
Android proporciona una implementación de referencia de todos los componentes necesarios para implementar Android Virtualization Framework. Actualmente, esta implementación se limita a ARM64. En esta página, se explica la arquitectura del framework.
Fondo
La arquitectura de Arm permite hasta cuatro niveles de excepción, en los que el nivel de excepción 0 (EL0) es el menos privilegiado y el nivel de excepción 3 (EL3) es el más privilegiado. La mayor parte de la base de código de Android (todos los componentes del espacio de usuario) se ejecuta en EL0. El resto de lo que comúnmente se denomina "Android" es el kernel de Linux, que se ejecuta en EL1.
La capa EL2 permite la introducción de un hipervisor que habilita el aislamiento de la memoria y los dispositivos en pVM individuales en EL1/EL0, con garantías sólidas de confidencialidad e integridad.
Hipervisor
La máquina virtual protegida basada en kernel (pKVM) se basa en el hipervisor Linux KVM, que se extendió con la capacidad de restringir el acceso a las cargas útiles que se ejecutan en máquinas virtuales invitadas marcadas como "protegidas" en el momento de la creación.
KVM/arm64 admite diferentes modos de ejecución según la disponibilidad de ciertas funciones de CPU, en particular, las extensiones de host de virtualización (VHE) (ARMv8.1 y versiones posteriores). En uno de esos modos, conocido comúnmente como modo no VHE, el código del hipervisor se divide de la imagen del kernel durante el arranque y se instala en EL2, mientras que el kernel en sí se ejecuta en EL1. Aunque forma parte de la base de código de Linux, el componente EL2 de KVM es un componente pequeño encargado del cambio entre varios EL1. El componente del hipervisor se compila con Linux, pero reside en una sección de memoria separada y dedicada de la imagen de vmlinux. pKVM aprovecha este diseño extendiendo el código del hipervisor con nuevas funciones que le permiten imponer restricciones en el kernel host y el espacio del usuario de Android, y limitar el acceso del host a la memoria del invitado y al hipervisor.
Módulos de proveedores de la pKVM
Un módulo de proveedor de la pKVM es un módulo específico del hardware que contiene funcionalidad específica del dispositivo, como los controladores de la unidad de administración de memoria de entrada y salida (IOMMU). Estos módulos te permiten transferir funciones de seguridad que requieren acceso de nivel de excepción 2 (EL2) a pKVM.
Para obtener información sobre cómo implementar y cargar un módulo de proveedores de la pKVM, consulta Implement a pKVM vendor module.
Procedimiento de inicio
En la siguiente figura, se ilustra el procedimiento de inicio de pKVM:
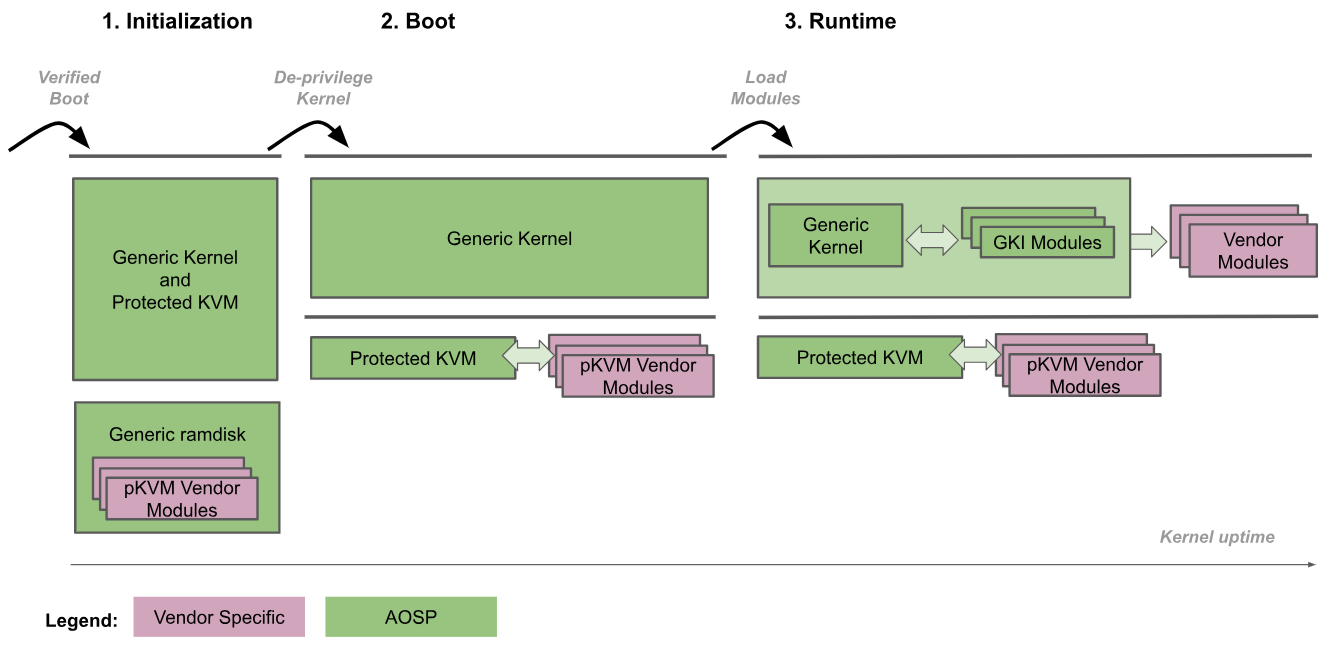
- Inicialización: El cargador de arranque ingresa al kernel genérico en EL2. Luego, el código del kernel de confianza en EL2 y EL1 inicializa la pKVM y sus módulos. Durante esta fase, EL2 confía en EL1, por lo que no se ejecuta código no confiable.
