
Android fournit une implémentation de référence de tous les composants nécessaires pour implémenter le Framework de virtualisation Android. Actuellement, cette implémentation est limitée à ARM64. Cette page explique l'architecture du framework.
Arrière-plan
L'architecture Arm autorise jusqu'à quatre niveaux d'exception, le niveau 0 (EL0) étant le moins privilégié et le niveau 3 (EL3) le plus privilégié. La plus grande partie du codebase Android (tous les composants de l'espace utilisateur) s'exécute au niveau EL0. Le reste de ce qui est communément appelé "Android" est le noyau Linux, qui s'exécute au niveau EL1.
La couche EL2 permet d'introduire un hyperviseur qui permet d'isoler la mémoire et les appareils dans des pVM individuelles au niveau EL1/EL0, avec de fortes garanties de confidentialité et d'intégrité.
Hyperviseur
La machine virtuelle protégée basée sur le noyau (pKVM) est basée sur l'hyperviseur Linux KVM, qui a été étendu pour permettre de restreindre l'accès aux charges utiles s'exécutant dans les machines virtuelles invitées marquées comme "protégées" au moment de leur création.
KVM/arm64 est compatible avec différents modes d'exécution en fonction de la disponibilité de certaines fonctionnalités du processeur, à savoir les extensions d'hôte de virtualisation (VHE) (ARMv8.1 et versions ultérieures). Dans l'un de ces modes, communément appelé mode non-VHE, le code de l'hyperviseur est extrait de l'image du noyau lors du démarrage et installé au niveau EL2, tandis que le noyau lui-même s'exécute au niveau EL1. Bien qu'il fasse partie du code source Linux, le composant EL2 de KVM est un petit composant chargé de la commutation entre plusieurs EL1. Le composant hyperviseur est compilé avec Linux, mais réside dans une section de mémoire distincte et dédiée de l'image vmlinux. pKVM exploite cette conception en étendant le code de l'hyperviseur avec de nouvelles fonctionnalités lui permettant d'imposer des restrictions au noyau hôte et à l'espace utilisateur Android, et de limiter l'accès de l'hôte à la mémoire invitée et à l'hyperviseur.
Modules de fournisseur pKVM
Un module fournisseur pKVM est un module spécifique au matériel qui contient des fonctionnalités spécifiques à l'appareil, telles que les pilotes d'unité de gestion de mémoire d'entrée/sortie (IOMMU). Ces modules vous permettent de transférer les fonctionnalités de sécurité nécessitant un accès de niveau d'exception 2 (EL2) vers pKVM.
Pour apprendre à implémenter et charger un module fournisseur pKVM, consultez Implémenter un module fournisseur pKVM.
Procédure de démarrage
La figure suivante illustre la procédure de démarrage de pKVM :
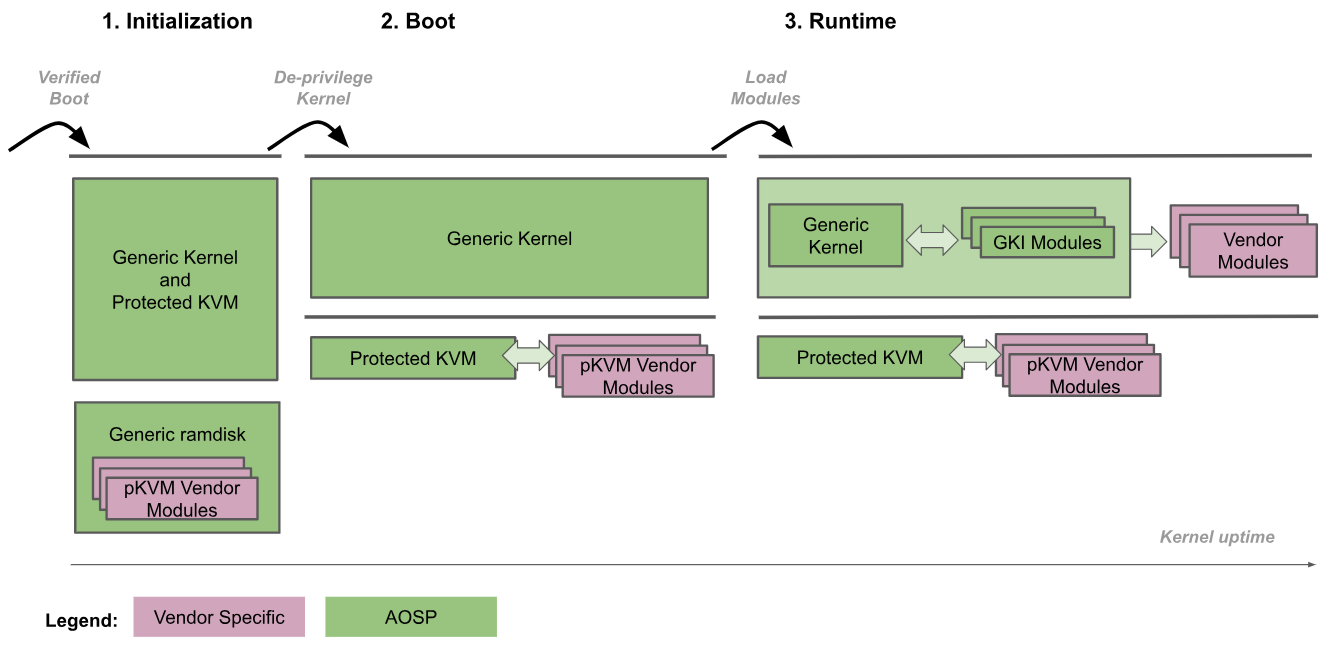
- Initialisation : le bootloader accède au noyau générique au niveau EL2. Le code du noyau de confiance aux niveaux EL2 et EL1 initialise ensuite pKVM et ses modules. Au cours de cette phase, EL1 est approuvé par EL2, de sorte qu'aucun code non approuvé n'est exécuté.
