
En esta página, se proporciona una descripción general de cómo implementar un controlador de la API de Neural Networks (NNAPI). Para obtener más detalles, consulta la documentación que se encuentra en los archivos de definición del HAL en hardware/interfaces/neuralnetworks.
En frameworks/ml/nn/driver/sample, se incluye una implementación de muestra del controlador.
Para obtener más información sobre la API de Neural Networks, consulta API de Neural Networks.
HAL de Neural Networks
La HAL de redes neuronales (NN) define una abstracción de los distintos dispositivos, como las unidades de procesamiento gráfico (GPU) y los procesadores de señales digitales (DSP), que se encuentran en un producto (por ejemplo, un teléfono o una tablet). Los controladores de estos dispositivos deben cumplir con la HAL de NN. La interfaz se especifica en los archivos de definición de HAL en hardware/interfaces/neuralnetworks.
El flujo general de la interfaz entre el framework y un controlador se muestra en la figura 1.
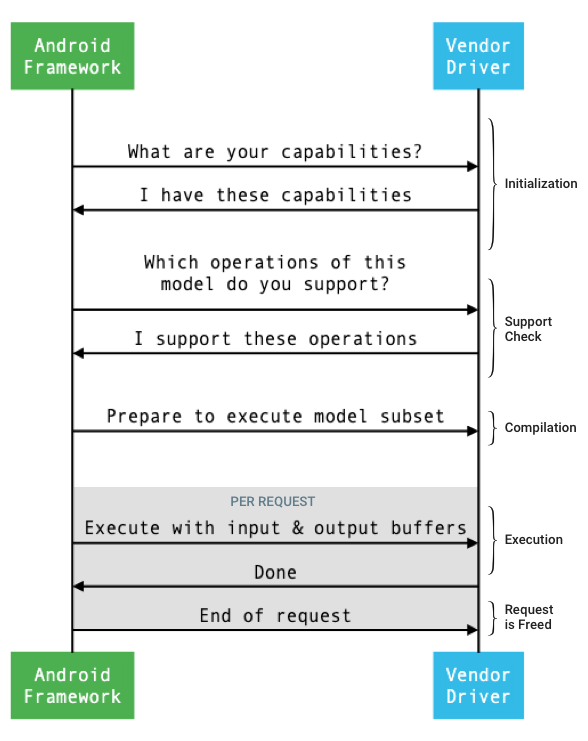
Figura 1: Flujo de redes neuronales
Inicialización
Durante la inicialización, el framework consulta las capacidades del controlador con IDevice::getCapabilities_1_3.
La estructura @1.3::Capabilities incluye todos los tipos de datos y representa el rendimiento no relajado con un vector.
Para determinar cómo asignar los cálculos a los dispositivos disponibles, el framework usa las capacidades para comprender con qué rapidez y eficiencia energética puede realizar una ejecución cada controlador. Para proporcionar esta información, el controlador debe proporcionar cifras de rendimiento estandarizadas basadas en la ejecución de cargas de trabajo de referencia.
Para determinar los valores que el controlador devuelve en respuesta a IDevice::getCapabilities_1_3, usa la app de comparativas de la NNAPI para medir el rendimiento de los tipos de datos correspondientes. Se recomiendan los modelos MobileNet v1 y v2, asr_float y tts_float para medir el rendimiento de los valores de punto flotante de 32 bits, y los modelos cuantificados MobileNet v1 y v2 para los valores cuantificados de 8 bits. Para obtener más información, consulta el Conjunto de pruebas de aprendizaje automático de Android.
En Android 9 y versiones anteriores, la estructura Capabilities incluye información sobre el rendimiento del controlador solo para tensores de punto flotante y cuantificados, y no incluye tipos de datos escalares.
Como parte del proceso de inicialización, el framework puede consultar más información con IDevice::getType, IDevice::getVersionString, IDevice:getSupportedExtensions y IDevice::getNumberOfCacheFilesNeeded.
Entre los reinicios del producto, el framework espera que todas las consultas descritas en esta sección siempre informen los mismos valores para un controlador determinado. De lo contrario, es posible que una app que use ese controlador muestre un rendimiento reducido o un comportamiento incorrecto.
Compilación
El framework determina qué dispositivos usar cuando recibe una solicitud de una app. En Android 10, las apps pueden descubrir y especificar los dispositivos que elige el framework. Para obtener más información, consulta Descubrimiento y asignación de dispositivos.
En el momento de la compilación del modelo, el framework envía el modelo a cada controlador candidato llamando a IDevice::getSupportedOperations_1_3.
