
כדי לתמוך בלוח בקרה של שילוב רציף (CI) שניתן להתאמה, בעל ביצועים טובים וגמישות, צריך לתכנן בקפידה את הקצה העורפי של VTS Dashboard עם הבנה מעמיקה של הפונקציונליות של מסדי הנתונים. Google Cloud Datastore הוא מסד נתונים מסוג NoSQL שמציע ערבויות ACID לטרנזקציות ועקביות בסופו של דבר, וגם עקביות חזקה בתוך קבוצות ישויות. עם זאת, המבנה שונה מאוד ממסדי נתונים של SQL (ואפילו מ-Cloud Bigtable). במקום טבלאות, שורות ותאים, יש סוגים, ישויות ומאפיינים.
בקטעים הבאים מתואר מבנה הנתונים ודפוסי השאילתות ליצירת קצוות עורפיים יעילים לשירות האינטרנט של VTS Dashboard.
ישויות
הישות הבאות שומרות תקצירים ומשאבים מרצפי בדיקות של VTS:
- ישות לבדיקה. אחסון מטא-נתונים על הפעלות בדיקה של בדיקה מסוימת. המפתח שלו הוא שם הבדיקה, והמאפיינים שלו כוללים את מספר הכשלים, מספר המעברים והרשימה של הכשלים בתרגיל הבדיקה מאז משימות ההתראות מעדכנות אותו.
- ישות של הרצה לבדיקה. מכיל מטא-נתונים מפעולות של בדיקה מסוימת. הוא צריך לאחסן את חותמות הזמן של תחילת הבדיקה וסיום הבדיקה, מזהה ה-build של הבדיקה, מספר תרחישי הבדיקה שעברו והכשלו, סוג ההרצה (למשל, לפני שליחה, אחרי שליחה או מקומית), רשימה של קישורים ליומני הרישום, שם המכונה המארחת ומספרי הסיכום של הכיסוי.
- ישות של פרטי מכשיר. מכיל פרטים על המכשירים שבהם השתמשתם במהלך הרצת הבדיקה. הוא כולל את מזהה ה-build של המכשיר, שם המוצר, יעד ה-build, ההסתעפות ומידע על ABI. המידע הזה מאוחסן בנפרד מהישות של הרצה של בדיקה, כדי לתמוך בהרצות של בדיקות במספר מכשירים באופן אחד-לרבים.
- Profiling Point Run Entity. סיכום הנתונים שנאספו בנקודת פרופיל מסוימת במהלך הרצה של בדיקה. הוא מתאר את תוויות הציר, שם הנקודה בפרופיל, הערכים, הסוג ומצב הרגרסיה של נתוני הפרופיל.
- ישות כיסוי. תיאור של נתוני הכיסוי שנאספו לקובץ אחד. הוא מכיל את פרטי הפרויקט ב-Git, את נתיב הקובץ ואת רשימת מספרי הכיסוי לכל שורה בקובץ המקור.
- ישות להרצת תרחיש בדיקה. תיאור התוצאה של תרחיש בדיקה מסוים מרצף בדיקות, כולל שם תרחיש הבדיקה והתוצאה שלו.
- ישות של מועדפים של משתמשים. אפשר לייצג כל מינוי משתמש בישות שמכילה הפניה לבדיקה ולמזהה המשתמש שנוצר משירות המשתמשים של App Engine. כך אפשר לבצע שאילתות דו-כיווניות יעילות (כלומר, לכל המשתמשים שנרשמו למבחן ולכל המבחנים שהמשתמש הוסיף למועדפים).
קיבוץ ישויות
כל מודול בדיקה מייצג את השורש של קבוצת ישויות. ישויות של הרצה של בדיקה הן גם צאצאים של הקבוצה הזו וגם הורים של ישויות של מכשירים, ישויות של נקודות ליצירת פרופיל וישויות של כיסוי רלוונטיות לאב הקדמון של הבדיקה וההרצה של הבדיקה.
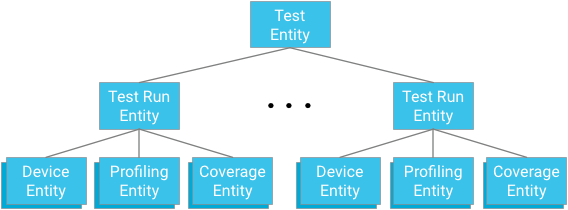
נקודת מפתח: כשמתכננים יחסי ישות אב, צריך לאזן בין הצורך לספק מנגנונים יעילים ועקביים לשליחת שאילתות לבין המגבלות שחלות על מסד הנתונים.
