
يتضمّن نظام التشغيل Android 8.0 اختبارات أداء binder وhwbinder لمعدل نقل البيانات و وقت الاستجابة. على الرغم من توفّر العديد من السيناريوهات لرصد مشكلات الأداء التي يمكن ملاحظتها، يمكن أن يستغرق تنفيذ هذه السيناريوهات بعض الوقت، وغالبًا ما لا تتوفّر النتائج إلا بعد دمج النظام. من خلال استخدام اختبارات الأداء المُقدَّمة، يصبح من الأسهل إجراء الاختبار أثناء التطوير ورصد المشاكل الخطيرة في وقت مبكر وتحسين تجربة المستخدم.
تشمل اختبارات الأداء الفئات الأربع التالية:
- معدل نقل البيانات في أداة ربط البيانات (متاح في
system/libhwbinder/vts/performance/Benchmark_binder.cpp) - وقت استجابة أداة الربط (متاح في
frameworks/native/libs/binder/tests/schd-dbg.cpp) - معدل نقل البيانات في hwbinder (متاح في
system/libhwbinder/vts/performance/Benchmark.cpp) - وقت استجابة hwbinder (متاح في
system/libhwbinder/vts/performance/Latency.cpp)
لمحة عن binder وhwbinder
Binder وhwbinder هما منهجَان لبنية برمجية لنظام Android تهدف إلى تنسيق الاتصالات بين العمليات (IPC) وتشتركان في برنامج تشغيل Linux نفسه، ولكنهما يختلفان عن بعضهما من حيث الجودة على النحو التالي:
| جانب | مجلد | hwbinder |
|---|---|---|
| الغرض | توفير مخطّط IPC للأغراض العامة للإطار | التواصل مع الأجهزة |
| الخاصية | محسَّنة لاستخدام إطار عمل Android | الحد الأدنى من وقت الاستجابة السريع |
| تغيير سياسة الجدولة للعناصر في المقدّمة/الخلفية | نعم | لا |
| تمرير الوسيطات | استخدام التسلسل المتوافق مع عنصر الطرد | يستخدم هذا الأسلوب مخازن التوزيع ويتجنب النفقات العامة لنسخ البيانات المطلوبة لسلسلة رسائل الصادرات . |
| اكتساب الأولوية | لا | نعم |
عمليتا Binder وhwbinder
يعرض أداة عرض systrace المعاملات على النحو التالي:
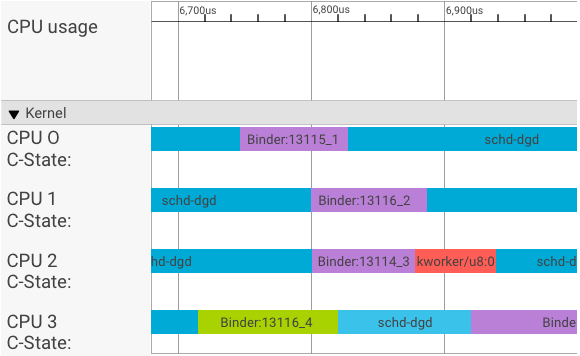
في المثال أعلاه:
- إنّ عمليات schd-dbg الأربعة هي عمليات العميل.
- عمليات الربط الأربعة هي عمليات الخادم (يبدأ الاسم بحرف Binder وينتهي برقم تسلسلي).
- تتم دائمًا إقران عملية العميل بعملية خادم مخصّصة للعميل.
- يتم جدولة جميع أزواج عمليات العميل والخادم بشكل مستقل من خلال kernel بالتزامن.
في وحدة المعالجة المركزية (CPU) 1، تنفِّذ نواة نظام التشغيل العميل لإصدار الطلب. بعد ذلك، يتم استخدام وحدة المعالجة المركزية نفسها كلما أمكن ذلك لتنشيط عملية الخادم ومعالجة الطلب وتبديل السياق مرة أخرى بعد اكتمال الطلب.
معدل نقل البيانات مقارنةً بوقت الاستجابة
في المعاملات المثالية، حيث يتم تبديل عملية العميل والخادم بسلاسة، لا تؤدي اختبارات معدل نقل البيانات ووقت الاستجابة إلى اختلافات مهمة في الرسائل. ومع ذلك، عندما يعالج نواة نظام التشغيل طلب مقاطعة (IRQ) من الأجهزة، أو في حال الانتظار للحصول على قفل، أو ببساطة اختيار عدم معالجة رسالة على الفور، يمكن أن تتشكل فقاعة وقت الاستجابة.
