
Android 8.0 มีการทดสอบประสิทธิภาพของ Binder และ hwbinder สำหรับอัตราการส่งผ่านข้อมูลและเวลาในการตอบสนอง แม้ว่าจะมีสถานการณ์ต่างๆ มากมายสําหรับการตรวจหาปัญหาด้านประสิทธิภาพที่สังเกตได้ แต่การเรียกใช้สถานการณ์ดังกล่าวอาจใช้เวลานานและมักไม่แสดงผลจนกว่าจะผสานรวมระบบแล้ว การใช้การทดสอบประสิทธิภาพที่มีให้จะช่วยให้ทดสอบระหว่างการพัฒนาได้ง่ายขึ้น ตรวจหาปัญหาร้ายแรงได้เร็วขึ้น และปรับปรุงประสบการณ์ของผู้ใช้
การทดสอบประสิทธิภาพมี 4 หมวดหมู่ ดังนี้
- อัตราการส่งข้อมูลของ Binder (พร้อมใช้งานใน
system/libhwbinder/vts/performance/Benchmark_binder.cpp) - เวลาในการตอบสนองของ Binder (พร้อมใช้งานใน
frameworks/native/libs/binder/tests/schd-dbg.cpp) - อัตราการส่งข้อมูล hwbinder (พร้อมใช้งานใน
system/libhwbinder/vts/performance/Benchmark.cpp) - hwbinder latency (พร้อมใช้งานใน
system/libhwbinder/vts/performance/Latency.cpp)
เกี่ยวกับ Binder และ hwbinder
Binder และ hwbinder เป็นโครงสร้างพื้นฐานการสื่อสารระหว่างกระบวนการ (IPC) ของ Android ที่ใช้ไดรเวอร์ Linux เดียวกัน แต่มีความแตกต่างกันในด้านคุณภาพดังนี้
| อัตราส่วน | แฟ้ม | hwbinder |
|---|---|---|
| วัตถุประสงค์ | ระบุรูปแบบ IPC ทั่วไปสำหรับเฟรมเวิร์ก | สื่อสารกับฮาร์ดแวร์ |
| พร็อพเพอร์ตี้ | เพิ่มประสิทธิภาพสำหรับการใช้งานเฟรมเวิร์ก Android | เวลาในการตอบสนองต่ำโดยมีค่าใช้จ่ายเพิ่มเติมขั้นต่ำ |
| เปลี่ยนนโยบายการกําหนดเวลาสําหรับเบื้องหน้า/เบื้องหลัง | ใช่ | ไม่ |
| การผ่านอาร์กิวเมนต์ | ใช้การทำให้เป็นอนุกรมที่ออบเจ็กต์ Parcel รองรับ | ใช้บัฟเฟอร์การกระจัดกระจายและหลีกเลี่ยงค่าใช้จ่ายเพิ่มเติมในการคัดลอกข้อมูลที่จำเป็นสำหรับการแปลงเป็นอนุกรมของ Parcel |
| การสืบทอดลําดับความสําคัญ | ไม่ | ใช่ |
กระบวนการ Binder และ hwbinder
เครื่องมือแสดงภาพ Systrace จะแสดงธุรกรรมดังนี้
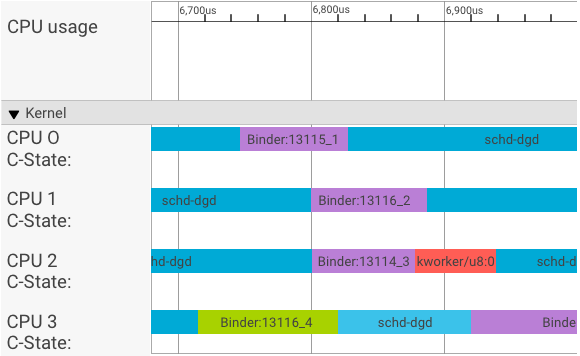
ในตัวอย่างด้านบน
- กระบวนการ schd-dbg 4 รายการเป็นกระบวนการไคลเอ็นต์
- กระบวนการ Binder 4 (4) รายการเป็นกระบวนการของเซิร์ฟเวอร์ (ชื่อขึ้นต้นด้วย Binder และลงท้ายด้วยหมายเลขลำดับ)
- กระบวนการของไคลเอ็นต์จะจับคู่กับกระบวนการของเซิร์ฟเวอร์เสมอ ซึ่งจะทํางานสําหรับไคลเอ็นต์โดยเฉพาะ
- เคอร์เนลจะกำหนดเวลาคู่กระบวนการไคลเอ็นต์-เซิร์ฟเวอร์ทั้งหมดให้ทำงานพร้อมกันโดยอิสระ
ใน CPU 1 เคอร์เนลระบบปฏิบัติการจะเรียกใช้ไคลเอ็นต์เพื่อส่งคำขอ จากนั้นจะใช้ CPU เดียวกันทุกครั้งที่เป็นไปได้เพื่อปลุกกระบวนการของเซิร์ฟเวอร์ จัดการคําขอ และเปลี่ยนบริบทกลับหลังจากคําขอเสร็จสมบูรณ์