יתרונות
דרישת העקביות מבטיחה שהפעולות העתידיות לא יראו את ההשפעות של עסקה עד שהיא תבוצע, ושעסקאות בעבר יהיו גלויות לפעולות הקיימות. ב-Cloud Datastore, קיבוץ ישויות יוצר איים של עקביות קריאה וכתיבה חזקה בתוך הקבוצה, שבמקרה הזה כוללת את כל הרצות הבדיקה והנתונים שקשורים למודול הבדיקה. היתרונות של השיטה הזו:
- אפשר להתייחס לקריאות ולעדכונים של סטטוס מודול הבדיקה על ידי משימות התראות כאל פעולות אטומיות
- תצוגה עקבית מובטחת של תוצאות של תרחישי בדיקה במודולים של בדיקות
- שאילתות מהירות יותר בעצי ישות אב
מגבלות
לא מומלץ לכתוב לקבוצת ישויות בקצב מהיר יותר מישות אחת לשנייה, כי יכול להיות שחלק מהכתובות יידחו. כל עוד משימות ההתראות וההעלאה לא מתבצעות בקצב מהיר יותר מכתיבת אחת לשנייה, המבנה יציב ומבטיח עקביות חזקה.
בסופו של דבר, המגבלה של כתיבת אחת לכל מודול בדיקה לשנייה היא סבירה, כי בדרך כלל הרצת בדיקות נמשכת לפחות דקה, כולל התקורה של מסגרת VTS. אלא אם הבדיקה מופעלת באופן עקבי בו-זמנית ביותר מ-60 מארחים שונים, לא יכולה להיות צווארון בקבוק בכתיבה. הסבירות לכך קטנה עוד יותר מכיוון שכל מודול הוא חלק מתוכנית בדיקה שלרוב נמשכת יותר משעה. אפשר לטפל בקלות בחריגות אם המארחים מריצים את הבדיקות באותו זמן, וכתוצאה מכך מתרחשות התפרצויות קצרות של פעולות כתיבה באותם מארחים (למשל, על ידי זיהוי שגיאות כתיבה וניסיון חוזר).
שיקולים לגבי התאמה לעומס
רצף בדיקות לא חייב לכלול את הבדיקה כהורה שלו (למשל, הוא יכול לכלול מפתח אחר ולהכיל את שם הבדיקה ואת שעת ההתחלה של הבדיקה כמאפיינים). עם זאת, במקרה כזה תהיה עקביות בסופו של דבר במקום עקביות חזקה. לדוגמה, יכול להיות שבמשימה של ההתראות לא תופיע קובץ snapshot עקבי של הפעלות הבדיקה האחרונות בתוך מודול הבדיקה, כלומר יכול להיות שהמצב הגלובלי לא יציג ייצוג מדויק לחלוטין של רצף הפעלות הבדיקה. הדבר עשוי להשפיע גם על הצגת הפעלות הבדיקה בתוך מודול בדיקה יחיד, שעשוי שלא להיות תצוגה עקבית של רצף ההפעלה. בסופו של דבר, קובץ snapshot יהיה עקבי, אבל אין ערובה שהנתונים העדכניים ביותר יהיו עקביים.
מקרי בדיקה
צוואר בקבוק פוטנציאלי נוסף הוא בדיקות גדולות עם הרבה מקרי בדיקה. שתי המגבלות התפעוליות הן קצב הכתיבה המקסימלי בקבוצת ישויות של פעולה אחת לשנייה, וגודל עסקה מקסימלי של 500 ישויות.
גישה אחת היא לציין מקרה בדיקה שיש לו הרצה של בדיקה בתור אב (בדומה לאופן שבו מאוחסנים נתוני כיסוי, נתוני פרופיל ומידע על המכשיר):

הגישה הזו מספקת אטומיות ועקביות, אבל היא מטילה הגבלות חמורות על הבדיקות: אם עסקה מוגבלת ל-500 ישויות, אז לבדיקה יכולים להיות לא יותר מ-498 תרחישי בדיקה (בהנחה שאין נתוני כיסוי או פרופיל). אם הבדיקה תחרוג מהמגבלה הזו, לא תהיה אפשרות לכתוב את כל התוצאות של מקרי הבדיקה בעסקה אחת, וחילוק מקרי הבדיקה לעסקאות נפרדות עלול לחרוג מהתפוקה המקסימלית של כתיבה בקבוצת ישויות, שהיא חזרה אחת לשנייה. הפתרון הזה לא מומלץ כי הוא לא יתאים להתאמה לעומס בלי להקריב את הביצועים.
