
Android fornisce un'implementazione di riferimento di tutti i componenti necessari per implementare il Framework di virtualizzazione di Android. Al momento, questa implementazione è limitata ad ARM64. Questa pagina descrive l'architettura del framework.
Sfondo
L'architettura Arm consente fino a quattro livelli di eccezione, con il livello di eccezione 0 (EL0) che è il meno privilegiato e il livello di eccezione 3 (EL3) il più privilegiato. La maggior parte del codebase Android (tutti i componenti dello spazio utente) viene eseguita a livello EL0. Il resto di quello che viene comunemente chiamato "Android" è il kernel Linux, che viene eseguito a livello EL1.
Il livello EL2 consente l'introduzione di un hypervisor che permette di isolare memoria e dispositivi in singole pVM a livello EL1/EL0, con solide garanzie di riservatezza e integrità.
Hypervisor
La macchina virtuale basata su kernel (pKVM) protetta si basa sull'hypervisor Linux KVM, che è stato esteso con la possibilità di limitare l'accesso ai payload in esecuzione nelle macchine virtuali guest contrassegnate come "protette" al momento della creazione.
KVM/arm64 supporta diverse modalità di esecuzione a seconda della disponibilità di
determinate funzionalità della CPU, ovvero le estensioni host di virtualizzazione (VHE) (ARMv8.1
e versioni successive). In una di queste modalità, comunemente nota come modalità non VHE, il
codice dell'hypervisor viene estratto dall'immagine del kernel durante l'avvio e installato a
EL2, mentre il kernel stesso viene eseguito a EL1. Sebbene faccia parte del
codice base di Linux, il componente EL2 di KVM è un piccolo componente incaricato di
passare da un EL1 all'altro. Il componente hypervisor viene compilato con
Linux, ma si trova in una sezione di memoria separata e dedicata dell'immagine vmlinux. pKVM sfrutta questo design estendendo il codice dell'hypervisor con nuove
funzionalità che gli consentono di imporre restrizioni al kernel host Android e allo spazio
utente e di limitare l'accesso dell'host alla memoria guest e all'hypervisor.
Moduli fornitore pKVM
Un modulo fornitore pKVM è un modulo specifico dell'hardware contenente funzionalità specifiche del dispositivo, come i driver dell'unità di gestione della memoria di input/output (IOMMU). Questi moduli consentono di trasferire a pKVM le funzionalità di sicurezza che richiedono l'accesso al livello di eccezione 2 (EL2).
Per scoprire come implementare e caricare un modulo fornitore pKVM, consulta Implementare un modulo fornitore pKVM.
Procedura di avvio
La figura seguente mostra la procedura di avvio di pKVM:
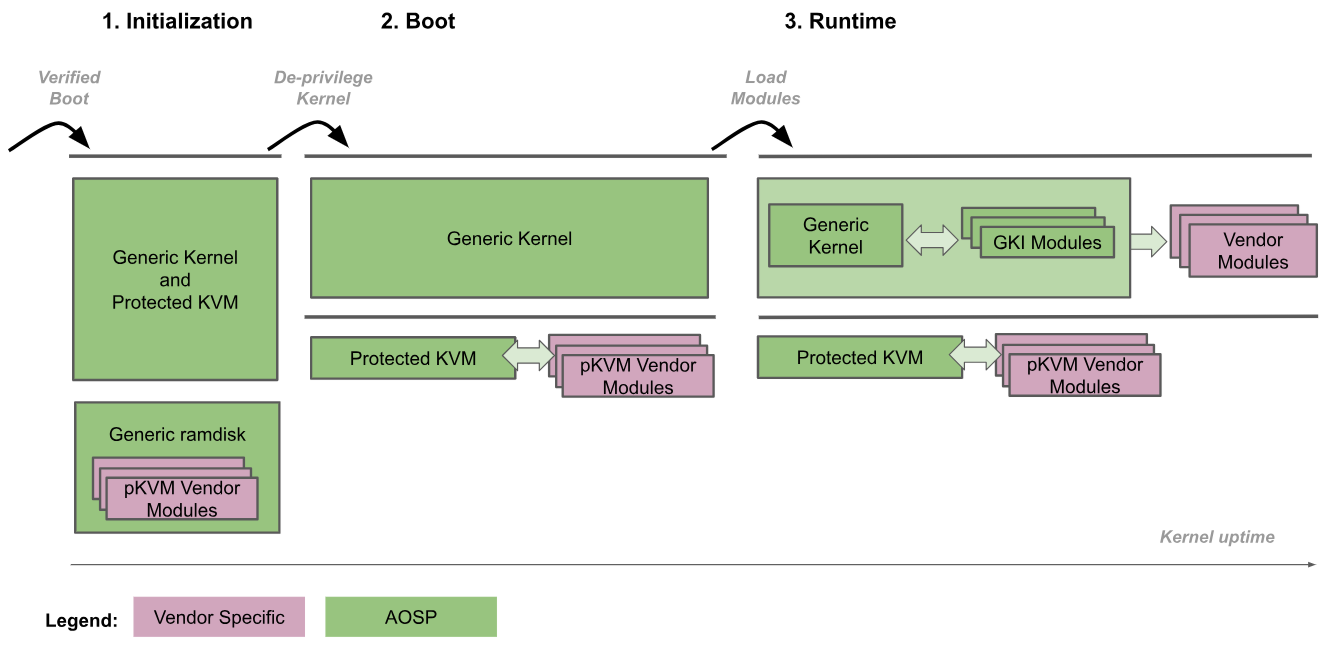
- Inizializzazione:il bootloader entra nel kernel generico a EL2. Il codice del kernel attendibile a livello EL2 ed EL1 inizializza pKVM e i relativi moduli. Durante questa fase, EL1 è considerato attendibile da EL2, quindi non viene eseguito codice non attendibile.