Cada controlador devuelve un array de valores booleanos que indica qué operaciones del modelo son compatibles. Un controlador puede determinar que no puede admitir una operación determinada por varios motivos. Por ejemplo:
- El controlador no admite el tipo de datos.
- El controlador solo admite operaciones con parámetros de entrada específicos. Por ejemplo, un controlador podría admitir operaciones de convolución de 3x3 y 5x5, pero no de 7x7.
- El controlador tiene restricciones de memoria que le impiden controlar gráficos o entradas grandes.
Durante la compilación, los operandos internos, de entrada y de salida del modelo, como se describe en OperandLifeTime, pueden tener dimensiones o rango desconocidos. Para obtener más información, consulta Forma del tensor de salida.
El framework indica a cada controlador seleccionado que se prepare para ejecutar un subconjunto del modelo llamando a IDevice::prepareModel_1_3.
Luego, cada controlador compila su subconjunto. Por ejemplo, un controlador puede generar código o crear una copia reordenada de los pesos. Dado que puede haber una cantidad significativa de tiempo entre la compilación del modelo y la ejecución de las solicitudes, no se deben asignar recursos, como grandes fragmentos de memoria del dispositivo, durante la compilación.
Si la operación se realiza correctamente, el controlador devuelve un identificador @1.3::IPreparedModel. Si el controlador devuelve un código de error cuando prepara su subconjunto del modelo, el framework ejecuta todo el modelo en la CPU.
Para reducir el tiempo que se usa para la compilación cuando se inicia una app, un controlador puede almacenar en caché los artefactos de compilación. Para obtener más información, consulta Almacenamiento en caché de la compilación.
Ejecución
Cuando una app le solicita al framework que ejecute una solicitud, el framework llama al método IPreparedModel::executeSynchronously_1_3 de HAL de forma predeterminada para realizar una ejecución síncrona en un modelo preparado.
Una solicitud también se puede ejecutar de forma asíncrona con el método execute_1_3, el método executeFenced (consulta Ejecución aislada) o con una ejecución en ráfaga.
Las llamadas de ejecución síncrona mejoran el rendimiento y reducen la sobrecarga de subprocesos en comparación con las llamadas asíncronas, ya que el control se devuelve al proceso de la app solo después de que se completa la ejecución. Esto significa que el controlador no necesita un mecanismo independiente para notificar al proceso de la app que se completó una ejecución.
Con el método asíncrono execute_1_3, el control vuelve al proceso de la app después de que se inicia la ejecución, y el controlador debe notificar al framework cuando se completa la ejecución, con @1.3::IExecutionCallback.
El parámetro Request que se pasa al método execute enumera los operandos de entrada y salida que se usan para la ejecución. La memoria que almacena los datos del operando debe usar el orden de fila principal con la primera dimensión que itera más lentamente y no tener relleno al final de ninguna fila. Para obtener más información sobre los tipos de operandos, consulta Operandos.
En el caso de los controladores de HAL de NN 1.2 o versiones posteriores, cuando se completa una solicitud, se devuelven al framework el estado de error, la forma de salida y la información de sincronización. Durante la ejecución, los operandos internos o de salida del modelo pueden tener una o más dimensiones desconocidas o una clasificación desconocida. Cuando al menos un operando de salida tiene una dimensión o un rango desconocidos, el controlador debe devolver información de salida con tamaño dinámico.
En el caso de los controladores con NN HAL 1.1 o versiones anteriores, solo se devuelve el estado de error cuando se completa una solicitud. Las dimensiones de los operandos de entrada y salida deben especificarse por completo para que la ejecución se complete correctamente. Los operandos internos pueden tener una o más dimensiones desconocidas, pero deben tener un rango especificado.
En el caso de las solicitudes del usuario que abarcan varios controladores, el framework es responsable de reservar memoria intermedia y de secuenciar las llamadas a cada controlador.
Se pueden iniciar varias solicitudes en paralelo en el mismo @1.3::IPreparedModel.
El controlador puede ejecutar solicitudes en paralelo o serializar las ejecuciones.
El framework puede pedirle a un controlador que conserve más de un modelo preparado. Por ejemplo, prepara el modelo m1, prepara m2, ejecuta la solicitud r1 en m1, ejecuta r2 en m2, ejecuta r3 en m1, ejecuta r4 en m2, libera (se describe en Limpieza) m1 y libera m2.
