
Android 8.0 include test delle prestazioni di binder e hwbinder per throughput e latenza. Sebbene esistano molti scenari per rilevare problemi di prestazioni percepibili, l'esecuzione di questi scenari può richiedere molto tempo e i risultati spesso non sono disponibili fino a dopo l'integrazione di un sistema. L'utilizzo dei test di prestazioni forniti semplifica i test durante lo sviluppo, consente di rilevare in anticipo i problemi gravi e migliora l'esperienza utente.
I test di rendimento includono le seguenti quattro categorie:
- throughput del binder (disponibile in
system/libhwbinder/vts/performance/Benchmark_binder.cpp) - Latenza binder (disponibile in
frameworks/native/libs/binder/tests/schd-dbg.cpp) - Throughput hwbinder (disponibile in
system/libhwbinder/vts/performance/Benchmark.cpp) - hwbinder latency (disponibile in
system/libhwbinder/vts/performance/Latency.cpp)
Informazioni su binder e hwbinder
Binder e hwbinder sono infrastrutture di comunicazione interprocessuale (IPC) Android che condividono lo stesso driver Linux, ma presentano le seguenti differenze qualitative:
| Aspetto | rilegatura | hwbinder |
|---|---|---|
| Finalità | Fornire uno schema IPC generico per il framework | Comunicare con l'hardware |
| Proprietà | Ottimizzato per l'utilizzo del framework Android | Latenza minima con overhead ridotto |
| Modificare il criterio di pianificazione per primo piano/sfondo | Sì | No |
| Trasmissione degli argomenti | Utilizza la serializzazione supportata dall'oggetto Parcel | Utilizza buffer di dispersione ed evita il sovraccarico per copiare i dati richiesti per la serializzazione dei pacchetti |
| Eredità della priorità | No | Sì |
Processi Binder e hwbinder
Un visualizzatore di systrace mostra le transazioni come segue:
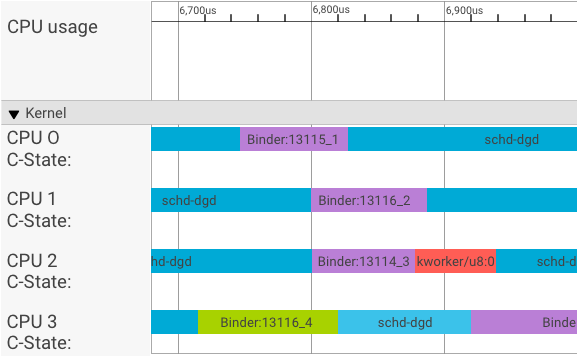
Nell'esempio riportato sopra:
- I quattro (4) processi schd-dbg sono processi client.
- I quattro (4) processi di Binder sono processi del server (il nome inizia con Binder e termina con un numero di sequenza).
- Un processo client è sempre accoppiato a un processo server dedicato al client.
- Tutte le coppie di processi client-server vengono pianificate in modo indipendente dal kernel contemporaneamente.
Nella CPU 1, il kernel del sistema operativo esegue il client per inviare la richiesta. Poi, se possibile, utilizza la stessa CPU per riattivare un processo del server, gestire la richiesta e tornare alla precedente commutazione di contesto al termine della richiesta.
Velocità effettiva e latenza
In una transazione perfetta, in cui il processo del client e del server passa senza problemi, i test di throughput e latenza non producono messaggi sostanzialmente diversi. Tuttavia, quando il kernel del sistema operativo gestisce una richiesta di interruzione (IRQ) dall'hardware, è in attesa di blocchi o semplicemente sceglie di non gestire un messaggio immediatamente, può formarsi una bolla di latenza.
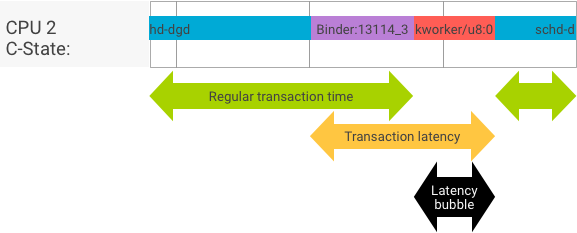
Il test di throughput genera un numero elevato di transazioni con dimensioni del payload diverse, fornendo una buona stima del tempo di transazione regolare (nei scenari migliori) e della velocità effettiva massima che il binder può raggiungere.