อัตราการส่งข้อมูลเทียบกับเวลาในการตอบสนอง
ในการทําธุรกรรมที่สมบูรณ์แบบ ซึ่งไคลเอ็นต์และเซิร์ฟเวอร์ประมวลผลสลับไปมาอย่างราบรื่น การทดสอบแบนด์วิดท์และเวลาในการตอบสนองจะไม่แสดงข้อความที่แตกต่างกันมากนัก อย่างไรก็ตาม เมื่อเคอร์เนลระบบปฏิบัติการจัดการคําขอขัดจังหวะ (IRQ) จากฮาร์ดแวร์ รอการล็อก หรือเลือกที่จะไม่จัดการข้อความในทันที บับเบิลเวลาในการตอบสนองอาจเกิดขึ้น
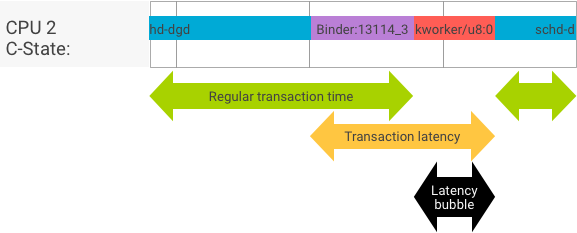
การทดสอบปริมาณงานจะสร้างธุรกรรมจํานวนมากที่มีขนาดเพย์โหลดแตกต่างกัน ซึ่งจะให้ค่าประมาณที่ดีสําหรับเวลาธุรกรรมปกติ (ในสถานการณ์ที่ดีที่สุด) และปริมาณงานสูงสุดที่เครื่องมือจัดเก็บข้อมูลบรรทัดแรกทำได้
ในทางตรงกันข้าม การทดสอบเวลาในการตอบสนองจะไม่ดําเนินการใดๆ กับเพย์โหลดเพื่อลดเวลาการทำธุรกรรมตามปกติ เราสามารถใช้เวลาธุรกรรมเพื่อประมาณค่าใช้จ่ายเพิ่มเติมของ Binder, สร้างสถิติสำหรับกรณีที่แย่ที่สุด และคำนวณอัตราส่วนของธุรกรรมที่เวลาในการตอบสนองตรงตามกำหนดเวลาที่ระบุ
จัดการการเปลี่ยนลําดับความสําคัญ
ปัญหาการกลับลําดับความสําคัญเกิดขึ้นเมื่อชุดข้อความที่มีลําดับความสําคัญสูงกว่ารอชุดข้อความที่มีลําดับความสําคัญต่ำกว่า แอปพลิเคชันแบบเรียลไทม์ (RT) มีปัญหาเกี่ยวกับลําดับความสําคัญดังนี้
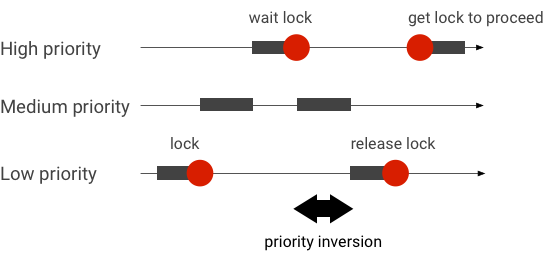
เมื่อใช้การจัดตารางเวลาของ Linux Completely Fair Scheduler (CFS) แต่ละเธรดจะมีโอกาสทำงานเสมอ แม้ว่าเธรดอื่นๆ จะมีลำดับความสำคัญสูงกว่าก็ตาม ด้วยเหตุนี้ แอปพลิเคชันที่มีการจัดตารางเวลา CFS จึงจัดการกับการกลับลำดับความสำคัญเป็นลักษณะการทำงานตามปกติ ไม่ใช่ปัญหา ในกรณีที่เฟรมเวิร์ก Android ต้องการการจัดตารางเวลา RT เพื่อรับประกันสิทธิ์ของเธรดที่มีลําดับความสําคัญสูง จะต้องแก้ไขการกลับลําดับความสําคัญ
ตัวอย่างการกลับลำดับความสำคัญระหว่างธุรกรรม Binder (เทรด RT ถูกบล็อกตามตรรกะโดยเทรด CFS อื่นๆ เมื่อรอให้เทรด Binder ให้บริการ)
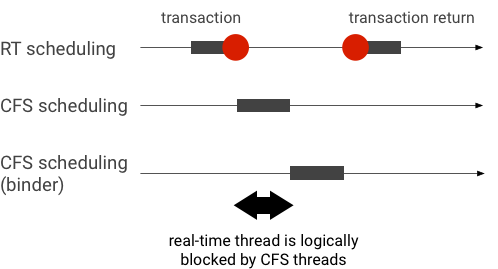
คุณสามารถใช้การสืบทอดลําดับความสําคัญเพื่อส่งต่อเธรด Binder ไปยังเธรด RT ชั่วคราวเมื่อให้บริการคําขอจากไคลเอ็นต์ RT เพื่อหลีกเลี่ยงการอุดตัน โปรดทราบว่าการกำหนดเวลา RT มีทรัพยากรจํากัดและควรใช้อย่างระมัดระวัง ในระบบที่มี CPU n ตัว จำนวนเทรด RT สูงสุดในปัจจุบันจะเป็น n เช่นกัน เทรด RT เพิ่มเติมอาจต้องรอ (และด้วยเหตุนี้จึงพลาดกำหนดเวลา) หากเทรด RT อื่นๆ ใช้ CPU ทั้งหมด
