
systrace to główne narzędzie do analizowania wydajności urządzeń z Androidem. Jest to jednak w rzeczywistości tylko nakładka na inne narzędzia. Jest to otoka po stronie hosta wokół narzędzia atrace, czyli wykonywalnego pliku po stronie urządzenia, który kontroluje śledzenie przestrzeni użytkownika i konfiguruje ftrace, czyli główny mechanizm śledzenia w jądrze systemu Linux. systrace używa narzędzia atrace do włączania śledzenia, a następnie odczytuje bufor ftrace i umieszcza wszystko w samodzielnej przeglądarce HTML. (Nowsze jądra obsługują rozszerzony filtr pakietów Berkeley (eBPF) w systemie Linux, ale ta strona dotyczy jądra 3.18 (bez eBPF), ponieważ było ono używane na urządzeniach Pixel i Pixel XL).
Narzędzie systrace jest własnością zespołów Google Android i Google Chrome i jest dostępne jako open source w ramach projektu Catapult. Oprócz narzędzia systrace Catapult zawiera inne przydatne narzędzia. Na przykład narzędzie ftrace ma więcej funkcji niż te, które można bezpośrednio włączyć za pomocą narzędzi systrace lub atrace, i zawiera zaawansowane funkcje, które są niezbędne do debugowania problemów z wydajnością. (Te funkcje wymagają dostępu do roota i często nowego jądra).
Uruchamianie narzędzia systrace
Podczas debugowania drgań na Pixelu lub Pixelu XL zacznij od tego polecenia:
./systrace.py sched freq idle am wm gfx view sync binder_driver irq workq input -b 96000
W połączeniu z dodatkowymi punktami śledzenia wymaganymi w przypadku aktywności potoku GPU i wyświetlania umożliwia to śledzenie od danych wejściowych użytkownika do klatki wyświetlanej na ekranie. Ustaw duży rozmiar bufora, aby uniknąć utraty zdarzeń (ponieważ bez dużego bufora niektóre procesory nie zawierają zdarzeń po pewnym momencie śledzenia).
Podczas analizowania śladu systemowego pamiętaj, że każde zdarzenie jest wywoływane przez coś na procesorze.
Systrace jest oparty na ftrace, a ftrace działa na procesorze, więc to procesor musi zapisywać bufor ftrace, który rejestruje zmiany sprzętowe. Oznacza to, że jeśli chcesz się dowiedzieć, dlaczego stan ogrodzenia wyświetlania się zmienił, możesz sprawdzić, co było uruchomione na procesorze w momencie przejścia (coś uruchomionego na procesorze spowodowało tę zmianę w logu). Ta koncepcja jest podstawą analizowania wydajności za pomocą narzędzia systrace.
Przykład: rama robocza
Ten przykład opisuje śledzenie systemowe w przypadku normalnego potoku interfejsu. Aby śledzić przykład, pobierz plik ZIP ze śladami (zawiera on też inne ślady, o których mowa w tej sekcji), rozpakuj go i otwórz plik systrace_tutorial.html w przeglądarce.
W przypadku spójnego, okresowego zadania, takiego jak TouchLatency, potok interfejsu użytkownika przebiega w tej kolejności:
- EventThread w SurfaceFlinger wybudza wątek interfejsu aplikacji, sygnalizując, że nadszedł czas na wyrenderowanie nowej klatki.
- Aplikacja renderuje klatkę w wątku interfejsu, wątku renderowania i zadaniach HWUI, korzystając z zasobów procesora i GPU. To większość limitu wykorzystanego na interfejs.
- Aplikacja wysyła wyrenderowaną ramkę do usługi SurfaceFlinger za pomocą mechanizmu Binder, a następnie usługa SurfaceFlinger przechodzi w stan uśpienia.
- Drugi wątek EventThread w SurfaceFlinger wybudza SurfaceFlinger, aby wywołać kompozycję i wyświetlić dane wyjściowe. Jeśli SurfaceFlinger stwierdzi, że nie ma nic do zrobienia, wraca do stanu uśpienia.
- SurfaceFlinger obsługuje kompozycję za pomocą kompozytora sprzętowego (HWC), kompozytora sprzętowego 2 (HWC2) lub GL. Kompozycja HWC i HWC2 jest szybsza i mniej energochłonna, ale ma ograniczenia w zależności od systemu na chipie (SoC). Zwykle zajmuje to od 4 do 6 ms, ale może się nakładać na krok 2, ponieważ aplikacje na Androida zawsze korzystają z potrójnego buforowania. (Aplikacje zawsze korzystają z potrójnego buforowania, ale w SurfaceFlinger może być tylko jedna oczekująca klatka, co sprawia, że wygląda to tak samo jak podwójne buforowanie).
- SurfaceFlinger wysyła ostateczne dane wyjściowe do wyświetlenia za pomocą sterownika dostawcy i wraca do stanu uśpienia, czekając na wybudzenie przez EventThread.
Oto przykład sekwencji klatek rozpoczynającej się od 15409 ms:
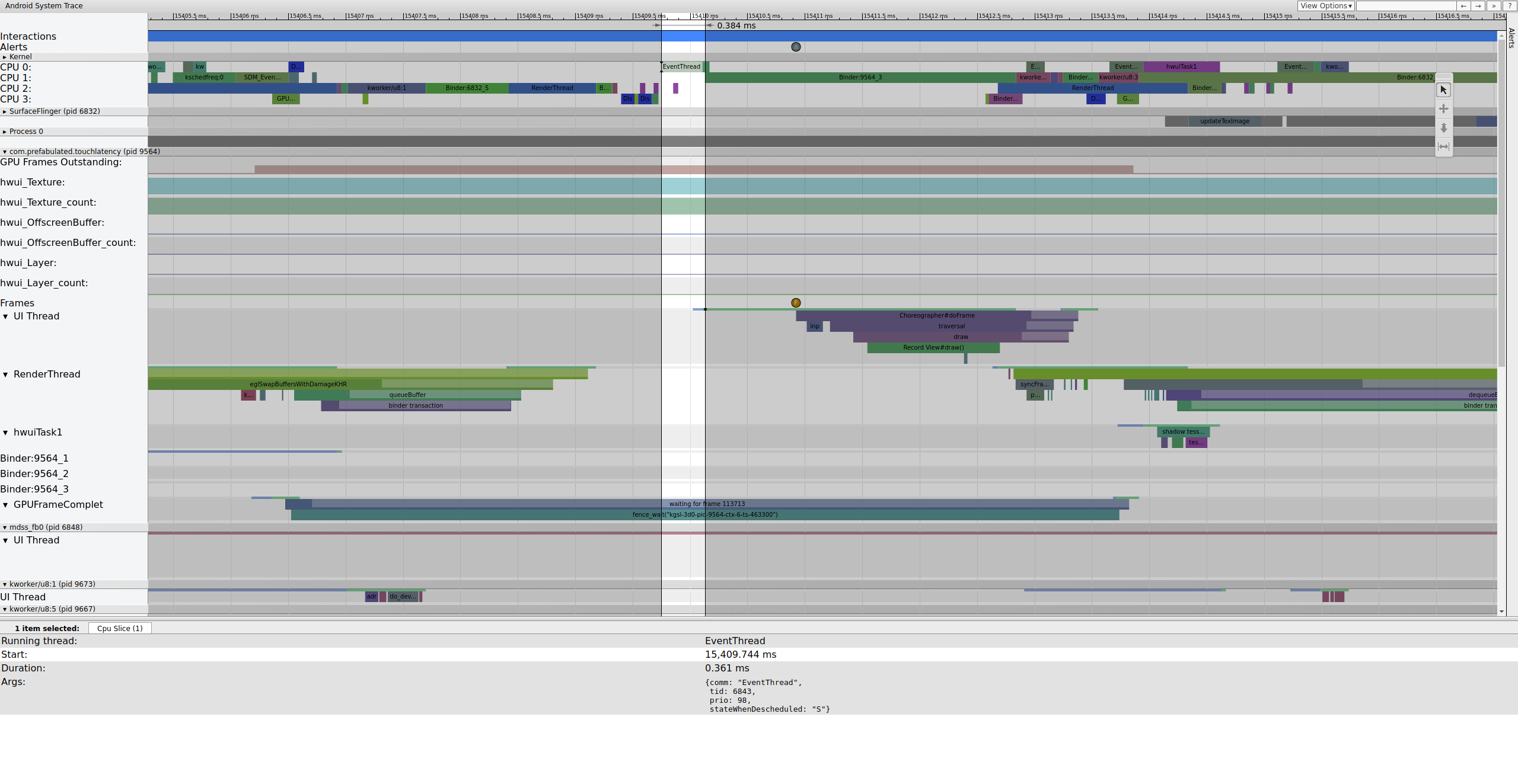
Rysunek 1. Normalny potok interfejsu, działający wątek zdarzeń.
