
Cette page explique comment implémenter un pilote de l'API Neural Networks (NNAPI). Pour en savoir plus, consultez la documentation disponible dans les fichiers de définition HAL de hardware/interfaces/neuralnetworks.
Un exemple d'implémentation de pilote se trouve dans frameworks/ml/nn/driver/sample.
Pour en savoir plus sur l'API Neural Networks, consultez API Neural Networks.
HAL Neural Networks
Le HAL des réseaux de neurones (NN) définit une abstraction des différents appareils, tels que les unités de traitement graphique (GPU) et les processeurs de signaux numériques (DSP), qui se trouvent dans un produit (par exemple, un téléphone ou une tablette). Les pilotes de ces appareils doivent être conformes à la NN HAL. L'interface est spécifiée dans les fichiers de définition HAL dans hardware/interfaces/neuralnetworks.
Le flux général de l'interface entre le framework et un pilote est illustré sur la figure 1.
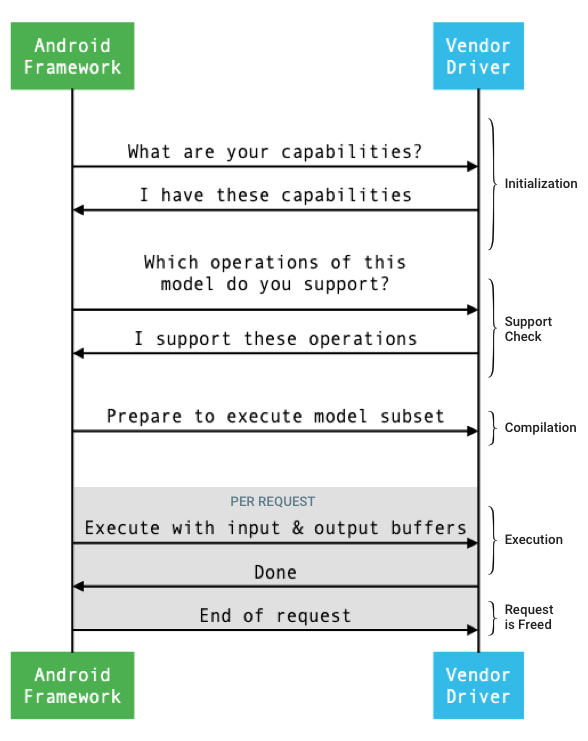
Figure 1. Flux de réseaux de neurones
Initialisation
Lors de l'initialisation, le framework interroge le pilote sur ses capacités à l'aide de IDevice::getCapabilities_1_3.
La structure @1.3::Capabilities inclut tous les types de données et représente les performances non relâchées à l'aide d'un vecteur.
Pour déterminer comment allouer les calculs aux appareils disponibles, le framework utilise les capacités pour comprendre la rapidité et l'efficacité énergétique de chaque pilote lors d'une exécution. Pour fournir ces informations, le pilote doit fournir des chiffres de performances standardisés basés sur l'exécution de charges de travail de référence.
Pour déterminer les valeurs que le pilote renvoie en réponse à IDevice::getCapabilities_1_3, utilisez l'application d'analyse comparative NNAPI pour mesurer les performances des types de données correspondants. Les modèles MobileNet v1 et v2, asr_float et tts_float sont recommandés pour mesurer les performances des valeurs à virgule flottante 32 bits, et les modèles quantifiés MobileNet v1 et v2 sont recommandés pour les valeurs quantifiées 8 bits. Pour en savoir plus, consultez Android Machine Learning Test Suite.
Dans Android 9 et versions antérieures, la structure Capabilities n'inclut des informations sur les performances du pilote que pour les Tensors à virgule flottante et quantifiés, et n'inclut pas les types de données scalaires.
Lors du processus d'initialisation, le framework peut demander plus d'informations à l'aide de IDevice::getType, IDevice::getVersionString, IDevice:getSupportedExtensions et IDevice::getNumberOfCacheFilesNeeded.
Entre les redémarrages du produit, le framework s'attend à ce que toutes les requêtes décrites dans cette section signalent toujours les mêmes valeurs pour un pilote donné. Sinon, une application utilisant ce pilote peut présenter des performances réduites ou un comportement incorrect.
Compilation
Le framework détermine les appareils à utiliser lorsqu'il reçoit une requête d'une application. Dans Android 10, les applications peuvent découvrir et spécifier les appareils parmi lesquels le framework choisit. Pour en savoir plus, consultez Découverte et attribution d'appareils.
Lors de la compilation du modèle, le framework envoie le modèle à chaque pilote candidat en appelant IDevice::getSupportedOperations_1_3.