- Déprivilégier le noyau : le noyau générique détecte qu'il s'exécute au niveau EL2 et se déprivilégie au niveau EL1. pKVM et ses modules continuent de s'exécuter au niveau EL2.
- Exécution : le noyau générique procède au démarrage normal, en chargeant tous les pilotes de périphériques nécessaires jusqu'à atteindre l'espace utilisateur. À ce stade, pKVM est en place et gère les tables de pages de niveau 2.
La procédure de démarrage fait confiance au bootloader pour vérifier et maintenir l'intégrité de l'image du noyau pour la phase d'initialisation. Une fois le noyau dépouillé de ses privilèges, il n'est plus considéré comme fiable par l'hyperviseur, qui est alors responsable de sa propre protection, même si le noyau est compromis.
Le fait d'avoir le noyau Android et l'hyperviseur dans la même image binaire permet une interface de communication très étroitement couplée entre eux. Ce couplage étroit garantit des mises à jour atomiques des deux composants, ce qui évite d'avoir à maintenir la stabilité de l'interface entre eux et offre une grande flexibilité sans compromettre la maintenabilité à long terme. Ce couplage étroit permet également d'optimiser les performances lorsque les deux composants peuvent coopérer sans impacter les garanties de sécurité fournies par l'hyperviseur.
De plus, l'adoption de GKI dans l'écosystème Android permet automatiquement de déployer l'hyperviseur pKVM sur les appareils Android dans le même binaire que le noyau.
Protection de l'accès à la mémoire du processeur
L'architecture Arm spécifie une unité de gestion de la mémoire (MMU) divisée en deux étapes indépendantes, qui peuvent toutes deux être utilisées pour implémenter la traduction d'adresse et le contrôle des accès à différentes parties de la mémoire. L'unité de gestion de la mémoire (MMU) de niveau 1 est contrôlée par EL1 et permet un premier niveau de traduction d'adresse. L'unité de gestion de la mémoire (MMU) de niveau 1 est utilisée par Linux pour gérer l'espace d'adressage virtuel fourni à chaque processus d'espace utilisateur et à son propre espace d'adressage virtuel.
La MMU de niveau 2 est contrôlée par EL2 et permet l'application d'une deuxième traduction d'adresse sur l'adresse de sortie de la MMU de niveau 1, ce qui donne une adresse physique (PA). La traduction de la phase 2 peut être utilisée par les hyperviseurs pour contrôler et traduire les accès à la mémoire de toutes les VM invitées. Comme le montre la figure 2, lorsque les deux étapes de la traduction sont activées, l'adresse de sortie de l'étape 1 est appelée adresse physique intermédiaire (IPA). Remarque : L'adresse virtuelle (VA) est traduite en IPA, puis en PA.
