Accelerator ที่พร้อมใช้งานทั้งหมด: การทดสอบจะดำเนินการกับไดรเวอร์ที่พร้อมใช้งานทั้งหมด
การทดสอบการชนทั้งหมดมีผลลัพธ์ที่เป็นไปได้ 4 อย่างดังนี้
SUCCESS: ดำเนินการเสร็จสมบูรณ์โดยไม่มีข้อผิดพลาดFAILURE: ดำเนินการไม่สำเร็จ โดยปกติแล้วเกิดจากความล้มเหลวเมื่อ ทดสอบโมเดล ซึ่งบ่งชี้ว่าไดรเวอร์คอมไพล์หรือเรียกใช้ โมเดลไม่สำเร็จHANG: กระบวนการทดสอบไม่ตอบสนองCRASH: กระบวนการทดสอบขัดข้อง
ดูข้อมูลเพิ่มเติมเกี่ยวกับการทดสอบความเครียดและรายการการทดสอบการหยุดทำงานทั้งหมดได้ที่
platform/test/mlts/benchmark/README.txt
ใช้ MLTS
วิธีใช้ MLTS
- เชื่อมต่ออุปกรณ์เป้าหมายกับเวิร์กสเตชันและตรวจสอบว่าเข้าถึงได้ผ่าน adb
ส่งออกตัวแปรสภาพแวดล้อม
ANDROID_SERIALของอุปกรณ์เป้าหมายหากเชื่อมต่ออุปกรณ์มากกว่า 1 เครื่อง cdไปยังไดเรกทอรีแหล่งที่มาของ Android ระดับบนสุดsource build/envsetup.sh lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available. ./test/mlts/benchmark/build_and_run_benchmark.shเมื่อสิ้นสุดการทดสอบประสิทธิภาพ ระบบจะแสดงผลลัพธ์เป็นหน้า HTML และส่งไปยัง
xdg-open
ดูข้อมูลเพิ่มเติมได้ที่
platform/test/mlts/benchmark/README.txt
เวอร์ชัน HAL ของโครงข่ายประสาทเทียม
ส่วนนี้จะอธิบายการเปลี่ยนแปลงที่เกิดขึ้นใน Android และ HAL เวอร์ชันของ Neural Networks
Android 11
Android 11 เปิดตัว NN HAL 1.3 ซึ่งมีการเปลี่ยนแปลงที่สำคัญต่อไปนี้
- รองรับการหาปริมาณแบบ 8 บิตที่ลงนามใน NNAPI เพิ่มประเภทตัวถูกดำเนินการ
TENSOR_QUANT8_ASYMM_SIGNEDไดรเวอร์ที่มี NN HAL 1.3 ซึ่งรองรับ การดำเนินการที่มีการหาปริมาณที่ไม่ได้ลงนามต้องรองรับตัวแปรที่ลงนาม ของการดำเนินการเหล่านั้นด้วย เมื่อเรียกใช้การดำเนินการเชิงปริมาณส่วนใหญ่ทั้งเวอร์ชันที่มีและไม่มีการลงนาม ไดรเวอร์ต้องสร้างผลลัพธ์เดียวกันโดยมีออฟเซ็ตไม่เกิน 128 ข้อกำหนดนี้มีข้อยกเว้น 5 ประการ ได้แก่CAST,HASHTABLE_LOOKUP,LSH_PROJECTION,PAD_V2และQUANTIZED_16BIT_LSTMการดำเนินการQUANTIZED_16BIT_LSTMไม่รองรับตัวถูกดำเนินการที่มีการลงชื่อ และการดำเนินการอีก 4 รายการรองรับการหาปริมาณที่มีการลงชื่อ แต่ไม่จำเป็นต้องให้ผลลัพธ์เหมือนกัน - รองรับการดำเนินการที่จำกัดขอบเขตซึ่งเฟรมเวิร์กเรียกใช้เมธอด
IPreparedModel::executeFencedเพื่อเปิดใช้การดำเนินการแบบอะซิงโครนัสที่จำกัดขอบเขตในโมเดลที่เตรียมไว้พร้อมเวกเตอร์ของรั้วการซิงค์เพื่อรอ ดูข้อมูลเพิ่มเติมได้ที่ การดำเนินการแบบจำกัด - รองรับโฟลว์การควบคุม เพิ่มการดำเนินการ