Rysunek 1 to normalna ramka otoczona normalnymi ramkami, więc jest to dobry punkt wyjścia do zrozumienia, jak działa potok interfejsu. Wiersz wątku interfejsu TouchLatency zawiera różne kolory w różnych momentach. Paski oznaczają różne stany wątku:
- Szary Śpiący.
- Niebieski Możliwe do uruchomienia (może zostać uruchomione, ale harmonogram jeszcze go nie wybrał).
- Zielony Aktywnie działający (harmonogram uważa, że działa).
- Czerwony Nieprzerwany sen (zwykle sen w trybie blokady w jądrze). Może wskazywać obciążenie wejścia/wyjścia. Bardzo przydatne do debugowania problemów z wydajnością.
- Orange Nieprzerwany sen z powodu obciążenia wejścia/wyjścia.
Aby wyświetlić powód nieprzerwanego snu (dostępny w punkcie śledzenia sched_blocked_reason), wybierz czerwony wycinek nieprzerwanego snu.
Gdy EventThread jest uruchomiony, wątek interfejsu TouchLatency staje się wykonywalny. Aby sprawdzić, co spowodowało wybudzenie, kliknij niebieską sekcję.
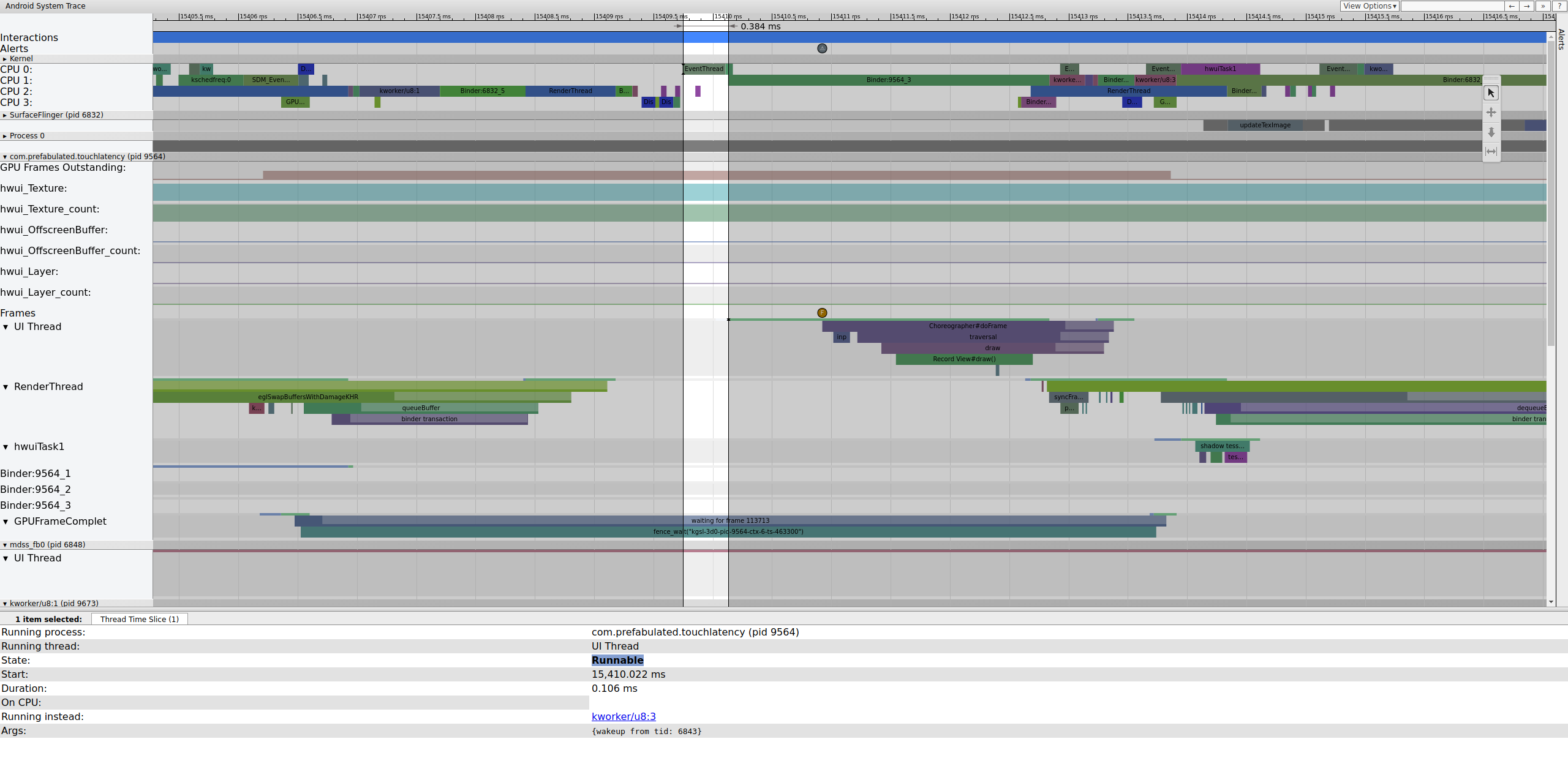
Rysunek 2. Wątek UI dla TouchLatency.
Rysunek 2 pokazuje, że wątek interfejsu TouchLatency został wybudzony przez identyfikator wątku 6843, który odpowiada wątkowi EventThread. Wątek interfejsu budzi się, renderuje klatkę i umieszcza ją w kolejce do wykorzystania przez SurfaceFlinger.
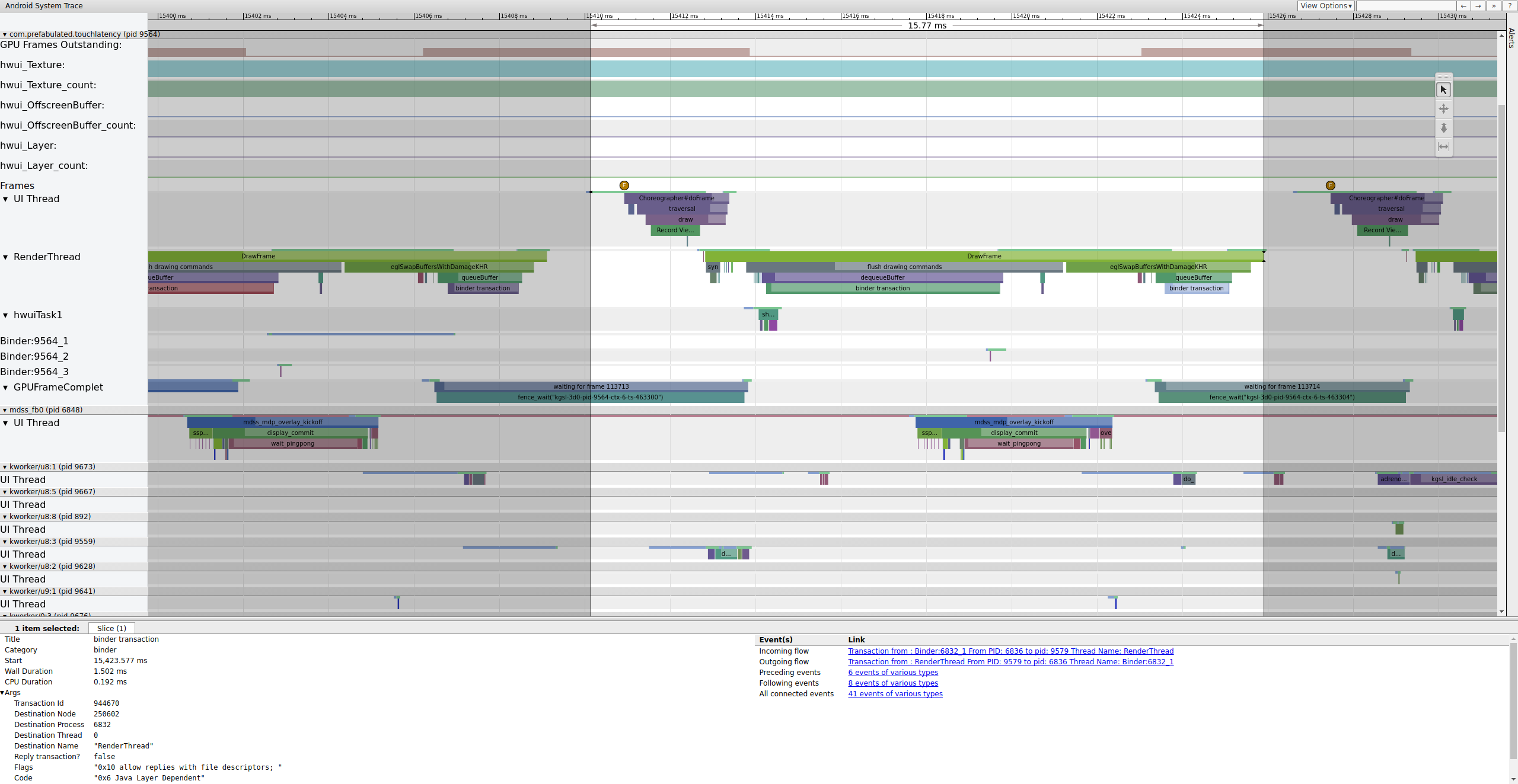
Rysunek 3. Wątek interfejsu budzi się, renderuje klatkę i umieszcza ją w kolejce do wykorzystania przez SurfaceFlinger.