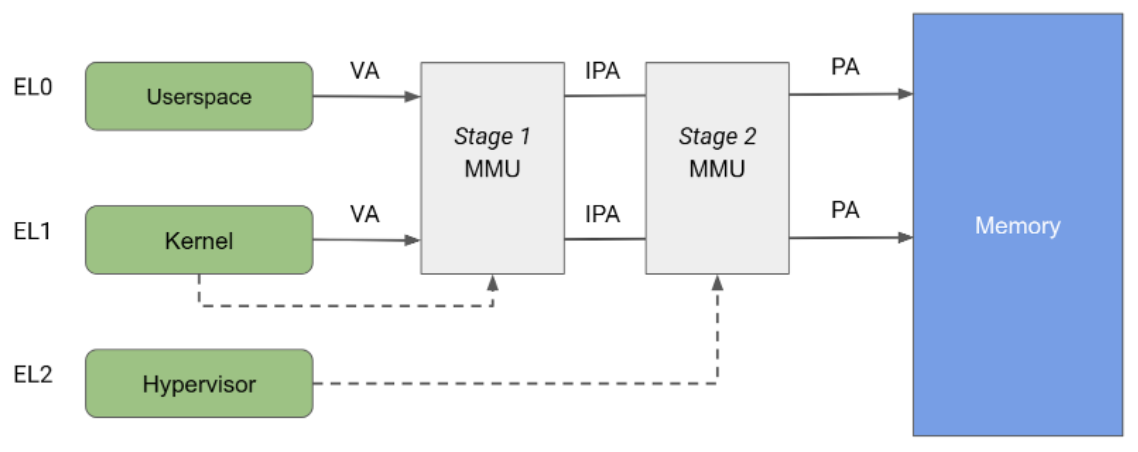
Historiquement, KVM s'exécute avec la traduction de niveau 2 activée lors de l'exécution des invités et avec la traduction de niveau 2 désactivée lors de l'exécution du noyau Linux de l'hôte. Cette architecture permet aux accès mémoire de l'unité de gestion de la mémoire (MMU) de niveau 1 de l'hôte de passer par la MMU de niveau 2, ce qui permet un accès illimité de l'hôte aux pages mémoire de l'invité. En revanche, pKVM permet une protection de niveau 2 même dans le contexte hôte et confie à l'hyperviseur la protection des pages de mémoire invitées au lieu de l'hôte.
KVM utilise pleinement la traduction d'adresse à l'étape 2 pour implémenter des mappages IPA/PA complexes pour les invités, ce qui crée l'illusion d'une mémoire contiguë pour les invités malgré la fragmentation physique. Toutefois, l'utilisation de l'unité de gestion de la mémoire (MMU) de niveau 2 pour l'hôte est limitée au contrôle des accès. L'étape 2 de l'hôte est mappée à l'identité, ce qui garantit que la mémoire contiguë dans l'espace IPA de l'hôte est contiguë dans l'espace PA. Cette architecture permet d'utiliser de grands mappages dans la table des pages et, par conséquent, de réduire la pression sur le tampon de traduction (TLB, translation lookaside buffer). Étant donné qu'un mappage d'identité peut être indexé par PA, l'étape 2 de l'hôte est également utilisée pour suivre la propriété de la page directement dans la table des pages.
Protection de l'accès direct à la mémoire (DMA)
Comme décrit précédemment, la suppression du mappage des pages invitées de l'hôte Linux dans les tables de pages du processeur est une étape nécessaire, mais insuffisante pour protéger la mémoire invitée. pKVM doit également se protéger contre les accès mémoire effectués par les appareils compatibles DMA sous le contrôle du noyau hôte, ainsi que contre la possibilité d'une attaque DMA initiée par un hôte malveillant. Pour empêcher un tel appareil d'accéder à la mémoire invitée, pKVM nécessite un matériel d'unité de gestion de mémoire d'entrée/sortie (IOMMU) pour chaque appareil compatible DMA du système, comme illustré à la figure 3.
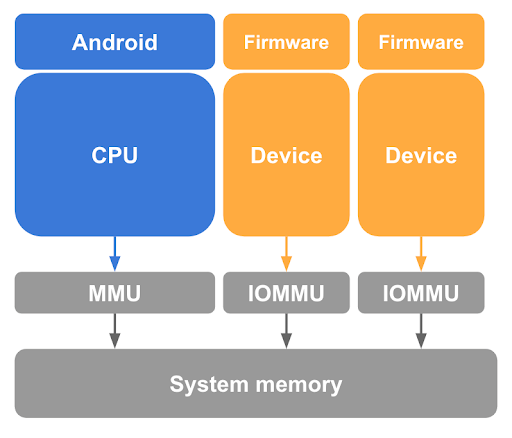
Au minimum, le matériel IOMMU permet d'accorder et de révoquer l'accès en lecture/écriture d'un appareil à la mémoire physique avec une granularité de page. Toutefois, ce matériel IOMMU limite l'utilisation des appareils dans les PV, car ils supposent une étape 2 avec mappage d'identité.
Pour garantir l'isolation entre les machines virtuelles, les transactions de mémoire générées pour le compte de différentes entités doivent être distinguables par l'IOMMU afin que l'ensemble approprié de tables de pages puisse être utilisé pour la traduction.
De plus, la réduction de la quantité de code spécifique au SoC au niveau EL2 est une stratégie clé pour réduire la base de calcul sécurisée (TCB) globale de pKVM et va à l'encontre de l'inclusion des pilotes IOMMU dans l'hyperviseur. Pour atténuer ce problème, l'hôte au niveau EL1 est responsable des tâches de gestion IOMMU auxiliaires, telles que la gestion de l'alimentation, l'initialisation et, le cas échéant, la gestion des interruptions.