Para evitar una primera ejecución lenta que podría generar una mala experiencia del usuario (por ejemplo, un primer fotograma con interrupciones), el controlador debe realizar la mayoría de las inicializaciones en la fase de compilación. La inicialización en la primera ejecución debe limitarse a las acciones que afectan negativamente el estado del sistema cuando se realizan de forma anticipada, como reservar búferes temporales grandes o aumentar la velocidad de reloj de un dispositivo. Los controladores que solo pueden preparar una cantidad limitada de modelos simultáneos tal vez deban realizar su inicialización en la primera ejecución.
En Android 10 y versiones posteriores, en los casos en que se ejecutan varias ejecuciones con el mismo modelo preparado en rápida sucesión, el cliente puede optar por usar un objeto de ráfaga de ejecución para comunicarse entre los procesos de la app y del controlador. Para obtener más información, consulta Ejecuciones en ráfaga y colas de mensajes rápidos.
Para mejorar el rendimiento de varias ejecuciones en rápida sucesión, el controlador puede conservar búferes temporales o aumentar las velocidades de reloj. Se recomienda crear un subproceso de vigilancia para liberar recursos si no se crean solicitudes nuevas después de un período fijo.
Forma de salida
Para las solicitudes en las que uno o más operandos de salida no tienen todas las dimensiones especificadas, el controlador debe proporcionar una lista de formas de salida que contenga la información de dimensión para cada operando de salida después de la ejecución. Para obtener más información sobre las dimensiones, consulta OutputShape.
Si una ejecución falla debido a un búfer de salida demasiado pequeño, el controlador debe indicar qué operandos de salida tienen un tamaño de búfer insuficiente en la lista de formas de salida y debe informar la mayor cantidad posible de información dimensional, usando cero para las dimensiones desconocidas.
Tiempos
En Android 10, una app puede solicitar el tiempo de ejecución si especificó un solo dispositivo para usar durante el proceso de compilación. Para obtener más información, consulta MeasureTiming y Descubrimiento y asignación de dispositivos.
En este caso, un controlador de HAL de NN 1.2 debe medir la duración de la ejecución o informar UINT64_MAX (para indicar que la duración no está disponible) cuando se ejecuta una solicitud. El controlador debe minimizar cualquier penalización de rendimiento que resulte de la medición de la duración de la ejecución.
El controlador informa las siguientes duraciones en microsegundos en la estructura Timing:
- Tiempo de ejecución en el dispositivo: No incluye el tiempo de ejecución en el controlador, que se ejecuta en el procesador del host.
- Tiempo de ejecución en el controlador: Incluye el tiempo de ejecución en el dispositivo.
Estas duraciones deben incluir el tiempo en que se suspende la ejecución, por ejemplo, cuando otras tareas la interrumpen o cuando espera que un recurso esté disponible.
Cuando no se le pide al controlador que mida la duración de la ejecución o cuando hay un error de ejecución, el controlador debe informar las duraciones como UINT64_MAX. Incluso cuando se le pide al controlador que mida la duración de la ejecución, puede informar UINT64_MAX para el tiempo en el dispositivo, el tiempo en el controlador o ambos. Cuando el conductor informa ambas duraciones como un valor distinto de UINT64_MAX, el tiempo de ejecución en el conductor debe ser igual o superior al tiempo en el dispositivo.
Ejecución cercada
En Android 11, NNAPI permite que las ejecuciones esperen una lista de identificadores sync_fence y, de manera opcional, muestren un objeto sync_fence, que se señala cuando se completa la ejecución. De esta manera, se reduce la sobrecarga de modelos de secuencia pequeños y los casos de uso de transmisión. La ejecución cercada también mejora la eficiencia de la interoperabilidad con otros componentes que pueden indicar o esperar sync_fence. Para obtener más información sobre sync_fence, consulta Marco de trabajo de sincronización.
En una ejecución cercada, el framework llama al método IPreparedModel::executeFenced para iniciar una ejecución asíncrona cercada en un modelo preparado con un vector de barreras de sincronización para esperar. Si la tarea asíncrona finaliza antes de que se muestre la llamada, se puede mostrar un identificador vacío para sync_fence. También se debe devolver un objeto IFencedExecutionCallback para permitir que el framework consulte el estado de error y la información de duración.
Una vez que se completa una ejecución, se pueden consultar los siguientes dos valores de sincronización que miden la duración de la ejecución a través de IFencedExecutionCallback::getExecutionInfo.
timingLaunched: Duración desde que se llama aexecuteFencedhasta queexecuteFencedseñala elsyncFencedevuelto.timingFenced: Duración desde que se marcan todas las barreras de sincronización que espera la ejecución hasta queexecuteFencedmarca elsyncFencedevuelto.
