
Per supportare una dashboard di integrazione continua scalabile, efficiente e flessibile, il backend della dashboard VTS deve essere progettato con attenzione e con una conoscenza approfondita della funzionalità del database. Google Cloud Datastore è un database NoSQL che offre garanzie ACID transazionali e coerenza eventuale, nonché elevata coerenza all'interno di gruppi di entità. Tuttavia, la struttura è molto diversa dai database SQL (e persino da Cloud Bigtable); anziché tabelle, righe e celle, ci sono tipi, entità e proprietà.
Le sezioni seguenti descrivono la struttura dei dati e i pattern di query per creare un backend efficace per il servizio web VTS Dashboard.
Entità
Le seguenti entità memorizzano i riepiloghi e le risorse delle esecuzioni dei test VTS:
- Entità di test. Memorizza i metadati relativi alle esecuzioni di test di un determinato test. La chiave è il nome del test e le relative proprietà includono il conteggio degli errori, il conteggio dei test superati e l'elenco dei guasti dei casi di test dal momento in cui i job di avviso lo aggiornano.
- Entità di esecuzione del test. Contiene i metadati delle esecuzioni di un determinato test. Deve memorizzare i timestamp di inizio e fine del test, l'ID compilazione del test, il numero di casi di test superati e non superati, il tipo di esecuzione (ad es. pre-invio, post-invio o locale), un elenco di link ai log, il nome della macchina host e i conteggi di riepilogo della copertura.
- Entità informazioni del dispositivo. Contiene dettagli sui dispositivi utilizzati durante l'esecuzione del test. Include l'ID build del dispositivo, il nome del prodotto, il target di build, il ramo e le informazioni sull'ABI. Viene archiviato separatamente dall'entità di esecuzione del test per supportare le esecuzioni di test su più dispositivi in un rapporto uno a molti.
- Profiling Point Run Entity. Riassume i dati raccolti per un determinato punto di profilazione all'interno di un'esecuzione di test. Descrive le etichette degli assi, il nome del punto di profilazione, i valori, il tipo e la modalità di regressione dei dati di profilazione.
- Entità di copertura. Descrive i dati sulla copertura raccolti per un file. Contiene le informazioni del progetto Git, il percorso del file e l'elenco dei conteggi della copertura per riga nel file di origine.
- Entità esecuzione scenario di test. Descrive l'esito di un determinato caso di test da un'esecuzione del test, incluso il nome del caso di test e il relativo risultato.
- Entità Preferiti utente. Ogni abbonamento utente può essere rappresentato in un'entità contenente un riferimento al test e all'ID utente generato dal servizio utente App Engine. Ciò consente di eseguire query bidirezionali efficienti (ovvero per tutti gli utenti iscritti a un test e per tutti i test preferiti da un utente).
Raggruppamento di entità
Ogni modulo di test rappresenta la radice di un gruppo di entità. Le entità di esecuzione del test sono sia secondarie di questo gruppo sia principali per le entità di dispositivo, le entità di punto di profilazione e le entità di copertura pertinenti al rispettivo test e all'antenato dell'esecuzione del test.
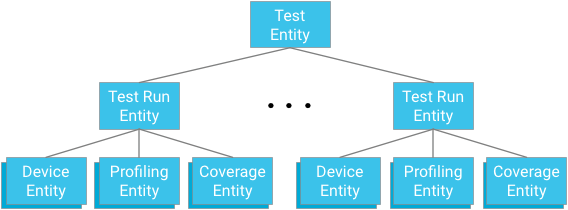
Punto chiave: quando progetti le relazioni di ascendenza, devi trovare un equilibrio tra la necessità di fornire meccanismi di query efficaci e coerenti e le limitazioni applicate dal database.
Vantaggi
Il requisito di coerenza garantisce che le operazioni future non vedano gli effetti di una transazione fino al suo commit e che le transazioni passate siano visibili alle operazioni attuali. In Cloud Datastore, il raggruppamento delle entità crea isole di forte coerenza di lettura e scrittura all'interno del gruppo, che in questo caso sono tutte le esecuzioni di test e i dati relativi a un modulo di test. Questa opzione offre i seguenti vantaggi:
- Le letture e gli aggiornamenti dello stato del modulo di test da parte dei job di avviso possono essere considerati atomici
- Visualizzazione coerente garantita dei risultati degli scenari di test all'interno dei moduli di test
- Query più rapide all'interno degli alberi genealogici
Limitazioni
Sconsigliamo di scrivere in un gruppo di entità a una velocità superiore a un'entità al secondo, in quanto alcune scritture potrebbero essere rifiutate. Finché i job di avviso e il caricamento non avvengono a una velocità superiore a una scrittura al secondo, la struttura è solida e garantisce una forte coerenza.
In definitiva, il limite di una scrittura per modulo di test al secondo è ragionevole perché solitamente le esecuzioni dei test richiedono almeno un minuto, incluso il sovraccarico del framework VTS. A meno che un test non venga eseguito contemporaneamente su più di 60 host diversi, non può esserci un collo di bottiglia per le scritture. Ciò diventa ancora più improbabile dato che ogni modulo fa parte di un piano di test che spesso richiede più di un'ora. Le anomalie possono essere gestite facilmente se gli host eseguono i test contemporaneamente, causando brevi picchi di scrittura sugli stessi host (ad es. rilevando gli errori di scrittura e riprovando).