- Deprivilege Kernel: il kernel generico rileva che è in esecuzione a EL2 e si deprivilegia a EL1. pKVM e i relativi moduli continuano a essere eseguiti a EL2.
- Runtime: il kernel generico procede all'avvio normalmente, caricando tutti i driver di dispositivo necessari fino a raggiungere lo spazio utente. A questo punto, pKVM è in posizione e gestisce le tabelle di pagine di fase 2.
La procedura di avvio considera il bootloader attendibile per verificare e mantenere l'integrità dell'immagine del kernel per la fase di inizializzazione. Una volta de-privilegiato, il kernel non è più considerato attendibile dall'hypervisor, che è quindi responsabile della propria protezione anche se il kernel è compromesso.
La presenza del kernel Android e dell'hypervisor nella stessa immagine binaria consente un'interfaccia di comunicazione molto strettamente accoppiata tra loro. Questo stretto accoppiamento garantisce aggiornamenti atomici dei due componenti, il che evita la necessità di mantenere stabile l'interfaccia tra loro e offre una grande flessibilità senza compromettere la manutenibilità a lungo termine. L'alto accoppiamento consente anche ottimizzazioni delle prestazioni quando entrambi i componenti possono cooperare senza influire sulle garanzie di sicurezza fornite dall'hypervisor.
Inoltre, l'adozione di GKI nell'ecosistema Android consente automaticamente l'implementazione dell'hypervisor pKVM sui dispositivi Android nello stesso binario del kernel.
Protezione dell'accesso alla memoria della CPU
L'architettura Arm specifica una Memory Management Unit (MMU) suddivisa in due fasi indipendenti, entrambe utilizzabili per implementare la conversione degli indirizzi e il controllo dell'accesso a diverse parti della memoria. L'MMU di fase 1 è controllata da EL1 e consente un primo livello di conversione degli indirizzi. La MMU di fase 1 viene utilizzata da Linux per gestire lo spazio di indirizzi virtuali fornito a ogni processo userspace e al proprio spazio di indirizzi virtuali.
La MMU di fase 2 è controllata da EL2 e consente l'applicazione di una seconda traduzione dell'indirizzo sull'indirizzo di output della MMU di fase 1, con conseguente indirizzo fisico (PA). La traduzione di secondo livello può essere utilizzata dagli hypervisor per controllare e tradurre gli accessi alla memoria da tutte le VM guest. Come mostrato nella Figura 2, quando entrambe le fasi di traduzione sono abilitate, l'indirizzo di output della fase 1 viene chiamato indirizzo fisico intermedio (IPA). Nota: l'indirizzo virtuale (VA) viene tradotto in un IPA e poi in un PA.