- Reducción de privilegios del kernel: El kernel genérico detecta que se ejecuta en EL2 y reduce sus privilegios a EL1. pKVM y sus módulos siguen ejecutándose en EL2.
- Tiempo de ejecución: El kernel genérico continúa con el inicio normal, cargando todos los controladores de dispositivos necesarios hasta llegar al espacio del usuario. En este punto, pKVM está en su lugar y controla las tablas de páginas de la etapa 2.
El procedimiento de arranque confía en el bootloader para verificar y mantener la integridad de la imagen del kernel durante la fase de inicialización. Después de que se quitan los privilegios del kernel, el hipervisor ya no lo considera de confianza, por lo que es responsable de protegerse incluso si el kernel se ve comprometido.
Tener el kernel de Android y el hipervisor en la misma imagen binaria permite una interfaz de comunicación muy estrechamente acoplada entre ellos. Este acoplamiento estrecho garantiza actualizaciones atómicas de los dos componentes, lo que evita la necesidad de mantener estable la interfaz entre ellos y ofrece una gran flexibilidad sin comprometer la capacidad de mantenimiento a largo plazo. El acoplamiento estrecho también permite optimizaciones del rendimiento cuando ambos componentes pueden cooperar sin afectar las garantías de seguridad que proporciona el hipervisor.
Además, la adopción del GKI en el ecosistema de Android permite automáticamente que el hipervisor de pKVM se implemente en dispositivos Android en el mismo objeto binario que el kernel.
Protección de acceso a la memoria de la CPU
La arquitectura de Arm especifica una unidad de administración de memoria (MMU) dividida en dos etapas independientes, ambas se pueden usar para implementar la traducción de direcciones y el control de acceso a diferentes partes de la memoria. La MMU de etapa 1 está controlada por EL1 y permite un primer nivel de traducción de direcciones. Linux usa la MMU de etapa 1 para administrar el espacio de direcciones virtuales que se proporciona a cada proceso de espacio de usuario y a su propio espacio de direcciones virtuales.
La MMU de etapa 2 está controlada por EL2 y permite la aplicación de una segunda traducción de direcciones en la dirección de salida de la MMU de etapa 1, lo que genera una dirección física (PA). Los hipervisores pueden usar la traducción de etapa 2 para controlar y traducir los accesos a la memoria de todas las VMs invitadas. Como se muestra en la figura 2, cuando ambas etapas de la traducción están habilitadas, la dirección de salida de la etapa 1 se denomina dirección física intermedia (IPA). Nota: La dirección virtual (VA) se traduce en una IPA y, luego, en una PA.