Considerazioni sulla scalabilità
Un'esecuzione del test non deve necessariamente avere il test come elemento principale (ad es. potrebbe avere un'altra chiave e avere il nome del test e l'ora di inizio del test come proprietà); tuttavia, in questo modo la coerenza forte viene sostituita dalla coerenza eventuale. Ad esempio, il job di avviso potrebbe non vedere uno snapshot mutuamente coerente delle esecuzioni di test più recenti all'interno di un modulo di test, il che significa che lo stato globale potrebbe non rappresentare una rappresentazione completamente accurata della sequenza di esecuzioni di test. Ciò può anche influire sulla visualizzazione delle esecuzioni di test all'interno di un singolo modulo di test, che potrebbe non essere necessariamente uno snapshot coerente della sequenza di esecuzione. Alla fine lo snapshot sarà coerente, ma non è garantito che siano i dati più recenti.
Scenari di test
Un altro potenziale collo di bottiglia sono i test di grandi dimensioni con molti casi di test. I due vincoli operativi sono la velocità effettiva di scrittura massima all'interno di un gruppo di entità di una al secondo, insieme a una dimensione massima della transazione di 500 entità.
Un approccio potrebbe essere specificare un test case che abbia un'esecuzione di test come antenato (in modo simile a come vengono archiviati i dati sulla copertura, i dati di profilazione e le informazioni sul dispositivo):
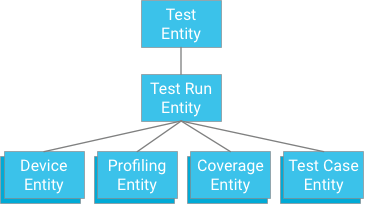
Sebbene questo approccio offra atomicità e coerenza, impone forti limitazioni ai test: se una transazione è limitata a 500 entità, un test non può avere più di 498 casi di test (supponendo che non siano presenti dati di copertura o profilazione). Se un test dovesse superare questo valore, una singola transazione non potrebbe scrivere tutti i risultati dello scenario di test contemporaneamente e la suddivisione degli scenari di test in transazioni separate potrebbe superare la velocità effettiva massima di scrittura del gruppo di entità di un'iterazione al secondo. Poiché questa soluzione non è scalabile senza sacrificare le prestazioni, non è consigliata.
Tuttavia, anziché memorizzare i risultati degli scenari di test come elementi secondari dell'esecuzione del test, gli scenari di test possono essere memorizzati in modo indipendente e le relative chiavi fornite all'esecuzione del test (un'esecuzione del test contiene un elenco di identificatori delle relative entità di scenari di test):
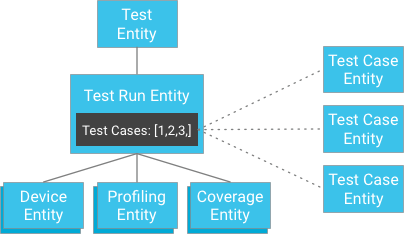
A prima vista, potrebbe sembrare che questa operazione violi la garanzia di elevata coerenza. Tuttavia, se il client dispone di un'entità di esecuzione del test e di un elenco di identificatori dei casi di test, non deve creare una query; può invece recuperare direttamente i casi di test tramite i relativi identificatori, che sono sempre garantiti come coerenti. Questo approccio riduce notevolmente il vincolo sul numero di casi di test che un'esecuzione del test può avere, garantendo al contempo una forte coerenza senza rischiare di scrivere eccessivamente all'interno di un gruppo di entità.
Pattern di accesso ai dati
La dashboard VTS utilizza i seguenti pattern di accesso ai dati:
- Preferiti dell'utente. È possibile eseguire query utilizzando un filtro di uguaglianza sulle entità dei preferiti dell'utente che hanno come proprietà il determinato oggetto utente App Engine.
- Scheda di prova. Query semplice delle entità di test. Per ridurre la larghezza di banda necessaria per il rendering della home page, è possibile utilizzare una proiezione sui conteggi di test superati e non superati in modo da omettere l'elenco potenzialmente lungo degli ID dei casi di test non superati e di altri metadati utilizzati dai job di avviso.
- Esecuzioni di test. La query per le entità di esecuzione del test richiede un ordinamento in base alla chiave (timestamp) e un possibile filtro sulle proprietà di esecuzione del test come ID build, conteggio di passaggi e così via. Se esegui una query sull'antenato con una chiave dell'entità di test, la lettura è fortemente coerente. A questo punto, tutti i risultati del caso di test possono essere recuperati utilizzando l'elenco di ID memorizzati in una proprietà di esecuzione del test. Inoltre, si tratta di un risultato fortemente coerente per la natura delle operazioni di recupero del data store.
- Dati di profilazione e copertura. È possibile eseguire query per i dati di copertura o di profilazione associati a un test senza recuperare anche altri dati di esecuzione del test (ad esempio altri dati di profilazione/copertura, dati dei casi di test e così via). Una query sull'antenato che utilizza le chiavi dell'entità test e dell'entità esecuzione test recupera tutti i punti di profilazione registrati durante l'esecuzione del test. Se applichi anche un filtro sul nome o sul nome file del punto di profilazione, puoi recuperare una singola entità di profilazione o copertura. Per la natura delle query sui predecessori, questa operazione è fortemente coerente.
Per informazioni dettagliate sull'interfaccia utente e screenshot di questi pattern di dati in azione, consulta Interfaccia utente della dashboard VTS.