Jeśli w śledzeniu jest włączony tag binder_driver, możesz wybrać transakcję bindera, aby wyświetlić informacje o wszystkich procesach w niej uczestniczących.

Rysunek 4. Transakcja wiążąca.
Rysunek 4 pokazuje, że przy 15 423,65 ms Binder:6832_1 w SurfaceFlinger staje się wykonywalny z powodu wątku 9579, czyli RenderThread w TouchLatency. Możesz też zobaczyć queueBuffer po obu stronach transakcji bindera.
Podczas wywołania queueBuffer po stronie SurfaceFlingera liczba oczekujących klatek z TouchLatency wzrasta z 1 do 2.
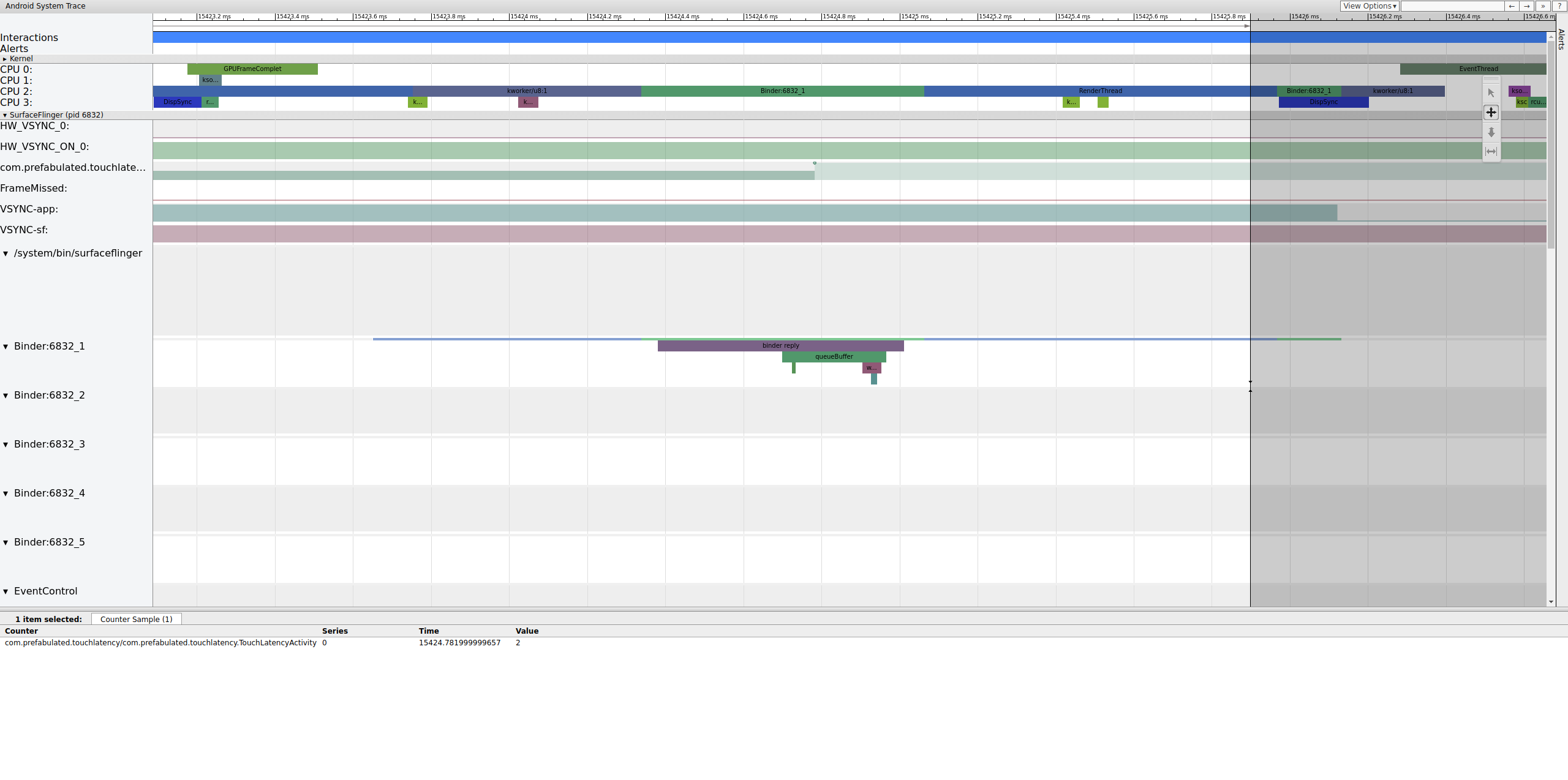
Rysunek 5. Oczekujące ramki mają wartości od 1 do 2.
Ilustracja 5 przedstawia potrójne buforowanie, w którym są 2 ukończone klatki, a aplikacja ma rozpocząć renderowanie trzeciej. Dzieje się tak, ponieważ niektóre klatki zostały już pominięte, więc aplikacja przechowuje 2 oczekujące klatki zamiast 1, aby uniknąć dalszego pomijania klatek.