Al contrario, il test di latenza non esegue alcuna azione sul payload per ridurre al minimo il tempo di transazione regolare. Possiamo utilizzare il tempo di transazione per stimare il sovraccarico del binder, generare statistiche per il caso peggiore e calcolare il rapporto tra le transazioni la cui latenza soddisfa una scadenza specificata.
Gestire le inversioni di priorità
Un'inversione della priorità si verifica quando un thread con priorità più elevata è in attesa di un thread con priorità inferiore. Le applicazioni in tempo reale (RT) hanno un problema di inversione della priorità:
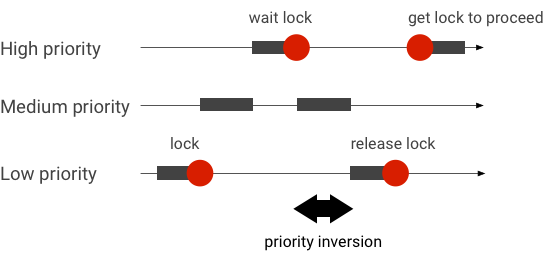
Quando utilizzi la pianificazione completamente equo (CFS) di Linux, un thread ha sempre la possibilità di essere eseguito anche quando altri thread hanno una priorità più alta. Di conseguenza, le applicazioni con pianificazione CFS gestiscono l'inversione della priorità come comportamento previsto e non come un problema. Tuttavia, nei casi in cui il framework Android abbia bisogno della pianificazione RT per garantire il privilegio dei thread ad alta priorità, l'inversione della priorità deve essere risolta.
Esempio di inversione della priorità durante una transazione di Binder (il thread RT è bloccato logicamente da altri thread CFS in attesa del servizio di un thread Binder):
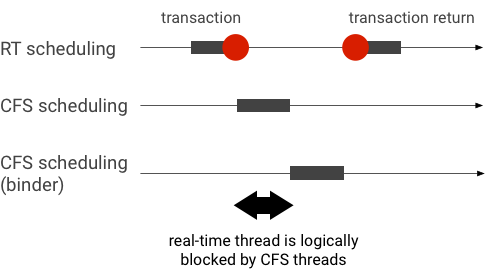
Per evitare blocchi, puoi utilizzare l'eredità della priorità per eseguire temporaneamente la riassegnazione del thread Binder a un thread RT quando gestisce una richiesta da un client RT. Tieni presente che la pianificazione RT ha risorse limitate e deve essere utilizzata con attenzione. In un sistema con n CPU, il numero massimo di thread RT correnti è anche n; altri thread RT potrebbero dover attendere (e quindi saltare le scadenze) se tutte le CPU sono occupate da altri thread RT.
Per risolvere tutte le possibili inversioni di priorità, puoi utilizzare l'eredità della priorità sia per binder che per hwbinder. Tuttavia, poiché Binder è ampiamente utilizzato nel sistema, l'attivazione dell'eredità della priorità per le transazioni di Binder potrebbe inviare spam al sistema con più thread RT di quelli che può gestire.
Esegui test di throughput
Il test di throughput viene eseguito in base al throughput delle transazioni binder/hwbinder. In un sistema non sovraccaricato, le bolle di latenza sono rare e il loro impatto può essere eliminato purché il numero di iterazioni sia sufficientemente elevato.
- Il test della velocità effettiva del binder è in
system/libhwbinder/vts/performance/Benchmark_binder.cpp. - Il test della velocità effettiva di hwbinder è in
system/libhwbinder/vts/performance/Benchmark.cpp.
Risultati del test
Esempi di risultati del test di throughput per le transazioni che utilizzano dimensioni del payload diverse:
Benchmark Time CPU Iterations --------------------------------------------------------------------- BM_sendVec_binderize/4 70302 ns 32820 ns 21054 BM_sendVec_binderize/8 69974 ns 32700 ns 21296 BM_sendVec_binderize/16 70079 ns 32750 ns 21365 BM_sendVec_binderize/32 69907 ns 32686 ns 21310 BM_sendVec_binderize/64 70338 ns 32810 ns 21398 BM_sendVec_binderize/128 70012 ns 32768 ns 21377 BM_sendVec_binderize/256 69836 ns 32740 ns 21329 BM_sendVec_binderize/512 69986 ns 32830 ns 21296 BM_sendVec_binderize/1024 69714 ns 32757 ns 21319 BM_sendVec_binderize/2k 75002 ns 34520 ns 20305 BM_sendVec_binderize/4k 81955 ns 39116 ns 17895 BM_sendVec_binderize/8k 95316 ns 45710 ns 15350 BM_sendVec_binderize/16k 112751 ns 54417 ns 12679 BM_sendVec_binderize/32k 146642 ns 71339 ns 9901 BM_sendVec_binderize/64k 214796 ns 104665 ns 6495
- Tempo indica il ritardo di andata e ritorno misurato in tempo reale.