หากต้องการแก้ไขการกลับลำดับความสำคัญทั้งหมดที่เป็นไปได้ คุณสามารถใช้การสืบทอดลําดับความสําคัญสําหรับทั้ง Binder และ hwbinder อย่างไรก็ตาม เนื่องจาก Binder มีการใช้งานอย่างแพร่หลายในระบบ การเปิดใช้การรับค่าลำดับความสำคัญสำหรับธุรกรรม Binder อาจทำให้ระบบสแปมด้วยเธรด RT มากกว่าที่ระบบจะรองรับได้
ทำการทดสอบปริมาณข้อมูล
การทดสอบอัตราการรับส่งข้อมูลจะทํากับอัตราการรับส่งข้อมูลธุรกรรมของ Binder/hwbinder ในระบบที่ไม่ทำงานหนักเกินไป บับเบิลเวลาในการตอบสนองจะเกิดขึ้นได้น้อยมาก และผลกระทบของบับเบิลดังกล่าวจะลดลงได้ตราบใดที่จำนวนการทำซ้ำมีมากพอ
- การทดสอบปริมาณงาน binder อยู่ใน
system/libhwbinder/vts/performance/Benchmark_binder.cpp - การทดสอบปริมาณงาน hwbinder อยู่ใน
system/libhwbinder/vts/performance/Benchmark.cpp
ผลการทดสอบ
ตัวอย่างผลลัพธ์การทดสอบอัตราการรับส่งข้อมูลสำหรับธุรกรรมที่ใช้เพย์โหลดขนาดต่างๆ
Benchmark Time CPU Iterations --------------------------------------------------------------------- BM_sendVec_binderize/4 70302 ns 32820 ns 21054 BM_sendVec_binderize/8 69974 ns 32700 ns 21296 BM_sendVec_binderize/16 70079 ns 32750 ns 21365 BM_sendVec_binderize/32 69907 ns 32686 ns 21310 BM_sendVec_binderize/64 70338 ns 32810 ns 21398 BM_sendVec_binderize/128 70012 ns 32768 ns 21377 BM_sendVec_binderize/256 69836 ns 32740 ns 21329 BM_sendVec_binderize/512 69986 ns 32830 ns 21296 BM_sendVec_binderize/1024 69714 ns 32757 ns 21319 BM_sendVec_binderize/2k 75002 ns 34520 ns 20305 BM_sendVec_binderize/4k 81955 ns 39116 ns 17895 BM_sendVec_binderize/8k 95316 ns 45710 ns 15350 BM_sendVec_binderize/16k 112751 ns 54417 ns 12679 BM_sendVec_binderize/32k 146642 ns 71339 ns 9901 BM_sendVec_binderize/64k 214796 ns 104665 ns 6495
- เวลาแสดงเวลาหน่วงในการไปและกลับที่วัดแบบเรียลไทม์
- CPU แสดงเวลาสะสมเมื่อมีการกําหนดเวลา CPU สําหรับการทดสอบ
- จำนวนรอบระบุจํานวนครั้งที่เรียกใช้ฟังก์ชันทดสอบ
เช่น สำหรับเพย์โหลด 8 ไบต์
BM_sendVec_binderize/8 69974 ns 32700 ns 21296
… อัตราการส่งข้อมูลสูงสุดที่ Binder ทำได้จะคำนวณดังนี้
อัตรารับส่งข้อมูลสูงสุดที่มีเพย์โหลด 8 ไบต์ = (8 * 21296)/69974 ~= 2.423 b/ns ~= 2.268 Gb/s
ตัวเลือกการทดสอบ
หากต้องการดูผลลัพธ์ใน .json ให้เรียกใช้การทดสอบด้วยอาร์กิวเมนต์ --benchmark_format=json ดังนี้
libhwbinder_benchmark --benchmark_format=json
{
"context": {
"date": "2017-05-17 08:32:47",
"num_cpus": 4,
"mhz_per_cpu": 19,