Toutefois, le fait de laisser l'hôte contrôler l'état de l'appareil impose des exigences supplémentaires à l'interface de programmation du matériel IOMMU pour s'assurer que les vérifications des autorisations ne peuvent pas être contournées par d'autres moyens, par exemple après une réinitialisation de l'appareil.
L'architecture Arm SMMU (System Memory Management Unit) est une IOMMU standard et bien prise en charge pour les appareils Arm. Elle permet à la fois l'isolation et l'attribution directe. Cette architecture est la solution de référence recommandée.
Propriété des souvenirs
Au moment du démarrage, toute la mémoire non hyperviseur est supposée appartenir à l'hôte et est suivie en tant que telle par l'hyperviseur. Lorsqu'une pVM est générée, l'hôte lui attribue des pages de mémoire pour lui permettre de démarrer, et l'hyperviseur transfère la propriété de ces pages de l'hôte à la pVM. L'hyperviseur met donc en place des restrictions de contrôle d'accès dans la table de pages de niveau 2 de l'hôte pour l'empêcher d'accéder à nouveau aux pages, ce qui garantit la confidentialité de l'invité.
La communication entre l'hôte et les invités est possible grâce au partage contrôlé de la mémoire entre eux. Les invités sont autorisés à partager certaines de leurs pages avec l'hôte à l'aide d'un hypercall, qui demande à l'hyperviseur de remapper ces pages dans la table de pages de l'hôte de niveau 2. De même, la communication de l'hôte avec TrustZone est rendue possible par des opérations de partage et/ou de prêt de mémoire, qui sont toutes étroitement surveillées et contrôlées par pKVM à l'aide de la spécification Firmware Framework for Arm (FF-A).
Étant donné que les besoins en mémoire d'une pVM peuvent évoluer au fil du temps, un hypercall est fourni, ce qui permet de restituer au hôte la propriété des pages spécifiées appartenant à l'appelant. En pratique, cet hypercall est utilisé avec le protocole virtio balloon pour permettre au VMM de demander de la mémoire à la pVM et à la pVM d'informer le VMM des pages libérées, de manière contrôlée.
L'hyperviseur est responsable du suivi de la propriété de toutes les pages de mémoire du système et de la détermination de leur partage ou de leur prêt à d'autres entités. La plupart de ce suivi d'état est effectué à l'aide de métadonnées associées aux tables de pages de niveau 2 de l'hôte et des invités, à l'aide de bits réservés dans les entrées de table de pages (PTE), qui, comme leur nom l'indique, sont réservées à l'utilisation logicielle.
L'hôte doit s'assurer de ne pas tenter d'accéder à des pages rendues inaccessibles par l'hyperviseur. Un accès hôte illégal entraîne l'injection d'une exception synchrone dans l'hôte par l'hyperviseur, ce qui peut entraîner la réception d'un signal SEGV par la tâche d'espace utilisateur responsable ou le plantage du noyau de l'hôte. Pour éviter les accès accidentels, les pages attribuées aux invités ne peuvent pas être échangées ni fusionnées par le noyau hôte.
Gestion des interruptions et des minuteurs
Les interruptions sont un élément essentiel de la façon dont un invité interagit avec les appareils et pour la communication entre les processeurs, où les interruptions interprocesseur (IPI) sont le principal mécanisme de communication. Le modèle KVM consiste à déléguer toute la gestion des interruptions virtuelles à l'hôte dans EL1, qui se comporte à cet effet comme une partie non fiable de l'hyperviseur.
pKVM offre une émulation complète de la version 3 du contrôleur d'interruption générique (GICv3) basée sur le code KVM existant. Les minuteurs et les IPI sont gérés dans le cadre de ce code d'émulation non fiable.
Compatibilité avec GICv3
L'interface entre EL1 et EL2 doit garantir que l'état d'interruption complet est visible pour l'hôte EL1, y compris les copies des registres de l'hyperviseur liés aux interruptions. Cette visibilité est généralement obtenue à l'aide de régions de mémoire partagée, une par processeur virtuel (vCPU).
Le code d'assistance de l'environnement d'exécution du registre système peut être simplifié pour ne prendre en charge que le trapping du registre SGIR (Software Generated Interrupt Register) et du registre DIR (Deactivate Interrupt Register). L'architecture exige que ces registres soient toujours interceptés par EL2, tandis que les autres pièges n'ont jusqu'à présent été utiles que pour atténuer les errata. Tout le reste est géré par le matériel.
Du côté MMIO, tout est émulé au niveau EL1, en réutilisant toute l'infrastructure actuelle dans KVM. Enfin, Wait for Interrupt (WFI) est toujours relayé vers EL1, car il s'agit de l'une des primitives de planification de base utilisées par KVM.