Wkrótce potem wątek główny SurfaceFlingera jest wybudzany przez drugi wątek EventThread, aby mógł wyświetlić starszą oczekującą klatkę:
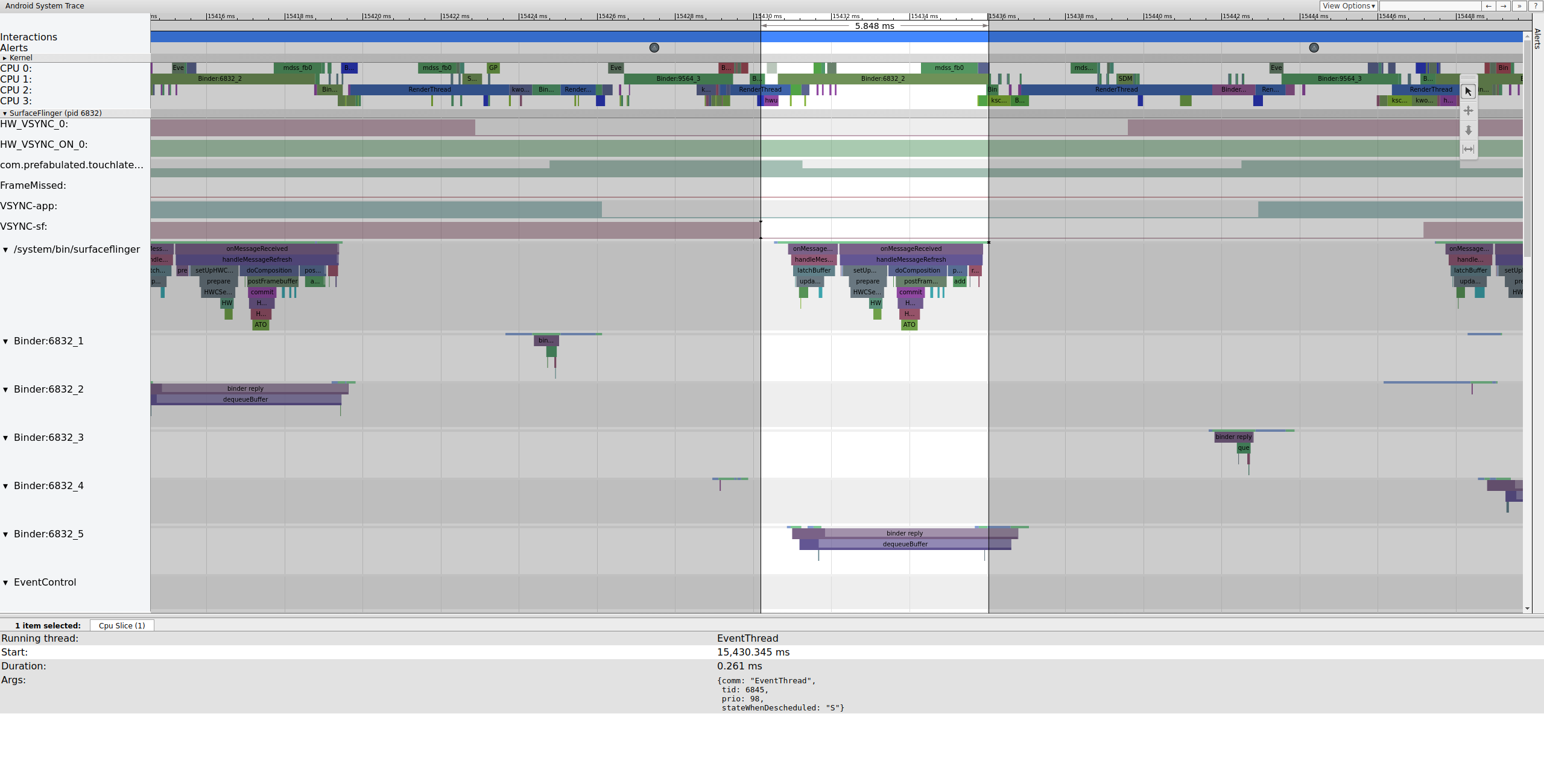
Rysunek 6. Główny wątek SurfaceFlingera jest wybudzany przez drugi wątek EventThread.
SurfaceFlinger najpierw zatrzaskuje starszy bufor oczekujący, co powoduje zmniejszenie liczby buforów oczekujących z 2 do 1:
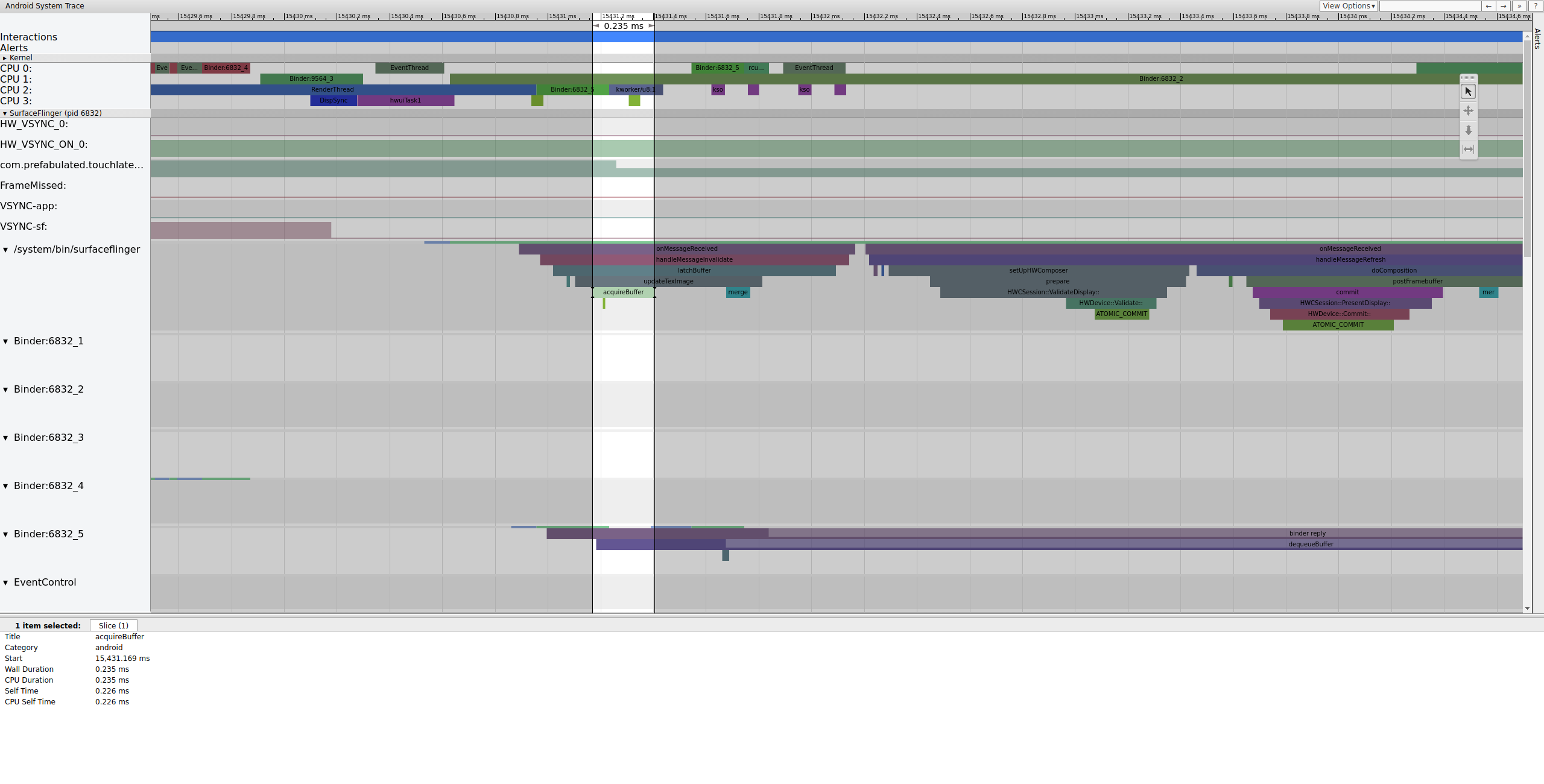
Rysunek 7. SurfaceFlinger najpierw blokuje starszy bufor oczekujący.
Po zatrzaśnięciu bufora SurfaceFlinger konfiguruje kompozycję i przesyła ostatnią klatkę do wyświetlacza. (Niektóre z tych sekcji są włączane w ramach mdsspunktu śledzenia, więc mogą nie być uwzględnione w Twoim układzie SoC).
