
Il modello di threading di Binder è progettato per facilitare le chiamate di funzioni locali, anche se queste chiamate potrebbero essere a un processo remoto. Nello specifico, qualsiasi processo che ospita un nodo deve avere un pool di uno o più thread di Binder per gestire le transazioni verso i nodi ospitati in quel processo.
Transazioni sincrone e asincrone
Binder supporta transazioni sincrone e asincrone. Le sezioni seguenti spiegano come viene eseguito ogni tipo di transazione.
Transazioni sincrone
Le transazioni sincrone si bloccano finché non vengono eseguite sul nodo e il chiamante non riceve una risposta per la transazione. La figura seguente mostra come viene eseguita una transazione sincrona:
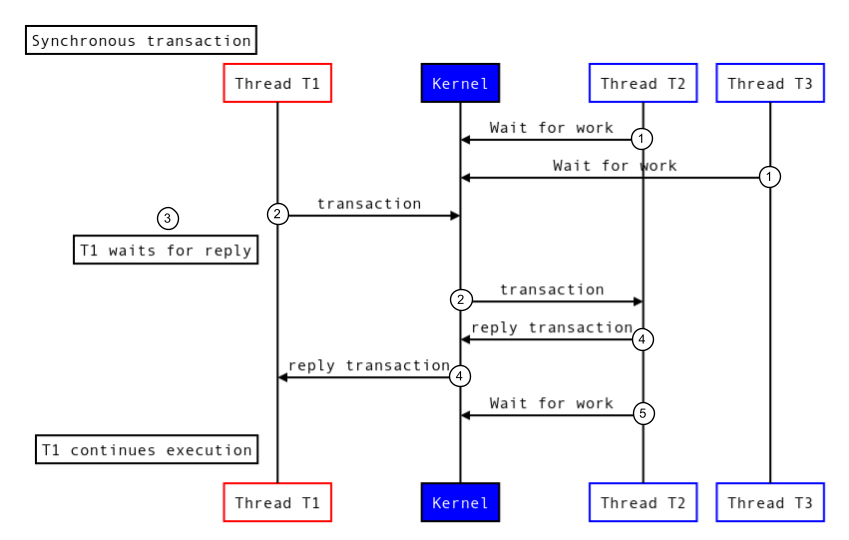
Figura 1. Transazione sincrona.
Per eseguire una transazione sincrona, Binder esegue le seguenti operazioni:
- I thread nel threadpool di destinazione (T2 e T3) chiamano il driver del kernel per attendere il lavoro in entrata.
- Il kernel riceve una nuova transazione e riattiva un thread (T2) nel processo di destinazione per gestire la transazione.
- Il thread chiamante (T1) si blocca e attende una risposta.
- Il processo di destinazione esegue la transazione e restituisce una risposta.
- Il thread nel processo di destinazione (T2) richiama il driver del kernel per attendere un nuovo lavoro.
Transazioni asincrone
Le transazioni asincrone non si bloccano per il completamento; il thread chiamante si sblocca non appena la transazione viene passata al kernel. La figura seguente mostra come viene eseguita una transazione asincrona:
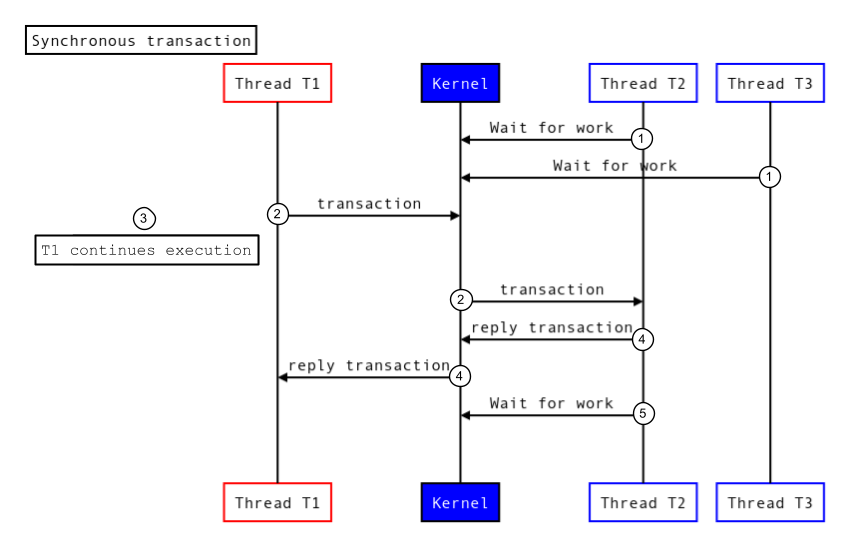
Figura 2. Transazione asincrona.