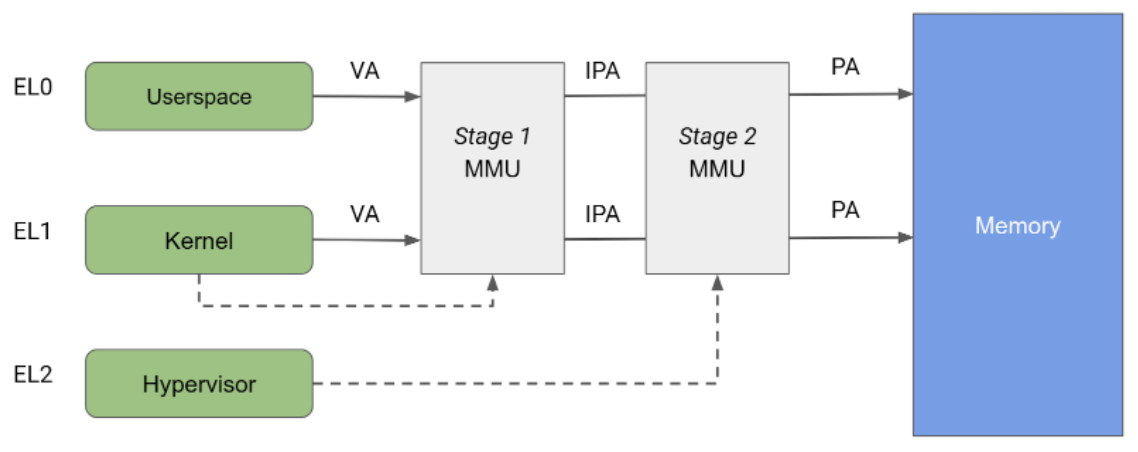
Históricamente, KVM se ejecuta con la traducción de la etapa 2 habilitada mientras se ejecutan invitados y con la etapa 2 inhabilitada mientras se ejecuta el kernel de Linux del host. Esta arquitectura permite que los accesos a la memoria desde la MMU de etapa 1 del host pasen por la MMU de etapa 2, lo que permite el acceso sin restricciones del host a las páginas de memoria del invitado. Por otro lado, pKVM habilita la protección de etapa 2 incluso en el contexto del host y pone al hipervisor a cargo de proteger las páginas de memoria del invitado en lugar del host.
KVM aprovecha al máximo la traducción de direcciones en la etapa 2 para implementar asignaciones complejas de IPA/PA para los invitados, lo que crea la ilusión de memoria contigua para los invitados a pesar de la fragmentación física. Sin embargo, el uso de la MMU de etapa 2 para el host se restringe solo al control de acceso. La etapa 2 del host se asigna de forma idéntica, lo que garantiza que la memoria contigua en el espacio de IPA del host sea contigua en el espacio de PA. Esta arquitectura permite el uso de asignaciones grandes en la tabla de páginas y, en consecuencia, reduce la presión sobre el búfer de anticipación de traducción (TLB). Dado que PA puede indexar una asignación de identidad, la etapa 2 del host también se usa para hacer un seguimiento de la propiedad de la página directamente en la tabla de páginas.
Protección de acceso directo a la memoria (DMA)
Como se describió anteriormente, desasignar las páginas de invitado del host de Linux en las tablas de páginas de la CPU es un paso necesario, pero insuficiente para proteger la memoria del invitado. pKVM también debe protegerse contra los accesos a la memoria que realizan los dispositivos compatibles con DMA bajo el control del kernel del host y la posibilidad de un ataque de DMA iniciado por un host malicioso. Para evitar que un dispositivo de este tipo acceda a la memoria del invitado, pKVM requiere hardware de la unidad de administración de memoria de entrada y salida (IOMMU) para cada dispositivo compatible con DMA del sistema, como se muestra en la figura 3.
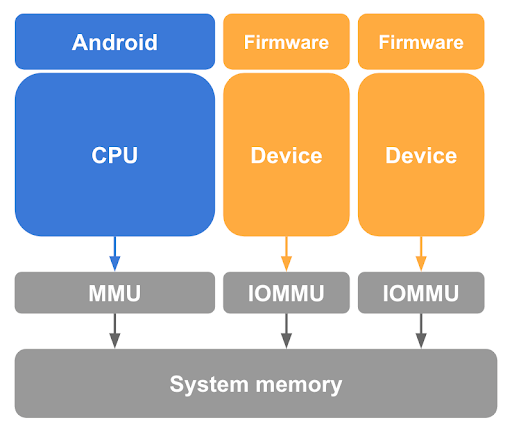
Como mínimo, el hardware de la IOMMU proporciona los medios para otorgar y revocar el acceso de lectura y escritura de un dispositivo a la memoria física con granularidad de página. Sin embargo, este hardware de IOMMU limita el uso de dispositivos en las PVMS, ya que asumen una etapa 2 asignada por identidad.
Para garantizar el aislamiento entre las máquinas virtuales, la IOMMU debe poder distinguir las transacciones de memoria generadas en nombre de diferentes entidades, de modo que se pueda usar el conjunto adecuado de tablas de páginas para la traducción.
Además, reducir la cantidad de código específico del SoC en EL2 es una estrategia clave para reducir la base de procesamiento confiable (TCB) general de pKVM y va en contra de la inclusión de controladores de IOMMU en el hipervisor. Para mitigar este problema, el host en EL1 es responsable de las tareas auxiliares de administración de la IOMMU, como la administración de energía, la inicialización y, cuando corresponda, el control de interrupciones.