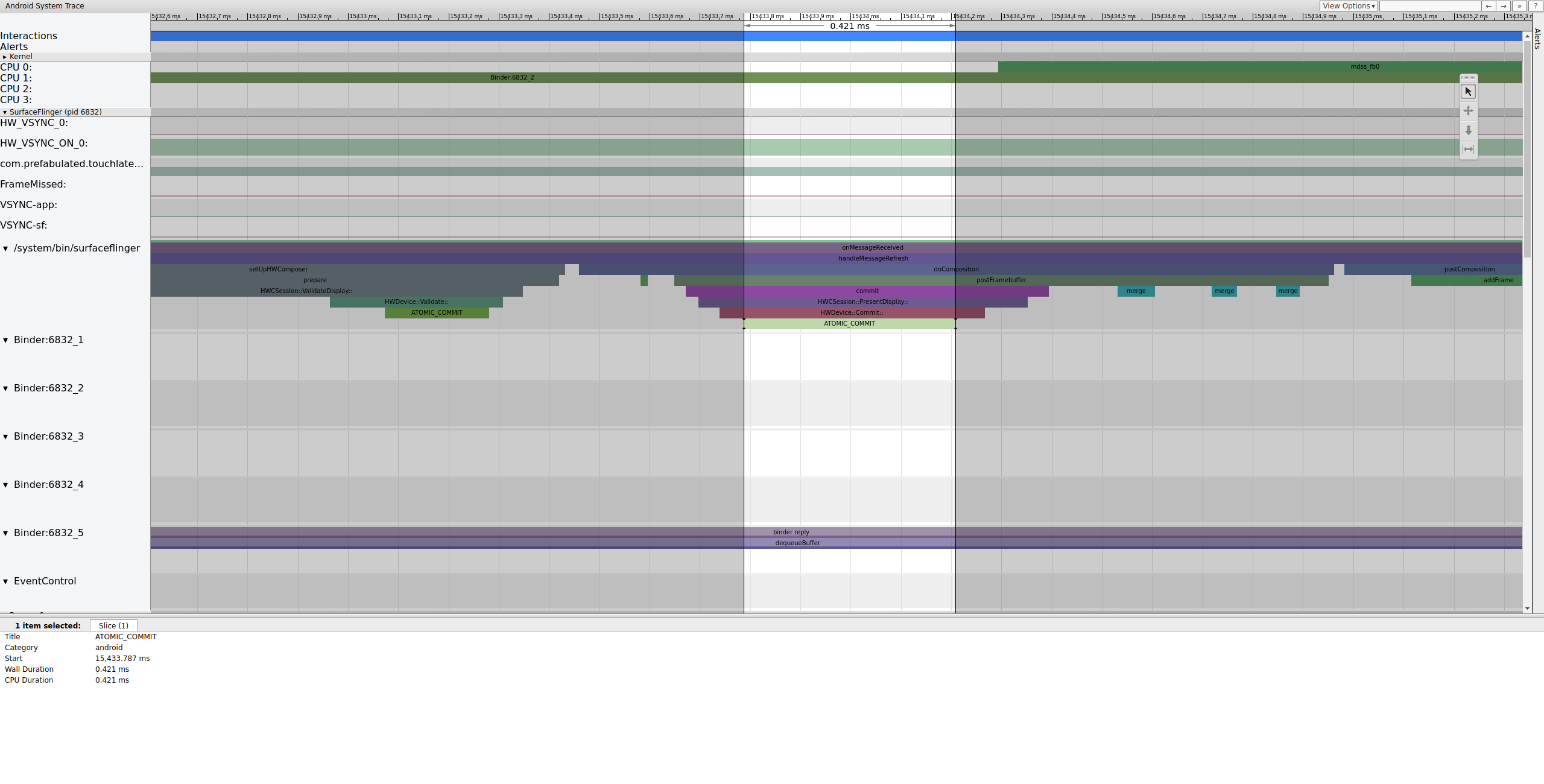
Rysunek 8. SurfaceFlinger konfiguruje kompozycję i przesyła klatkę końcową.
Następnie mdss_fb0 budzi się na procesorze 0. mdss_fb0 to wątek jądra potoku wyświetlania, który odpowiada za wyświetlanie wyrenderowanej klatki.
Zwróć uwagę, że pole mdss_fb0 jest osobnym wierszem w śladzie (przewiń w dół, aby wyświetlić):
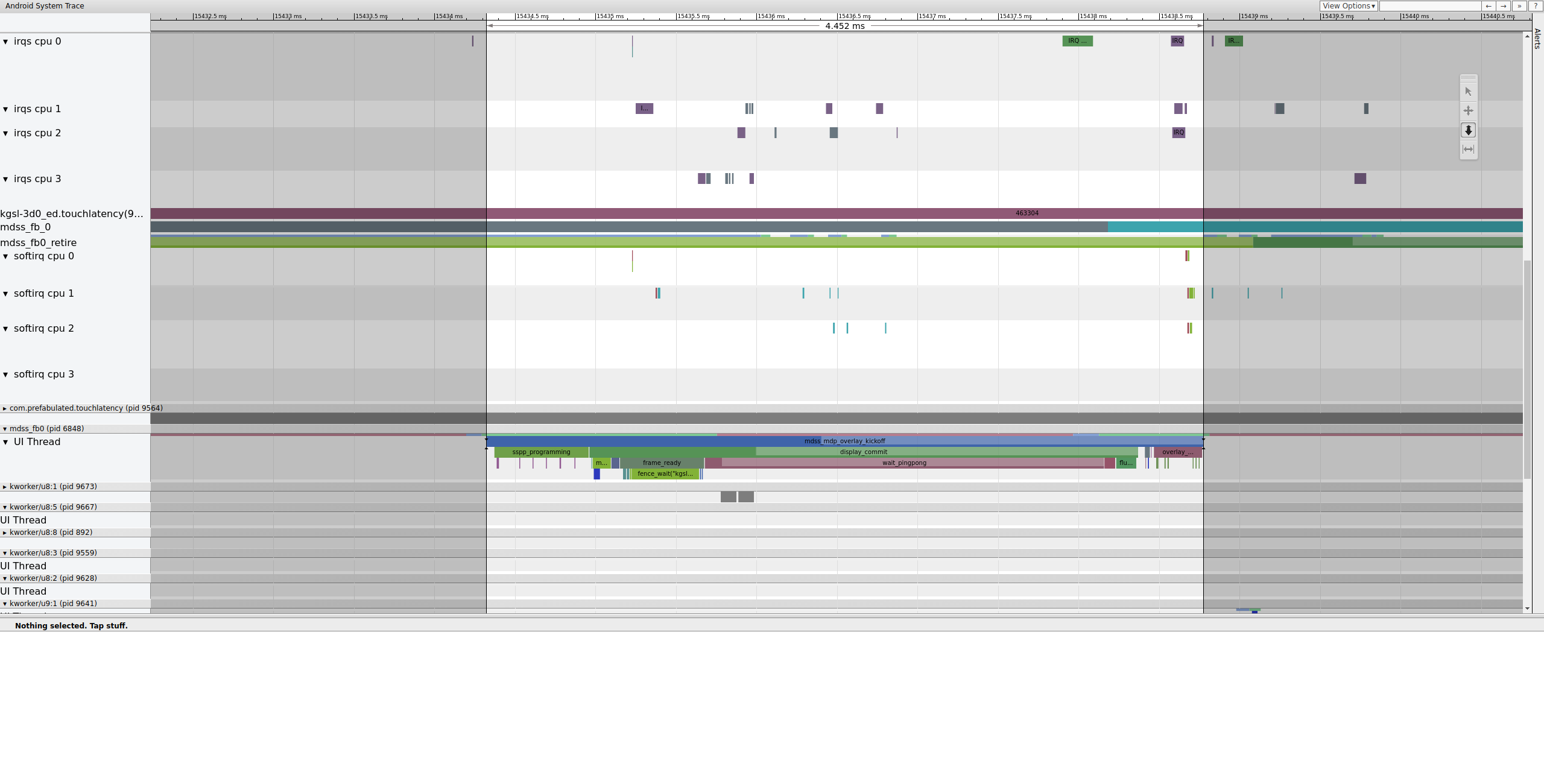
Ilustracja 9. mdss_fb0 wybudza procesor 0.
mdss_fb0 budzi się, krótko działa, przechodzi w stan nieprzerwanego uśpienia, a potem znów się budzi.
Przykład: nieużywana ramka
Ten przykład opisuje śledzenie systemowe używane do debugowania drgań na urządzeniach Pixel lub Pixel XL. Aby prześledzić przykład, pobierz plik ZIP ze śladami (który zawiera inne ślady, o których mowa w tej sekcji), rozpakuj go i otwórz plik systrace_tutorial.html w przeglądarce.
Po otwarciu śledzenia systemowego zobaczysz coś podobnego do tego:

Rysunek 10. Aplikacja TouchLatency uruchomiona na telefonie Pixel XL z włączoną większością opcji.
Na rysunku 10 większość opcji jest włączona, w tym punkty śledzenia mdss i kgsl.
Podczas wyszukiwania zacięć sprawdź wiersz FrameMissed w sekcji SurfaceFlinger.
FrameMissed to ulepszenie zwiększające komfort użytkowania, które zapewnia HWC2. Podczas wyświetlania śladu systemowego na innych urządzeniach wiersz FrameMissed może nie być widoczny, jeśli urządzenie nie korzysta z HWC2. W obu przypadkach zdarzenie FrameMissed jest skorelowane z tym, że SurfaceFlinger nie wykonał jednego z regularnych przebiegów, a liczba oczekujących buforów aplikacji (com.prefabulated.touchlatency) w momencie synchronizacji pionowej nie uległa zmianie.

Rysunek 11. Korelacja FrameMissed z SurfaceFlinger.