- I thread nel threadpool di destinazione (T2 e T3) chiamano il driver del kernel per attendere il lavoro in entrata.
- Il kernel riceve una nuova transazione e riattiva un thread (T2) nel processo di destinazione per gestire la transazione.
- Il thread chiamante (T1) continua l'esecuzione.
- Il processo di destinazione esegue la transazione e restituisce una risposta.
- Il thread nel processo di destinazione (T2) richiama il driver del kernel per attendere un nuovo lavoro.
Identificare una funzione sincrona o asincrona
Le funzioni contrassegnate come oneway nel file AIDL sono asincrone. Ad esempio:
oneway void someCall();
Se una funzione non è contrassegnata come oneway, è una funzione sincrona, anche se la funzione restituisce void.
Serializzazione delle transazioni asincrone
Binder serializza le transazioni asincrone da qualsiasi singolo nodo. La figura seguente mostra come Binder serializza le transazioni asincrone:
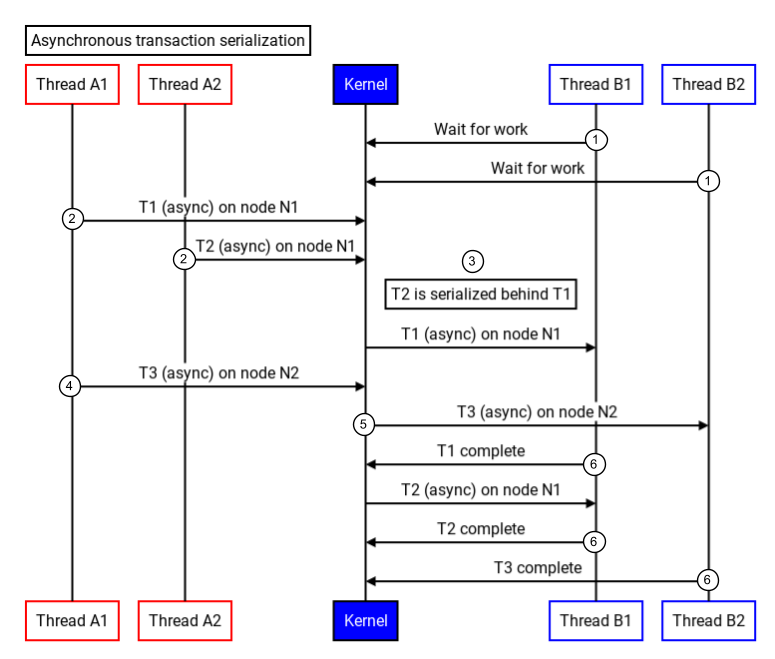
Figura 3. Serializzazione delle transazioni asincrone.
- I thread nel threadpool di destinazione (B1 e B2) chiamano il driver del kernel per attendere il lavoro in entrata.
- Due transazioni (T1 e T2) sullo stesso nodo (N1) vengono inviate al kernel.
- Il kernel riceve nuove transazioni e, poiché provengono dallo stesso nodo (N1), le serializza.
- Un'altra transazione su un nodo diverso (N2) viene inviata al kernel.
- Il kernel riceve la terza transazione e riattiva un thread (B2) nel processo di destinazione per gestire la transazione.
- I processi di destinazione eseguono ogni transazione e restituiscono una risposta.