Assistance pour le minuteur
La valeur du comparateur pour le minuteur virtuel doit être exposée à EL1 sur chaque WFI de capture afin qu'EL1 puisse injecter des interruptions de minuteur lorsque la vCPU est bloquée. Le minuteur physique est entièrement émulé et tous les pièges sont relayés vers EL1.
Gestion des MMIO
Pour communiquer avec le moniteur de machine virtuelle (VMM) et effectuer l'émulation GIC, les traps MMIO doivent être relayés vers l'hôte dans EL1 pour un tri plus approfondi. pKVM nécessite les éléments suivants :
- Adresse IP et taille de l'accès
- Données en cas d'écriture
- Endianness du processeur au moment de l'interception
De plus, les traps avec un registre à usage général (GPR) comme source/destination sont relayés à l'aide d'un pseudo-registre de transfert abstrait.
Interfaces invitées
Un invité peut communiquer avec un invité protégé en utilisant une combinaison d'hypercalls et d'accès à la mémoire pour les régions piégées. Les hypercalls sont exposés conformément à la norme SMCCC, avec une plage réservée à une allocation de fournisseur par KVM. Les hypercalls suivants sont particulièrement importants pour les invités pKVM.
Hyperappels génériques
- PSCI fournit un mécanisme standard permettant à l'invité de contrôler le cycle de vie de ses vCPU, y compris la mise en ligne, la mise hors ligne et l'arrêt du système.
- TRNG fournit un mécanisme standard permettant à l'invité de demander de l'entropie au pKVM, qui relaie l'appel à EL3. Ce mécanisme est particulièrement utile lorsque l'hôte ne peut pas être considéré comme fiable pour virtualiser un générateur de nombres aléatoires (RNG) matériel.
Hyperappels pKVM
- Partage de mémoire avec l'hôte. Toute la mémoire invitée est initialement inaccessible à l'hôte, mais l'accès hôte est nécessaire pour la communication en mémoire partagée et pour les appareils paravirtualisés qui s'appuient sur des tampons partagés. Les hypercalls pour le partage et l'annulation du partage de pages avec l'hôte permettent à l'invité de décider exactement quelles parties de la mémoire sont rendues accessibles au reste d'Android sans avoir besoin d'une poignée de main.
- Libération de la mémoire vers l'hôte. Toute la mémoire invitée appartient généralement à l'invité jusqu'à ce qu'elle soit détruite. Cet état peut être insuffisant pour les VM de longue durée dont les besoins en mémoire varient au fil du temps. L'hypercall
relinquishpermet à un invité de transférer explicitement la propriété des pages à l'hôte sans nécessiter la fin de l'invité. - Piégeage de l'accès à la mémoire de l'hôte. Traditionnellement, si un invité KVM accède à une adresse qui ne correspond pas à une région de mémoire valide, le thread de vCPU quitte l'hôte et l'accès est généralement utilisé pour MMIO et émulé par le VMM dans l'espace utilisateur. Pour faciliter cette gestion, pKVM doit communiquer à l'hôte des informations sur l'instruction à l'origine de la défaillance, telles que son adresse, ses paramètres d'enregistrement et potentiellement leur contenu. Cela pourrait involontairement exposer des données sensibles d'un invité protégé si le piège n'avait pas été anticipé. pKVM résout ce problème en traitant ces défaillances comme fatales, sauf si l'invité a précédemment émis un hyperappel pour identifier la plage d'adresses IP à l'origine de la défaillance comme une plage pour laquelle les accès sont autorisés à être piégés vers l'hôte. Cette solution est appelée protection MMIO.
Appareil d'E/S virtuel (virtio)
Virtio est une norme populaire, portable et mature pour implémenter des périphériques paravirtualisés et interagir avec eux. La majorité des appareils exposés aux invités protégés sont implémentés à l'aide de virtio. Virtio est également à la base de l'implémentation vsock utilisée pour la communication entre un invité protégé et le reste d'Android.
Les périphériques Virtio sont généralement implémentés dans l'espace utilisateur de l'hôte par le VMM, qui intercepte les accès mémoire piégés de l'invité à l'interface MMIO du périphérique virtio et émule le comportement attendu. L'accès MMIO est relativement coûteux, car chaque accès à l'appareil nécessite un aller-retour vers le VMM. La plupart des transferts de données réels entre l'appareil et l'invité se font donc à l'aide d'un ensemble de virtqueues en mémoire. Une hypothèse clé de virtio est que l'hôte peut accéder à la mémoire invitée de manière arbitraire. Cette hypothèse est évidente dans la conception de la virtqueue, qui peut contenir des pointeurs vers des tampons dans l'invité auxquels l'émulation de l'appareil est censée accéder directement.
Bien que les hypercalls de partage de mémoire décrits précédemment puissent être utilisés pour partager des tampons de données virtio de l'invité à l'hôte, ce partage est nécessairement effectué avec une granularité de page et pourrait finir par exposer plus de données que nécessaire si la taille de la mémoire tampon est inférieure à celle d'une page. Au lieu de cela, l'invité est configuré pour allouer les virtqueues et leurs tampons de données correspondants à partir d'une fenêtre fixe de mémoire partagée, les données étant copiées (retransmises) vers et depuis la fenêtre selon les besoins.