Na rysunku 11 widać pominiętą klatkę przy 15598,29 ms.SurfaceFlinger na krótko wybudził się w interwale VSync i ponownie przeszedł w stan uśpienia, nie wykonując żadnej pracy. Oznacza to, że SurfaceFlinger uznał, że nie warto ponownie wysyłać klatki na wyświetlacz.
Aby zrozumieć, dlaczego w przypadku tej klatki potok uległ awarii, najpierw zapoznaj się z przykładem działającej klatki powyżej, aby zobaczyć, jak normalny potok interfejsu użytkownika wygląda w systrace. Gdy to zrobisz, wróć do pominiętej klatki i cofnij się. Zwróć uwagę, że usługa SurfaceFlinger budzi się i natychmiast przechodzi w stan uśpienia. Gdy sprawdzasz liczbę oczekujących klatek w TouchLatency, widzisz 2 klatki (to dobra wskazówka, która pomaga określić, co się dzieje).
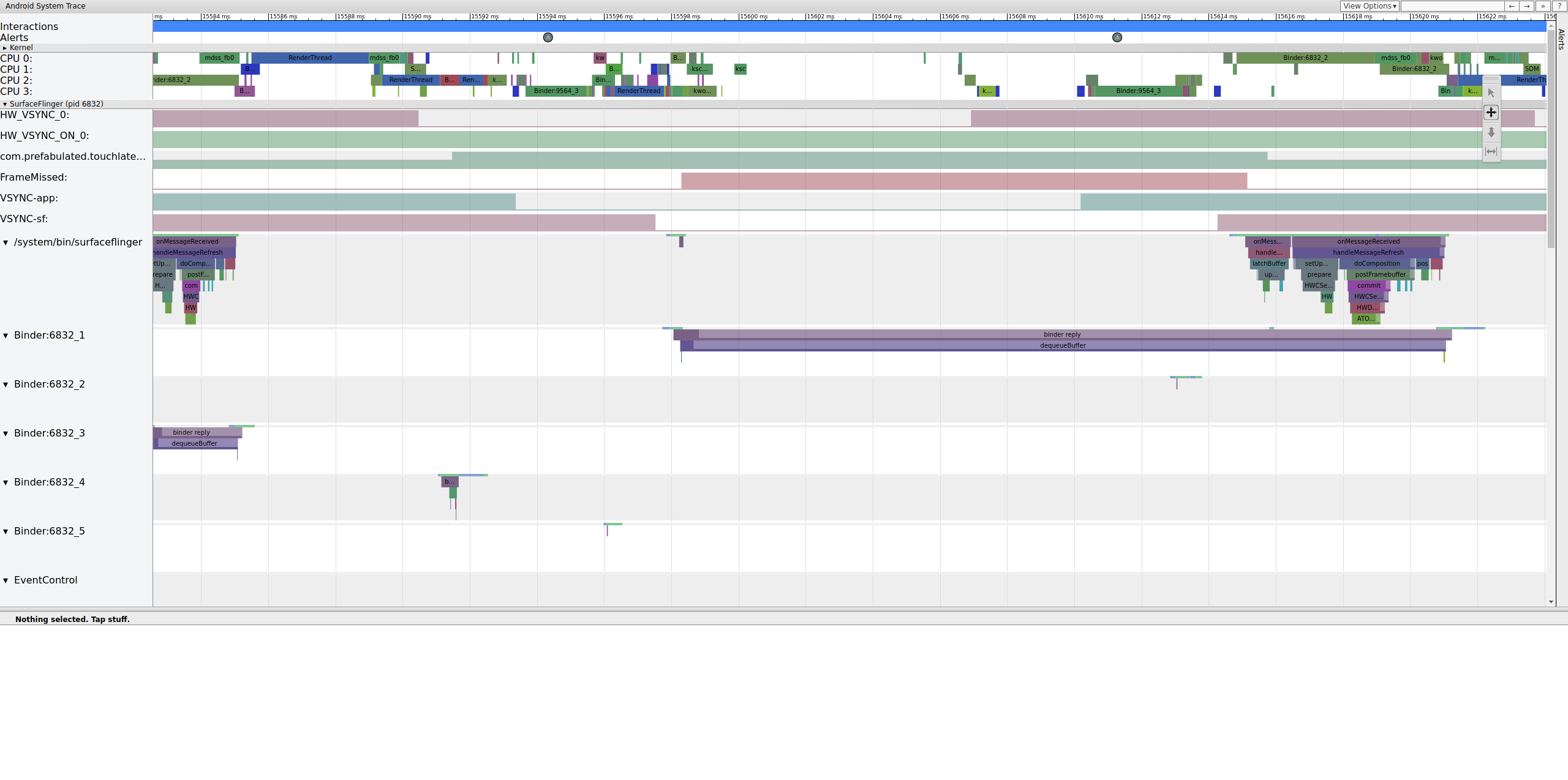
Rysunek 12. SurfaceFlinger budzi się i natychmiast zasypia.
Ponieważ w SurfaceFlinger występują klatki, nie jest to problem z aplikacją. Dodatkowo SurfaceFlinger wznawia działanie w odpowiednim czasie, więc problem nie dotyczy SurfaceFlingera. Jeśli zarówno SurfaceFlinger, jak i aplikacja wyglądają normalnie, prawdopodobnie problem dotyczy sterownika.
Ponieważ punkty śledzenia mdss i sync są włączone, możesz uzyskać informacje o barierkach (udostępnianych sterownikowi wyświetlacza i usłudze SurfaceFlinger), które kontrolują, kiedy klatki są przesyłane do wyświetlacza.
Te ramki są wymienione w sekcji mdss_fb0_retire, która oznacza, kiedy ramka jest wyświetlana. Te ogrodzenia są dostępne w ramach kategorii śladów sync. To, które bariery odpowiadają poszczególnym zdarzeniom w SurfaceFlingerze, zależy od układu SOC i stosu sterowników, więc skontaktuj się z dostawcą układu SOC, aby poznać znaczenie kategorii barier w śladach.
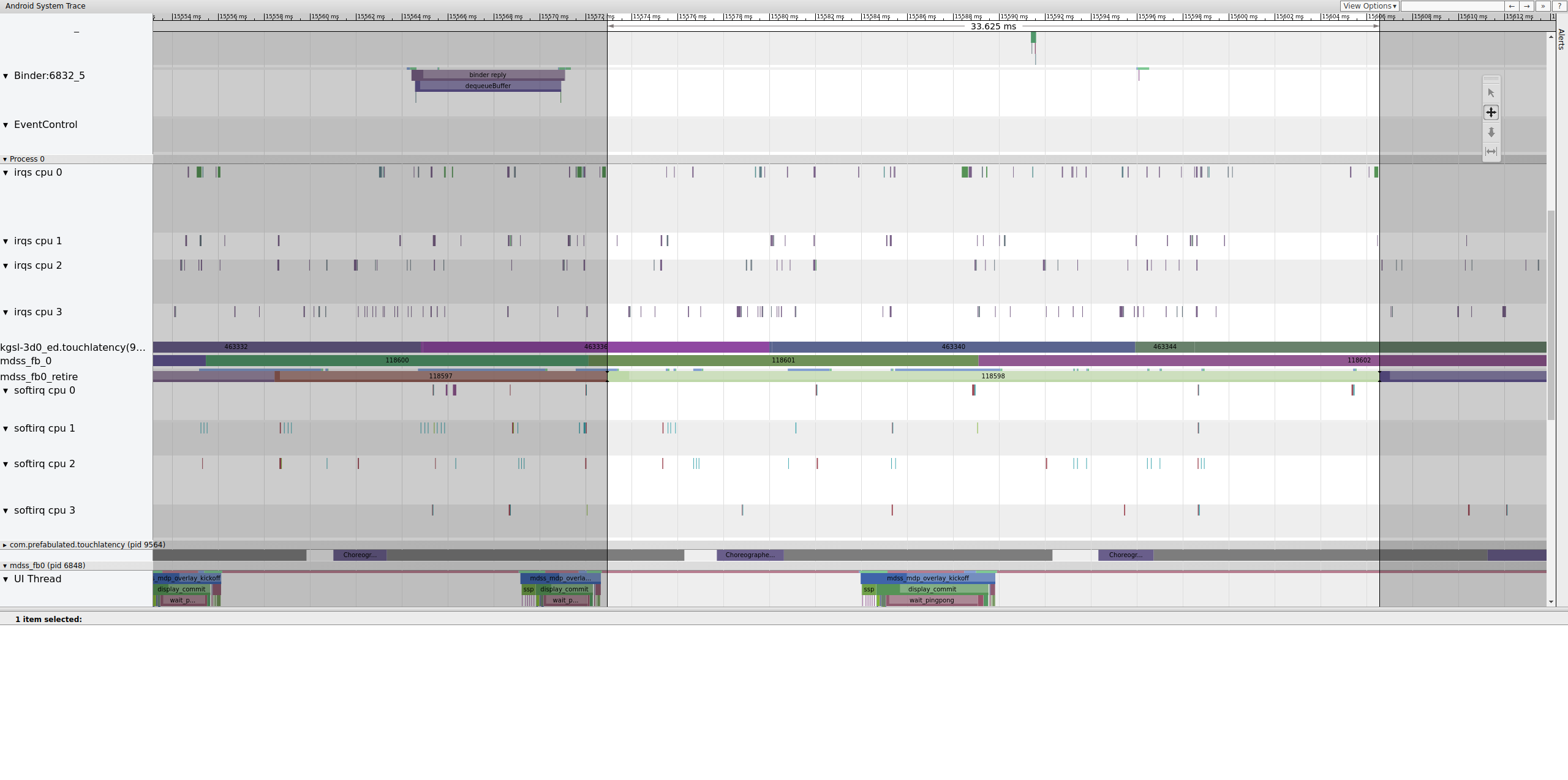
Ilustracja 13. mdss_fb0_retire fences.