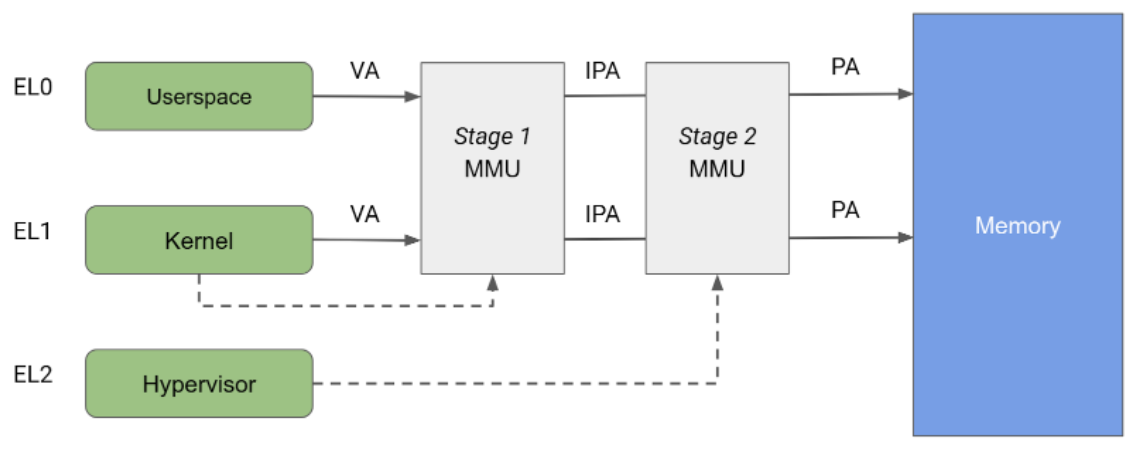
Storicamente, KVM viene eseguito con la traduzione di fase 2 abilitata durante l'esecuzione degli ospiti e con la fase 2 disabilitata durante l'esecuzione del kernel Linux host. Questa architettura consente agli accessi alla memoria dalla MMU di fase 1 dell'host di passare attraverso la MMU di fase 2, consentendo quindi l'accesso senza restrizioni dall'host alle pagine di memoria guest. D'altra parte, pKVM abilita la protezione di fase 2 anche nel contesto host e affida all'hypervisor la protezione delle pagine di memoria guest anziché all'host.
KVM utilizza la traduzione degli indirizzi nella fase 2 per implementare mappature IPA/PA complesse per gli ospiti, il che crea l'illusione di una memoria contigua per gli ospiti nonostante la frammentazione fisica. Tuttavia, l'utilizzo dell'MMU di fase 2 per l'host è limitato al solo controllo dell'accesso. L'host stage 2 è mappato in base all'identità, garantendo che la memoria contigua nello spazio IPA host sia contigua nello spazio PA. Questa architettura consente l'utilizzo di mapping di grandi dimensioni nella tabella delle pagine e di conseguenza riduce la pressione sul translation lookaside buffer (TLB). Poiché una mappatura delle identità può essere indicizzata da PA, la fase 2 dell'host viene utilizzata anche per monitorare la proprietà della pagina direttamente nella tabella delle pagine.
Protezione dell'accesso diretto alla memoria (DMA)
Come descritto in precedenza, l'annullamento del mapping delle pagine guest dall'host Linux nelle tabelle delle pagine della CPU è un passaggio necessario ma insufficiente per proteggere la memoria guest. pKVM deve anche proteggere dagli accessi alla memoria effettuati da dispositivi compatibili con DMA sotto il controllo del kernel host e dalla possibilità di un attacco DMA avviato da un host dannoso. Per impedire a un dispositivo di questo tipo di accedere alla memoria guest, pKVM richiede l'hardware dell'unità di gestione della memoria di input/output (IOMMU) per ogni dispositivo compatibile con DMA nel sistema, come mostrato nella figura 3.
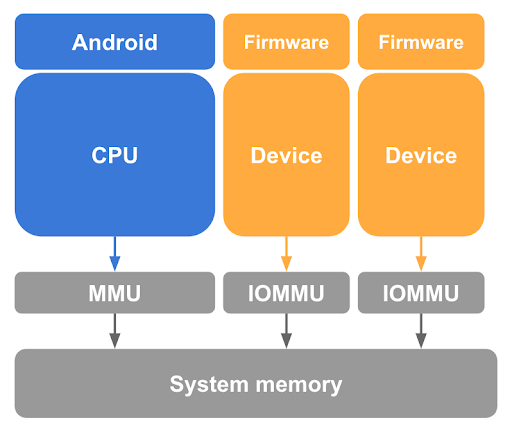
Come minimo, l'hardware IOMMU fornisce i mezzi per concedere e revocare l'accesso in lettura/scrittura per un dispositivo alla memoria fisica con granularità di pagina. Tuttavia, questo hardware IOMMU limita l'utilizzo dei dispositivi nelle pVM in quanto presuppongono una fase 2 con mappatura dell'identità.
Per garantire l'isolamento tra le macchine virtuali, le transazioni di memoria generate per conto di entità diverse devono essere distinguibili dalla IOMMU in modo che possa essere utilizzato il set appropriato di tabelle di pagine per la traduzione.
Inoltre, la riduzione della quantità di codice specifico per SoC a EL2 è una strategia chiave per ridurre la base di calcolo attendibile (TCB) complessiva di pKVM e va contro l'inclusione dei driver IOMMU nell'hypervisor. Per risolvere questo problema, l'host a livello EL1 è responsabile delle attività di gestione IOMMU ausiliarie, come la gestione dell'alimentazione, l'inizializzazione e, se appropriato, la gestione degli interrupt.