Sin embargo, poner al host en control del estado del dispositivo impone requisitos adicionales en la interfaz de programación del hardware de la IOMMU para garantizar que las verificaciones de permisos no se puedan omitir por otros medios, por ejemplo, después de restablecer el dispositivo.
Una IOMMU estándar y bien compatible para dispositivos Arm que permite el aislamiento y la asignación directa es la arquitectura de la unidad de administración de memoria del sistema (SMMU) de Arm. Esta arquitectura es la solución de referencia recomendada.
Propiedad de la memoria
En el momento del arranque, se supone que el host es propietario de toda la memoria que no es del hipervisor, y el hipervisor la rastrea como tal. Cuando se genera una pVM, el host dona páginas de memoria para permitir que se inicie, y el hipervisor transfiere la propiedad de esas páginas del host a la pVM. Por lo tanto, el hipervisor establece restricciones de control de acceso en la tabla de páginas de la etapa 2 del host para evitar que vuelva a acceder a las páginas, lo que proporciona confidencialidad al invitado.
La comunicación entre el host y los invitados es posible gracias al uso compartido controlado de la memoria entre ellos. Los invitados pueden compartir algunas de sus páginas con el host a través de una hiperllamada, que le indica al hipervisor que reasigne esas páginas en la tabla de páginas de la etapa 2 del host. Del mismo modo, la comunicación del host con TrustZone es posible gracias a las operaciones de préstamo o uso compartido de memoria, todas ellas supervisadas y controladas de cerca por pKVM a través de la especificación del marco de trabajo de firmware para Arm (FF-A).
Dado que los requisitos de memoria de una pVM pueden cambiar con el tiempo, se proporciona una hiperllamada que permite que la propiedad de las páginas especificadas que pertenecen a la entidad llamadora se devuelva al host. En la práctica, esta hiperllamada se usa con el protocolo de globo virtio para permitir que el VMM solicite memoria a la pVM y que la pVM notifique al VMM las páginas cedidas, de manera controlada.
El hipervisor es responsable de hacer un seguimiento de la propiedad de todas las páginas de memoria del sistema y de si se comparten o se prestan a otras entidades. La mayor parte de este seguimiento de estado se realiza con metadatos adjuntos a las tablas de páginas de nivel 2 del host y los invitados, con bits reservados en las entradas de la tabla de páginas (PTE) que, como su nombre lo indica, se reservan para el uso del software.
El host debe asegurarse de no intentar acceder a las páginas a las que el hipervisor les quitó el acceso. Un acceso ilegal al host hace que el hipervisor inserte una excepción síncrona en el host, lo que puede provocar que la tarea responsable del espacio del usuario reciba un mensaje SEGV o que falle el kernel del host. Para evitar accesos accidentales, el kernel del host inhabilita las páginas donadas a los invitados para que no se puedan intercambiar ni combinar.
Control de interrupciones y temporizadores
Las interrupciones son una parte esencial de la forma en que un invitado interactúa con los dispositivos y para la comunicación entre las CPU, en la que las interrupciones entre procesadores (IPI) son el principal mecanismo de comunicación. El modelo de KVM consiste en delegar toda la administración de interrupciones virtuales al host en EL1, que, para ese propósito, se comporta como una parte no confiable del hipervisor.
pKVM ofrece una emulación completa de la versión 3 del controlador de interrupciones genérico (GICv3) basada en el código de KVM existente. El temporizador y los IPI se controlan como parte de este código de emulación no confiable.
Compatibilidad con GICv3
La interfaz entre EL1 y EL2 debe garantizar que el host de EL1 pueda ver el estado completo de la interrupción, incluidas las copias de los registros del hipervisor relacionados con las interrupciones. Por lo general, esta visibilidad se logra con regiones de memoria compartida, una por CPU virtual (vCPU).
El código de compatibilidad del tiempo de ejecución del registro del sistema se puede simplificar para admitir solo el registro de interrupciones generadas por software (SGIR) y el registro de desactivación de interrupciones (DIR). La arquitectura exige que estos registros siempre generen una excepción en EL2, mientras que las otras excepciones solo han sido útiles hasta ahora para mitigar erratas. Todo lo demás se controla con hardware.
En el lado de MMIO, todo se emula en EL1, y se reutiliza toda la infraestructura actual en KVM. Por último, Wait for Interrupt (WFI) siempre se retransmite a EL1, ya que es una de las primitivas de programación básicas que usa KVM.