Flujo de control
En el caso de los dispositivos que ejecutan Android 11 o versiones posteriores, la NNAPI incluye dos operaciones de control de flujo, IF y WHILE, que toman otros modelos como argumentos y los ejecutan de forma condicional (IF) o repetida (WHILE). Para obtener más información sobre cómo implementar esto, consulta Control de flujo.
Calidad de servicio
En Android 11, la NNAPI incluye una calidad de servicio (QoS) mejorada, ya que permite que una app indique las prioridades relativas de sus modelos, el tiempo de espera máximo para que se prepare un modelo y el tiempo de espera máximo para que se complete una ejecución. Para obtener más información, consulta Calidad del servicio.
Limpieza
Cuando una app termina de usar un modelo preparado, el framework libera su referencia al objeto @1.3::IPreparedModel. Cuando ya no se hace referencia al objeto IPreparedModel, se destruye automáticamente en el servicio de controlador que lo creó. En este momento, se pueden recuperar los recursos específicos del modelo en la implementación del destructor del controlador. Si el servicio de controlador desea que el objeto IPreparedModel se destruya automáticamente cuando el cliente ya no lo necesite, no debe conservar ninguna referencia al objeto IPreparedModel después de que se haya devuelto el objeto IPreparedeModel a través de IPreparedModelCallback::notify_1_3.
Uso de CPU
Se espera que los controladores usen la CPU para configurar los cálculos. Los controladores no deben usar la CPU para realizar cálculos de grafos, ya que esto interfiere con la capacidad del framework para asignar trabajo correctamente. El controlador debe informar al framework las partes que no puede controlar y dejar que el framework controle el resto.
El framework proporciona una implementación de CPU para todas las operaciones de la NNAPI, excepto las operaciones definidas por el proveedor. Para obtener más información, consulta Extensiones de proveedores.
Las operaciones introducidas en Android 10 (nivel de API 29) solo tienen una implementación de CPU de referencia para verificar que las pruebas de CTS y VTS sean correctas. Se prefieren las implementaciones optimizadas incluidas en los frameworks de aprendizaje automático para dispositivos móviles por sobre la implementación de la CPU de la NNAPI.
Funciones de utilidad
La base de código de la NNAPI incluye funciones de utilidad que pueden usar los servicios de controladores.
El archivo
frameworks/ml/nn/common/include/Utils.h
contiene diversas funciones de utilidad, como las que se usan para el registro y
para convertir entre diferentes versiones de NN HAL.
VLogging:
VLOGes una macro de wrapper alrededor deLOGde Android que solo registra el mensaje si se establece la etiqueta adecuada en la propiedaddebug.nn.vlog. Se debe llamar ainitVLogMask()antes de cualquier llamada aVLOG. La macroVLOG_IS_ONse puede usar para verificar siVLOGestá habilitado actualmente, lo que permite omitir el código de registro complicado si no es necesario. El valor de la propiedad debe ser uno de los siguientes:- Es una cadena vacía que indica que no se debe realizar ningún registro.
- El token
1oall, que indica que se debe realizar todo el registro. - Es una lista de etiquetas, delimitadas por espacios, comas o dos puntos, que indican qué registros se deben realizar. Las etiquetas son
compilation,cpuexe,driver,execution,managerymodel.
compliantWithV1_*: Devuelvetruesi un objeto de HAL de NN se puede convertir al mismo tipo de una versión diferente de HAL sin perder información. Por ejemplo, llamar acompliantWithV1_0en unV1_2::Modeldevuelvefalsesi el modelo incluye tipos de operación introducidos en NN HAL 1.1 o NN HAL 1.2.convertToV1_*: Convierte un objeto de HAL de NN de una versión a otra. Se registra una advertencia si la conversión genera una pérdida de información (es decir, si la nueva versión del tipo no puede representar completamente el valor).Capacidades: Las funciones
nonExtensionOperandPerformanceyupdatese pueden usar para ayudar a compilar el campoCapabilities::operandPerformance.Consultar propiedades de tipos:
isExtensionOperandType,isExtensionOperationType,nonExtensionSizeOfData,nonExtensionOperandSizeOfData,nonExtensionOperandTypeIsScalar,tensorHasUnspecifiedDimensions.
El archivo frameworks/ml/nn/common/include/ValidateHal.h contiene funciones de utilidad para validar que un objeto HAL de NN sea válido según la especificación de su versión de HAL.
validate*: Devuelvetruesi el objeto de HAL de NN es válido según la especificación de la versión de HAL. No se validan los tipos de OEM ni los tipos de extensión. Por ejemplo,validateModeldevuelvefalsesi el modelo contiene una operación que hace referencia a un índice de operando que no existe o una operación que no se admite en esa versión del HAL.