Chaque pilote renvoie un tableau de valeurs booléennes indiquant les opérations du modèle qui sont prises en charge. Un pilote peut déterminer qu'il ne peut pas prendre en charge une opération donnée pour plusieurs raisons. Exemple :
- Le pilote n'est pas compatible avec le type de données.
- Le pilote n'accepte que les opérations avec des paramètres d'entrée spécifiques. Par exemple, un pilote peut prendre en charge les opérations de convolution 3x3 et 5x5, mais pas celles de convolution 7x7.
- Le pilote présente des contraintes de mémoire qui l'empêchent de gérer des graphiques ou des entrées volumineux.
Lors de la compilation, les opérandes d'entrée, de sortie et internes du modèle, tels que décrits dans OperandLifeTime, peuvent avoir des dimensions ou un rang inconnus. Pour en savoir plus, consultez Forme de sortie.
Le framework demande à chaque pilote sélectionné de se préparer à exécuter un sous-ensemble du modèle en appelant IDevice::prepareModel_1_3.
Chaque pilote compile ensuite son sous-ensemble. Par exemple, un pilote peut générer du code ou créer une copie réorganisée des pondérations. Étant donné qu'il peut s'écouler un temps considérable entre la compilation du modèle et l'exécution des requêtes, les ressources telles que les grands blocs de mémoire de l'appareil ne doivent pas être attribuées lors de la compilation.
En cas de réussite, le pilote renvoie un handle @1.3::IPreparedModel. Si le pilote renvoie un code d'échec lors de la préparation de son sous-ensemble du modèle, le framework exécute l'intégralité du modèle sur le processeur.
Pour réduire le temps de compilation au démarrage d'une application, un pilote peut mettre en cache les artefacts de compilation. Pour en savoir plus, consultez Mise en cache de la compilation.
Exécution
Lorsqu'une application demande au framework d'exécuter une requête, le framework appelle la méthode HAL IPreparedModel::executeSynchronously_1_3 par défaut pour effectuer une exécution synchrone sur un modèle préparé.
Une requête peut également être exécutée de manière asynchrone à l'aide de la méthode execute_1_3, de la méthode executeFenced (voir Exécution dans un cadre) ou à l'aide d'une exécution par rafale.
Les appels d'exécution synchrone améliorent les performances et réduisent la surcharge de threading par rapport aux appels asynchrones, car le contrôle n'est renvoyé au processus de l'application qu'une fois l'exécution terminée. Cela signifie que le pilote n'a pas besoin d'un mécanisme distinct pour notifier au processus de l'application qu'une exécution est terminée.
Avec la méthode asynchrone execute_1_3, le contrôle revient au processus de l'application une fois l'exécution lancée. Le pilote doit notifier le framework lorsque l'exécution est terminée, à l'aide de @1.3::IExecutionCallback.
Le paramètre Request transmis à la méthode d'exécution liste les opérandes d'entrée et de sortie utilisés pour l'exécution. La mémoire qui stocke les données des opérandes doit utiliser l'ordre des lignes, la première dimension étant celle qui itère le plus lentement, et ne doit pas comporter de marge intérieure à la fin d'une ligne. Pour en savoir plus sur les types d'opérandes, consultez Opérandes.
Pour les pilotes NN HAL 1.2 ou version ultérieure, lorsqu'une requête est terminée, l'état d'erreur, la forme de sortie et les informations de timing sont renvoyés au framework. Lors de l'exécution, les opérandes de sortie ou internes du modèle peuvent avoir une ou plusieurs dimensions inconnues ou un rang inconnu. Lorsque au moins un opérande de sortie a une dimension ou un rang inconnus, le pilote doit renvoyer des informations de sortie de taille dynamique.
Pour les pilotes avec NN HAL 1.1 ou version antérieure, seul l'état d'erreur est renvoyé lorsqu'une requête est terminée. Les dimensions des opérandes d'entrée et de sortie doivent être entièrement spécifiées pour que l'exécution aboutisse. Les opérandes internes peuvent avoir une ou plusieurs dimensions inconnues, mais leur rang doit être spécifié.
Pour les requêtes utilisateur qui couvrent plusieurs pilotes, le framework est responsable de la réservation de la mémoire intermédiaire et du séquençage des appels à chaque pilote.
Plusieurs requêtes peuvent être lancées en parallèle sur le même @1.3::IPreparedModel.
Le pilote peut exécuter les requêtes en parallèle ou les sérialiser.
Le framework peut demander à un pilote de conserver plusieurs modèles préparés. Par exemple, préparez le modèle m1, préparez m2, exécutez la requête r1 sur m1, exécutez r2 sur m2, exécutez r3 sur m1, exécutez r4 sur m2, libérez (décrit dans Nettoyage) m1 et libérez m2.