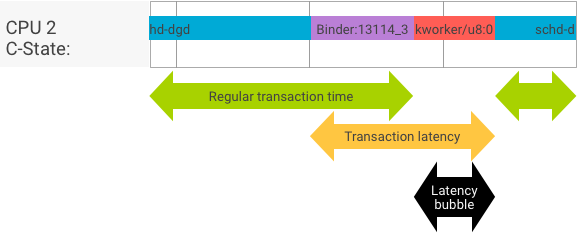
يُنشئ اختبار معدل نقل البيانات عددًا كبيرًا من المعاملات بأحجام حمولة مختلفة، ما يقدّم تقديرًا جيدًا لوقت المعاملات العادي (في أفضل السيناريوهات) والحد الأقصى لمعدل نقل البيانات الذي يمكن أن يحقّقه الرابط.
في المقابل، لا ينفِّذ اختبار وقت الاستجابة أي إجراءات على الحمولة لتقليل وقت المعاملة العادي. يمكننا استخدام وقت المعاملة لتقدير وقت الربط الإضافي، وإنشاء إحصاءات لأسوأ الحالات، وحساب نسبة المعاملات التي تستوفي وقت استجابةها مهلة زمنية محدّدة.
التعامل مع عمليات عكس الأولوية
تحدث مشكلة قلب الأولويات عندما تكون سلسلة محادثات ذات أولوية أعلى في انتظار سلسلة محادثات ذات أولوية أقل. تواجه تطبيقات الوقت الفعلي (RT) مشكلة في عكس الأولوية:
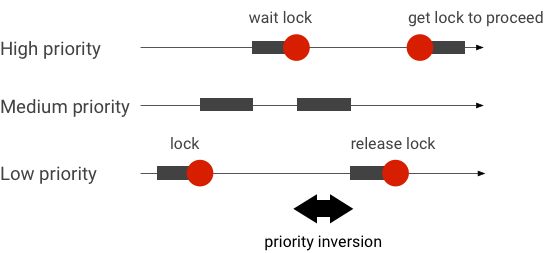
عند استخدام جدولة "المجدول العادل تمامًا" (CFS) في نظام التشغيل Linux، تتوفر لسلسلة المهام دائمًا فرصة للتنفيذ حتى عندما تكون سلاسل المهام الأخرى ذات أولوية أعلى. نتيجةً لذلك، تتعامل التطبيقات التي تستخدم جدولة CFS مع انعكاس الأولوية على أنّه سلوك متوقّع وليس مشكلة. في الحالات التي يحتاج فيها إطار عمل Android إلى جدولة RT لضمان امتياز سلاسل المهام ذات الأولوية العالية، يجب حلّ مشكلة قلب الأولويات.
مثال على انعكاس الأولوية أثناء معاملة Binder (يتم حظر سلسلة التعليمات RT بشكل منطقي من خلال سلاسل التعليمات CFS الأخرى عند انتظار سلسلة تعليمات Binder للقيام بتقديم الخدمة):
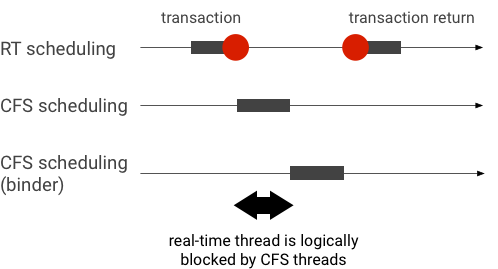
لتجنُّب عمليات التوقف، يمكنك استخدام اكتساب الأولوية لرفع معالجة سلسلتَي Binder مؤقتًا إلى سلسلة مهام RT عند معالجة طلب من عميل RT. يُرجى العِلم أنّ ميزة جدولة البث المباشر في الوقت الفعلي تتطلب موارد محدودة، لذا يجب استخدامها بعناية. في نظام يتضمّن n وحدة معالجة مركزية، يكون الحد الأقصى لعدد سلاسل المحادثات المتعلّقة بالمعالجة المحدودة للوقت هو n أيضًا. وقد تحتاج سلاسل المحادثات الإضافية المتعلّقة بالمعالجة المحدودة للوقت إلى الانتظار (وبالتالي عدم الالتزام بالمواعيد النهائية) إذا كانت جميع وحدات المعالجة المركزية مشغولة بسلاسل محادثات أخرى تتعلّق بالمعالجة المحدودة للوقت.