El archivo frameworks/ml/nn/common/include/Tracing.h contiene macros para simplificar la adición de información de systrace al código de redes neuronales.
Para ver un ejemplo, consulta las invocaciones de la macro NNTRACE_* en el controlador de muestra.
El archivo frameworks/ml/nn/common/include/GraphDump.h contiene una función de utilidad para volcar el contenido de un Model en formato gráfico con fines de depuración.
graphDump: Escribe una representación del modelo en formato Graphviz (.dot) en el flujo especificado (si se proporciona) o en el registro (si no se proporciona ningún flujo).
Validación
Para probar tu implementación de la NNAPI, usa las pruebas de VTS y CTS incluidas en el framework de Android. VTS ejercita tus controladores directamente (sin usar el framework), mientras que CTS los ejercita indirectamente a través del framework. Estas pruebas verifican cada método de la API y comprueban que todas las operaciones admitidas por los controladores funcionen correctamente y proporcionen resultados que cumplan con los requisitos de precisión.
Los requisitos de precisión en CTS y VTS para la NNAPI son los siguientes:
Números de punto flotante: abs(esperado - real) <= atol + rtol * abs(esperado); donde:
- Para fp32, atol = 1e-5f, rtol = 5.0f * 1.1920928955078125e-7
- Para fp16, atol = rtol = 5.0f * 0.0009765625f
Cuantificado: Desviación de uno (excepto para
mobilenet_quantized, que tiene una desviación de tres)Booleano: Coincidencia exacta
Una forma en que las pruebas del CTS prueban la NNAPI es generando gráficos seudoaleatorios fijos que se usan para probar y comparar los resultados de ejecución de cada controlador con la implementación de referencia de la NNAPI. En el caso de los controladores con HAL de NN 1.2 o versiones posteriores, si los resultados no cumplen con los criterios de precisión, el CTS informa un error y vuelca un archivo de especificaciones para el modelo fallido en /data/local/tmp para la depuración.
Para obtener más detalles sobre los criterios de precisión, consulta TestRandomGraph.cpp y TestHarness.h.
Prueba de Fuzz
El objetivo de las pruebas de fuzzing es encontrar fallas, aserciones, incumplimientos de memoria o comportamientos indefinidos generales en el código que se está probando debido a factores como entradas inesperadas. Para las pruebas de Fuzz de NNAPI, Android usa pruebas basadas en libFuzzer, que son eficientes para las pruebas de Fuzz porque usan la cobertura de líneas de casos de prueba anteriores para generar nuevas entradas aleatorias. Por ejemplo, libFuzzer favorece los casos de prueba que se ejecutan en líneas de código nuevas. Esto reduce en gran medida el tiempo que tardan las pruebas en encontrar código problemático.
Para realizar pruebas de fuzz y validar la implementación del controlador, modifica frameworks/ml/nn/runtime/test/android_fuzzing/DriverFuzzTest.cpp en la utilidad de prueba libneuralnetworks_driver_fuzzer que se encuentra en AOSP para incluir el código del controlador. Para obtener más información sobre las pruebas de fuzzing de NNAPI, consulta frameworks/ml/nn/runtime/test/android_fuzzing/README.md.
Seguridad
Dado que los procesos de la app se comunican directamente con el proceso de un controlador, los controladores deben validar los argumentos de las llamadas que reciben. VTS verifica esta validación. El código de validación se encuentra en frameworks/ml/nn/common/include/ValidateHal.h.
Los conductores también deben asegurarse de que las apps no interfieran con otras cuando se usa el mismo dispositivo.
Android Machine Learning Test Suite
El paquete de pruebas de aprendizaje automático de Android (MLTS) es una comparativa de NNAPI incluida en CTS y VTS para validar la precisión de los modelos reales en dispositivos de proveedores. La comparativa evalúa la latencia y la precisión, y compara los resultados de los controladores con los resultados obtenidos con TF Lite ejecutándose en la CPU, para el mismo modelo y los mismos conjuntos de datos. Esto garantiza que la precisión de un controlador no sea peor que la implementación de referencia de la CPU.
Los desarrolladores de la plataforma de Android también usan MLTS para evaluar la latencia y la precisión de los controladores.
La comparativa de la NNAPI se puede encontrar en dos proyectos en AOSP:
platform/test/mlts/benchmark(app de referencia)platform/test/mlts/models(modelos y conjuntos de datos)
Modelos y conjuntos de datos
La comparativa de la NNAPI usa los siguientes modelos y conjuntos de datos.