"cpu_scaling_enabled": true,
"library_build_type": "release"
},
"benchmarks": [
{
"name": "BM_sendVec_binderize/4",
"iterations": 32342,
"real_time": 47809,
"cpu_time": 21906,
"time_unit": "ns"
},
….
}ทำการทดสอบเวลาในการตอบสนอง
การทดสอบเวลาในการตอบสนองจะวัดเวลาที่ไคลเอ็นต์เริ่มเริ่มต้นธุรกรรม เปลี่ยนไปใช้กระบวนการของเซิร์ฟเวอร์เพื่อจัดการ และรับผลลัพธ์ นอกจากนี้ การทดสอบยังมองหาลักษณะการทํางานที่ไม่ถูกต้องของเครื่องมือจัดตารางเวลาซึ่งอาจส่งผลเสียต่อเวลาในการตอบสนองของธุรกรรม เช่น เครื่องมือจัดตารางเวลาที่ไม่รองรับการสืบทอดลําดับความสําคัญหรือไม่สนใจการแจ้งว่าต้องซิงค์
- การทดสอบเวลาในการตอบสนองของ Binder อยู่ใน
frameworks/native/libs/binder/tests/schd-dbg.cpp - การทดสอบเวลาในการตอบสนองของ hwbinder อยู่ใน
system/libhwbinder/vts/performance/Latency.cpp
ผลการทดสอบ
ผลลัพธ์ (ในรูปแบบ .json) จะแสดงสถิติสำหรับเวลาในการตอบสนองโดยเฉลี่ย/ดีที่สุด/แย่ที่สุด และจำนวนกำหนดเวลาที่พลาด
ตัวเลือกการทดสอบ
การทดสอบเวลาในการตอบสนองใช้ตัวเลือกต่อไปนี้
| คำสั่ง | คำอธิบาย |
|---|---|
-i value |
ระบุจํานวนรอบ |
-pair value |
ระบุจํานวนคู่กระบวนการ |
-deadline_us 2500 |
ระบุกำหนดเวลาเป็นเขตเวลาสหรัฐอเมริกา |
-v |
รับเอาต์พุตแบบละเอียด (การแก้ไขข้อบกพร่อง) |
-trace |
หยุดการติดตามเมื่อถึงกำหนดเวลา |
ส่วนต่อไปนี้จะอธิบายตัวเลือกแต่ละรายการอย่างละเอียด อธิบายการใช้งาน และแสดงตัวอย่างผลลัพธ์
ระบุจำนวนรอบ
ตัวอย่างที่มีจำนวนรอบจำนวนมากและปิดใช้เอาต์พุตแบบละเอียด
libhwbinder_latency -i 5000 -pair 3
{
"cfg":{"pair":3,"iterations":5000,"deadline_us":2500},
"P0":{"SYNC":"GOOD","S":9352,"I":10000,"R":0.9352,
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}
},
"P1":{"SYNC":"GOOD","S":9334,"I":10000,"R":0.9334,
"other_ms":{ "avg":0.19, "wst":2.9 , "bst":0.055, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":3.1 , "bst":0.066, "miss":1, "meetR":0.9998}
},
"P2":{"SYNC":"GOOD","S":9369,"I":10000,"R":0.9369,
"other_ms":{ "avg":0.19, "wst":4.8 , "bst":0.055, "miss":6, "meetR":0.9988},
"fifo_ms": { "avg":0.15, "wst":1.8 , "bst":0.067, "miss":0, "meetR":1}
},
"inheritance": "PASS"
}ผลการทดสอบเหล่านี้แสดงข้อมูลต่อไปนี้
"pair":3- สร้างคู่ไคลเอ็นต์และเซิร์ฟเวอร์ 1 คู่
"iterations": 5000- รวม 5,000 รอบ
"deadline_us":2500- กำหนดเวลาคือ 2500us (2.5ms) โดยคาดว่าธุรกรรมส่วนใหญ่จะเป็นไปตามค่านี้