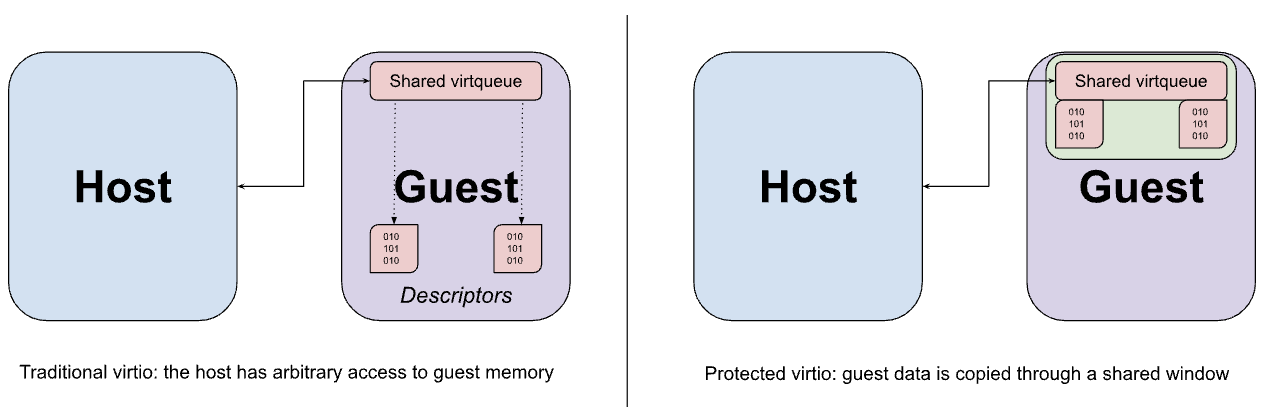
Interaction avec TrustZone
Bien que les invités ne puissent pas interagir directement avec TrustZone, l'hôte doit toujours pouvoir émettre des appels SMC dans le monde sécurisé. Ces appels peuvent spécifier des tampons de mémoire adressés physiquement et inaccessibles à l'hôte. Étant donné que le logiciel sécurisé n'est généralement pas au courant de l'accessibilité du tampon, un hôte malveillant peut utiliser ce tampon pour effectuer une attaque de type "confused deputy" (analogue à une attaque DMA). Pour éviter de telles attaques, pKVM intercepte tous les appels SMC de l'hôte vers EL2 et sert de proxy entre l'hôte et le Secure Monitor au niveau EL3.
Les appels PSCI de l'hôte sont transférés au micrologiciel EL3 avec des modifications minimales. Plus précisément, le point d'entrée d'un processeur qui se met en ligne ou qui reprend son activité après une suspension est réécrit de sorte que la table de pages de niveau 2 soit installée au niveau EL2 avant de revenir à l'hôte au niveau EL1. Au démarrage, cette protection est appliquée par pKVM.
Cette architecture repose sur le SoC prenant en charge PSCI, de préférence en utilisant une version à jour de TF-A comme micrologiciel EL3.
La norme Firmware Framework for Arm (FF-A) standardise les interactions entre les mondes normal et sécurisé, en particulier en présence d'un hyperviseur sécurisé. Une grande partie de la spécification définit un mécanisme de partage de mémoire avec le monde sécurisé, en utilisant à la fois un format de message commun et un modèle d'autorisations bien défini pour les pages sous-jacentes. pKVM sert de proxy pour les messages FF-A afin de s'assurer que l'hôte ne tente pas de partager de la mémoire avec le côté sécurisé pour lequel il ne dispose pas des autorisations suffisantes.
Cette architecture repose sur le logiciel Secure World qui applique le modèle d'accès à la mémoire. Elle permet de s'assurer que les applications approuvées et tout autre logiciel exécuté dans Secure World ne peuvent accéder à la mémoire que si elle appartient exclusivement à Secure World ou si elle a été explicitement partagée avec lui à l'aide de FF-A. Sur un système avec S-EL2, l'application du modèle d'accès à la mémoire doit être effectuée par un Secure Partition Manager Core (SPMC), tel que Hafnium, qui gère les tables de pages de niveau 2 pour le monde sécurisé. Sur un système sans S-EL2, le TEE peut appliquer un modèle d'accès à la mémoire via ses tables de pages de niveau 1.
Si l'appel SMC à EL2 n'est pas un appel PSCI ni un message défini par FF-A, les SMC non traités sont transférés à EL3. L'hypothèse est que le micrologiciel sécurisé (nécessairement fiable) peut gérer les SMC non traités de manière sécurisée, car il comprend les précautions nécessaires pour maintenir l'isolation de la pVM.