IFและWHILEซึ่งใช้โมเดลอื่นๆ เป็นอาร์กิวเมนต์และดำเนินการตามเงื่อนไข (IF) หรือซ้ำๆ (WHILE) ดูข้อมูลเพิ่มเติมได้ที่โฟลว์การควบคุม - คุณภาพของบริการ (QoS) ที่ดีขึ้นเนื่องจากแอปสามารถระบุลำดับความสำคัญที่เกี่ยวข้องของโมเดล เวลาสูงสุดที่คาดไว้ในการเตรียมโมเดล และเวลาสูงสุดที่คาดไว้ในการดำเนินการให้เสร็จสมบูรณ์ ดูข้อมูลเพิ่มเติมได้ที่ คุณภาพของบริการ
- รองรับโดเมนหน่วยความจำที่จัดเตรียมอินเทอร์เฟซตัวจัดสรรสำหรับบัฟเฟอร์ที่ไดรเวอร์จัดการ ซึ่งช่วยให้ส่งหน่วยความจำดั้งเดิมของอุปกรณ์ ในการดำเนินการต่างๆ ได้ โดยจะระงับการคัดลอกและการแปลงข้อมูลที่ไม่จำเป็น ระหว่างการดำเนินการที่ต่อเนื่องกันในไดรเวอร์เดียวกัน ดูข้อมูลเพิ่มเติมได้ที่โดเมนหน่วยความจำ
Android 10
Android 10 เปิดตัว NN HAL 1.2 ซึ่งมีการเปลี่ยนแปลงที่สำคัญต่อไปนี้
Capabilitiesstruct มีประเภทข้อมูลทั้งหมด รวมถึงประเภทข้อมูลสเกลาร์ และแสดงประสิทธิภาพที่ไม่ผ่อนปรนโดยใช้เวกเตอร์แทน ฟิลด์ที่มีชื่อ- เมธอด
getVersionStringและgetTypeช่วยให้เฟรมเวิร์กสามารถ เรียกข้อมูลประเภทอุปกรณ์ (DeviceType) และเวอร์ชัน ดูการค้นหาและการกำหนดอุปกรณ์ - ระบบจะเรียกใช้เมธอด
executeSynchronouslyโดยค่าเริ่มต้นเพื่อดำเนินการ การเรียกใช้แบบพร้อมกัน เมธอดexecute_1_2จะบอกให้เฟรมเวิร์ก ดำเนินการแบบไม่พร้อมกัน ดูการดำเนินการ - พารามิเตอร์
MeasureTimingไปยังexecuteSynchronously,execute_1_2และการดำเนินการแบบกลุ่มจะระบุว่าไดรเวอร์จะวัดระยะเวลาการดำเนินการหรือไม่ ระบบจะรายงานผลลัพธ์ในTimingดูเวลา - รองรับการดำเนินการที่ตัวถูกดำเนินการเอาต์พุตอย่างน้อย 1 รายการมีมิติข้อมูลหรืออันดับที่ไม่รู้จัก ดูรูปร่างเอาต์พุต
- การรองรับส่วนขยายของผู้ให้บริการ ซึ่งเป็นคอลเล็กชันของ
การดำเนินการและประเภทข้อมูลที่ผู้ให้บริการกำหนด ไดรเวอร์รายงานส่วนขยายที่รองรับผ่านเมธอด
IDevice::getSupportedExtensionsดูส่วนขยายของผู้ให้บริการ - ความสามารถของออบเจ็กต์การประมวลผลแบบกลุ่มในการควบคุมชุดการประมวลผลแบบกลุ่มโดยใช้ คิวข้อความด่วน (FMQ) เพื่อสื่อสารระหว่างกระบวนการของแอปและไดรเวอร์ ซึ่งจะช่วยลดเวลาในการตอบสนอง ดูการดำเนินการแบบกลุ่มและคิวข้อความที่รวดเร็ว
- รองรับ AHardwareBuffer เพื่อให้ไดรเวอร์ดำเนินการได้ โดยไม่ต้องคัดลอกข้อมูล ดู AHardwareBuffer