Tuttavia, il controllo dello stato del dispositivo da parte dell'host impone requisiti aggiuntivi all'interfaccia di programmazione dell'hardware IOMMU per garantire che i controlli delle autorizzazioni non possano essere aggirati con altri mezzi, ad esempio dopo un ripristino del dispositivo.
Un'IOMMU standard e ben supportata per i dispositivi Arm che rende possibile sia l'isolamento che l'assegnazione diretta è l'architettura Arm System Memory Management Unit (SMMU). Questa architettura è la soluzione di riferimento consigliata.
Proprietà dei ricordi
Al momento dell'avvio, si presume che tutta la memoria non hypervisor sia di proprietà dell'host e viene monitorata come tale dall'hypervisor. Quando viene generata una pVM, l'host dona pagine di memoria per consentirne l'avvio e l'hypervisor trasferisce la proprietà di queste pagine dall'host alla pVM. Pertanto, l'hypervisor impone restrizioni di controllo dell'accesso nella tabella delle pagine di secondo livello dell'host per impedirgli di accedere nuovamente alle pagine, garantendo la riservatezza dell'ospite.
La comunicazione tra l'host e gli ospiti è resa possibile dalla condivisione controllata della memoria tra loro. Gli ospiti possono condividere alcune delle loro pagine con l'host utilizzando un'iperchiamata, che indica all'hypervisor di rimappare queste pagine nella tabella delle pagine di secondo livello dell'host. Analogamente, la comunicazione dell'host con TrustZone è resa possibile dalle operazioni di condivisione e/o prestito della memoria, tutte strettamente monitorate e controllate da pKVM utilizzando la specifica Firmware Framework for Arm (FF-A).
Poiché i requisiti di memoria di una pVM possono cambiare nel tempo, viene fornita una chiamata di sistema che consente di restituire al sistema operativo host la proprietà delle pagine specificate appartenenti al chiamante. In pratica, questa hypercall viene utilizzata con il protocollo virtio balloon per consentire al VMM di richiedere memoria alla pVM e alla pVM di notificare al VMM le pagine cedute, in modo controllato.
L'hypervisor è responsabile del monitoraggio della proprietà di tutte le pagine di memoria del sistema e della condivisione o del prestito ad altre entità. La maggior parte di questo monitoraggio dello stato viene eseguita utilizzando i metadati allegati alle tabelle di pagine di fase 2 dell'host e degli ospiti, utilizzando bit riservati nelle voci della tabella di pagine (PTE) che, come suggerisce il nome, sono riservati all'uso del software.
L'host deve assicurarsi di non tentare di accedere a pagine rese inaccessibili dall'hypervisor. Un accesso host illegale causa l'inserimento di un'eccezione sincrona nell'host da parte dell'hypervisor, che può comportare la ricezione di un segnale SEGV da parte del task userspace responsabile o l'arresto anomalo del kernel host. Per evitare accessi accidentali, le pagine donate agli ospiti non sono idonee per lo scambio o l'unione da parte del kernel host.
Gestione degli interrupt e timer
Gli interrupt sono una parte essenziale del modo in cui un ospite interagisce con i dispositivi e per la comunicazione tra le CPU, dove gli interrupt interprocessore (IPI) sono il meccanismo di comunicazione principale. Il modello KVM prevede di delegare tutta la gestione degli interrupt virtuali all'host in EL1, che a questo scopo si comporta come una parte non attendibile dell'hypervisor.
pKVM offre un'emulazione completa di Generic Interrupt Controller versione 3 (GICv3) basata sul codice KVM esistente. Il timer e gli IPI vengono gestiti come parte di questo codice di emulazione non attendibile.
Supporto GICv3
L'interfaccia tra EL1 ed EL2 deve garantire che l'intero stato di interruzione sia visibile all'host EL1, incluse le copie dei registri dell'hypervisor correlati alle interruzioni. Questa visibilità viene in genere ottenuta utilizzando regioni di memoria condivisa, una per ogni CPU virtuale (vCPU).
Il codice di supporto del runtime del registro di sistema può essere semplificato per supportare solo il trapping dei registri SGIR (Software Generated Interrupt Register) e DIR (Deactivate Interrupt Register). L'architettura impone che questi registri vengano sempre intercettati da EL2, mentre le altre intercettazioni finora sono state utili solo per mitigare gli errata. Tutto il resto viene gestito nell'hardware.
Sul lato MMIO, tutto viene emulato a livello EL1, riutilizzando tutta l'infrastruttura attuale in KVM. Infine, Wait for Interrupt (WFI) viene sempre inoltrato a EL1, perché si tratta di una delle primitive di pianificazione di base utilizzate da KVM.