Transazioni nidificate
Le transazioni sincrone possono essere nidificate; un thread che gestisce una transazione può emettere una nuova transazione. La transazione nidificata può essere a un processo diverso o allo stesso processo da cui hai ricevuto la transazione corrente. Questo comportamento imita le chiamate di funzioni locali. Ad esempio, supponiamo di avere una funzione con funzioni nidificate:
def outer_function(x):
def inner_function(y):
def inner_inner_function(z):
Se si tratta di chiamate locali, vengono eseguite sullo stesso thread.
Nello specifico, se il chiamante di inner_function è anche il processo
che ospita il nodo che implementa inner_inner_function, la chiamata a
inner_inner_function viene eseguita sullo stesso thread.
La figura seguente mostra come Binder gestisce le transazioni nidificate:
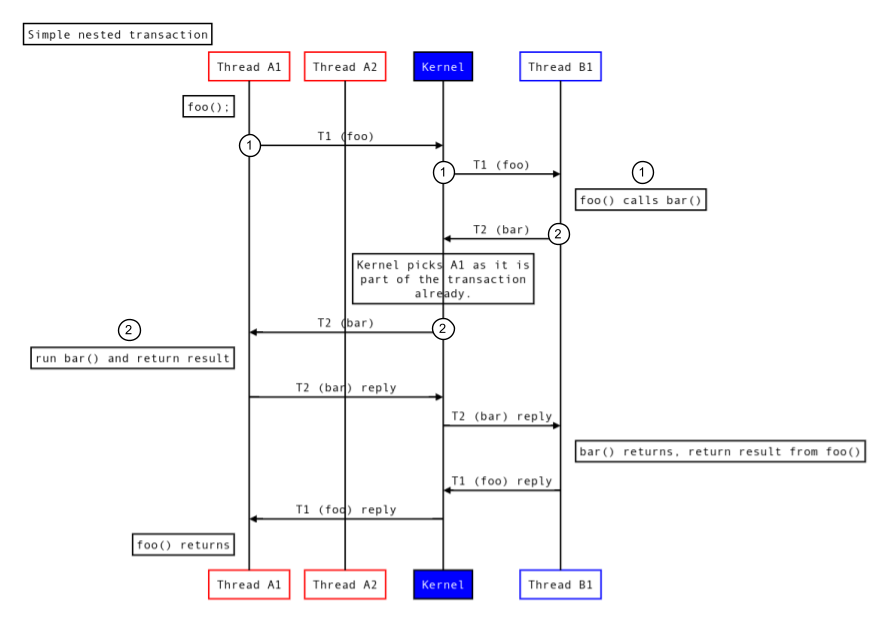
Figura 4. Transazioni nidificate.
- Il thread A1 richiede l'esecuzione di
foo(). - Nell'ambito di questa richiesta, il thread B1 esegue
bar()che A esegue sullo stesso thread A1.
La figura seguente mostra l'esecuzione del thread se il nodo che implementa bar() si trova in un processo diverso:
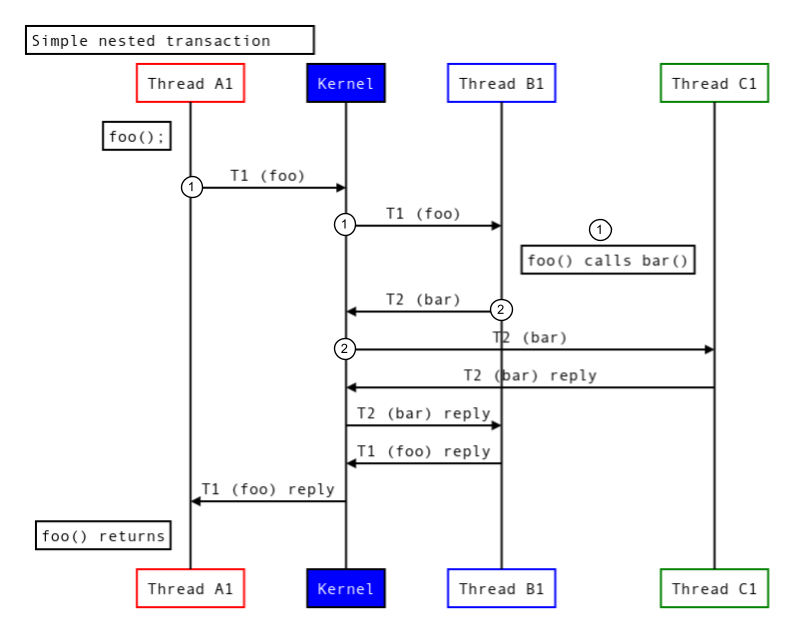
Figura 5. Transazioni nidificate in processi diversi.