Moniteur de machine virtuelle
crosvm est un moniteur de machine virtuelle (VMM) qui exécute des machines virtuelles via l'interface KVM de Linux. La particularité de crosvm réside dans son accent sur la sécurité grâce à l'utilisation du langage de programmation Rust et d'un bac à sable autour des périphériques virtuels pour protéger le noyau hôte. Pour en savoir plus sur crosvm, consultez sa documentation officielle ici.
Descripteurs de fichiers et ioctls
KVM expose le périphérique de caractères /dev/kvm à l'espace utilisateur avec des ioctls qui composent l'API KVM. Les ioctls appartiennent aux catégories suivantes :
- Les ioctls système interrogent et définissent les attributs globaux qui affectent l'ensemble du sous-système KVM, et créent des pVM.
- Les ioctl de VM interrogent et définissent des attributs qui créent des processeurs virtuels (vCPU) et des appareils, et affectent une VM protégée entière, comme la disposition de la mémoire et le nombre de processeurs virtuels (vCPU) et d'appareils.
- Les ioctls de vCPU interrogent et définissent les attributs qui contrôlent le fonctionnement d'un seul CPU virtuel.
- Les ioctls d'appareil interrogent et définissent les attributs qui contrôlent le fonctionnement d'un seul appareil virtuel.
Chaque processus crosvm exécute exactement une instance de machine virtuelle. Ce processus utilise le système KVM_CREATE_VM ioctl pour créer un descripteur de fichier VM qui peut être utilisé pour émettre des ioctl pVM. Un ioctl KVM_CREATE_VCPU ou KVM_CREATE_DEVICE sur un FD de VM crée un vCPU/appareil et renvoie un descripteur de fichier pointant vers la nouvelle ressource. Les ioctls sur un FD de vCPU ou d'appareil peuvent être utilisés pour contrôler l'appareil créé à l'aide de l'ioctl sur un FD de VM. Pour les processeurs virtuels, cela inclut la tâche importante d'exécution du code invité.
En interne, crosvm enregistre les descripteurs de fichier de la VM auprès du noyau à l'aide de l'interface epoll à déclenchement par front. Le noyau avertit ensuite crosvm chaque fois qu'un nouvel événement est en attente dans l'un des descripteurs de fichier.
pKVM ajoute une nouvelle fonctionnalité, KVM_CAP_ARM_PROTECTED_VM, qui peut être utilisée pour obtenir des informations sur l'environnement pVM et configurer le mode protégé pour une VM. crosvm l'utilise lors de la création de pVM si l'indicateur --protected-vm est transmis, pour interroger et réserver la quantité de mémoire appropriée pour le micrologiciel pVM, puis pour activer le mode protégé.
Allocation de mémoire
L'une des principales responsabilités d'un VMM est d'allouer la mémoire de la VM et de gérer sa disposition de mémoire. crosvm génère une disposition de mémoire fixe décrite de manière approximative dans le tableau ci-dessous.
| FDT en mode normal | PHYS_MEMORY_END - 0x200000
|
| Espace disponible | ...
|
| Ramdisk | ALIGN_UP(KERNEL_END, 0x1000000)
|
| Noyau | 0x80080000
|
| Bootloader | 0x80200000
|
| FDT en mode BIOS | 0x80000000
|
| Base de la mémoire physique | 0x80000000
|
| Micrologiciel des pVM | 0x7FE00000
|
| Mémoire de l'appareil | 0x10000 - 0x40000000
|
La mémoire physique est allouée avec mmap et la mémoire est donnée à la VM pour remplir ses régions de mémoire, appelées memslots, avec l'ioctl KVM_SET_USER_MEMORY_REGION. Toute la mémoire de la VM invitée est donc attribuée à l'instance crosvm qui la gère, ce qui peut entraîner l'arrêt du processus (et donc de la VM) si l'hôte commence à manquer de mémoire libre. Lorsqu'une VM est arrêtée, la mémoire est automatiquement effacée par l'hyperviseur et renvoyée au noyau de l'hôte.
Avec KVM standard, le VMM conserve l'accès à toute la mémoire invitée. Avec pKVM, la mémoire invitée est non mappée à partir de l'espace d'adressage physique de l'hôte lorsqu'elle est donnée à l'invité. La seule exception concerne la mémoire explicitement partagée par l'invité, par exemple pour les appareils virtio.
Les régions MMIO de l'espace d'adressage de l'invité ne sont pas mappées. L'accès à ces régions par l'invité est intercepté et entraîne un événement d'E/S sur le FD de la VM. Ce mécanisme est utilisé pour implémenter des appareils virtuels. En mode protégé, l'invité doit reconnaître qu'une région de son espace d'adressage est utilisée pour MMIO à l'aide d'un hypercall, afin de réduire le risque de fuite accidentelle d'informations.