Compatibilidad con el temporizador
El valor del comparador del temporizador virtual debe exponerse a EL1 en cada WFI de captura para que EL1 pueda insertar interrupciones del temporizador mientras la CPU virtual está bloqueada. El temporizador físico se emula por completo, y todas las interrupciones se retransmiten a EL1.
Control de MMIO
Para comunicarse con el supervisor de máquina virtual (VMM) y realizar la emulación de GIC, las trampas de MMIO deben retransmitirse al host en EL1 para una clasificación posterior. pKVM requiere lo siguiente:
- IPA y tamaño del acceso
- Datos en caso de escritura
- Orden de bytes de la CPU en el punto de interrupción
Además, las trampas con un registro de uso general (GPR) como fuente o destino se retransmiten con un seudoregistro de transferencia abstracto.
Interfaces de invitados
Un invitado puede comunicarse con un invitado protegido a través de una combinación de hiperllamadas y acceso a la memoria de regiones atrapadas. Las hiperllamadas se exponen según el estándar SMCCC, con un rango reservado para una asignación del proveedor por parte de KVM. Las siguientes hiperllamadas son de especial importancia para los invitados de pKVM.
Hiperllamadas genéricas
- PSCI proporciona un mecanismo estándar para que el invitado controle el ciclo de vida de sus vCPUs, lo que incluye la conexión, la desconexión y el apagado del sistema.
- El TRNG proporciona un mecanismo estándar para que el invitado solicite entropía al pKVM, que retransmite la llamada al EL3. Este mecanismo es particularmente útil cuando no se puede confiar en el host para virtualizar un generador de números aleatorios (RNG) de hardware.
Hiperllamadas de la pKVM
- Compartir memoria con el host Inicialmente, el host no puede acceder a la memoria del invitado, pero el acceso del host es necesario para la comunicación de memoria compartida y para los dispositivos paravirtualizados que dependen de búferes compartidos. Las hiperllamadas para compartir y dejar de compartir páginas con el host permiten que el invitado decida exactamente qué partes de la memoria se hacen accesibles para el resto de Android sin necesidad de un handshake.
- Liberación de memoria para el host. Por lo general, toda la memoria del invitado le pertenece hasta que se destruye. Este estado puede ser inadecuado para las VMs de larga duración con requisitos de memoria que varían con el tiempo. La hiperllamada
relinquishpermite que un invitado transfiera explícitamente la propiedad de las páginas al host sin necesidad de finalizar la sesión del invitado. - Se realiza una captura del acceso a la memoria para el host. Tradicionalmente, si un invitado de KVM accede a una dirección que no corresponde a una región de memoria válida, el subproceso de la CPU virtual sale al host y el acceso se usa, por lo general, para MMIO y el VMM lo emula en el espacio del usuario. Para facilitar este control, pKVM debe anunciar detalles sobre la instrucción que generó la falla, como su dirección, los parámetros de registro y, posiblemente, su contenido al host, lo que podría exponer de forma involuntaria datos sensibles de un invitado protegido si no se anticipó la trampa. pKVM resuelve este problema tratando estas fallas como fatales, a menos que el invitado haya emitido previamente una hiperllamada para identificar el rango de IPA que generó la falla como uno para el que se permiten los accesos para volver a atrapar al host. Esta solución se conoce como protección de MMIO.
Dispositivo de E/S virtual (virtio)
Virtio es un estándar popular, portátil y consolidado para implementar dispositivos paravirtualizados y para interactuar con ellos. La mayoría de los dispositivos expuestos a huéspedes protegidos se implementan con virtio. Virtio también sustenta la implementación de vsock que se usa para la comunicación entre un invitado protegido y el resto de Android.