Pour éviter une première exécution lente qui pourrait entraîner une mauvaise expérience utilisateur (par exemple, un bégaiement de la première image), le pilote doit effectuer la plupart des initialisations lors de la phase de compilation. L'initialisation lors de la première exécution doit être limitée aux actions qui affectent négativement l'état du système lorsqu'elles sont effectuées tôt, comme la réservation de grands tampons temporaires ou l'augmentation de la fréquence d'horloge d'un appareil. Les pilotes qui ne peuvent préparer qu'un nombre limité de modèles simultanés peuvent avoir à effectuer leur initialisation lors de la première exécution.
Dans Android 10 ou version ultérieure, dans les cas où plusieurs exécutions avec le même modèle préparé sont exécutées en succession rapide, le client peut choisir d'utiliser un objet d'exécution par rafale pour communiquer entre les processus d'application et de pilote. Pour en savoir plus, consultez Exécutions par rafale et files d'attente de messages rapides.
Pour améliorer les performances lors de plusieurs exécutions successives, le pilote peut conserver des tampons temporaires ou augmenter les fréquences d'horloge. Il est recommandé de créer un thread watchdog pour libérer les ressources si aucune nouvelle requête n'est créée après une période fixe.
Forme de sortie
Pour les requêtes dans lesquelles une ou plusieurs opérandes de sortie n'ont pas toutes les dimensions spécifiées, le pilote doit fournir une liste des formes de sortie contenant les informations sur les dimensions pour chaque opérande de sortie après l'exécution. Pour en savoir plus sur les dimensions, consultez OutputShape.
Si une exécution échoue en raison d'une mémoire tampon de sortie trop petite, le pilote doit indiquer les opérandes de sortie dont la taille de mémoire tampon est insuffisante dans la liste des formes de sortie. Il doit également fournir autant d'informations dimensionnelles que possible, en utilisant zéro pour les dimensions inconnues.
Durée
Dans Android 10, une application peut demander le temps d'exécution si elle a spécifié un seul appareil à utiliser lors du processus de compilation. Pour en savoir plus, consultez MeasureTiming et Détection et attribution d'appareils.
Dans ce cas, un pilote NN HAL 1.2 doit mesurer la durée d'exécution ou signaler UINT64_MAX (pour indiquer que la durée n'est pas disponible) lors de l'exécution d'une requête. Le pilote doit minimiser toute pénalité de performances résultant de la mesure de la durée d'exécution.
Le pilote indique les durées suivantes en microsecondes dans la structure Timing :
- Temps d'exécution sur l'appareil : n'inclut pas le temps d'exécution dans le pilote, qui s'exécute sur le processeur hôte.
- Temps d'exécution dans le pilote : inclut le temps d'exécution sur l'appareil.
Ces durées doivent inclure le moment où l'exécution est suspendue, par exemple lorsque l'exécution a été préemptée par d'autres tâches ou lorsqu'elle attend qu'une ressource devienne disponible.
Lorsque le pilote n'a pas été invité à mesurer la durée d'exécution ou en cas d'erreur d'exécution, il doit indiquer les durées sous la forme UINT64_MAX. Même lorsque le pilote est invité à mesurer la durée d'exécution, il peut à la place signaler UINT64_MAX pour le temps passé sur l'appareil, le temps passé dans le pilote ou les deux. Lorsque le pilote indique les deux durées avec une valeur autre que UINT64_MAX, le temps d'exécution dans le pilote doit être égal ou supérieur au temps sur l'appareil.
Exécution cloisonnée
Dans Android 11, NNAPI permet aux exécutions d'attendre une liste de handles sync_fence et de renvoyer éventuellement un objet sync_fence, qui est signalé lorsque l'exécution est terminée. Cela réduit la surcharge pour les petits modèles de séquence et les cas d'utilisation de streaming. L'exécution cloisonnée permet également une interopérabilité plus efficace avec d'autres composants pouvant signaler ou attendre sync_fence. Pour en savoir plus sur sync_fence, consultez Framework de synchronisation.
Dans une exécution clôturée, le framework appelle la méthode IPreparedModel::executeFenced pour lancer une exécution clôturée et asynchrone sur un modèle préparé avec un vecteur de clôtures synchrones à attendre. Si la tâche asynchrone est terminée avant le retour de l'appel, un handle vide peut être renvoyé pour sync_fence. Un objet IFencedExecutionCallback doit également être renvoyé pour permettre au framework d'interroger l'état des erreurs et les informations sur la durée.
Une fois l'exécution terminée, les deux valeurs de timing suivantes mesurant la durée de l'exécution peuvent être interrogées via IFencedExecutionCallback::getExecutionInfo.
timingLaunched: Durée entre l'appel deexecuteFencedet le moment oùexecuteFencedsignale lesyncFencerenvoyé.timingFenced: durée écoulée entre le moment où toutes les barrières de synchronisation pour lesquelles l'exécution attend sont signalées et le moment oùexecuteFencedsignale lesyncFencerenvoyé.