Na rysunku 13 widać ramkę, która była wyświetlana przez 33 ms, a nie przez 16,7 ms, jak oczekiwano. W połowie tego wycinka ramka powinna zostać zastąpiona nową, ale tak się nie stało. Wyświetl poprzednią klatkę i poszukaj w niej czegoś.
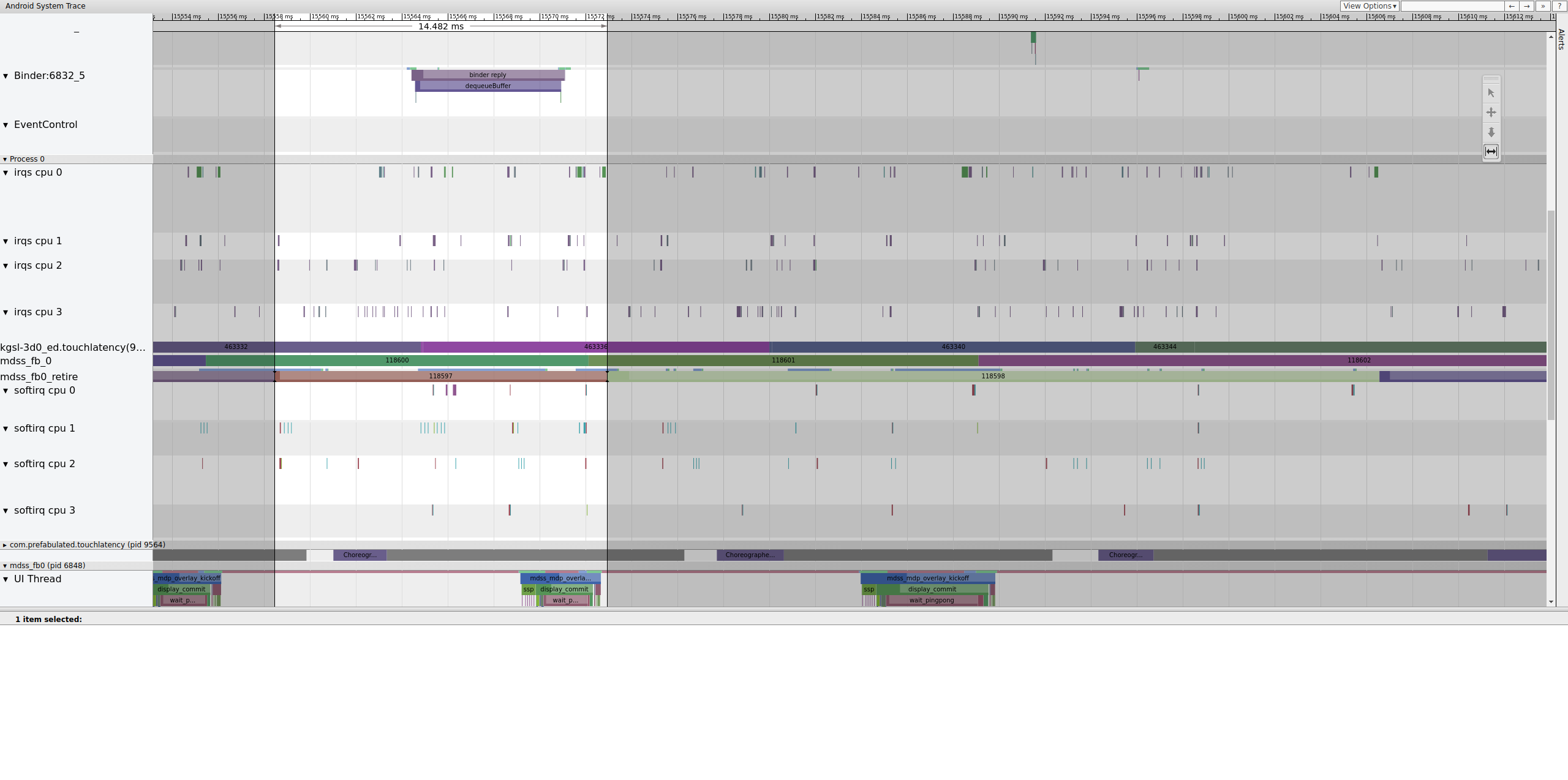
Rysunek 14. Klatka poprzedzająca uszkodzoną klatkę.
Rysunek 14 przedstawia klatkę o długości 14,482 ms. Uszkodzony segment składający się z 2 klatek trwał 33,6 ms, co jest wartością zbliżoną do oczekiwanej w przypadku 2 klatek (wyświetlanych z częstotliwością 60 Hz, 16,7 ms na klatkę). Jednak 14,482 ms nie jest bliskie 16,7 ms, co sugeruje, że coś jest nie tak z potokiem wyświetlania.