لحلّ جميع حالات انعكاس الأولوية المحتمَلة، يمكنك استخدام ميزة اكتساب الأولوية لكلٍّ من binder وhwbinder. ومع ذلك، بما أنّ أداة الربط تُستخدَم على نطاق واسع في جميع أنحاء النظام، قد يؤدي تفعيل اكتساب الأولوية لمعاملات أداة الربط إلى إرسال رسائل غير مرغوب فيها إلى النظام من خلال سلاسل مهام RT أكثر مما يمكنه التعامل معه.
إجراء اختبارات معدل نقل البيانات
يتم إجراء اختبار معدل نقل البيانات استنادًا إلى معدل نقل معاملات binder/hwbinder. في النظام الذي لا يتضمّن عددًا كبيرًا من العمليات، تكون فقاعات وقت الاستجابة نادرة ويمكن إزالة تأثيرها ما دام عدد التكرارات مرتفعًا بما يكفي.
- اختبار معدل نقل البيانات للمُجمِّع في مرحلة
system/libhwbinder/vts/performance/Benchmark_binder.cpp. - اختبار معدل نقل البيانات hwbinder في
system/libhwbinder/vts/performance/Benchmark.cpp.
نتائج الاختبار
مثال على نتائج اختبار معدل نقل البيانات للمعاملات التي تستخدم أحجامًا مختلفة من الحمولة:
Benchmark Time CPU Iterations --------------------------------------------------------------------- BM_sendVec_binderize/4 70302 ns 32820 ns 21054 BM_sendVec_binderize/8 69974 ns 32700 ns 21296 BM_sendVec_binderize/16 70079 ns 32750 ns 21365 BM_sendVec_binderize/32 69907 ns 32686 ns 21310 BM_sendVec_binderize/64 70338 ns 32810 ns 21398 BM_sendVec_binderize/128 70012 ns 32768 ns 21377 BM_sendVec_binderize/256 69836 ns 32740 ns 21329 BM_sendVec_binderize/512 69986 ns 32830 ns 21296 BM_sendVec_binderize/1024 69714 ns 32757 ns 21319 BM_sendVec_binderize/2k 75002 ns 34520 ns 20305 BM_sendVec_binderize/4k 81955 ns 39116 ns 17895 BM_sendVec_binderize/8k 95316 ns 45710 ns 15350 BM_sendVec_binderize/16k 112751 ns 54417 ns 12679 BM_sendVec_binderize/32k 146642 ns 71339 ns 9901 BM_sendVec_binderize/64k 214796 ns 104665 ns 6495
- تشير المدة إلى تأخّر الرحلة ذهابًا وإيابًا الذي يتم قياسه في الوقت الفعلي.
- يشير وحدة المعالجة المركزية إلى الوقت التراكمي الذي يتم فيه جدولة وحدات المعالجة المركزية للاختبار.
- تشير عمليات التكرار إلى عدد المرات التي تم فيها تنفيذ دالة الاختبار.
على سبيل المثال، بالنسبة إلى الحمولة التي تبلغ 8 بايت:
BM_sendVec_binderize/8 69974 ns 32700 ns 21296
… يتم احتساب الحد الأقصى للإنتاجية التي يمكن أن يحققها الرابط على النحو التالي:
أقصى معدل نقل بيانات باستخدام الحمولة التي تبلغ 8 بايت = (8 * 21296)/69974 ~= 2.423 بت/ns ~= 2.268 غيغابايت/ثانية
خيارات الاختبار
للحصول على النتائج بتنسيق .json، شغِّل الاختبار باستخدام الوسيطة
--benchmark_format=json:
libhwbinder_benchmark --benchmark_format=json
{
"context": {
"date": "2017-05-17 08:32:47",
"num_cpus": 4,
"mhz_per_cpu": 19,
"cpu_scaling_enabled": true,
"library_build_type": "release"
},
"benchmarks": [
{
"name": "BM_sendVec_binderize/4",
"iterations": 32342,
"real_time": 47809,
"cpu_time": 21906,
"time_unit": "ns"
},
….
}إجراء اختبارات وقت الاستجابة
يقيس اختبار وقت الاستجابة الوقت الذي يستغرقه العميل لبدء تهيئة المعاملة والتبديل إلى عملية الخادم لمعالجتها وتلقّي النتيجة. يبحث الاختبار أيضًا عن سلوكيات معروفة غير مناسبة لجدول التشغيل والتي يمكن أن تؤثّر سلبًا في وقت استجابة المعاملات، مثل جدول التشغيل الذي لا يتيح اكتساب الأولوية أو لا يراعي علامة المزامنة.