Supporto del timer
Il valore del comparatore per il timer virtuale deve essere esposto a EL1 su ogni trappola WFI in modo che EL1 possa inserire interruzioni del timer mentre la vCPU è bloccata. Il timer fisico è completamente emulato e tutti gli interrupt vengono inoltrati a EL1.
Gestione MMIO
Per comunicare con il monitor delle macchine virtuali (VMM) ed eseguire l'emulazione GIC, le intercettazioni MMIO devono essere ritrasmesse all'host in EL1 per un'ulteriore valutazione. pKVM richiede quanto segue:
- IPA e dimensioni dell'accesso
- Dati in caso di scrittura
- Endianness della CPU al momento dell'interruzione
Inoltre, i trap con un registro di uso generale (GPR) come origine/destinazione vengono inoltrati utilizzando un pseudo-registro di trasferimento astratto.
Interfacce guest
Un guest può comunicare con un guest protetto utilizzando una combinazione di hypercall e accesso alla memoria alle regioni intrappolate. Gli hypercall vengono esposti in base allo standard SMCCC, con un intervallo riservato a un'allocazione del fornitore da parte di KVM. Le seguenti chiamate di sistema sono di particolare importanza per gli ospiti pKVM.
Hypercall generiche
- PSCI fornisce un meccanismo standard per consentire al guest di controllare il ciclo di vita delle relative vCPU, inclusi l'online, l'offline e l'arresto del sistema.
- TRNG fornisce un meccanismo standard per consentire all'ospite di richiedere entropia alla pKVM, che inoltra la chiamata a EL3. Questo meccanismo è particolarmente utile quando non è possibile considerare attendibile l'host per la virtualizzazione di un generatore di numeri casuali (RNG) hardware.
Hypercall pKVM
- Condivisione della memoria con l'organizzatore. Tutta la memoria guest è inizialmente inaccessibile all'host, ma l'accesso host è necessario per la comunicazione con memoria condivisa e per i dispositivi paravirtualizzati che si basano su buffer condivisi. Le chiamate ipervisore per la condivisione e l'annullamento della condivisione delle pagine con l'host consentono all'ospite di decidere esattamente quali parti della memoria vengono rese accessibili al resto di Android senza la necessità di un handshake.
- Rilascio della memoria all'host. Tutta la memoria guest in genere appartiene
al guest finché non viene distrutta. Questo stato può essere inadeguato per le VM di lunga durata con requisiti di memoria che variano nel tempo. L'hypercall
relinquishconsente a un ospite di trasferire esplicitamente la proprietà delle pagine all'host senza richiedere la terminazione dell'ospite. - Trappola di accesso alla memoria all'host. Tradizionalmente, se un guest KVM accede a un indirizzo che non corrisponde a una regione di memoria valida, il thread vCPU esce dall'host e l'accesso viene in genere utilizzato per MMIO ed emulato dal VMM nello spazio utente. Per facilitare questa gestione, pKVM deve pubblicizzare i dettagli sull'istruzione che ha generato l'errore, come l'indirizzo, i parametri dei registri e potenzialmente i relativi contenuti all'host, il che potrebbe esporre involontariamente dati sensibili di un guest protetto se la trappola non era prevista. pKVM risolve questo problema trattando questi errori come irreversibili, a meno che il guest non abbia precedentemente emesso una chiamata iper per identificare l'intervallo IPA che ha generato l'errore come uno per il quale gli accessi sono autorizzati a tornare all'host. Questa soluzione è chiamata MMIO guard.
Dispositivo I/O virtuale (virtio)
Virtio è uno standard popolare, portatile e consolidato per l'implementazione e l'interazione con i dispositivi paravirtualizzati. La maggior parte dei dispositivi esposti agli ospiti protetti viene implementata utilizzando virtio. Virtio è alla base anche dell'implementazione di vsock utilizzata per la comunicazione tra un guest protetto e il resto di Android.