- MobileNetV1 cuantificada como float y u8 en diferentes tamaños, ejecutada en un subconjunto pequeño (1,500 imágenes) del conjunto de datos de Open Images v4.
- MobileNetV2 en formato de coma flotante y cuantificado en u8 en diferentes tamaños, ejecutado en un subconjunto pequeño (1,500 imágenes) del conjunto de datos de Open Images v4.
- Modelo acústico basado en la memoria a corto plazo de larga duración (LSTM) para la conversión de texto a voz, ejecutado en un pequeño subconjunto del conjunto de datos de CMU Arctic.
- Modelo acústico basado en LSTM para el reconocimiento de voz automático, ejecutado en un pequeño subconjunto del conjunto de datos de LibriSpeech.
Para obtener más información, consulta platform/test/mlts/models
Pruebas de esfuerzo
El paquete de pruebas de aprendizaje automático de Android incluye una serie de pruebas de fallas para validar la resiliencia de los controladores en condiciones de uso intenso o en casos extremos del comportamiento de los clientes.
Todas las pruebas de fallas proporcionan las siguientes funciones:
- Detección de bloqueos: Si el cliente de la NNAPI se bloquea durante una prueba, esta falla con el motivo de falla
HANGy el paquete de pruebas pasa a la siguiente prueba. - Detección de fallas del cliente de NNAPI: Las pruebas sobreviven a las fallas del cliente y fallan con el motivo de falla
CRASH. - Detección de fallas del controlador: Las pruebas pueden detectar una falla del controlador que provoque un error en una llamada a la NNAPI. Ten en cuenta que es posible que haya fallas en los procesos del controlador que no provoquen un error de NNAPI ni que la prueba falle. Para cubrir este tipo de fallas, se recomienda ejecutar el comando
tailen el registro del sistema para detectar errores o fallas relacionados con el controlador. - Segmentación para todos los aceleradores disponibles: Las pruebas se ejecutan en todos los controladores disponibles.
Todas las pruebas de fallas tienen los siguientes cuatro resultados posibles:
SUCCESS: La ejecución se completó sin errores.FAILURE: La ejecución falló. Por lo general, se debe a una falla durante la prueba de un modelo, lo que indica que el controlador no pudo compilar ni ejecutar el modelo.HANG: El proceso de prueba dejó de responder.CRASH: Se produjo una falla en el proceso de prueba.
Para obtener más información sobre las pruebas de estrés y una lista completa de las pruebas de fallas, consulta platform/test/mlts/benchmark/README.txt.
Usa MLTS
Para usar el MLTS, haz lo siguiente:
- Conecta un dispositivo de destino a tu estación de trabajo y asegúrate de que se pueda acceder a él a través de adb.
Exporta la variable de entorno
ANDROID_SERIALdel dispositivo de destino si hay más de un dispositivo conectado. cden el directorio del código fuente de nivel superior de Android.source build/envsetup.sh lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available. ./test/mlts/benchmark/build_and_run_benchmark.shCuando finalice la ejecución de la comparativa, los resultados se mostrarán en el formato de una página HTML y se pasarán a
xdg-open.
Para obtener más información, consulta platform/test/mlts/benchmark/README.txt
Versiones de HAL de redes neuronales
En esta sección, se describen los cambios que se introdujeron en las versiones de Android y la HAL de redes neuronales.
Android 11
Android 11 presenta la HAL de NN 1.3, que incluye los siguientes cambios destacados.
- Se agregó compatibilidad con la cuantización de 8 bits con firma en la NNAPI. Agrega el tipo de operando
TENSOR_QUANT8_ASYMM_SIGNED. Los controladores con NN HAL 1.3 que admiten operaciones con cuantización sin signo también deben admitir las variantes con signo de esas operaciones. Cuando se ejecutan versiones con y sin firma de la mayoría de las operaciones cuantificadas, los controladores deben producir los mismos resultados con una diferencia de hasta 128. Existen cinco excepciones a este requisito:CAST,HASHTABLE_LOOKUP,LSH_PROJECTION,PAD_V2yQUANTIZED_16BIT_LSTM. La operaciónQUANTIZED_16BIT_LSTMno admite operandos firmados, y las otras cuatro operaciones admiten la cuantificación firmada, pero no requieren que los resultados sean los mismos. - Compatibilidad con ejecuciones cercadas en las que el framework llama al método
IPreparedModel::executeFencedpara iniciar una ejecución asíncrona cercada en un modelo preparado con un vector de barreras de sincronización para esperar. Para obtener más información, consulta Ejecución aislada. - Compatibilidad con el flujo de control. Se agregan las operaciones
IFyWHILE, que toman otros modelos como argumentos y los ejecutan de forma condicional (IF) o repetida (WHILE). Para obtener más información, consulta Flujo de control. - Calidad de servicio (QoS) mejorada, ya que las apps pueden indicar las prioridades relativas de sus modelos, el tiempo de espera máximo para que se prepare un modelo y el tiempo de espera máximo para que se complete una ejecución. Para obtener más información, consulta Calidad del servicio.