Planification
Chaque processeur virtuel est représenté par un thread POSIX et planifié par le planificateur Linux de l'hôte. Le thread appelle KVM_RUN ioctl sur le FD du vCPU, ce qui entraîne le passage de l'hyperviseur au contexte du vCPU invité. Le planificateur hôte comptabilise le temps passé dans un contexte invité comme du temps utilisé par le thread de vCPU correspondant. KVM_RUN est renvoyé lorsqu'un événement doit être géré par le VMM, comme une E/S, la fin d'une interruption ou l'arrêt du processeur virtuel. Le VMM gère l'événement et appelle à nouveau KVM_RUN.
Pendant KVM_RUN, le thread reste préemptible par le planificateur hôte, à l'exception de l'exécution du code de l'hyperviseur EL2, qui n'est pas préemptible. La VM invitée elle-même ne dispose d'aucun mécanisme pour contrôler ce comportement.
Étant donné que tous les threads de processeur virtuel sont planifiés comme n'importe quelle autre tâche d'espace utilisateur, ils sont soumis à tous les mécanismes de qualité de service standards. Plus précisément, chaque thread de processeur virtuel peut être affiné aux processeurs physiques, placé dans des cpusets, boosté ou limité à l'aide du clamping d'utilisation, voir sa priorité/sa stratégie de planification modifiée, et plus encore.
Appareils virtuels
crosvm est compatible avec un certain nombre d'appareils, y compris les suivants :
- virtio-blk pour les images de disque composite, en lecture seule ou en lecture/écriture
- vhost-vsock pour la communication avec l'hôte
- virtio-pci en tant que transport virtio
- Horloge en temps réel (RTC) pl030
- UART 16550a pour la communication série
Micrologiciel des pVM
Le micrologiciel des pVM (pvmfw) est le premier code exécuté par une pVM, comme la ROM de démarrage d'un appareil physique. L'objectif principal de pvmfw est d'amorcer le démarrage sécurisé et de dériver le secret unique de la pVM. pvmfw n'est pas limité à l'utilisation avec un OS spécifique, tel que Microdroid, tant que l'OS est pris en charge par crosvm et a été correctement signé.
Le binaire pvmfw est stocké dans une partition flash du même nom et est mis à jour à l'aide d'OTA.
Démarrage de l'appareil
La séquence d'étapes suivante est ajoutée à la procédure de démarrage d'un appareil compatible pKVM :
- Le bootloader Android (ABL) charge pvmfw depuis sa partition dans la mémoire et vérifie l'image.
- L'ABL obtient ses secrets DICE (Device Identifier Composition Engine) (identifiants d'appareil composés (CDI) et chaîne de certificats DICE) à partir d'une racine de confiance.
- L'ABL dérive les CDI nécessaires pour pvmfw et les ajoute au binaire pvmfw.
- L'ABL ajoute un nœud de région de mémoire réservée
linux,pkvm-guest-firmware-memoryau DT, décrivant l'emplacement et la taille du binaire pvmfw et des secrets qu'il a dérivés à l'étape précédente. - L'ABL cède le contrôle à Linux, qui initialise pKVM.
- pKVM supprime le mappage de la région de mémoire pvmfw des tables de pages de niveau 2 de l'hôte et la protège de l'hôte (et des invités) pendant toute la durée de fonctionnement de l'appareil.
Après le démarrage de l'appareil, Microdroid est démarré en suivant les étapes de la section Séquence de démarrage du document Microdroid.
Démarrage de la VM protégée
Lors de la création d'une pVM, crosvm (ou un autre VMM) doit créer un emplacement mémoire suffisamment grand pour être rempli avec l'image pvmfw par l'hyperviseur. Le VMM est également limité dans la liste des registres dont il peut définir la valeur initiale (x0-x14 pour le processeur virtuel principal, aucun pour les processeurs virtuels secondaires). Les registres restants sont réservés et font partie de l'ABI hypervisor-pvmfw.
Lorsque la pVM est exécutée, l'hyperviseur transmet d'abord le contrôle du processeur virtuel principal à pvmfw. Le micrologiciel s'attend à ce que crosvm ait chargé un noyau signé AVB, qui peut être un bootloader ou toute autre image, et un FDT non signé en mémoire à des décalages connus. pvmfw valide la signature AVB et, en cas de succès, génère un arbre de périphériques de confiance à partir du FDT reçu, efface ses secrets de la mémoire et passe au point d'entrée de la charge utile. Si l'une des étapes de validation échoue, le micrologiciel émet un hypercall PSCI SYSTEM_RESET.
Entre les démarrages, les informations sur l'instance de VM protégée sont stockées dans une partition (périphérique virtio-blk) et chiffrées avec le code secret de pvmfw pour s'assurer qu'après un redémarrage, le code secret est provisionné pour la bonne instance.