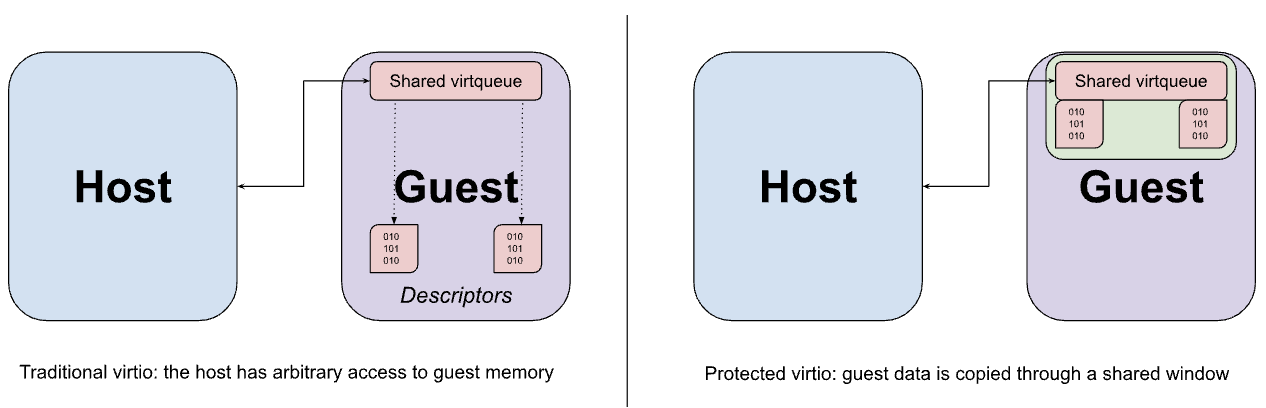
I dispositivi Virtio vengono in genere implementati nello spazio utente dell'host dal VMM, che intercetta gli accessi alla memoria intrappolati dal guest all'interfaccia MMIO del dispositivo Virtio ed emula il comportamento previsto. L'accesso MMIO è relativamente costoso perché ogni accesso al dispositivo richiede un round trip alla VMM e viceversa, quindi la maggior parte del trasferimento effettivo di dati tra il dispositivo e l'ospite avviene utilizzando un insieme di virtqueue in memoria. Un'ipotesi fondamentale di virtio è che l'host possa accedere alla memoria guest in modo arbitrario. Questa ipotesi è evidente nella progettazione di virtqueue, che potrebbe contenere puntatori a buffer nel guest a cui l'emulazione del dispositivo è destinata ad accedere direttamente.
Sebbene le chiamate ipervisore di condivisione della memoria descritte in precedenza possano essere utilizzate per condividere i buffer di dati virtio dal guest all'host, questa condivisione viene necessariamente eseguita con granularità di pagina e potrebbe finire per esporre più dati del necessario se la dimensione del buffer è inferiore a quella di una pagina. Al contrario, l'ospite è configurato per allocare sia le virtqueue sia i buffer di dati corrispondenti da una finestra fissa di memoria condivisa, con i dati copiati (rimbalzati) da e verso la finestra in base alle necessità.
Interazione con TrustZone
Sebbene gli ospiti non possano interagire direttamente con TrustZone, l'host deve comunque essere in grado di effettuare chiamate SMC nel mondo sicuro. Queste chiamate possono specificare buffer di memoria indirizzati fisicamente inaccessibili all'host. Poiché il software sicuro in genere non è a conoscenza dell'accessibilità del buffer, un host dannoso potrebbe utilizzare questo buffer per eseguire un attacco di tipo confused deputy (analogo a un attacco DMA). Per prevenire questi attacchi, pKVM intercetta tutte le chiamate SMC host a EL2 e funge da proxy tra l'host e il monitor sicuro a EL3.
Le chiamate PSCI dall'host vengono inoltrate al firmware EL3 con modifiche minime. Nello specifico, il punto di ingresso per una CPU che si connette o riprende dall'attesa viene riscritto in modo che la tabella delle pagine di fase 2 venga installata a EL2 prima di tornare all'host a EL1. Durante l'avvio, questa protezione viene applicata da pKVM.
Questa architettura si basa sul SoC che supporta PSCI, preferibilmente tramite l'utilizzo di una versione aggiornata di TF-A come firmware EL3.
Il framework del firmware per Arm (FF-A) standardizza le interazioni tra il mondo normale e quello sicuro, in particolare in presenza di un hypervisor sicuro. Una parte importante della specifica definisce un meccanismo per la condivisione della memoria con il mondo sicuro, utilizzando sia un formato di messaggio comune sia un modello di autorizzazioni ben definito per le pagine sottostanti. pKVM funge da proxy per i messaggi FF-A per garantire che l'host non tenti di condividere la memoria con il lato sicuro per il quale non dispone di autorizzazioni sufficienti.
Questa architettura si basa sul software secure world che applica il modello di accesso alla memoria, per garantire che le app attendibili e qualsiasi altro software in esecuzione in secure world possano accedere alla memoria solo se è di proprietà esclusiva di secure world o se è stata condivisa esplicitamente con esso utilizzando FF-A. Su un sistema con S-EL2, l'applicazione del modello di accesso alla memoria deve essere eseguita da un core Secure Partition Manager (SPMC), ad esempio Hafnium, che gestisce le tabelle di pagine di livello 2 per il mondo sicuro. Su un sistema senza S-EL2, il TEE può invece applicare un modello di accesso alla memoria tramite le tabelle di pagine di fase 1.
Se la chiamata SMC a EL2 non è una chiamata PSCI o un messaggio definito da FF-A, le chiamate SMC non gestite vengono inoltrate a EL3. Si presume che il firmware sicuro (necessariamente attendibile) possa gestire in sicurezza gli SMC non gestiti perché il firmware comprende le precauzioni necessarie per mantenere l'isolamento della pVM.