- Il thread A1 richiede l'esecuzione di
foo(). - Nell'ambito di questa richiesta, il thread B1 esegue
bar()che viene eseguito in un altro thread C1.
La figura seguente mostra come il thread riutilizza lo stesso processo in qualsiasi punto della catena di transazioni:
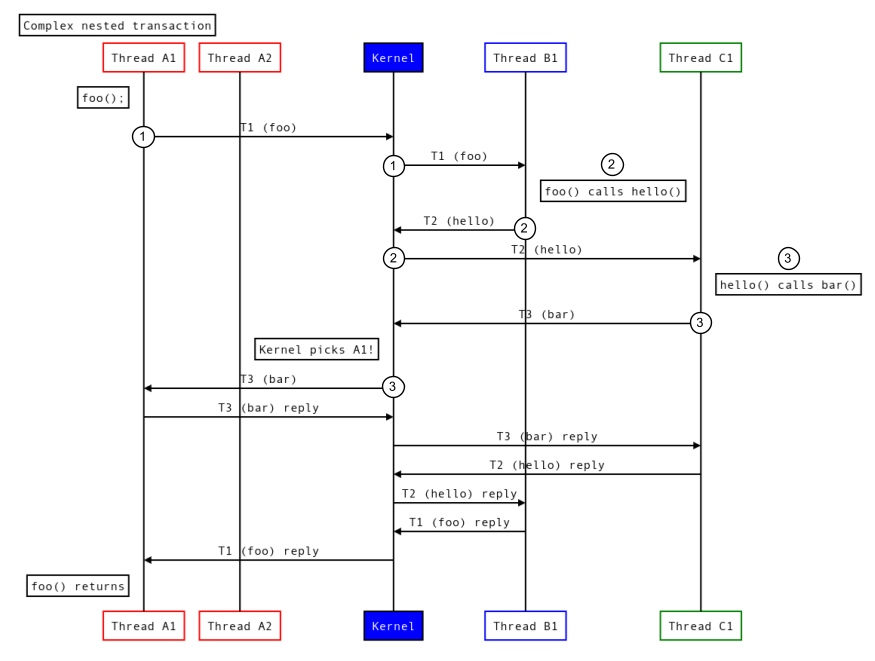
Figura 6. Transazioni nidificate che riutilizzano un thread.
- Il processo A chiama il processo B.
- Il processo B chiama il processo C.
- Il processo C effettua una chiamata di nuovo al processo A e il kernel riutilizza il thread A1 nel processo A che fa parte della catena di transazioni.
Per le transazioni asincrone, la nidificazione non svolge un ruolo; il client non attende il risultato di una transazione asincrona, quindi non esiste la nidificazione. Se il gestore di una transazione asincrona effettua una chiamata al processo che ha emesso la transazione asincrona, la transazione può essere gestita su qualsiasi thread libero in quel processo.