- Compatibilidad con dominios de memoria que proporcionan interfaces asignables para búferes administrados por controladores. Esto permite pasar memorias nativas del dispositivo entre ejecuciones, lo que evita la transformación y la copia innecesarias de datos entre ejecuciones consecutivas dentro del mismo controlador. Para obtener más información, consulta Dominios de memoria.
Android 10
Android 10 presenta NN HAL 1.2, que incluye los siguientes cambios destacados.
- La estructura
Capabilitiesincluye todos los tipos de datos, incluidos los tipos de datos escalares, y representa el rendimiento no relajado con un vector en lugar de campos con nombre. - Los métodos
getVersionStringygetTypepermiten que el framework recupere el tipo de dispositivo (DeviceType) y la información de la versión. Consulta Descubrimiento y asignación de dispositivos. - De forma predeterminada, se llama al método
executeSynchronouslypara realizar una ejecución de forma síncrona. El métodoexecute_1_2le indica al framework que realice una ejecución de forma asíncrona. Consulta Ejecución. - El parámetro
MeasureTimingparaexecuteSynchronously,execute_1_2y la ejecución en ráfaga especifica si el controlador debe medir la duración de la ejecución. Los resultados se informan en la estructuraTiming. Consulta Timing. - Se admite la ejecución cuando uno o más operandos de salida tienen una dimensión o un rango desconocidos. Consulta Forma de salida.
- Compatibilidad con extensiones del proveedor, que son colecciones de operaciones y tipos de datos definidos por el proveedor El controlador informa las extensiones admitidas a través del método
IDevice::getSupportedExtensions. Consulta Extensiones de proveedores. - Capacidad de un objeto de ráfaga para controlar un conjunto de ejecuciones de ráfaga con colas de mensajes rápidas (FMQ) para comunicarse entre los procesos de la app y del controlador, lo que reduce la latencia. Consulta Ejecuciones en ráfaga y colas de mensajes rápidos.
- Compatibilidad con AHardwareBuffer para permitir que el controlador realice ejecuciones sin copiar datos. Consulta AHardwareBuffer.
- Se mejoró la compatibilidad con el almacenamiento en caché de artefactos de compilación para reducir el tiempo que se usa para la compilación cuando se inicia una app. Consulta Almacenamiento en caché de compilación.
Android 10 introduce los siguientes tipos de operandos y operaciones.
-
ANEURALNETWORKS_BOOLANEURALNETWORKS_FLOAT16ANEURALNETWORKS_TENSOR_BOOL8ANEURALNETWORKS_TENSOR_FLOAT16ANEURALNETWORKS_TENSOR_QUANT16_ASYMMANEURALNETWORKS_TENSOR_QUANT16_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL
-
ANEURALNETWORKS_ABSANEURALNETWORKS_ARGMAXANEURALNETWORKS_ARGMINANEURALNETWORKS_AXIS_ALIGNED_BBOX_TRANSFORMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_RNNANEURALNETWORKS_BOX_WITH_NMS_LIMITANEURALNETWORKS_CASTANEURALNETWORKS_CHANNEL_SHUFFLEANEURALNETWORKS_DETECTION_POSTPROCESSINGANEURALNETWORKS_EQUALANEURALNETWORKS_EXPANEURALNETWORKS_EXPAND_DIMSANEURALNETWORKS_GATHERANEURALNETWORKS_GENERATE_PROPOSALSANEURALNETWORKS_GREATERANEURALNETWORKS_GREATER_EQUALANEURALNETWORKS_GROUPED_CONV_2DANEURALNETWORKS_HEATMAP_MAX_KEYPOINTANEURALNETWORKS_INSTANCE_NORMALIZATIONANEURALNETWORKS_LESSANEURALNETWORKS_LESS_EQUALANEURALNETWORKS_LOGANEURALNETWORKS_LOGICAL_ANDANEURALNETWORKS_LOGICAL_NOTANEURALNETWORKS_LOGICAL_ORANEURALNETWORKS_LOG_SOFTMAXANEURALNETWORKS_MAXIMUMANEURALNETWORKS_MINIMUMANEURALNETWORKS_NEGANEURALNETWORKS_NOT_EQUALANEURALNETWORKS_PAD_V2ANEURALNETWORKS_POWANEURALNETWORKS_PRELUANEURALNETWORKS_QUANTIZEANEURALNETWORKS_QUANTIZED_16BIT_LSTMANEURALNETWORKS_RANDOM_MULTINOMIALANEURALNETWORKS_REDUCE_ALLANEURALNETWORKS_REDUCE_ANYANEURALNETWORKS_REDUCE_MAXANEURALNETWORKS_REDUCE_MINANEURALNETWORKS_REDUCE_PRODANEURALNETWORKS_REDUCE_SUMANEURALNETWORKS_RESIZE_NEAREST_NEIGHBORANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_ROI_POOLINGANEURALNETWORKS_RSQRTANEURALNETWORKS_SELECTANEURALNETWORKS_SINANEURALNETWORKS_SLICEANEURALNETWORKS_SPLITANEURALNETWORKS_SQRTANEURALNETWORKS_TILEANEURALNETWORKS_TOPK_V2ANEURALNETWORKS_TRANSPOSE_CONV_2DANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_RNN
Android 10 presenta actualizaciones para muchas de las operaciones existentes. Las actualizaciones se relacionan principalmente con lo siguiente:
- Compatibilidad con el diseño de memoria NCHW
- Se agregó compatibilidad con tensores con un rango diferente de 4 en las operaciones de softmax y normalización.
- Compatibilidad con convoluciones dilatadas
- Compatibilidad con entradas con cuantización mixta en
ANEURALNETWORKS_CONCATENATION
En la siguiente lista, se muestran las operaciones que se modificaron en Android 10. Para obtener detalles completos sobre los cambios, consulta OperationCode en la documentación de referencia de la NNAPI.
ANEURALNETWORKS_ADDANEURALNETWORKS_AVERAGE_POOL_2DANEURALNETWORKS_BATCH_TO_SPACE_NDANEURALNETWORKS_CONCATENATIONANEURALNETWORKS_CONV_2DANEURALNETWORKS_DEPTHWISE_CONV_2DANEURALNETWORKS_DEPTH_TO_SPACEANEURALNETWORKS_DEQUANTIZEANEURALNETWORKS_DIVANEURALNETWORKS_FLOORANEURALNETWORKS_FULLY_CONNECTEDANEURALNETWORKS_L2_NORMALIZATIONANEURALNETWORKS_L2_POOL_2DANEURALNETWORKS_LOCAL_RESPONSE_NORMALIZATIONANEURALNETWORKS_LOGISTICANEURALNETWORKS_LSH_PROJECTIONANEURALNETWORKS_LSTMANEURALNETWORKS_MAX_POOL_2DANEURALNETWORKS_MEANANEURALNETWORKS_MULANEURALNETWORKS_PADANEURALNETWORKS_RELUANEURALNETWORKS_RELU1ANEURALNETWORKS_RELU6ANEURALNETWORKS_RESHAPEANEURALNETWORKS_RESIZE_BILINEARANEURALNETWORKS_RNNANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_SOFTMAXANEURALNETWORKS_SPACE_TO_BATCH_NDANEURALNETWORKS_SPACE_TO_DEPTHANEURALNETWORKS_SQUEEZEANEURALNETWORKS_STRIDED_SLICEANEURALNETWORKS_SUBANEURALNETWORKS_SVDFANEURALNETWORKS_TANHANEURALNETWORKS_TRANSPOSE
Android 9
En Android 9, se introduce el HAL de NN 1.1, que incluye los siguientes cambios destacados.
IDevice::prepareModel_1_1incluye un parámetroExecutionPreference. Un conductor puede usar este parámetro para ajustar su preparación, ya que sabe que la app prefiere conservar la batería o ejecutará el modelo en llamadas sucesivas rápidas.- Se agregaron nueve operaciones nuevas:
BATCH_TO_SPACE_ND,DIV,MEAN,PAD,SPACE_TO_BATCH_ND,SQUEEZE,STRIDED_SLICE,SUByTRANSPOSE. - Una app puede especificar que los cálculos de números de punto flotante de 32 bits se pueden ejecutar con un rango o una precisión de números de punto flotante de 16 bits estableciendo
Model.relaxComputationFloat32toFloat16entrue. La estructuraCapabilitiestiene el campo adicionalrelaxedFloat32toFloat16Performancepara que el controlador pueda informar su rendimiento relajado al framework.
Android 8.1
La HAL de redes neuronales (1.0) inicial se lanzó en Android 8.1. Para obtener más información, consulta /neuralnetworks/1.0/.