- ปรับปรุงการรองรับการแคชอาร์ติแฟกต์การคอมไพล์เพื่อลดเวลาที่ใช้ในการคอมไพล์เมื่อแอปเริ่มต้น ดู การแคชการคอมไพล์
Android 10 มีตัวถูกดำเนินการและ การดำเนินการต่อไปนี้
-
ANEURALNETWORKS_BOOLANEURALNETWORKS_FLOAT16ANEURALNETWORKS_TENSOR_BOOL8ANEURALNETWORKS_TENSOR_FLOAT16ANEURALNETWORKS_TENSOR_QUANT16_ASYMMANEURALNETWORKS_TENSOR_QUANT16_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL
-
ANEURALNETWORKS_ABSANEURALNETWORKS_ARGMAXANEURALNETWORKS_ARGMINANEURALNETWORKS_AXIS_ALIGNED_BBOX_TRANSFORMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_RNNANEURALNETWORKS_BOX_WITH_NMS_LIMITANEURALNETWORKS_CASTANEURALNETWORKS_CHANNEL_SHUFFLEANEURALNETWORKS_DETECTION_POSTPROCESSINGANEURALNETWORKS_EQUALANEURALNETWORKS_EXPANEURALNETWORKS_EXPAND_DIMSANEURALNETWORKS_GATHERANEURALNETWORKS_GENERATE_PROPOSALSANEURALNETWORKS_GREATERANEURALNETWORKS_GREATER_EQUALANEURALNETWORKS_GROUPED_CONV_2DANEURALNETWORKS_HEATMAP_MAX_KEYPOINTANEURALNETWORKS_INSTANCE_NORMALIZATIONANEURALNETWORKS_LESSANEURALNETWORKS_LESS_EQUALANEURALNETWORKS_LOGANEURALNETWORKS_LOGICAL_ANDANEURALNETWORKS_LOGICAL_NOTANEURALNETWORKS_LOGICAL_ORANEURALNETWORKS_LOG_SOFTMAXANEURALNETWORKS_MAXIMUMANEURALNETWORKS_MINIMUMANEURALNETWORKS_NEGANEURALNETWORKS_NOT_EQUALANEURALNETWORKS_PAD_V2ANEURALNETWORKS_POWANEURALNETWORKS_PRELUANEURALNETWORKS_QUANTIZEANEURALNETWORKS_QUANTIZED_16BIT_LSTMANEURALNETWORKS_RANDOM_MULTINOMIALANEURALNETWORKS_REDUCE_ALLANEURALNETWORKS_REDUCE_ANYANEURALNETWORKS_REDUCE_MAXANEURALNETWORKS_REDUCE_MINANEURALNETWORKS_REDUCE_PRODANEURALNETWORKS_REDUCE_SUMANEURALNETWORKS_RESIZE_NEAREST_NEIGHBORANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_ROI_POOLINGANEURALNETWORKS_RSQRTANEURALNETWORKS_SELECTANEURALNETWORKS_SINANEURALNETWORKS_SLICEANEURALNETWORKS_SPLITANEURALNETWORKS_SQRTANEURALNETWORKS_TILEANEURALNETWORKS_TOPK_V2ANEURALNETWORKS_TRANSPOSE_CONV_2DANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_RNN
Android 10 มีการอัปเดตการดำเนินการที่มีอยู่หลายอย่าง การอัปเดตส่วนใหญ่เกี่ยวข้องกับสิ่งต่อไปนี้
- รองรับเลย์เอาต์หน่วยความจำ NCHW