Monitor delle macchine virtuali
crosvm è un monitor delle macchine virtuali (VMM) che esegue macchine virtuali tramite l'interfaccia KVM di Linux. Ciò che rende unico crosvm è la sua attenzione alla sicurezza con l'uso del linguaggio di programmazione Rust e una sandbox intorno ai dispositivi virtuali per proteggere il kernel host. Per saperne di più su crosvm, consulta la documentazione ufficiale qui.
Descrittori di file e ioctl
KVM espone il dispositivo di caratteri /dev/kvm allo spazio utente con ioctl che compongono
l'API KVM. Gli ioctl appartengono alle seguenti categorie:
- Le ioctl di sistema eseguono query e impostano attributi globali che interessano l'intero sottosistema KVM e creano pVM.
- Le ioctl VM eseguono query e impostano attributi che creano CPU virtuali (vCPU) e dispositivi e influiscono su un'intera pVM, ad esempio includendo il layout della memoria e il numero di CPU virtuali (vCPU) e dispositivi.
- vCPU ioctls esegue query e imposta gli attributi che controllano il funzionamento di una singola CPU virtuale.
- Gli ioctl del dispositivo eseguono query e impostano gli attributi che controllano il funzionamento di un singolo dispositivo virtuale.
Ogni processo crosvm esegue esattamente un'istanza di una macchina virtuale. Questo processo
utilizza l'ioctl di sistema KVM_CREATE_VM per creare un descrittore del file VM che può
essere utilizzato per emettere ioctl pVM. Un ioctl KVM_CREATE_VCPU o KVM_CREATE_DEVICE
su un FD VM crea una vCPU/un dispositivo e restituisce un descrittore del file che punta alla
nuova risorsa. Gli ioctl su un FD vCPU o dispositivo possono essere utilizzati per controllare il dispositivo
che è stato creato utilizzando l'ioctl su un FD VM. Per le vCPU, questo include l'importante attività di esecuzione del codice guest.
Internamente, crosvm registra i descrittori di file della VM con il kernel utilizzando
l'interfaccia epoll attivata dal fronte. Il kernel quindi invia una notifica a crosvm ogni volta che
c'è un nuovo evento in attesa in uno dei descrittori di file.
pKVM aggiunge una nuova funzionalità, KVM_CAP_ARM_PROTECTED_VM, che può essere utilizzata per
ottenere informazioni sull'ambiente pVM e configurare la modalità protetta per una VM.
crosvm la utilizza durante la creazione di pVM se viene passato il flag --protected-vm,
per eseguire query e riservare la quantità di memoria appropriata per
il firmware pVM e poi per attivare la modalità protetta.
Allocazione della memoria
Una delle principali responsabilità di un VMM è l'allocazione della memoria della VM e la gestione del relativo layout. crosvm genera un layout di memoria fisso descritto in modo approssimativo nella tabella seguente.
| FDT in modalità normale | PHYS_MEMORY_END - 0x200000
|
| Spazio libero | ...
|
| Ramdisk | ALIGN_UP(KERNEL_END, 0x1000000)
|
| Kernel | 0x80080000
|
| Bootloader | 0x80200000
|
| FDT in modalità BIOS | 0x80000000
|
| Base della memoria fisica | 0x80000000
|
| Firmware pVM | 0x7FE00000
|
| Memoria del dispositivo | 0x10000 - 0x40000000
|
La memoria fisica viene allocata con mmap e viene donata alla VM per popolare le relative regioni di memoria, chiamate memslot, con l'ioctl KVM_SET_USER_MEMORY_REGION. Tutta la memoria pVM ospite viene quindi
attribuita all'istanza crosvm che la gestisce e può comportare l'interruzione del processo (terminando la VM) se l'host inizia a esaurire la memoria libera. Quando una VM viene arrestata, la memoria viene cancellata automaticamente
dall'hypervisor e restituita al kernel host.
In KVM normale, il VMM mantiene l'accesso a tutta la memoria guest. Con pKVM, la memoria guest viene mappata dallo spazio di indirizzi fisici host quando viene donata al guest. L'unica eccezione è la memoria condivisa esplicitamente dal guest, ad esempio per i dispositivi virtio.
Le regioni MMIO nello spazio di indirizzi dell'ospite vengono lasciate non mappate. L'accesso a queste regioni da parte dell'ospite viene intercettato e genera un evento I/O sul descrittore di file della VM. Questo meccanismo viene utilizzato per implementare i dispositivi virtuali. In modalità protetta, l'ospite deve riconoscere che una regione del suo spazio di indirizzi viene utilizzata per MMIO utilizzando una hypercall, per ridurre il rischio di perdita accidentale di informazioni.