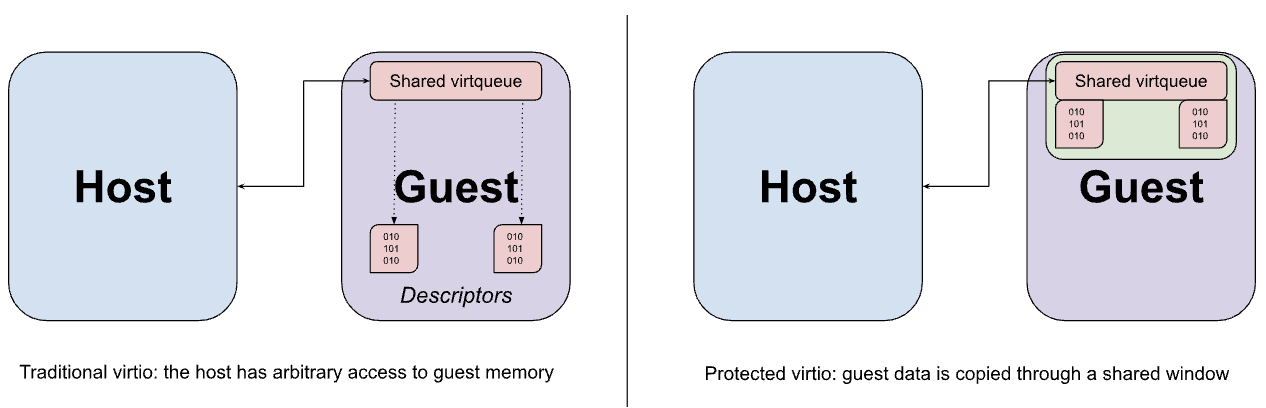
Por lo general, el VMM implementa los dispositivos virtio en el espacio del usuario del host, intercepta los accesos a la memoria atrapados del invitado a la interfaz MMIO del dispositivo virtio y emula el comportamiento esperado. El acceso a MMIO es relativamente costoso porque cada acceso al dispositivo requiere un viaje de ida y vuelta al VMM, por lo que la mayor parte de la transferencia de datos real entre el dispositivo y el invitado se produce con un conjunto de virtqueues en la memoria. Una suposición clave de virtio es que el host puede acceder a la memoria del invitado de forma arbitraria. Esta suposición se evidencia en el diseño de la virtqueue, que puede contener punteros a búferes en el invitado a los que se pretende que la emulación del dispositivo acceda directamente.
Si bien las hiperllamadas de uso compartido de memoria descritas anteriormente se podrían usar para compartir búferes de datos de virtio del invitado al host, este uso compartido se realiza necesariamente con una granularidad de página y podría terminar exponiendo más datos de los necesarios si el tamaño del búfer es menor que el de una página. En cambio, el invitado está configurado para asignar tanto las virtqueues como sus búferes de datos correspondientes desde una ventana fija de memoria compartida, con datos que se copian (rebotan) hacia y desde la ventana según sea necesario.
Interacción con TrustZone
Aunque los invitados no pueden interactuar directamente con TrustZone, el host debe poder emitir llamadas a SMC en el mundo seguro. Estas llamadas pueden especificar búferes de memoria con direcciones físicas a los que el host no puede acceder. Dado que el software seguro generalmente no conoce la accesibilidad del búfer, un host malicioso podría usar este búfer para realizar un ataque de diputado confundido (análogo a un ataque de DMA). Para evitar estos ataques, pKVM intercepta todas las llamadas SMC del host a EL2 y actúa como proxy entre el host y el monitor seguro en EL3.
Las llamadas a PSCI desde el host se reenvían al firmware EL3 con modificaciones mínimas. Específicamente, el punto de entrada para una CPU que se conecta o se reanuda desde la suspensión se reescribe de modo que la tabla de páginas de la etapa 2 se instale en EL2 antes de volver al host en EL1. Durante el inicio, pKVM aplica esta protección.
Esta arquitectura se basa en que el SoC admita PSCI, de preferencia a través del uso de una versión actualizada de TF-A como su firmware EL3.
El estándar de Firmware Framework for Arm (FF-A) estandariza las interacciones entre los mundos normal y seguro, en especial en presencia de un hipervisor seguro. Una parte importante de la especificación define un mecanismo para compartir memoria con el mundo seguro, que usa un formato de mensaje común y un modelo de permisos bien definido para las páginas subyacentes. pKVM reenvía mensajes de FF-A para garantizar que el host no intente compartir memoria con el lado seguro para el que no tiene permisos suficientes.
Esta arquitectura se basa en el software del mundo seguro que aplica el modelo de acceso a la memoria para garantizar que las apps de confianza y cualquier otro software que se ejecute en el mundo seguro puedan acceder a la memoria solo si el mundo seguro es propietario exclusivo de ella o si se compartió explícitamente con él a través de FF-A. En un sistema con S-EL2, un núcleo del administrador de particiones seguro (SPMC), como Hafnium, debe aplicar el modelo de acceso a la memoria, ya que mantiene las tablas de páginas de la etapa 2 para el mundo seguro. En un sistema sin S-EL2, el TEE puede aplicar un modelo de acceso a la memoria a través de sus tablas de páginas de etapa 1.
Si la llamada a SMC a EL2 no es una llamada a PSCI o un mensaje definido por FF-A, las SMC no controladas se reenvían a EL3. Se supone que el firmware seguro (necesariamente confiable) puede controlar los SMC no controlados de forma segura porque comprende las precauciones necesarias para mantener el aislamiento de la pVM.