Evitare i deadlock
L'immagine seguente mostra un deadlock comune:
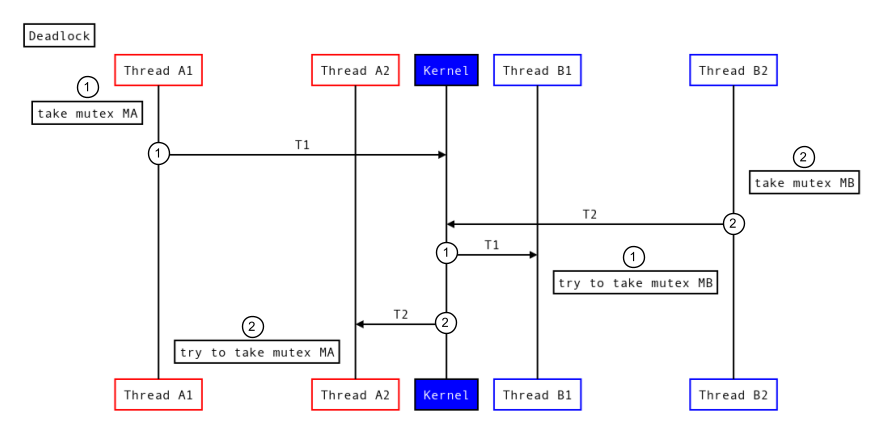
Figura 7. Deadlock comune.
- Il processo A acquisisce il mutex MA ed effettua una chiamata di Binder (T1) al processo B, che tenta anche di acquisire il mutex MB.
- Contemporaneamente, il processo B acquisisce il mutex MB ed effettua una chiamata di Binder (T2) al processo A, che tenta di acquisire il mutex MA.
Se queste transazioni si sovrappongono, ogni transazione potrebbe potenzialmente acquisire un mutex nel proprio processo mentre attende che l'altro processo rilasci un mutex, con conseguente deadlock.
Per evitare i deadlock durante l'utilizzo di Binder, non mantenere alcun blocco durante l'esecuzione di una chiamata di Binder.
Regole di ordinamento dei blocchi e deadlock
In un singolo ambiente di esecuzione, il deadlock viene spesso evitato con una regola di ordinamento dei blocchi. Tuttavia, quando si effettuano chiamate tra processi e tra codebase, soprattutto quando il codice viene aggiornato, è impossibile mantenere e coordinare una regola di ordinamento.
Singolo mutex e deadlock
Con le transazioni nidificate, il processo B può richiamare direttamente lo stesso thread nel processo A che contiene un mutex. Pertanto, a causa di una ricorsione imprevista, è comunque possibile ottenere un deadlock con un singolo mutex.
Chiamate asincrone e deadlock
Sebbene le chiamate di Binder asincrone non si blocchino per il completamento, è consigliabile evitare di mantenere un blocco per le chiamate asincrone. Se mantieni un blocco, potresti riscontrare problemi di blocco se una chiamata unidirezionale viene accidentalmente modificata in una chiamata sincrona.
Singolo thread di Binder e deadlock
Il modello di transazione di Binder consente la rientrabilità, quindi anche se un processo ha un singolo thread di Binder, è comunque necessario il blocco. Ad esempio, supponiamo di eseguire l'iterazione su un elenco in un processo A a thread singolo. Per ogni elemento dell'elenco, effettui una transazione di Binder in uscita. Se l'implementazione della funzione che stai chiamando effettua una nuova transazione di Binder a un nodo ospitato nel processo A, la transazione viene gestita sullo stesso thread che stava eseguendo l'iterazione dell'elenco. Se l'implementazione di questa transazione modifica lo stesso elenco, potresti riscontrare problemi quando continui a eseguire l'iterazione dell'elenco in un secondo momento.
Configurare le dimensioni del threadpool
Quando un servizio ha più client, l'aggiunta di altri thread al threadpool può ridurre la contesa e gestire più chiamate in parallelo. Dopo aver gestito correttamente la concorrenza, puoi aggiungere altri thread. Un problema che può essere causato dall'aggiunta di altri thread è che alcuni thread potrebbero non essere utilizzati durante i carichi di lavoro inattivi.
I thread vengono generati su richiesta fino a un massimo configurato. Dopo che un thread di Binder è stato generato, rimane attivo fino alla fine del processo che lo ospita.
La libreria libbinder ha un valore predefinito di 15 thread. Utilizza setThreadPoolMaxThreadCount per modificare questo valore:
using ::android::ProcessState;
ProcessState::self()->setThreadPoolMaxThreadCount(size_t maxThreads);