"I": 10000- การทดสอบซ้ำ 1 ครั้งประกอบด้วยธุรกรรม 2 รายการ ดังนี้
- ธุรกรรม 1 รายการตามลําดับความสําคัญปกติ (
CFS other) - ธุรกรรม 1 รายการตามลําดับความสําคัญแบบเรียลไทม์ (
RT-fifo)
- ธุรกรรม 1 รายการตามลําดับความสําคัญปกติ (
"S": 9352- ธุรกรรม 9352 รายการมีการซิงค์ใน CPU เดียวกัน
"R": 0.9352- ระบุอัตราส่วนการซิงค์ไคลเอ็นต์และเซิร์ฟเวอร์ใน CPU เดียวกัน
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996}- กรณีเฉลี่ย (
avg) แย่ที่สุด (wst) และดีที่สุด (bst) สำหรับธุรกรรมทั้งหมดที่ออกโดยผู้เรียกที่มีลําดับความสําคัญปกติ ธุรกรรม 2 รายการmissกำหนดเวลา ทำให้อัตราส่วนการปฏิบัติตามข้อกำหนด (meetR) เท่ากับ 0.9996 "fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}- คล้ายกับ
other_msแต่สำหรับธุรกรรมที่ออกโดยไคลเอ็นต์ที่มีลำดับความสำคัญrt_fifoมีโอกาส (แต่ไม่จำเป็นต้องเป็นเช่นนั้น) ที่fifo_msจะให้ผลลัพธ์ดีกว่าother_msโดยมีค่าavgและwstต่ำกว่า และmeetRสูงกว่า (ความแตกต่างอาจยิ่งมีนัยสำคัญมากขึ้นเมื่อมีการโหลดในเบื้องหลัง)
หมายเหตุ: ภาระงานเบื้องหลังอาจส่งผลต่อผลลัพธ์ของอัตราการส่งผ่านข้อมูลและทูเปิล other_ms ในการทดสอบเวลาในการตอบสนอง เฉพาะ fifo_ms เท่านั้นที่อาจแสดงผลลัพธ์ที่คล้ายกัน ตราบใดที่การโหลดในเบื้องหลังมีลําดับความสําคัญต่ำกว่า RT-fifo
ระบุค่าคู่
กระบวนการของไคลเอ็นต์แต่ละรายการจะจับคู่กับกระบวนการของเซิร์ฟเวอร์สำหรับไคลเอ็นต์โดยเฉพาะ และแต่ละคู่อาจได้รับการกำหนดเวลาให้ทำงานบน CPU ใดก็ได้แยกกัน อย่างไรก็ตาม การย้ายข้อมูล CPU ไม่ควรเกิดขึ้นในระหว่างธุรกรรม ตราบใดที่ Flag SYNC เป็นhonor
ตรวจสอบว่าระบบไม่ได้ทำงานหนักมากจนเกินไป แม้ว่าระบบที่มีภาระงานสูงจะมีความล่าช้าสูง แต่ผลการทดสอบระบบที่มีภาระงานสูงจะไม่ให้ข้อมูลที่เป็นประโยชน์ หากต้องการทดสอบระบบที่มีแรงดันสูงกว่า ให้ใช้ -pair
#cpu-1 (หรือ -pair #cpu ด้วยความระมัดระวัง) การทดสอบโดยใช้ -pair n กับ n > #cpu จะทําให้ระบบทำงานหนักและสร้างข้อมูลที่ไร้ประโยชน์
ระบุค่ากำหนดเวลา
หลังจากการทดสอบสถานการณ์การใช้งานอย่างละเอียด (การทดสอบเวลาในการตอบสนองในผลิตภัณฑ์ที่ผ่านการรับรอง) เราพิจารณาแล้วว่า 2.5 มิลลิวินาทีคือกำหนดเวลาที่ต้องทำให้ได้ สำหรับแอปพลิเคชันใหม่ที่มีข้อกำหนดที่สูงขึ้น (เช่น รูปภาพ 1,000 ภาพ/วินาที) ค่ากำหนดเวลานี้จะเปลี่ยนแปลง
ระบุเอาต์พุตแบบละเอียด
การใช้ตัวเลือก -v จะแสดงผลลัพธ์แบบละเอียด ตัวอย่าง