- รองรับเทนเซอร์ที่มีอันดับต่างจาก 4 ในการดำเนินการ Softmax และ การดำเนินการ Normalization
- รองรับการบิดเบือน
- รองรับอินพุตที่มีการหาปริมาณแบบผสมใน
ANEURALNETWORKS_CONCATENATION
รายการด้านล่างแสดงการดำเนินการที่ได้รับการแก้ไขใน Android 10 ดูรายละเอียดทั้งหมดของการเปลี่ยนแปลงได้ที่ OperationCode ในเอกสารอ้างอิง NNAPI
ANEURALNETWORKS_ADDANEURALNETWORKS_AVERAGE_POOL_2DANEURALNETWORKS_BATCH_TO_SPACE_NDANEURALNETWORKS_CONCATENATIONANEURALNETWORKS_CONV_2DANEURALNETWORKS_DEPTHWISE_CONV_2DANEURALNETWORKS_DEPTH_TO_SPACEANEURALNETWORKS_DEQUANTIZEANEURALNETWORKS_DIVANEURALNETWORKS_FLOORANEURALNETWORKS_FULLY_CONNECTEDANEURALNETWORKS_L2_NORMALIZATIONANEURALNETWORKS_L2_POOL_2DANEURALNETWORKS_LOCAL_RESPONSE_NORMALIZATIONANEURALNETWORKS_LOGISTICANEURALNETWORKS_LSH_PROJECTIONANEURALNETWORKS_LSTMANEURALNETWORKS_MAX_POOL_2DANEURALNETWORKS_MEANANEURALNETWORKS_MULANEURALNETWORKS_PADANEURALNETWORKS_RELUANEURALNETWORKS_RELU1ANEURALNETWORKS_RELU6ANEURALNETWORKS_RESHAPEANEURALNETWORKS_RESIZE_BILINEARANEURALNETWORKS_RNNANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_SOFTMAXANEURALNETWORKS_SPACE_TO_BATCH_NDANEURALNETWORKS_SPACE_TO_DEPTHANEURALNETWORKS_SQUEEZEANEURALNETWORKS_STRIDED_SLICEANEURALNETWORKS_SUBANEURALNETWORKS_SVDFANEURALNETWORKS_TANHANEURALNETWORKS_TRANSPOSE
Android 9
มีการเปิดตัว NN HAL 1.1 ใน Android 9 และมีการเปลี่ยนแปลงที่สำคัญดังต่อไปนี้
IDevice::prepareModel_1_1มีพารามิเตอร์ExecutionPreferenceไดรเวอร์สามารถใช้ข้อมูลนี้เพื่อปรับการเตรียมการ โดยทราบว่า แอปต้องการประหยัดแบตเตอรี่หรือจะเรียกใช้โมเดล ในการเรียกที่ต่อเนื่องกันอย่างรวดเร็ว- เราได้เพิ่มการดำเนินการใหม่ 9 รายการ ได้แก่
BATCH_TO_SPACE_ND,DIV,MEAN,PAD,SPACE_TO_BATCH_ND,SQUEEZE,STRIDED_SLICE,SUB,TRANSPOSE - แอปสามารถระบุว่าการคำนวณแบบ Float 32 บิตสามารถเรียกใช้ได้
โดยใช้ช่วงและ/หรือความแม่นยำแบบ Float 16 บิตโดยการตั้งค่า
Model.relaxComputationFloat32toFloat16เป็นtrueCapabilitiesโครงสร้างมีฟิลด์เพิ่มเติมrelaxedFloat32toFloat16Performanceเพื่อ ให้ไดรเวอร์รายงานประสิทธิภาพที่ผ่อนคลายไปยังเฟรมเวิร์กได้
Android 8.1
HAL โครงข่ายประสาทเทียม (1.0) เวอร์ชันแรกเปิดตัวใน Android 8.1 ดูข้อมูลเพิ่มเติมได้ที่
/neuralnetworks/1.0/