- CPU indica il tempo accumulato quando le CPU sono pianificate per il test.
- Iterazioni indica il numero di volte in cui è stata eseguita la funzione di test.
Ad esempio, per un payload di 8 byte:
BM_sendVec_binderize/8 69974 ns 32700 ns 21296
… la velocità effettiva massima che il binder può raggiungere viene calcolata come segue:
Velocità effettiva MASSIMA con un payload di 8 byte = (8 * 21296)/69974 ~= 2423 b/ns ~= 2268 Gb/s
Opzioni di test
Per ottenere i risultati in formato .json, esegui il test con l'argomento
--benchmark_format=json:
libhwbinder_benchmark --benchmark_format=json
{
"context": {
"date": "2017-05-17 08:32:47",
"num_cpus": 4,
"mhz_per_cpu": 19,
"cpu_scaling_enabled": true,
"library_build_type": "release"
},
"benchmarks": [
{
"name": "BM_sendVec_binderize/4",
"iterations": 32342,
"real_time": 47809,
"cpu_time": 21906,
"time_unit": "ns"
},
….
}Esegui test di latenza
Il test di latenza misura il tempo necessario al client per iniziare a inizializzare la transazione, passare al processo del server per la gestione e ricevere il risultato. Il test cerca anche comportamenti noti degli schedulatori errati che possono influire negativamente sulla latenza delle transazioni, ad esempio uno schedulatore che non supporta l'eredità della priorità o rispetta il flag di sincronizzazione.
- Il test della latenza del binder è in
frameworks/native/libs/binder/tests/schd-dbg.cpp. - Il test di latenza di hwbinder è in
system/libhwbinder/vts/performance/Latency.cpp.
Risultati del test
I risultati (in .json) mostrano le statistiche relative alla latenza media/migliore/peggiore e al numero di scadenze mancate.
Opzioni di test
I test di latenza accettano le seguenti opzioni:
| Comando | Descrizione |
|---|---|
-i value |
Specifica il numero di iterazioni. |
-pair value |
Specifica il numero di coppie di processi. |
-deadline_us 2500 |
Specifica la scadenza in USA. |
-v |
Visualizza un output dettagliato (di debug). |
-trace |
Interrompi la traccia al raggiungimento di una scadenza. |
Le sezioni seguenti descrivono in dettaglio ogni opzione, ne illustrano l'utilizzo e forniscono risultati di esempio.
Specifica le iterazioni
Esempio con un numero elevato di iterazioni e output dettagliato disattivato:
libhwbinder_latency -i 5000 -pair 3
{
"cfg":{"pair":3,"iterations":5000,"deadline_us":2500},
"P0":{"SYNC":"GOOD","S":9352,"I":10000,"R":0.9352,
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}
},
"P1":{"SYNC":"GOOD","S":9334,"I":10000,"R":0.9334,
"other_ms":{ "avg":0.19, "wst":2.9 , "bst":0.055, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":3.1 , "bst":0.066, "miss":1, "meetR":0.9998}
},
"P2":{"SYNC":"GOOD","S":9369,"I":10000,"R":0.9369,
"other_ms":{ "avg":0.19, "wst":4.8 , "bst":0.055, "miss":6, "meetR":0.9988},
"fifo_ms": { "avg":0.15, "wst":1.8 , "bst":0.067, "miss":0, "meetR":1}
},
"inheritance": "PASS"
}Questi risultati del test mostrano quanto segue:
"pair":3- Crea una coppia di client e server.
"iterations": 5000- Sono incluse 5000 iterazioni.
"deadline_us":2500- Scadenza: 2500 us (2,5 ms); la maggior parte delle transazioni dovrebbe soddisfare questo valore.
"I": 10000- Una singola esecuzione del test include due (2) transazioni:
- Una transazione con priorità normale (
CFS other) - Una transazione in base alla priorità in tempo reale (
RT-fifo)
- Una transazione con priorità normale (
"S": 9352- 9352 delle transazioni vengono sincronizzate nella stessa CPU.
"R": 0.9352- Indica il rapporto con cui il client e il server vengono sincronizzati nella stessa CPU.