עם זאת, במקום לשמור את התוצאות של תרחישי הבדיקה כצאצאים של הרצה של הבדיקה, אפשר לשמור את תרחישי הבדיקה בנפרד ולספק את המפתחות שלהם להרצה של הבדיקה (הרצת בדיקה מכילה רשימה של מזהים לישויות של תרחישי הבדיקה שלה):
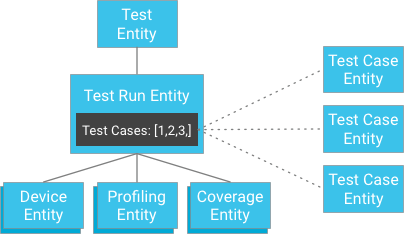
במבט ראשון, נראה שהפעולה הזו מפירה את ההתחייבות לקונסistency חזק. עם זאת, אם ללקוח יש ישות של הרצה של בדיקה ורשימת מזהים של תרחישי בדיקה, הוא לא צריך ליצור שאילתה. במקום זאת, הוא יכול לקבל ישירות את תרחישי הבדיקה לפי המזהים שלהם, שתמיד מובטח שהם עקביים. הגישה הזו מפחיתה באופן משמעותי את האילוץ על מספר תרחישי הבדיקה שיכולים להיות להרצת בדיקה, תוך שמירה על עקביות חזקה בלי לסכן כתיבה מוגזמת בתוך קבוצת ישויות.
דפוסי גישה לנתונים
בלוח הבקרה של VTS נעשה שימוש בדפוסי הגישה לנתונים הבאים:
- המועדפים של המשתמש. אפשר לשלוח שאילתות עליהם באמצעות מסנן שוויון על ישויות של מועדפים של משתמשים שיש בהן את אובייקט המשתמש הספציפי ב-App Engine כמאפיין.
- בדיקת כרטיס המוצר. שאילתה פשוטה של ישויות בדיקה. כדי לצמצם את רוחב הפס להצגת דף הבית, אפשר להשתמש בתחזית על מספרי הבדיקות שעברו ובדיקות שנכשלו, כדי להשמיט את הרשימה הארוכה של מזהי תרחישי הבדיקה שנכשלו ומטא-נתונים אחרים שמשמשים את משימות ההתראות.
- הרצות לניסיון. כדי לשלוח שאילתות לגבי ישויות של הרצה של בדיקה, צריך למיין לפי המפתח (חותמת הזמן) ולסנן לפי מאפייני ההרצה של הבדיקה, כמו מזהה ה-build, מספר הבקשות שעברו וכו'. ביצוע שאילתת ישות אב עם מפתח של ישות בדיקה מבטיח עקביות גבוהה בקריאה. בשלב הזה אפשר לאחזר את כל התוצאות של תרחישי הבדיקה באמצעות רשימת המזהים ששמורים במאפיין של הרצה של בדיקה. בנוסף, התוצאה תהיה עקבית מאוד בגלל אופי פעולות האחזור של מאגר הנתונים.
- נתוני פרופיל ונתוני כיסוי. אפשר להריץ שאילתות לקבלת נתוני פרופיל או נתוני כיסוי שמשויכים לבדיקה, בלי לאחזר גם נתונים אחרים של הרצת הבדיקה (כמו נתוני פרופיל או כיסוי אחרים, נתונים של תרחישים לבדיקה וכו'). שאילתה של אב באמצעות מפתחות הישות של בדיקת הבדיקה והרצת הבדיקה תשחזר את כל נקודות הפרופיל שתועדו במהלך רצת הבדיקה. אם תוסיפו גם סינון לפי שם נקודת הפרופיל או שם הקובץ, תוכלו לאחזר ישות אחת של פרופיל או כיסוי. מטבען של שאילתות אב, הפעולה הזו עקבית מאוד.
למידע נוסף על ממשק המשתמש ועל צילומי מסך של תבניות הנתונים האלה בפעולה, ראו ממשק המשתמש של לוח הבקרה של VTS.