Flux de contrôle
Pour les appareils équipés d'Android 11 ou version ultérieure, l'API NNAPI inclut deux opérations de flux de contrôle, IF et WHILE, qui prennent d'autres modèles comme arguments et les exécutent de manière conditionnelle (IF) ou répétée (WHILE). Pour en savoir plus sur l'implémentation, consultez Flux de contrôle.
Qualité de service
Dans Android 11, NNAPI inclut une qualité de service (QoS) améliorée en permettant à une application d'indiquer les priorités relatives de ses modèles, le temps maximal attendu pour la préparation d'un modèle et le temps maximal attendu pour l'exécution d'un calcul. Pour en savoir plus, consultez Qualité de service.
Nettoyage
Lorsqu'une application a fini d'utiliser un modèle préparé, le framework libère sa référence à l'objet @1.3::IPreparedModel. Lorsque l'objet IPreparedModel n'est plus référencé, il est automatiquement détruit dans le service de pilote qui l'a créé. Les ressources spécifiques au modèle peuvent être récupérées à ce moment-là dans l'implémentation du destructeur par le pilote. Si le service de pilote souhaite que l'objet IPreparedModel soit automatiquement détruit lorsqu'il n'est plus nécessaire au client, il ne doit conserver aucune référence à l'objet IPreparedModel après que l'objet IPreparedeModel a été renvoyé via IPreparedModelCallback::notify_1_3.
Utilisation du processeur
Les pilotes sont censés utiliser le processeur pour configurer les calculs. Les pilotes ne doivent pas utiliser le processeur pour effectuer des calculs de graphiques, car cela interfère avec la capacité du framework à répartir correctement le travail. Le pilote doit signaler au framework les parties qu'il ne peut pas gérer et laisser le framework gérer le reste.
Le framework fournit une implémentation de processeur pour toutes les opérations NNAPI, à l'exception des opérations définies par le fournisseur. Pour en savoir plus, consultez Extensions de fournisseur.
Les opérations introduites dans Android 10 (niveau d'API 29) ne disposent que d'une implémentation CPU de référence pour vérifier que les tests CTS et VTS sont corrects. Les implémentations optimisées incluses dans les frameworks de machine learning mobile sont préférables à l'implémentation NNAPI CPU.
Fonctions utilitaires
La base de code NNAPI inclut des fonctions utilitaires qui peuvent être utilisées par les services de pilote.
Le fichier frameworks/ml/nn/common/include/Utils.h contient diverses fonctions utilitaires, telles que celles utilisées pour la journalisation et pour la conversion entre différentes versions de NN HAL.
VLogging :
VLOGest une macro wrapper autour deLOGd'Android qui n'enregistre le message que si le tag approprié est défini dans la propriétédebug.nn.vlog.initVLogMask()doit être appelé avant tout appel àVLOG. La macroVLOG_IS_ONpeut être utilisée pour vérifier siVLOGest actuellement activé, ce qui permet d'ignorer le code de journalisation complexe s'il n'est pas nécessaire. La valeur de la propriété doit correspondre à l'un des éléments suivants :- Chaîne vide indiquant qu'aucune journalisation ne doit être effectuée.
- Jeton
1ouall, indiquant que toute la journalisation doit être effectuée. - Liste de tags, délimités par des espaces, des virgules ou des deux-points, indiquant les journaux à créer. Les tags sont
compilation,cpuexe,driver,execution,manageretmodel.
compliantWithV1_*: renvoietruesi un objet NN HAL peut être converti en un type identique d'une autre version HAL sans perte d'informations. Par exemple, l'appel decompliantWithV1_0sur unV1_2::Modelrenvoiefalsesi le modèle inclut des types d'opérations introduits dans NN HAL 1.1 ou NN HAL 1.2.convertToV1_*: convertit un objet NN HAL d'une version à une autre. Un avertissement est consigné si la conversion entraîne une perte d'informations (c'est-à-dire si la nouvelle version du type ne peut pas représenter entièrement la valeur).Capacités : les fonctions
nonExtensionOperandPerformanceetupdatepeuvent être utilisées pour créer le champCapabilities::operandPerformance.Interroger les propriétés des types :
isExtensionOperandType,isExtensionOperationType,nonExtensionSizeOfData,nonExtensionOperandSizeOfData,nonExtensionOperandTypeIsScalar,tensorHasUnspecifiedDimensions.