Supervisor de máquina virtual
crosvm es un monitor de máquinas virtuales (VMM) que ejecuta máquinas virtuales a través de la interfaz KVM de Linux. Lo que hace que crosvm sea único es su enfoque en la seguridad con el uso del lenguaje de programación Rust y una zona de pruebas alrededor de los dispositivos virtuales para proteger el kernel del host. Para obtener más información sobre crosvm, consulta su documentación oficial aquí.
Descriptores de archivos y ioctls
KVM expone el dispositivo de caracteres /dev/kvm al espacio del usuario con ioctls que componen la API de KVM. Los ioctl pertenecen a las siguientes categorías:
- Los ioctl del sistema consultan y establecen atributos globales que afectan a todo el subsistema de KVM, y crean pVMs.
- Los ioctl de la VM consultan y establecen atributos que crean CPU virtuales (vCPU) y dispositivos, y afectan a toda una pVM, como la inclusión del diseño de la memoria y la cantidad de CPU virtuales (vCPU) y dispositivos.
- Los ioctl de CPU virtual consultan y establecen atributos que controlan el funcionamiento de una sola CPU virtual.
- Los ioctl del dispositivo consultan y establecen atributos que controlan el funcionamiento de un solo dispositivo virtual.
Cada proceso de crosvm ejecuta exactamente una instancia de una máquina virtual. Este proceso usa el ioctl del sistema KVM_CREATE_VM para crear un descriptor de archivo de VM que se puede usar para emitir ioctls de pVM. Un ioctl KVM_CREATE_VCPU o KVM_CREATE_DEVICE en un FD de VM crea una vCPU o un dispositivo y devuelve un descriptor de archivo que apunta al recurso nuevo. Los ioctl en un FD de vCPU o dispositivo se pueden usar para controlar el dispositivo que se creó con el ioctl en un FD de VM. En el caso de las CPU virtuales, esto incluye la importante tarea de ejecutar código invitado.
Internamente, crosvm registra los descriptores de archivos de la VM con el kernel usando la interfaz epoll activada por flanco. Luego, el kernel notifica a crosvm cada vez que hay un evento nuevo pendiente en cualquiera de los descriptores de archivos.
pKVM agrega una nueva capacidad, KVM_CAP_ARM_PROTECTED_VM, que se puede usar para obtener información sobre el entorno de la pVM y configurar el modo protegido para una VM. crosvm usa esto durante la creación de la pVM si se pasa la marca --protected-vm, para consultar y reservar la cantidad adecuada de memoria para el firmware de la pVM y, luego, habilitar el modo protegido.
Asignación de memoria:
Una de las principales responsabilidades de un VMM es asignar la memoria de la VM y administrar su diseño de memoria. crosvm genera un diseño de memoria fijo que se describe de forma general en la siguiente tabla.
| FDT en modo normal | PHYS_MEMORY_END - 0x200000
|
| Espacio disponible | ...
|
| Ramdisk | ALIGN_UP(KERNEL_END, 0x1000000)
|
| Kernel | 0x80080000
|
| Bootloader | 0x80200000
|
| FDT en modo BIOS | 0x80000000
|
| Base de memoria física | 0x80000000
|
| Firmware de la pVM | 0x7FE00000
|
| Memoria del dispositivo | 0x10000 - 0x40000000
|
La memoria física se asigna con mmap y se dona a la VM para completar sus regiones de memoria, llamadas ranuras de memoria, con el ioctl KVM_SET_USER_MEMORY_REGION. Por lo tanto, toda la memoria de la pVM invitada se atribuye a la instancia de crosvm que la administra y puede provocar que se cierre el proceso (lo que finaliza la VM) si el host comienza a quedarse sin memoria libre. Cuando se detiene una VM, el hipervisor borra automáticamente la memoria y la devuelve al kernel del host.
En el KVM normal, el VMM conserva el acceso a toda la memoria del invitado. Con pKVM, la memoria del invitado se desvincula del espacio de direcciones físicas del host cuando se dona al invitado. La única excepción es la memoria que el invitado comparte de forma explícita, como en el caso de los dispositivos virtio.
Las regiones de MMIO en el espacio de direcciones del invitado no se asignan. El acceso a estas regiones por parte del invitado se intercepta y genera un evento de E/S en el FD de la VM. Este mecanismo se usa para implementar dispositivos virtuales. En el modo protegido, el invitado debe confirmar que se usará una región de su espacio de direcciones para MMIO con una hiperllamada, para reducir el riesgo de filtración accidental de información.