- اختبار وقت استجابة أداة الربط في مرحلة
frameworks/native/libs/binder/tests/schd-dbg.cpp. - اختبار وقت استجابة hwbinder متوفّر في
system/libhwbinder/vts/performance/Latency.cpp.
نتائج الاختبار
تعرض النتائج (بتنسيق .json) إحصاءات لمتوسط وقت الاستجابة أو أفضل وقت استجابة أو أسوأ وقت استجابة و عدد المواعيد النهائية التي تم تفويتها.
خيارات الاختبار
تعتمد اختبارات وقت الاستجابة على الخيارات التالية:
| الأمر | الوصف |
|---|---|
-i value |
حدِّد عدد التكرارات. |
-pair value |
حدِّد عدد أزواج العمليات. |
-deadline_us 2500 |
حدِّد الموعد النهائي بالتنسيق الأمريكي. |
-v |
الحصول على نتائج مفصّلة (لتصحيح الأخطاء) |
-trace |
يمكنك إيقاف التتبّع عند بلوغ الموعد النهائي. |
توضّح الأقسام التالية كل خيار بالتفصيل، وتشرح طريقة الاستخدام، وتقدّم مثالاً على النتائج.
تحديد النُسخ
مثال على عدد كبير من التكرارات مع إيقاف الإخراج التفصيلي:
libhwbinder_latency -i 5000 -pair 3
{
"cfg":{"pair":3,"iterations":5000,"deadline_us":2500},
"P0":{"SYNC":"GOOD","S":9352,"I":10000,"R":0.9352,
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}
},
"P1":{"SYNC":"GOOD","S":9334,"I":10000,"R":0.9334,
"other_ms":{ "avg":0.19, "wst":2.9 , "bst":0.055, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":3.1 , "bst":0.066, "miss":1, "meetR":0.9998}
},
"P2":{"SYNC":"GOOD","S":9369,"I":10000,"R":0.9369,
"other_ms":{ "avg":0.19, "wst":4.8 , "bst":0.055, "miss":6, "meetR":0.9988},
"fifo_ms": { "avg":0.15, "wst":1.8 , "bst":0.067, "miss":0, "meetR":1}
},
"inheritance": "PASS"
}تعرض نتائج الاختبار هذه ما يلي:
"pair":3- إنشاء زوج من العميل والخادم
"iterations": 5000- تتضمن 5,000 تكرار.
"deadline_us":2500- المهلة هي 2500us (2.5ms)، ومن المتوقّع أن تستوفي معظم المعاملات هذه القيمة.
"I": 10000- تتضمن دورة اختبار واحدة معاملتَين:
- معاملة واحدة بأولوية عادية (
CFS other) - معاملة واحدة حسب الأولوية في الوقت الفعلي (
RT-fifo)
- معاملة واحدة بأولوية عادية (
"S": 9352- تمّت مزامنة 9352 معاملة في وحدة المعالجة المركزية نفسها.
"R": 0.9352- يشير إلى النسبة التي تتم بها مزامنة العميل والخادم معًا في وحدة المعالجة المركزية نفسها.
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996}- متوسط (
avg) وحالة أسوأ (wst) وحالة أفضل (bst) لجميع المعاملات التي يجريها متصل لديه الأولوية العادية معاملتان بعدmissمن الموعد النهائي، ما يجعل نسبة الامتثال (meetR) 0.9996. "fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}- يشبه
other_ms، ولكن للمعاملات التي يجريها العميل بأولويةrt_fifo. من المرجّح (وليس ضروريًا) أن يحقّق الإصدارfifo_msنتيجة أفضل من الإصدارother_ms، مع قيم أقلavgوwstوقيمة أعلىmeetR(يمكن أن يكون الفرق أكثر أهمية عند التحميل في الخلفية).
ملاحظة: قد يؤثّر التحميل في الخلفية في نتيجة معدل نقل البيانات
ومجموعة other_ms في اختبار وقت الاستجابة. قد يعرض الإجراء
fifo_ms نتائج مشابهة فقط ما دام تحميل الخلفية
له أولوية أقل من RT-fifo.
تحديد قيم الأزواج
تتم إقران كل عملية عميل بعملية خادم مخصّصة للعميل،
وقد يتم جدولة كل زوج بشكل مستقل لأي وحدة معالجة مركزية. ومع ذلك، يجب ألا تحدث عملية نقل بيانات ملف المعالجة المركزية أثناء إجراء معاملة ما دام علامة SYNC honor.