Le fichier frameworks/ml/nn/common/include/ValidateHal.h contient des fonctions utilitaires permettant de valider qu'un objet NN HAL est valide conformément à la spécification de sa version HAL.
validate*: renvoietruesi l'objet NN HAL est valide selon les spécifications de sa version HAL. Les types d'OEM et d'extensions ne sont pas validés. Par exemple,validateModelrenvoiefalsesi le modèle contient une opération qui fait référence à un index d'opérande inexistant ou une opération non compatible avec cette version HAL.
Le fichier frameworks/ml/nn/common/include/Tracing.h contient des macros permettant de simplifier l'ajout d'informations systrace au code des réseaux de neurones.
Pour obtenir un exemple, consultez les appels de macro NNTRACE_* dans l'exemple de pilote.
Le fichier frameworks/ml/nn/common/include/GraphDump.h contient une fonction utilitaire permettant de vider le contenu d'un Model sous forme graphique à des fins de débogage.
graphDump: écrit une représentation du modèle au format Graphviz (.dot) dans le flux spécifié (le cas échéant) ou dans le logcat (si aucun flux n'est fourni).
Validation
Pour tester votre implémentation de l'API NN, utilisez les tests VTS et CTS inclus dans le framework Android. VTS exerce vos pilotes directement (sans utiliser le framework), tandis que CTS les exerce indirectement via le framework. Ces tests vérifient chaque méthode d'API et s'assurent que toutes les opérations prises en charge par les pilotes fonctionnent correctement et fournissent des résultats qui répondent aux exigences de précision.
Les exigences de précision dans CTS et VTS pour l'API NN sont les suivantes :
Virgule flottante : abs(expected - actual) <= atol + rtol * abs(expected), où :
- Pour fp32, atol = 1e-5f, rtol = 5.0f * 1.1920928955078125e-7
- Pour fp16, atol = rtol = 5.0f * 0.0009765625f
Quantifié : décalage d'une unité (sauf pour
mobilenet_quantized, qui est décalé de trois unités)Booléen : correspondance exacte
Le CTS teste la NNAPI en générant des graphiques pseudo-aléatoires fixes utilisés pour tester et comparer les résultats d'exécution de chaque pilote avec l'implémentation de référence de la NNAPI. Pour les pilotes avec NN HAL 1.2 ou version ultérieure, si les résultats ne répondent pas aux critères de précision, CTS signale une erreur et génère un fichier de spécification pour le modèle défaillant sous /data/local/tmp à des fins de débogage.
Pour en savoir plus sur les critères de précision, consultez TestRandomGraph.cpp et TestHarness.h.
Tests de fuzzing
L'objectif du fuzz testing est de détecter les plantages, les assertions, les violations de mémoire ou le comportement indéfini général dans le code testé en raison de facteurs tels que des entrées inattendues. Pour les tests fuzzing NNAPI, Android utilise des tests basés sur libFuzzer, qui sont efficaces pour le fuzzing, car ils utilisent la couverture de ligne des cas de test précédents pour générer de nouvelles entrées aléatoires. Par exemple, libFuzzer privilégie les scénarios de test qui s'exécutent sur de nouvelles lignes de code. Cela réduit considérablement le temps nécessaire aux tests pour trouver le code problématique.
Pour effectuer des tests fuzz afin de valider l'implémentation de votre pilote, modifiez frameworks/ml/nn/runtime/test/android_fuzzing/DriverFuzzTest.cpp dans l'utilitaire de test libneuralnetworks_driver_fuzzer disponible dans AOSP pour inclure le code de votre pilote. Pour en savoir plus sur les tests fuzzing NNAPI, consultez frameworks/ml/nn/runtime/test/android_fuzzing/README.md.
Sécurité
Étant donné que les processus d'application communiquent directement avec le processus d'un pilote, les pilotes doivent valider les arguments des appels qu'ils reçoivent. Cette validation est vérifiée par VTS. Le code de validation se trouve dans frameworks/ml/nn/common/include/ValidateHal.h.
Les développeurs doivent également s'assurer que les applications ne peuvent pas interférer avec d'autres applications lorsqu'elles utilisent le même appareil.
Suite de tests de machine learning Android
La suite de tests de machine learning (MLTS) Android est un benchmark NNAPI inclus dans CTS et VTS pour valider l'exactitude des modèles réels sur les appareils des fournisseurs. Le benchmark évalue la latence et la précision, et compare les résultats des pilotes avec ceux obtenus à l'aide de TF Lite exécuté sur le processeur, pour le même modèle et les mêmes ensembles de données. Cela garantit que la précision d'un pilote n'est pas inférieure à celle de l'implémentation de référence du processeur.
Les développeurs de la plate-forme Android utilisent également MLTS pour évaluer la latence et la précision des pilotes.