Programación
Cada CPU virtual se representa con un subproceso POSIX y se programa con el programador de Linux del host. El subproceso llama a KVM_RUN ioctl en el FD de la CPU virtual, lo que hace que el hipervisor cambie al contexto de la CPU virtual invitada. El programador del host tiene en cuenta el tiempo que se dedica a un contexto invitado como tiempo utilizado por el subproceso de la CPU virtual correspondiente. KVM_RUN se devuelve cuando hay un evento que debe controlar el VMM, como E/S, fin de interrupción o detención de la CPU virtual. El VMM controla el evento y vuelve a llamar a KVM_RUN.
Durante KVM_RUN, el subproceso sigue siendo apropiable por el programador del host, excepto por la ejecución del código del hipervisor EL2, que no es apropiable. La pVM invitada no tiene ningún mecanismo para controlar este comportamiento.
Dado que todos los subprocesos de CPU virtuales se programan como cualquier otra tarea del espacio del usuario, están sujetos a todos los mecanismos de QoS estándar. Específicamente, cada subproceso de CPU virtual se puede fijar a CPUs físicas, colocar en cpusets, aumentar o limitar con la fijación de utilización, cambiar su prioridad o política de programación, y mucho más.
Dispositivos virtuales
crosvm admite varios dispositivos, incluidos los siguientes:
- virtio-blk para imágenes de disco compuestas, de solo lectura o de lectura y escritura
- vhost-vsock para la comunicación con el host
- virtio-pci como transporte virtio
- Reloj en tiempo real (RTC) pl030
- UART 16550a para comunicación serial
Firmware de la pVM
El firmware de la pVM (pvmfw) es el primer código que ejecuta una pVM, de manera similar a la ROM de arranque de un dispositivo físico. El objetivo principal de pvmfw es iniciar el arranque seguro y derivar el secreto único de la pVM. El pvmfw no se limita a usarse con ningún SO específico, como Microdroid, siempre que crosvm admita el SO y se haya firmado correctamente.
El archivo binario pvmfw se almacena en una partición flash del mismo nombre y se actualiza con OTA.
Arranque del dispositivo
Se agrega la siguiente secuencia de pasos al procedimiento de arranque de un dispositivo habilitado para pKVM:
- El bootloader de Android (ABL) carga pvmfw desde su partición en la memoria y verifica la imagen.
- El ABL obtiene sus secretos de Device Identifier Composition Engine (DICE) (identificadores de dispositivos compuestos [CDI] y cadena de certificados de DICE) de una raíz de confianza.
- El ABL deriva los CDI necesarios para pvmfw y los agrega al binario de pvmfw.
- El ABL agrega un nodo de región de memoria reservada
linux,pkvm-guest-firmware-memoryal DT, que describe la ubicación y el tamaño del objeto binario pvmfw y los secretos que derivó en el paso anterior. - El ABL le entrega el control a Linux, y Linux inicializa pKVM.
- pKVM desasigna la región de memoria de pvmfw de las tablas de páginas de etapa 2 del host y la protege del host (y de los invitados) durante el tiempo de actividad del dispositivo.
Después de que se inicia el dispositivo, Microdroid se inicia según los pasos de la sección Secuencia de inicio del documento de Microdroid.
Arranque de la pVM
Cuando se crea una pVM, crosvm (o otro VMM) debe crear un memslot lo suficientemente grande para que el hipervisor lo complete con la imagen de pvmfw. El VMM también está restringido en la lista de registros cuyo valor inicial puede establecer (x0-x14 para la CPU virtual principal, ninguno para las CPU virtuales secundarias). Los registros restantes están reservados y forman parte de la ABI de hypervisor-pvmfw.
Cuando se ejecuta la pVM, el hipervisor primero entrega el control de la vCPU principal a pvmfw. El firmware espera que crosvm haya cargado un kernel firmado por AVB, que puede ser un bootloader o cualquier otra imagen, y un FDT sin firmar en la memoria en desplazamientos conocidos. pvmfw valida la firma de AVB y, si tiene éxito, genera un árbol de dispositivos de confianza a partir del FDT recibido, borra sus secretos de la memoria y se bifurca al punto de entrada de la carga útil. Si uno de los pasos de verificación falla, el firmware emite una hiperllamada SYSTEM_RESET de PSCI.
Entre los inicios, la información sobre la instancia de pVM se almacena en una partición (dispositivo virtio-blk) y se encripta con el secreto de pvmfw para garantizar que, después de un reinicio, el secreto se aprovisione en la instancia correcta.