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996}- Il caso medio (
avg), peggiore (wst) e migliore (bst) per tutte le transazioni emesse da un chiamante con priorità normale. Due transazionimissdopo la scadenza, con un rapporto di corrispondenza (meetR) pari a 0,9996. "fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}- Simili a
other_ms, ma per le transazioni emesse dal client con prioritàrt_fifo. È probabile (ma non obbligatorio) chefifo_msabbia un risultato migliore rispetto aother_ms, con valoriavgewstinferiori emeetRsuperiore (la differenza può essere ancora più significativa con il caricamento in background).
Nota:il carico in background può influire sul risultato del throughput e sulla tupla other_ms nel test di latenza. Solo il
fifo_ms potrebbe mostrare risultati simili, a condizione che il caricamento in background abbia
una priorità inferiore a RT-fifo.
Specifica i valori delle coppie
Ogni processo client è accoppiato a un processo server dedicato al client e ogni coppia può essere pianificata in modo indipendente su qualsiasi CPU. Tuttavia, la migrazione della CPU non deve avvenire durante una transazione, a condizione che il flag SYNC sia honor.
Assicurati che il sistema non sia sovraccarico. Sebbene sia prevista una latenza elevata in un sistema sovraccaricato, i risultati dei test per un sistema sovraccaricato non forniscono informazioni utili. Per testare un sistema con una pressione più elevata, utilizza -pair
#cpu-1 (o -pair #cpu con cautela). I test che utilizzano
-pair n con n > #cpu sovraccaricano il
sistema e generano informazioni inutili.
Specifica i valori della scadenza
Dopo aver eseguito test approfonditi sugli scenari utente (eseguendo il test di latenza su un prodotto qualificato), abbiamo stabilito che 2,5 ms è la scadenza da rispettare. Per le nuove applicazioni con requisiti più elevati (ad esempio 1000 foto/secondo), questo valore della scadenza cambierà.
Specifica un output dettagliato
L'utilizzo dell'opzione -v mostra un output dettagliato. Esempio:
libhwbinder_latency -i 1 -v-------------------------------------------------- service pid: 8674 tid: 8674 cpu: 1 SCHED_OTHER 0-------------------------------------------------- main pid: 8673 tid: 8673 cpu: 1 -------------------------------------------------- client pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0-------------------------------------------------- fifo-caller pid: 8677 tid: 8678 cpu: 0 SCHED_FIFO 99 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 ??? 99-------------------------------------------------- other-caller pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 SCHED_OTHER 0
- Il thread di servizio viene creato con una priorità
SCHED_OTHERed eseguito inCPU:1conpid 8674. - La prima transazione viene quindi avviata da un
fifo-caller. Per gestire questa transazione, hwbinder esegue l'upgrade della priorità del server (pid: 8674 tid: 8676) a 99 e lo contrassegna anche con una classe di pianificazione transitoria (stampata come???). Lo schedulatore quindi inserisce il processo del server inCPU:0per l'esecuzione e lo sincronizza con la stessa CPU del client. - L'autore della chiamata della seconda transazione ha una priorità
SCHED_OTHER. Il server esegue il downgrade e serve l'utente chiamante con prioritàSCHED_OTHER.
Utilizzare la traccia per il debug
Puoi specificare l'opzione -trace per eseguire il debug dei problemi di latenza. Se viene utilizzato, il test di latenza interrompe la registrazione del log traccia nel momento in cui viene rilevata una latenza elevata. Esempio:
atrace --async_start -b 8000 -c sched idle workq binder_driver sync freqlibhwbinder_latency -deadline_us 50000 -trace -i 50000 -pair 3deadline triggered: halt ∓ stop trace log:/sys/kernel/debug/tracing/trace
I seguenti componenti possono influire sulla latenza:
- Modalità di compilazione Android. La modalità Eng è in genere più lenta della modalità userdebug.
- Framework. In che modo il servizio del framework utilizza
ioctlper eseguire la configurazione del binder? - Driver del binder. Il driver supporta il blocco granulare? Contiene tutte le patch di ottimizzazione delle prestazioni?
- Versione del kernel. Migliore è la funzionalità in tempo reale del kernel, migliori saranno i risultati.
- Configurazione del kernel. La configurazione del kernel contiene configurazioni
DEBUGcomeDEBUG_PREEMPTeDEBUG_SPIN_LOCK? - Scheduler del kernel. Il kernel dispone di uno schedulatore Energy-Aware (EAS) o Heterogeneous Multi-Processing (HMP)? I driver del kernel (driver
cpu-freq, drivercpu-idle,cpu-hotpluge così via) influiscono sull'organizzatore?