libhwbinder_latency -i 1 -v-------------------------------------------------- service pid: 8674 tid: 8674 cpu: 1 SCHED_OTHER 0-------------------------------------------------- main pid: 8673 tid: 8673 cpu: 1 -------------------------------------------------- client pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0-------------------------------------------------- fifo-caller pid: 8677 tid: 8678 cpu: 0 SCHED_FIFO 99 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 ??? 99-------------------------------------------------- other-caller pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 SCHED_OTHER 0
- ระบบจะสร้างเธรดบริการที่มีลําดับความสําคัญ
SCHED_OTHERและทํางานในCPU:1ด้วยpid 8674 - จากนั้น ธุรกรรมแรกจะเริ่มต้นโดย
fifo-callerหากต้องการให้บริการธุรกรรมนี้ hwbinder จะอัปเกรดลำดับความสำคัญของเซิร์ฟเวอร์ (pid: 8674 tid: 8676) เป็น 99 และทําเครื่องหมายด้วยคลาสการจัดตารางเวลาชั่วคราว (แสดงเป็น???) จากนั้นตัวจัดตารางเวลาจะใส่กระบวนการของเซิร์ฟเวอร์ในCPU:0เพื่อเรียกใช้และซิงค์กับ CPU เดียวกันกับไคลเอ็นต์ - ผู้เรียกธุรกรรมที่ 2 มีลําดับความสําคัญ
SCHED_OTHERเซิร์ฟเวอร์จะดาวน์เกรดตัวเองและให้บริการผู้โทรที่มีลําดับความสําคัญSCHED_OTHER
ใช้การติดตามเพื่อแก้ไขข้อบกพร่อง
คุณสามารถระบุตัวเลือก -trace เพื่อแก้ไขข้อบกพร่องเกี่ยวกับเวลาในการตอบสนอง เมื่อใช้ การทดสอบเวลาในการตอบสนองจะหยุดการบันทึกบันทึกการติดตามทันทีที่ตรวจพบเวลาในการตอบสนองที่ไม่ดี ตัวอย่าง
atrace --async_start -b 8000 -c sched idle workq binder_driver sync freqlibhwbinder_latency -deadline_us 50000 -trace -i 50000 -pair 3deadline triggered: halt ∓ stop trace log:/sys/kernel/debug/tracing/trace
คอมโพเนนต์ต่อไปนี้อาจส่งผลต่อเวลาในการตอบสนอง
- โหมดการสร้าง Android โดยปกติแล้ว โหมด Eng จะช้ากว่าโหมด userdebug
- เฟรมเวิร์ก บริการเฟรมเวิร์กใช้
ioctlเพื่อกำหนดค่าให้กับ Binder อย่างไร - โปรแกรมควบคุม Binder ไดร์เวอร์รองรับการล็อกแบบละเอียดไหม มีแพตช์ทั้งหมดที่ปรับปรุงประสิทธิภาพหรือไม่
- เวอร์ชันเคอร์เนล ยิ่งเคอร์เนลทำงานแบบเรียลไทม์ได้ดีเท่าใด ผลลัพธ์ก็จะยิ่งดีขึ้นเท่านั้น
- การกำหนดค่าเคอร์เนล การกําหนดค่าเคอร์เนลมีการกำหนดค่า
DEBUGหรือไม่ เช่นDEBUG_PREEMPTและDEBUG_SPIN_LOCK - เครื่องจัดตารางเวลาเคอร์เนล เคอร์เนลมีตัวจัดตารางเวลาแบบประหยัดพลังงาน (EAS) หรือแบบประมวลผลแบบหลายประเภท (HMP) ไหม ไดรเวอร์เคอร์เนล (
cpu-freqdriver,cpu-idledriver,cpu-hotplugฯลฯ) ส่งผลต่อตัวจัดตารางเวลาไหม