L'analyse comparative de NNAPI est disponible dans deux projets AOSP :
platform/test/mlts/benchmark(application de benchmark)platform/test/mlts/models(modèles et ensembles de données)
Modèles et ensembles de données
L'analyse comparative de NNAPI utilise les modèles et ensembles de données suivants.
- MobileNetV1 float et u8 quantifiés dans différentes tailles, exécutés sur un petit sous-ensemble (1 500 images) d'Open Images Dataset v4.
- MobileNetV2 float et u8 quantifiés dans différentes tailles, exécutés sur un petit sous-ensemble (1 500 images) d'Open Images Dataset v4.
- Modèle acoustique basé sur la mémoire à long terme (LSTM) pour la synthèse vocale, exécuté sur un petit sous-ensemble de l'ensemble CMU Arctic.
- Modèle acoustique basé sur LSTM pour la reconnaissance vocale automatique, exécuté sur un petit sous-ensemble de l'ensemble de données LibriSpeech.
Pour en savoir plus, consultez les sections sur platform/test/mlts/models
Tests de contrainte
La suite de tests Android Machine Learning inclut une série de tests de plantage pour valider la résilience des pilotes dans des conditions d'utilisation intensive ou dans des cas extrêmes de comportement des clients.
Tous les tests de plantage offrent les fonctionnalités suivantes :
- Détection des blocages : si le client NNAPI se bloque pendant un test, celui-ci échoue avec le motif d'échec
HANGet la suite de tests passe au test suivant. - Détection des plantages du client NNAPI : les tests survivent aux plantages du client et échouent avec le motif d'échec
CRASH. - Détection des plantages de pilotes : les tests peuvent détecter un plantage de pilote qui entraîne un échec d'un appel NNAPI. Notez qu'il peut y avoir des plantages dans les processus de pilote qui n'entraînent pas d'échec de l'NNAPI ni du test. Pour couvrir ce type d'échec, il est recommandé d'exécuter la commande
tailsur le journal système pour les erreurs ou les plantages liés au pilote. - Ciblage de tous les accélérateurs disponibles : les tests sont exécutés sur tous les pilotes disponibles.
Tous les tests de plantage peuvent avoir quatre résultats possibles :
SUCCESS: l'exécution s'est terminée sans erreur.FAILURE: l'exécution a échoué. Cette erreur est généralement due à un échec lors du test d'un modèle, ce qui indique que le pilote n'a pas réussi à compiler ni à exécuter le modèle.HANG: le processus de test ne répond plus.CRASH: le processus de test a planté.
Pour en savoir plus sur les tests de résistance et obtenir la liste complète des tests de plantage, consultez platform/test/mlts/benchmark/README.txt.
Utiliser MLTS
Pour utiliser le MLTS :
- Connectez un appareil cible à votre poste de travail et assurez-vous qu'il est accessible via adb.
Exportez la variable d'environnement
ANDROID_SERIALde l'appareil cible si plusieurs appareils sont connectés. cddans le répertoire source Android de premier niveau.source build/envsetup.sh lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available. ./test/mlts/benchmark/build_and_run_benchmark.shÀ la fin d'une analyse comparative, les résultats sont présentés sous la forme d'une page HTML et transmis à
xdg-open.
Pour en savoir plus, consultez les sections sur platform/test/mlts/benchmark/README.txt
Versions HAL des réseaux de neurones
Cette section décrit les modifications apportées aux versions Android et Neural Networks HAL.
Android 11
Android 11 introduit NN-HAL 1.3, qui inclut les modifications notables suivantes.
- Prise en charge de la quantification signée 8 bits dans NNAPI. Ajoute le type d'opérande
TENSOR_QUANT8_ASYMM_SIGNED. Les pilotes avec NN HAL 1.3 qui sont compatibles avec les opérations avec quantification non signée doivent également être compatibles avec les variantes signées de ces opérations. Lors de l'exécution des versions signées et non signées de la plupart des opérations quantifiées, les pilotes doivent produire les mêmes résultats, à un décalage de 128 près. Il existe cinq exceptions à cette exigence :CAST,HASHTABLE_LOOKUP,LSH_PROJECTION,PAD_V2etQUANTIZED_16BIT_LSTM. L'opérationQUANTIZED_16BIT_LSTMn'accepte pas les opérandes signés, tandis que les quatre autres opérations acceptent la quantification signée, mais n'exigent pas que les résultats soient identiques. - Prise en charge des exécutions cloisonnées où le framework appelle la méthode
IPreparedModel::executeFencedpour lancer une exécution cloisonnée et asynchrone sur un modèle préparé avec un vecteur de barrières de synchronisation à attendre. Pour en savoir plus, consultez Exécution cloisonnée. - Prise en charge du flux de contrôle. Ajoute les opérations
IFetWHILE, qui prennent d'autres modèles comme arguments et les exécutent de manière conditionnelle (IF) ou répétée (WHILE). Pour en savoir plus, consultez Flux de contrôle. - Qualité de service (QoS) améliorée, car les applications peuvent indiquer les priorités relatives de leurs modèles, le temps maximal attendu pour la préparation d'un modèle et le temps maximal attendu pour l'exécution d'un modèle. Pour en savoir plus, consultez Qualité de service.