تأكَّد من عدم التحميل الزائد على النظام. على الرغم من أنّه من المتوقّع حدوث وقت استجابة مرتفع في
النظام الذي يواجه حمولة زائدة، لا تقدّم نتائج اختبار النظام الذي يواجه حمولة زائدة
معلومات مفيدة. لاختبار نظام بضغط أعلى، استخدِم -pair
#cpu-1 (أو -pair #cpu بحذر). يؤدي اختبار استخدام
-pair n مع n > #cpu إلى زيادة تحميل
النظام وإنشاء معلومات غير مفيدة.
تحديد قيم الموعد النهائي
بعد إجراء اختبار مكثّف لسيناريوهات المستخدمين (إجراء اختبار وقت الاستجابة على أحد المنتجات المؤهّلة)، تبيّن لنا أنّ 2.5 ملي ثانية هو الحدّ الأقصى المسموح به. بالنسبة إلى التطبيقات الجديدة التي تتطلّب متطلبات أعلى (مثل 1,000 صورة في الثانية)، ستتغيّر قيمة مهلة المعالجة هذه.
تحديد إخراج مفصّل
يؤدي استخدام الخيار -v إلى عرض معلومات تفصيلية. مثال:
libhwbinder_latency -i 1 -v-------------------------------------------------- service pid: 8674 tid: 8674 cpu: 1 SCHED_OTHER 0-------------------------------------------------- main pid: 8673 tid: 8673 cpu: 1 -------------------------------------------------- client pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0-------------------------------------------------- fifo-caller pid: 8677 tid: 8678 cpu: 0 SCHED_FIFO 99 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 ??? 99-------------------------------------------------- other-caller pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 SCHED_OTHER 0
- يتم إنشاء سلسلة محادثات الخدمة باستخدام أولوية
SCHED_OTHERويتم تشغيلها فيCPU:1باستخدامpid 8674. - بعد ذلك، يتم بدء المعاملة الأولى باستخدام
fifo-caller. لتقديم هذه المعاملة، يُجري hwbinder ترقية للأولوية الخادم (pid: 8674 tid: 8676) لتكون 99 ويصنّفه أيضًا باستخدام فئة جدولة عابرة (يتم طباعتها على النحو التالي:???). ثم يضع جدول التشغيل عملية الخادم فيCPU:0لتشغيلها ويزامنها مع وحدة المعالجة المركزية نفسها مع العميل. - يحصل المُتصل بالمعاملة الثانية على أولوية
SCHED_OTHER. يُخفض الخادم فئته ويقدّم الخدمة للمتصل بأولويةSCHED_OTHER.
استخدام التتبُّع لتصحيح الأخطاء
يمكنك تحديد الخيار -trace لتصحيح أخطاء وقت الاستجابة. عند استخدام اختبار وقت الاستجابة، يوقف الاختبار تسجيل سجلّ التتبّع في اللحظة التي يتم فيها رصد وقت استجابة سئ. مثال:
atrace --async_start -b 8000 -c sched idle workq binder_driver sync freqlibhwbinder_latency -deadline_us 50000 -trace -i 50000 -pair 3deadline triggered: halt ∓ stop trace log:/sys/kernel/debug/tracing/trace
يمكن أن تؤثر المكوّنات التالية في وقت الاستجابة:
- وضع إنشاء تطبيق Android يكون وضع Eng عادةً أبطأ من وضع userdebug.
- الإطار: كيف تستخدِم خدمة إطار العمل
ioctlلضبط الربط؟ - برنامج تشغيل الربط هل يدعم برنامج التشغيل ميزة التأمين المفصّل؟ هل يحتوي على جميع تصحيحات الأداء؟
- إصدار النواة وكلما كانت قدرة kernel في الوقت الفعلي أفضل، كانت النتائج أفضل.
- إعدادات kernel هل تحتوي إعدادات kernel على
DEBUGإعدادات مثلDEBUG_PREEMPTوDEBUG_SPIN_LOCK؟ - أداة جدولة نظام التشغيل هل يحتوي kernel على جدولة مدركة للطاقة (EAS) أو جدولة معالجة متعددة الأنواع (HMP)؟ هل هناك أيّ من برامج تشغيل
النواة (برنامج تشغيل
cpu-freqأو برنامج تشغيلcpu-idleأوcpu-hotplugأو غير ذلك) تؤثّر في جدول التشغيل؟