Sprawdź, gdzie dokładnie kończy się ten płot, aby określić, co go kontroluje:
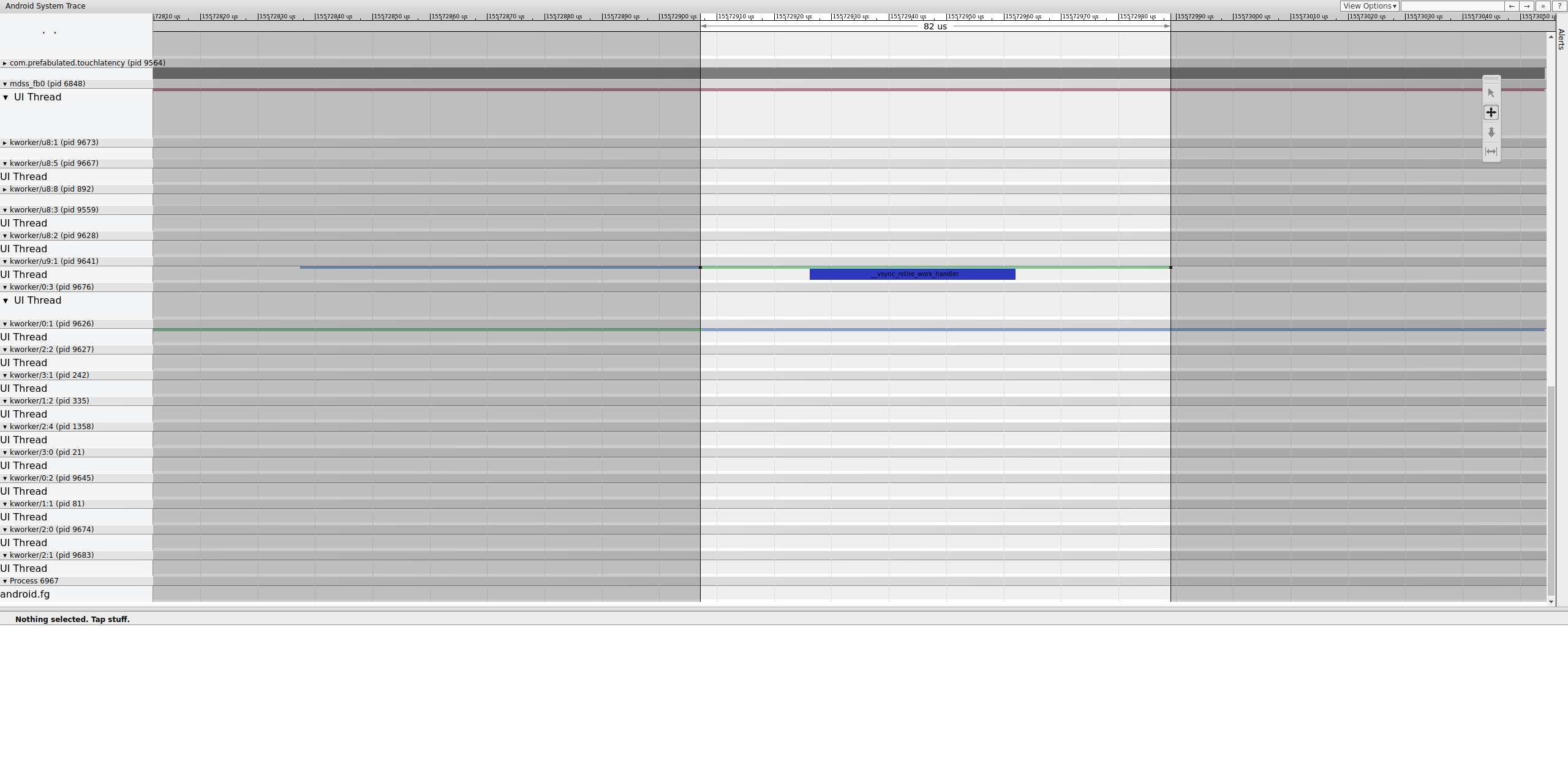
Rysunek 15. Sprawdź koniec ogrodzenia.
Kolejka zadań zawiera __vsync_retire_work_handler, które jest uruchomione, gdy zmienia się bariera. W kodzie źródłowym jądra widać, że jest to część sterownika wyświetlacza. Wygląda na to, że znajduje się na ścieżce krytycznej potoku wyświetlania, więc musi działać jak najszybciej. Może działać przez około 70 μs (nie jest to długie opóźnienie w harmonogramowaniu), ale jest to kolejka zadań i może nie być dokładnie zaplanowana.
Sprawdź poprzednią klatkę, aby ustalić, czy to ona spowodowała problem. Czasami drgania mogą się kumulować i w końcu spowodować przekroczenie terminu:
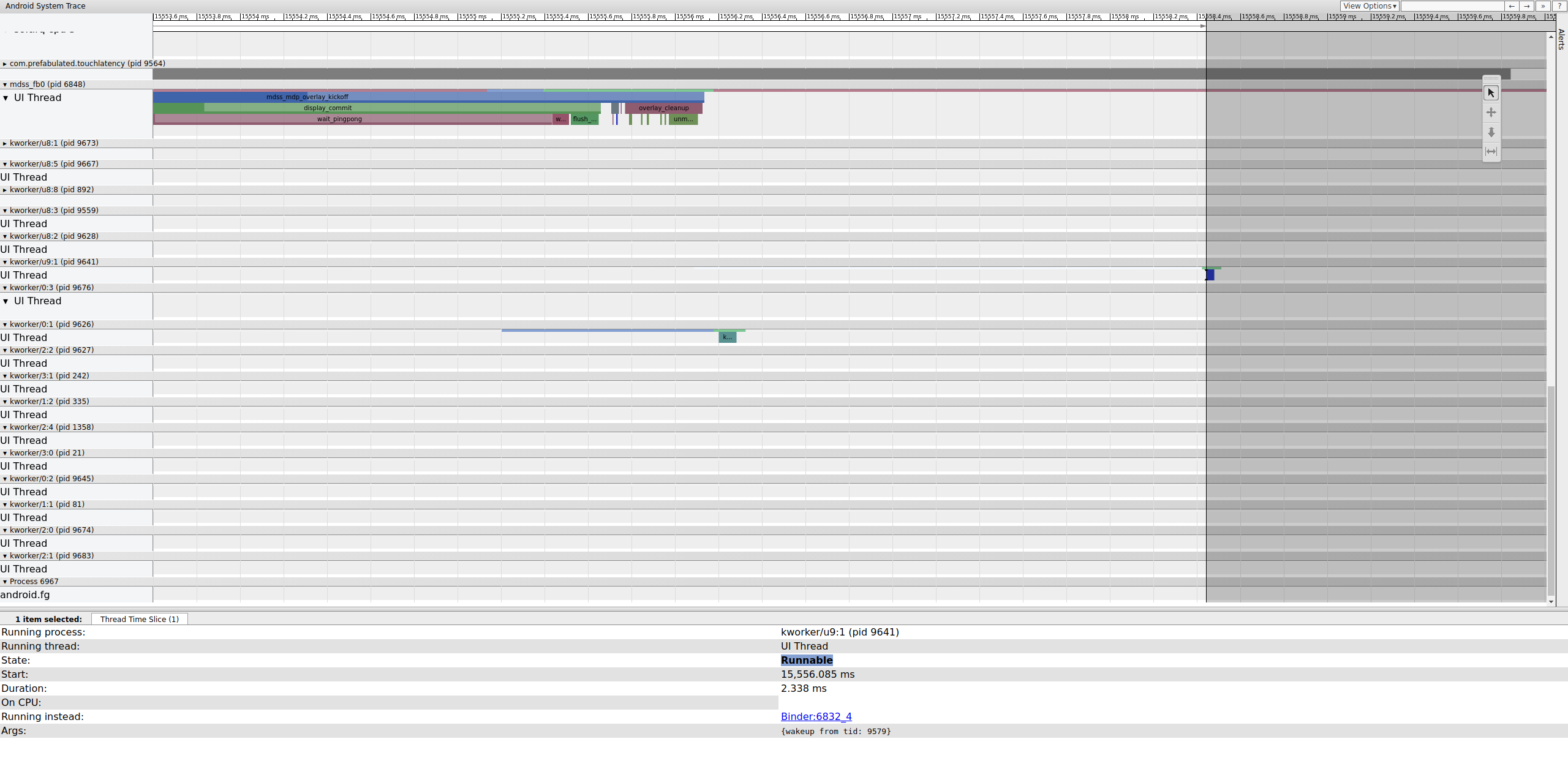
Rysunek 16. Poprzednia klatka.
Wątek wykonywalny w procesie kworker nie jest widoczny, ponieważ po wybraniu jest on wyświetlany na biało, ale statystyki mówią same za siebie: opóźnienie harmonogramu wynoszące 2,3 ms w przypadku części ścieżki krytycznej potoku wyświetlania jest niekorzystne.
Zanim przejdziesz dalej, wyeliminuj opóźnienie, przenosząc tę część ścieżki krytycznej potoku wyświetlania z kolejki zadań (która działa jako wątek SCHED_OTHERCFS) do dedykowanego SCHED_FIFO
wątku jądra. Ta funkcja wymaga gwarancji czasowych, których kolejki zadań nie mogą zapewnić (i nie są do tego przeznaczone).
Nie jest jasne, czy to jest przyczyną zacinania się. Poza łatwymi do zdiagnozowania przypadkami, takimi jak rywalizacja o blokadę jądra powodująca uśpienie wątków krytycznych dla wyświetlania, ślady zwykle nie wskazują problemu. Te wahania mogły być przyczyną utraty klatki. Czas oczekiwania powinien wynosić 16,7 ms, ale w klatkach poprzedzających pominiętą klatkę nie jest nawet zbliżony do tej wartości. Ze względu na ścisłe powiązanie potoku wyświetlania może się zdarzyć, że wahania czasu oczekiwania na sygnał spowodują pominięcie klatki.
W tym przykładzie rozwiązanie polega na przekształceniu __vsync_retire_work_handler z kolejki zadań w dedykowany wątek jądra. Dzięki temu w teście z odbijającą się piłką zauważalnie zmniejsza się drganie i zacinanie. Kolejne ślady pokazują czasy bariery zbliżone do 16,7 ms.