- Compatibilité avec les domaines de mémoire qui fournissent des interfaces d'allocation pour les tampons gérés par le pilote. Cela permet de transmettre les mémoires natives d'appareils lors des exécutions, en supprimant la copie et la transformation inutiles des données entre les exécutions consécutives sur le même pilote. Pour en savoir plus, consultez Domaines de mémoire.
Android 10
Android 10 introduit NN HAL 1.2, qui inclut les modifications notables suivantes.
- La structure
Capabilitiesinclut tous les types de données, y compris les types de données scalaires, et représente les performances non relâchées à l'aide d'un vecteur plutôt que de champs nommés. - Les méthodes
getVersionStringetgetTypepermettent au framework de récupérer le type d'appareil (DeviceType) et les informations sur la version. Consultez Détection et attribution d'appareils. - La méthode
executeSynchronouslyest appelée par défaut pour effectuer une exécution de manière synchrone. La méthodeexecute_1_2indique au framework d'effectuer une exécution de manière asynchrone. Voir Exécution. - Le paramètre
MeasureTimingsurexecuteSynchronously,execute_1_2et l'exécution par rafale indiquent si le pilote doit mesurer la durée d'exécution. Les résultats sont indiqués dans la structureTiming. Consultez Timing. - Prise en charge des exécutions dans lesquelles un ou plusieurs opérandes de sortie ont une dimension ou un rang inconnus. Consultez Forme de sortie.
- Prise en charge des extensions de fournisseur, qui sont des collections d'opérations et de types de données définis par le fournisseur. Le pilote signale les extensions compatibles via la méthode
IDevice::getSupportedExtensions. Consultez Extensions du fournisseur. - Capacité d'un objet burst à contrôler un ensemble d'exécutions burst à l'aide de files d'attente de messages rapides (FMQ) pour communiquer entre les processus d'application et de pilote, ce qui réduit la latence. Consultez Exécutions intensives et files d'attente de messages rapides.
- Prise en charge d'AHardwareBuffer pour permettre au pilote d'effectuer des exécutions sans copier de données. Consultez AHardwareBuffer.
- Amélioration de la prise en charge de la mise en cache des artefacts de compilation pour réduire le temps de compilation au démarrage d'une application. Consultez Mise en cache de la compilation.
Android 10 introduit les types d'opérandes et les opérations suivants.
-
ANEURALNETWORKS_BOOLANEURALNETWORKS_FLOAT16ANEURALNETWORKS_TENSOR_BOOL8ANEURALNETWORKS_TENSOR_FLOAT16ANEURALNETWORKS_TENSOR_QUANT16_ASYMMANEURALNETWORKS_TENSOR_QUANT16_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMMANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL
-
ANEURALNETWORKS_ABSANEURALNETWORKS_ARGMAXANEURALNETWORKS_ARGMINANEURALNETWORKS_AXIS_ALIGNED_BBOX_TRANSFORMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_BIDIRECTIONAL_SEQUENCE_RNNANEURALNETWORKS_BOX_WITH_NMS_LIMITANEURALNETWORKS_CASTANEURALNETWORKS_CHANNEL_SHUFFLEANEURALNETWORKS_DETECTION_POSTPROCESSINGANEURALNETWORKS_EQUALANEURALNETWORKS_EXPANEURALNETWORKS_EXPAND_DIMSANEURALNETWORKS_GATHERANEURALNETWORKS_GENERATE_PROPOSALSANEURALNETWORKS_GREATERANEURALNETWORKS_GREATER_EQUALANEURALNETWORKS_GROUPED_CONV_2DANEURALNETWORKS_HEATMAP_MAX_KEYPOINTANEURALNETWORKS_INSTANCE_NORMALIZATIONANEURALNETWORKS_LESSANEURALNETWORKS_LESS_EQUALANEURALNETWORKS_LOGANEURALNETWORKS_LOGICAL_ANDANEURALNETWORKS_LOGICAL_NOTANEURALNETWORKS_LOGICAL_ORANEURALNETWORKS_LOG_SOFTMAXANEURALNETWORKS_MAXIMUMANEURALNETWORKS_MINIMUMANEURALNETWORKS_NEGANEURALNETWORKS_NOT_EQUALANEURALNETWORKS_PAD_V2ANEURALNETWORKS_POWANEURALNETWORKS_PRELUANEURALNETWORKS_QUANTIZEANEURALNETWORKS_QUANTIZED_16BIT_LSTMANEURALNETWORKS_RANDOM_MULTINOMIALANEURALNETWORKS_REDUCE_ALLANEURALNETWORKS_REDUCE_ANYANEURALNETWORKS_REDUCE_MAXANEURALNETWORKS_REDUCE_MINANEURALNETWORKS_REDUCE_PRODANEURALNETWORKS_REDUCE_SUMANEURALNETWORKS_RESIZE_NEAREST_NEIGHBORANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_ROI_POOLINGANEURALNETWORKS_RSQRTANEURALNETWORKS_SELECTANEURALNETWORKS_SINANEURALNETWORKS_SLICEANEURALNETWORKS_SPLITANEURALNETWORKS_SQRTANEURALNETWORKS_TILEANEURALNETWORKS_TOPK_V2ANEURALNETWORKS_TRANSPOSE_CONV_2DANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_LSTMANEURALNETWORKS_UNIDIRECTIONAL_SEQUENCE_RNN
Android 10 apporte des modifications à de nombreuses opérations existantes. Les mises à jour concernent principalement les éléments suivants :
- Compatibilité avec la disposition de mémoire NCHW
- Compatibilité avec les Tensors dont le rang est différent de 4 dans les opérations softmax et de normalisation
- Compatibilité avec les convolutions dilatées
- Prise en charge des entrées avec quantification mixte dans
ANEURALNETWORKS_CONCATENATION
La liste ci-dessous présente les opérations modifiées dans Android 10. Pour en savoir plus sur les modifications, consultez OperationCode dans la documentation de référence de NNAPI.
ANEURALNETWORKS_ADDANEURALNETWORKS_AVERAGE_POOL_2DANEURALNETWORKS_BATCH_TO_SPACE_NDANEURALNETWORKS_CONCATENATIONANEURALNETWORKS_CONV_2DANEURALNETWORKS_DEPTHWISE_CONV_2DANEURALNETWORKS_DEPTH_TO_SPACEANEURALNETWORKS_DEQUANTIZEANEURALNETWORKS_DIVANEURALNETWORKS_FLOORANEURALNETWORKS_FULLY_CONNECTEDANEURALNETWORKS_L2_NORMALIZATIONANEURALNETWORKS_L2_POOL_2DANEURALNETWORKS_LOCAL_RESPONSE_NORMALIZATIONANEURALNETWORKS_LOGISTICANEURALNETWORKS_LSH_PROJECTIONANEURALNETWORKS_LSTMANEURALNETWORKS_MAX_POOL_2DANEURALNETWORKS_MEANANEURALNETWORKS_MULANEURALNETWORKS_PADANEURALNETWORKS_RELUANEURALNETWORKS_RELU1ANEURALNETWORKS_RELU6ANEURALNETWORKS_RESHAPEANEURALNETWORKS_RESIZE_BILINEARANEURALNETWORKS_RNNANEURALNETWORKS_ROI_ALIGNANEURALNETWORKS_SOFTMAXANEURALNETWORKS_SPACE_TO_BATCH_NDANEURALNETWORKS_SPACE_TO_DEPTHANEURALNETWORKS_SQUEEZEANEURALNETWORKS_STRIDED_SLICEANEURALNETWORKS_SUBANEURALNETWORKS_SVDFANEURALNETWORKS_TANHANEURALNETWORKS_TRANSPOSE
Android 9
NN HAL 1.1 est introduit dans Android 9 et inclut les modifications notables suivantes.
IDevice::prepareModel_1_1inclut un paramètreExecutionPreference. Un pilote peut l'utiliser pour ajuster sa préparation, en sachant que l'application préfère économiser la batterie ou exécutera le modèle lors d'appels rapides et successifs.- Neuf nouvelles opérations ont été ajoutées :
BATCH_TO_SPACE_ND,DIV,MEAN,PAD,SPACE_TO_BATCH_ND,SQUEEZE,STRIDED_SLICE,SUB,TRANSPOSE. - Une application peut spécifier que les calculs à virgule flottante 32 bits peuvent être exécutés à l'aide d'une plage et/ou d'une précision à virgule flottante 16 bits en définissant
Model.relaxComputationFloat32toFloat16surtrue. La structureCapabilitiescomporte le champ supplémentairerelaxedFloat32toFloat16Performanceafin que le pilote puisse signaler ses performances relâchées au framework.
Android 8.1
La première HAL (1.0) des réseaux de neurones a été publiée dans Android 8.1. Pour en savoir plus, consultez les pages suivantes : /neuralnetworks/1.0/.