Programmazione
Ogni CPU virtuale è rappresentata da un thread POSIX e pianificata dallo scheduler Linux host. Il thread chiama l'ioctl KVM_RUN sul descrittore di file vCPU, con conseguente
passaggio dell'hypervisor al contesto della vCPU guest. Lo scheduler host
tiene conto del tempo trascorso in un contesto ospite come tempo utilizzato dal thread vCPU corrispondente. KVM_RUN viene restituito quando si verifica un evento che deve essere gestito dal VMM, ad esempio I/O, fine dell'interruzione o arresto della vCPU. VMM gestisce
l'evento e chiama di nuovo KVM_RUN.
Durante KVM_RUN, il thread rimane preemptible dallo scheduler host, ad eccezione
dell'esecuzione del codice dell'hypervisor EL2, che non è preemptible. La pVM guest
non dispone di alcun meccanismo per controllare questo comportamento.
Poiché tutti i thread vCPU vengono pianificati come qualsiasi altra attività dello spazio utente, sono soggetti a tutti i meccanismi QoS standard. In particolare, ogni thread vCPU può essere associato a CPU fisiche, inserito in cpuset, potenziato o limitato utilizzando il blocco dell'utilizzo, la priorità/la policy di pianificazione può essere modificata e altro ancora.
Dispositivi virtuali
crosvm supporta diversi dispositivi, tra cui:
- virtio-blk per immagini disco composite, di sola lettura o lettura/scrittura
- vhost-vsock per la comunicazione con l'host
- virtio-pci come trasporto virtio
- pl030 real time clock (RTC)
- UART 16550a per la comunicazione seriale
Firmware pVM
Il firmware pVM (pvmfw) è il primo codice eseguito da una pVM, in modo simile alla ROM di avvio di un dispositivo fisico. L'obiettivo principale di pvmfw è di avviare l'avvio protetto e derivare il segreto univoco della pVM. pvmfw non è limitato all'uso con un sistema operativo specifico, ad esempio Microdroid, purché il sistema operativo sia supportato da crosvm e sia stato firmato correttamente.
Il binario pvmfw è memorizzato in una partizione flash con lo stesso nome e viene aggiornato tramite OTA.
Avvio del dispositivo
La seguente sequenza di passaggi viene aggiunta alla procedura di avvio di un dispositivo abilitato a pKVM:
- Android Bootloader (ABL) carica pvmfw dalla sua partizione in memoria e verifica l'immagine.
- L'ABL ottiene i segreti di Device Identifier Composition Engine (DICE) (Compound Device Identifiers (CDI) e catena di certificati DICE) da una radice di attendibilità.
- ABL deriva i CDI necessari per pvmfw e li aggiunge al binario pvmfw.
- L'ABL aggiunge un nodo
linux,pkvm-guest-firmware-memorydella regione di memoria riservata al DT, che descrive la posizione e le dimensioni del binario pvmfw e dei segreti derivati nel passaggio precedente. - ABL passa il controllo a Linux e Linux inizializza pKVM.
- pKVM esegue l'unmapping della regione di memoria pvmfw dalle tabelle di pagine di secondo livello dell'host e la protegge dall'host (e dagli ospiti) per tutto il tempo di attività del dispositivo.
Dopo l'avvio del dispositivo, Microdroid viene avviato in base ai passaggi descritti nella sezione Sequenza di avvio del documento Microdroid.
Avvio di pVM
Quando crei una pVM, crosvm (o un altro VMM) deve creare un memslot sufficientemente grande da essere compilato con l'immagine pvmfw dall'hypervisor. Il VMM è anche limitato nell'elenco dei registri il cui valore iniziale può essere impostato (x0-x14 per la vCPU primaria, nessuno per le vCPU secondarie). I registri rimanenti sono riservati e fanno parte dell'ABI hypervisor-pvmfw.
Quando viene eseguita la pVM, l'hypervisor passa prima il controllo della vCPU principale
a pvmfw. Il firmware prevede che crosvm abbia caricato un kernel firmato AVB, che può essere un bootloader o qualsiasi altra immagine, e un FDT non firmato nella memoria a offset noti. pvmfw convalida la firma AVB e, se l'operazione va a buon fine, genera un Device Tree attendibile dall'FDT ricevuto, cancella i suoi secret dalla memoria e passa all'entry point del payload. Se uno dei passaggi di verifica non va a buon fine, il firmware emette una chiamata ipervisore PSCI SYSTEM_RESET.
Tra un avvio e l'altro, le informazioni sull'istanza pVM vengono archiviate in una partizione (dispositivo virtio-blk) e criptate con il secret di pvmfw per garantire che, dopo un riavvio, il secret venga sottoposto a provisioning nell'istanza corretta.